1. Introduction
The arrival of the era of big data has been accompanied by an exponential growth of network traffic, and malicious traffic generated by malicious programs is also endless. Network traffic classification can associate traffic with its generation program. In the field of network security, traffic classification is the first step in the task of network malicious resource detection [
1]. Therefore, the accurate classification of network traffic has always been a hot topic in the field. In recent years, deep learning has achieved great success in the field of traffic classification [
2,
3,
4].
However, deep learning relies on the supervised training of large labeled datasets. Due to the high concealment of malicious traffic and changing attack behavior, the amount of malicious traffic data that can be captured and accurately marked is small, and it is difficult to provide the amount of data that can drive deep learning training. In addition, the current malicious traffic classification model only focuses on the model effect in the offline case and pays less attention to the model performance on the online device. When the deep learning model is deployed on the online device, the constantly updated and changing malicious traffic class requires the classification model to have the ability to add classification tasks. In the classification model based on deep learning, the classifier is often supervised by a set of data. If we want to add classification tasks to the classifier, we must use a large amount of old class data and new class data to jointly retrain the classifier. If the old class data cannot be re-enabled, using only the new class data will cause the catastrophic forgetting of the classifier, meaning that the classification performance of the classifier for the old class is greatly reduced.
When the network completes training and is deployed in a practical application scenario, it usually cannot carry the training data of the network, which results in the additional consumption of storage resources and is not conducive to data privacy protection. Although, in order to facilitate the test, the small number of old class sample categories used in this paper makes the computing resources occupied by the old class small-sample data seem small. However, in reality, there are many kinds of Trojan horses. The storage resources for the old class small samples and the computing resources required for the retraining of the old class still overwhelm the online equipment. At the same time, malicious traffic is constantly iteratively changing, which is necessary for the update of the classifier. Therefore, an incremental learning method is needed to solve the update of the classifier without combining the old data. In addition, as an important defense line for network security, malicious traffic classification is often deployed on edge computing devices, such as robots, smart devices, and other products. These products are not rich in storage and computing resources due to their light and flexible characteristics. Therefore, the question of how to solve the scalability problem with respect to a small-sample malicious traffic classification model in the case of scarce computing resources is worth exploring in the field of malicious traffic classification.
The ability to allow the model to extend new classification tasks and learn from new class data without forgetting the old class is referred to as incremental learning ability. In recent years, researchers have proposed many incremental learning methods. This includes the method of playback based on old data [
5,
6,
7], which alleviates the problem of catastrophic forgetting by jointly guiding the classifier with old data and new data. However, this method requires storing old data, and the old data should be representative and equal to the number of new data as, if not, it will affect the classification performance of the classifier for the old class. Therefore, the playback method requires more storage resources and is prone to category imbalance, which makes the classifier overfit the old or new classes and leads to low overall classification performance. Regularization-based methods [
8,
9] use knowledge distillation as a regularization term to constrain the model, penalizing the model’s forgetting of old classes when fitting new data. This process requires storing the weight of the old model to obtain the source of knowledge distillation. However, there is an antagonistic relationship between knowledge distillation and incremental learning. If the model constraint is too strong, the model will seriously fit the current data, resulting in poor robustness. If the model constraint is weak, it cannot effectively alleviate the problem of catastrophic forgetting. Therefore, the current research on regularization methods should also make efforts to design better distillation methods. The method based on model expansion [
10,
11] aims to adapt to new data by adding a new model structure and keeping the weight of the old model unchanged for the old class so as to avoid forgetting. However, the increase in model structure will inevitably lead to the aggravation of computing resources and computational burden. When the number of new tasks increases gradually, the model will become overwhelmed.
In summary, the incremental learning problem of small-sample malicious traffic classification currently faces the following three major challenges, and no method in the existing literature can fully solve these challenges:
Q1: Learning new tasks brings the catastrophic forgetting of old tasks. Due to the limited computing and storage resources of online devices, when a new task arrives, there is often a performance tradeoff between the old and new classes. The adaptation of new tasks will inevitably lead to a decrease in the accuracy of old tasks. Improving the overall performance of the model is the primary challenge that incremental learning must solve.
Q2: Small-sample data prove difficult in driving neural network training. Due to the hidden and changeable characteristics of malicious traffic, in the real-world, it is often faced with the contradiction between the amount of data that can be captured and the large parameters of neural networks. Therefore, the performance of the small-sample classification model is the focus of this paper.
Q3: The current incremental learning method has a large demand for computing resources. Mainstream incremental learning methods—playback-based methods, regularization-based methods, and model expansion-based methods—all require computing resources to varying degrees. Therefore, maintaining the performance of the classifier while minimizing the demand for computing resources is one of the challenges that needs to be solved.
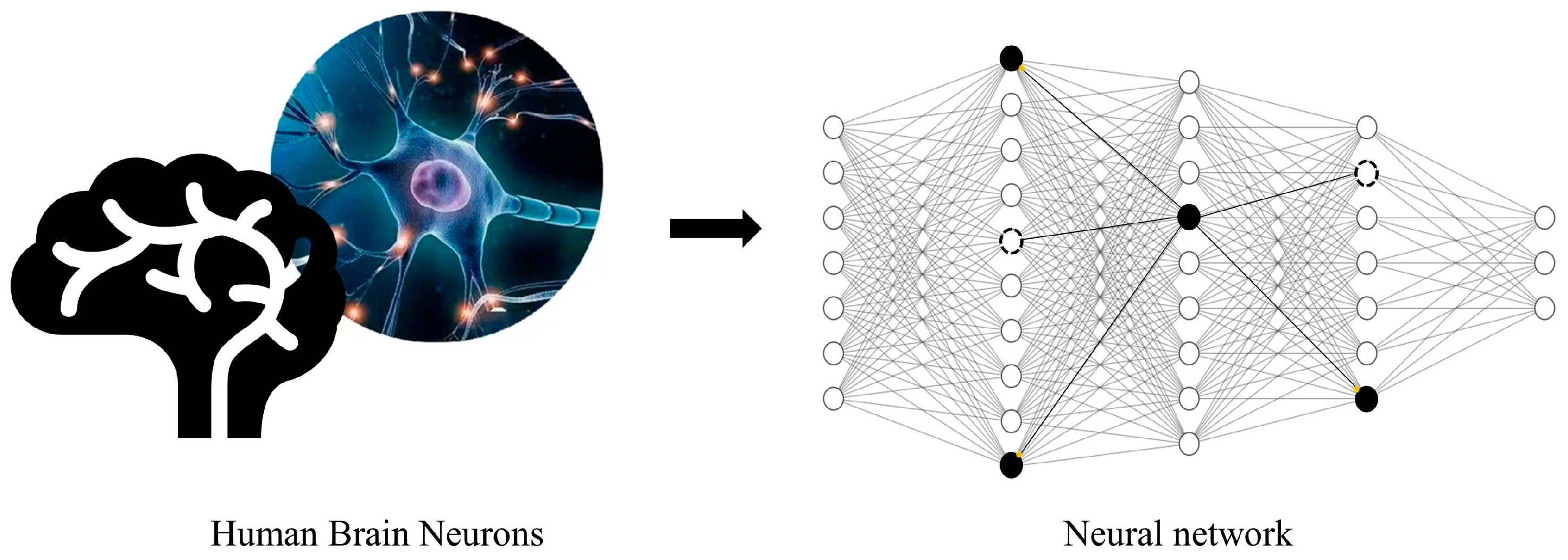
Compared with neural networks, humans are often able to remember old tasks in the face of new tasks in the process of learning. Researchers have found [
12] that this is because the adult brain contains a large number of ‘silent synapses,’ and the connections between these neurons remain inactive before forming new memories; therefore, the old memories will not be forgotten when forming new memories. Inspired by the ‘silent synapse’ in the human brain, as shown in
Figure 1, in this paper, we propose a dynamic retraining method (DRnet). The method pruned the trained neural network so that it can form ‘silent neurons’ for new tasks while reducing the redundant structure of the network. When a new task arrives, we dynamically allocate ‘silent neurons’ according to the similarity between the old and new tasks, retrain these neurons, and update the classifier so that the network can adapt to the new task. At the same time, the neural network also has some inactive ‘silent neurons’ waiting for the next new task. For small-sample incremental tasks, we use the idea of transfer learning to freeze the number of network layers of common features when extracting new and old task features, reducing the parameters that the network needs to adjust to adapt to the small-sample data volume.
Our contributions can be summarized as follows:
We design an incremental learning method for malicious traffic small-sample classification, which alleviates the catastrophic forgetting of old tasks when training new tasks and improves classification accuracy for small-sample incremental tasks.
An improved transfer learning method is applied to the process of class increment, which alleviates the contradiction between the new tasks of small samples and the large number of parameters to be adjusted in the model.
The proposed incremental learning method applies a dynamic retraining redundant neuron strategy, which can effectively use redundant neurons to learn new classes while making the model structure more lightweight, saving computing resources.
The remainder of this paper is structured as follows:
Section 2 reviews related works in the literature.
Section 3 introduces the DRnet method.
Section 4 introduces the experimental dataset and data preprocessing method and presents an analysis of the experimental results.
Section 5 discusses the effectiveness of the study, its limitations, and future work to be addressed regarding the method. Finally, in
Section 6, the work of this paper is summarized, and conclusions are drawn.
2. Related Works
Research on incremental learning in the traffic domain: Prasath et al. [
13] extended the incremental learning method in the image field to general network security and specific intrusion detection systems for the catastrophic forgetting problem in intrusion detection. This work compares the performance of various methods in simulating real-world distributed alternating batch attacks and concludes that the playback-based method is superior to traditional statistical techniques and the most advanced Boosting model and DNN model in dealing with catastrophic forgetting. Based on the idea of transfer learning, Doshi et al. [
8] designed a feature extraction module and a decision module to solve the task of incremental continuous learning. The feature extraction module is used to minimize the complexity of the training and extract motion, position, and appearance features. The decision module is a sequential anomaly detector, which quickly updates the learned model using incremental labels. Through experiments on public datasets, the detector trained by this method is significantly better than the most advanced algorithms. Amalapuram et al. [
9] evaluated the challenges and practicality of incremental learning in the design of intrusion detection systems. This work found that class incremental methods have a greater impact on task order sensitivity. At the same time, by applying the current popular incremental learning algorithms—Elastic Weight Combination (EWC) [
14] and Gradient Embedding Memory (GEM) [
15]—it was found that the performance could be further improved by combining the memory population technology based on the perception of empirical forgetting. Pezze et al. [
16] proposed an incremental learning method based on compressed playback. The method uses a super-resolution model to compress and playback the original image and combines the anomaly detection module to enable the model to perform anomaly detection tasks in an environment that constantly learns new tasks. This method represents the first time that the compression module has been applied to incremental learning tasks. A large number of experiments have proved that the method can use fewer computing resources to complete incremental tasks.
Research on small-sample incremental learning: At present, there are few studies on small-sample incremental learning in the field of traffic, so we have some related working methods proposed in other fields to use them as references. Aiming at the demand for fine-grained multi-tasks of classifiers in the field of image classification, Mallya et al. [
17] proposed a method that adds multiple tasks to a single deep neural network while avoiding catastrophic forgetting. This work uses redundancy in large deep networks to release parameters and is then used to learn new tasks. By performing iterative pruning and network retraining, this work can sequentially ‘package’ multiple tasks into a single network while ensuring minimum performance degradation and minimum storage overhead. However, in the process of pruning and retraining, the complexity of the new task is not considered, which greatly affects the classification performance of the model by the order of the arrival of the new task, and there is no effective solution to the small-sample problem. The work of this paper is based on the work of Mallya et al. In the field of object detection, Kang et al. [
18] developed a small-sample object detector. This work uses a meta-feature learner, a reweighted module in the first-level detection architecture, and a fully labeled base class and quickly adapts to new classes. Through a large number of experiments, this work proves that the model’s few-shot object detection task and class increment task on multiple datasets are much better than the established baseline. Douillard et al. [
19] introduced a new distillation loss that constrains the entire convolutional network using the idea of knowledge distillation to solve small-sample incremental learning. This loss balances the forgetting of old classes and the learning of new classes, which is conducive to long-term incremental learning. At the same time, the method proposes a multi-mode similar classifier, which makes the model more robust to the inherent distribution displacement of incremental learning. This method has achieved good experimental results on multiple datasets. Tao et al. [
20] used neural gas (NG) networks to represent knowledge for small-sample incremental learning problems and proposed a neural science-inspired topology protection framework for effective class incremental learning. At the same time, a topology preserving loss (TPL) was designed to maintain the topology of the feature space and reduce forgetting. Through testing on multiple datasets, it was proven that the method could continuously learn new classes and reduce forgetting.
3. Methods
Problem definition: Incremental learning is divided into multi-task incremental learning [
21,
22] and single-task incremental learning [
23,
24]. The difference between the two types is that the classifiers assigned to each type of task are different. For multi-task learning, the same model needs to gradually learn many isolated tasks without forgetting how to solve the previous tasks. This means that multi-task learning assigns each type of task to different classifiers. There is no class overlap between different tasks, and the accuracy of each task is calculated separately. Therefore, multi-task learning is very suitable for studying the feasibility of training a single model on a series of disjointed tasks without forgetting how to solve the previous tasks, but it is not suitable for solving class increment problems. For single-task incremental learning, a unified classifier is used and the entire incremental learning process is considered as an overall task, i.e., we add new classes in order, but the classification problem is unique. In the calculation accuracy, we need to distinguish all the classes encountered so far. This article aims to study the incremental problem regarding malicious traffic classification tasks under small-sample conditions. For newly added malicious traffic categories, it is hoped that the classifier can accurately classify them while not forgetting the old ones. The goal of this study is to help solve the single-task incremental learning problem, so this article focuses on single-task learning.
We define the small-sample single-task incremental learning problem as follows: Suppose we have a labeled small-sample target dataset
, the new small-sample task data are represented by
,
is the class set of training set,
is the class set of
test set.
,
. The model is first trained and tested on
. After the model can fit the target classification task,
arrives as a new task, the test set of the model is
, and the classifiers need to identify
class tasks. At this time, the
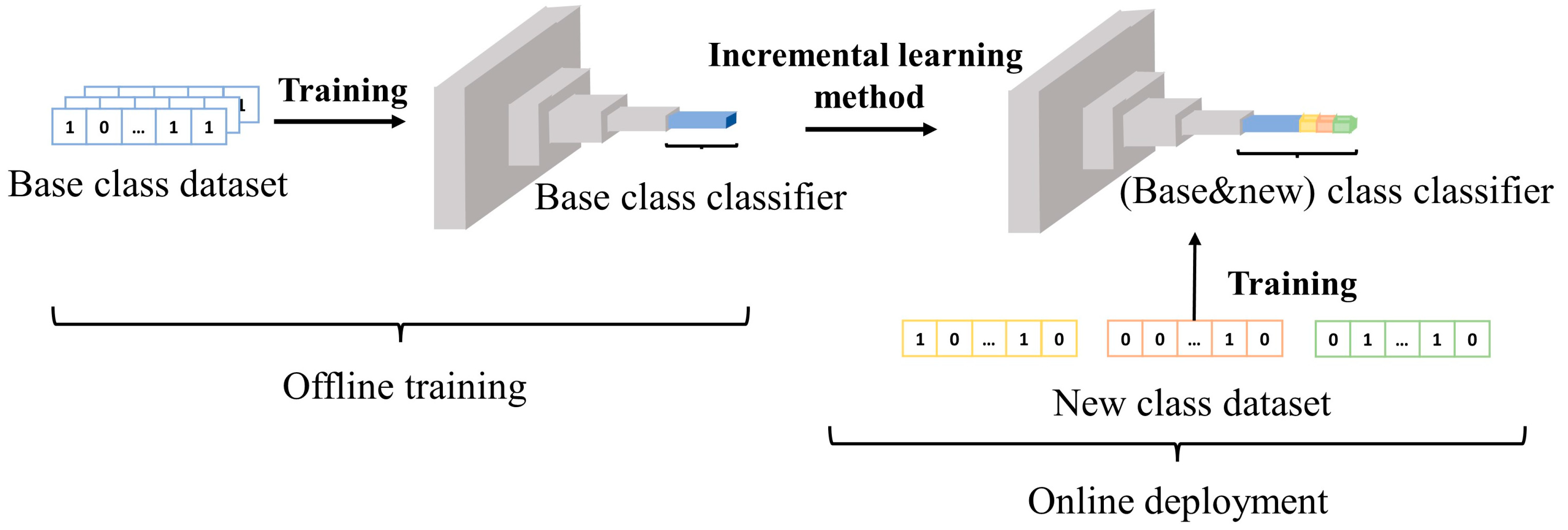
dataset is not allowed for joint training. The process of single-task small-sample incremental learning is shown in
Figure 2. In the offline training phase, the base class classifier is trained using the base class data
. When deployed online, only the new class data
can be called for network training. At this time, a certain incremental learning method is used to train the classifier to identify all categories
of the base class and the new class. Complete the malicious traffic classifier incremental task. The challenges that the task needs to solve are as follows: avoiding the catastrophic forgetting of old tasks caused by new tasks, solving the problem of small-sample task classification performance, and reducing the computing resources required to complete the task.
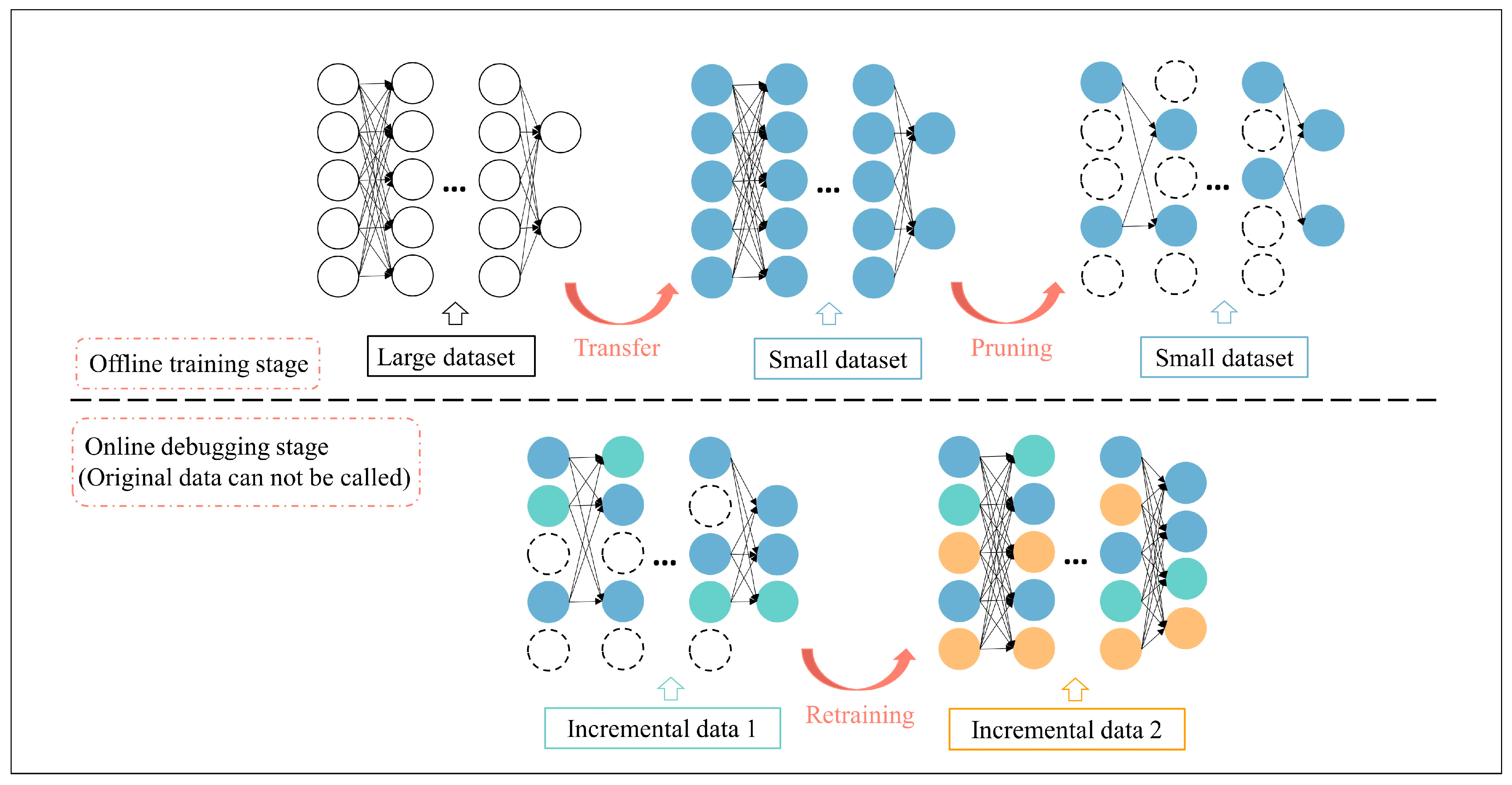
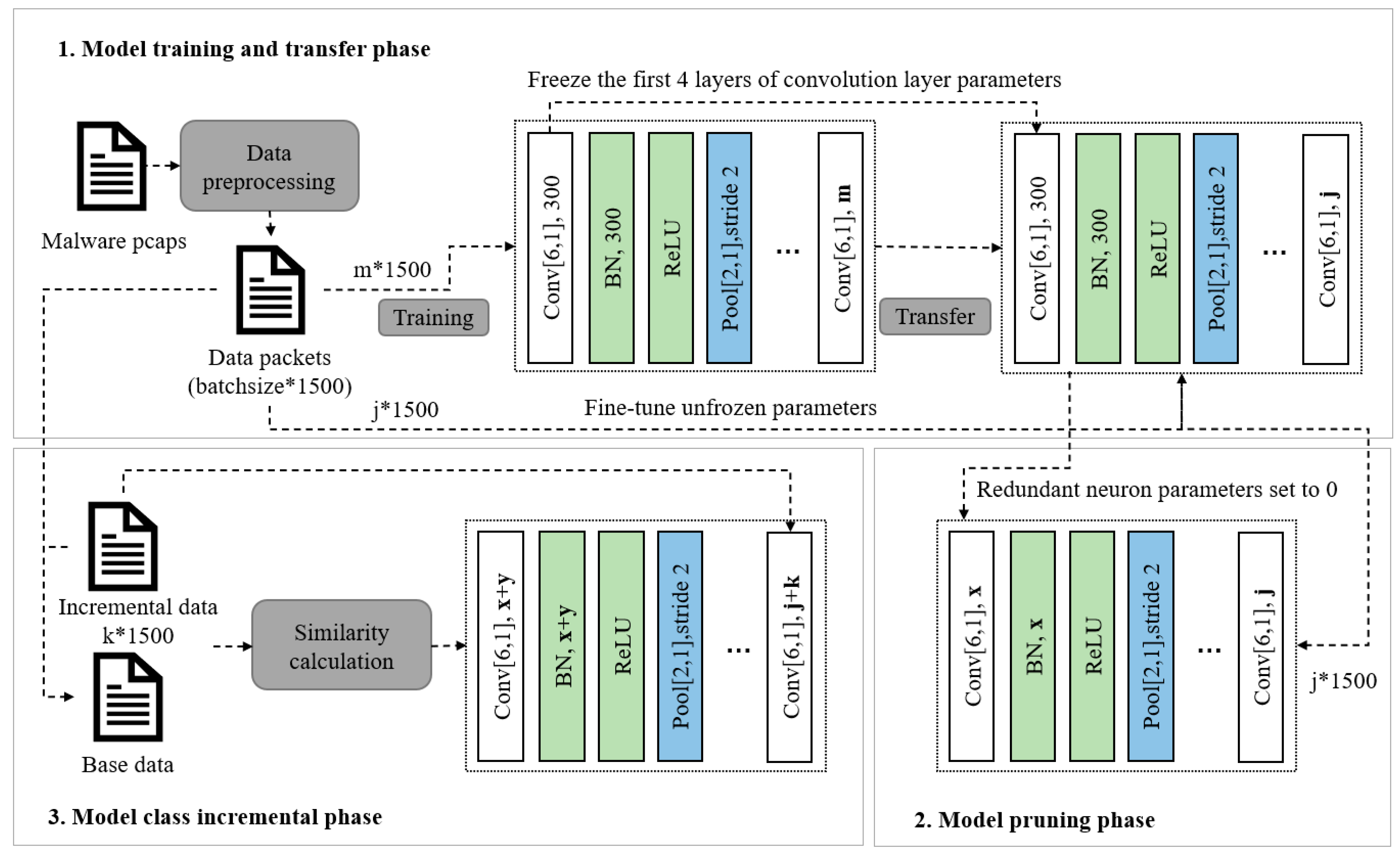
In order to solve the above challenges, we propose a small-sample malicious traffic classification incremental learning method, the process for which is shown in
Figure 3. We designed a fully convolutional network as the source network. In order to maintain the good feature extraction ability of the source network, we used a large dataset to train it and transfer the knowledge learned to the target dataset and new tasks through transfer learning to reduce the number of parameters that needed to be fine-tuned for small-sample data. At this time, the network has a large number of redundant neurons for small-sample classification tasks, so we pruned the network and used the pruned neurons as the reserve network structure of the new task. When performing new tasks, we dynamically allocated new tasks according to the category similarity between new tasks and old tasks and used pruned neurons for training new tasks. We introduce the detailed methods of each stage as follows:
The main flow chart of the method is shown in
Figure 4. After the original malicious traffic data packet was preprocessed, the model was trained in the form of data packets, and the format was batchsize × 1500. In the model training phase, the large dataset trains the original model, and the training dataset size was m × 1500. Then, the model was migrated, the parameters of the first four convolutional neural networks of the model were frozen, and the small-sample dataset of j × 1500 was used for fine-tuning. In the model pruning stage, the redundant neuron parameters in the model were set to 0. At this time, the number of convolutional layer neurons is the minimum remaining number x when the accuracy drop is less than 0.1, and the small-sample dataset is used to fine-tune the remaining parameters. In the final class increment stage, the similarity between the incremental data and the base class data was first calculated to determine the number of neurons y used to train the incremental data. After changing the model structure, the original model parameters were frozen, and the new dataset with a size of k × 1500 was used to train the assigned neurons y, achieving the goal of class increment.
Source model training phase: We designed an end-to-end fully convolutional malicious traffic classification network using a 1D Convolutional Neural Network (1DCNN) as the initial network. The network consists of ten one-dimensional convolutional layers and seven maximum pooling layers. The purpose of using the fully convolutional network is because the fully convolutional network abandons the traditional fully connected layer and replaces it with a convolutional layer, which saves a lot of network parameters. Secondly, the fully connected layer structure is difficult to change, and this is not conducive to our maximum pruning operation later. The weight sharing between the convolutional layers and the sparse connection provides convenience for subsequent pruning and class increment. After each convolutional layer, we added a Batch Normalization (BN) layer. In addition to the traditional prevention of overfitting and acceleration of model convergence, the BN layer is also used to evaluate the filter contribution of subsequent pruning. We set the number of neurons in the convolutional layer to 300, added the Rectified Linear Unit (RELU) function after the BN layer, and took a 0.05 dropout rate after each fully connected layer to prevent overfitting. The detailed hyperparameters of the network structure settings are shown in
Table 1. We used large datasets to train the initial network to train its good feature extraction ability (obtaining a good initial parameter set is crucial for subsequent transfer and pruning of the network). We set 30 epochs for the initial network. The learning rate was 0.01.
The selection of hyperparameters in network construction and training is based on the empirical conclusions of researchers and the actual situation of the problems solved in this paper. Firstly, the network convolution layer was set to 10 layers, and the maximum pooling layer was set to 7 layers. This is because the small sample size cannot support neural network training that is too complex. The number of neurons was set to 300, because the subsequent increment was based on the retraining of redundant neurons in the current network. Therefore, more neurons were set than the traditional classical traffic classification network. In addition, we referred to the empirical parameter settings of the current network, such as the initial learning rate (set to 0.01), the convolution kernel size (set to 6), and the Dropout rate (0.05).
Transfer phase: In order to solve the small sample problem of malicious traffic, we used an improved transfer learning method. In this study, two types of small-sample data were involved: small-sample target dataset and new task small-sample data, so we actually applied transfer learning in two parts. When training the classification network for the target dataset, because the small-sample dataset is not enough to train the large neural network, based on the trained initial network, we froze the first four-layer parameters of the network and fine-tuned the remaining parameters. Because the shallow network of the model often extracts low-level features, this operation did not affect the performance of the fine-tuned classifier. However, this can greatly reduce the number of parameters that need to be adjusted to improve the performance of the classification network. When faced with new tasks, we hoped that the model could train new tasks while maintaining the classification ability of old tasks. Therefore, we maintained the network weights of all old tasks during training and used its feature extraction ability for old tasks to participate in retraining with neurons assigned to new tasks. In this process, the old dataset does not participate in training but transfers its acquired knowledge. At the same time, the weight of the pruned redundant parameters is not set to 0, but the original parameters are maintained. This method ensures that the newly added small-sample data requires less adjustment when training the assigned redundant parameters so that the small-sample data can better fit the network parameters.
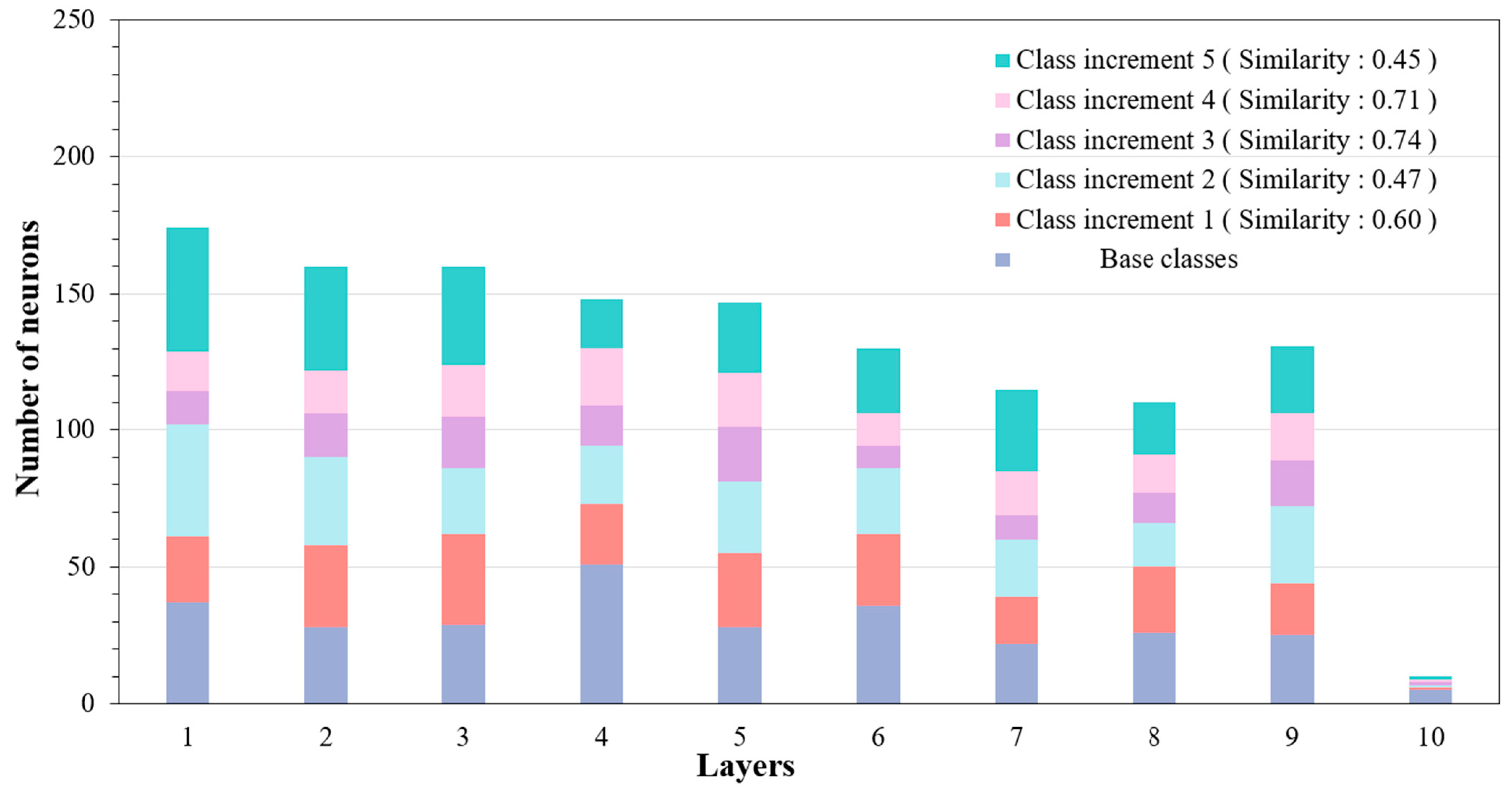
Pruning phase: In this study, the purpose of our pruning was not only to lighten the network in the traditional sense but also to screen out the redundant network structure that can be used by new task training. Therefore, we hoped to eliminate as many redundant neurons as possible without affecting the classification accuracy of the current task. Unlike Mallya et al. [
17], we only performed network pruning once, which greatly saved the pruning overhead. Our approach used the scaling factor of the BN layer as an indicator to rank neurons to determine their importance. We reduced the accuracy of the classifier by less than 1% as a criterion that does not affect the classification performance of the classifier. We represented this part of the neuron as R. According to experience, more than 80% of the neurons are identified as redundant neurons. We ranked these neurons according to weight and size so that they could be assigned to new tasks. At this time, we ensured that the R neurons did not participate in the back propagation and used a small-sample dataset to retrain the remaining neurons. This is due to a change in the network structure caused by the pruning operation, which needs to reestablish the connection between neurons. After the pruning phase is complete, the network will be deployed on the online network device, and the old data will not be called again.
Incremental phase: Mallya et al. selected 50% or 75% of the redundant parameters of the current task as the new task training for the class incremental task. Because the redundant parameters are constantly occupied, the first-arriving parameters can be assigned to more neurons for training. Therefore, this method is only effective when the difficulty of the new task is difficult. However, in the real world, the task will not appear in an orderly manner. We propose to dynamically match the number of parameters required for the task according to the difficulty of the task. In order to evaluate the difficulty of the new task, we introduced the Maximum mean discrepancy (MMD) distance [
25]. MMD is a nonparametric measure used to measure the distance between distributions based on kernel embedding in the reproducing kernel Hilbert space. Suppose
maps each instance to the kernel
related Hilbert space
,
and
are the sample size of small-sample datasets and new datasets. Then, the domain samples
and
of two distributions, whose MMD distance is defined as follows:
By introducing the MMD distance, we can obtain the position and distance of the two datasets in the Hilbert space. In our opinion, the closer the distance between the two domains is, the higher the similarity is. Therefore, we take the distance from the representative sample to the center position in
and the ratio of the distance from the two datasets as the similarity. In order to alleviate the influence of the deviation sample on the similarity, we select the median of the nearest and farthest distance from the center position in
as the distance of the representative sample. The similarity measure method we designed is defined as follows:
After obtaining the similarity of the network, we assigned the number of neurons required for the current new task according to the similarity, which is expressed as:
When the network adds new tasks, the neurons in the last convolutional layer will be re-adjusted to a new number of classifications. At the same time, the new tasks need to be trained for the assigned parameters. Therefore, we use the new sample data to retrain the network. For the neurons of the old task, we kept their weights unchanged. At this time, only a small number of neurons participate in training. We set the epoch to 10 and the learning rate to 0.01.
Then, whenever the network has new task requirements, the operation of dynamic allocation and retraining will be re-performed to adapt to the new task. At this point, the network will be able to dynamically allocate and adjust the network neurons without affecting the old task to complete the goal of classifying new tasks to adapt to the changing real world. Because the network does not increase the structure compared with the source network and the old data does not need to be stored, the consumption of computing resources is small.
5. Discussion
5.1. Method Effectiveness Analysis
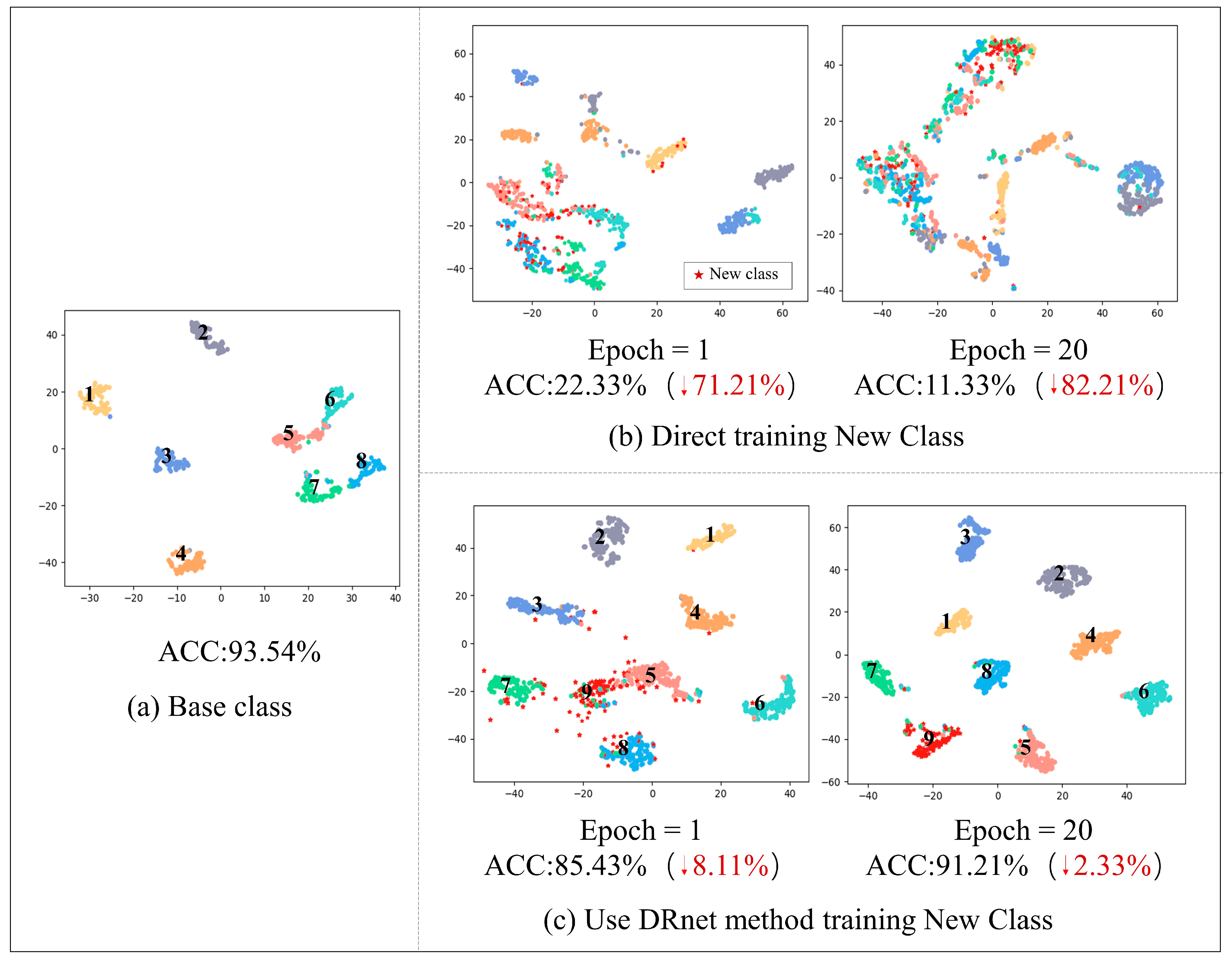
In order to address the need of solving the incremental tasks of small-sample classes when the model is deployed online, we studied the scalability of the malicious traffic small-sample classification model. Due to the conservation of computing resources and the protection of data privacy, we propose a class increment method without storing old classes. Firstly, based on the model transfer method, the small sample problem regarding malicious traffic is solved. Secondly, we pruned the redundant neurons of the model for small-sample tasks and imitated the ‘silent synapse’ structure of the human brain. The pruned neurons are used as a network structure that can be called at any time for the training of new categories. When training new classes, the weight of old classes is fixed. The method alleviates the catastrophic forgetting of old classes, solves the problem of data privacy, and does not increase computing resources.
In addition, when allocating redundant neurons, we abandoned the proportional allocation strategy in the traditional method and designed a measurement method to measure the similarity between classes. The dynamic allocation of redundant neurons according to task difficulty not only makes the allocation reasonable but also ensures that the classification performance of the new task model will not vary greatly with the order of task arrival or task difficulty.
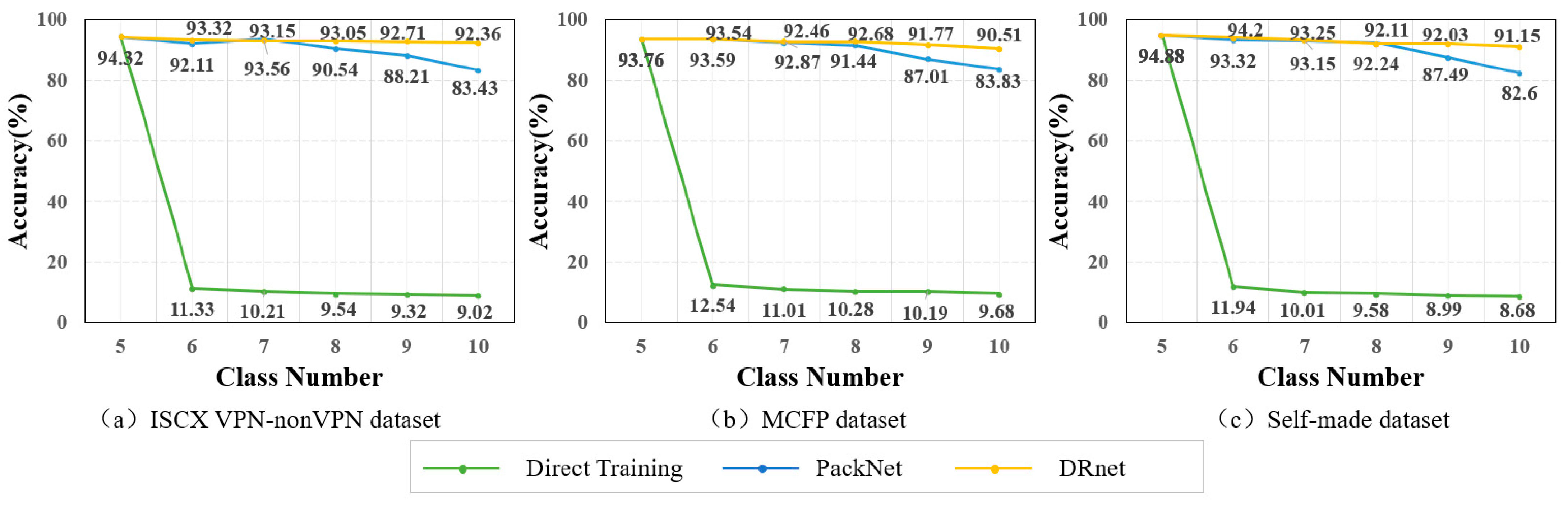
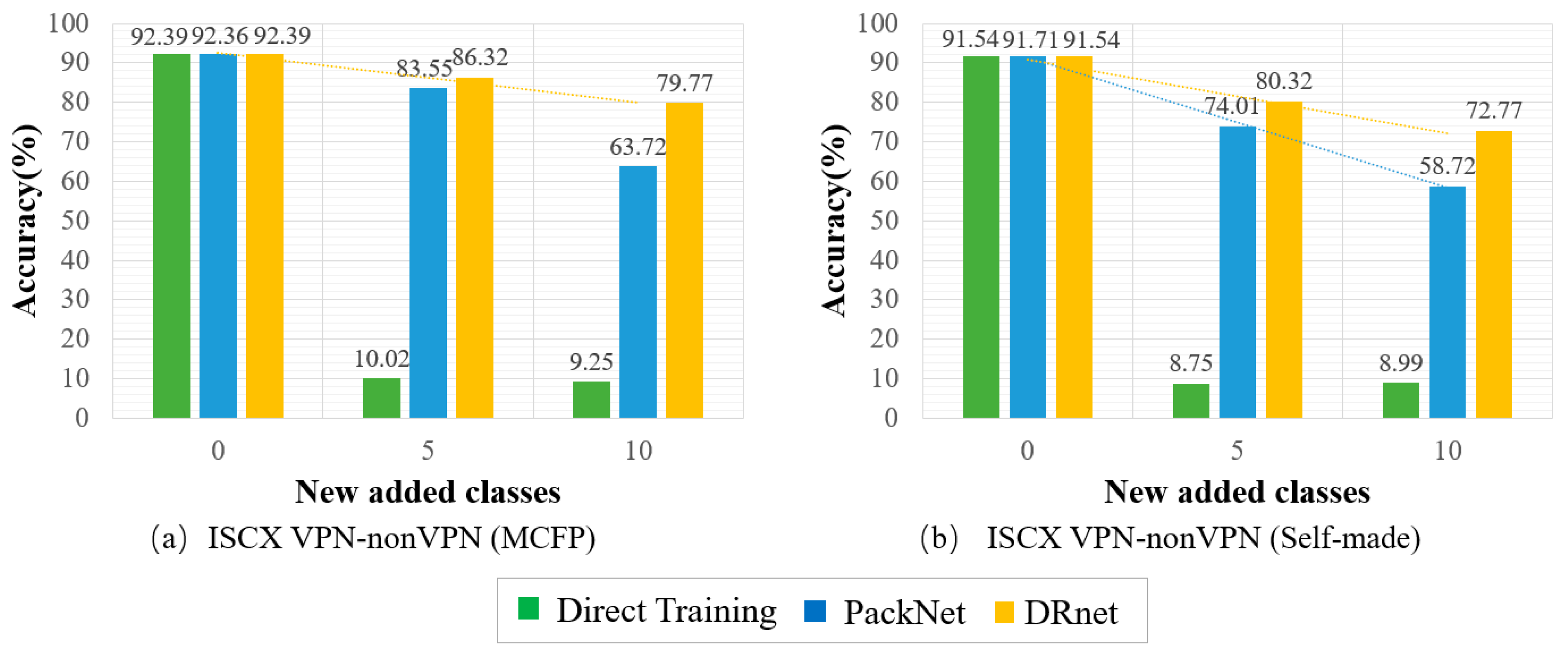
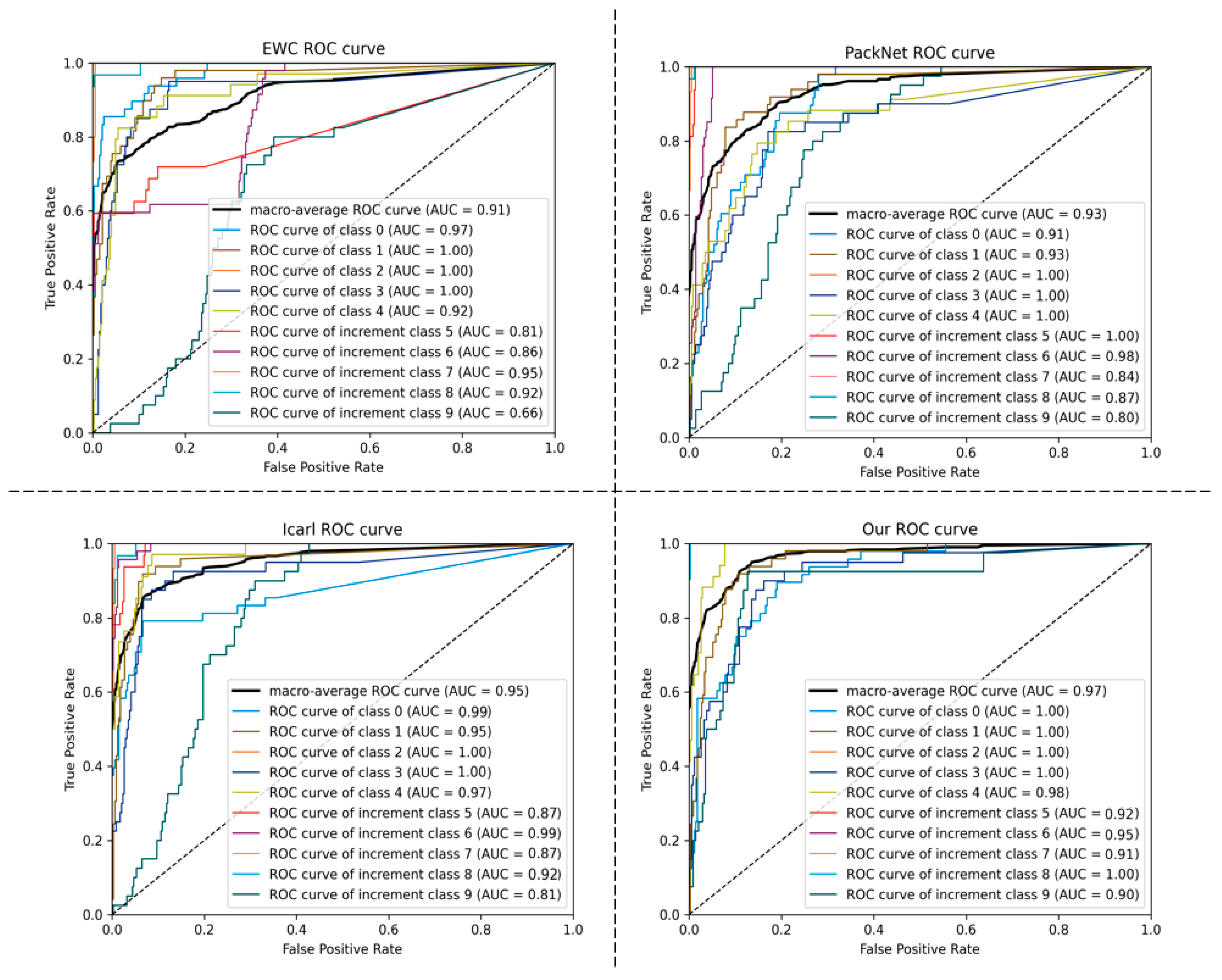
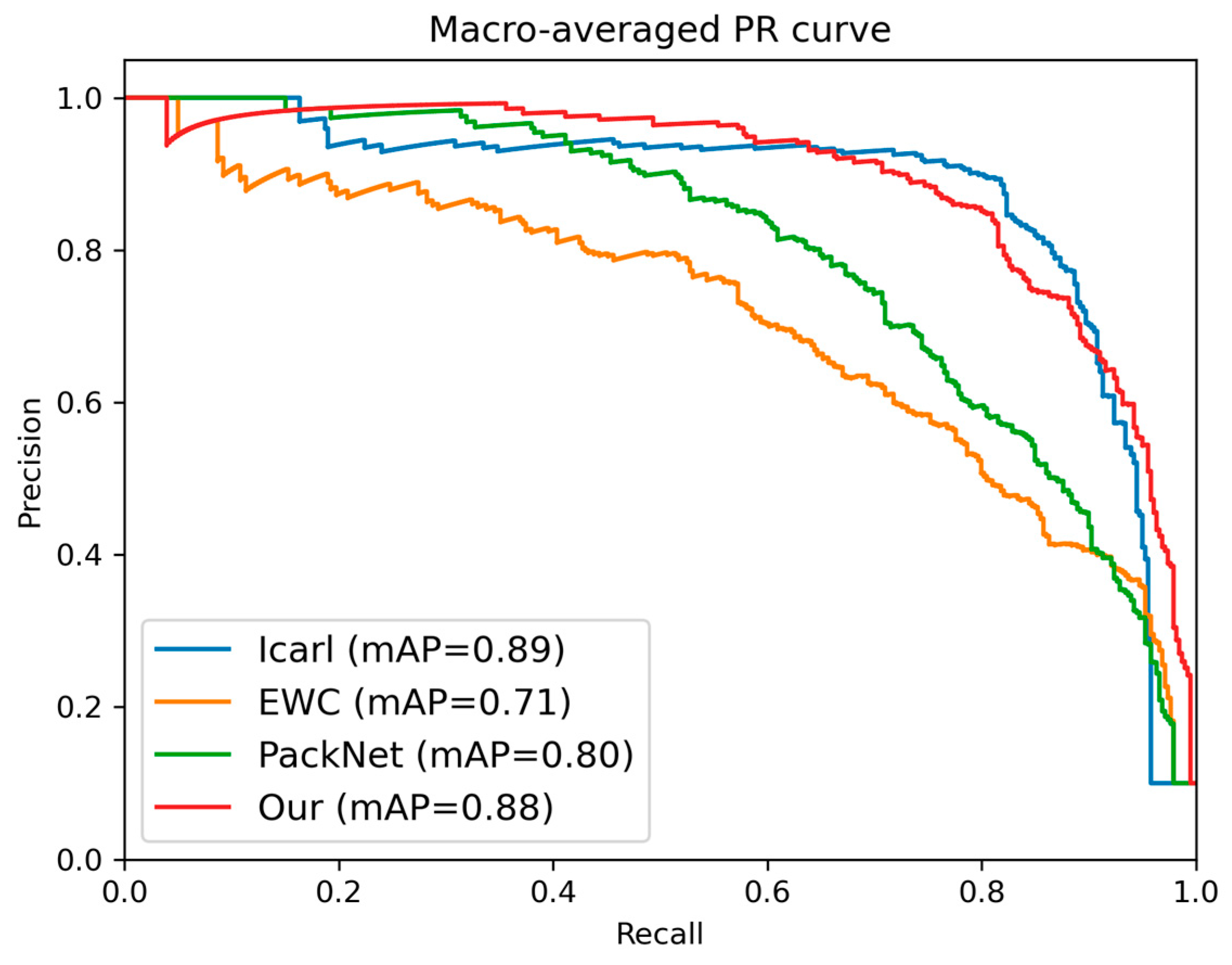
Experiments show that our method has better classification accuracy than the traditional class increment method, whether it is the same domain small-sample malicious traffic increment task with high similarity or the difficult inter-domain small-sample malicious traffic increment task. Additionally, our method also has certain advantages that become clear when comparing memory usage and calculation times.
5.2. Limitations and Future Work
This paper explores the scalability of the malicious traffic classification model. The proposed dynamic parameter allocation method based on interclass similarity shows good performance in both intra-domain small-sample class incremental tasks and inter-domain small-sample classification tasks. However, the method still has some limitations, which we plan to explore further in future work.
Firstly, the method trains new classes based on neurons with current task redundancy. The advantage of this method is that it can complete the class incremental task without affecting the classification performance of the old classes. However, the redundant parameters of the model are limited. The focus of this paper is to ensure the classification accuracy of new classes. Therefore, the standard for allocating redundant neurons is only the number of neurons required by the current task compared with the old class task; the limitation of the number of class increments is not considered. When new tasks continue to arrive, there arises a situation wherein the model cannot add new tasks due to the exhaustion of a redundant parameter. At the same time, as the difficulty of new tasks increases, the redundant parameters will be exhausted earlier. For this problem, future research could consider model expansion, which could help further meet the needs of class increment by expanding the model. However, this will inevitably lead to an increase in computing resources. Balancing the consumption of computing resources and the performance of new class classification is also worthy of further exploration among researchers.
Secondly, in the real world, many practical applications cannot adapt to experimental settings with nonoverlapping tasks. Furthermore, due to the continuous updating of malicious traffic and changes associated with it, the distribution of classes will gradually change, which is often called concept drift. When deployed online, defining whether the class with concept drift belongs to the new class has become a topic of increasing concern. The problem of concept drift in the field of malicious traffic needs to be further defined. At the same time, the model also needs some robustness to resist the changes in category over time.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}