
Process Discovery Techniques Recommendation Framework



Abstract
:1. Introduction
1.1. Event Log
1.2. Process Discovery Techniques Overview
2. Literature Review
3. Process Discovery Recommendation Framework
3.1. Constructs
- Sequence: Certain process activities need to be sequentially executed.
- Exclusive choice: Certain process parts of the process are mutually exclusive. In several notations, this is known as XOR split/join.
- Parallelism: Certain branches are “parallel”, indicating that the activities of a first part of the model are executed simultaneously with the activities of a second part of the model. In several notations, this is known as AND split/join.
- Inclusive choice: a choice needs to be made on which part(s) of the process that follow need to be performed, when reaching given points of the process. Inclusive choice is different from exclusive choice because multiple parts can be executed in parallel and different from the parallelism construct since not every part that follows the reached point needs to be executed. In several notations, this is known as OR split/join.
- Loop: The execution of certain parts of the process can be sequentially repeated multiple times.
- Invisible tasks: Certain transitions are incorporated into the model for a process-routing purpose. For instance, combined with exclusive choices, invisible tasks allow the execution of some parts of the process to be skipped.
- Duplicate activities: Certain activities share the same name but placed in two or more nodes in the process model.
- Non-free choice: when the choice of one or multiple branches is influenced by a choice that occurred before.
3.2. Complex Construct Detection
3.2.1. Basic Ordering Relations
- Relation : This relation signifies that two activities can be executed successively, one after the other. It indicates a direct succession between the activities.
- Relation : This relation represents a loop with a length-two structure, such as “aba.” It is also used to differentiate between length-2-loops and parallel routing.
- Relation : This relation indicates a two-way loop with a length of two. It means that two activities have the relation between them, for example, “aba” or “bab.”
- Relation : This relation denotes a direct causal relationship between two activities, indicating that one activity is a direct cause or prerequisite for the other.
- Relation ‖_L: The ‖_L relation signifies that activities can be executed concurrently, meaning they can happen simultaneously or in parallel. For instance, “ab” or “ba” can be executed concurrently.
- Relation : This relation implies that two activities should never directly follow each other. There should always be other activities or conditions between them.
3.2.2. Short Loops Detection
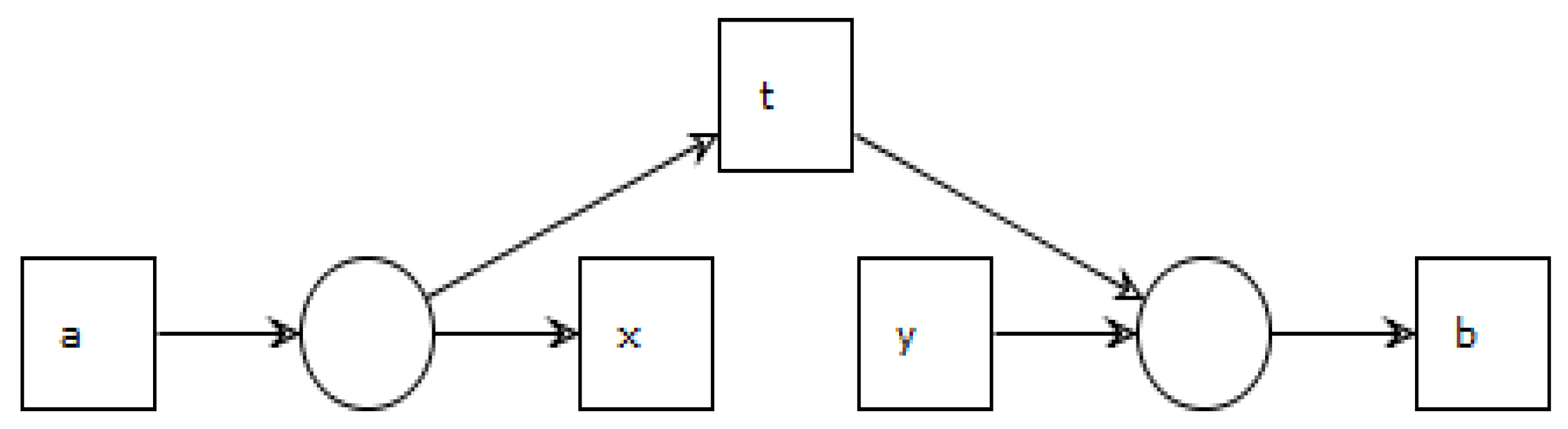
3.2.3. Invisible Tasks Detection
- Short-Skip: Task is of Short-Skip type if tasks and are equal. In a sequential workflow, this type of invisible task can be detected by the relation .
- Long-Skip: Task is of Long-Skip type if reaches . Again, in a sequential workflow, this type of invisible task can be detected by the relation .
- Short-Redo: Task is of Short-Redo type if tasks and are equivalent. In a sequential workflow, this type of invisible task can be detected by the relation .
- Long-Redo: Task is of Long-Redo type if reaches . Once again, in a sequential workflow, this type of invisible task can be detected by the relation
- Switch: If none of the above conditions are met, task is considered a Switch type.
3.2.4. Non-Free Choice Constructs
- (XOR-Split): This relation represents an exclusive OR (XOR) splitting of a process flow. It indicates that at a specific point in the process, there are multiple possible outgoing transitions, but only one of them can be taken. (XOR-Join): This relation corresponds to an exclusive OR (XOR) joining of a process flow. It indicates that there are multiple incoming transitions to a specific point in the process, but only one of them is enabled and must be followed.
- (AND-Split): This relation represents an AND-split in the process flow. It indicates that at a particular point in the process, multiple outgoing transitions can be taken simultaneously.
3.2.5. Invisible Tasks Involved in a Non-Free Choice Construct Detection
3.3. Knowledge Data Base Construction
3.3.1. Algorithms Classification Based on Their Ability in Mining Complex Constructs
3.3.2. Mining Time Based Classification of Discovery Algorithms
3.3.3. Algorithms Classification Based on Their Ability in Discovering Sound Models
4. Recommendation Framework Implementation and Evaluation
4.1. Implementation in ProM
4.2. Evaluation Framework
4.3. Evaluation Using Artificial Event Logs
4.4. Evaluation Based on Real-Life Event Logs
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- R’bigui, H.; Cho, C. The state-of-the-art of business process mining challenges. Int. J. Bus. Process Integr. Manag. 2017, 8, 285–303. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P.; Reijers, H.A.; Weijters, A.J.M.M.; van Dongen, B.F.; de Medeiros, A.K.A.; Song, M.; Verbeek, H.M.W. Business process mining: An industrial application. Inf. Syst. 2007, 32, 713–732. [Google Scholar] [CrossRef]
- Taylor, P.; Leida, M.; Majeed, B. Case Study in Process Mining in a Multinational Enterprise. In Data-Driven Process Discovery and Analysis. SIMPDA 2011; Aberer, K., Damiani, E., Dillon, T., Eds.; Springer: Berlin, Heidelberg, 2012; Volume 116, pp. 134–153. [Google Scholar]
- Van der Aalst, W.M.P. Book on Process Mining: Discovery, Conformance and Enhancement of Business Processes, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Dennis, J.B. Petri Nets. In Encyclopedia of Parallel Computing; Padua, D., Ed.; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P.; Weijters, A.J.M.M.; Maruster, L. Workflow Mining: Discovering Process Models from Event Logs. IEEE Trans. Knowl. Data Eng. 2004, 16, 1128–1142. [Google Scholar] [CrossRef]
- De Medeiros, A.K.A.; van Dongen, B.F.; van der Aalst, W.M.P.; Weijters, A.J.M.M. Process Mining: Extending the Alpha-Algorithm to Mine Short Loops; BETA Working Paper Series, WP 113; Eindhoven University of Technology: Eindhoven, The Netherlands, 2004. [Google Scholar]
- Wen, L.; van der Aalst, W.M.P.; Wang, J.; Sun, J. Mining process models with non-free choice constructs. Data Min. Knowl. Discov. 2007, 15, 145–180. [Google Scholar] [CrossRef]
- Wen, L.; Wang, J.; Sun, J. Mining Invisible Tasks from Event Logs. In Advances in Data and Web Management; Lecture Notes in Computer Science 4505; Springer: Berlin/Heidelberg, Germany, 2007; pp. 358–365. [Google Scholar]
- Wen, L.; Wang, J.; van der Aalst, W.M.P.; Huang, B.; Sun, J. Mining process models with prime invisible tasks. Data Knowl. Eng. 2010, 69, 999–1021. [Google Scholar] [CrossRef]
- Guo, Q.; Wen, L.; Wang, J.; Yan, Z.; Yu, P.S. Mining invisible tasks in non-free-choice constructs. In Business Process Management—BPM 2016; Motahari-Nezhad, H., Recker, J., Weidlich, M., Eds.; Lecture Notes in Computer Science 9253; Springer: Cham, Switzerland, 2015; pp. 109–125. [Google Scholar]
- Weijters, A.J.M.M.; van der Aalst, W.M.P.; de Medeiros, A.K.A. Process Mining with the Heuristics Miner-Algorithm; BETA Working Paper Series, WP 166; Eindhoven University of Technology: Eindhoven, The Netherlands, 2006. [Google Scholar]
- Leemans, S.J.J.; Fahland, D.; van der Aalst, W.M.P. Discovering block-structured process models from event logs—A constructive approach. In Application and Theory of Petri Nets and Concurrency; Lecture Notes in Computer Science 7927; Springer: Berlin/Heidelberg, Germany, 2013; pp. 311–329. [Google Scholar]
- Bergenthum, R.; Desel, J.; Lorenz, R.; Mauser, S. Process mining based on regions of languages. In Business Process Management—BPM 2007; Lecture Notes in Computer Science 4714; Springer: Berlin/Heidelberg, Germany, 2007; pp. 375–383. [Google Scholar]
- Rozinat, A.; Alves de Medeiros, A.K.; Günther, C.W.; Weijters, A.J.M.M.; Van der Aalst, W.M.P. Toward an Evaluation Framework for Process Mining Algorithms; BPM Center Report BPM-07-06; Technische Universiteit Eindhoven: Eindhoven, The Netherlands, 2007; Available online: http://bpmcenter.org/ (accessed on 2 February 2023).
- Wang, J.; Tan, S.; Wen, L. An Empirical Evaluation of Process Mining Algorithms based on Structural and Behavioral Similarities. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012; pp. 211–213. [Google Scholar]
- Wang, J.; Wong, R.K.; Ding, J.; Guo, Q.; Wen, L. Efficient selectin of Process Mining Algorithms. IEEE Trans. Serv. Comput. 2013, 6, 484–496. [Google Scholar] [CrossRef]
- Ribeiro, J.; Carmouna, J. RS4PD: A Tool for Recommending Control-Flow Algorithms; BPM (Demos): Eindhoven, The Netherlands, 2014; p. 66. [Google Scholar]
- Pérez-Alfonso, D.; Fundora-Ramírez, O.; Lazo-Cortés, M.S.; Roche-Escobar, R. Recommendation of Process Discovery Algorithms Through Event Log Classification. In Pattern Recognition, MCPR 2015; Carrasco-Ochoa, J., Martínez-Trinidad, J., Sossa-Azuela, J., Olvera López, J., Famili, F., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9116. [Google Scholar]
- Jouck, T.; Bolt, A.; Depaire, B.; de Leoni, M.; van der Aalst, W.M. An Integrated Framework for Process DiscoveryAlgorithm Evaluation. arXiv 2018, arXiv:1806.07222. [Google Scholar]
- R’bigui, H.; Al-Absi, M.A.; Cho, C. Process Discovery Algorithms Recommendation Approach. In International Conference on Smart Computing and Cyber Security: Strategic Foresight, Security Challenges and Innovation; Lecture Notes in Networks and Systemsthis link is disabled; Springer Nature Singapore: Singapore, 2021; pp. 55–60. [Google Scholar]
- Buijs, J.C.A.M.; van Dongen, B.F.; van der Aalst, W.M.P. On the Role of Fitness, Precision, Generalization and Simplicity in Process Discovery. In On the Move to Meaningful Internet Systems: OTM 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 305–322. [Google Scholar]
- Wen, L.; Wang, J.; Sun, J. Detecting Implicit Dependencies Between Tasks from Event Logs. In Frontiers of WWW Research and Development—APWeb 2006; Zhou, X., Li, J., Shen, H.T., Kitsuregawa, M., Zhang, Y., Eds.; Lecture Notes in Computer Science 3841; Springer: Berlin/Heidelberg, Germany, 2006; pp. 591–603. [Google Scholar]
- Van der Werf, J.M.E.M.; van Dongen, B.F.; Hurkens, C.A.J.; Serebrenik, A. Process Discovery using Integer Linear Programming. Fundam. Inform. 2009, 94, 387–412. [Google Scholar] [CrossRef] [Green Version]
- Kalenkova, A.A.; Lomazova, I.A.; van der Aalst, W.M.P. Process Model Discovery: A Method Based on Transition System Decomposition, In Application and Theory of Petri Nets and Concurrency; Ciardo, G., Kindler, E., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8489. [Google Scholar]
- Greco, G.; Guzzo, A.; Pontieri, L.; Saccà, D. Discovering Expressive Process Models by Clustering Log Traces. IEEE Trans. Knowl. Data Eng. 2006, 18, 1010–1027. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
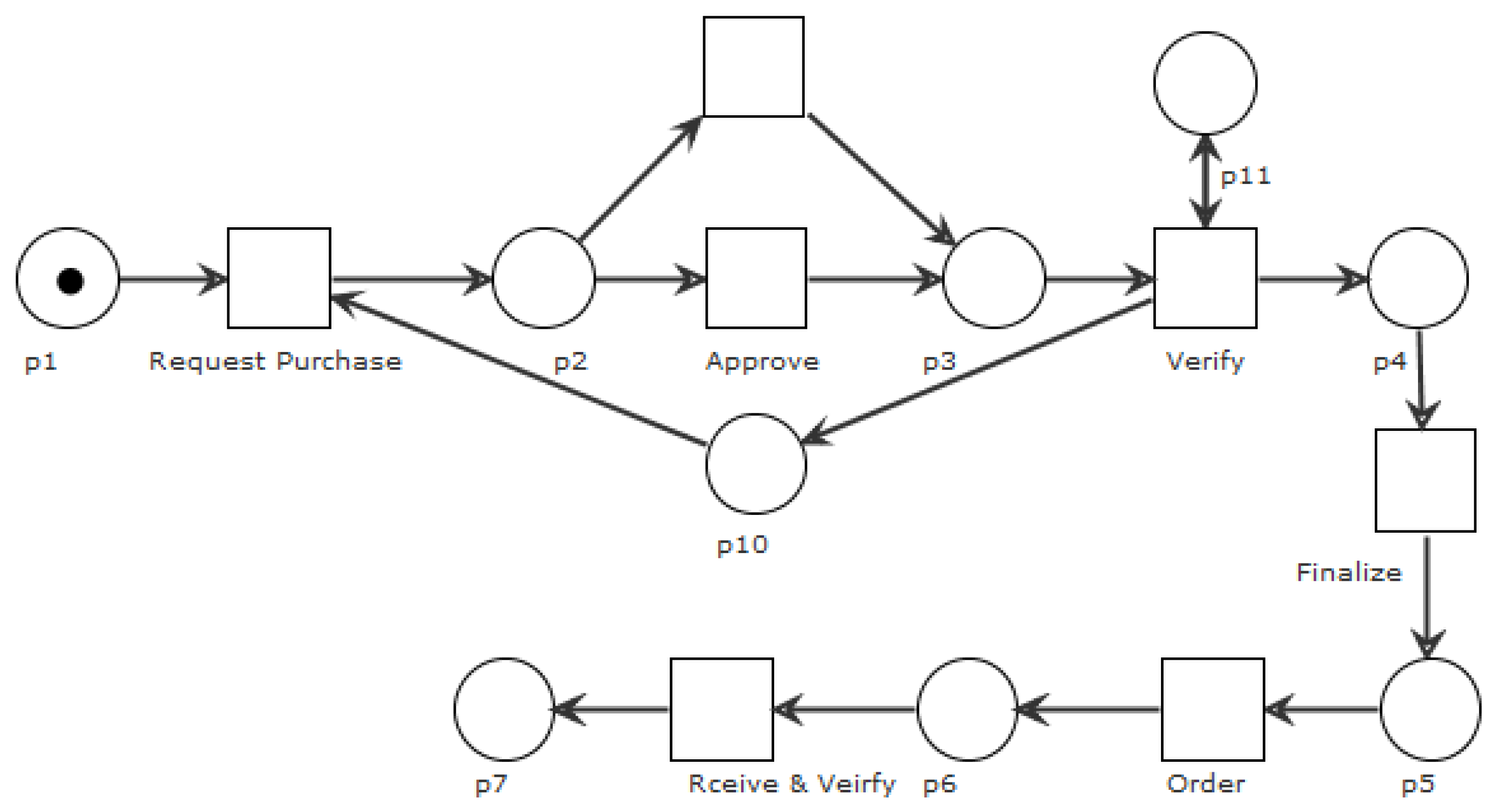
| Case Id | Event Id | Activity | Timestamp | Resource | …. |
|---|---|---|---|---|---|
| Q521-QZR | N0060 | Purchase Request | 5/15/2022 16:35 | Hind | …. |
| N0070 | Purchase Approval | 5/15/2022 16:40 | Safae | …. | |
| N0080 | Approval Verification | 5/16/2022 16:40 | Soukaina | …. | |
| N0090 | Purchase Finalization | 5/16/2022 17:42 | Younes | …. | |
| N0100 | Purchase Order | 5/16/2022 17:30 | Moui | …. | |
| N0110 | Purchase Reception and verification | 6/13/2022 10:55 | Mohammed | …. | |
| Q543-289 | N0060 | Purchase Request | 5/15/2022 10:38 | Hind | …. |
| N0070 | Purchase Approval | 5/15/2022 11:41 | Safae | …. | |
| N0080 | Approval Verification | 5/15/2022 12:42 | Soukaina | …. | |
| N0060 | Purchase Request | 5/15/2022 13:42 | Hind | …. | |
| N0080 | Approval Verification | 5/15/2022 15:42 | Soukaina | …. | |
| N0090 | Purchase Finalization | 5/15/2022 16:43 | Younes | …. | |
| N0100 | Purchase Order | 5/15/2022 16:45 | Moui | …. | |
| N0110 | Purchase Reception and verification | 6/15/2022 11:45 | Mohammed | …. |
| IM | HM | ILP | ETM | RM | TS | DWS | GM | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | Sb | No | Yes | Yes | No | Sb | No | Yes | |
| Yes | Yes | Yes | Sb | Yes | No | Yes | Yes | Yes | Yes | |
| Sb | Yes | Yes | No | No | No | No | Sb | Yes | No | |
| No | Yes | Yes | Yes | No | No | Sb | No | Yes | Yes | |
| No | No | No | No | No | No | No | No | No | No | |
| No | No | Yes | No | No | No | No | No | No | Yes | |
| No | Yes | Yes | Yes | No | Yes | No | Yes | Yes | Yes | |
| No | No | Yes | No | No | No | No | Sb | No | No | |
| No | Yes | Yes | Yes | No | Yes | No | No | Yes | Yes | |
| No | No | Yes | Yes | No | No | No | No | No | Yes | |
| No | Yes | No | Yes | No | No | No | No | Yes | Yes | |
| NFC | Yes | No | No | No | No | No | No | No | No | Yes |
| No | No | No | No | No | No | No | No | No | No |
| Event Logs | L1 | L2 | L3 | L4 | L5 |
|---|---|---|---|---|---|
| cases | 97 | 110 | 663 | 1676 | 31,509 |
| events | 361 | 3770 | 19,658 | 129,428 | 1,202,267 |
| tasks | 8 | 21 | 18 | 38 | 66 |
| Recommended algorithm | Alpha++ | IM/ILP | IM | IM/DWS | ILP |
| HM | Alpha++ | IM | Alpha# | ILP | DWS | |
|---|---|---|---|---|---|---|
| L1 | 0.7973 | 1.0 | 0.8 | 0.8 | 0.8 | 0.69 |
| L2 | 0.3811 | 0.6665 | 0.6665 | 0.6665 | 0.7 | 0.6665 |
| L3 | - | - | 0.945 | 0.4423 | 0.361 | 0.3 |
| L4 | 0.4 | 0.03 | 0.8709 | 0.02 | - | 0.89 |
| L5 | 0.681 | - | 0.89 | - | 0.91 | 0.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Absi, M.A.; R’bigui, H. Process Discovery Techniques Recommendation Framework. Electronics 2023, 12, 3108. https://doi.org/10.3390/electronics12143108
Al-Absi MA, R’bigui H. Process Discovery Techniques Recommendation Framework. Electronics. 2023; 12(14):3108. https://doi.org/10.3390/electronics12143108
Chicago/Turabian StyleAl-Absi, Mohammed Abdulhakim, and Hind R’bigui. 2023. "Process Discovery Techniques Recommendation Framework" Electronics 12, no. 14: 3108. https://doi.org/10.3390/electronics12143108
APA StyleAl-Absi, M. A., & R’bigui, H. (2023). Process Discovery Techniques Recommendation Framework. Electronics, 12(14), 3108. https://doi.org/10.3390/electronics12143108