



Recommender System Metaheuristic for Optimizing Decision-Making Computation

Abstract
:1. Introduction
2. Problem Context
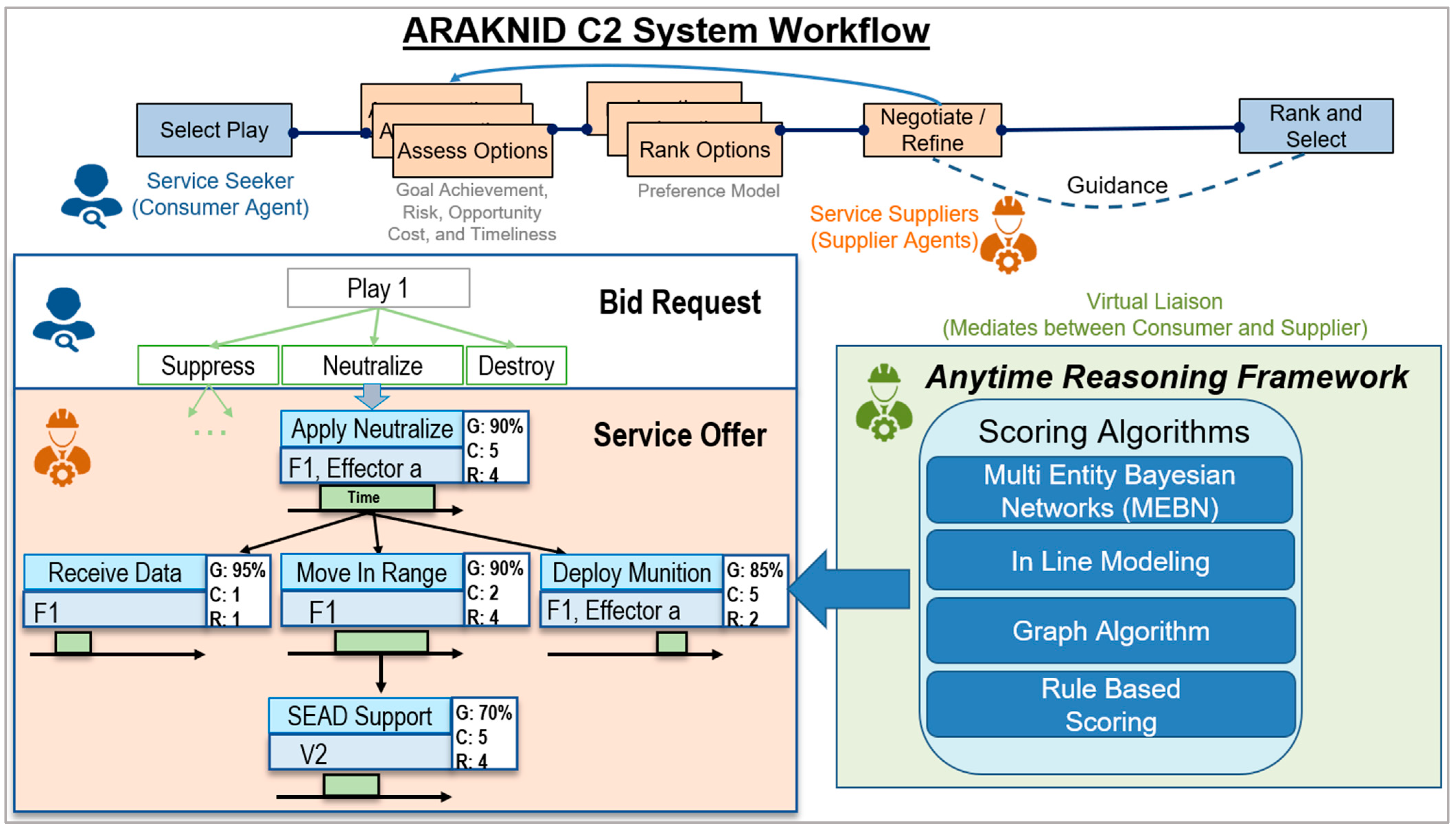
2.1. Command and Control Problem Summary
- Automatically computes, scores, and ranks C2-webs involving multiple Courses of Action (CoAs) sourced in real-time with assets across all warfighting domains;
- Provides battle managers with meaningful tradeoffs to select the CoA that best meets commander’s intent;
- Reduces latencies via machine-to-machine messaging during CoA execution.
2.2. Data Available for Further Optimization
- Requester preferences: The C2 requester may have the option to manually enter key metric preferences into our RS system (such as wanting to value the key metric of risk more than timeliness, etc.), or the C2 system may have an automated system for determining the requester preferences (such as automatically choosing to value timeliness more than risk if the request consists of a rescue scenario), both of which can be considered within our optimizations.
- CoA optimality: Near-optimal choices are important because this computation step can be the difference between, for example, a rescue mission succeeding or failing, an incoming cruise missile being successfully intercepted or allowed into a populated area, etc. CoA optimality is measured as a weighted average of each CoA’s key metrics (timeliness, risk, etc.).
- CoA diversity: Diversity of CoAs provided in the output options is important because it provides the requester flexibility in choosing a slightly less optimal CoA in terms of calculated metrics, which may be a better fit based on the requester’s past experiences.
- CoA feedback: Incorporation of feedback from users, simulations, and real-world results into the RS is important because we want the RS to consider collective human wisdom/experience during CoA selection, as well as prior simulations and real-world results of similar scenarios portraying which types of CoA choices result in the best global outcomes.
- RS computation time: Overall C2 computation response time is often required to be a few seconds or less in crisis-level situations. To support the overall C2 system’s need for fast response times, RS inference computation time must also be minimal.
3. Methods
3.1. Solution Formulation
3.2. RS Metric Calculation Methods
- Preference measure: Based on user preferences, the metric ranks the CoAs based on a simple weighted sum against quantitative CoA key metrics;
- Optimality measure: A novel “Pareto-mesh” technique for quantitative CoA metrics, which offers robust and computationally efficient comparisons of Pareto-front percent coverages among ranking options;
- Diversity measure: A novel “linchpin-based qualitative/quantitative diversity” technique that considers qualitative data’s Hamming distances, quantitative data’s Euclidean distances, and optimizes diversity of returned CoAs based a chosen top linchpin CoA using maximin optimization;
- Feedback measure: Based on implicit user choices, peripheral simulation results, and real-world scenario results, collaborative filtering methods such as Neural Collaborative Filtering (NCF) [29] can be used to predict requester/CoA ratings.
3.3. Optimization of RS Performance
4. Results
4.1. RS Model Tuning Results
4.2. Realistic C2 System’s Simplified RS Metaheuristic Results against Baseline
- “pK”: Estimates ranking of potential CoA parameters with the goal of maximizing probability of successful engagement with an enemy, which is an estimation of the “goal achievement” C2 metric;
- “ClosestAgents”: Estimates ranking of potential CoA parameters with the goal of choosing agents that are closest to the requested mission area, which is an estimation of the “timeliness” and “goal achievement” C2 metrics;
- “LowestCurrentTasking”: Estimates ranking of potential CoA parameters with the goal of choosing agents which have minimal existing tasking within their schedules, for reducing potential availability conflicts during instantiation, which is again an estimation of both the “timeliness” and “goal achievement” C2 metrics;
- “AllThree”: Estimates ranking of potential CoA parameters through a combination of the three aforementioned ranking estimators.
4.3. Experimental C2 System’s Comprehensive RS Metaheuristic Results against Baseline
- Instantiation computation time per CoA: 9.8 ms, with a standard deviation of 3.8 ms;
- RS ranking accuracy for select C2 metrics:
- ○
- “Timeliness” metric average accuracy of 92.7% with a standard deviation of 6.1%;
- ○
- “Goal achievement” metric average accuracy of 86.8% with a standard deviation of 11.4%.
- Baseline: Baseline algorithm using a pure combinatorics technique to instantiate all possible CoA options, with no RS search space reduction implemented;
- RS to Maximize Optimality: Maximizes Optimality based on the estimated realistic C2 system’s “ranking accuracy” of each C2 metric;
- RS to Maximize Optimality/Diversity/Feedback/Preference: Maximizes Optimality, Diversity, Feedback, and Preference using the model tuning parameters discussed in a prior section, a human-input Feedback weighting of 22%, and a human-input Preference weighting of 22%
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hamdy, T. Operations Research: An Introduction, 10th ed.; Pearson: London, UK, 2016. [Google Scholar]
- Adam, E.E.; Ebert, R.J. Production and Operations Management: Concepts, Models, and Behavior; Prentice Hall: Englewood Cliffs, NJ, USA, 1992. [Google Scholar]
- Assad, A.A.; Gass, S.I. Profiles in Operations Research: Pioneers and Innovators; Springer Science & Business Media: New York, NY, USA, 2011; Volume 147. [Google Scholar]
- Balci, O. Computer Science and Operations Research: New Developments in Their Interfaces; Elsevier: New York, NY, USA, 2014. [Google Scholar]
- Winston, W.L. Operations Research: Applications and Algorithms, 4th ed.; Brooks/Cole: Boston, MA, USA, 2004. [Google Scholar]
- Du, K.L.; Swamy, M.N.S. Search and Optimization by Metaheuristics; Birkhäuser: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Gendreau, M.; Potvin, J.-Y. Handbook of Metaheuristics; Springer: New York, NY, USA, 2010; Volume 2. [Google Scholar]
- Glover, F.W.; Kochenberger, G.A. Handbook of Metaheuristics; Springer Science & Business Media: New York, NY, USA, 2006; Volume 5. [Google Scholar]
- Li, D.; Lian, J.; Zhang, L.; Ren, K.; Lu, D.; Wu, T.; Xie, X. Recommender Systems: Frontiers and Practices; Publishing House of Electronics Industry: Beijing, China, 2022. (In Chinese) [Google Scholar]
- Argyriou, A.; González-Fierro, M.; Zhang, L. Microsoft Recommenders: Best Practices for Production-Ready Recommendation Systems. In Proceedings of the WWW 2020: Companion Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, T.; Xie, X.; Argyriou, A.; González-Fierro, M.; Lian, J. Building Production-Ready Recommendation System at Scale. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining 2019 (KDD 2019), Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Graham, S.; Min, J.K.; Wu, T. Microsoft recommenders: Tools to accelerate developing recommender systems, RecSys ’19. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019. [Google Scholar] [CrossRef]
- Bajenaru, V.; Vaccaro, J.; Colby, M.; Benyo, B. Comprehensive top-K recommender system for command and control, using novel evaluation and optimization algorithms. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications IV, Online, 2–4 April 2022; Volume 12113. [Google Scholar] [CrossRef]
- Gadepally, V.N.; Hancock, B.J.; Greenfield, K.B.; Campbell, J.P.; Campbell, W.M.; Reuther, A.I. Recommender systems for the Department of Defense and intelligence community. Linc. Lab. J. 2016, 22, 74–89. [Google Scholar]
- Fernandez, M.; Bellogín, A. Recommender Systems and misinformation: The problem or the solution? OHARS’20. In Proceedings of the Workshop on Online Misinformation- and Harm-Aware Recommender System, Virtual, 25 September 2020. [Google Scholar]
- Bedi, P.; Sinha, A.K.; Agarwal, S.; Awasthi, A.; Gaurav, P.; Saini, D. Influence of Terrain on Modern Tactical Combat: Trust-based Recommender System. Def. Sci. J. 2010, 60, 405–411. [Google Scholar] [CrossRef] [Green Version]
- Debie, E.; El-Fiqi, H.; Fidock, J.; Barlow, M.; Kasmarik, K.; Anavatti, S.; Garratt, M.; Abbass, H. Autonomous recommender system for reconnaissance tasks using a swarm of UAVs and asynchronous shepherding. Hum.-Intell. Syst. Integr. 2021, 3, 175–186. [Google Scholar] [CrossRef]
- Cerri, T.; Laster, N.; Hernandez, A.; Hall, S.B.; Stothart, C.R.; Donahue, J.K.; French, K.; Soyka Tradoc, G.M.; Johnson, A.; Sleevi Tradoc, G.N.F. Approved for public release; Distribution unlimited using AI to assist commanders with complex decision-making. In Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC), Paper No. 18072, Orlando, FL, USA, 15 November 2018. [Google Scholar]
- Pilarski, M.G. The concept of recommender system supporting command and control system in hierarchical organization. In Proceedings of the 2014 European Network Intelligence Conference, Wroclaw, Poland, 29–30 September 2014; pp. 138–141. [Google Scholar]
- Schaffer, J.; O’Donovan, J.; Höllerer, T. Easy to please: Separating user experience from choice satisfaction. In Proceedings of the 26th Conference on User Modeling, Adaptation and Personalization, Singapore, 8–11 July 2018. [Google Scholar]
- Marius, V.; Alberts, D.S.; Agre, J.R. C2 Re-Envisioned: The Future of the Enterprise; CRC Press: New York, NY, USA, 2015; p. 1. ISBN 9781466595804. [Google Scholar]
- Benyo, B.; Atighetchi, M.; Broderick-Sander, R.; Jeter, S.; Hiebel, J.; Bajenaru, V. Building Adaptive Cross-Domain Kill-Webs. In Proceedings of the IEEE MILCOM 2022 Restricted Access Technical Program, Systems Perspectives Session, National Capital Region, Online, 30 November 2022. [Google Scholar]
- Lingel, S.; Hagen, J.; Hastings, E.; Lee, M.; Sargent, M.; Walsh, M.; Zhang, L.A.; Blancett, D.; Zhang, L.A.; Blancett, D. Joint All Domain Command and Control for Modern Warfare: An Analytic Framework for Identifying and Developing Artificial Intelligence Applications; RAND: Santa Monica, CA, USA, 2022. [Google Scholar]
- Erol, K.; Hendler, J.A.; Nau, D.S. Semantics for Hierarchical Task-Network Planning; DTIC Document: Fort Belvoir, VA, USA, 1995. [Google Scholar]
- Gunawardana, A.; Shani, G. A Survey of Accuracy Evaluation Metrics of Recommendation Tasks. J. Mach. Learn. Res. 2009, 10, 2935–2962. [Google Scholar]
- Paraschakis, D.; Nilsson, B.J.; Hollander, J. Comparative Evaluation of Top-N Recommenders in e-Commerce: An Industrial Perspective. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015. [Google Scholar]
- Koren, Y.; Bell, R. Advances in Collaborative Filtering. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Cauteruccio, F.; Terracina, G.; Ursino, D. Generalizing identity-based string comparison metrics: Framework and techniques. Knowl.-Based Syst. 2020, 187, 104820. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, WWW ’17, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Knuth, D. The Art of Computer Programming, Volume 3: Sorting and Searching, 3rd ed.; Addison–Wesley: Boston, MA, USA, 1997; ISBN 0-201-89685-0. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Bellman, R.E. Dynamic Programming, Dover Paperback ed.; Princeton University Press: Princeton, NJ, USA, 2003; ISBN 978-0-486-42809-3. [Google Scholar]
- Feinberg, E.A.; Shwartz, A. (Eds.) Handbook of Markov Decision Processes; Kluwer: Boston, MA, USA, 2002; ISBN 9781461508052. [Google Scholar]
- Guo, X.; Hernández-Lerma, O. Continuous-Time Markov Decision Processes. In Stochastic Modelling and Applied Probability; Springer: Berlin/Heidelberg, Germany, 2009; ISBN 9783642025464. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System Input Category | System Input Subcategory | System Input Data |
|---|---|---|
| Each computed CoA’s details | Each CoA’s requestor’s original intent | Requesting user type (commander, analyst, etc.) |
| Request priority (1–5, 1 being highest) | ||
| Request class (rescue, control, defensive, offensive, etc.) | ||
| Request subclass (find, fix, track, target, engage, assess, etc.) | ||
| Request detail (estimated region of effect, time constraints, etc.) | ||
| User’s preference model for the specific request (weights of each key success metric) | ||
| Related requests, their details, and pointers to computed CoA’s (other requests desired to be performed in series/parallel/etc.) | ||
| Each CoA’s details | Each subtask within CoA (perform imaging, classification, then data transfer, etc.) | |
| Each subtask’s domain (space, air, ground, maritime, cyber, etc.) | ||
| Each asset/personnel ID per subtask | ||
| Each asset/personnel type per ID (LEO Satellite, OSINT analyst, SIGINT analyst, etc.) | ||
| Each CoA’s calculated key success metrics (timeliness = 85%, risk = 20%, etc.) | ||
| Human feedback | Implicit data when CoA’s presented | Chosen CoA’s and associated CoA properties are rated well (e.g., ratings of 5 stars out of 5 are aggregated into data pool) |
| Ignored CoA’s are rated poorly (e.g., ratings of 2 stars out of 5 are aggregated into data pool) | ||
| Explicit data when CoA’s presented | During simulations/live execution/historical execution, commanders/analysts can rate all CoA’s based on their experience (e.g., rating of 1–5 stars) | |
| Automated system feedback | Representative scenario simulation results | As C2 system runs Monte Carlo simulations, determines overall scenario successes/failures, and rates accordingly (e.g., rating of 1–5 stars) |
| Real-world scenario results | As C2 system runs live, determines overall scenario successes/failures, and rates accordingly (e.g., rating of 1–5 stars) |
| CoA Qualitative Attributes | CoA Quantitative Attributes | RS Metrics | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CandidateCoA ID # | Domain | Task Type | Asset/Person Type | Effector Type | Timeliness (CommanderPref = 0.21) | Risk (CommanderPref = 0.04) | Goal Achievement (CommanderPref = 0.38) | Opportunity Cost (CommanderPref = 0.37) | Preference | Feedback | Optimality | Diversity |
| 23 | Air | Find: EO Scan | HALE Drone | EO-High-Res | 0.88 | 0.76 | 0.89 | 0.48 | 0.59 | 0.52 | 6.30 × 10−1 | 0.92 |
| 4 | Space | Find: IR Scan | LEO EO/IR | IR-Low-Res | 0.56 | 0.74 | 0.82 | 0.74 | 0.55 | 0.56 | 2.55 × 10−1 | 0.92 |
| 78 | Maritime | Find: RF Scan | SAR Ship | RF-Short-Range | 0.05 | 0.63 | 0.57 | 0.74 | 0.40 | 0.60 | 3.67 × 10−11 | 0.92 |
| 46 | Cyber | Find: Net. Sig. | Net. Analyst | Net-Analysis | 0.16 | 0.17 | 0.30 | 0.42 | 0.75 | 0.58 | 4.50 × 10−53 | 0.86 |
| 54 | Space | Find: EO Scan | MEO EO/IR | EO-Low-Res | 0.59 | 0.56 | 0.06 | 0.93 | 0.43 | 0.51 | 1.06 × 10−1 | 0.43 |
| 11 | Maritime | Find: EO Scan | SAR Ship | EO-High-Res | 0.09 | 0.56 | 0.88 | 0.52 | 0.49 | 0.57 | 1.69 × 10−3 | 0.64 |
| 3 | Air | Find: IR Scan | MALE Drone | IR-High-Res | 0.18 | 0.84 | 0.33 | 0.14 | 0.69 | 0.68 | 6.78 × 10−3 | 0.64 |
| 92 | Air | Find: RF Scan | HALE Drone | RF-Med-Range | 0.42 | 0.25 | 0.57 | 0.77 | 0.48 | 0.42 | 6.29 × 10−11 | 0.64 |
| 74 | Maritime | Find: RF Scan | SAR Ship | RF-Short-Range | 0.65 | 0.33 | 0.71 | 0.10 | 0.27 | 0.36 | 7.86 × 10−11 | 0.64 |
| 36 | Space | Find: RF Scan | MEO RF Sat | RF-Long-Range | 0.35 | 0.08 | 0.34 | 0.57 | 0.27 | 0.48 | 8.10 × 10−36 | 0.30 |
| Inversion Scores: | 0.69 | 0.64 | 0.71 | 0.91 | ||||||||
| Optimality/Diversity HPs | NCF Feedback HPs |
|---|---|
| optimalityParetoFavoringExpWeight = 2.38 diversityQuantitativeWeight = 0.06 diversityQualitativeExpWeight = 0.04 diversityQualitativeWeight = 0.21 optimalityVsDiversityWeight = 0.82 | model type = NeuMF dim. of latent space = 5 MLP layer sizes = 4, 8, 16 number of epochs = 150 batch size = 1024 learning rate = 1 × 10−4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bajenaru, V.; Lavoie, S.; Benyo, B.; Riker, C.; Colby, M.; Vaccaro, J. Recommender System Metaheuristic for Optimizing Decision-Making Computation. Electronics 2023, 12, 2661. https://doi.org/10.3390/electronics12122661
Bajenaru V, Lavoie S, Benyo B, Riker C, Colby M, Vaccaro J. Recommender System Metaheuristic for Optimizing Decision-Making Computation. Electronics. 2023; 12(12):2661. https://doi.org/10.3390/electronics12122661
Chicago/Turabian StyleBajenaru, Victor, Steven Lavoie, Brett Benyo, Christopher Riker, Mitchell Colby, and James Vaccaro. 2023. "Recommender System Metaheuristic for Optimizing Decision-Making Computation" Electronics 12, no. 12: 2661. https://doi.org/10.3390/electronics12122661
APA StyleBajenaru, V., Lavoie, S., Benyo, B., Riker, C., Colby, M., & Vaccaro, J. (2023). Recommender System Metaheuristic for Optimizing Decision-Making Computation. Electronics, 12(12), 2661. https://doi.org/10.3390/electronics12122661