
Research on a Knowledge Graph Embedding Method Based on Improved Convolutional Neural Networks for Hydraulic Engineering

Abstract
:1. Introduction
- The integration of spatial location feature information in the embedding representation of entity relations enhances the representation of water knowledge;
- It proposed the ConvMVD model, which utilizes multi-scale dilated convolution for high and low level feature interaction, resulting in richer semantic information and more reasonable entity-relationship embedding representation;
- The ConvMVD model was applied to the hydraulic engineering dataset, and the experimental results showed that the model performed significantly better than other representative baseline methods in the linkage prediction task.
2. Related Work
2.1. Convolutional Neural Networks
2.2. Dilated Convolution
2.3. Knowledge Graph Embedding
- The model based on translation distance treats the relationship as a translation from the head entity to the tail entity in vector space, which has the features of high computational efficiency and wide application but, compared with the neural network-based and deep learning methods, it still needs to be improved in semantic feature extraction and learning;
- The bilinear model measures the similarity between entities and relationships by mapping them into a low-dimensional vector space and using bilinear functions. Its simple form is easy to implement, but its weak expressiveness limits its application in modeling complex relationships;
- The neural network-based model is to use different neural network methods to complete the feature representation of entities and relations, and is then used for inference prediction of the knowledge triad. Due to its greater advantages in semantic feature learning and extraction, it has become the mainstream research direction of current knowledge graph embedding models.
3. Materials and Methods
3.1. Problem Formulation
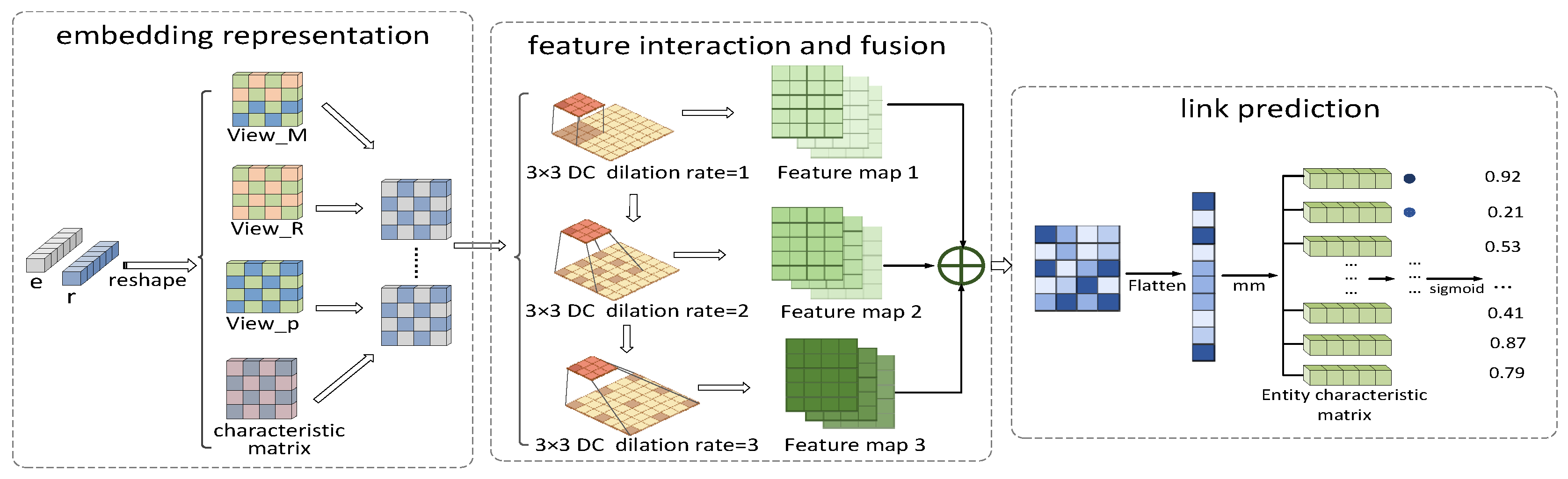
3.2. ConvMVD
3.2.1. Embedding Representation
- (1)
- Characteristic matrix
- (2)
- Spatial transformation view
3.2.2. Feature Interaction and Fusion
3.2.3. Scoring Functions
4. Experiment
4.1. Experimental Setting
4.1.1. Dataset
4.1.2. Hyperparameter Setting
4.1.3. Evaluation Indicators
4.2. Experimental Results and Analysis
4.2.1. Link Prediction Experiments
4.2.2. Ablation Experiments
4.2.3. Hyperparameter Optimization Experiment
5. AI-Based Formal Methods for Verification
- Automated specification and property generation: utilizing methods like machine learning, automatic learning and generation of formal specifications and properties can be achieved from existing system behavior data;
- Intelligent verification tools: developing intelligent verification tools using natural language processing and knowledge representation and reasoning techniques enables non-experts to easily apply formal methods for system verification;
- Efficient verification algorithms: improving the verification algorithms of formal methods through the application of machine learning and optimization techniques to enhance verification efficiency and accuracy;
- Reinforcement of formal verification: integrating techniques such as reinforcement learning to automate the formal verification process, enhancing the robustness and adaptability of verification.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, X. Knowledge graph construction and application in geosciences: A review. Comput. Geosci. 2022, 161, 105082. [Google Scholar] [CrossRef]
- Rondón Díaz, J.D.; Vilches-Blázquez, L.M. Characterizing water quality datasets through multi-dimensional knowledge graphs: A case study of the Bogota river basin. J. Hydroinform. 2022, 24, 295–314. [Google Scholar] [CrossRef]
- Yan, J.; Lv, T.; Yu, Y. Construction and recommendation of a water affair knowledge graph. Sustainability 2018, 10, 3429. [Google Scholar] [CrossRef] [Green Version]
- Duan, H.; Han, K.; Zhao, H.; Jiang, Y.; Li, H.; Mao, W. Research on construction of comprehensive knowledge map of water conservancy. J. Hydraul. Eng. 2021, 52, 948–958. [Google Scholar]
- Liu, X.; Lu, H.; Li, H. Intelligent generation method of emergency plan for hydraulic engineering based on knowledge graph–take the South-to-North Water Diversion Project as an example. LHB 2022, 108, 2153629. [Google Scholar] [CrossRef]
- Ye, X.; Wang, S.; Lu, Z.; Song, Y.; Yu, S. Towards an AI-driven framework for multi-scale urban flood resilience planning and design. Comput. Urban Sci. 2021, 1, 11. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Yang, S.; Yoo, S.; Jeong, O. DeNERT-KG: Named entity and relation extraction model using DQN, knowledge graph, and BERT. Appl. Sci. 2020, 10, 6429. [Google Scholar] [CrossRef]
- Al-Moslmi, T.; Ocaña, M.G.; Opdahl, A.L.; Veres, C. Named entity extraction for knowledge graphs: A literature overview. IEEE Access 2020, 8, 32862–32881. [Google Scholar] [CrossRef]
- Geng, Z.; Zhang, Y.; Han, Y. Joint entity and relation extraction model based on rich semantics. Neurocomputing 2021, 429, 132–140. [Google Scholar] [CrossRef]
- Shen, T.; Zhang, F.; Cheng, J. A comprehensive overview of knowledge graph completion. Knowl.-Based Syst. 2022, 255, 109597. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015. [Google Scholar]
- Yang, B.; Yih, W.-T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Agrawal, N.; Talukdar, P. Interacte: Improving convolution-based knowledge graph embeddings by increasing feature interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Zhou, Z.; Wang, C.; Feng, Y.; Chen, D. JointE: Jointly utilizing 1D and 2D convolution for knowledge graph embedding. Knowl.-Based Syst. 2022, 240, 108100. [Google Scholar] [CrossRef]
- Vu, T.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A capsule network-based embedding model for knowledge graph completion and search personalization. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Jiang, X.; Wang, Q.; Wang, B. Adaptive convolution for multi-relational learning. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Verstraete, D.; Ferrada, A.; Droguett, E.L.; Meruane, V.; Modarres, M. Deep learning enabled fault diagnosis using time-frequency image analysis of rolling element bearings. Shock Vib. 2017, 2017, 5067651. [Google Scholar] [CrossRef] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Zafar, A.; Aamir, M.; Mohd Nawi, N.; Arshad, A.; Riaz, S.; Alruban, A.; Dutta, A.K.; Almotairi, S. A Comparison of Pooling Methods for Convolutional Neural Networks. Appl. Sci. 2022, 12, 8643. [Google Scholar] [CrossRef]
- Vargas-Hakim, G.-A.; Mezura-Montes, E.; Acosta-Mesa, H.-G. A review on convolutional neural network encodings for neuroevolution. IEEE Trans. Evol. Comput. 2021, 26, 12–27. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Chen, Z.; Wang, Y.; Zhao, B.; Cheng, J.; Zhao, X.; Duan, Z. Knowledge graph completion: A review. IEEE Access 2020, 8, 192435–192456. [Google Scholar] [CrossRef]
- Jiang, D.; Wang, R.; Xue, L.; Yang, J. Multiview feature augmented neural network for knowledge graph embedding. Knowl.-Based Syst. 2022, 255, 109721. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Q.; Shi, F.; Li, D.; Cai, Y.; Wang, J.; Li, B.; Wang, X.; Zhang, Z.; Zheng, C. Knowledge graph embedding model with attention-based high-low level features interaction convolutional network. Inf. Process. Manag. 2023, 60, 103350. [Google Scholar] [CrossRef]
- Lu, X.; Wang, L.; Jiang, Z.; Liu, S.; Lin, J. MRE: A translational knowledge graph completion model based on multiple relation embedding. Math. Biosci. Eng. 2023, 20, 5881–5900. [Google Scholar] [CrossRef] [PubMed]
- Krichen, M.; Mihoub, A.; Alzahrani, M.Y.; Adoni, W.Y.H.; Nahhal, T. Are Formal Methods Applicable to Machine Learning and Artificial Intelligence? In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022. [Google Scholar]
- Raman, R.; Gupta, N.; Jeppu, Y. Framework for Formal Verification of Machine Learning Based Complex System-of-Systems. Insight 2023, 26, 91–102. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | LR | Batch Size | Embedding Size | Input Dropout | Feature Dropout | Hidden Dropout |
|---|---|---|---|---|---|---|
| FB15K-237 | 0.001 | 64 | 350 | 0.2 | 0.3 | 0.2 |
| Hydraulic_eng | 0.001 | 64 | 350 | 0.2 | 0.3 | 0.2 |
| Method | MRR | Hits@10 | Hits@3 | Hits@1 |
|---|---|---|---|---|
| TransE | 0.287 | 0.475 | 0.325 | 0.192 |
| DistMult | 0.178 | 0.352 | 0.204 | 0.092 |
| ConvE | 0.316 | 0.491 | 0.350 | 0.239 |
| ConvR | 0.350 | 0.528 | 0.385 | 0.261 |
| InteractE | 0.353 | 0.541 | 0.390 | 0.260 |
| JointE | 0.356 | 0.543 | 0.393 | 0.262 |
| ConvMVD | 0.363 | 0.565 | 0.421 | 0.236 |
| Method | MRR | Hits@10 | Hits@3 | Hits@1 |
|---|---|---|---|---|
| TransE | 0.082 | 0.167 | 0.086 | 0.031 |
| DistMult | 0.073 | 0.148 | 0.074 | 0.025 |
| ConvE | 0.338 | 0.651 | 0.394 | 0.196 |
| ConvR | 0.317 | 0.618 | 0.373 | 0.179 |
| InteractE | 0.342 | 0.655 | 0.401 | 0.199 |
| JointE | 0.341 | 0.655 | 0.40 | 0.198 |
| ConvMVD | 0.349 | 0.665 | 0.411 | 0.204 |
| Method | MRR | Hits@10 | Hits@3 | Hits@1 |
|---|---|---|---|---|
| TransE | 1.41 × 10−5 | 2.38 × 10−5 | 1.87 × 10−5 | 4.51 × 10−5 |
| DistMult | 0.98 × 10−5 | 1.14 × 10−5 | 0.88 × 10−5 | 2.23 × 10−5 |
| ConvE | 0.0014 | 0.0035 | 0.0018 | 0.0007 |
| ConvR | 0.0021 | 0.0122 | 0.0041 | 0.0019 |
| InteractE | 0.0016 | 0.0034 | 0.002 | 0.0014 |
| JointE | 0.001 | 0.0052 | 0.0035 | 0.0023 |
| ConvMVD | 0.0004 | 0.0014 | 0.0007 | 0.0001 |
| Method | MRR | Hits@10 | Hits@3 | Hits@1 |
|---|---|---|---|---|
| TransE | 0.0002 | 0.0009 | 0.0002 | 3.41 × 10−5 |
| DistMult | 0.0001 | 0.0006 | 0.0001 | 1.61 × 10−5 |
| ConvE | 0.0030 | 0.0079 | 0.0047 | 0.0017 |
| ConvR | 0.0046 | 0.0143 | 0.0069 | 0.0022 |
| InteractE | 0.0031 | 0.0078 | 0.0049 | 0.0018 |
| JointE | 0.0036 | 0.0089 | 0.0056 | 0.0020 |
| ConvMVD | 0.0022 | 0.0057 | 0.0036 | 0.0012 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Tian, J.; Liu, X.; Tao, T.; Ren, Z.; Wang, X.; Wang, Y. Research on a Knowledge Graph Embedding Method Based on Improved Convolutional Neural Networks for Hydraulic Engineering. Electronics 2023, 12, 3099. https://doi.org/10.3390/electronics12143099
Liu Y, Tian J, Liu X, Tao T, Ren Z, Wang X, Wang Y. Research on a Knowledge Graph Embedding Method Based on Improved Convolutional Neural Networks for Hydraulic Engineering. Electronics. 2023; 12(14):3099. https://doi.org/10.3390/electronics12143099
Chicago/Turabian StyleLiu, Yang, Jiayun Tian, Xuemei Liu, Tianran Tao, Zehong Ren, Xingzhi Wang, and Yize Wang. 2023. "Research on a Knowledge Graph Embedding Method Based on Improved Convolutional Neural Networks for Hydraulic Engineering" Electronics 12, no. 14: 3099. https://doi.org/10.3390/electronics12143099
APA StyleLiu, Y., Tian, J., Liu, X., Tao, T., Ren, Z., Wang, X., & Wang, Y. (2023). Research on a Knowledge Graph Embedding Method Based on Improved Convolutional Neural Networks for Hydraulic Engineering. Electronics, 12(14), 3099. https://doi.org/10.3390/electronics12143099