

MKGCN: Multi-Modal Knowledge Graph Convolutional Network for Music Recommender Systems
 , , , and
, , , and
Abstract
:1. Introduction
- To the best of our knowledge, we are the first music recommender system based on multi-modal knowledge graphs. We put a strong emphasis on fully leveraging the multi-modal data of music items, particularly the audio-domain and sentiment features of music, to provide more accurate and personalized music recommendations for users.
- We propose a novel music recommender system called Multi-modal Knowledge Graph Convolutional Network (MKGCN). Inspired by CNN, we design three aggregators that can effectively integrate different types of data, and propagate entity embeddings through the user’s historical interaction items and diverse adjacency relations of entities on the KG, achieving a high-order integration of user preferences and music items.
- We conduct extensive experiments to validate the efficacy of MKGCN and have also made our implementation code and self-made music multi-modal knowledge graph publicly available to researchers for replication and further research. The code and dataset can be accessed at https://github.com/QuXiaolong0812/mkgcn (accessed on 20 April 2023).
2. Related Work
2.1. Convolutional Neural Networks
2.2. Multi-Modal Knowledge Graph
2.3. Recommendations with MMKGs
2.4. Negative Sampling Strategy
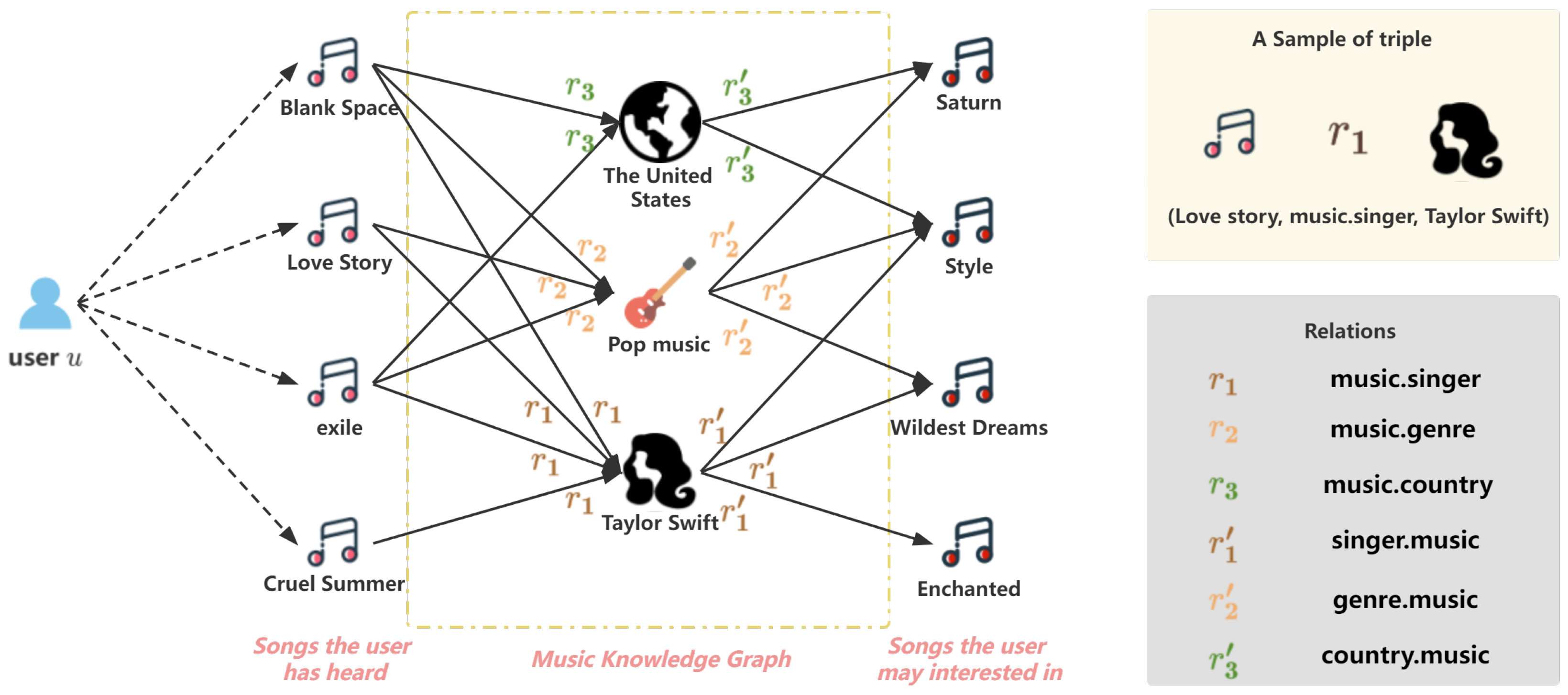
3. Problem Formulation
3.1. User–Item Interaction Matrix
3.2. Multi-Modal Knowledge Graph
3.3. Collaborative Knowledge Graph
3.4. Problem Description
4. Methodology
4.1. Alignment and Knowledge Propagation Layer
4.2. Multi-Modal Aggregation Layer
- Sum multi-modal aggregator sums all modal representation vectors and then performs the nonlinear transformation:where and are trainable transformation weights and biases, respectively, represents the multi-modal entity, and is an activation function, such as LeakyReLU. Please note that the same symbols in the other two aggregators represent the same meanings, so they are not repeated.
- Concat multi-modal aggregator connects the representation vectors of multi-modal data before applying the nonlinear transformation:
- Max multi-modal aggregator selects the modal vector with the largest amount of characterization information to replace the current entity embedding vector and then performs a nonlinear transformation:
4.3. GCN Aggregation Layer
4.3.1. User Aggregator
- Max user aggregator selects the largest item representation vector in the user historical interaction items and then performs a nonlinear transformation:where and are trainable transformation weights and biases, respectively, represent the k items that have been selected and multi-modal aggregated from the historical interaction items of user u, and is an activation function, such as LeakyReLU. Same symbols in the mean user aggregator represent the same meanings, so they are not repeated.
- Mean user aggregator sums all entity representations and averages them, and then performs a nonlinear transformation:
- Multi-head attention user aggregator uses a multi-headed self-attention mechanism to capture user preferences for different music items. Specifically, the aggregator first processes the embedding vectors of historical items using the self-attention mechanism to compute attention weights and weighted embedding vectors:where , , are the learnable parameter matrices, softmax is the activation function, k is the neighbor sampling size, and is the weighted embedding vector of the i-th historical item. Finally, the weighted embedding vector is pooled on average in dimension 0 to obtain the embedding vector of user:
4.3.2. Item Aggregator
- Sum item aggregator sums the two vectors and then performs the nonlinear transformation:where and are trainable transformation weights and biases, respectively, and is an activation function, such as LeakyReLU. Same symbols in the other two aggregators represent the same meanings, so they are not repeated.
- Concat item aggregator concats two vectors and then performs a nonlinear transformation:
- Neighbor item aggregator directly replaces the entity representation with a linear combination of the neighbors aggregation:
4.4. Prediction Layer
5. Experiments
5.1. Datasets
5.2. Baselines
- SVD [40] is a CF-based recommendation framework that models user interactions using inner products.
- CKE [12] is a recommendation framework that combines textual knowledge, visual knowledge, structural knowledge, and CF.
- RippleNet [32] is a representative of KG-based methods, which is a memory-network-like approach that propagates users’ preferences on the KG for recommendation.
- KGCN [22] is a recommendation framework that utilizes GCN aggregation of neighbors and modeling of relations on KGs to improve recommendations.
- MMGCN [29] constructs bipartite graphs for each modality, representing the relationship between users and items. These bipartite graphs are then trained using GCN. Subsequently, a decision message is generated for each modality and these messages are fused together to obtain the final decision message.
- MKGAT [28] incorporates visual and textual modal information for each entity on the knowledge graph and aggregates it to the entity representation. It then utilizes GCN to aggregate neighbors and improve the entity representation.
5.3. Experiment Setup
5.4. Performance Comparison with Baselines
- SVD and CKE achieve the lowest performance, which suggests that collaborative filtering-based algorithms are not able to effectively utilize side information, leading to lower recommendation accuracy. CKE outperform SVD because it incorporates visual and textual multi-modal data, demonstrating that the use of multi-modal data can enhance the performance of recommendation systems.
- RippleNet and KGCN are both knowledge-graph-based methods and their performance is better than that of collaborative-filtering-based methods, indicating that knowledge graphs can effectively utilize side information to improve recommendation accuracy. The performance of RippleNet is worse than that of KGCN because RippleNet is a memory-based network that does not model relations, whereas KGCN considers users’ preferences for different relations, demonstrating that modeling relation preferences can improve the performance of the recommender system.
- MKGCN, MKGAT, and MMGCN are all multi-modal knowledge-graph-based methods, and achieve superior performance over KG-based and CF-based methods, highlighting the importance of multi-modal knowledge graphs for enhancing recommender systems. Both MKGAT and MMGCN utilize textual and visual multi-modality, but MKGAT outperforms MMGCN, indicating that its feature fusion strategy, which employs decision-based fusion, captures more complementary information between modalities. However, MKGCN achieve the best performance and outperformed MKGAT, thanks to its richer multi-modal data and efficient negative sampling strategy.
5.5. Effect of Component Setting
5.5.1. Effect of Parameters Setting
5.5.2. Effect of Aggregators
- The concat strategy of the multi-modal aggregator outperforms the max representation strategy and the sum strategy, as it retains information from multiple modalities simultaneously by concatenating their features. In contrast, the max strategy only considers the maximum value in each modality’s feature, which may result in the loss of some important details. Similarly, the sum strategy may also lose some crucial details and, in addition, the sum value may be less accurate for modalities that contain outliers or noise.
- The mean strategy yields the best performance for user aggregators. The mean strategy calculates the average of the historical interaction item representation vector and can effectively represent the user’s interests. Conversely, the max strategy can only capture the most salient user preferences but not the full range of their preferences, since it uses the largest value of the item representation vector as the embedding representation of the user. The multi-head attention strategy is not suitable for users with sparse historical interaction data and hence performs the worst.
- The concat and neighbor strategies for the item aggregator achieve comparable results, but the neighbor strategy performs better overall. This can be attributed to the fact that the neighbor strategy directly employs a linear combination of the neighbor nodes, rather than the current entity, which facilitates better utilization of the information from neighbor nodes compared to the concat strategy. The sum strategy achieves the worst results, mainly due to information loss, as values of different dimensions may cancel each other out.
5.5.3. Effect of Negative Sampling Strategy
5.5.4. Effect of Multi-Modal Data
- (1)
- MKGCN-mm: MKGCN solely utilizes structural triples data and does not aggregate multi-modal data.
- (2)
- MKGCN-ae: MKGCN employs only text and image modality embeddings, and does not utilize audio and sentiment feature embeddings.
- (3)
- MKGCN-e: MKGCN incorporates embeddings from text, image, and audio modal features, but does not utilize sentiment feature embeddings.
- (4)
- MKGCN-a: MKGCN employs embeddings from text, image, and sentiment modal features, but does not utilize audio feature embeddings.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hagen, A.N. The playlist experience: Personal playlists in music streaming services. Pop. Music. Soc. 2015, 38, 625–645. [Google Scholar] [CrossRef] [Green Version]
- Kamehkhosh, I.; Bonnin, G.; Jannach, D. Effects of recommendations on the playlist creation behavior of users. User Model. User Adapt. Interact. 2020, 30, 285–322. [Google Scholar] [CrossRef] [Green Version]
- Burgoyne, J.A.; Fujinaga, I.; Downie, J.S. Music information retrieval. In A New Companion to Digital Humanities; Wiley: Hoboken, NJ, USA, 2015; pp. 213–228. [Google Scholar]
- Murthy, Y.V.S.; Koolagudi, S.G. Content-based music information retrieval (cb-mir) and its applications toward the music industry: A review. ACM Comput. Surv. CSUR 2018, 51, 1–46. [Google Scholar] [CrossRef]
- Schedl, M.; Zamani, H.; Chen, C.W.; Deldjoo, Y.; Elahi, M. Current challenges and visions in music recommender systems research. Int. J. Multimed. Inf. Retr. 2018, 7, 95–116. [Google Scholar] [CrossRef] [Green Version]
- Schedl, M.; Gómez, E.; Urbano, J. Music information retrieval: Recent developments and applications. Found. Trends Inf. Retr. 2014, 8, 127–261. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; He, X.; Wang, X.; Zhang, K.; Wang, M. A survey on accuracy-oriented neural recommendation: From collaborative filtering to information-rich recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 4425–4445. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Zhang, H.R.; Min, F.; Zhang, Z.H.; Wang, S. Efficient collaborative filtering recommendations with multi-channel feature vectors. Int. J. Mach. Learn. Cybern. 2019, 10, 1165–1172. [Google Scholar] [CrossRef]
- Fan, W.; Ma, Y.; Li, Q.; He, Y.; Zhao, E.; Tang, J.; Yin, D. Graph neural networks for social recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 417–426. [Google Scholar]
- Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; Liu, Q. Shine: Signed heterogeneous information network embedding for sentiment link prediction. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 592–600. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Sun, Y.; Yuan, N.J.; Xie, X.; McDonald, K.; Zhang, R. Collaborative intent prediction with real-time contextual data. ACM Trans. Inf. Syst. TOIS 2017, 35, 1–33. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. CSUR 2021, 54, 1–37. [Google Scholar]
- Duan, H.; Liu, P.; Ding, Q. RFAN: Relation-fused multi-head attention network for knowledge graph enhanced recommendation. Appl. Intell. 2023, 53, 1068–1083. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 12175–12185. [Google Scholar]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G.; Lv, J. Automatically designing CNN architectures using the genetic algorithm for image classification. IEEE Trans. Cybern. 2020, 50, 3840–3854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 2017 Annual Conference on Neural Information Processing Systems: Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and deep locally connected networks on graphs. In Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Zhu, X.; Li, Z.; Wang, X.; Jiang, X.; Sun, P.; Wang, X.; Xiao, Y.; Yuan, N.J. Multi-modal knowledge graph construction and application: A survey. IEEE Trans. Knowl. Data Eng. 2022, 1, 1–20. [Google Scholar] [CrossRef]
- Mousselly-Sergieh, H.; Botschen, T.; Gurevych, I.; Roth, S. A multimodal translation-based approach for knowledge graph representation learning. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, New Orleans, LA, USA, 5–6 June 2018; pp. 225–234. [Google Scholar]
- Pezeshkpour, P.; Chen, L.; Singh, S. Embedding Multimodal Relational Data for Knowledge Base Completion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3208–3218. [Google Scholar]
- Guo, W.; Wang, J.; Wang, S. Deep multimodal representation learning: A survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Sun, R.; Cao, X.; Zhao, Y.; Wan, J.; Zhou, K.; Zhang, F.; Wang, Z.; Zheng, K. Multi-modal knowledge graphs for recommender systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020; pp. 1405–1414. [Google Scholar]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Hong, R.; Chua, T.S. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1437–1445. [Google Scholar]
- Tao, S.; Qiu, R.; Ping, Y.; Ma, H. Multi-modal knowledge-aware reinforcement learning network for explainable recommendation. Knowl.-Based Syst. 2021, 227, 107217. [Google Scholar] [CrossRef]
- Vyas, P.; Vyas, G.; Dhiman, G. RUemo—The Classification Framework for Russia-Ukraine War-Related Societal Emotions on Twitter through Machine Learning. Algorithms 2023, 16, 69. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, Z.; Lin, G.; Tan, H.; Chen, Q.; Liu, X. CKAN: Collaborative knowledge-aware attentive network for recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 25–30 July 2020; pp. 219–228. [Google Scholar]
- Togashi, R.; Otani, M.; Satoh, S. Alleviating cold-start problems in recommendation through pseudo-labelling over knowledge graph. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Online, 8–12 March 2021; pp. 931–939. [Google Scholar]
- Chen, Y.; Wang, X.; Fan, M.; Huang, J.; Yang, S.; Zhu, W. Curriculum meta-learning for next POI recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Online, 14–18 August 2021; pp. 2692–2702. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Moscati, M.; Parada-Cabaleiro, E.; Deldjoo, Y.; Zangerle, E.; Schedl, M. Music4All-Onion—A Large-Scale Multi-faceted Content-Centric Music Recommendation Dataset (Version v0). In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 968–977. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Expansion |
|---|---|
| KG | Knowledge graph |
| MMKG | Multi-modal knowledge graph |
| CF | Collaborative filtering |
| CKG | Collaborative knowledge graph |
| CNN | Convolutional neural network |
| GCN | Graph convolutional network |
| PCA | Principal component analysis |
| KG | Music multi-modal knowledge graph |
| MFCC | Mel-frequency cepstral coefficient |
| Triple | Head | Relation/Attribute | Tail |
|---|---|---|---|
| Justin Bieber | Singer.Nation | Canada | |
| Taylor Swift | Singer.Music | exile | |
| Love Story | Music.Genre | Pop | |
| exile | Music.Poster | exile_poster.png | |
| exile | Music.Lyrics | exile_lyrics.txt | |
| Saturn | Music.audio | Saturn.mp3 |
| KG-12M | KG-3M | KG-20k | KG-6k | |
|---|---|---|---|---|
| #users | 52,431 | 44,548 | 9843 | 5999 |
| #items | 51,842 | 19,123 | 5268 | 4836 |
| #interactions | 11,987,329 | 3,209,509 | 196,754 | 56,492 |
| #entities | 60,312 | 23,781 | 7513 | 6775 |
| #relations | 76 | 51 | 26 | 7 |
| #triples | 445,866 | 152,921 | 42,170 | 36,264 |
| Model | KG-12M | KG-3M | KG-20k | KG-6k | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | F1 | AUC | F1 | AUC | F1 | AUC | F1 | |
| SVD | 0.729 | 0.612 | 0.743 | 0.639 | 0.738 | 0.635 | 0.731 | 0.640 |
| CKE | 0.767 | 0.689 | 0.792 | 0.704 | 0.766 | 0.697 | 0.744 | 0.673 |
| RippleNet | 0.852 | 0.792 | 0.796 | 0.723 | 0.785 | 0.707 | 0.780 | 0.702 |
| KGCN | 0.909 | 0.843 | 0.887 | 0.799 | 0.867 | 0.781 | 0.811 | 0.721 |
| MMGCN | 0.937 | 0.885 | 0.906 | 0.832 | 0.885 | 0.814 | 0.876 | 0.756 |
| MKGAT | 0.952 | 0.897 | 0.935 | 0.850 | 0.913 | 0.843 | 0.899 | 0.812 |
| MKGCN | 0.973 | 0.916 | 0.960 | 0.896 | 0.942 | 0.867 | 0.918 | 0.841 |
| Parameter | KG-12M | KG-3M | KG-20k | KG-6k |
|---|---|---|---|---|
| d | 128 | 128 | 64 | 32 |
| k | 8 | 8 | 16 | 8 |
| l | 2 | 1 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, X.; Qu, X.; Li, D.; Yang, Y.; Li, Y.; Zhang, X. MKGCN: Multi-Modal Knowledge Graph Convolutional Network for Music Recommender Systems. Electronics 2023, 12, 2688. https://doi.org/10.3390/electronics12122688
Cui X, Qu X, Li D, Yang Y, Li Y, Zhang X. MKGCN: Multi-Modal Knowledge Graph Convolutional Network for Music Recommender Systems. Electronics. 2023; 12(12):2688. https://doi.org/10.3390/electronics12122688
Chicago/Turabian StyleCui, Xiaohui, Xiaolong Qu, Dongmei Li, Yu Yang, Yuxun Li, and Xiaoping Zhang. 2023. "MKGCN: Multi-Modal Knowledge Graph Convolutional Network for Music Recommender Systems" Electronics 12, no. 12: 2688. https://doi.org/10.3390/electronics12122688