
Privacy-Preserving Fine-Grained Redaction with Policy Fuzzy Matching in Blockchain-Based Mobile Crowdsensing

 ,
, 
Abstract
:1. Introduction
- How to enable fine-grained redactable blockchain with fuzzy policy matching;
- How to conceal the policy based on fuzzy policy matching;
- How to ensure data privacy while maintaining privilege downward compatibility (i.e., allowing redactable users to access the data) through policy concealment;
- How to minimize user overhead in a privacy-preserving paradigm.
1.1. Contribution
- We introduce a novel privacy-preserving fine-grained redactable blockchain with fuzzy policy matching for mobile crowdsensing scenarios. Concretely, to achieve data privacy preservation and fuzzy matching for the redactable blockchain, we leverage the Lagrange interpolation theorem-based secret sharing to distribute the data decryption keys and chameleon hash trapdoors.
- To further satisfy the requirement of privacy-preserving policy matching and reduce the user overhead, we design a privacy-preserving policy matching delegation mechanism for PRBFM.
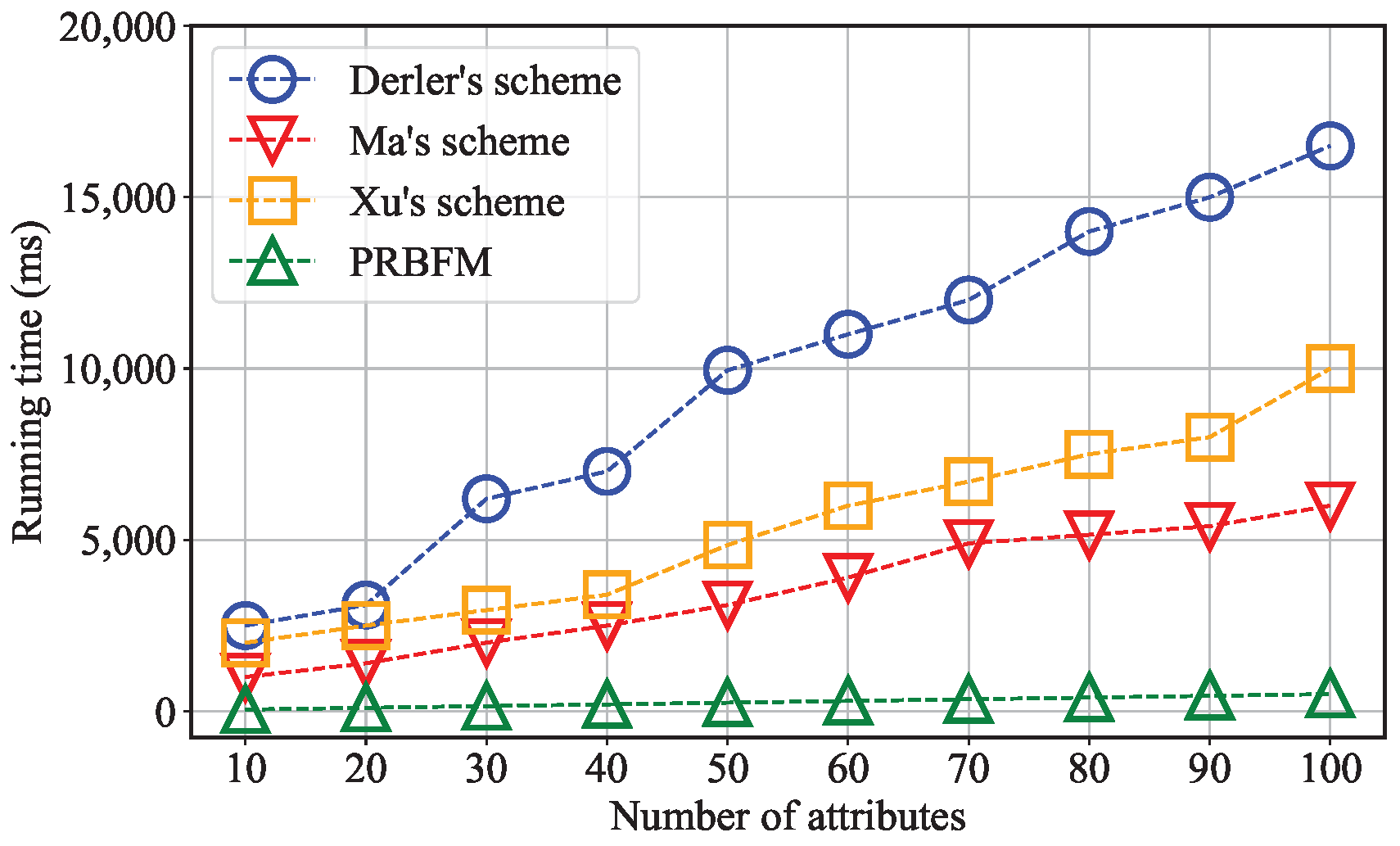
- A formal security analysis is provided to demonstrate the security of PRBFM against chosen-ciphertext attacks in a random oracle model. Subsequently, we employ a real-world dataset to perform experiments on the FISCO blockchain platform. The experimental results demonstrate that our schemes outperform related existing solutions, with a speed improvement of a minimum of .
1.2. Roadmap
2. Problem Formulation
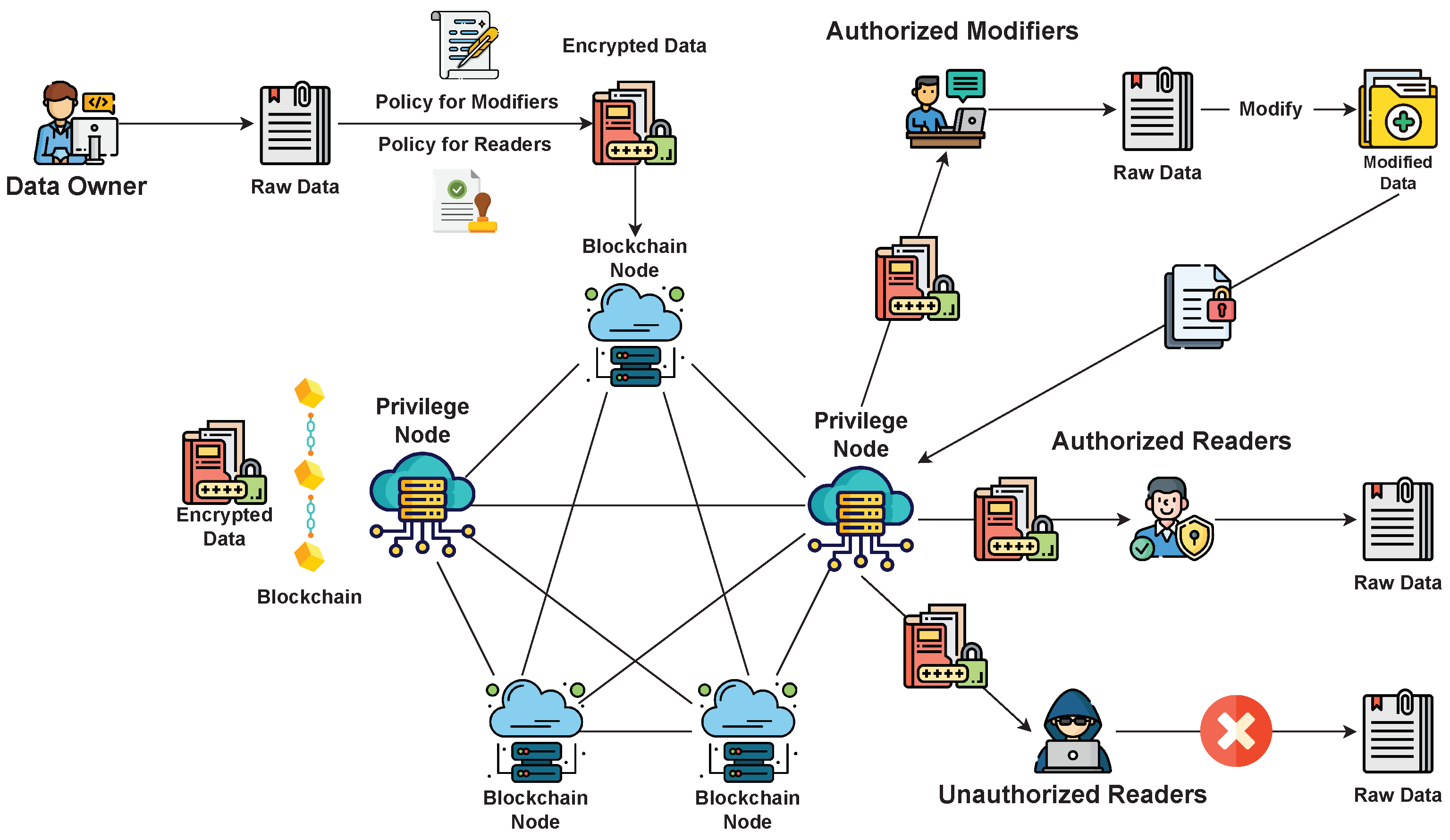
2.1. System Model
2.2. Threat Model
- Unauthorized access attack: Since encrypted data submitted by corresponding owners may contain commercially sensitive or private details, they become a prime target of potential adversaries. One such threat is the unauthorized access attack, whereby individuals without authorization may attempt to read or modify the data.
- Eavesdropping attack: An unauthorized party may eavesdrop on data transmitted through public channels in an attempt to deduce sensitive details from the intercepted ciphertext.
- User inferring attack: Attributes and policies may contain specific characteristics of individuals, such as their occupation, rank, or identity. An attack that expert adversaries may use to elicit sensitive information without knowing personal identifiers, such as the user identity or type of encrypted data, is known as the user inferring attack.
- Identity disguising attack: Access to encrypted data is determined based on specific attributes of individual users, including their identity. As a result, identity disguising attacks occur when unauthorized entities attempt to appear as authorized readers or modifiers. These attacks may involve disguising the encryption key with unauthorized attributes or attaching unauthorized attributes to obtained ciphertexts to mislead other entities. In some instances, unauthorized actors may alter or tamper with the message to deceive other parties.
- Collusion attack: Unauthorized entities may collaborate to perform various attacks, including those outlined above. For example, unauthorized users may pool their secret keys to recover encrypted data without proper authorization. They may also exchange keys to obtain encrypted data without proper authorization from the specified sender’s attributes.
2.3. Problem Statement and Design Goals
3. Preliminaries
3.1. Chameleon Hash
- PPGen(). This algorithm’s input is the security parameter . The output of this algorithm is the public parameters . Notably, we implicitly assume that is the input for the subsequent algorithms.
- KeyGen(). This algorithm uses the public parameters as input and generates the public key and secret key as output.
- HashGen(). This algorithm takes the public key and plaintext message m as input, and outputs the hash h and random value r.
- Verify(). This algorithm takes the public key , plaintext message m, random value r, and hash h as input, and generates the decision result d as output. Specifically, d is equal to 1 if the hash is valid, and 0 otherwise.
- Adapt(). This algorithm takes the secret key , plaintext message m, alternate message , random value r, and hash h as input, and generates the alternate random value as output.
3.2. Threshold Linear Shamir Secret Sharing
3.3. Bilinear Group
4. Proposed PRBFM
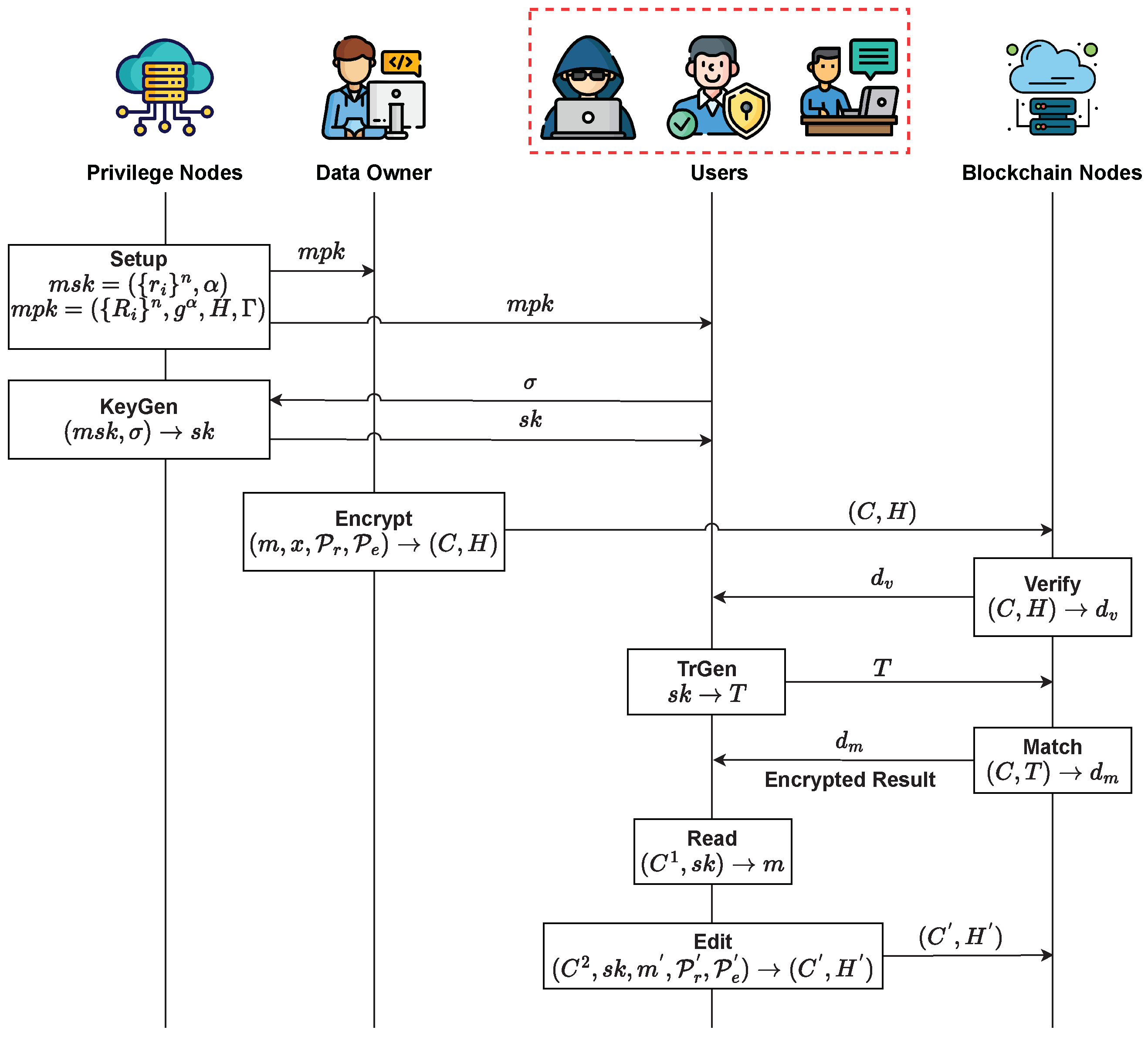
4.1. Brief Definition
- Setup (). The algorithm yields the master secret key and master public key when given a security parameter λ. For simplicity, is implicitly assumed to be taken as input by all other algorithms.
- KeyGen (). The algorithm takes σ and as inputs and produces the user’s secret key .
- Encrypt (). The algorithm takes message , Chameleon hash trapdoor x, readability policy , and editability policy as inputs and outputs ciphertext C along with the corresponding hash value .
- Verify (). The algorithm produces a verification result by validating the pair , with .
- TrGen (). The algorithm takes the secret key as input to generate the trapdoor T, which is composed of and .
- Match (). Given the trapdoor T and the ciphertext C, the algorithm outputs a match result to indicate different levels of access. Specifically, is returned when , and is returned when .
- Read (). Given the ciphertext and the secret key as inputs, the algorithm retrieves the message m only if . Otherwise, the algorithm returns an error symbol ⊥.
- Edit (). Given the ciphertext , secret key , and new message along with their respective policies , the algorithm generates a new ciphertext and hash value . Importantly, the editability feature preserves the correspondence of on-chain hashes and off-chain data.
4.2. Detailed Construction
- Generate the description of bilinear map , where . Subsequently, assume the attribute universe as and the size of as n. Set the threshold of policy matching as d. Next, generate n random values . Then, compute . Next, select a random value and a hash function .
- Generate the master secret key and the master public key .
- Randomly generate a -degree polynomial , where . Then, for each attribute , compute . Subsequently, utilize the Lagrange interpolation theorem to compute the Lagrange parameters .
- Generate the secret key . Then, return to the user.
- Select two random values and . Generate the readability policy . Compute and . Subsequently, compute and .
- Select two random values and , and the chameleon secret key x. Generate the editability policy . Subsequently, compute , , , and . To guarantee the right downward compatibility, compute .
- Select a random value to compute the chameleon hash .
- Generate the ciphertext , , and hash value .
- Send the pair to computation nodes and the chameleon hash h to the blockchain. Next, computation nodes upload the pairs to storage nodes.
- Check the equation . If the equation holds, output as 1. Otherwise, output as 0 prompts the storage nodes that the pair is invalid.
- Select a random value and compute . Then, utilize to compute .
- Generate the trapdoor and send T to computation nodes.
- Obtain ciphertexts from the storage nodes. Based on the threshold d, respectively select d values from and to conduct a set . Then, for each , check the equation .
- If the equation does not hold for all , computation nodes output . Otherwise, record the set and computation nodes output . In addition, it means that the user is an authorized reader of this message.
- If equals to 1, computation nodes further select d values from and to conduct a set . Then, for each , check the equation . If this equation holds, computation nodes output , and it means that the user is an authorized modifier for this message. Then, record the set .
- If equals to 1, return to the user. If equals to 2, return , , , , to the user.
- Compute . Recover the message .
- Perform the Read algorithm to recover the message m.
- Compute . Recover the message . If the user attempts to edit the message, generate a new message . Subsequently, generate new readability policy and editability policy and compute the ciphertext , . Next, compute = and generate .
- Send the new pair to computation nodes.
5. Analysis and Discussion
5.1. Correctness Analysis
5.2. Security Analysis
5.3. Complexity Analysis
5.4. Application Discussion
- Smart Medical: Drug testing in the smart medical scenario, based on mobile crowdsourcing, can utilize various sensors. Typically, access to these medical data is limited to patients with specific symptoms. However, attaining a 100% match using patients’ physiological data is not feasible, considering the variability of these numerical values. Furthermore, since these physiological data belong to the patients themselves, it is crucial to protect their privacy. Consequently, based on its characters, PRBFM can be applied in this scenario to overcome these challenges.
- Smart Transportation: Some companies may employ vehicles equipped with sensors to collect and update transportation data for the purpose of offering predictive services. However, to alleviate the server load, only vehicles in specific conditions (e.g., traffic jams) would be granted access to these prediction data, as using the strict match rule to judge the satisfaction of the conditions is unrealistic. Thus, in this scenario, there is a significant need for fuzzy matching with data privacy preservation, making it conducive to adopting PRBFM.
6. Experimental Evaluation
6.1. Experimental Settings
6.1.1. Setup
6.1.2. Dataset
6.1.3. Baselines for Comparison
6.1.4. Metrics
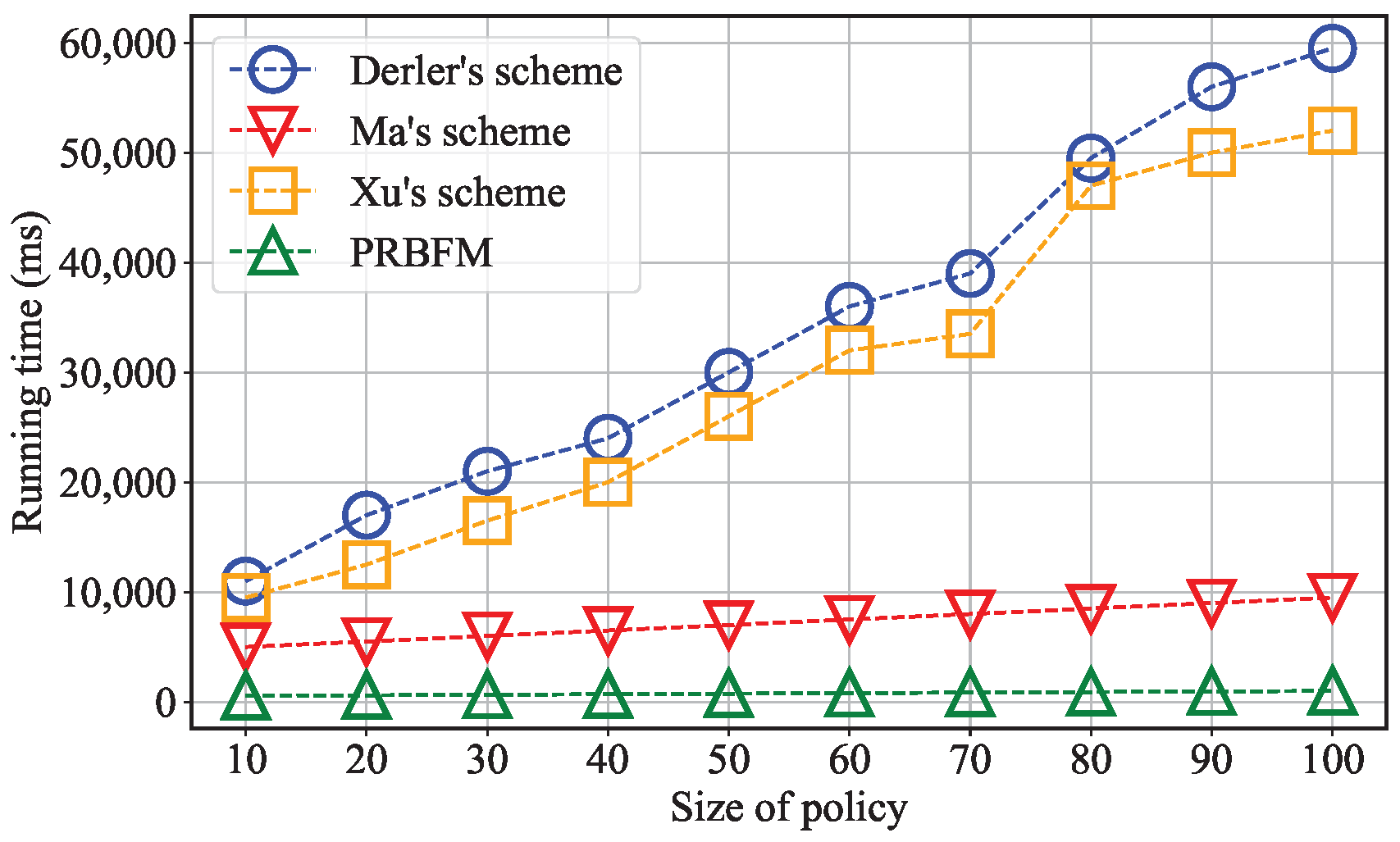
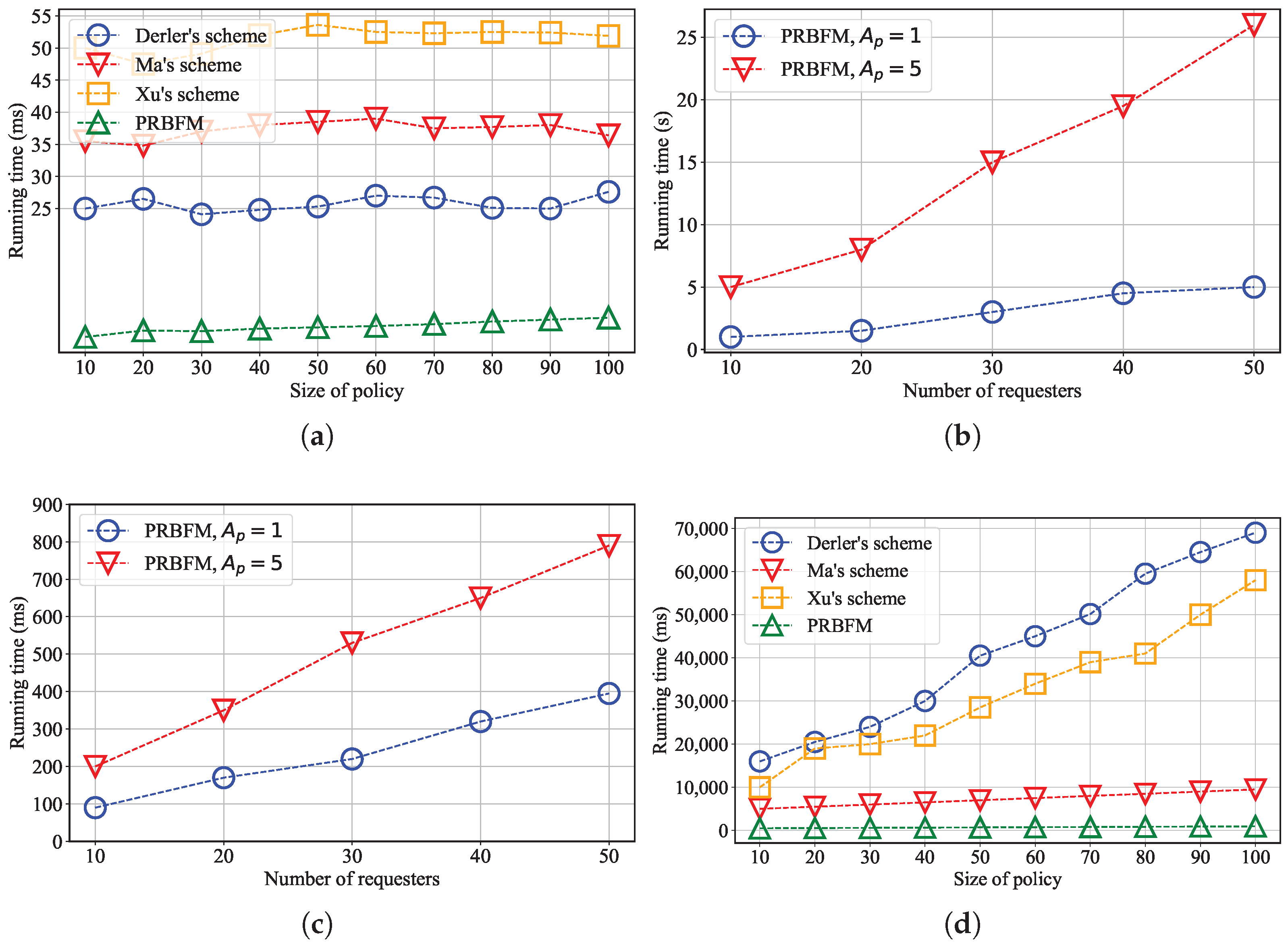
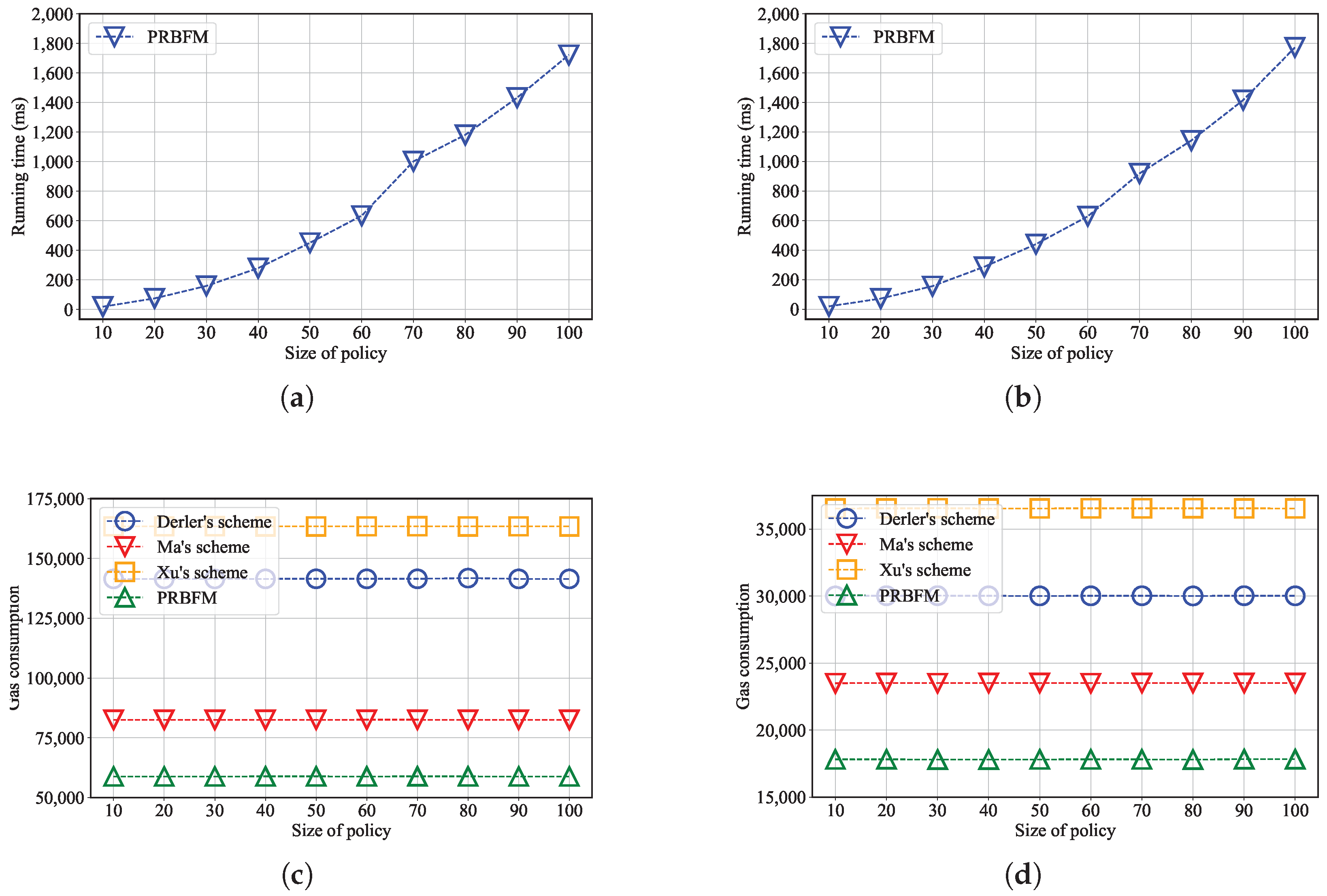
- The running time for key generation;
- Time consumption on the data owner side;
- Time consumption on the user side;
- Consumption on the blockchain node side.
6.2. Experimental Results
7. Related Works
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zou, S.; Xi, J.; Wang, H.; Xu, G. CrowdBLPS: A blockchain-based location-privacy-preserving mobile crowdsensing system. IEEE Trans. Ind. Inform. 2019, 16, 4206–4218. [Google Scholar] [CrossRef]
- Huang, J.; Kong, L.; Dai, H.N.; Ding, W.; Cheng, L.; Chen, G.; Jin, X.; Zeng, P. Blockchain-based mobile crowd sensing in industrial systems. IEEE Trans. Ind. Inform. 2020, 16, 6553–6563. [Google Scholar] [CrossRef]
- Wang, W.; Yang, Y.; Yin, Z.; Dev, K.; Zhou, X.; Li, X.; Qureshi, N.M.F.; Su, C. BSIF: Blockchain-based secure, interactive, and fair mobile crowdsensing. IEEE J. Sel. Areas Commun. 2022, 40, 3452–3469. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Zhu, L.; Zhang, W.; Wu, T.; Ni, J. FRUIT: A blockchain-based efficient and privacy-preserving quality-aware incentive scheme. IEEE J. Sel. Areas Commun. 2022, 40, 3343–3357. [Google Scholar]
- Zhang, C.; Zhao, M.; Zhu, L.; Wu, T.; Liu, X. Enabling efficient and strong privacy-preserving truth discovery in mobile crowdsensing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3569–3581. [Google Scholar] [CrossRef]
- Derler, D.; Samelin, K.; Slamanig, D.; Striecks, C. Fine-grained and controlled rewriting in blockchains: Chameleon-hashing gone attribute-based. Cryptol. Eprint Arch. 2019. [Google Scholar] [CrossRef]
- Ma, J.; Xu, S.; Ning, J.; Huang, X.; Deng, R.H. Redactable blockchain in decentralized setting. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1227–1242. [Google Scholar] [CrossRef]
- Xu, S.; Ning, J.; Ma, J.; Xu, G.; Yuan, J.; Deng, R.H. Revocable policy-based chameleon hash. In Proceedings of the Computer Security—ESORICS 2021: 26th European Symposium on Research in Computer Security, Darmstadt, Germany, 4–8 October 2021; Proceedings, Part I 26. Springer: Cham, Switzerland, 2021; pp. 327–347. [Google Scholar]
- Jia, M.; Chen, J.; He, K.; Du, R.; Zheng, L.; Lai, M.; Wang, D.; Liu, F. Redactable Blockchain From Decentralized Chameleon Hash Functions. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2771–2783. [Google Scholar] [CrossRef]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, pp. 10–5555. [Google Scholar]
- Alfonsín, J.M.L. Argentina: The right to be forgotten. In The Right to Be Forgotten: A Comparative Study of the Emergent Right’s Evolution and Application in Europe, the Americas, and Asia; Springer: Cham, Switzerland, 2020; pp. 239–248. [Google Scholar]
- Li, C.; Guan, L.; Wu, H.; Cheng, N.; Li, Z.; Shen, X.S. Dynamic Spectrum Control-Assisted Secure and Efficient Transmission Scheme in Heterogeneous Cellular Networks. Engineering 2022, 17, 220–231. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, C.; Wu, T.; Zhu, L.; Liu, X. Achieving Efficient and Privacy-Preserving Neural Network Training and Prediction in Cloud Environments. IEEE Trans. Dependable Secur. Comput. 2022; early access. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, C.; Lei, D.; Wu, T.; Liu, X.; Zhu, L. Achieving Privacy-Preserving and Verifiable Support Vector Machine Training in the Cloud. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3476–3491. [Google Scholar] [CrossRef]
- Li, J.; Ma, H.; Wang, J.; Song, Z.; Xu, W.; Zhang, R. Wolverine: A Scalable and Transaction-Consistent Redactable Permissionless Blockchain. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1653–1666. [Google Scholar] [CrossRef]
- Ateniese, G.; Magri, B.; Venturi, D.; Andrade, E. Redactable blockchain–or–rewriting history in bitcoin and friends. In Proceedings of the 2017 IEEE European Symposium on Security and Privacy (EuroS&P), Paris, France, 26–28 April 2017; IEEE: New York, NY, USA, 2017; pp. 111–126. [Google Scholar]
- Zhang, Z.; Li, T.; Wang, Z.; Liu, J. Redactable transactions in consortium blockchain: Controlled by multi-authority CP-ABE. In Proceedings of the Information Security and Privacy: 26th Australasian Conference, ACISP 2021, Virtual Event, 1–3 December 2021; Proceedings 26. Springer: Cham, Switzerland, 2021; pp. 408–429. [Google Scholar]
- Tian, Y.; Li, N.; Li, Y.; Szalachowski, P.; Zhou, J. Policy-based chameleon hash for blockchain rewriting with black-box accountability. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2020; pp. 813–828. [Google Scholar]
- Liu, Z.; Cao, Z.; Wong, D.S. Blackbox traceable CP-ABE: How to catch people leaking their keys by selling decryption devices on ebay. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 475–486. [Google Scholar]
- Liu, Z.; Cao, Z.; Wong, D.S. Traceable CP-ABE: How to trace decryption devices found in the wild. IEEE Trans. Inf. Forensics Secur. 2014, 10, 55–68. [Google Scholar]
- Xu, S.; Huang, X.; Yuan, J.; Li, Y.; Deng, R.H. Accountable and Fine-Grained Controllable Rewriting in Blockchains. IEEE Trans. Inf. Forensics Secur. 2022, 18, 101–116. [Google Scholar] [CrossRef]
- Zhang, D.; Le, J.; Lei, X.; Xiang, T.; Liao, X. Secure Redactable Blockchain With Dynamic Support. IEEE Trans. Dependable Secur. Comput. 2023; early access. [Google Scholar] [CrossRef]
- Shen, J.; Chen, X.; Liu, Z.; Susilo, W. Verifiable and Redactable Blockchains with Fully Editing Operations. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3787–3802. [Google Scholar] [CrossRef]
- Liu, Y.; He, D.; Feng, Q.; Luo, M.; Choo, K.K.R. PERCE: A Permissioned Redactable Credentials Scheme for a Period of Membership. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3132–3142. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Xu, Y.; Wu, T.; Li, Y.; Zhu, L.; Wang, H. Achieving fuzzy matching data sharing for secure cloud-edge communication. China Commun. 2022, 19, 257–276. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. Contactless fingerprint recognition based on global minutia topology and loose genetic algorithm. IEEE Trans. Inf. Forensics Secur. 2019, 15, 28–41. [Google Scholar] [CrossRef]
- Boutros, F.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Elasticface: Elastic margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1578–1587. [Google Scholar]
- Kumar, R.; Kumar, P.; Tripathi, R.; Gupta, G.P.; Islam, A.N.; Shorfuzzaman, M. Permissioned Blockchain and Deep Learning for Secure and Efficient Data Sharing in Industrial Healthcare Systems. IEEE Trans. Ind. Inform. 2022, 18, 8065–8073. [Google Scholar] [CrossRef]
- Shen, B.; Dong, C.; Minner, S. Combating copycats in the supply chain with permissioned blockchain technology. Prod. Oper. Manag. 2022, 31, 138–154. [Google Scholar] [CrossRef]
- Wu, L.; Lu, W.; Xue, F.; Li, X.; Zhao, R.; Tang, M. Linking permissioned blockchain to Internet of Things (IoT)-BIM platform for off-site production management in modular construction. Comput. Ind. 2022, 135, 103573. [Google Scholar] [CrossRef]
- Hunhevicz, J.; Dounas, T.; Hall, D.M. The promise of blockchain for the construction industry: A governance lens. In Blockchain for Construction; Springer: Singapore, 2022; pp. 5–33. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Falzon, F.; Markatou, E.A.; Espiritu, Z.; Tamassia, R. Range Search over Encrypted Multi-Attribute Data. Proc. VLDB Endow. 2022, 16, 587–600. [Google Scholar] [CrossRef]
- Servan-Schreiber, S.; Langowski, S.; Devadas, S. Private approximate nearest neighbor search with sublinear communication. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–25 May 2022; IEEE: New York, NY, USA, 2022; pp. 911–929. [Google Scholar]
- Camenisch, J.; Derler, D.; Krenn, S.; Pöhls, H.C.; Samelin, K.; Slamanig, D. Chameleon-Hashes with Ephemeral Trapdoors: And Applications to Invisible Sanitizable Signatures. In Proceedings of the Public-Key Cryptography—PKC 2017: 20th IACR International Conference on Practice and Theory in Public-Key Cryptography, Amsterdam, The Netherlands, 28–31 March 2017; Proceedings, Part II 20. Springer: Cham, Switzerland, 2017; pp. 152–182. [Google Scholar]
- Agrawal, S.; Chase, M. FAME: Fast attribute-based message encryption. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 665–682. [Google Scholar]
- Deuber, D.; Magri, B.; Thyagarajan, S.A.K. Redactable blockchain in the permissionless setting. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: New York, NY, USA, 2019; pp. 124–138. [Google Scholar]
- Panwar, G.; Vishwanathan, R.; Misra, S. ReTRACe: Revocable and traceable blockchain rewrites using attribute-based cryptosystems. In Proceedings of the 26th ACM Symposium on Access Control Models and Technologies, Virtual, 16–18 June 2021; pp. 103–114. [Google Scholar]
- Xu, S.; Ning, J.; Ma, J.; Huang, X.; Deng, R.H. K-time modifiable and epoch-based redactable blockchain. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4507–4520. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Liang, H.; Zhao, M.; Xiao, Y.; Wu, T.; Xue, J.; Zhu, L. Privacy-Preserving Fine-Grained Redaction with Policy Fuzzy Matching in Blockchain-Based Mobile Crowdsensing. Electronics 2023, 12, 3416. https://doi.org/10.3390/electronics12163416
Guo H, Liang H, Zhao M, Xiao Y, Wu T, Xue J, Zhu L. Privacy-Preserving Fine-Grained Redaction with Policy Fuzzy Matching in Blockchain-Based Mobile Crowdsensing. Electronics. 2023; 12(16):3416. https://doi.org/10.3390/electronics12163416
Chicago/Turabian StyleGuo, Hongchen, Haotian Liang, Mingyang Zhao, Yao Xiao, Tong Wu, Jingfeng Xue, and Liehuang Zhu. 2023. "Privacy-Preserving Fine-Grained Redaction with Policy Fuzzy Matching in Blockchain-Based Mobile Crowdsensing" Electronics 12, no. 16: 3416. https://doi.org/10.3390/electronics12163416
APA StyleGuo, H., Liang, H., Zhao, M., Xiao, Y., Wu, T., Xue, J., & Zhu, L. (2023). Privacy-Preserving Fine-Grained Redaction with Policy Fuzzy Matching in Blockchain-Based Mobile Crowdsensing. Electronics, 12(16), 3416. https://doi.org/10.3390/electronics12163416