1. Introduction
In recent years, with the development of artificial intelligence technology, object detection [
1] has experienced significant development and has been widely applied as a fundamental task and a research hotspot in the field of computer vision. Object detection has been applied in various domains of human life. For instance, in the field of autonomous driving [
2], it is used to accurately recognize and locate pedestrians, vehicles, and other objects on the road. In the medical field [
3], object detection assists in tasks such as lesion recognition and tumor detection, contributing to diagnosis and healthcare. Additionally, it plays a crucial role in domains such as facial recognition [
4], agriculture [
5], and industry [
6].
Object detection can be classified into single-stage object detection algorithms, represented by YOLO (you only look once) [
7] and SSD (single shot multibox detector) [
8], and two-stage object detection algorithms, represented by RCNN (Region CNN) [
9], Fast RCNN [
10], and Faster RCNN [
11], based on the detection approach. However, mainstream object detection algorithms are often developed and studied using high-quality image datasets with good lighting conditions. As a result, factors related to specific environments may not be adequately considered in practical application scenarios. For example, images may suffer from distortion, inadequate exposure, and other challenges that can affect the performance of object detection algorithms.
Mineral resources serve as a crucial foundation and support for the development of human society. In recent years, the integration of artificial intelligence technology with the mining industry has emerged as a popular research direction [
12] to maintain normal mining operations and to ensure the safety of underground workers. However, the actual environment of underground mines is highly complex, posing various challenges to object detection algorithms, including issues such as image distortion and insufficient exposure mentioned earlier, thereby affecting the performance of object detection algorithms in underground mining settings. To address the challenges posed by low lighting conditions and other environmental factors in underground mines, researchers have proposed hardware-based measures to enhance detection performance, such as using high-power light sources, thermal imaging technology, or cameras with higher sensitivity [
13]. However, these methods currently incur high costs, making it difficult for them to be widely adopted. Therefore, researchers are directing their attention toward proposing or improving object detection algorithms to enhance their performance in low-light scenarios like underground mines.
To mitigate the impact of low-light conditions on object detection performance in specific scenarios, some researchers have made improvements to the network structure of object detection models. For instance, Xiao et al. [
14] argued that mainstream object detection models are designed for normal lighting conditions. Therefore, they proposed a specialized feature pyramid network and contextual fusion network based on the RFB-Net (receptive field block net) model proposed by Liu et al. [
15] to improve object detection performance in low-light scenarios. Li et al. [
16], addressing the challenges of poor illumination and complex environments in underground mines, presented an improved faster R-CNN method for pedestrian detection. They replaced the traditional handcrafted feature engineering approach with a deep convolutional neural network to automatically extract features from images. Additionally, they incorporated feature fusion techniques to enhance the detection performance of pedestrians in underground mines, considering factors such as blurriness, occlusion, and small target sizes. However, these approaches, which solely focus on enhancing the capability of extracting low-light image features at the network structure level, may not be effective under extremely low-lighting conditions. It becomes necessary to consider improving the quality of low-light images themselves, as the illumination intensity significantly influences the performance of object detection tasks.
Low-light image enhancement has been a popular research direction among researchers. In recent years, with the advancement of artificial intelligence technology, several deep learning-based algorithms for low-light image enhancement have emerged. For example, Wei et al. [
17] proposed RetinexNet, a low-light image enhancement network based on Retinex, and Jiang et al. [
18] designed EnlightenGAN, a generative adversarial network with self-attention mechanisms. According to the research conducted by Sobbahi et al. [
19], significant progress has been made in utilizing deep learning methods for low-light image enhancement. They comprehensively compare the impact of various deep learning-based low-light image enhancement algorithms on object detection tasks and summarize that the integration of deep learning techniques with image enhancement can yield positive results to a certain extent. Therefore, some researchers have shifted their focus toward integrating low-light image enhancement algorithms with object detection models. Li et al. [
20] addressed the issue of poor object detection performance in low-light scenarios by combining the perception-sensitive bi-directional similarity (PSB) image enhancement algorithm with the SSD object detection algorithm. This approach effectively improved the detection speed and accuracy of low-light images. Zhang Mingzhen [
21] proposed the dense-YOLO model for pedestrian detection in low-light underground mine scenarios. The model enhanced low-light images using algorithms such as gamma transformation and weighted logarithmic transformation, followed by global denoising. These enhancements were then used as inputs to the object detection network, resulting in improved pedestrian detection in low-light underground scenarios. Xu et al. [
22] proposed a salient object detection model to address the challenges caused by the degradation of low-light images in object detection tasks due to scene depth and environmental lighting. The principle of their approach involves directly embedding the physical lighting model into the deep neural network, resulting in an improved detection performance in low-light environments. In the context of poor lighting conditions in foggy traffic scenes, Qiu et al. [
23] proposed a module called IDOD (AOD + SAIP) that combines the defogging algorithm AOD (an all-in-one network for dehazing and beyond) with the image enhancement algorithm SAIP. They integrated this image processing module, IDOD, with the YOLOv7 detection model for end-to-end joint learning. Their research demonstrates that the integrated approach not only improves the visual quality of the images, but also enhances the performance of object detection. In order to overcome the challenges of insufficient illumination and high noise in low-light environments, Cui et al. [
24] proposed a multitask auto-encoding transformation model (MAET). The model adopts a self-supervised approach to encode and decode realistic illumination-degrading transformations, considering the physical noise model and image signal processing (ISP), in order to learn the intrinsic visual structure. On the basis of the above, it can be integrated with mainstream object detection architectures to achieve improved object detection performance in low-light conditions. However, most of the research mentioned above is to improve detection performance by enhancing image quality through the improvement of image enhancement algorithms. Therefore, the challenge faced by object detection models incorporating low-light image enhancement algorithms is that, in addition to amplifying the desired target features during the enhancement process, there is a possibility of amplifying noise characteristics as well. Therefore, this requires continuous attention from researchers, and perhaps it is worth considering improvements in the object detection algorithms to combine with the low-light image enhancement algorithms.
We propose a low-light adaptive object detection model called DK_YOLOv5, based on the YOLOv5 model. First, the model takes low-light enhanced images as input to achieve relatively better visual effects and amplify the object information and features to some extent. Second, we improve the last layer SPPF (spatial pyramid pooling fast) module of the model’s backbone network to the R-SPPF module, which offers faster inference speed and stronger feature representation. Next, we replace all C3 structures in the backbone network, including the first C3 structure in the neck, with C2f structures. This modification aims to reduce the network’s depth while enriching the gradient information flow in feature extraction. Additionally, the last three C3 modules in the neck are replaced with the proposed C2f_SKA module, which incorporates the attention mechanism SKAttention to fuse multi-scale feature information. This helps the detection model focus more on the target regions during the learning process, thereby reducing the impact of noise introduced by low-light image enhancement algorithms and improving the network’s learning ability. Finally, we replace the detection head of the network with a decoupled head that is more suitable for low-light detection tasks in such environments. This improvement enhances the detection accuracy of the network. Experimental evaluations conducted on the Exdark (exclusively dark) low-light dataset [
25] and the Mine_Exdark low-light dataset, augmented specifically for underground targets, demonstrate that the DK_YOLOv5 model outperforms other models in low-light scenarios and performs well in underground object detection tasks. This confirms the rationality and effectiveness of the proposed improvements and innovations in this paper.
This paper will be structured into six sections. In the introductory
Section 1, we will provide a detailed overview of the research background in low-light environment object detection, survey related low-light image enhancement algorithms, and the existing object detection models. Additionally, we will summarize the relevant improvements of our work. In
Section 2, we will delve into the theoretical foundations starting with an exploration of the YOLO series algorithms, followed by the selection of the baseline model for our research.
Section 3, the related work section, will discuss the current low-light environment object detection datasets, some low-light image enhancement algorithms, and their integration with object detection models to explore their impact on detection performance. Subsequently, in
Section 4, we will provide detailed descriptions of the proposed improvement modules, along with the corresponding network architecture and low-light image enhancement diagram.
Section 5 will focus on the experimental setup, presenting and discussing the experimental results to derive meaningful conclusions. Finally, in
Section 6, we will summarize the contributions of our work, highlight the remaining challenges, and outline future research directions.
2. Theoretical Background
2.1. YOLO Series Algorithms
The YOLO series algorithm has gained significant attention in the field of real-time object detection due to its ability to strike a balance between inference speed and detection accuracy. Since its introduction by J. Redmon et al. [
26] at CVPR (IEEE Conference on Computer Vision and Pattern Recognition) in 2016 with the YOLOv1 model, it has evolved to the latest YOLOv8 version.
Currently, the widely used YOLO series models in real-time object detection include YOLOv5, YOLOv7 [
27], and YOLOv8. YOLOv7 was published by the authors of YOLOv4 [
28] on ArXiv in July 2022. YOLOv5 and YOLOv8 are open-sourced and maintained by Ultralytics. As of the writing of this paper, they have not yet published academic papers on these models, but they continue to maintain and update YOLOv5 and YOLOv8. YOLOv5 has reached a relatively stable version, while YOLOv8 is still undergoing continuous updates and improvements. In terms of computational efficiency and accuracy, YOLOv8 has shown improvements over YOLOv5 and YOLOv7. However, YOLOv5 has advantages in terms of training speed, inference speed, and memory usage, especially in certain applications with mobile devices or limited resources.
Since the release of YOLOv5 v1.0 by Ultralytics in 2020, subsequent updates were made, including version v6.1 in February 2022, v6.2 in August 2022, and v7.0 in November 2022. Considering that after the v6.2 version, the updates focused on expanding classification and instance segmentation tasks based on object detection, YOLOv5 v6.1 is considered a great choice for focusing on object detection tasks, but scientific justification is still required to substantiate this claim.
2.2. Scientific Justification for YOLO Algorithm Selection
Although we have provided a brief overview of the strengths and weaknesses of the YOLO series algorithms, the selection of a specific YOLO version still requires a scientific justification. Therefore, in this section, we will use a table to present a comparative analysis of various models based on initial parameters, computational complexity, and inference speed, aiming to quantitatively assess their respective merits. The comparison is shown in
Table 1.
We selected various YOLO models commonly used for evaluating and comparing models. The comparison includes parameters, computational complexity (GFlops), and FPS (frames per second), along with the mAP (mean average precision) accuracy on the Exdark dataset as shown in
Table 2. These parameters represent the model’s parameter count, computational resource consumption, and frames per second during inference, combined with the mAP metric to measure its accuracy on the Exdark dataset.
It can be observed that among these models, YOLOv5s achieves the highest FPS while using the fewest parameters and computational resources. It also demonstrates commendable accuracy. Therefore, considering the potential application of real-time object detection in low-light underground scenarios, where a balance between accuracy and speed is crucial, we chose the YOLOv5s model from the YOLOv5 v6.1 version as our baseline.
2.3. YOLOv5 Algorithm Model
YOLOv5 is one of the classic object detection algorithms in the YOLO series. Although it has slightly lower detection accuracy compared to subsequent versions of YOLO, it stands out for its unique advantages of fast inference speed, lightweight design, and quick deployment in specific scenarios.
YOLOv5 v6.1 is a newer and more stable version. Its core idea is to transform the object detection task into a regression problem, where the network predicts the bounding boxes and classes of various objects. Numerous improvements have been made in model architecture, data augmentation, and post-processing strategies, resulting in enhanced performance and optimized detection efficiency. YOLOv5 provides different scales of models, including YOLOv5n, YOLOv5s, and YOLOv5l. These versions share a similar network structure, with the only difference being the depth of the network to meet the accuracy and real-time requirements of different application scenarios.
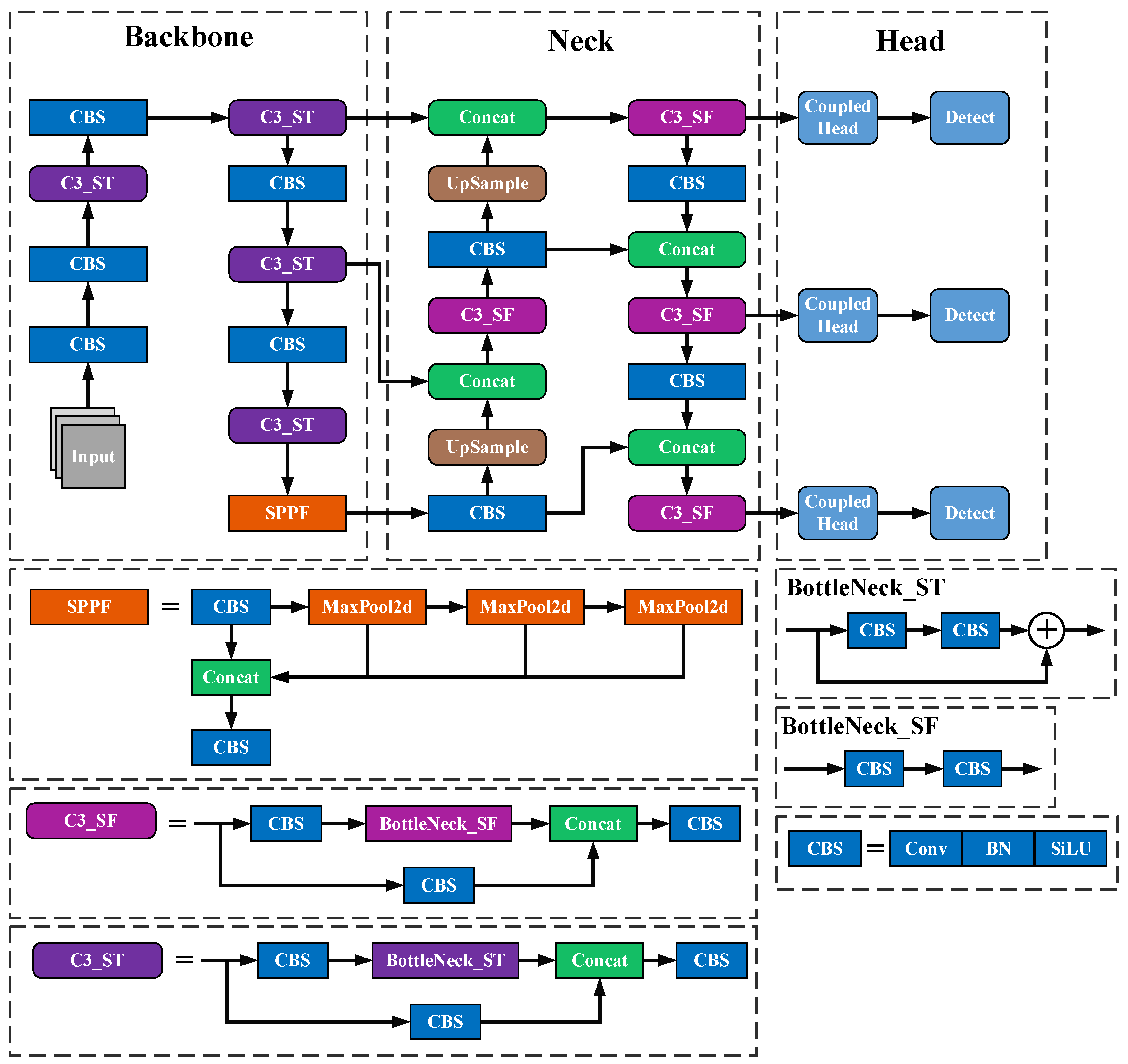
Among them, YOLOv5s is the model that strikes the best balance between detection accuracy and real-time performance. Its network structure, as shown in
Figure 1, consists of three main parts: the backbone network, neck, and detection head.
The YOLOv5 algorithm incorporates the Mosaic data augmentation at its input, which combines four different images together to enrich the training dataset. Moreover, to enable the model to adapt to various object detection datasets, the authors employ an algorithm to automatically compute the optimal anchor box values for each dataset. Additionally, the input images are adaptively scaled to the desired size, enhancing the inference speed of the model.
YOLOv5 utilizes Darknet53 as its backbone network. The C3 module is employed to replace the CSP (cross stage partial network) module used in earlier versions, which plays a crucial role in reducing the number of network parameters and improving both training and inference speed. Furthermore, YOLOv5 introduces the SPPF module to replace the original SPP module, maintaining the same level of effectiveness while further enhancing speed.
In the neck network, YOLOv5 adopts a PAN (path aggregation network) structure to fuse the multi-scale feature maps extracted from the backbone network. This results in a series of feature maps with varying scales and semantic information, thereby increasing the network’s ability to express features.
The detection head module of YOLOv5 is primarily responsible for multi-scale object detection based on the multi-scale feature maps obtained from the neck network. Currently, it still utilizes a coupled head. Moreover, compared to earlier versions of YOLO, YOLOv5 employs the GIoU as the loss function for bounding boxes, optimizing their positions and sizes.
3. Related Work
3.1. About the Low-Light Object Detection Datasets
In the field of object detection under low-light conditions, several well-known datasets have been widely applied, including NightOwls, Exdark, CityPersons, and DarkFace. These datasets share the common goal of providing image samples under low-light environments for training and evaluating low-light object detection algorithms.
The NightOwls dataset primarily focuses on pedestrian detection at night, capturing diverse images in urban nighttime scenes. It encompasses various object categories such as pedestrians, vehicles, and bicycles, along with complex background scenarios.
The Exdark dataset is specifically designed for low-light object detection. Its strength lies in providing diverse low-light images covering 12 object categories and a variety of dark scenes, effectively simulating real-world low-light conditions. Its diverse low-light images and multiple object categories make it a significant benchmark for studying object detection algorithms under low-light conditions.
The CityPersons dataset is dedicated to pedestrian detection in urban scenes. It offers challenging urban environment images, including different lighting conditions during the day and night. The aim of the CityPersons dataset is to encourage researchers to develop pedestrian detection algorithms suitable for real urban scenarios, providing detailed bounding box annotations.
The DarkFace dataset is specifically tailored for face detection in low-light environments. It includes face images captured under dim lighting conditions and serves as a benchmark for evaluating face detection algorithms under low-light situations. The dataset’s distinctive feature is its inclusion of complex lighting variations found in real-world scenarios, enabling algorithms to accurately detect and localize faces under low-light conditions.
Although these datasets provide samples in low-light conditions, they focus on different application scenarios, such as pedestrian detection or face detection. Therefore, to comprehensively improve the detection performance in low-light environments, it is preferable to select datasets that provide more diverse scenes and object classes for evaluation.
Based on the aforementioned reasons, we have chosen the Exdark dataset as our primary evaluation dataset. The Exdark dataset not only provides a rich collection of samples under low-light conditions but also encompasses diverse object categories and scenes. It covers 12 object categories and a variety of low-light scenes, allowing for a comprehensive assessment of algorithm robustness and accuracy in low-light conditions. Furthermore, due to the diversity of object categories and scenes in the Exdark dataset, we have the opportunity to expand the dataset by adding our own application-specific image data. This enables us to incorporate the desired application scenarios into the evaluation process, thereby enhancing the practicality and relevance of low-light object detection algorithms. Therefore, based on its advantages, we have chosen it as the primary dataset for our research.
3.2. About the Low-Light Image Enhancement Algorithms
In selecting low-light image enhancement algorithms, we considered several key factors. First, through literature review and research, we identified widely cited and representative algorithms for low-light image enhancement, including MBLLEN [
29], RetinexNet, KinD [
30], Zero-DCE (zero-reference deep curve estimation) [
31], EnlightenGAN, Zero-DCE++ [
32], URetinexNet4 [
33], SCI (self-calibrated illumination) [
34], and SGZ (semantic-guided zero-shot) [
35]. These algorithms have received significant attention in both academia and industry.
Second, we compared the technical approaches of these algorithms and categorized them into different techniques based on classical Retinex theory, zero-shot learning, and generative adversarial network (GAN) learning. Given the importance of diverse algorithm selection, we aimed to cover these different technical approaches.
Therefore, we chose several representative algorithms to combine with object detection algorithms and observe their impact on object detection performance. The specific algorithms selected include RetinexNet, which is based on classical Retinex theory, Zero-DCE, Zero-DCE++, and SGZ, which are based on zero-shot learning, as well as EnlightenGAN, which utilizes GAN learning. These algorithms have achieved significant results in previous research and demonstrate diverse technical strategies and practical application potential. By combining these low-light image enhancement algorithms with object detection models, we can make a fair comparison of the impact of different enhancement algorithms based on different approaches, avoiding biases resulting from selecting algorithms with the same technical approach.
3.3. Incorporating Low-Light Image Enhancement Algorithm into YOLOv5
In recent years, researchers have discovered the advantages of using low-light image enhancement algorithms to address object detection in low-light environments, including low cost, applicability to various environments, and high flexibility. However, it is essential to consider the potential negative effects of such algorithms as well. In order to investigate the impact of low-light image enhancement algorithms on object detection algorithms, we selected several algorithms, namely EnlightenGAN, SGZ, RetinexNet, Zero-DCE, and Zero-DCE++, to enhance the ExDark dataset. In
Section 5, we provide a detailed description of the ExDark dataset and its data partition. Here, we first trained the YOLOv5 model on the original ExDark training set (4800 images) and validated it on the original ExDark validation set (2563 images) to obtain the detection performance of the YOLOv5 model on this dataset. Next, to explore the impact of low-light image enhancement algorithms on object detection performance, we applied these several low-light image enhancement algorithms to the ExDark validation set, resulting in enhanced validation sets corresponding to each algorithm.
Figure 2 presents examples of the enhancement effects of these algorithms on the validation set. From
Figure 2, we can observe that enhancement algorithms based on Retinex theory, zero-shot learning methods, and generative adversarial network learning methods exhibit different effects in image enhancement. Clearly, enhancement algorithms based on the latter two methods can achieve relatively better visual effects.
As mentioned earlier, we trained the YOLOv5 model on the original ExDark training set and applied various image enhancement algorithms to the ExDark validation set to create corresponding enhanced validation sets. Subsequently, we used the trained model to perform detections on both the original ExDark validation set and each enhanced validation set to obtain the mAP values for each set when evaluated with the original YOLOv5 model. The two columns in
Table 2 represent mAP 0.5 and mAP 0.5:0.95, respectively. They measure the mean average precision (mAP) at an IoU threshold of 0.5 and across a range of IoU thresholds from 0.5 to 0.95, serving as metrics to evaluate the object detection performance after incorporating the low-light image enhancement algorithms. The complete results are presented in
Table 2.
Based on the results shown in
Figure 2 and
Table 2, it can be observed that although combining YOLOv5 with low-light image enhancement algorithms can achieve relatively better visual effects, it did not yield the expected improvement in terms of object detection performance. Most of the selected enhancement algorithms did not contribute to an improvement in detection performance, and even the EnlightenGAN algorithm only achieved a marginal increase of 0.3% in mAP. This indicates that the noise introduced during the enhancement process by low-light image enhancement algorithms cannot be overlooked. Therefore, for the YOLOv5 model, while integrating low-light image enhancement algorithms to obtain enhanced images that achieve relatively better visual effects, there is a need for model improvements to enhance its ability to extract meaningful features and mitigate the impact of noise on detection performance, thus enhancing the overall object detection performance.
Therefore, it is highly necessary to analyze the first-layer feature maps of various images input to the models, using the EnlightenGAN enhancement algorithm as an example, which brings marginal improvement in object detection performance. Specifically, we compare the first-layer feature map of the original image input to the YOLOv5 model, the first-layer feature map of the image input enhanced by the EnlightenGAN algorithm to the YOLOv5 model, and the first-layer feature map of the image input enhanced by the EnlightenGAN algorithm to the DK_YOLOv5 model. The corresponding feature maps are shown in
Figure 3.
As shown in
Figure 3, from left to right, we have the first-layer feature maps of the original image input to the YOLOv5 model, the image enhanced by the EnlightenGAN algorithm and input to the YOLOv5 model, and the image enhanced by the EnlightenGAN algorithm and input to the DK_YOLOv5 model. Analyzing the comparison between
Figure 3a,b, we can observe that
Figure 3b represents the first-layer feature map of the original YOLOv5 model after image enhancement. It can be seen that
Figure 3b contains richer target features around the person compared to
Figure 3a. Additionally, the background and other noise features in
Figure 3b are amplified and become more pronounced. Similarly, comparing
Figure 3b with
Figure 3c, both
Figure 3b,c undergo image enhancement. However,
Figure 3c represents the first-layer feature map input to our proposed model. It can be observed that, compared to
Figure 3b,c maintains the amplified target features while reducing the background noise features to some extent.
4. Methods
We employed YOLOv5 as the detection model and found that its performance in directly detecting objects in low-light conditions was subpar. Even when using low-light enhanced image data as input to the network, the detection performance showed limited improvement and, in some cases, even declined. To ensure that the enhanced images achieve relatively better visual effects, while effectively improving the object detection performance, it is crucial to improve the network architecture of the YOLOv5 detection model. This enhancement aims to improve its feature extraction capabilities for low-light conditions and noise-enhanced data, reducing the impact of insufficient lighting and noisy features on the object detection performance, thereby meeting the requirements for object detection in low-light scenarios such as underground mine environments.
4.1. SKAttention-Based C2f_SKA Module
YOLOv5 network utilizes multiple C3 structures to increase network depth and receptive field, as shown in
Figure 1. Each C3 structure consists of three standard convolutional modules and multiple residual modules. However, in low-light conditions, the input image quality is poor, and the C3 module fails to extract effective low-level features and reduce the impact of insufficient lighting and noisy features, consequently affecting the object detection performance.
To address these issues, this paper draws inspiration from the design principles of the C2f structure and proposes a feature learning module called C2f_SKA based on the attention mechanism of SKNet [
36]. The C2f_SKA module enhances the existing convolutional branch in the C2f module by incorporating a channel attention mechanism branch. It performs multi-scale fusion with the features learned by the residual structure, allowing for the acquisition of more informative low-level features and gradient flow information while reducing the network’s depth. This improvement increases the network’s feature learning capability. The structure of the proposed C2f_SKA module is illustrated in
Figure 4.
The C2f_SKA module first splits the input convolution branch into two identical branches. One branch is fed into the residual module for residual feature learning and multi-scale feature fusion. Additionally, a new feature learning branch with attention mechanism is introduced to enable the network to extract low-level features of the target region effectively while reducing the influence of noise. This branch is then fused with the other convolution branch and the residual features at multiple scales, thereby significantly enhancing the detection capability of the network.
In
Figure 4, the size of the feature maps in the Conv1 section is denoted as
, where
represents the batch size,
represents the number of channels,
represents the height, and
represents the width. After the split operation, the feature maps of the two convolution branches are represented as
. One convolution branch goes through
residual module branches and one SKAttention branch, which performs attention, and is concatenated with the other convolution branch to form the input of Conv2. Therefore, the size of the feature maps in the Conv2 section is
.
The SKAttention part takes the output
of Conv1 as input and splits it into multiple branches with different convolution kernel sizes, as shown in
Figure 5, where
and
are two example branches.
Then, the feature maps of
and
are element-wise summed to obtain the feature map
. Subsequently, a global average pooling is applied to
to generate channel-wise statistics. The calculation formula is as follows:
where
and
represent the width and height of the feature map, respectively, and
and
indicate their corresponding spatial feature positions. By utilizing this equation, the channel-wise statistics of
, denoted as
, are calculated. Following that, a fully connected layer is employed to map the original c-dimensional information to a z-dimensional space. It is calculated using the following equation:
here,
denotes the ReLU activation function,
represents batch normalization,
d corresponds to the dimension of features after the fully connected layer, and
W has a dimension of
, while
has a dimension of
. Following this,
is linearly transformed back to the original c-dimensional space, and a softmax normalization is applied to obtain weight vectors for each channel. These weight vectors are multiplied with their respective
and
, resulting in the multiplied modules
and
. The information fusion of
and
yields the final module
, which encompasses multi-scale information.
In response to the challenges presented by low-light environments, such as underground mine scenarios, we propose a solution by replacing the C3 modules in the backbone network and the first C3 module in the neck part of YOLOv5 with C2f modules. This improvement not only reduces the network’s depth but also enhances the backbone network’s capability to extract gradient information flow. To further improve the network’s focus on crucial information in the target region and mitigate the impact of noise, the last three C3 modules in the neck part are replaced with the newly proposed C2f_SKA modules. Finally, adjustments are made to the fusion layers of concatenation at the 19th and 22nd layers of the network, allowing them to, respectively, concatenate with the first C2f layer in the neck part and the last layer of the backbone network.
4.2. Improving the SPPF Module
YOLOv5 introduces a novel structure called SPPF based on SPP [
37]. SPPF retains the ability of the SPP structure to fuse local and global features while improving the model’s speed. The convolutional module in SPPF utilizes SiLU as the activation function, defined by the following equation:
In the equation, represents the input of the function, and represents the sigmoid activation function with as its input.
The activation function, SiLU, possesses several desirable properties, including being unbounded with a lower bound and exhibiting smooth non-monotonic behavior, making it perform well in deeper networks. However, SiLU also has some clear disadvantages. In extreme cases of excessively large or small data, it may suffer from gradient vanishing or exploding issues. Additionally, the trade-off between the computational overhead introduced by SiLU and the corresponding performance improvement needs to be further balanced.
When using images from low-light environments, such as those encountered in underground mine scenarios, as input to the network, extreme pixel values are likely to be encountered. Additionally, the inference speed of the model needs to be taken into consideration. Therefore, to address this issue, this paper replaces the activation function in the convolutional modules of SPPF with ReLU, defined by the following equation:
here,
represents the input to the function.
The ReLU activation function can be regarded as a piecewise function and exhibits favorable computational properties during neural network training. It further enhances the inference speed of YOLOv5 compared to the original SiLU activation function. Additionally, in the case of input images from low-light conditions such as underground mine scenarios, extreme values are likely to occur. By replacing the SiLU activation function with ReLU in the SPPF module, the proposed approach significantly mitigates the issues of gradient explosion or vanishing gradients caused by extreme inputs. This improvement ensures the retention of the SPPF module’s capability to integrate local and global features. The modified SPPF module is referred to as R-SPPF, as illustrated in
Figure 6.
4.3. Introducing Decoupled Head
The detection head used in the YOLOv5 algorithm adopts a coupled head structure, where the weight parameters are shared between the classification and regression tasks in the object detection task. However, it is evident that these two tasks conflict with each other. Therefore, inspired by the drawbacks of the coupled head structure, Ge et al. [
38] proposed a decoupled detection head, where the coupled head structure is redesigned into a decoupled head structure. In the decoupled head structure, the classification and regression tasks are separately processed using different branch heads. This decoupling approach effectively enhances the detection performance of the object detection network. The structures of the coupled head and the decoupled head are illustrated in
Figure 7.
From the diagram, it can be observed that the coupled head structure utilizes the same weight parameters to process both the classification and regression tasks using the feature map from the upper layers. The decoupled head structure separates the classification and regression tasks, employing different network branches with distinct weight parameters for each task. Furthermore, within the regression task branch, it further divides the tasks into regressing the target position information and regressing the confidence. This approach improves the detection performance of the model.
Based on the analysis above and considering the issue of low detection accuracy in underground and low-light conditions, it is more reasonable to use the decoupled head structure. Therefore, in this paper, we replaced the coupled head structure in the YOLOv5 algorithm with the decoupled head structure, effectively enhancing the detection performance of the network.
4.4. Overall Network Structure
We propose an object detection model called DK_YOLOv5, which is based on YOLOv5 and designed for low-light environments. The overall network structure is illustrated in
Figure 8.
In this network, the SPPF module in the last layer of the backbone network is improved to R-SPPF module. This modification enhances the model’s inference speed while achieving the fusion of local and global features, thereby enhancing the feature representation capability. Furthermore, all C3 modules in the backbone network and the first C3 module in the neck are replaced with C2f modules. This not only reduces the network depth but also enriches the extraction of gradient information in the backbone network. Additionally, the last three layers of C3 modules are replaced with C2f_SKA modules proposed in this paper. By incorporating the attention mechanism, SKAttention, these modules integrate multi-scale feature information and focus more on the information features of the target area, thereby reducing the impact of noise and enhancing the network’s ability to filter out relevant information. Finally, the detection head of the network is replaced with a decoupled head that is more suitable for object detection tasks. By separately learning the classification and regression tasks, the network’s detection performance can be effectively improved.
In regard to the enhancement part in the overall network architecture, it can be any low-light image enhancement algorithm. Based on the
Section 3 and the data and conclusions presented in the
Section 5, we have chosen to incorporate the EnlightenGAN enhancement algorithm in this context, as depicted in
Figure 9.
EnlightenGAN is an image enhancement algorithm that utilizes a generative adversarial network framework. As shown in
Figure 9, it consists of two main components: a generator network and a discriminator network. The generator network takes low-light images as input and aims to generate their enhanced versions. The discriminator network acts as a binary classifier to distinguish between the generated enhanced images and real high-quality images.
5. Experiment and Results Discussion
5.1. Experimental Environment and Parameter Configuration
The experiments were completed based on the Windows 10 operating system and the Pytorch framework version 1.9.0. The CPU model of our equipment is Intel i5-12400F CPU, the GPU model is GeForce GTX 3060 12G. The software environment included CUDA 11.1 and CuDNN 8.0, the Python version was 3.7.2. The experiments were conducted using the PyCharm IDE 2022.2.3 (Professional Edition).
The training parameters have a direct impact on the convergence speed and generalization ability of the model. Therefore, to find a relatively balanced set of training parameters during the experimental process, it is necessary to continuously adjust these parameters, striking a balance between convergence speed and the prevention of underfitting and overfitting. In the experimental process, we employed a controlled variable approach to iteratively adjust these parameters, including selecting optimization strategies, fine-tuning the initial learning rate, choosing pretraining weights, and adjusting momentum. Additionally, we took hardware factors into consideration, such as batch size and the number of workers. We evaluated the convergence speed and generalization ability by analyzing loss graphs and the number of training epochs required for convergence. Based on these evaluations, we determined the following parameter settings: We utilized stochastic gradient descent (SGD) as the optimization strategy with an initial learning rate of 0.01 and a momentum of 0.937. Mosaic data augmentation was applied during the training process with eight workers. The batch size was set to 16, and the number of training epochs was set to 80.
5.2. Dataset Introduction
In order to evaluate the effectiveness of the proposed algorithm in low-light conditions, the publicly available Exdark dataset is used as the base dataset. This dataset consists of a total of 7363 images captured in low-light environments. It comprises 12 common object classes, including bicycles (652 images), boats (679 images), bottles (547 images), buses (527 images), cars (638 images), cats (735 images), chairs (648 images), cups (519 images), dogs (801 images), motorbikes (503 images), people (609 images), and tables (505 images). To create a balanced training set, 400 images were selected from each class, resulting in a total of 4800 images. The remaining 2563 images were allocated for validation purposes.
To enable the model to perform object detection tasks in low-light environments in underground mines, we further expanded the Exdark dataset by adding 1716 additional images collected from Shandong Jiaojia Gold Mine and the internet. These images include various object classes such as underground track equipment (686 images), non-track equipment (583 images), and signs (447 images). Out of these images, 1317 were used to expand the training set of the Exdark dataset. Among them, 516 images were added for the underground track equipment class, 478 images for the non-track equipment class, and 323 images for the signs class. The remaining 399 images were used to expand the validation set. As a result, the expanded dataset consists of 6117 images for training and 2962 images for validation. This expanded dataset is referred to as Mine_Exdark, and
Figure 10 illustrates some examples from the expanded dataset. The division ensures that the dataset captures a representative distribution of the various object classes, facilitating comprehensive training and evaluation of the proposed algorithms. The primary experiments in this paper were conducted on the expanded dataset to validate the effectiveness of the proposed improvements and innovative methods.
5.3. Training mAP and Loss
During the training process of the model, the mAP and the validation loss of the detection objects are shown in
Figure 11.
From
Figure 11a, it can be observed that the proposed model consistently achieves higher mAP during the training process compared to YOLOv5s. The improvement in mAP values provides preliminary evidence that our proposed model achieves higher detection accuracy compared to the YOLOv5s model. This confirms the effectiveness of the enhancements we proposed in improving the detection performance. In
Figure 11b depicting the loss, it can be seen that both our model and YOLOv5s exhibit a decreasing trend and have converged after 80 epochs of training. However, our model shows a faster convergence rate and a steeper decrease in loss. This demonstrates that our proposed model possesses better learning and optimization capabilities, enabling it to adapt to the training data in an efficient manner compared to YOLOv5s.
Based on the trends of these two values, it can be initially concluded that our proposed DK_YOLOv5 model converges faster and achieves higher detection accuracy compared to the original YOLOv5s model. Meanwhile, further experiments are needed to validate its performance comprehensively.
5.4. Experimental Results Discussion and Comparison
In the experimental section, precision (P), recall (R), and mean average precision (mAP) were used as evaluation metrics to assess the performance of the detection models. To provide a comprehensive evaluation of the model’s performance, we utilized mAP at an IoU threshold of 0.5 (mAP 0.5) and mAP across a range of IoU thresholds from 0.5 to 0.95 (mAP 0.5:0.95).
To validate the improved feature extraction capability of the proposed DK_YOLOv5 model in low-light environments, a comparison was conducted among DK_YOLOv5, multitask AET (MAET) proposed in reference [
24], and the current mainstream YOLO single-stage object detection models. This comparison involved training and result analysis on the Mine_Exdark dataset. The detection results of various object detection models on this dataset are presented in
Table 3.
From the experimental results in
Table 3, it can be observed that without incorporating low-light image enhancement algorithms, the detection performance of different models on the low-light environment dataset Mine_Exdark varies. Overall, the proposed improved model DK_YOLOv5 exhibits the highest detection performance, achieving precision (P) of 0.750, recall (R) of 0.622, mAP 0.5:0.95 of 0.470, and mAP 0.5 of 0.715 across all evaluation metrics. Meanwhile, it can be observed that the MAET method proposed in reference [
24] has the lowest mAP 0.5 and mAP 0.5:0.95 values in this dataset, which are 59.2% and 35.1%, respectively. Looking at the results in
Table 3, it can be seen that using YOLOv6s and YOLOv7 models on the Mine_Exdark dataset even results in lower mAP 0.5 and mAP 0.5:0.95 compared to the YOLOv5s model, indicating their inferior performance in the specific application environments of this paper. The latest YOLOv8s model demonstrates better detection performance than the previous three models. The proposed improved model DK_YOLOv5 exhibits better performance improvements across different IOU thresholds compared to other comparative models. It achieves a mAP 0.5 of 71.5%, outperforming the YOLOv8s model by 3.2% and demonstrating a 4.4% enhancement over the original YOLOv5s model. Additionally, its mAP 0.5:0.95 of 0.470 surpasses the experimental results of the previous models. This demonstrates that even without employing image enhancement algorithms to amplify features, the proposed improved algorithm exhibits better feature extraction capability in low-light environments compared to these algorithms, thus validating the effectiveness of the proposed improvement algorithm.
Furthermore, based on the conclusions drawn from the exploration of the impact of low-light image enhancement algorithms on object detection performance, we select two effective enhancement algorithms, namely EnlightenGAN and Zero_DCE++, to combine with each object detection model in
Table 3. This is done to validate the ability of the proposed DK_YOLOv5 model to better suppress negative features introduced by image enhancement algorithms, such as noise, while simultaneously enhancing the feature extraction capability in target regions. The detection results of each combined model are presented in
Table 4.
From
Table 4, it can be observed that the detection performance of various YOLO detection algorithms on the low-light environment dataset is improved when combined with the EnlightenGAN image enhancement algorithm, compared to the models without the enhancement algorithm in
Table 3. However, after applying the Zero_DCE++ enhancement, the performance of the models slightly decreases. This demonstrates that combining the detection models with the EnlightenGAN algorithm in the low-light dataset helps amplify the target features in the images. Among them, the proposed model combined with EnlightenGAN achieves a mAP 0.5 of 71.9%, which is higher than the previous results. It exhibits a 4.4% improvement over the combination with YOLOv5s and a 3.5% improvement over the combination with YOLOv8s. The results of mAP 0.5:0.95 are also higher than the previous combination. This validates that the proposed DK_YOLOv5 model, when combined with low-light image algorithms, effectively suppresses the noise introduced by the enhancement algorithm and enhances the feature extraction capability in the target regions, resulting in improved detection performance.
5.5. Ablation Experiments
To investigate the impact of various improvements and innovations in the proposed DK_YOLOv5 model on detection performance, ablation experiments were conducted on the Exdark and Mine_Exdark datasets. These experiments aimed to validate the rationality and effectiveness of the proposed modules in different low-light datasets. The results of these experiments are presented in
Table 5 and
Table 6. The symbol √ is used to denote the utilization of the module, while its absence indicates non-utilization.
Based on the experimental results shown in
Table 5 and
Table 6, it can be observed that the proposed improvements and innovations to the YOLOv5 model effectively enhance the object detection capability across different datasets. By replacing the coupled head of YOLOv5 with a decoupled head, the mAP 0.5 improves from 64.2% to 66.9% on the Exdark dataset and from 67.1% to 68.2% on the Mine_Exdark dataset, demonstrating that the decoupled head is a more suitable choice for object detection models.
Furthermore, replacing the C3 module with the C2f module, enhanced to the C2f_SKA module, results in a performance improvement of 3.4% and 2.0% on the two datasets, respectively. This enhancement enhances the model’s capability to extract effective features from low-light images and suppresses the interference of noise features, thereby achieving better object detection performance. The improvement in the SPPF module further enhances the accuracy by 0.9%, contributing to the overall detection performance of the network.
By combining these improved modules, the experimental results on different low-light datasets consistently demonstrate improved accuracy compared to the baseline models. This validates the rationality and effectiveness of the proposed improvements and innovations, as well as their complementary advantages when used in combination. The final mAP 0.5 reaches 69.8% and 71.5% on the two datasets, respectively, representing an improvement of 5.6% and 4.4% compared to the original model.
5.6. Comparison of Multi-Object Detection Results
To visually compare the performance difference between the proposed DK_YOLOv5 model and the original YOLOv5 model for object detection in low-light scenarios, we selected several representative images to compare the effects of the models, as shown in
Figure 12.
Figure 12a represents the original image captured in a low-light environment,
Figure 12b represents the image enhanced by EnlightenGAN,
Figure 12c represents the image detected by the original YOLOv5 model, and
Figure 12d represents the image detected by the proposed DK_YOLOv5 model. By analyzing the confidence levels and the number of detected objects in the images, it can be observed that the DK_YOLOv5 model proposed in this paper, combined with the image enhancement algorithm, effectively improves the accuracy of object detection in low-light environments. This verifies the effectiveness of our approach in practical applications.
6. Conclusions
Aiming at the challenges of existing object detection models in low-light environments and the impact of noise introduced by low-light image enhancement algorithms, we propose an improved object detection model, DK_YOLOv5, adapted to low-light conditions based on the YOLOv5 model. The proposed model takes low-light enhanced images as input, amplifying the object features while achieving relatively better visual effects. The SPPF module in the backbone network is replaced with the R-SPPF module, which offers faster inference speed and stronger feature representation. Additionally, all C3 modules are substituted with C2f modules, further improved as C2f_SKA modules, to reduce the noise introduced by the low-light enhancement algorithm and enhance the network’s learning capabilities by enriching the gradient information flow while reducing network depth. The detection head of the network is replaced with a more effective decoupled head to adapt to object detection tasks in low-light scenarios. Furthermore, to adapt the model for object detection tasks in underground low-light scenarios, we expanded the Exdark dataset by including underground mine target images. Experimental results demonstrate that the proposed DK_YOLOv5 model achieves higher detection accuracy in low-light conditions compared to other models and performs well in object detection tasks in underground mine scenarios. Although our work has achieved certain results, there are still some issues that need further research and investigation. Under extremely poor lighting conditions, excessive image noise leads to poor image quality and the loss of significant details, imposing higher requirements on the image enhancement algorithms. Additionally, there is a relative scarcity of low-light scenarios object detection datasets, making it necessary to further expand the relevant datasets for research and application. Therefore, in future work, we will continue to explore the algorithmic aspects by optimizing the image enhancement algorithms and considering the integration of other methods, such as image denoising, to enhance image quality. Furthermore, we will persist in improving the object detection model to enhance its detection performance in low-light environments. Simultaneously, we will continue to collect low-light environment datasets, particularly focusing on underground scenes, that are relevant to our research. Our future plan involves integrating the image enhancement algorithm into the object detection model to create a unified system, enabling further improvements that would allow its deployment on mobile devices. These works will contribute to further refining the existing problems and providing more reliable solutions for practical applications.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}