
MRI Image Fusion Based on Sparse Representation with Measurement of Patch-Based Multiple Salient Features

Abstract
:1. Introduction
- (a)
- Kronecker-criterion-based SR, with a designed activity level measure integrating the salient features of multiple domains, will effectively reduce the loss of structural detailed information in the fusion process.
- (b)
- Inspired by the formation process of the vision system, the spatial saliency by textural contrast consists of luminance and orientation contrasts that can promote more highlighted textural information in order to participate in the fusion process.
- (c)
- Compared with the l1-norm-based activity level measure in sparse vectors, the transform saliency by the sum of sparse salient features can highlight more coefficients to measure the composite activity level through the sum of differences in the adjacent areas.
2. Related Work
2.1. SR-Based Image Fusion
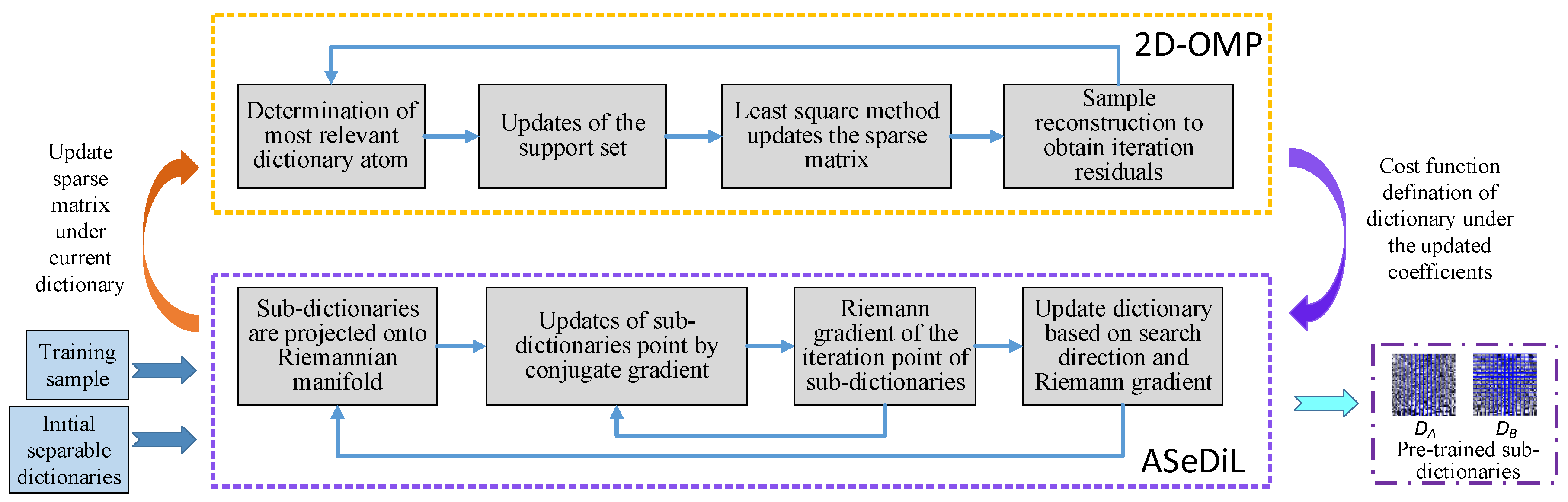
2.2. Separable Dictionary Learning Algorithm
3. Proposed Fusion Method
3.1. The Measurement of Activity Level for Fusion
3.1.1. Spatial Saliency by Textural Contrast
3.1.2. Spatial Saliency by Textural Contrast
3.2. Fusion Scheme
4. Experiments
4.1. Experimental Setting
4.1.1. Source Images
4.1.2. Objective Evaluation Metrics
4.1.3. Methods for Comparison
4.1.4. Algorithm Parameter Setting
4.2. Comparison to Other Fusion Methods
4.2.1. Subjective Visual Evaluation
4.2.2. Objective Quality Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahmad, S.; Khan, S.; Ajmi, M.F.A.; Dutta, A.K.; Dang, L.M.; Joshi, G.P.; Moon, H. Deep learning enabled disease diagnosis for decure internet of medical things. Comput. Mater. Contin. 2022, 73, 965–979. [Google Scholar]
- Haq, A.; Li, J.; Agbley, B.; Khan, A.; Khan, I.; Uddin, M.; Khan, S. IIMFCBM: Intelligent integrated model for feature extraction and classification of brain tumors using MRI clinical imaging data in IoT-Healthcare. IEEE J. Biomed. Health Inform. 2022, 26, 5004–5012. [Google Scholar] [CrossRef] [PubMed]
- Haq, A.; Li, J.; Khan, S.; Alshara, M.; Alotaibi, R.; Mawuli, C. DACBT: Deep learning approach for classification of brain tumors using MRI data in IoT healthcare environment. Sci. Rep. 2022, 12, 15331. [Google Scholar] [CrossRef] [PubMed]
- Hermessi, H.; Mourali, O.; Zagrouba, E. Multimodal medical image fusion review: Theoretical background and recent advances. Signal Process. 2021, 183, 108036. [Google Scholar] [CrossRef]
- Yousef, R.; Khan, S.; Gupta, G.; Siddiqui, T.; Albahlal, B.; Alajlan, S.; Haq, M. U-net-based models towards optimal MR brain image segmentation. Diagnostics 2023, 13, 1624. [Google Scholar] [CrossRef]
- Unar, S.; Xingyuan, W.; Chuan, Z. Visual and textual information fusion using kernel method for content based image retrieval. Inf. Fusion 2018, 44, 176–187. [Google Scholar] [CrossRef]
- Unar, S.; Wang, X.; Wang, C.; Wang, Y. A decisive content based image retrieval approach for feature fusion in visual and textual images. Knowl. Based Syst. 2019, 179, 8–20. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Zhou, W.; Li, R.; Wang, C.; Zhang, C. Color medical image lossless watermarking using chaotic system and accurate quaternion polar harmonic transforms. Signal Process. 2019, 157, 108–118. [Google Scholar] [CrossRef]
- Wang, C.; Wang, X.; Xia, Z.; Zhang, C. Ternary radial harmonic Fourier moments based robust stereo image zero-watermarking algorithm. Inf. Sci. 2019, 470, 109–120. [Google Scholar] [CrossRef]
- Wang, C.; Wang, X.; Xia, Z.; Ma, B.; Shi, Y. Image description with polar harmonic Fourier moments. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4440–4452. [Google Scholar] [CrossRef]
- Liu, S.; Zhao, J.; Shi, M. Medical image fusion based on improved sum-modified-laplacian. Int. J. Imaging Syst. Technol. 2015, 25, 206–212. [Google Scholar] [CrossRef]
- Liu, S.; Zhao, J.; Shi, M. Medical image fusion based on rolling guidance filter and spiking cortical model. Comput. Math. Methods Med. 2015, 2015, 156043. [Google Scholar]
- Sneha, S.; Anand, R.S. Ripplet domain fusion approach for CT and MR medical image information. Biomed. Signal Process. Control 2018, 46, 281–292. [Google Scholar]
- Talbar, S.N.; Chavan, S.S.; Pawar, A. Non-subsampled complex wavelet transform based medical image fusion. In Proceedings of the Future Technologies Conference, Vancouver, BC, Canada, 15–16 November 2018; pp. 548–556. [Google Scholar]
- Zhao, W.; Yang, H.; Wang, J.; Pan, X.; Cao, Z. Region- and pixel-level multi-focus image fusion through convolutional neural networks. Mob. Netw. Appl. 2021, 26, 40–56. [Google Scholar] [CrossRef]
- Jin, X.; Nie, R.; Zhang, X.; He, D.Z.K. Multi-focus image fusion combining focus-region-level partition and pulse-coupled neural network. Soft Comput. 2019, 23, 4685–4699. [Google Scholar]
- Qiu, X.; Li, M.; Yuan, L.Z.X. Guided filter-based multi-focus image fusion through focus region detection. Signal Process. Image Commun. 2019, 72, 35–46. [Google Scholar] [CrossRef]
- Li, H.; Ma, K.; Yong, H.; Zhang, L. Fast multi-scale structural patch decomposition for multi-exposure image fusion. IEEE Trans. Image Process. 2020, 29, 5805–5816. [Google Scholar] [CrossRef]
- Ma, K.; Li, H.; Yong, H.; Wang, Z.; Meng, D.; Zhang, L. Robust multi-exposure image fusion: A structural patch decomposition approach. IEEE Trans. Image Process. 2017, 26, 2519–2532. [Google Scholar] [CrossRef]
- Li, H.; Chan, T.N.; Qi, X.; Xie, W. Detail-preserving multi-exposure fusion with edge-preserving structural patch decomposition. IEEE Trans. Circuits Syst. Video Technol. 2021, 99, 4293–4304. [Google Scholar] [CrossRef]
- Nair, R.R.; Singh, T. MAMIF: Multimodal adaptive medical image fusion based on B-spline registration and non-subsampled shearlet transform. Multimed. Tools Appl. 2021, 80, 19079–19105. [Google Scholar] [CrossRef]
- Kong, W.; Miao, Q.; Lei, Y. Multimodal sensor medical image fusion based on local difference in non-subsampled domain. IEEE Trans. Instrum. Meas. 2019, 68, 938–951. [Google Scholar] [CrossRef]
- Padmavathi, K.; Karki, M.V.; Bhat, M. Medical image fusion of different modalities using dual tree complex wavelet transform with PCA. In Proceedings of the International Conference on Circuits, Controls, Communications and Computing, Bangalore, India, 4–6 October 2016; pp. 1–5. [Google Scholar]
- Xi, X.; Luo, X.; Zhang, Z.; You, Q.; Wu, X. Multimodal medical volumetric image fusion based on multi-feature in 3-D shearlet transform. In Proceedings of the International Smart Cities Conference, Wuxi, China, 14–17 September 2017; pp. 1–6. [Google Scholar]
- Shabanzade, F.; Ghassemian, H. Multimodal image fusion via sparse representation and clustering-based dictionary learning algorithm in nonsubsampled contourlet domain. In Proceedings of the 8th International Symposium on Telecommunications, Tehran, Iran, 27–28 September 2016; pp. 472–477. [Google Scholar]
- Xia, J.; Chen, Y.; Chen, A.; Chen, Y. Medical image fusion based on sparse representation and pcnn in nsct domain. Comput. Math. Methods Med. 2018, 5, 2806047. [Google Scholar] [CrossRef]
- Yin, M.; Liu, X.N.; Liu, Y.; Chen, X. Medical image fusion with parameter-adaptive pulse coupled-neural network in nonsubsampled shearlet transform domain. IEEE Trans. Instrum. Meas. 2018, 68, 49–64. [Google Scholar] [CrossRef]
- Dinh, P.H. A novel approach based on three-scale image decomposition and marine predators algorithm for multi-modal medical image fusion. Biomed. Signal Process. Control 2021, 67, 102536. [Google Scholar] [CrossRef]
- Pei, C.; Fan, K.; Wang, W. Two-scale multimodal medical image fusion based on guided filtering and sparse representation. IEEE Access 2020, 8, 140216–140233. [Google Scholar] [CrossRef]
- Shahdoosti, H.R.; Mehrabi, A. Multimodal image fusion using sparse representation classification in tetrolet domain. Digit. Signal Process. 2018, 79, 9–22. [Google Scholar] [CrossRef]
- Ling, T.; Yu, X. Medical image fusion based on fast finite shearlet transform and sparse representation. Comput. Math. Methods Med. 2019, 2019, 3503267. [Google Scholar]
- Elad, M.; Yavneh, I. A plurality of sparse representations is better than the sparsest one alone. IEEE Trans. Inf. Theory 2009, 55, 4701–4714. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Rabab, K.W.; Wang, Z. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Ghassemi, M.; Shakeri, Z.; Sarwate, A.D.; Bajwa, W.U. Learning mixtures of separable dictionaries for tensor data: Analysis and algorithms. IEEE Trans. Signal Process. 2019, 68, 33–48. [Google Scholar] [CrossRef] [Green Version]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef] [PubMed]
- Sturm, B.L.; Christensen, M.G. Cyclic matching pursuits with multiscale time-frequency dictionaries. In Proceedings of the Conference Record of the Forty Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 7–10 November 2011. [Google Scholar]
- Schnass, K. Average performance of orthogonal matching pursuit (OMP) for sparse approximation. IEEE Signal Process. Lett. 2018, 26, 1566–1567. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2010, 3, 1–122. [Google Scholar] [CrossRef]
- Hawe, S.; Seibert, M.; Kleinsteuber, M. Separable dictionary learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 438–445. [Google Scholar]
- Hu, Q.; Hu, S.; Zhang, F. Multi-modality medical image fusion based on separable dictionary learning and Gabor filtering. Signal Process. Image Commun. 2020, 83, 115758. [Google Scholar] [CrossRef]
- Kim, W.; Kim, C. Spatiotemporal saliency detection using textural contrast and its applications. IEEE Trans. Circuits Syst. Video Technol. 2013, 24, 646–659. [Google Scholar]
- Zhou, Z.; Li, S.; Wang, B. Multi-scale weighted gradient-based fusion for multi-focus images. Inf. Fusion 2014, 20, 60–72. [Google Scholar] [CrossRef]
- Hou, X.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Minneapolis, MI, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Liu, X.; Mei, W.; Du, H. Structure tensor and nonsubsampled shearlet transform based algorithm for CT and MRI image fusion. Neurocomputing 2017, 235, 131–139. [Google Scholar] [CrossRef]
- Pan, S.; Zhang, J.; Liu, X.; Guo, X. Complementary Harris feature point extraction method based on mutual information. Signal Process. 2017, 130, 132–139. [Google Scholar]
- Petrović, V. Subjective tests for image fusion evaluation and objective metric validation. Inf. Fusion 2007, 8, 208–216. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, J.; Wang, X.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. Int. Conf. Image Process. 2003, 3, 173–176. [Google Scholar]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Guo, X.; Han, P.; Wang, X.; Luo, T. Laplacian re-decomposition for multimodal medical image fusion. IEEE Trans. Instrum. Meas. 2020, 69, 6880–6890. [Google Scholar] [CrossRef]
- Tan, W.; Tiwari, P.; Pandey, H.M.; Moreira, C.; Jaiswal, A.K. Multimodal medical image fusion algorithm in the era of big data. Neural Comput. Appl. 2020, 3, 1–21. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.; Wang, Z.J. Medical image fusion via convolutional sparsity based morphological component analysis. IEEE Signal Process. Lett. 2019, 26, 485–489. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Metric | Symbol | Description |
|---|---|---|---|
| Textural-feature-preservation-based metrics | Normalized mutual information | QNMI | It measures the mutual information of a fused image and source images. |
| Edge-dependent-sharpness-based metrics | Normalized weighted performance index | QAB/F | It measures the amount of edge and orientation information of the fused image using the Sobel edge detection operator. |
| Overall image quality index | Q0 | It evaluates structural distortions in the fused image. | |
| Comprehensive-evaluation-based metrics | Weighted fusion quality index | QW | It values the structural similarity by addressing the coefficient correlation, illumination, and contrast. |
| Structural similarity index | QS | It determines the structural similarity by taking comparisons of luminance, contrast, and structure. | |
| Universal image index | QU | It is designed by modeling image distortion as a combination of the loss of correlation, luminance distortion, and contrast distortion. |
| WBAMI | Metric | NSST- | |||||
|---|---|---|---|---|---|---|---|
| LRD | MSMG- | CSMCA | l1-norm | SSSF | Proposed | ||
| PCNN | |||||||
| Acute stroke (28 pairs of CT/MR -PD, CT/MR-T2) | QAB/F | 0.4821 | 0.5187 | 0.5513 | 0.5863 | 0.5844 | 0.5880 |
| QS | 0.7244 | 0.6972 | 0.7254 | 0.7359 | 0.7366 | 0.7418 | |
| QU | 0.6709 | 0.4628 | 0.5862 | 0.6803 | 0.6809 | 0.6866 | |
| Q0 | 0.3008 | 0.2984 | 0.3038 | 0.3271 | 0.3270 | 0.3319 | |
| QW | 0.5633 | 0.5791 | 0.5873 | 0.6035 | 0.6061 | 0.6090 | |
| QNMI | 0.7466 | 0.6693 | 0.7097 | 0.8554 | 0.8357 | 0.8827 | |
| Hypertensive encephalopathy (28 pairs of CT/MR-Gad, CT/MR-T2) | QAB/F | 0.5062 | 0.5343 | 0.5840 | 0.6242 | 0.6248 | 0.6290 |
| QS | 0.6974 | 0.6699 | 0.7165 | 0.7144 | 0.7163 | 0.7211 | |
| QU | 0.6283 | 0.4506 | 0.5825 | 0.6395 | 0.6413 | 0.6474 | |
| Q0 | 0.3152 | 0.3051 | 0.3130 | 0.3540 | 0.3563 | 0.3541 | |
| QW | 0.5984 | 0.6254 | 0.6419 | 0.6607 | 0.6671 | 0.6736 | |
| QNMI | 0.6883 | 0.6240 | 0.6680 | 0.7091 | 0.7040 | 0.7464 | |
| Multiple embolic infarctions (60 pairs of CT/MR -PD, CT/MR-T1, CT/MR-T2) | QAB/F | 0.4584 | 0.5140 | 0.5545 | 0.5850 | 0.5784 | 0.5840 |
| QS | 0.6893 | 0.6785 | 0.7002 | 0.6939 | 0.6952 | 0.7016 | |
| QU | 0.6146 | 0.4438 | 0.6146 | 0.6331 | 0.6343 | 0.6412 | |
| Q0 | 0.3211 | 0.3158 | 0.3111 | 0.3449 | 0.3458 | 0.3488 | |
| QW | 0.5562 | 0.5851 | 0.5842 | 0.5962 | 0.5977 | 0.5994 | |
| QNMI | 0.6951 | 0.6327 | 0.6536 | 0.7204 | 0.7095 | 0.7575 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Q.; Cai, W.; Xu, S.; Hu, S. MRI Image Fusion Based on Sparse Representation with Measurement of Patch-Based Multiple Salient Features. Electronics 2023, 12, 3058. https://doi.org/10.3390/electronics12143058
Hu Q, Cai W, Xu S, Hu S. MRI Image Fusion Based on Sparse Representation with Measurement of Patch-Based Multiple Salient Features. Electronics. 2023; 12(14):3058. https://doi.org/10.3390/electronics12143058
Chicago/Turabian StyleHu, Qiu, Weiming Cai, Shuwen Xu, and Shaohai Hu. 2023. "MRI Image Fusion Based on Sparse Representation with Measurement of Patch-Based Multiple Salient Features" Electronics 12, no. 14: 3058. https://doi.org/10.3390/electronics12143058
APA StyleHu, Q., Cai, W., Xu, S., & Hu, S. (2023). MRI Image Fusion Based on Sparse Representation with Measurement of Patch-Based Multiple Salient Features. Electronics, 12(14), 3058. https://doi.org/10.3390/electronics12143058