
CUDA-Optimized GPU Acceleration of 3GPP 3D Channel Model Simulations for 5G Network Planning

Abstract
:1. Introduction
2. Related Work
- proposing a GPU-based hardware acceleration for the 3GPP 3D channel model, which is a highly parameterized and realistic channel model for 5G NR networks;
- application of various CUDA-based optimization techniques to efficiently utilize GPU resources and increase the overall performance of the channel model simulator;
- evaluation of the performance and accuracy of the GPU accelerator using benchmark parameters and comparison with both a CPU-based C++ model and a previous design on an FPGA based on the same 16 technology node as the GPU;
- showing that the GPU accelerator can achieve an overall speedup of about 240× compared to the CPU model and 33.3% higher single-precision performance than a comparable FPGA design, while maintaining high accuracy and flexibility.
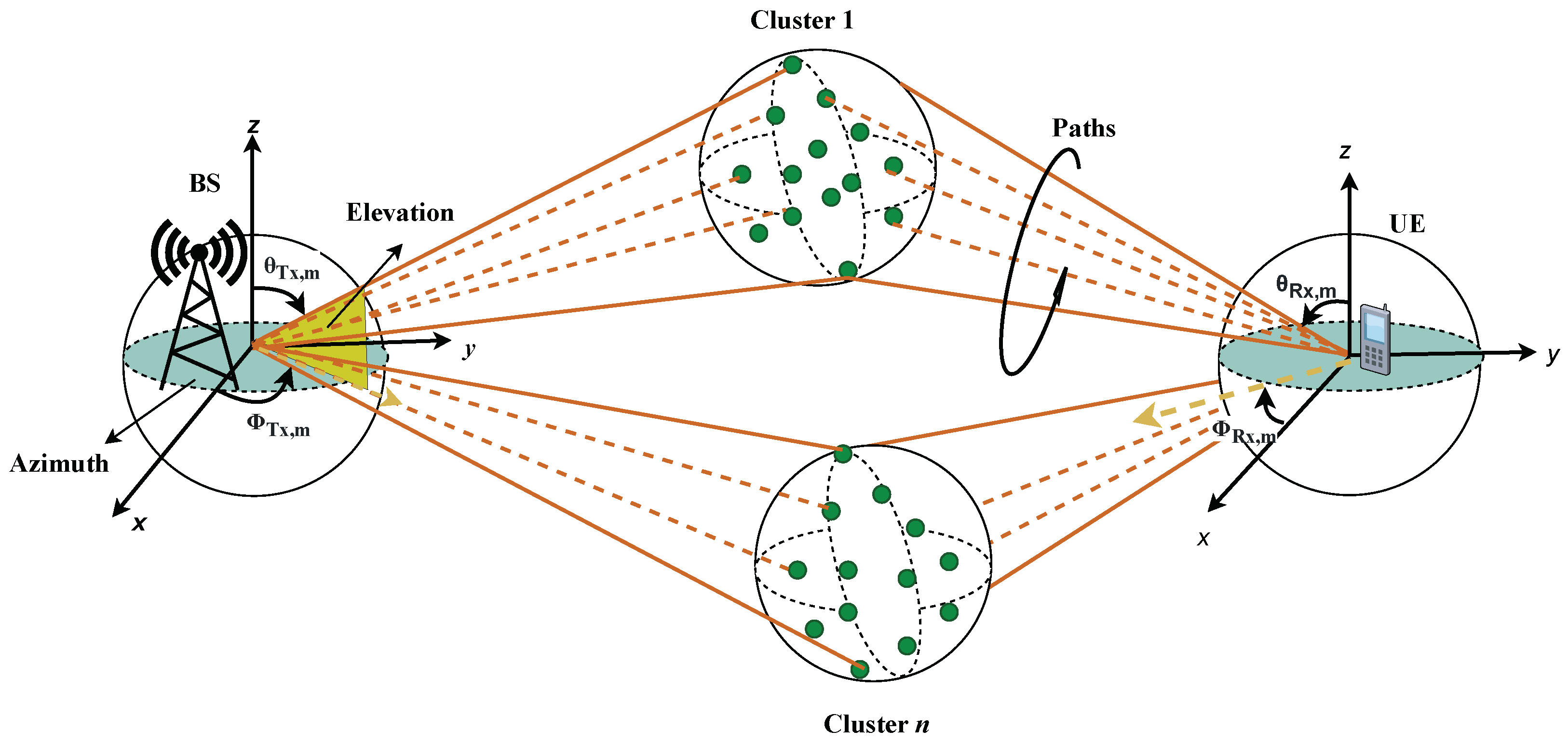
3. The 3GPP Channel Model for 5G NR
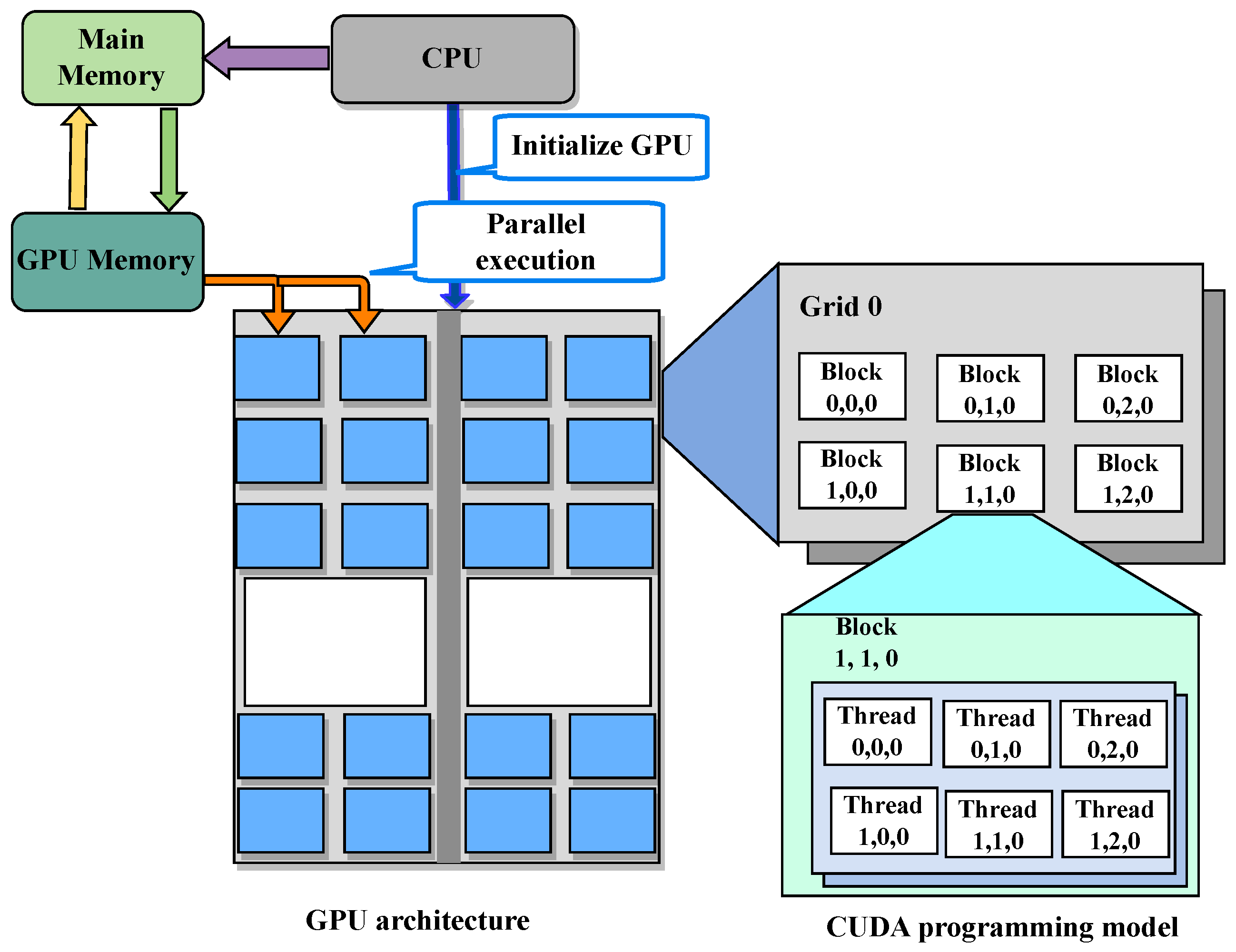
4. GPU-Based Acceleration Using NVIDIA CUDA
- Allocating arrays to explicit levels in the memory hierarchy.
- Explicitly modeling concurrency via threads.
4.1. Thread Synchronization
- All threads involved in a concurrent set of memory transfers, where each thread copies one or a few words of a large off-chip memory buffer to an on-chip memory one, are finished when computations using the transferred data begin,
- All threads performing parallel computations are finished when the results begin to be transferred back from on-chip memory to off-chip memory.
- Parallelism between thread blocks, where synchronization is impossible;
- Parallelism within a thread block, where synchronization can be requested by the designer;
- Parallelism within thread warp, where synchronization is automatically ensured by the GPU hardware.
4.2. Register-Based Parallel Reduction
4.3. Global Memory
4.4. Shared Memory
5. Channel Emulator Acceleration on GPU
| Listing 1. CUDA calcCIR kernel. |
 |
| Listing 2. CUDA applyFIR kernel. |
 |
6. Results and Discussion
Coding Style: CUDA vs. HLS
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2D | two-dimensional |
| 2D-SCM | two-dimensional spatial channel model |
| 2G | second-generation |
| 3D | three-dimensional |
| 3GPP | 3rd Generation Partnership Project |
| 5G | fifth-generation |
| 5G NR | fifth-generation new radio |
| ASIC | application-specific integrated circuit |
| CIR | channel impulse response |
| CPU | central processing unit |
| CTA | cooperative-thread-array |
| CUDA | compute unified device architecture |
| FIR | finite impulse response |
| ITU | International Telecommunication Union |
| DP | double-precision |
| DRAM | dynamic RAM |
| DSP | digital signal processing |
| FPGA | field programmable gate array |
| GPU | graphics processing unit |
| GSCM | geometry-based stochastic model |
| HLS | high level synthesis |
| LOS | line-of-sight |
| MIMO | multiple-input multiple-output |
| NLOS | non-LOS |
| SIMD | single-instruction-multiple-data |
| SM | streaming multiprocessor |
| SP | single-precision |
| SSP | small-scale parameter |
References
- Mort, G.S.; Drennan, J. Mobile Communications: A Study of Factors Influencing Consumer Use of m-Services. J. Advert. Res. 2007, 47, 302–312. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Yadav, R. Impact of mobile technology on libraries: A descriptive study. Int. J. Digit. Libr. Serv. 2013, 3, 1–13. [Google Scholar]
- Castleman, W.A.; Harper, R.; Herbst, S.; Kies, J.; Lane, S.; Nagel, J. The impact of mobile technologies on everyday life. In Proceedings of the CHI’01 Extended Abstracts on Human Factors in Computing Systems, Seattle, WA, USA, 31 March–5 April 2001; pp. 227–228. [Google Scholar]
- Wang, D.; Xiang, Z.; Fesenmaier, D.R. Smartphone use in everyday life and travel. J. Travel Res. 2016, 55, 52–63. [Google Scholar] [CrossRef]
- Riviello, D.G.; Di Stasio, F.; Tuninato, R. Performance Analysis of Multi-User MIMO Schemes under Realistic 3GPP 3-D Channel Model for 5G mmWave Cellular Networks. Electronics 2022, 11, 330. [Google Scholar] [CrossRef]
- Cisco Systems, Inc. Cisco Global Cloud Index: Forecast and Methodology, 2012–2017; Technical Report; Ciso: San Jose, CA, USA, 2013. [Google Scholar]
- Zhang, L.; Ijaz, A.; Xiao, P.; Quddus, A.; Tafazolli, R. Subband filtered multi-carrier systems for multi-service wireless communications. IEEE Trans. Wirel. Commun. 2017, 16, 1893–1907. [Google Scholar] [CrossRef] [Green Version]
- Sector, I.R. Guidelines for Evaluation of Radio Interface Technologies for IMT-2020; Technical Report; International Telecommunication Union: Geneva, Switzerland, 2017; Available online: https://www.itu.int/pub/R-REP-M.2412-2017 (accessed on 2 June 2023).
- Liu, L.; Oestges, C.; Poutanen, J.; Haneda, K.; Vainikainen, P.; Quitin, F.; Tufvesson, F.; De Doncker, P. The COST 2100 MIMO channel model. IEEE Wirel. Commun. 2012, 19, 92–99. [Google Scholar] [CrossRef] [Green Version]
- Weiler, R.J.; Peter, M.; Keusgen, W.; Maltsev, A.; Karls, I.; Pudeyev, A.; Bolotin, I.; Siaud, I.; Ulmer-Moll, A.M. Quasi-deterministic millimeter-wave channel models in MiWEBA. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 84. [Google Scholar] [CrossRef] [Green Version]
- Nurmela, V.; Karttunen, A.; Roivainen, A.; Raschkowski, L.; Hovinen, V.; Ylitalo, J.; Omaki, N.; Kusume, K.; Hekkala, A.; Weiler, R. Deliverable D1.4 METIS Channel Models. ICT-317669-METIS/D1.4 ver 3. 2015. Available online: https://www.google.co.uk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwjj9eGsmqmAAxXYVPUHHem7Ak4QFnoECBEQAQ&url=https%3A%2F%2Fmetis2020.com%2Fwp-content%2Fuploads%2Fdeliverables%2FMETIS_D1.4_v1.0.pdf&usg=AOvVaw3ZtN0bJnmB4SaDFS6WSXOZ&opi=89978449 (accessed on 9 July 2023).
- ETSI. 5G; Study on Channel Model for Frequencies from 0.5 to 100 GHz (3GPP TR 38.901 Version 16.1.0 Release 16); ETSI: Sophia-Antipolis, France, 2020; Available online: https://portal.3gpp.org/desktopmodules/Specifications/SpecificationDetails.aspx?specificationId=3173 (accessed on 2 June 2023).
- Sun, S.; MacCartney, G.R.; Rappaport, T.S. A novel millimeter-wave channel simulator and applications for 5G wireless communications. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar]
- Jaeckel, S.; Raschkowski, L.; Wu, S.; Thiele, L.; Keusgen, W. An explicit ground reflection model for mm-wave channels. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), San Francisco, CA, USA, 19–22 March 2017; pp. 1–5. [Google Scholar]
- Ju, S.; Kanhere, O.; Xing, Y.; Rappaport, T.S. A millimeter-wave channel simulator NYUSIM with spatial consistency and human blockage. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Jaeckel, S.; Raschkowski, L.; Burkhardt, F.; Thiele, L. Efficient sum-of-sinusoids-based spatial consistency for the 3GPP new-radio channel model. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Pessoa, A.M.; Guerreiro, I.M.; Silva, C.F.; Maciel, T.F.; Sousa, D.A.; Moreira, D.C.; Cavalcanti, F.R. A stochastic channel model with dual mobility for 5G massive networks. IEEE Access 2019, 7, 149971–149987. [Google Scholar] [CrossRef]
- Hofer, M.; Xu, Z.; Vlastaras, D.; Schrenk, B.; Löschenbrand, D.; Tufvesson, F.; Zemen, T. Real-time geometry-based wireless channel emulation. IEEE Trans. Veh. Technol. 2018, 68, 1631–1645. [Google Scholar] [CrossRef]
- Shah, N.A.; Lazarescu, M.T.; Quasso, R.; Scarpina, S.; Lavagno, L. FPGA Acceleration of 3GPP Channel Model Emulator for 5G New Radio. IEEE Access 2022, 10, 119386–119401. [Google Scholar] [CrossRef]
- Abdelrazek, A.F.; Kaschub, M.; Blankenhorn, C.; Necker, M.C. A novel architecture using NVIDIA CUDA to speed up simulation of multi-path fast fading channels. In Proceedings of the VTC Spring 2009-IEEE 69th Vehicular Technology Conference, Barcelona, Spain, 6–29 April 2009; pp. 1–5. [Google Scholar]
- Borries, K.C.; Judd, G.; Stancil, D.D.; Steenkiste, P. FPGA-based channel simulator for a wireless network emulator. In Proceedings of the VTC Spring 2009-IEEE 69th Vehicular Technology Conference, Barcelona, Spain, 6–29 April 2009; pp. 1–5. [Google Scholar]
- Buscemi, S.; Sass, R. Design of a scalable digital wireless channel emulator for networking radios. In Proceedings of the 2011-MILCOM 2011 Military Communications Conference, Baltimore, MD, USA, 7–10 November 2011; pp. 1858–1863. [Google Scholar]
- Endovitskiy, E.; Kureev, A.; Khorov, E. Reducing computational complexity for the 3GPP TR 38.901 MIMO channel model. IEEE Wirel. Commun. Lett. 2022, 11, 1133–1136. [Google Scholar] [CrossRef]
- Nam, Y.H.; Ng, B.L.; Sayana, K.; Li, Y.; Zhang, J.; Kim, Y.; Lee, J. Full-dimension MIMO (FD-MIMO) for next generation cellular technology. IEEE Commun. Mag. 2013, 51, 172–179. [Google Scholar] [CrossRef]
- Chang, H.; Bian, J.; Wang, C.X.; Bai, Z.; Zhou, W.; Aggoune, E.-H.M. A 3D non-stationary wideband GBSM for low-altitude UAV-to-ground V2V MIMO channels. IEEE Access 2019, 7, 70719–70732. [Google Scholar] [CrossRef]
- Czajkowski, T.S.; Aydonat, U.; Denisenko, D.; Freeman, J.; Kinsner, M.; Neto, D.; Wong, J.; Yiannacouras, P.; Singh, D.P. From OpenCL to high-performance hardware on FPGAs. In Proceedings of the 22nd International Conference on Field Programmable Logic and Applications (FPL), Oslo, Norway, 29–31 August 2012; pp. 531–534. [Google Scholar]
- NVIDIA. CUDA Toolkit—Free Tools and Training | NVIDIA Developer. Available online: https://developer.nvidia.com/cuda-toolkit (accessed on 2 June 2023).
- NVIDIA. GeForce GTX 1070 Specifications | GeForce. Available online: https://www.nvidia.com/en-gb/geforce/graphics-cards/geforce-gtx-1070/specifications (accessed on 2 June 2023).
- Vitis Unified Software Platform. Available online: https://www.xilinx.com/products/design-tools/vitis/vitis-platform.html (accessed on 2 June 2023).
- Xilinx. Alveo U280 Data Center Accelerator Card. Available online: https://www.xilinx.com/products/boards-and-kits/alveo/u280.html (accessed on 2 June 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Polarizations | 2 | Oversampling factor | 1 to 4 |
| Elements on H-Planes | 4 | Elements on V-Planes | 1 to 4 |
| Carrier Frequency () | 3600 | Sampling freq. () | 122.88 |
| Transmitting Antennas | 2 to 32 | Receiving Antennas | 2 to 32 |
| Clusters | 23 (CDL-B) & 13 (CDL-D) | Rays | 20 |
| User Speed () | 120 | Subcarriers | 2048 |
| Link Type | Kernel | Execution Latency Downlink ( × ), Uplink ( × ) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 × 2 | 4 × 4 | 4 × 8 | 8 × 8 | 8 × 16 | 16 × 16 | 2 × 32 | 4 × 32 | ||
| Downlink | calcCIR () | 5.43 | 8.22 | 8.29 | 10.94 | 12.93 | 20.16 | 9.25 | 12.67 |
| applyFIR () | 1.72 | 5.95 | 11.23 | 22.04 | 43.12 | 85.42 | 22.12 | 43.06 | |
| Uplink | calcCIR () | 5.43 | 8.00 | 8.35 | 11.10 | 12.58 | 19.46 | 8.86 | 11.23 |
| applyFIR () | 1.72 | 5.93 | 11.78 | 022.13 | 43.88 | 85.32 | 24.93 | 45.50 | |
| Link Type | Kernel | Execution Latency Downlink ( × ), Uplink ( × ) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 × 2 | 4 × 4 | 4 × 8 | 8 × 8 | 8 × 16 | 16 × 16 | 2 × 32 | 4 × 32 | ||
| Downlink | calcCIR () | 6.56 | 11.71 | 8.64 | 10.72 | 11.52 | 25.09 | 8.90 | 9.47 |
| applyFIR () | 1.09 | 2.95 | 5.56 | 11.01 | 21.52 | 42.14 | 10.90 | 21.21 | |
| Uplink | calcCIR () | 8.03 | 11.58 | 8.74 | 10.94 | 16.54 | 16.06 | 7.74 | 10.85 |
| applyFIR () | 1.37 | 2.4 | 4.58 | 9.62 | 21.70 | 33.16 | 12.46 | 22.68 | |
| Platform | Latency | Speedup | Power | Energy |
|---|---|---|---|---|
| () | (Times) | () | () | |
| CPU | 5.01 | N/A | 105 | 526.0 |
| FPGA (DP) | 0.03 | 172 | 31.1 | 0.96 |
| FPGA (SP) | 0.03 | 172 | 29.3 | 0.79 |
| GPU (DP) | 0.08 | 60 | 52.0 | 4.37 |
| GPU (SP) | 0.02 | 240 | 40.5 | 0.85 |
| Platform | Precision | Memory (%) | SM (%) | DSP (%) |
|---|---|---|---|---|
| FPGA | DP | 13.14 | N/A | 17.24 |
| SP | 6.25 | N/A | 8.05 | |
| GPU | DP | 40.89 | 63.61 | N/A |
| SP | 32.28 | 42.09 | N/A |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, N.A.; Lazarescu, M.T.; Quasso, R.; Lavagno, L. CUDA-Optimized GPU Acceleration of 3GPP 3D Channel Model Simulations for 5G Network Planning. Electronics 2023, 12, 3214. https://doi.org/10.3390/electronics12153214
Shah NA, Lazarescu MT, Quasso R, Lavagno L. CUDA-Optimized GPU Acceleration of 3GPP 3D Channel Model Simulations for 5G Network Planning. Electronics. 2023; 12(15):3214. https://doi.org/10.3390/electronics12153214
Chicago/Turabian StyleShah, Nasir Ali, Mihai T. Lazarescu, Roberto Quasso, and Luciano Lavagno. 2023. "CUDA-Optimized GPU Acceleration of 3GPP 3D Channel Model Simulations for 5G Network Planning" Electronics 12, no. 15: 3214. https://doi.org/10.3390/electronics12153214