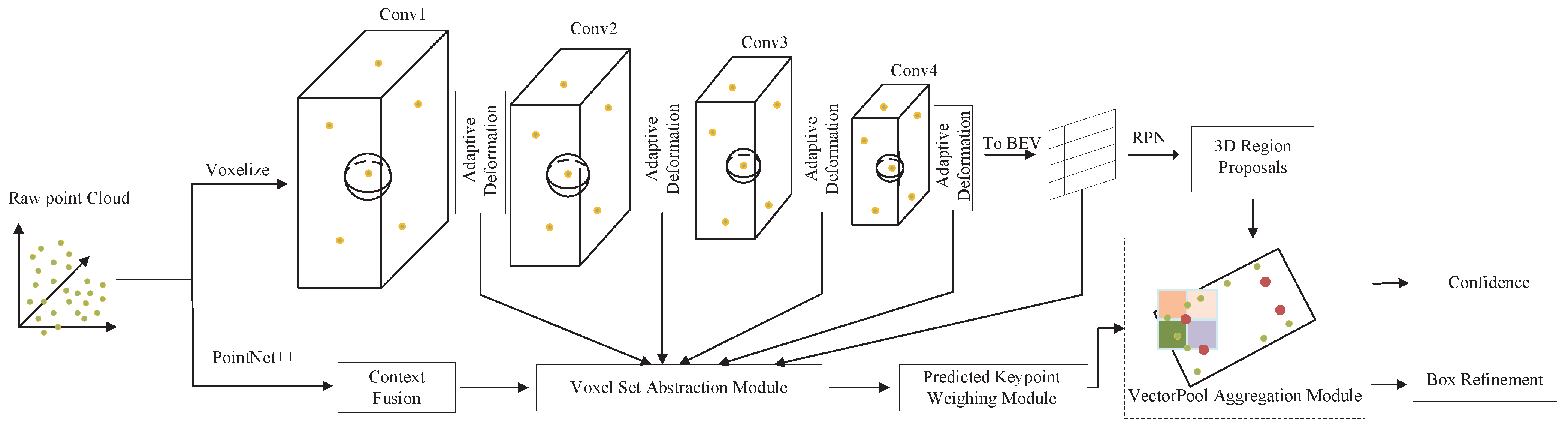
We designed a network that can fully adapt to different object sizes and reduce computing resource consumption. First, the set abstraction for voxel feature extraction in PV-RCNN is replaced with an adaptive deformation module, which can aggregate the instance features of object features of different scales on the keypoints; secondly, the set abstraction in the aggregation operation of the keypoints features in the second stage of PV-RCNN is replaced by the VectorPool aggregation module to display and encode the spatial structure information of the keypoints features; finally, the context fusion module is used to filter the keypoints features obtained directly from PointNet++ in PV-RCNN, dynamically select representative and discriminative features from local evidence, and adaptively highlight relevant contextual features. In this section, a brief introduction to the original PV-RCNN model is given first, followed by a detailed description of the voxel set abstraction module, deformable convolution, adaptive deformation module, context fusion module, roI-grid pooling module, and VectorPool aggregation module.
3.2. Voxel Set Abstraction Module
The voxel set abstraction (VSA) module is used to encode the voxel features in the scene in the 3D sparse convolution into a set of keypoints, that is, each keypoint uses the set abstraction operation proposed by PointNet++ [
9] to aggregate voxel features at multiple scales. Specifically, the FurthestPoint-Sampling (FPS) algorithm is used to sample
n keypoints
from the entire point cloud P, where in the KITTI dataset
, the keypoints can be evenly distributed in the entire point by the FurthestPoint-Sampling (FPS) algorithm, it can represent the entire point cloud scene, the keypoints are surrounded by voxel features obtained through 3D sparse convolution, and the keypoints directly use the set abstraction in PointNet++ to perform multi-scale feature extraction on the surrounding voxel features.
Specifically,
is represented as the non-empty voxel feature vector set of the
k-th layer of the 3D sparse convolution, and
is represented as the three-dimensional coordinates of the non-empty voxel of the
k-th layer of the 3D sparse convolution, where
is the number of non-empty voxels in the
k-th layer of 3D sparse convolution, for each keypoint
, we first search for non-empty voxels within the radius
of the
k-th layer to obtain the voxel-level feature vector set of the keypoint
as:
It concatenates the local relative coordinates
to represent the relative position of the semantic voxel feature
. The voxel features in the adjacent voxel set
of
are then transformed by Set Abstraction in PointNet++ [
9] to generate the features of the keypoint
:
where
represents random sampling of at most
voxels from the adjacent voxel set
to save computation, and
represents a simple MLP network.
represents the maximum pooling operation on all adjacent voxel features
along all channels of the voxel.
Finally, by concatenating the keypoint features of all layers, the final feature of the keypoint
is obtained:
The above is the whole content of the voxel set abstraction module. When using the set abstraction of PointNet++ [
9] to extract the surrounding neighborhood features, multiple scales are used to extract the surrounding voxel features. Although good results have been achieved, it cannot fully adapt to problems such as different object scales, different point cloud densities, clutter, etc., resulting in some objects not being detected. For example, sometimes the keypoints are far from the object or the center of the object, and the features extracted by the key points cannot well-represent the shape of the object and cannot fully adapt to objects of different sizes, which may easily cause wrong detection results and lead to a decrease in accuracy.
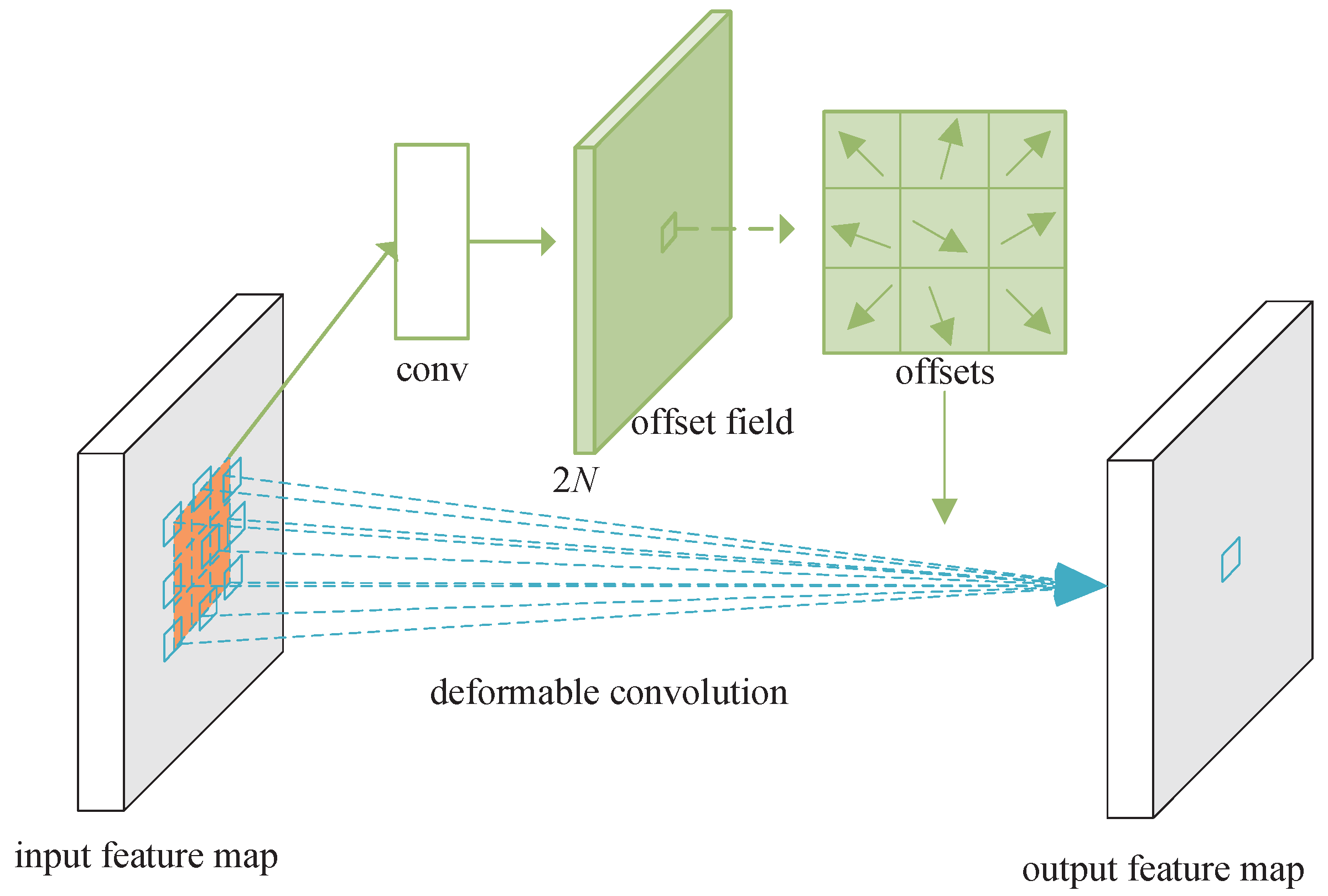
3.3. Deformable Convolution
In 2D object detection, deformable convolution has shown its powerful ability. Deformable convolution can adaptively shift the position of sampling points to a place with richer feature information, so as to sample richer feature information and fully adapt to objects of different sizes, as shown in
Figure 3.
The core of 2D convolution is the convolution kernel
R, which is used to sample the feature map
x. The convolution kernel determines the size of the receptive field, such as the 3 × 3 kernel:
In order to achieve each position
on the output feature map
y, we have
where
is each position in the convolution kernel
R.
In deformable convolution, the convolution kernel
R uses the offset
to obtain a new sampling position, where
. Equation (
5) becomes:
Now, the position of the convolution kernel sampling is
. Since the offset
is usually a fraction, Equation (
6) is realized by bilinear interpolation as:
where
p represents any (fractional) position (
in Equation (
6)),
q enumerates all integral spatial positions in the feature map
x, and
is the bilinear interpolation kernel. Note that
E is two-dimensional. It is split into two 1D kernels:
where
.
The offset is obtained by applying a convolutional layer, and the offset has many different forms, as shown in
Figure 4, which lists three different offset forms. The output offset has 2N dimensions, corresponding to N two-dimensional offsets.
3.4. Adaptive Deformation Module
The adaptive deformation module extends the core principle of deformable convolution to 3D, and the keypoints can adaptively learn the characteristics of objects of different scales through the adaptive deformation module. As shown in
Figure 5, in 3D, the keypoints replace the sampling positions of the regular grid in two dimensions. First, the keypoints collect the non-empty voxels in the surrounding neighborhood, and then obtain the offset and new features by adaptively learning the features in the non-empty voxels in the surrounding neighborhood, this new feature is the feature of the deformed keypoints, and then add the learned offset to the original keypoint coordinates to obtain the deformed keypoint coordinates, and then perform feature extraction according to the set abstraction in PointNet++ in PV-RCNN to obtain the final deformed keypoint features, as shown in
Figure 5.
Specifically, the sampled n keypoints
have 3D positions
and feature vectors
corresponding to each layer of Conv1, Conv2, Conv3 or Conv4, and our module computes the updated feature
as follows:
where
refers to the number of non-empty voxels in the neighborhood around the i-th keypoint, and
is a weight matrix for learning keypoint offsets. Then, we obtain new deformed keypoint positions as
, where
is a weight matrix for learning keypoint position alignment. This is similar to the alignment in Mesh R-CNN [
19] and PointDAN [
20]. After obtaining the new deformation key points and their features, we use the set abstraction in PointNet++ [
9] in PV-RCNN to perform feature extraction on the new deformation key points.
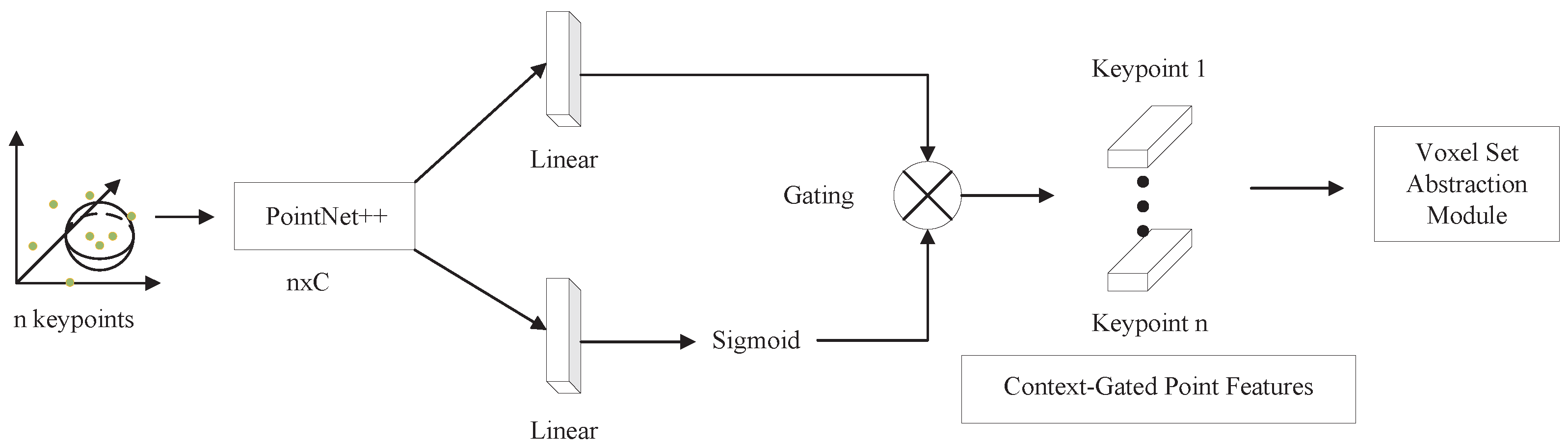
3.5. Context Fusion Module
The context fusion module uses the context gating mechanism to select relatively representative point cloud features, and uses two independent linear layers on the key points, one of which uses the Sigmoid function on the linear layer, and the other linear layer does not, and then multiplying these two streams can strengthen those relatively prominent features and suppress those inconspicuous features, which can provide more representative features for the subsequent refinement of candidate boxes, as shown in
Figure 6.
Specifically, the key point feature is given, the gating weights are obtained as , and the context gating features are obtained as , where , , are the weight parameter learned from the data.
3.6. RoI-Grid Pooling Module
RoI-grid pooling module uses the 3D candidate boxes generated by 3D sparse convolution to select a certain number of grid points. Each grid point uses the set abstraction in Pointnet++ [
9] to obtain the keypoint features of the surrounding neighborhood, and the keypoint features contain very rich point cloud scene information, so each grid point has very rich information, as shown in
Figure 7.
Specifically, a
grid point is uniformly sampled in each 3D candidate box, denoted as
. Through the set abstraction in PointNet++, the keypoint features
are aggregated into the grid points. More precisely, we first determine the adjacent keypoints of grid point
within radius
as:
where
denotes the local relative position of the feature
starting from keypoint
. Then, we use the set abstraction in PointNet++ [
9] to aggregate the adjacent key point feature set
to generate the features of the grid point
:
where
represents random sampling of at most
voxels from the keypoint neighborhood set
to save computation, and
represents a simple MLP.
represents the maximum pooling operation on all adjacent keypoint features
along all channels of the keypoint features.
After each grid point obtains rich features from surrounding keypoints, all grid point features in the same candidate box can obtain a 3D prediction box representing the entire scene through a two-layer MLP with 256 dimensions.
In this module, the set abstraction operation in PointNet++ is used to capture richer context information with a flexible receptive field, and even the receptive field exceeds the boundary of the 3D candidate boxes to capture the surrounding keypoint features outside the 3D candidate boxes. However, the set abstraction operation is very time-consuming and resource-consuming in large-scale point clouds, because it applies several shared parameter MLP layers on each local point, and the maximum pooling operation in set abstraction abandons the local points. Spatial distribution information greatly impairs the ability of grid points to gather local features.
3.7. VectorPool Aggregation Module
The VectorPool aggregation module is very suitable for local feature aggregation of large-scale point cloud scenes. Firstly, by collecting the keypoints in the cube neighborhood centered on the grid point, and then dividing the cube neighborhood into multiple sub-voxels, each sub-voxel feature is extracted, and then each sub-voxel feature is assigned independent kernel weights and channels to generate local features sensitive to local position information. Finally, all channel features are concatenated into a single vector, which not only preserves the local information of the cubic neighborhood of the grid points, but also avoids the use of MLP with shared parameters, reducing the consumption of computing resources, as shown in
Figure 8.
Specifically,
is the set of keypoints after Voxel Set Abstraction,
M is the number of keypoints,
is the number of feature channels of keypoints,
is the set of grid points generated by using 3D candidate boxes, and
N is the number of grid points. Given a grid point
, first determine the set of keypoints in its cubic neighborhood, which can be expressed as:
where
is half the length of the cube space,
obtains the maximum axis alignment value of the 3D distance. We double the half-length of the cubic space of grid points to include more keypoints, which is beneficial for the local feature aggregation of this grid point.
In order to generate position-sensitive features in a local 3D neighborhood centered on
, we split its adjacent 3D space into
small local sub-voxels. Inspired by PointNet++, we use an inverse distance weighting strategy to interpolate the features of the
t-th sub-voxel by considering its three nearest neighbors to
, where
represents the index of each sub-voxel, and we assign its corresponding sub-voxel. The center is denoted as
. We can then generate the features of the
t-th subvoxel as:
where
,
refers to the set of indices of
’s three nearest neighbors (i.e.,
) in the neighbor set
. The result
is the local feature encoding for a specific -th local sub-voxel in the local cube.
Features in different local sub-voxels may represent very different local features. Therefore, instead of encoding local features using a shared parameter MLP as in PointNet++, we use separate local kernel weights to encode different local sub-voxels to capture position-sensitive features:
where
represents the relative position of the three nearest neighbors of
,
is the concatenation operation that fuses the relative position and features,
is the learnable kernel weight value of the
t-th local sub-voxel-specific feature encoded by the feature channel
, and the different positions encode position-sensitive local features that have different learnable kernel weights.
Finally, we directly sort the spatial order of the local sub-voxel features
along each 3D axis, and concatenate their features in order to generate the final local vector expressed as:
where
. Intra-sequence stitching encodes structure-preserved local features by simply assigning features at different locations to corresponding feature channels, naturally preserving the spatial structure of local features in the adjacent space centered at
, and finally for this local vector, representation performs multiple MLPs processing, and encodes the local features into the
feature channel for subsequent processing.
Compared with set abstraction, the VectorPool aggregation module performs position-sensitive local feature encoding on different regions centered on grid points through independent kernel weights and channels, which not only preserves the spatial structure of grid points well, but also saves on computation resource consumption.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}