
Privacy-Friendly Task Offloading for Smart Grid in 6G Satellite–Terrestrial Edge Computing Networks †

Abstract
:1. Introduction
2. Background and Related Works
2.1. Task Offloading in Satellite–Terrestrial Cooperative Networks
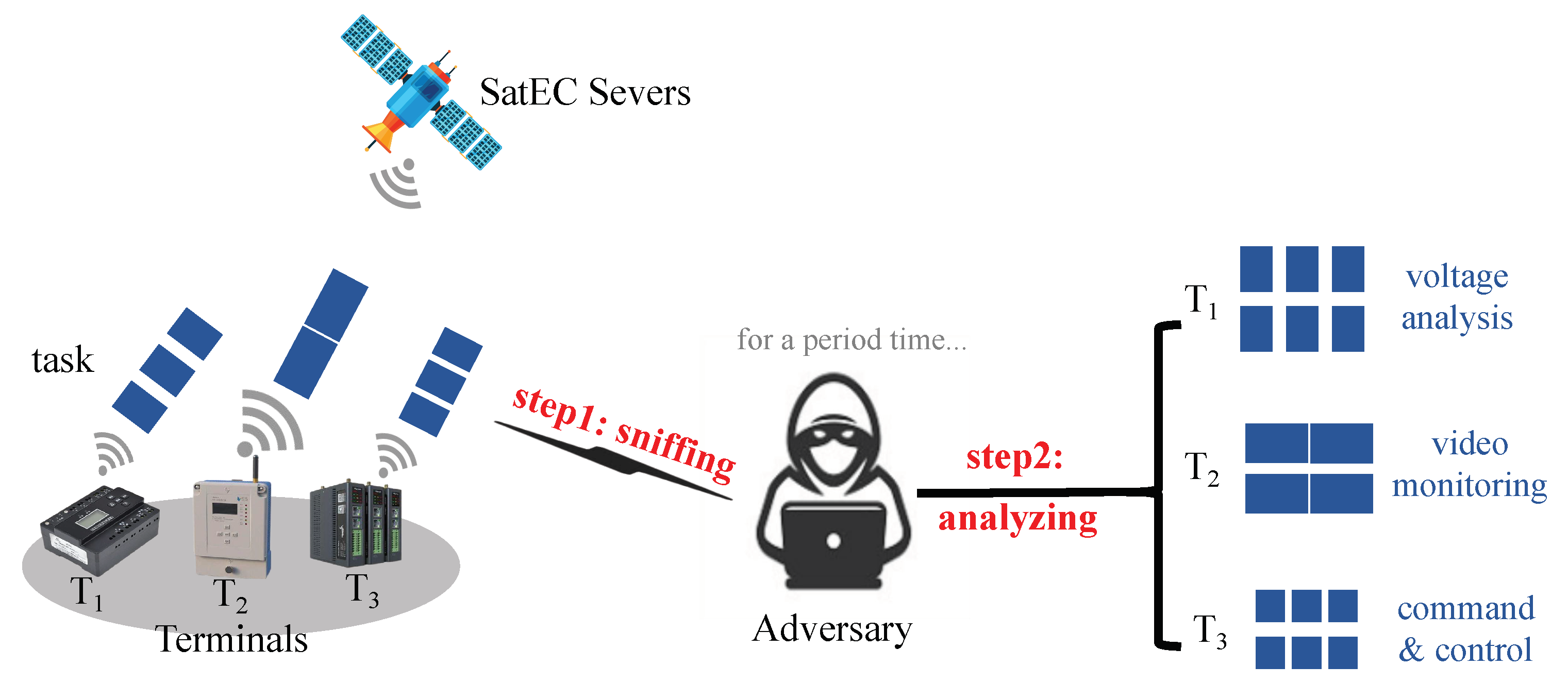
2.2. Privacy Problem in Task Offloading
2.3. Related Works on Privacy Protection
3. System Model and Problem Formulation
3.1. Overview
3.2. Offloading Location
3.3. Offloading Cost
3.3.1. Offloaded to SatEC Server
3.3.2. Offloaded to TC
3.3.3. Offloaded with Privacy Protection
3.4. Problem Formulation
4. DRTO: Deep Reinforcement Learning for Task Offloading
| Algorithm 1 The DRTO algorithm. |
|
4.1. Generate the Offloading Location
4.2. Update the Offloading Policy
4.3. Dynamically Adjust K
5. Simulation and Evaluation Results
5.1. DRTO Algorithm Performance Evaluation
5.1.1. The Convergence Performance
5.1.2. The Offloading Cost of Decision Location Given by DRTO
- Distributed deep learning-based offloading (DDLO) [41]. Multiple DNNs take the duplicated channel gain as input, then each DNN generates a candidate offloading location. Then, the optimal offloading location is selected with respect to the minimum offloading cost. In the comparison with DRTO, we assume that DDLO is composed of N DNNs.
- Coordinate descent (CD) [42]. The CD algorithm is a traditional numerical optimization method, which iteratively swaps the offloading location of each ST that leads to the largest offloading cost decrement. The iteration stops when the offloading cost cannot be further decreased by swapping the offloading location.
- Enumeration. We enumerate all offloading location combinations and greedily select the best one.
- Pure TC computing. The LEO access satellite forwards all the tasks to TC for execution.
- Pure SatEC computing. The LEO access satellite locally executes all the tasks.
5.1.3. The Runtime Consumption of DRTO
5.2. Privacy Protection Effectiveness Evaluation
5.2.1. Experimental Settings
5.2.2. Evaluation Metrics
- Task size: Task size assesses the variability in computational task size transmitted from STs to the satellite before and after adding the redundancy package. Intuitively, a larger change in task size means a more significant difference, which is more effective in confusing the adversary and therefore better for privacy protection.
- Task jitter: Task jitter assesses the variability in the task arrival interval received by the satellite before and after adding the redundancy package. Similarly, a larger change in task jitter is more effective in confusing the adversary and better for privacy protection.
5.2.3. Evaluation Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An overview on edge computing research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Xie, R.; Tang, Q.; Wang, Q.; Liu, X.; Yu, F.R.; Huang, T. Satellite-Terrestrial Integrated Edge Computing Networks: Architecture, Challenges, and Open Issues. IEEE Netw. 2020, 34, 224–231. [Google Scholar] [CrossRef]
- Yan, L.; Cao, S.; Gong, Y.; Han, H.; Wei, J.; Zhao, Y.; Yang, S. SatEC: A 5G Satellite Edge Computing Framework Based on Microservice Architecture. Sensors 2019, 19, 831. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yang, J.; Guo, X.; Qu, Z. Satellite Edge Computing for the Internet of Things in Aerospace. Sensors 2019, 19, 4375. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Wei, J.; Han, J.; Cao, S. Satellite IoT edge intelligent computing: A research on architecture. Electronics 2019, 8, 1247. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Guo, X.; Qu, Z. A Game-Theoretic Approach to Computation Offloading in Satellite Edge Computing. IEEE Access 2020, 8, 12510–12520. [Google Scholar] [CrossRef]
- Denby, B.; Lucia, B. Orbital edge computing: Nanosatellite constellations as a new class of computer system. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 939–954. [Google Scholar]
- Zhu, W.; Yang, W.; Liu, G. Server Selection and Resource Allocation for Energy Minimization in Satellite Edge Computing. In Proceedings of the International Conference on 5G for Future Wireless Networks, Harbin, China, 17–18 December 2022; pp. 142–154. [Google Scholar]
- Aung, H.; Soon, J.J.; Goh, S.T.; Lew, J.M.; Low, K.S. Battery management system with state-of-charge and opportunistic state-of-health for a miniaturized satellite. IEEE Trans. Aerosp. Electron. Syst. 2019, 56, 2978–2989. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, H.; Guo, C.; Xu, H.; Song, L.; Han, Z. Satellite-Aerial Integrated Computing in Disasters: User Association and Offloading Decision. In Proceedings of the IEEE ICC—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020. [Google Scholar]
- Zhou, C.; Wu, W.; He, H.; Yang, P.; Lyu, F.; Cheng, N.; Shen, X. Delay-Aware IoT Task Scheduling in Space-Air-Ground Integrated Network. In Proceedings of the IEEE GLOBECOM—2019 IEEE Global Communications Conference, Big Island, HI, USA, 9–13 December 2019. [Google Scholar]
- Kim, J.; Kim, T.; Hashemi, M.; Brinton, C.G.; Love, D.J. Joint Optimization of Signal Design and Resource Allocation in Wireless D2D Edge Computing. In Proceedings of the IEEE INFOCOM—IEEE Conference on Computer Communications, Virtual Event, 6–9 July 2020. [Google Scholar]
- Huang, S.; Li, G.; Ben-Awuah, E.; Afum, B.O.; Hu, N. A Stochastic Mixed Integer Programming Framework for Underground Mining Production Scheduling Optimization Considering Grade Uncertainty. IEEE Access 2020, 8, 24495–24505. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, L.; Shen, X. Service Offloading in Terrestrial-Satellite Systems: User Preference and Network Utility. In Proceedings of the IEEE GLOBECOM—2019 IEEE Global Communications Conference, Big Island, HI, USA, 9–13 December 2019. [Google Scholar]
- Ramirez-Espinosa, P.; Lopez-Martinez, F.J. On the Utility of the Inverse Gamma Distribution in Modeling Composite Fading Channels. In Proceedings of the IEEE GLOBECOM—2019 IEEE Global Communications Conference, Big Island, HI, USA, 9–13 December 2019. [Google Scholar]
- Conti, M.; Mancini, L.V.; Spolaor, R.; Verde, N.V. Can’t you hear me knocking: Identification of user actions on android apps via traffic analysis. In Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, San Antonio, TX, USA, 2–4 March 2015; pp. 297–304. [Google Scholar]
- Zhao, Y.; Chen, J. A survey on differential privacy for unstructured data content. ACM Comput. Surv. (CSUR) 2022, 54, 1–28. [Google Scholar] [CrossRef]
- Dong, J.; Roth, A.; Su, W.J. Gaussian differential privacy. J. R. Stat. Soc. Ser. B Stat. Methodol. 2022, 84, 3–37. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, Y.; Shi, M.; Li, P.; Li, R.; Xiong, N.N. An adaptive federated learning scheme with differential privacy preserving. Future Gener. Comput. Syst. 2022, 127, 362–372. [Google Scholar] [CrossRef]
- Zhang, X.; Hamm, J.; Reiter, M.K.; Zhang, Y. Defeating traffic analysis via differential privacy: A case study on streaming traffic. Int. J. Inf. Secur. 2022, 21, 689–706. [Google Scholar] [CrossRef]
- He, X.; Liu, J.; Jin, R.; Dai, H. Privacy-aware offloading in mobile-edge computing. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Zhu, D.; Liu, H.; Li, T.; Sun, J.; Liang, J.; Zhang, H.; Geng, L.; Liu, Y. Deep reinforcement learning-based task offloading in satellite-terrestrial edge computing networks. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–7. [Google Scholar]
- Chen, Y.; Gu, W.; Li, K. Dynamic task offloading for internet of things in mobile edge computing via deep reinforcement learning. Int. J. Commun. Syst. 2022, 2022, e5154. [Google Scholar] [CrossRef]
- Al-Masri, E.; Souri, A.; Mohamed, H.; Yang, W.; Olmsted, J.; Kotevska, O. Energy-efficient cooperative resource allocation and task scheduling for Internet of Things environments. Internet Things 2023, 23, 100832. [Google Scholar] [CrossRef]
- Manukumar, S.T.; Muthuswamy, V. A novel data size-aware offloading technique for resource provisioning in mobile cloud computing. Int. J. Commun. Syst. 2023, 36, e5378. [Google Scholar] [CrossRef]
- Jaiswal, K.; Dahiya, A.; Saxena, S.; Singh, V.; Singh, A.; Kushwaha, A. A Novel Computation Offloading Under 6G LEO Satellite-UAV-based IoT. In Proceedings of the 2022 3rd International Conference on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, 15–17 November 2022; pp. 1–6. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhang, X.; Wang, P.; Liu, L. A Computation Offloading Strategy in Satellite Terrestrial Networks with Double Edge Computing. In Proceedings of the 2018 IEEE International Conference on Communication Systems (ICCS), Chengdu, China, 19–21 December 2018; pp. 450–455. [Google Scholar]
- Tong, M.; Wang, X.; Li, S.; Peng, L. Joint Offloading Decision and Resource Allocation in Mobile Edge Computing-Enabled Satellite-Terrestrial Network. Symmetry 2022, 14, 564. [Google Scholar] [CrossRef]
- Zhao, Z.; Huangfu, W.; Sun, L. NSSN: A network monitoring and packet sniffing tool for wireless sensor networks. In Proceedings of the 2012 8th International Wireless Communications and Mobile Computing Conference (IWCMC), Limassol, Cyprus, 27–31 August 2012; pp. 537–542. [Google Scholar]
- Kovač, J.; Crnogorac, J.; Kočan, E.; Vučinić, M. Sniffing multi-hop multi-channel wireless sensor networks. In Proceedings of the 2020 28th Telecommunications Forum (TELFOR), Belgrade, Serbia, 24–25 November 2020; pp. 1–4. [Google Scholar]
- Sarkar, S.; Liu, J.; Jovanov, E. A robust algorithm for sniffing ble long-lived connections in real-time. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Wang, Q.; Yahyavi, A.; Kemme, B.; He, W. I know what you did on your smartphone: Inferring app usage over encrypted data traffic. In Proceedings of the 2015 IEEE Conference on Communications and Network Security (CNS), Florence, Italy, 28–30 September 2015; pp. 433–441. [Google Scholar]
- Chan, T.H.H.; Shi, E.; Song, D. Private and continual release of statistics. ACM Trans. Inf. Syst. Secur. (TISSEC) 2011, 14, 1–24. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Y.; Tang, D.; Zhang, S.; Zhao, Z.; Ci, S. TCP-FNC: A novel TCP with network coding for wireless networks. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 2078–2084. [Google Scholar]
- Marsland, S. Machine Learning: An Algorithmic Perspective; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef]
- Diamond, S.; Boyd, S. CVXPY: A Python-Embedded Modeling Language for Convex Optimization. J. Mach. Learn. Res. 2016, 17, 2909–2913. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Huang, L.; Feng, X.; Feng, A.; Huang, Y.; Qian, L.P. Distributed Deep Learning-based Offloading for Mobile Edge Computing Networks. Mob. Netw. Appl. 2018, 27, 1123–1130. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation Rate Maximization for Wireless Powered Mobile-Edge Computing With Binary Computation Offloading. IEEE Trans. Wirel. Commun. 2018, 17, 4177–4190. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Parameters | Value |
| Transmission power of ST and satellite (W) | 1, 3 |
| Antenna gain and path loss exponent | 4.11, 2.8 |
| Carrier frequency (GHz) | 30 |
| Total bandwidth B (MHz) | 800 |
| Receiver noise power (W) | |
| Task size L (MB) | 100 |
| Parameters | Value |
| Computational intensity k (cycles/bit) | 10 |
| Computing Power Consumption of SatEC server (W) | 0.5 |
| CPU frequency of SatEC server and TC (GHz) | 0.4, 3 |
| Latency-energy weight parameter | 0.5 |
| Training interval | 10 |
| Random batch size | 128 |
| Replay memory size | 1024 |
| Learning rate | 0.01 |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | |
|---|---|---|---|---|---|
| 0.05 | 0.10 | 0.15 | 0.20 | 0.25 | |
| (0.05,) | (0.1,) | (0.15,) | (0.2,) | (0.25,) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, J.; Yuan, Z.; Xin, P.; Xiao, Z.; Sun, J.; Zhuang, S.; Guo, Z.; Fu, J.; Liu, Y. Privacy-Friendly Task Offloading for Smart Grid in 6G Satellite–Terrestrial Edge Computing Networks. Electronics 2023, 12, 3484. https://doi.org/10.3390/electronics12163484
Zou J, Yuan Z, Xin P, Xiao Z, Sun J, Zhuang S, Guo Z, Fu J, Liu Y. Privacy-Friendly Task Offloading for Smart Grid in 6G Satellite–Terrestrial Edge Computing Networks. Electronics. 2023; 12(16):3484. https://doi.org/10.3390/electronics12163484
Chicago/Turabian StyleZou, Jing, Zhaoxiang Yuan, Peizhe Xin, Zhihong Xiao, Jiyan Sun, Shangyuan Zhuang, Zhaorui Guo, Jiadong Fu, and Yinlong Liu. 2023. "Privacy-Friendly Task Offloading for Smart Grid in 6G Satellite–Terrestrial Edge Computing Networks" Electronics 12, no. 16: 3484. https://doi.org/10.3390/electronics12163484