Abstract
Aiming at the environment of low illumination, high dust, and heavy water fog in coal mine driving face and the problems of occlusion, coincidence, and irregularity of bolt mesh laid on coal wall, a YOLOv7 bolt mesh-detection algorithm combining the image enhancement and convolutional block attention module is proposed. First, the image brightness is enhanced by a hyperbolic mapping transform-based image enhancement algorithm, and the image is defogged by a dark channel-based image defogging algorithm. Second, by introducing a convolutional block attention model in the YOLOv7 detection network, the significance of bolt mesh targets in the image is improved, and its feature expression ability in the detection network is enhanced. Meanwhile, the original activation function ReLU in the convolutional layer Conv of the YOLOv7 network is replaced by LeakyReLU so that the activation function has stronger nonlinear expression capability, which enhances the feature extraction performance of the network and thus improves the detection accuracy. Finally, the training and testing samples were prepared using the actual video of the drilling and bolting operation, and the proposed algorithm is compared with five classical target detection algorithms. The experimental results show that the proposed algorithm can be better applied to the low illumination, high dust environment, and irregular shape on the detection accuracy of coal mine roadway bolt mesh, and the average detection accuracy of the image can reach 95.4% with an average detection time of 0.0392 s.
1. Introduction
In coal mine roadway-support construction, after the drilling rig acquires the preset drilling position, it usually needs to rely on human eyes to manually adjust the direction and position of the drilling rig to avoid interfering with the bolt mesh laid on the coal wall. In order to free productivity from the harsh underground construction environment, it is important to integrate machine vision into drilling rig positioning and accurately identify bolt mesh hole positions to achieve intelligent support [1,2,3,4].
At present, many scholars at home and abroad have conducted much research on underground coal mine target detection using machine vision technology and have achieved more remarkable results and progress [5,6,7,8]. Liang et al. [9] proposed a drilling robot pressure relief hole-identification method based on a single image generation adversarial network (SinGAN). They improved the fast regional convolutional neural network (faster R-CNN), which has significantly improved both accuracy and recall rate. Kou et al. [10] proposed a multi-scale convolutional neural network (Ucm-YOLOv5) for real-time detection in underground coal mines, which solved the problems of infrared camera imaging itself with little texture information, much noise, and blurred images, and improved the detection accuracy and detection speed to some extent. Nan et al. [11] proposed a real-time saliency detection method based on random sampling region contrast calculation for the real-time perception of key targets in underground coal mines, which improved detection segmentation accuracy and real-time processing efficiency. Jia et al. [12] proposed a detection model combining Faster RCNN and VGG16 convolutional neural network with the top pallet of the roadway as the detection target, which improved the detection accuracy of the digger position posture. Li et al. [13] proposed an improved YOLOv4 detection network, and the improved network has strong robustness and generalization ability, which improved the detection accuracy of underground coal mine workers. Zhang et al. [14] enabled the model to achieve lightweight depth by improving the backbone and neck network of YOLOv4 while ensuring detection accuracy. Ding et al. [15] proposed a deep learning training method that fuses infrared and visible samples to improve the performance of the recognition network by expanding the number of samples and features, which effectively improves the problem of low accuracy and poor real-time performance caused by noise, complex background, and occlusion in coal gangue classification detection. Pan et al. [16] proposed a machine vision-based detection method for the relative positioning of hydraulic brackets in coal mining driving faces, which effectively reduces the model size and computational effort to meet the requirements of real-time detection. To address the limitations of existing algorithms in extracting image features and identifying targets of different sizes, Shan et al. [17] proposed a cascade network incorporating the borehole feature extraction transform (BFET) and borehole detection (BD), which improved the contrast of images and the accuracy of real-time detection. For the problem of detecting the possible artifacts of the target, Song et al. [18] proposed a multi-scale feature fusion and attention-based multi-branch detection network to solve the problem of accurately identifying multiple complex obstacles by automatic driving in open pit mines. Jiang et al. [8] proposed a motion target tracking algorithm based on principal component analysis feature transformation at the same scale, and the optimized algorithm has stronger robustness.
The above algorithms and models have solved the problem of difficult detection of targets due to harsh environments to a certain extent, but the detection of bolt mesh targets in underground coal mines has rarely been reported. To address the problem that bolt mesh targets in complex coal mine environments are irregular, overlapping, and obscured [19,20,21,22], this paper proposes a YOLOv7 bolt mesh detection algorithm that incorporates image enhancement and convolutional block attention modules. The innovative points are as follows: (i) Image enhancement based on hyperbolic mapping transform [23,24] and dark channel-based defogging algorithm [25,26,27] are used to pre-process bolt mesh images with degraded features, such as low illumination and high dust obtained from underground excavation workings to improve the quality of the input images of the detection network. (ii) To suppress the interference caused by irregularly shaped mesh targets to the training model, the Convolutional Block Attention Module (CBAM) [28] is introduced based on the YOLOv7 [29] detection network to enhance the feature representation of bolt mesh targets and improve the detection accuracy. (iii) Facing the complex background environment, the bolt mesh detection network training is prone to the problem of gradient disappearance, and the activation function in the Conv module of the YOLOv7 network is deformed into LeakyRelu [30] to reduce the information loss by introducing negative slope and maintain a strong feature extraction capability.
2. YOLOv7 Model
The YOLOv7 algorithm was proposed by Wang et al. [29] in July 2022, using E-ELAN, cascade-based models (concatenation-based models), model scaling [31], convolutional reparameterization [32], and other strategies to outperform all known target detectors in the range from 5 frame/s to 160 frame/s in terms of speed and accuracy. As shown in Figure 1, the YOLOv7 network structure consists of four parts: input, backbone, head, and prediction. Mosaic data enhancement is used in input to improve the training speed of the model and the accuracy of the network, and adaptive anchor frame calculation and image scaling are used to enrich the data set and add small sample targets to further optimize the network in terms of training speed and reduce the memory requirement for training the network model. The backbone module processes the input high-dimensional data and extracts image features of different scales, which are composed of several BConv layers, E-ELAN layers, and MPConv layers. The BConv layer consists of a convolutional layer + BN layer + ReLU activation function for the extraction of target features; the E-ELAN layer maintains the original ELAN design architecture, learns more diverse features by guiding the calculation blocks of different feature groups, improves the learning ability of the network without damaging the original gradient path, and extends cardinality in the computational block section to perform OSA Module related operations in VOVNet; and the MPConv convolutional layer adds a Maxpool layer to the BConv layer to form two branches, the upper branch halves the image aspect through Maxpool and halves the image channel through the BConv layer. In the lower branch, the image channels are halved by the first BConv layer, and the image aspect is halved by the second BConv layer, and finally, the features extracted from the upper and lower branches are fused using the Cat operation to improve the feature-extraction capability of the network. The head is composed of a path aggregation feature pyramid network (PAFPN) [33] structure, which processes the feature maps extracted by the backbone and functionally includes feature fusion and classification positioning prediction. It is composed of the SPPCPC layer, BConv layer, MPConv layer, Catconv layer, and RepVGG block layer. After outputting the feature map, it outputs different sizes of unprocessed prediction results through REP and Conv layers. By introducing a bottom-up path, it is easier for low-level information to be transmitted to high-level information, thus achieving an efficient fusion of features at different levels; the prediction module adjusts the number of image channels for three different scale features of P3, P4, and P5 output by PAFPN using the REP (RepVGG Block) structure [32], and finally passes through 1 × 1 convolution used for predicting confidence, categories, and anchor boxes.
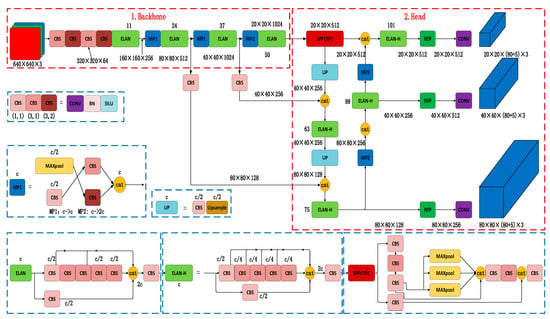
Figure 1.
YOLOv7 network structure.
3. Bolt Mesh Detection Method Based on Improved YOLOv7
In order to improve the detection accuracy of bolt mesh in the downhole environment, this paper improves the YOLOv7 network as follows: Firstly, a pre-processing image link is added to the input front-end to brighten and defog the image. Secondly, the attention mechanism CBAM module is added to the front end of the MP1 module in the YOLOv7 backbone network to enhance the attention of the network for detecting targets. Finally, the activation function in the Conv module is replaced with LeakyReLU to improve the network feature expression capability, and the framework of the improved algorithm is shown in Figure 2.
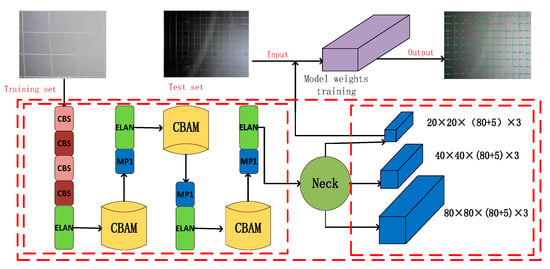
Figure 2.
The algorithm detection framework of this paper.
The detection process of the algorithm in this paper is as follows: First, the images collected under the mine are defogged and brightened; then, they are fed into the designed detection network for training to obtain the training weights of the detection model; and finally, the proposed detection network is tested and verified using the test data.
3.1. Fusion of Dark Channel Prior and Hyperbolic Mapping Transform Image Processing
Due to the characteristics of low illumination and high dust in the underground coal mine excavation driving face, which leads to different degradation characteristics of the images acquired during bolt support operations, the accuracy of the YOLOv7 algorithm in detecting such images is reduced. Therefore, this paper pre-processes the images with enhancement before the input part. Firstly, a dark channel-based defogging algorithm is used to defog the high dust images, and then a low-illumination image-enhancement algorithm based on hyperbolic mapping transform is used for low illumination enhancement.
The dark channel prior is a widely used image-processing method in computer vision. It is based on the assumption that in an image of a natural scene, there is at least one pixel point with a very low value (close to zero) on at least one color channel. This is due to the fact that in natural scenes, almost no pixel point is completely opaque. Therefore, the atmospheric light intensity of the entire image can be inferred from these very dark pixel points and thus used for image defogging. The formula for the defogged image is as follows:
where J(x) is the image after defogging, I(x) is the image original image and A is the atmospheric light value, t(x) is the transmitted light rate, and t0 is a small positive number usually taken as 0.1 for avoiding division by zero. A local comparison of the dark channel after a priori defogging treatment is shown in Figure 3:

Figure 3.
Results of the dark channel-based defogging algorithm. (a) Original image and (b) enhanced image.
The enhancement of a low-illuminance image based on hyperbolic mapping transformation is mainly to use the maximum entropy algorithm to calculate the threshold value of the V component in the HSV color space and, based on this threshold value, give the pixel value in the V component of the image light and dark two attributes, and use the improved hyperbolic tangent Sigmoid function and hyperbolic secant cumulative distribution function (Equation (2)) to enhance the two pixels of the image light and dark attributes, respectively.
where V(i, j) is the component after conversion to HSV space, the component after enhancement, and the maximum entropy of the image, which is used as a segmentation threshold to distinguish the image into dark and light areas. After partition processing, it can reduce image distortion caused by excessive enhancement of bright areas or insufficient enhancement of dark areas; λ is the scalar that controls the enhancement process, which is calculated as follows:
where is the variance of the gray value of the original input image.
In this case, the overall brightness of the obtained image is dark, so light compensation is required. Through extensive experiments, it is concluded that the nonlinear transformation function can compensate the image for illumination. The function is defined as follows:
where Iin is the image converted back to RGB space, f(Iin) is the image after lighting compensation, and indicates the absolute value. The mapping function can enhance the overall image brightness without affecting the contrast effect.
The local comparison chart after the low-illumination enhancement process is shown in Figure 4.

Figure 4.
Image enhancement based on hyperbolic mapping transform. (a) Original image and (b) enhanced image.
From these two images, it can be seen that the enhanced image shows the specific texture of the detection target and gives more information about the target, which is beneficial for the next training and detection.
3.2. Detection Network with Fused Convolutional Block Attention Model
Due to the unevenness of coal walls in underground coal mines, which leads to the irregular shape of bolt mesh, thus causing the problem of missed detection and false detection, this paper introduces the channel and spatial convolutional block attention model before the 3 MP1 modules of YOLOv7 network model, whose structure is shown in Figure 5, where F is the input feature map; Fx is the feature map obtained after passing spatial attention.
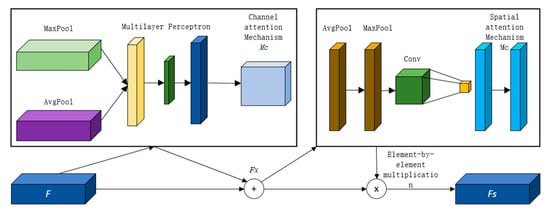
Figure 5.
CBAM module.
In Figure 5, MC is the channel attention in the convolutional block attention model, and Ms is the spatial attention. Given the feature map , where C is the number of channels in the feature map, H × W is the size of the feature map, and is the 3D matrix composed of C, H, and W.
The CBAM module first pools the input feature map by channel with global average and global maximum to obtain different features of the channel, calculates the channel attention vector by multi-layer perceptron with the obtained average and maximum values, and activates the obtained vector nonlinearly with sigmoid function to obtain the channel attention feature, which is calculated as follows:
where MLP (multi-layer perceptron) is the multi-layer perceptron; AvgPool (·) and MaxPool (·) denote the operations of average pooling and maximum pooling of feature graph spatial information by the module, respectively; and are the global average pooling and maximum average pooling operations of the channel attention mechanism, respectively; W0 is the layer 1 weight of the multi-layer perceptron and W1 is the layer 2 weight.
For a given feature map, two different spatial feature maps are obtained through average pooling and maximum pooling, followed by two 1 × 1 convolutions and activation of the sigmoid function to obtain two numerical vectors, which are stitched together and then passed through the convolution and sigmoid function to finally obtain the spatial attention feature map, which is calculated as follows:
where Cat is the join operation, is the convolution operation of size 7 × 7, and and are the global average pooling and maximum average pooling operations of the spatial attention mechanism, respectively.
YOLOv7 has no attention preference in the feature extraction process and uses the same weighting for features of different importance. In this paper, we solve the original network no attention preference problem by engaging CBAM modules before each of the three MP1 modules so that the network can pay more attention to the interest target during detection.
3.3. Activation Functions
In deep neural networks, each neuron in the neural network has input data and output features, but the output transformation of the linear model has a natural linear mapping property, and for nonlinear classification problems, the data is not well linearly differentiable. The role of the activation function is to nonlinearly map the input signals of the neurons, thus enabling the neural network to learn and represent more complex patterns and functional relationships, making the classification surface more complex, improving the discriminative power of the model, and enhancing the representation capability of the network. Secondly, in the output layer of the neural network, the output of the network usually needs to be mapped to a specific range. Using the activation function output range, such as [0, 1], [−1, 1], [0, inf], etc., can help the neural network to accomplish this mapping and scaling operation. The training of deep neural networks requires gradient optimization, in which the activation output curve of each neuron needs to be calculated by the activation function, and its derivative is used to calculate the error back propagation. The activation function plays a crucial role in optimizing the algorithm and training speed and reducing problems such as gradient disappearance and gradient explosion.
The advantage of the activation function ReLU used in the convolutional layer of the YOLOv7 model network structure is that it is simple and easy to optimize, as the output is zero when the definition domain is negative, which makes the network sparser and helps to alleviate overfitting and meet the requirements of a lightweight network. The gradient of the output stays 1 when the definition domain is positive, which means that its gradient will be more useful for learning. However, the disadvantage of ReLU is that if the weight is negative when the network is trained for the first time, according to the function expression of ReLU, the subsequent training will always be zero. Because of the characteristics of low illumination and high dust in the underground coal mine excavation driving face, the detection target background is extraordinarily complex, and the loss of negative gradient information will directly lead to the missed detection of bolt mesh targets. Therefore, to avoid this phenomenon, LeakyReLU is used as the activation function in this paper; ReLU function, LeakyReLU function graph, as shown in Figure 6; and ReLU function, LeakyReLU function expression as shown in Equations (7) and (8).
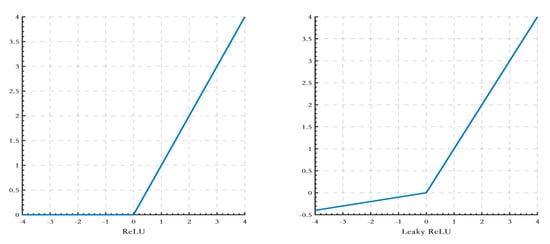
Figure 6.
Comparison chart of ReLU and LeakyReLU functions.
The activation function LeakyReLU slows down the problem of gradient disappearance during training, making the backpropagation more effective and thus accelerating the convergence and training speed of the model. When the neuron is not activated, the activation function still has a non-zero output with a small gradient, thus avoiding the possible ‘death’ of the neuron. Moreover, the nonlinear nature of the LeakyReLU function improves the feature extraction capability of the network, which further alleviates the problem of low detection accuracy when facing irregular bolt mesh networks.
4. Model Training and Result Analysis
The hardware and software platform configurations used in the experiments are shown in Table 1.

Table 1.
Software and hardware platform configuration.
4.1. Data Acquisition
The data used in this paper come from the main coal laboratory and the video taken during the support operation of a coal mine excavation driving face, in which 800 photos were taken in the main coal laboratory, and 200 were intercepted from the video by frame. In the experiment, 700 were randomly selected as training samples, and the remaining 300 were used as test samples.
4.2. Analysis of Experimental Results
To avoid the model falling into local optimum or skipping the optimal solution during training, a cosine function with a coefficient of 0.85 is used to set the decreasing learning rate. Finally, after 300 rounds of model iterative training, the optimal model weights are obtained. In order to verify the advantages of the algorithm in this paper, the proposed algorithm in this paper is compared with YOLOv7, and the results are shown in Figure 7 and Figure 8.
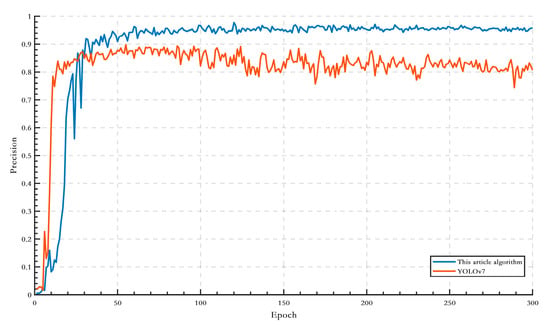
Figure 7.
Accuracy change curve.
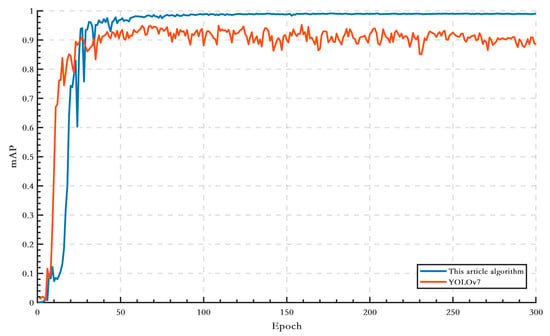
Figure 8.
mAP% Curve.
From Figure 7, it can be seen that the final stable accuracy of the YOLOv7 algorithm is low, only about 0.82; meanwhile, it is still difficult to achieve complete convergence in the later stage. In contrast, the final accuracy of the algorithm in this paper is stable at about 0.95, while the accuracy changes in the late iterations fluctuate less. mAP curve comparison results are shown in Figure 8.
From Figure 8, it can be seen that the mAP (mean average precision) values of the algorithm in this paper are significantly higher than those of the YOLOv7 network.
4.2.1. Ablation Experiments
In this paper, the algorithm carries out image enhancement, introduces the CBAM attention mechanism module, and replaces the activation function under the original YOLOv7 detection framework, respectively. To verify the role of each part, ablation experiments are conducted to validate the results, which are shown in Table 2.
Table 2.
Results of ablation experiments.
The first row in Table 2 shows the detection results of the original YOLOv7 network. Table 2 shows that when the image enhancement module is added to the original network, it can reduce the image haze and improve the brightness of the image, which makes the image clearer and thus improves the detection accuracy by 1.4%; when the CBAM module is added, it can improve the feature expression ability of the irregularly shaped bolt mesh, and its detection accuracy improves by 1.1% compared with the original network. When the activation function is replaced, its nonlinear features improve the feature extraction ability of the network, which improves the detection accuracy by 5.1% compared with the original network. When the activation function is replaced, its strong nonlinear ability improves the feature extraction ability of the network, which improves the detection accuracy by 5.1% on the basis of the original network; the algorithm in this paper integrates the advantages of each module and the detection accuracy can reach 95.4%.
4.2.2. Comparative Experiments
- (1)
- Subjective Evaluation
In order to verify the merits of the algorithm in this paper, images under low illumination scenes have been selected for testing and validation, as shown in Figure 9a. Figure 9b shows the enhanced image, and the detected targets have been marked with green boxes for the convenience of analysis. For the convenience of description, the detected bolt mesh is indicated by mk. 5 classical detection algorithms, SSD, YOLOv3, YOLOv4, YOLOv5, and YOLOv7, which are selected for comparison with the detection algorithm proposed in this paper, and the detection results are shown in Figure 9c–h.


Figure 9.
Comparison of detection results of different algorithms. (a) Original drawing; (b) enhanced image; (c) SSD; (d) YOLOv3; (e) YOLOv4; (f) YOLOv5; (g) YOLOv7; (h) ours.
From the results of Group 1, it can be observed that the traditional five contrast algorithms generally have the problem of missing detection in target detection when the ambient illumination is too low. However, the algorithm in this paper uses a low illumination enhancement algorithm based on hyperbolic mapping transform to improve the image brightness and make the details in the image more visible. The enhanced image can present more information about the texture of the detected target, which makes the feature expression of the target more prominent and thus can detect all the bolt mesh.
From the results of Group 2, it can be seen that in the permanently supported environment of the driving face, the scene is very dark and hazy, which leads to the common problem of missing detection in the target detection by the traditional five comparison algorithms. The present algorithm, however, uses a dark channel prior-based defogging algorithm to enhance the image and highlights the outline of the bolt mesh target during the processing. Such processing effectively solves the target leakage detection problem caused by high dust environments solving the problem of missing target detection caused by the high dust environment.
From the results of Group 3, it can be seen that all the five compared algorithms have missed or wrong detection when detecting irregular bolt mesh. In contrast, the algorithm in this paper introduces the CBAM module, which enables the network to automatically obtain the importance of each channel by using the channel attention of the module and superimposes the information of each channel with the weight-sharing multi-layer perceptron to give different weights to each channel to strengthen the target features; by using the spatial attention of the CBAM module to generate weights for each position in the feature map and weigh the output, the target expression capability is enhanced. By using the spatial attention of the CBAM module to generate weights for each location in the feature map and weighing the output, the feature representation of the bolt mesh target is enhanced. Meanwhile, replacing the activation function in the YOLOv7 model Conv with the LeakyRelu function improves the feature-extraction ability of the network and finally improves the detection ability of the network for irregularly shaped bolt mesh.
- (2)
- Objective Analysis
In order to better verify the advantages of the algorithm in this paper, it is compared with the above five comparison algorithms for objective indexes, and the results are shown in Table 3.
Table 3.
Comparison results of objective indicators.
From the detection results of the comparison algorithm in Table 3, we can see that the detection accuracy of the five comparison algorithms is between 0.78 and 0.831, and this algorithm in the detection accuracy of 0.954 detection accuracy compared to the comparison algorithm, improved by more than 10%, significantly higher than the other five detection algorithms. The detection speed is 40 fps faster than SSD, YOLOv3, and YOLOv4 within the acceptable range.
5. Conclusions
A YOLOv7 bolt mesh detection algorithm integrating image enhancement and convolutional block attention module is proposed for the problem that the visually acquired images of coal mine excavation driving face have different degradation characteristics such as low illumination, high dust, and local glare, as well as the low accuracy of traditional detection algorithm caused by the occlusion and overlap phenomenon of roadway bolt mesh laying.
- (1)
- The fog removal algorithm based on the dark channel prior and the low illumination enhancement algorithm based on hyperbolic mapping changes are used to pre-process the acquired images. For low-illumination images, light and dark partitioning enhancement is performed to improve the brightness of the images without distortion. For high dust images, the haze of the images is reduced to make the texture features of the images more prominent, which improves the quality of the data set and provides a reliable input for the detection network;
- (2)
- A YOLOv7 bolt mesh detection algorithm that incorporates image enhancement and convolutional block attention modules is proposed. The problem of weak edge saliency of irregular bolt mesh is effectively solved by introducing the CBAM attention mechanism while replacing the activation function of Conv in the YOLOv7 network with LeakyRelu, which solves the problem that due to the complex background of an underground coal mine environment, the detection network is prone to gradient disappearance during training, which leads to increased information loss and decreased accuracy of detection results, and improves the feature extraction capability of the network and the detection accuracy of irregular bolt mesh networks;
- (3)
- The experimental results indicate that the average detection accuracy of this paper’s algorithm for bolt mesh laid on the coal wall of the roadway is 95.4%, which is more than 10% higher than other comparative algorithms, the detection speed is 40 fps, and the overall results are better than the SSD, YOLOv3, YOLOv4, YOLOv5, and YOLOv7 algorithms;
- (4)
- For the special-shaped bolt mesh network, the detection accuracy of the algorithm in this paper is limited, and the robustness of the detection algorithm needs to be further improved. Meanwhile, due to the replacement of the activation function, the complexity of the model is increased, and the model is not light enough to be improved.
Author Contributions
Conceptualization, S.S., H.M. and C.W.; methodology, K.W.; software, Z.W.; validation, S.S., H.M. and K.W.; formal analysis, Z.W.; investigation, H.Y.; resources, H.M.; data curation, S.S.; writing—original draft preparation, K.W.; writing—review and editing, H.Y.; visualization, S.S.; supervision, Z.W.; project administration, H.M. and C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Scientific Research Plan Projects of Shaanxi Province Education Department, grant number 21JK0769, the National Natural Science Foundation of China, grant number 51975468, and the Shaanxi Provincial Department of Education to Serve Local Special Program Projects, grant number 22JC051.
Data Availability Statement
The bolt mesh detection data set in this paper is a homemade data set and is not disclosed due to its use in subsequent studies.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ma, H.; Yao, Y.; Xue, X.; Wang, C.; Gao, J. Research on body positioning method of drill-anchor robot based on multi-sensor combination. Coal Sci. Technol. 2021, 49, 278–285. [Google Scholar]
- You, S.; Zhu, H.; Li, M.; Wang, L.; Tang, C. Tracking system of Mine Patrol Robot for Low Illumination Environment. arXiv 2019, arXiv:1907.01806. [Google Scholar]
- King, R.; Hicks, M.; Signer, S. Using unsupervised learning for feature detection in a coal mine roof. Eng. Appl. Artif. Intell. 1993, 6, 565–573. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Shi, X.; Huang, J.; Huang, B. An Underground Abnormal Behavior Recognition Method Based on an Optimized Alphapose-ST-GCN. J. Circuits Syst. Comput. 2022, 31, 2250214. [Google Scholar] [CrossRef]
- Hao, S.; Gao, S.; Ma, X.; An, B.; He, T. Anchor-free infrared pedestrian detection based on cross-scale feature fusion and hierarchical attention mechanism. Infrared Phys. Technol. 2023, 131, 104660. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, W.; Zhao, S.; Xue, B.; Zhang, W.; Xing, Z. A Big Coal Block Alarm Detection Method for Scraper Conveyor Based on YOLO-BS. Sensors 2022, 22, 9052. [Google Scholar] [CrossRef]
- Jiang, D.; Dai, L.; Zhang, S. Moving-Object Tracking Algorithm Based on PCA-SIFT and Optimization for Underground Coal Mines. IEEE Access. 2019, 7, 35556–35563. [Google Scholar]
- Liang, B.; Wang, Z.; Si, L.; Wei, D.; Gu, J.; Dai, J. A Novel Pressure Relief Hole Recognition Method of Drilling Robot Based on SinGAN and Improved Faster R-CNN. Appl. Sci. 2023, 13, 513. [Google Scholar] [CrossRef]
- Kou, F.; Xiao, W.; He, H.; Chen, R. Research on Target Detection in Underground Coal Mines Based on Improved YOLOv5. J. Electron. Inf. Technol. 2023, 45, 1–8. [Google Scholar] [CrossRef]
- Nan, B.; Guo, Z.; Wang, K.; Li, S.; Dong, X.; Huo, D. Study on real-time perception of target ROl in underground coal mines based on visual saliency. Coal Sci. Technol. 2022, 50, 247–258. [Google Scholar]
- Jia, Q.; Tian, Y. Roof Object Detection of Underground Coal Mine Roadway Based on Faster RCNN. Coal Mine Mach. 2022, 43, 174–177. [Google Scholar]
- Li, X.; Wang, S.; Liu, B.; Chen, W.; Fan, W.; Tian, Z. Improved YOLOv4 network using infrared images for personnel detection incoal mines. J. Electron. Imaging 2022, 31, 1301. [Google Scholar]
- Zhang, M.; Cao, Y.; Jiang, K.; Li, M.; Liu, L.; Yu, Y.; Zhou, M.; Zhang, Y. Proactive measures to prevent conveyor belt Failures: Deep Learning-based faster foreign object detection. Eng. Fail. Anal. 2022, 141, 106653. [Google Scholar] [CrossRef]
- Ding, Z.; Chen, G.; Wang, Z.; Chi, W.; Wang, Z.; Fan, Y. A Real-Time Multilevel Fusion Recognition System for Coal and GangueBased on Near-Infrared Sensing. IEEE Access. 2020, 8, 178722–178732. [Google Scholar] [CrossRef]
- Pan, L.; Duan, Y.; Zhang, Y.; Xie, B.; Zhang, R. A lightweight algorithm based on YOLOv5 for relative position detection of hydraulic support at coal mining faces. J. Real-Time Image Process. 2023, 20, 40. [Google Scholar] [CrossRef]
- Pan, S.; Tian, Z.; Qin, Y.; Yue, Z.; Yu, T. Intelligent Blasthole Detection of Roadway Working Face Based on Improved YOLOv7 Network. Appl. Sci. 2023, 13, 6587. [Google Scholar] [CrossRef]
- Song, R.; Ai, Y.; Tian, B.; Chen, L.; Zhu, F.; Yao, F. MSFANet: A Light Weight Object Detector Based on Context Aggregation and Attention Mechanism for Autonomous Mining Truck. IEEE T Intell. Veh. 2023, 8, 2285–2295. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Q.; Kamiński, P.; Deifalla, A.F.; Sufian, M.; Dyczko, A.; Atig, M. Compressive strength of steel fiber-reinforced concrete employing supervised machine learning techniques. Materials 2022, 15, 4209. [Google Scholar] [CrossRef]
- Skrzypkowski, K.; Korzeniowski, W.; Zagórski, K.; Zagórska, A. Modified rock bolt support for mining method with controlled roof bending. Energies 2020, 13, 1868. [Google Scholar] [CrossRef]
- Jinqiang, W.; Basnet, P.; Mahtab, S. Review of machine learning and deep learning application in mine microseismic event classification. Min. Miner. Depos. 2021, 15, 19–26. [Google Scholar] [CrossRef]
- Krykovskyi, O.; Krykovska, V.; Skipochka, S. Interaction of rock-bolt supports while weak rock reinforcing by means of injection rock bolts. Min. Miner. Depos. 2021, 15, 8–14. [Google Scholar] [CrossRef]
- Hua, G.; Jiang, D. A New Method of Image Denoising for Underground Coal Mine Based on the Visual Characteristics. J. Appl. Math. 2014, 2014, 362716. [Google Scholar] [CrossRef]
- Dai, J.; Feng, Z.; Cui, M.; Zhao, X.; Yuan, S. Research on low illumination road image enhancement method based on hyperbolic mapping transformation. Laser J. 2023, 44, 146–151. [Google Scholar]
- Xiao, W.; Ya, L.; Sha, Y. Restoration Algorithms of Degradation Image in Underground Mine Based on Dark Channel Prior. Coal Sci. Technol. 2012, 40, 77–80. [Google Scholar]
- Liu, J.; Zhang, B.; Lu, C.; Wang, Y.; Di, L. Optimized Technique of Single Image Haze Removal Based on Dark Channel Prior. Fire Control Command Control 2019, 44, 164–167+172. [Google Scholar]
- Ding, Y.; Huang, S. An Improved Generative Adversarial Network for Image Dehazing. Comput. Eng. 2022, 48, 207–212. [Google Scholar]
- Woo, S.; Park, J.; Lee, J. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Spiringer: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Jiang, T.; Cheng, J. Target recognition based on CNN with LeakyReLU and PReLU activation functions. In Proceedings of the IEEE Conference on Sensing, Diagnostics, Prognostics, and Control, Beijing, China, 15–17 August 2019; IEEE Press: New York, NY, USA, 2019; pp. 718–722. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE Press: New York, NY, USA, 2021; pp. 13024–13033. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N. RepVGG: Making VGG-style ConvNets great again. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE Press: New York, NY, USA, 2021; pp. 13728–13737. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).