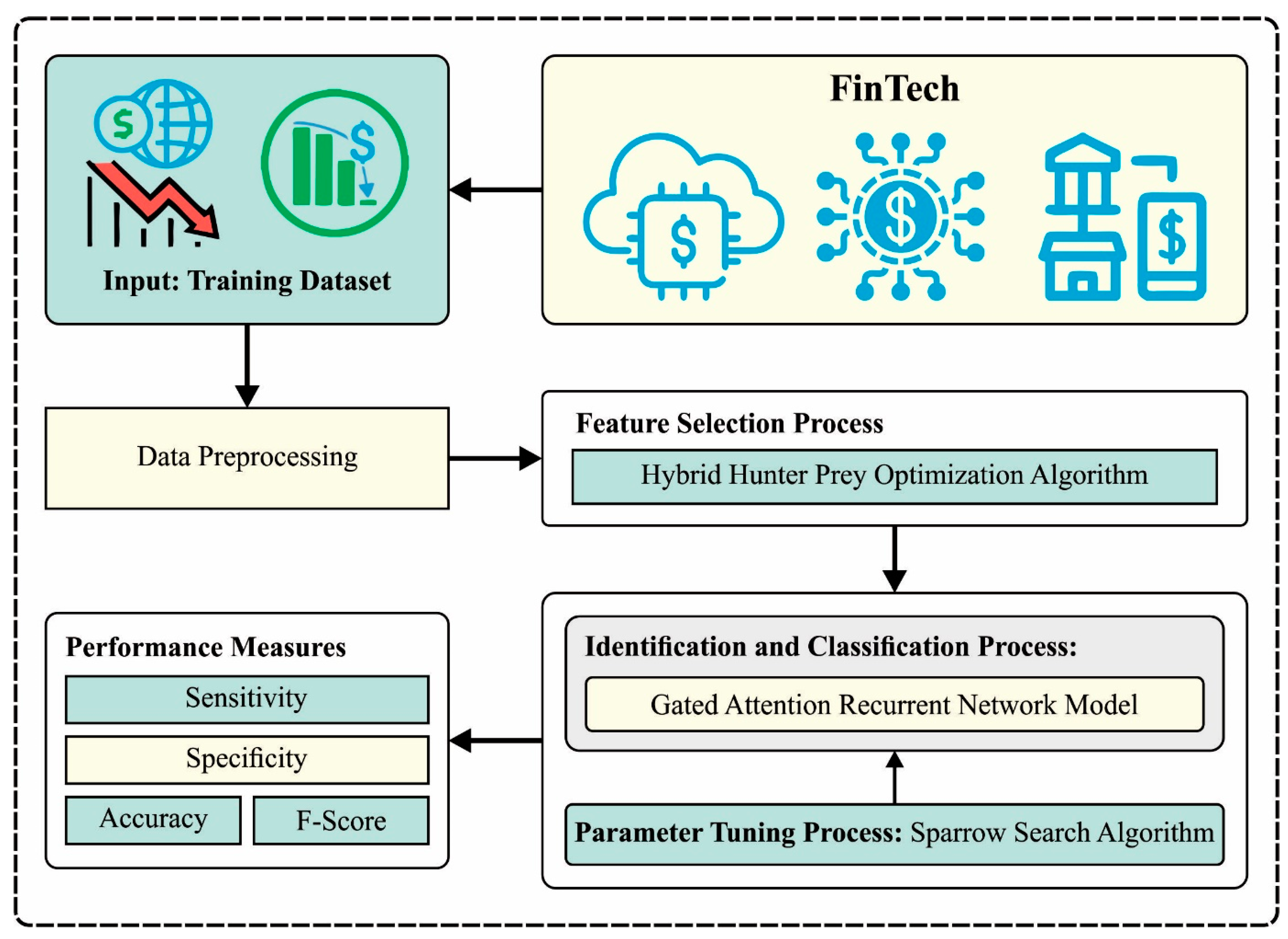
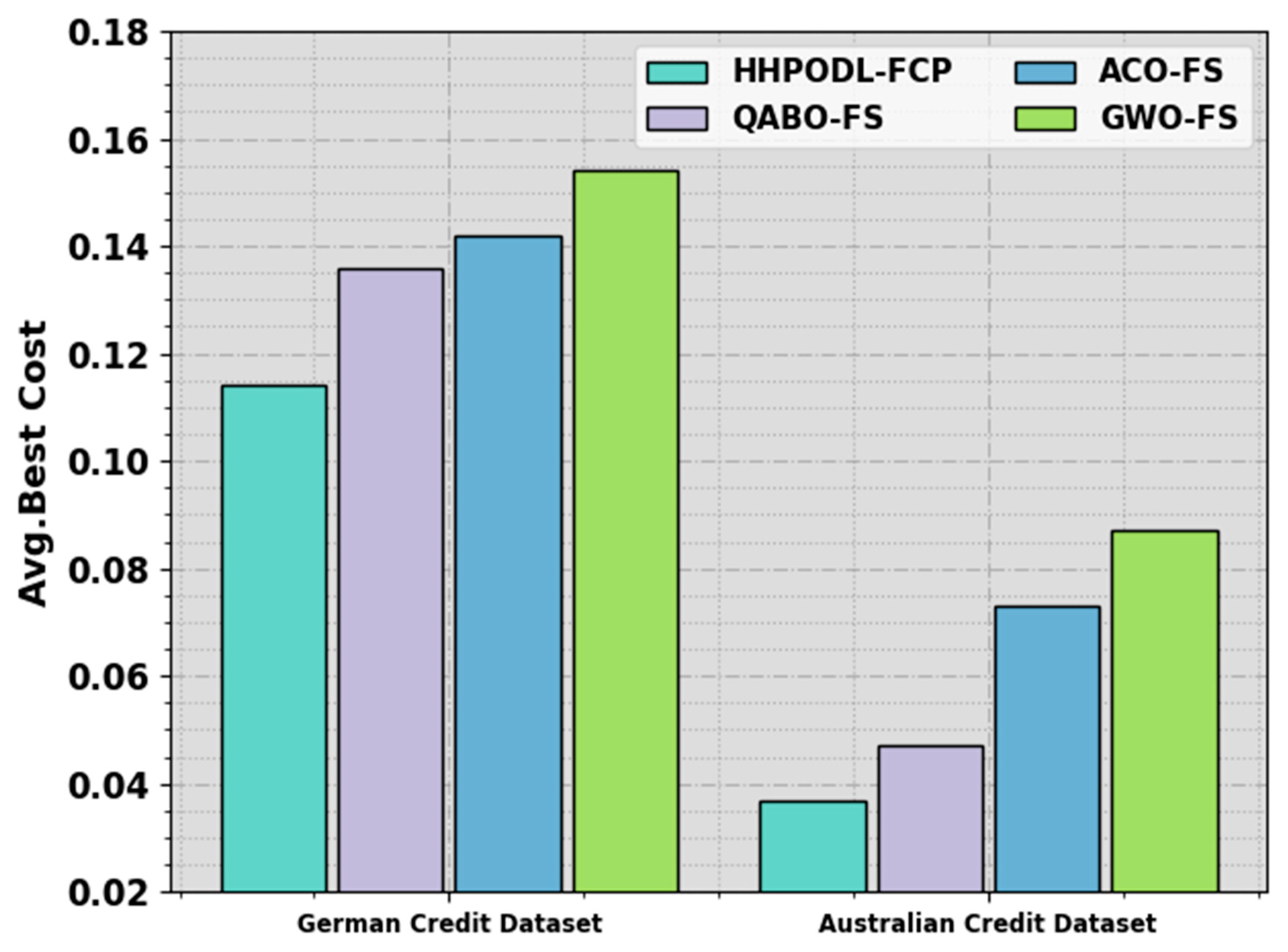
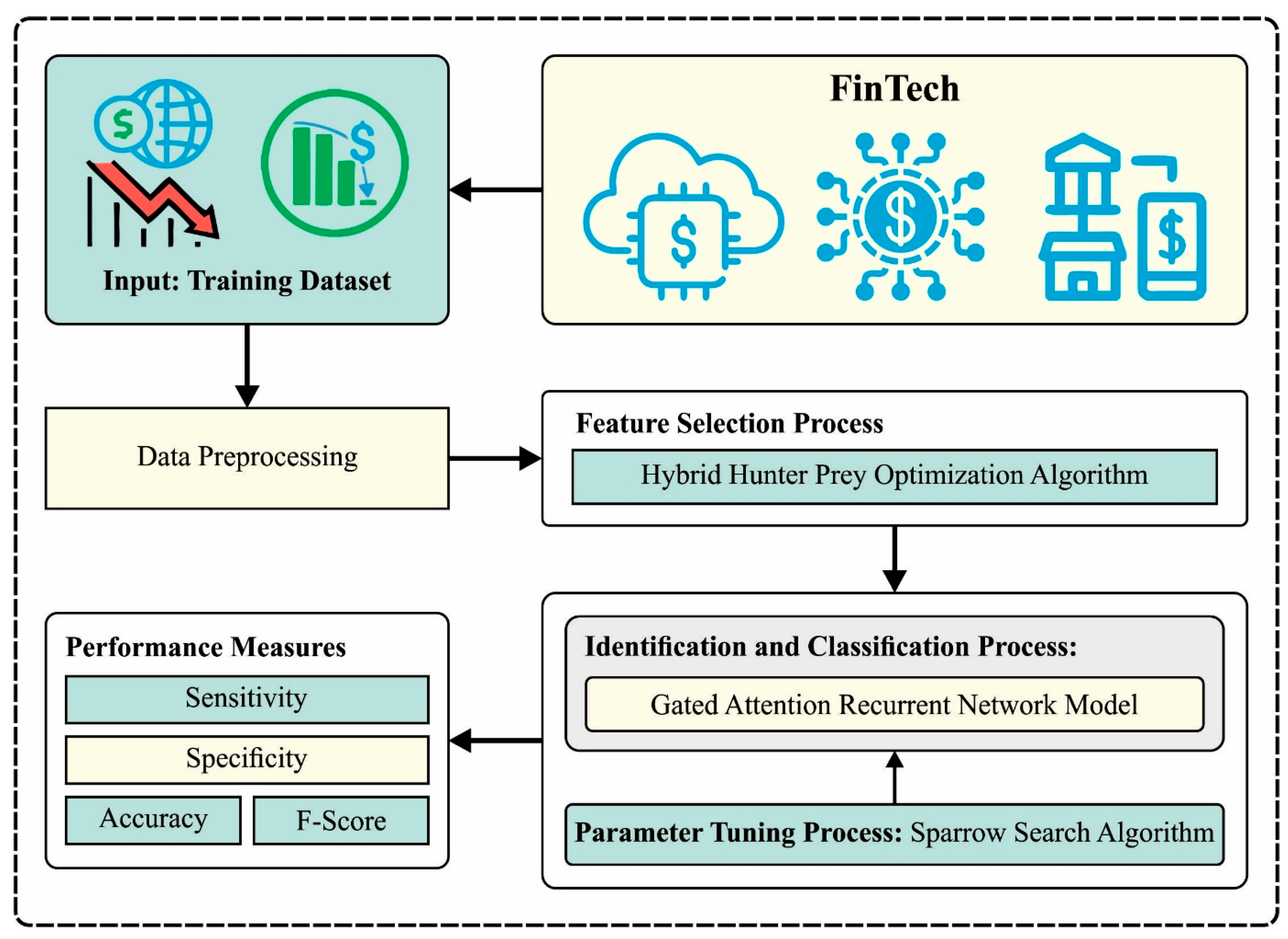
3.1. Design of HHPO-Based Feature Selection
At the primary stage, the HHPO algorithm is used to choose an optimal set of features [
19]. In the HPO technique, the search process for the hunter is expressed by Equation (1).
The variable
defines the predator’s location, and
stands for the place of prey. Additionally,
represents the mean of every position, and
denotes the adaptive parameter calculated by employing Equation (2).
where
and
imply the stochastic vector in the range of zero and one
defines the randomly generated number in the interval [
], and
suggests the index amount of the vector which fulfills the
condition.
The key parameter
is used to balance among exploration and exploitation stages whose value slowly reduces from a primary value of
to a minimal threshold of 0.02. This value can be defined by applying Equation (3).
Afterward, the purpose of the prey position
proceeds by primary computation of the mean
of every position expressed by Equation (4), then, the distance calculation
among the entire individual is studied, and the mean position is written in Equation (5).
If you engage in hunting performances, it is general practice to hunt for capturing and chasing prey, which leads to the death of the prey. Then, the hunters need to find a novel place to endure hunting. To overcome the convergence issue, which is inherent in the present method as demonstrated in Equation (6), it can be suggested to execute a diminishing process.
where
parameter implies the count of searching populations from the optimizer manner. In the beginning, the
value corresponded to the size of the population. The farthermost searching individuals in the selected target
are labeled as prey
and are consequently caught by the hunters. For determining the prey’s place
Equation (7) is established in Equations (4)–(6) over a rigorous analytical procedure.
If the prey anticipates the attack, it will instinctively search for refuge in a safe place. It can be assumed that the optimum safe place is none except the global optimum location, as it gives the prey the highest possibility of survival. Subsequently, the predator drive chooses a novel prey location, which can be obtained by employing Equation (8) for updating the prey’s location.
where the present prey places are defined by the parameter
, which is a critical element in the optimizer method. The global optimal location is represented by
, but the variable
refers to the arbitrary number in the range [0, 1]. The
function and the input parameters can be employed for calculating the next location of prey that is tactically located at a distinct radius and angle in the global optimal location for enhancing the method. The purpose of the prey and hunter is accomplished by configuring the alteration
parameter that is presented at a value of
. Additionally, the parameter
is an arbitrarily created number within [
]. Particularly, the hunter location can be updated by Equation (1) if
, while Equation (8) is used for updating the prey location.
In the design of the HHPO algorithm, the Tent chaos mapping and opposition-based learning (OBL) approach called TOBL was proposed to enhance population quality. The population intelligence optimization algorithm widely uses random generation for initializing the population. This nonuniform distribution has a direct impact on the convergence rate and performance of the optimization technique for identifying the optimum result. Good traversal, chaotic sequence, and possessing diversity characteristics were introduced as promising solutions to these issues. Prey population, which integrates chaotic sequences, namely cubic mapping, Tent mapping, logistic mapping, and circle mapping, exhibits the best diversity Tent chaotic mapping, described by better convergence speed and traversal uniformity, which creates a uniform distribution chaotic sequence in the interval of .
The formula of Tent chaotic mapping is shown as follows:
In Equation (9),
indicates the amount of chaos produced after
iterations,
, whereas
shows a constant between
By using a uniform variation of Tent, the TOBL approach includes dynamic compression of the distribution range with the sum of lower and upper boundaries of the objective function. The final objective is to guarantee uniformity in the population.
The steps of the TOBL algorithm are given in the following: consider an number of populations. First, population position was generated at random, then, the chaotic opposing position was generated by TOBL, and then, position was ranked with respect to fitness, and the top position was chosen as the initial population.
The TOBL approach includes the following subsequent stages: assume a population size of ; initially, the population position was randomly generated. Next, the chaotic opposing position was produced by the TOBL. Later, based on the respective fitness level, the position was ranked, and the top position was chosen for the population initialization.
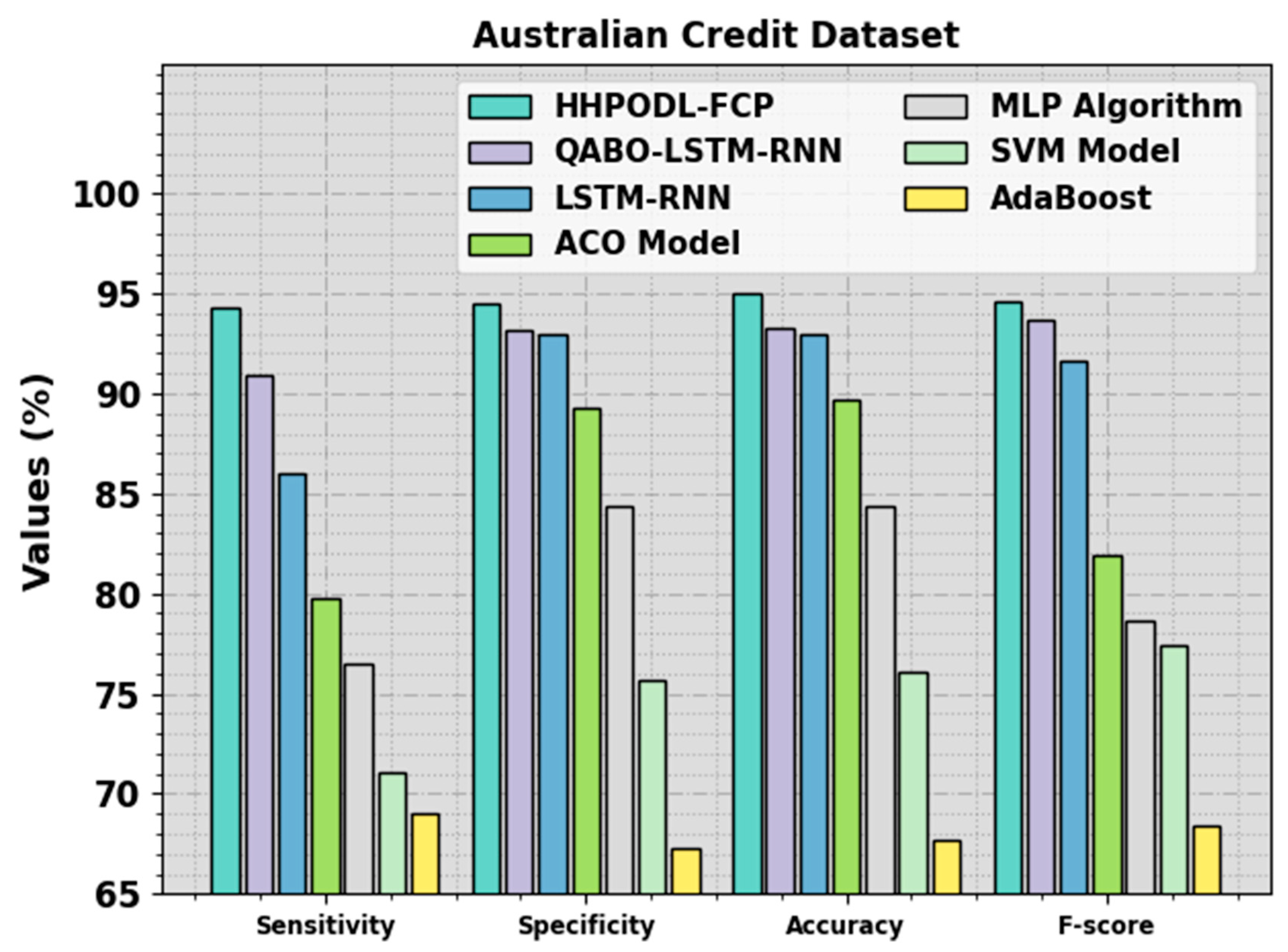
In the HHPO approach, FF is used to balance the classification accuracy (maximal) and the number of features selected in the solution (minimal). Equation (11) represents the FF to estimate the solution.
where
denotes the cardinality of the selected subset,
shows the classification error rate of a given classifier.
refers to the overall amount of features in the dataset, and the two parameters
and
correspond to the significance of classification quality and subset length. ∈ [1, 0] and
3.3. Hyperparameter Tuning Using SSA
The SSA is applied in this study to adjust the hyperparameter values of the GARN model. SSA is a metaheuristic optimization technique based on the foraging and anti-predation behaviors of sparrows [
21]. In this work, discoverers, followers, and watchers are three different strategies of individuals in SSA. The mathematical expression and natural behaviors of sparrows were defined as follows:
Discoverers: All the generations of discoverers signify a point in the population, i.e., nearer to food, and their major objective is to provide direction for the whole population to search for food. The formula for the updating position of the discoverers can be given as the following:
In Equation (15), shows the maximal amount of iterations, denotes the location of the sparrows in the dimension at iterations, indicates the safety threshold, and represents randomly generated values within [], stands for the vector with the element, and denotes the uniformly distributed random integer. If the discoverers can extensively search for food. If then there is danger, and the discoverers must withdraw from the danger zone.
Followers: The follower’s role is to follow the discoverers searching for food. The updating strategy can be given below:
In Equation (16), shows that the present follower is in a poor location and extensively searches for food by deviating from the worst individuals; or else, the food search can be done by competing with other optimal individuals. indicates the random vector with values of or for all the elements, , correspondingly showing the individuals with the best individuals and worst current fitness.
Vigilantes are random proportions of an individual in the population whose primary task is to alert the foraging region. The formula can be given as follows:
In Equation (17), shows the random value between and ; , and represent the fitness function of the existing alert, optimum, and worst individuals, correspondingly; denotes the update step with a mean of and variance of ; and is used to prevent a constant with a denominator of The sparrow individual at the center of the population feels threatened if , and move towards its species, which reduces the predation risk; and the sparrow at the edge of the population if and thereby approaches other optimum individuals.
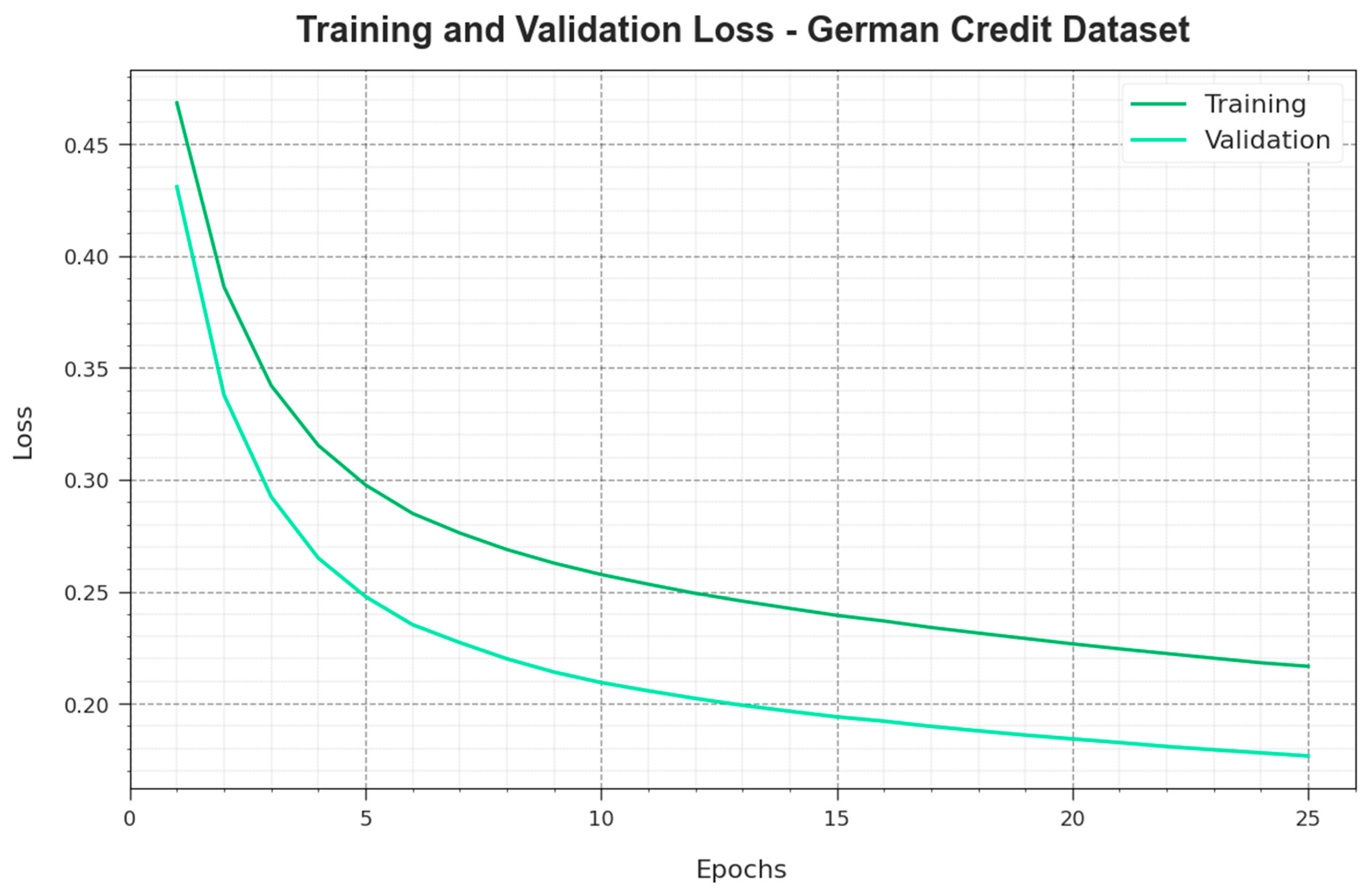
The SSA approach derives a fitness function from obtaining the high efficiency of the GARN classification model. The fitness function describes a positive integer to represent the best outcomes of the solution candidate. The decline in the classification error rate can be defined as a FF.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}