
A Fast Weight Control Strategy for Programmable Linear RAM Based on the Self-Calibrating Erase Operation

 ,
,
Abstract
:1. Introduction
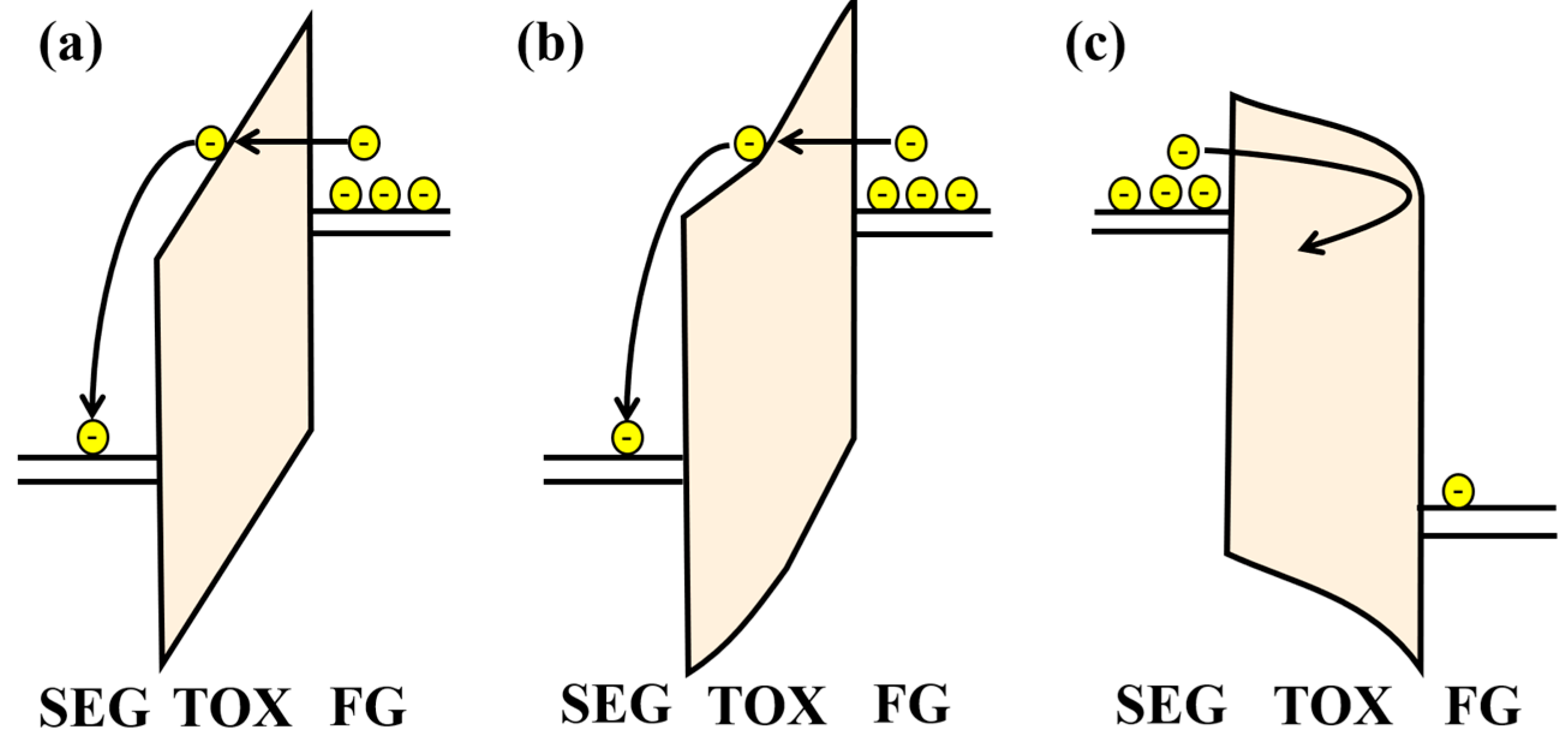
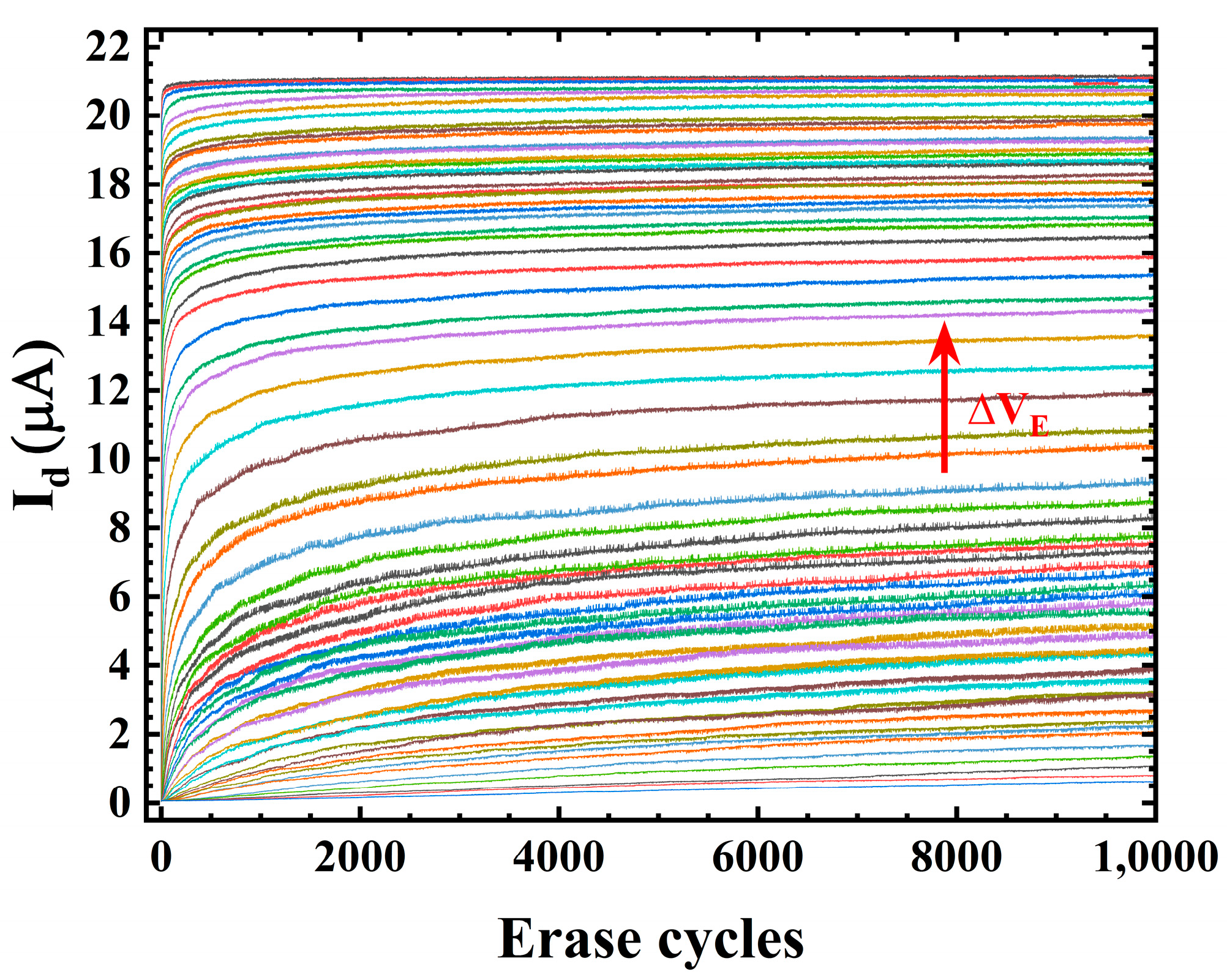
2. Physical Characterization Analysis
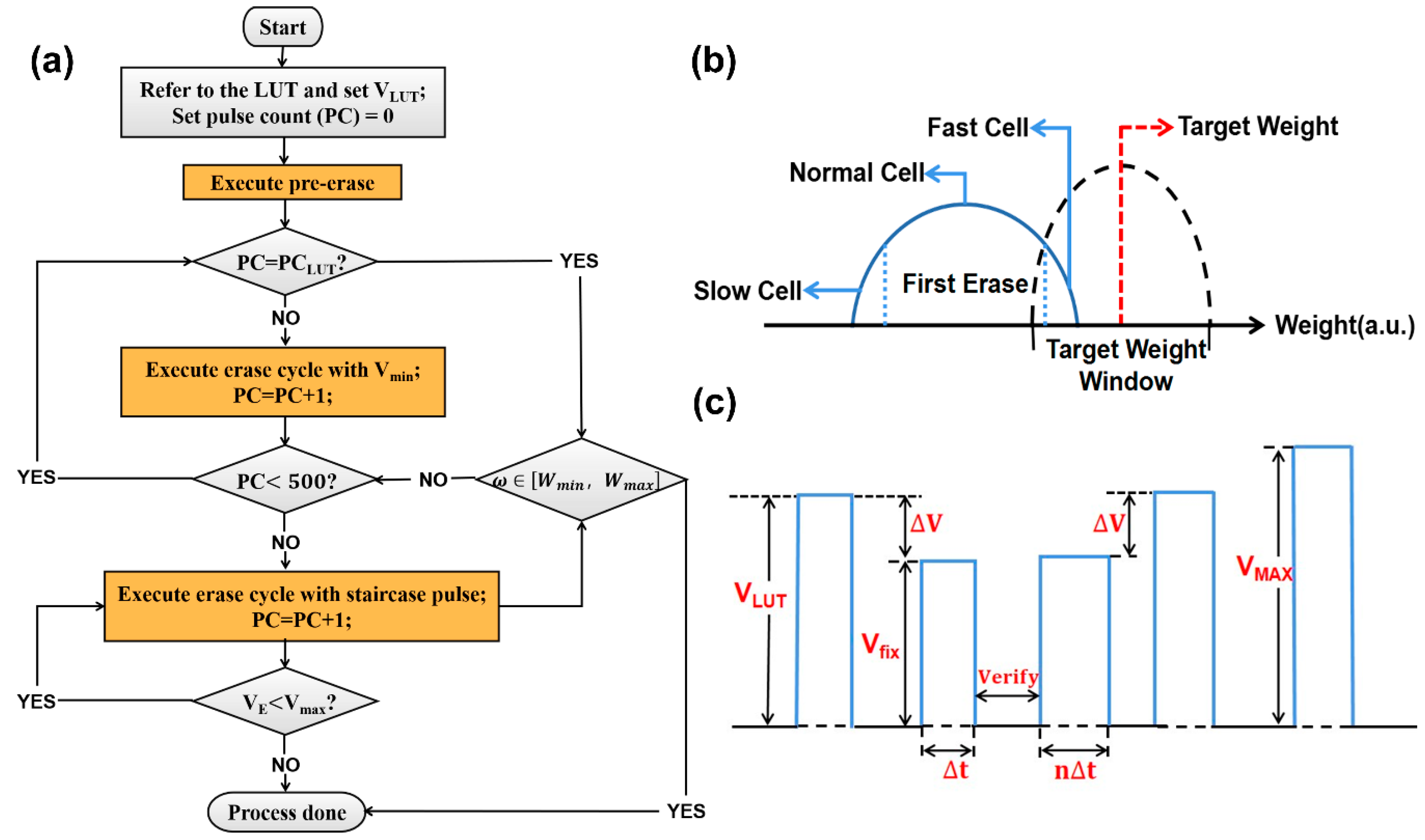
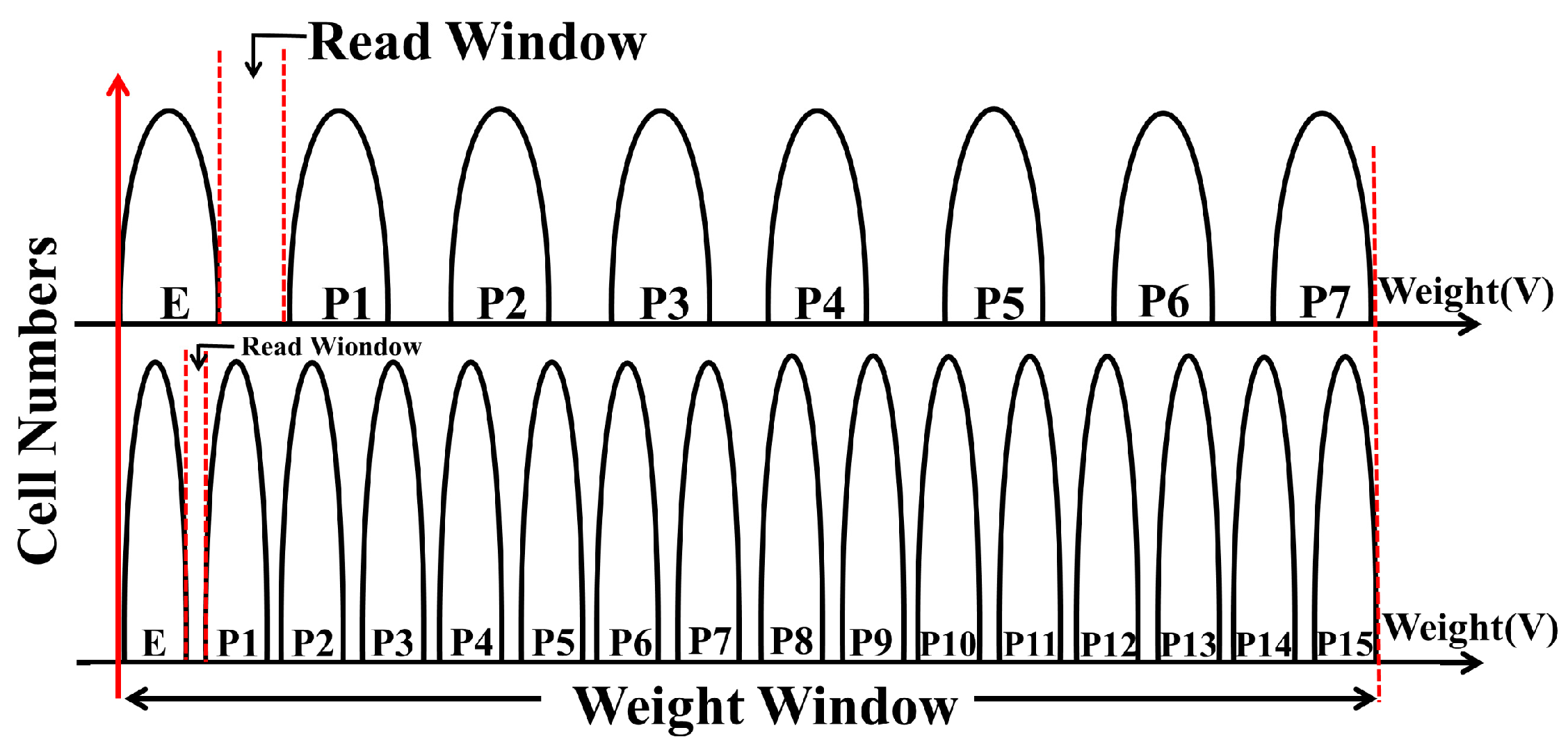
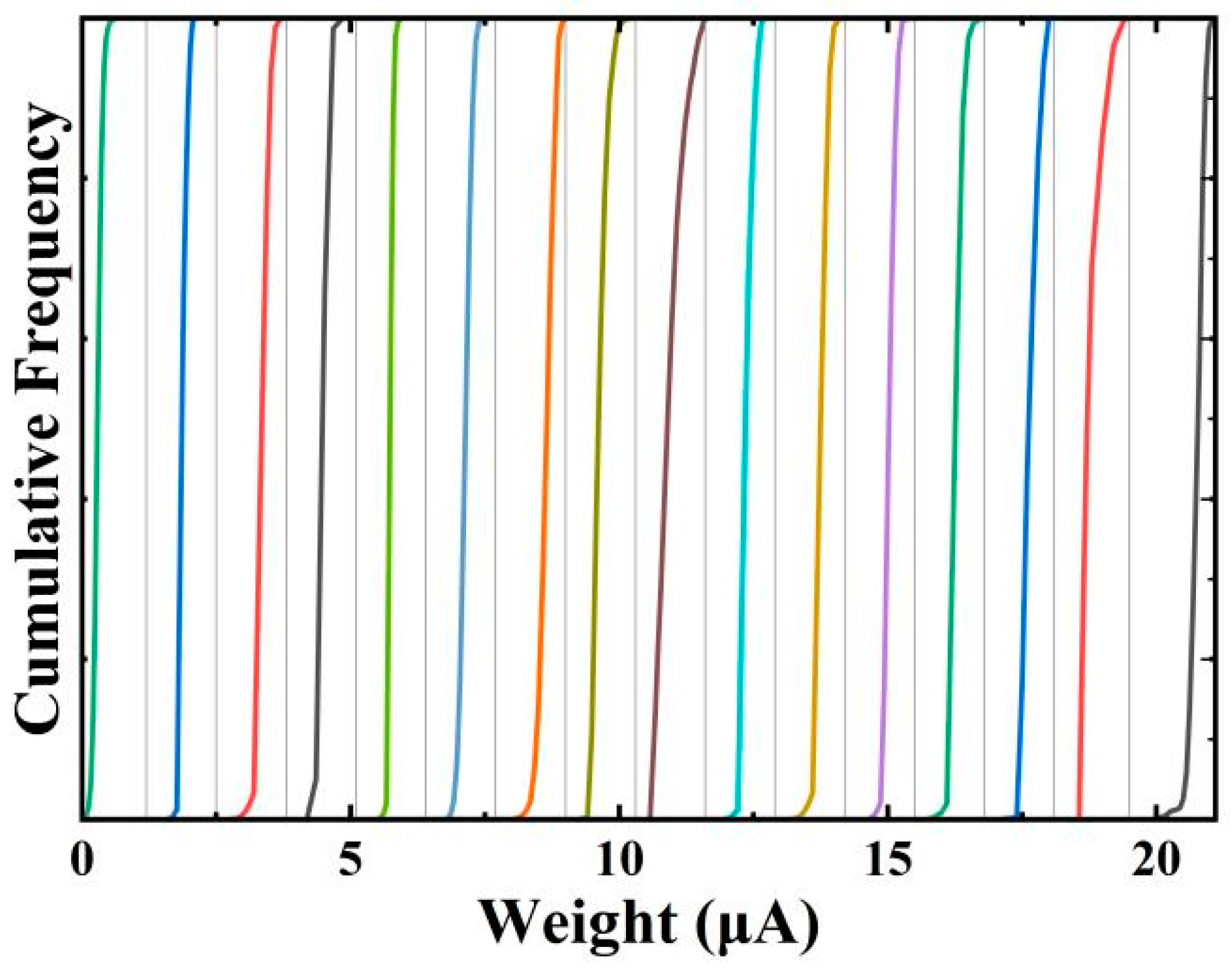
3. Algorithm and Verification
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qureshi, Z.; Mailthody, V.S.; Min, S.W.; Chung, I.-H.; Xiong, J.; Hwu, W. Tearing down the memory wall. arXiv 2020, arXiv:2008.10169. [Google Scholar]
- Wulf, W.A.; McKee, S.A. Hitting the Memory Wall: Implications of the Obvious. ACM Sigarch Comput. Archit. News 1995, 23, 20–24. [Google Scholar] [CrossRef]
- Ielmini, D.; Wong, H.-S.P. In-memory computing with resistive switching devices. Nat. Electron. 2018, 1, 333–343. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 14–28 June 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Pawlowski, J.T. Hybrid Memory Cube (HMC). In Proceedings of the 2011 IEEE Hot Chips 23 Symposium (HCS), Stanford, CA, USA, 17–19 August 2011; pp. 1–24. [Google Scholar] [CrossRef]
- Lee, D.U.; Kim, K.W.; Kim, K.W.; Kim, H.; Kim, J.Y.; Park, Y.J.; Kim, J.H.; Kim, D.S.; Park, H.B.; Shin, J.W.; et al. 25.2 A 1.2V 8Gb 8-channel 128GB/s high-bandwidth memory (HBM) stacked DRAM with effective microbump I/O test methods using 29nm process and TSV. In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 432–433. [Google Scholar] [CrossRef]
- Di Ventra, M.; Pershin, Y.V. The parallel approach. Nat. Phys. 2013, 9, 200–202. [Google Scholar] [CrossRef]
- Indiveri, G.; Liu, S.C. Memory and Information Processing in Neuromorphic Systems. Proc. IEEE 2018, 103, 1379–1397. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W.; Liu, Q.; Zhao, X.; Wei, J.; Cao, R.; Yao, Z.; Zhu, X.; Zhang, F.; Lv, H.; et al. An Artificial Neuron Based on a Threshold Switching Memristor. IEEE Electron Device Lett. 2017, 39, 308–311. [Google Scholar] [CrossRef]
- Luo, Q.; Xu, X.; Gong, T.; Lv, H.; Dong, D.; Ma, H.; Yuan, P.; Gao, J.; Liu, J.; Yu, Z.; et al. 8-layers 3D Vertical RRAM with Excellent Scalability towards Storage Class Memory Applications. In Proceedings of the IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 2–6 December 2017; pp. 2.7.1–2.7.4. [Google Scholar] [CrossRef]
- Shin, J.H.; Jeong, Y.J.; Zidan, M.A.; Wang, Q.; Lu, W.D. Hardware Acceleration of Simulated Annealing of Spin Glass by RRAM Crossbar Array. In Proceedings of the 2018 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 1–5 December 2018; pp. 3.3.1–3.3.4. [Google Scholar] [CrossRef]
- Narayanan, P.; Burr, G.W.; Virwani, K.; Kurdi, B.N. Circuit-Level Benchmarking of Access Devices for Resistive Nonvolatile Memory Arrays. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 330–338. [Google Scholar] [CrossRef]
- Ambrogio, S.; Narayanan, P.; Tsai, H.; Shelby, R.M.; Boybat, I.; di Nolfo, C.; Sidler, S.; Giordano, M.; Bodini, M.; Farinha, N.C.P.; et al. Equivalent-accuracy accelerated neural-network training using analogue memory. Nature 2018, 558, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Tsai, H.; Ambrogio, S.; Mackin, C.; Narayanan, P.; Shelby, R.M.; Rocki, K.; Chen, A.; Bur, G.W. Inference of Long-Short Term Memory Networks at Software-Equivalent Accuracy Using 2.5 M analog Phase Change Memory Devices. In Proceedings of the 2019 Symposium on VLSI Technology, Kyoto, Japan, 9–14 June 2019; pp. T82–T83. [Google Scholar] [CrossRef]
- Gao, S.; Hu, J.; Xiao, J.; Zhang, B. Programmable Linear RAM: A New Flash Memory-based Memristor for Artificial Synapses and Its Application to Speech Recognition System. In Proceedings of the 2019 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 14.1.1–14.1.4. [Google Scholar] [CrossRef]
- Zhao, L.; Gao, S.; Zhang, S.; Qiu, X.; Yang, F.; Li, J.; Chen, Z.; Zhao, Y. Neural network acceleration and voice recognition with a flash-based in-memory computing SoC. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Ricco, B.; Torelli, G.; Lanzoni, M.; Manstretta, A.; Maes, H.E.; Montanari, D.; Modelli, A. Nonvolatile multilevel memories for digital applications. Proc. IEEE 1998, 86, 2399–2423. [Google Scholar] [CrossRef]
- Gao, S.; Cong, Y.; Zhang, Z.; Qiu, X.; Lee, C.; Zhao, Y. Superior Data Retention of Programmable Linear RAM (PLRAM) for Compute-in-Memory Application. In Proceedings of the 2020 IEEE International Reliability Physics Symposium (IRPS), Dallas, TX, USA, 28 April–30 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Tkachev, Y.; Liu, X.; Kotov, A. Floating-Gate Corner-Enhanced Poly-to-Poly Tunneling in Split-Gate Flash Memory Cells. IEEE Trans. Electron Devices 2011, 59, 5–11. [Google Scholar] [CrossRef]
- Lenzlinger, M.; Snow, E.H. Fowler-Nordheim Tunneling into Thermally Grown SiO2. J. Appl. Phys. 1969, 40, 278–283. [Google Scholar] [CrossRef]
- Hemink, G.J.; Tanaka, T.; Endoh, T.; Aritome, S.; Shirota, R. Fast and accurate programming method for multi-level NAND EEPROMs. In Proceedings of the 1995 Symposium on VLSI Technology, Kyoto, Japan, 6–8 June 1995; pp. 129–130. [Google Scholar] [CrossRef]
- Shibata, N.; Maejima, H.; Isobe, K.; Iwasa, K.; Nakagawa, M.; Fujiu, M.; Shimizu, T.; Honma, M.; Hoshi, S.; Kawaai, T.; et al. A 70 nnm 16 Gb 16-level-cell NAND Flash Memory. In Proceedings of the 2007 IEEE Symposium on VLSI Circuits, Kyoto, Japan, 14–16 June 2007; pp. 190–191. [Google Scholar] [CrossRef]
- Trinh, C.; Shibata, N.; Nakano, T.; Ogawa, M. A 5.6 MB/s 64 Gb 4b/Cell NAND Flash memory in 43 nm CMOS. In Proceedings of the 2009 IEEE International Solid-State Circuits Conference-Digest of Technical Papers, San Francisco, CA, USA, 8–12 February 2009; pp. 246–247. [Google Scholar] [CrossRef]
- Shibata, N.; Kanda, K.; Shimizu, T.; Nakai, J.; Nagao, O.; Kobayashi, N.; Miakashi, M.; Nagadomi, Y.; Nakano, T.; Kawabe, T.; et al. A 1.33-Tb 4-Bit/Cell 3-D Flash Memory on a 96-Word-Line-Layer Technology. IEEE J. Solid-State Circuits 2020, 55, 178–188. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, D.; Zhao, G.; Sun, Z.; Bai, M.; Qi, Y.; Gong, X.; Liu, J.; Zhang, J.; Wu, J.; et al. A Novel Array Programming Scheme for Large Matrix Processing in Flash-Based Computing-in-Memory (CIM) with Ultrahigh Bit Density. IEEE Trans. Electron Devices 2023, 70, 461–467. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | This Work | 16-16 Two-Step Programming [23] | Three-Step Programming [24] | 8-16 Two-Step Programming [25] | IPNPP [26] |
|---|---|---|---|---|---|
| Circuit | NOR | NAND | NAND | NAND | NOR |
| Process | 90 nm | 70 nm | 43 nm | BiCS | 55 nm |
| Verification steps | 10 | 555 | About 600 | About 455 | 15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Liu, Y.; Zhou, X.; Yang, J.; Li, Z.; Mei, Y.; Yu, W.; Zhu, B.; Wu, X.; Ding, S.; et al. A Fast Weight Control Strategy for Programmable Linear RAM Based on the Self-Calibrating Erase Operation. Electronics 2023, 12, 3466. https://doi.org/10.3390/electronics12163466
Li Y, Liu Y, Zhou X, Yang J, Li Z, Mei Y, Yu W, Zhu B, Wu X, Ding S, et al. A Fast Weight Control Strategy for Programmable Linear RAM Based on the Self-Calibrating Erase Operation. Electronics. 2023; 12(16):3466. https://doi.org/10.3390/electronics12163466
Chicago/Turabian StyleLi, Yanfei, Yinchi Liu, Xinlong Zhou, Jining Yang, Zehui Li, Yihang Mei, Wenjie Yu, Bao Zhu, Xiaohan Wu, Shijin Ding, and et al. 2023. "A Fast Weight Control Strategy for Programmable Linear RAM Based on the Self-Calibrating Erase Operation" Electronics 12, no. 16: 3466. https://doi.org/10.3390/electronics12163466