
SimoSet: A 3D Object Detection Dataset Collected from Vehicle Hybrid Solid-State LiDAR


Abstract
:1. Introduction
- (1)
- We present a single modal point cloud dataset named SimoSet. It is the world’s first open-source dataset dedicated to the task of 3D object detection and uses a hybrid solid-state LiDAR to collect point cloud data.
- (2)
- Data for SimoSet were collected in a university campus, including complex traffic environments, varied time periods and lighting conditions, and major traffic participant annotation classes. Based on SimoSet, we provide baselines for LiDAR-only 3D object detection.
- (3)
- The SimoSet dataset is aligned to the KITTI format for direct use by researchers. We share the procedure of data collection, annotation, and format conversion for LiDAR, which can be used as a reference for researchers to process custom data.
2. Related Work
2.1. Related Datasets
2.2. LiDAR-Only 3D Object Detection Methods
3. SimoSet Dataset
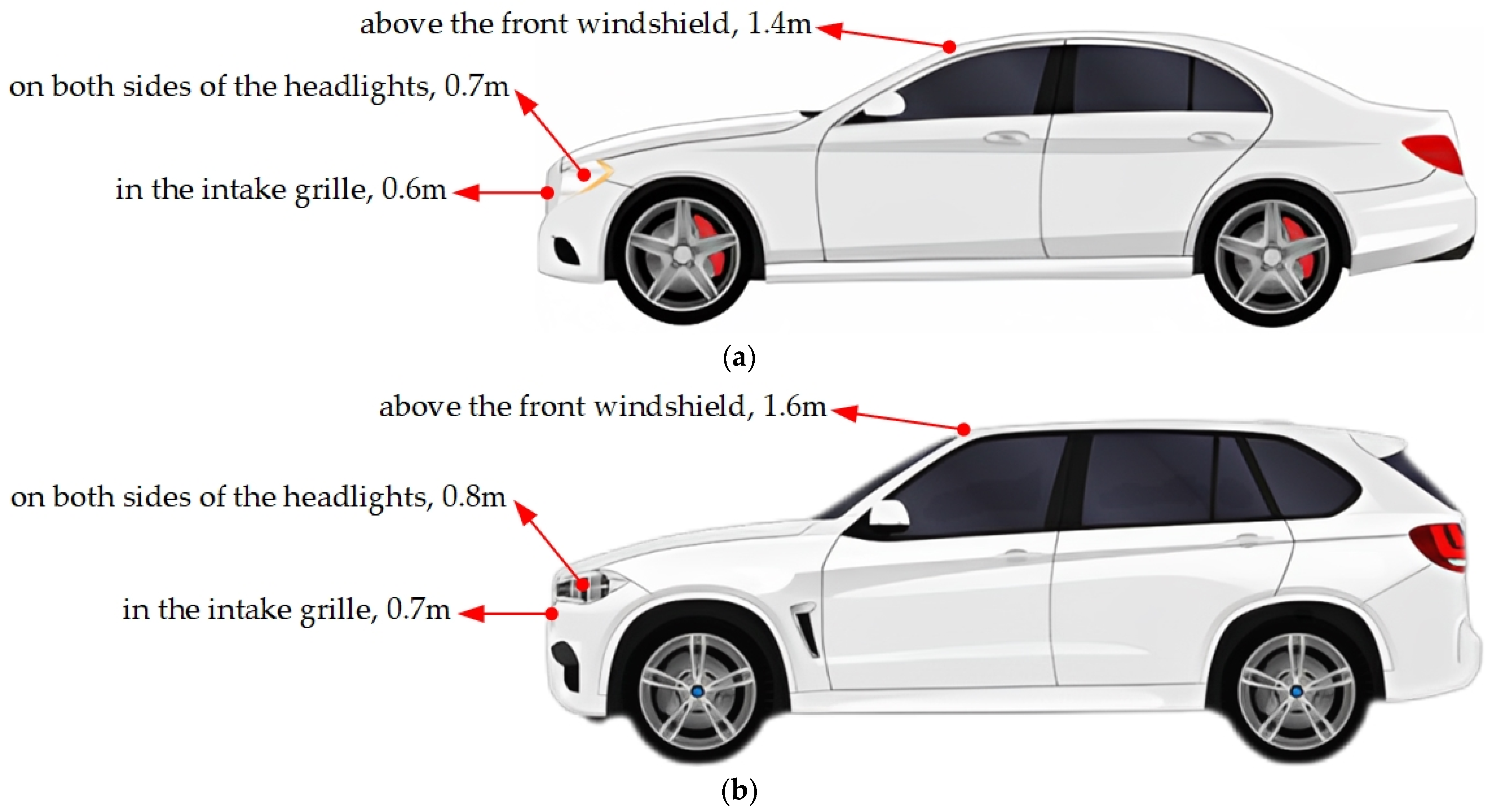
3.1. Sensor Specification and Layout
3.2. Scene Selection and Data Annotation
3.3. Format Conversion and Dataset Statistics
4. Baseline Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Koopman, P.; Wagner, M. Autonomous Vehicle Safety: An Interdisciplinary Challenge. IEEE Intell. Transp. Syst. Mag. 2017, 9, 90–96. [Google Scholar] [CrossRef]
- Khan, M.A.; EI Sayed, H.; Malik, S.; Zia, T.; Khan, J.; Alkaabi, N.; Ignatious, H. Level-5 Autonomous Driving-Are We There Yet? A Review of Research Literature. ACM Comput. Surv. 2023, 55, 27. [Google Scholar] [CrossRef]
- Li, Y.; Ibanez-Guzman, J. Lidar for Autonomous Driving: The Principles, Challenges, and Trends for Automotive Lidar and Perception Systems. IEEE Signal Process. Mag. 2020, 37, 50–61. [Google Scholar] [CrossRef]
- Roriz, R.; Cabral, J.; Gomes, T. Automotive LiDAR Technology: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6282–6297. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.C.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet plus plus: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Theodose, R.; Denis, D.; Chateau, T.; Fremont, V.; Checchin, P. A Deep Learning Approach for LiDAR Resolution-Agnostic Object Detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 14582–14593. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A Survey on 3D Object Detection Methods for Autonomous Driving Applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.F.; Zhong, Z.L.; Liu, F.; Chapman, M.A.; Cao, D.P.; Li, J.T. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Huang, X.Y.; Wang, P.; Cheng, X.J.; Zhou, D.F.; Geng, Q.C.; Yang, R.G. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2702–2719. [Google Scholar] [CrossRef] [PubMed]
- Patil, A.; Malla, S.; Gang, H.M.; Chen, Y.T. The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes. In Proceedings of the International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 9552–9557. [Google Scholar]
- Houston, J.; Zuidhof, G.; Bergamini, L.; Ye, Y.W.; Chen, L.; Jain, A.; Omari, S.; Iglovikov, V.; Ondruska, P. One Thousand and One Hours: Self-driving Motion Prediction Dataset. arXiv 2020, arXiv:2006.14480. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8740–8749. [Google Scholar]
- Pham, Q.H.; Sevestre, P.; Pahwa, R.S.; Zhan, H.J.; Pang, C.H.; Chen, Y.D.; Mustafa, A.; Chandrasekhar, V.; Lin, J. A*3D Dataset: Towards Autonomous Driving in Challenging Environments. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–15 June 2020; pp. 2267–2273. [Google Scholar]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2D2: Audi Autonomous Driving Dataset. arXiv 2020, arXiv:2004.06320. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.N.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2443–2451. [Google Scholar]
- Wang, Z.; Ding, S.H.; Li, Y.; Fenn, J.; Roychowdhury, S.; Wallin, A.; Martin, L.; Ryvola, S.; Sspiro, G.; Qiu, Q. Cirrus: A Long-range Bi-pattern LiDAR Dataset. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 5744–5750. [Google Scholar]
- Xiao, P.C.; Shao, Z.L.; Hao, S.; Zhang, Z.S.; Chai, X.L.; Jiao, J.; Li, Z.S.; Wu, J.; Sun, K.; Jiang, K.; et al. PandaSet: Advanced Sensor Suite Dataset for Autonomous Driving. In Proceedings of the IEEE International Transportation Systems Conference, Indianapolis, IN, USA, 19–22 September 2021; pp. 3095–3101. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.X.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, J.B.; Yang, J.O.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12689–12697. [Google Scholar]
- Zheng, W.; Tang, W.L.; Chen, S.J.; Jiang, L.; Fu, C.W. CIA-SSD: Confident IoU-Aware Single-Stage Object Detector from Point Cloud. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 3555–3562. [Google Scholar]
- Shi, S.S.; Wang, Z.; Shi, J.P.; Wang, X.G.; Li, H.S. From Points to Parts: 3D Object Detection from Point Cloud with Part-Aware and Part-Aggregation Network. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- He, C.H.; Zeng, H.; Huang, J.Q.; Hua, X.S.; Zhang, L. Structure Aware Single-Stage 3D Object Detection from Point Cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11870–11879. [Google Scholar]
- Deng, J.J.; Shi, S.S.; Li, P.W.; Zhou, W.G.; Zhang, Y.Y.; Li, H.Q. Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 1201–1209. [Google Scholar]
- Zhou, S.F.; Tian, Z.; Chu, X.X.; Zhang, X.Y.; Zhang, B.; Lu, X.B.; Feng, C.J.; Jie, Z.Q.; Chiang, P.K.; Ma, L. FastPillars: A Deployment-friendly Pillar-based 3D Detector. arXiv 2023, arXiv:2302.02367. [Google Scholar]
- Yin, T.W.; Zhou, X.Y.; Krahenbuhl, P. Center-based 3D Object Detection and Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 11779–11788. [Google Scholar]
- Chen, Y.K.; Liu, J.H.; Zhang, X.Y.; Qi, X.J.; Jia, J.Y. VoxelNeXt: Fully Sparse VoxelNet for 3D Object Detection and Tracking. arXiv 2023, arXiv:2303.11301. [Google Scholar]
- Shi, S.S.; Wang, X.G.; Li, H.S. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 770–779. [Google Scholar]
- Yang, Z.T.; Sun, Y.N.; Liu, S.; Jia, J.Y. 3DSSD: Point-based 3D Single Stage Object Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2019; pp. 11037–11045. [Google Scholar]
- Zhang, Y.F.; Hu, Q.Y.; Xu, G.Q.; Ma, Y.X.; Wan, J.W.; Guo, Y.L. Not All Points Are Equal: Learning Highly Efficient Point-based Detectors for 3D LiDAR Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18931–18940. [Google Scholar]
- Liu, Z.J.; Tang, H.T.; Lin, Y.J.; Han, S. Point-Voxel CNN for Efficient 3D Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Shi, S.S.; Guo, C.X.; Jiang, L.; Wang, Z.; Shi, J.P.; Wang, X.G. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10526–10535. [Google Scholar]
- Noh, J.; Lee, S.; Ham, B. HVPR: Hybrid Voxel-Point Representation for Single-stage 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14600–14609. [Google Scholar]
- Li, Z.C.; Wang, F.; Wang, N.F. LiDAR R-CNN: An Efficient and Universal 3D Object Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7542–7551. [Google Scholar]
- Li, E.; Wang, S.J.; Li, C.Y.; Li, D.C.; Wu, X.B.; Hao, Q. SUSTech POINTS: A PorTable 3D Point Cloud Interactive Annotation Platform System. In Proceedings of the IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 23–16 June 2020; pp. 1108–1115. [Google Scholar]
- Simonelli, A.; Bulò, S.R.; Porzi, L.; Lopez-Antequera, M.; Kontschieder, P. Disentangling Monocular 3D Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1991–1999. [Google Scholar]
- Zhu, B.J.; Jiang, Z.K.; Zhou, X.X.; Li, Z.M.; Yu, G. Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection. arXiv 2019, arXiv:1908.09492. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | LiDARs | Scenes | Ann. Frames | Classes | Night | Locations |
|---|---|---|---|---|---|---|---|
| KITTI | 2012 | 1 × MS | 22 | 7481 | 8 | No | Germany |
| ApolloScape | 2019 | 2 × MS | - | 144k | 6 | Yes | China |
| H3D | 2019 | 1 × MS | 160 | 27k | 8 | No | USA |
| Lyft L5 | 2019 | 3 × MS | 366 | 46k | 9 | No | USA |
| Argoverse | 2019 | 2 × MS | 113 | 22k | 15 | Yes | USA |
| A*3D | 2019 | 1 × MS | - | 39k | 7 | Yes | SG |
| A2D2 | 2020 | 5 × MS | - | 12k | 14 | Yes | Germany |
| nuScenes | 2020 | 1 × MS | 1k | 40k | 23 | Yes | SG, USA |
| Waymo Open | 2020 | 5 × MS | 1150 | 200k | 4 | Yes | USA |
| Cirrus | 2020 | 2 × FF | 12 | 6285 | 8 | Yes | USA |
| Pandaset | 2021 | 1 × MS 1 × FF | 103 | 8240 | 28 | Yes | USA |
| Simoset | 2023 | 1 × FF | 52 | 4160 | 3 | Yes | China |
| LiDAR | Details |
|---|---|
| 1 × hybrid solid-state LiDAR | MEMS mirror-based scanning, 120° horizontal FOV, 25° Vertical FOV, equivalent to 125 channels @ 10 Hz, 150 m range @ 10% reflectivity (Robosense RS-LiDAR-M1) |
| Method | Type | Stage | GPU | Class | AP3D(%) | |
|---|---|---|---|---|---|---|
| LEVEL_1 | LEVEL_2 | |||||
| SECOND | Voxel-based | One | GTX 3070 | Car | 80.23 | 65.71 |
| Cyclist | 81.52 | 45.08 | ||||
| Pedestrian | 78.16 | 38.92 | ||||
| PointPillars | Voxel-based | One | Car | 78.73 | 63.15 | |
| Cyclist | 84.05 | 47.13 | ||||
| Pedestrian | 81.50 | 42.55 | ||||
| SA-SSD | Voxel-based | One | Car | 82.79 | 68.93 | |
| Cyclist | 86.36 | 47.87 | ||||
| Pedestrian | 85.28 | 45.29 | ||||
| PointRCNN | Point-based | Two | Car | 80.65 | 67.00 | |
| Cyclist | 85.27 | 47.53 | ||||
| Pedestrian | 85.45 | 21.81 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Jin, L.; He, Y.; Wang, H.; Huo, Z.; Shi, Y. SimoSet: A 3D Object Detection Dataset Collected from Vehicle Hybrid Solid-State LiDAR. Electronics 2023, 12, 2424. https://doi.org/10.3390/electronics12112424
Sun X, Jin L, He Y, Wang H, Huo Z, Shi Y. SimoSet: A 3D Object Detection Dataset Collected from Vehicle Hybrid Solid-State LiDAR. Electronics. 2023; 12(11):2424. https://doi.org/10.3390/electronics12112424
Chicago/Turabian StyleSun, Xinyu, Lisheng Jin, Yang He, Huanhuan Wang, Zhen Huo, and Yewei Shi. 2023. "SimoSet: A 3D Object Detection Dataset Collected from Vehicle Hybrid Solid-State LiDAR" Electronics 12, no. 11: 2424. https://doi.org/10.3390/electronics12112424
APA StyleSun, X., Jin, L., He, Y., Wang, H., Huo, Z., & Shi, Y. (2023). SimoSet: A 3D Object Detection Dataset Collected from Vehicle Hybrid Solid-State LiDAR. Electronics, 12(11), 2424. https://doi.org/10.3390/electronics12112424