
Research on Speech Emotion Recognition Based on Teager Energy Operator Coefficients and Inverted MFCC Feature Fusion


Abstract
:1. Introduction
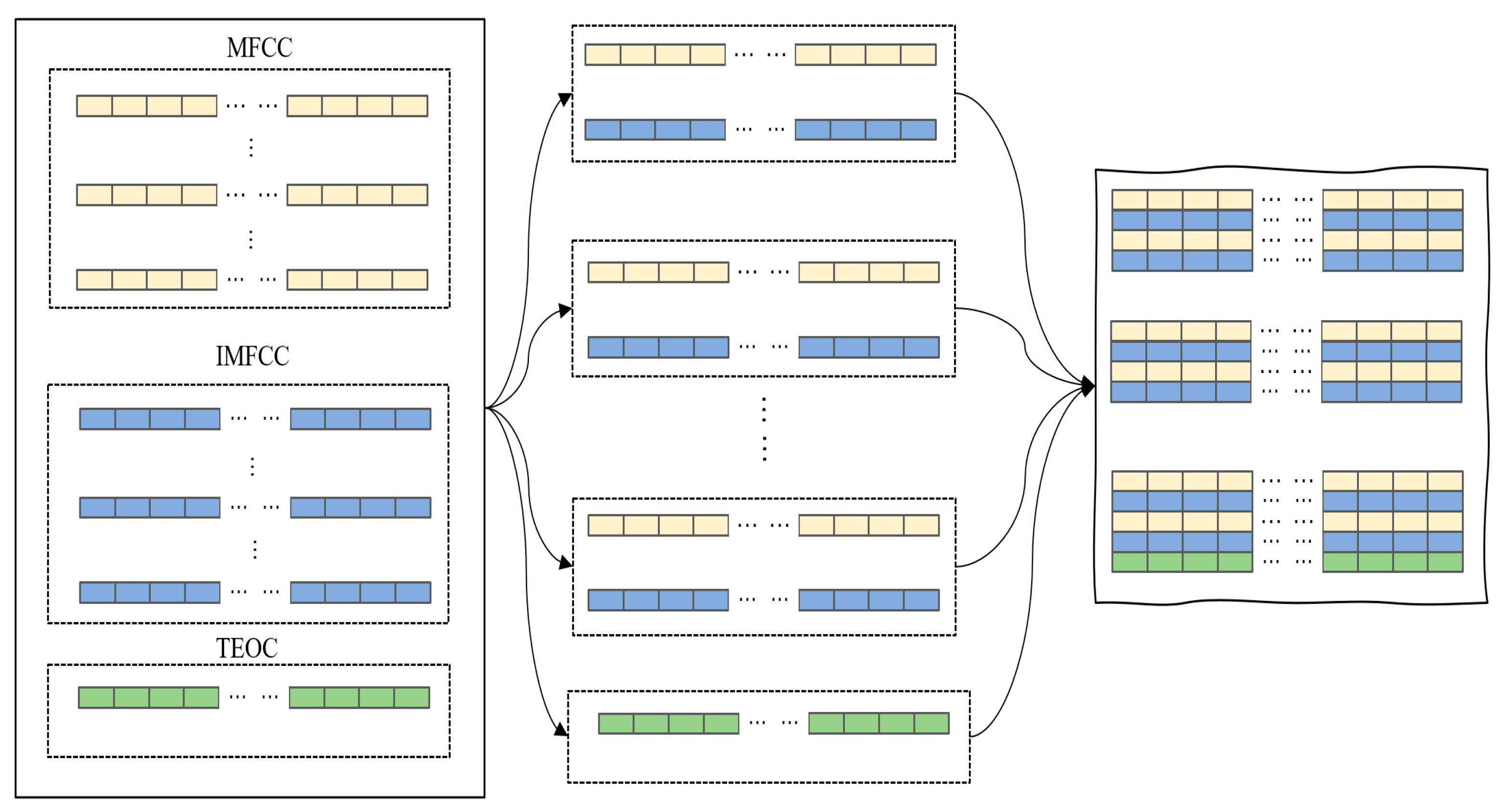
2. Feature Preprocessing
2.1. The Extraction Process of TEOC
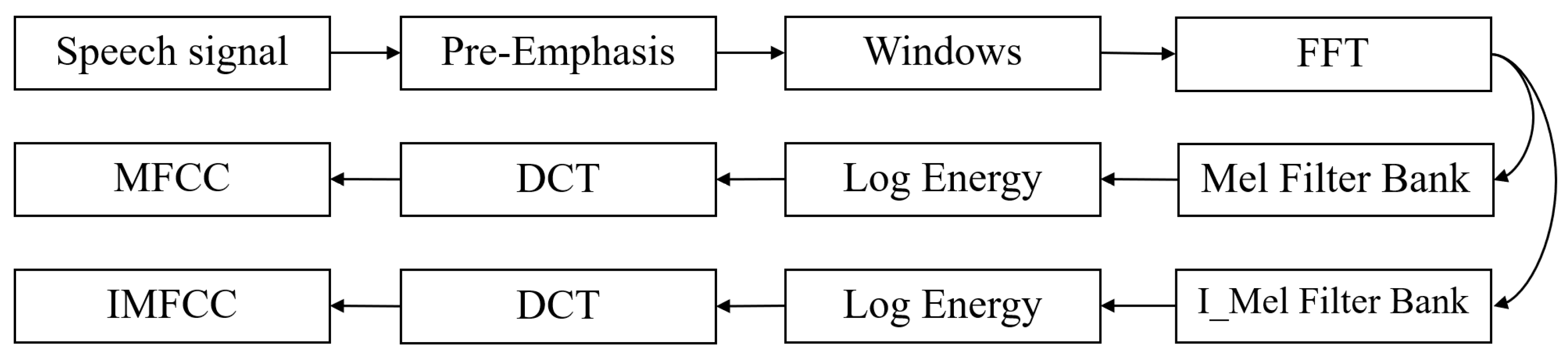
2.2. The Extraction Process of MFCC and IMFCC
- Pre-emphasis of speech: The speech signal passes through a high-pass filter: ,where the value of is between 0.9 and 1.0, and is taken as 0.97 after comparative experiments. The speech production system tends to suppress the high-frequency components of speech [14].
- Framing of speech signals: To avoid abrupt changes between adjacent frames, an overlap region is introduced between them. The sampling frequency of speech signals in this paper is 48 KHz.
- Hamming Window: Suppose that the signal after framing is , is the size of the frame, then after multiplying the Hamming window, has the following form:Different values of will produce different Hamming Windows, and is generally taken to be 0.46.
- Fast Fourier transform: The signal is first Hamming windowed, and then each frame of the signal undergoes a Fast Fourier Transform (FFT) to determine how energetic the signal is over the frequency spectrum. The frequency spectrum of the signal is then multiplied by magnitude squared to produce the power spectrum of the voice signal.
- Mel filter bank: The key role of the triangular filters is to smooth the frequency spectrum, emphasizing the resonant peaks of the speech signal and eliminating unnecessary frequency fluctuations. The structure diagrams of the Mel filter bank and the reversed Mel filter bank are shown in Figure 4.
- 6.
- Calculate the log energy of each filter bank output as:where represents the index of the filter bank, represents the number of points in the FFT, represents the amplitude spectrum of the frequency domain signal, and represents the response function of filter bank .
- 7.
- Discrete cosine transform: MFCC coefficients are obtained by discrete cosine Transform (DCT):By performing the discrete cosine transform on the logarithmic energy, we can calculate L-order MFCC coefficients. In the equation, M represents the number of triangular filters.
- 8.
- Extraction of dynamic difference parameters: To capture the dynamic characteristics of speech in addition to the static features extracted by MFCC, differential spectral features are introduced as a complement to the static features. The calculation of differential parameters can be implemented using the following formula:where represents the first-order difference of the t-th frame, represents the t-th cepstral coefficient, represents the order of cepstral coefficients, and represents the time difference for the first-order derivative, which can be 1 or 2. By substituting the results from the equation back, we can obtain the parameters for the second-order difference.
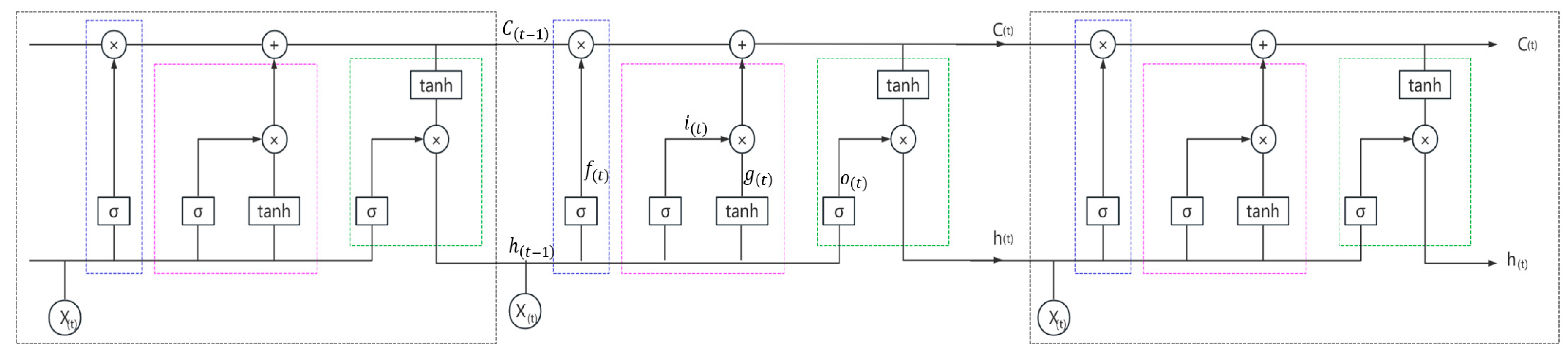
3. Model for the Neural Network
4. Experimental Database and Results
4.1. Database
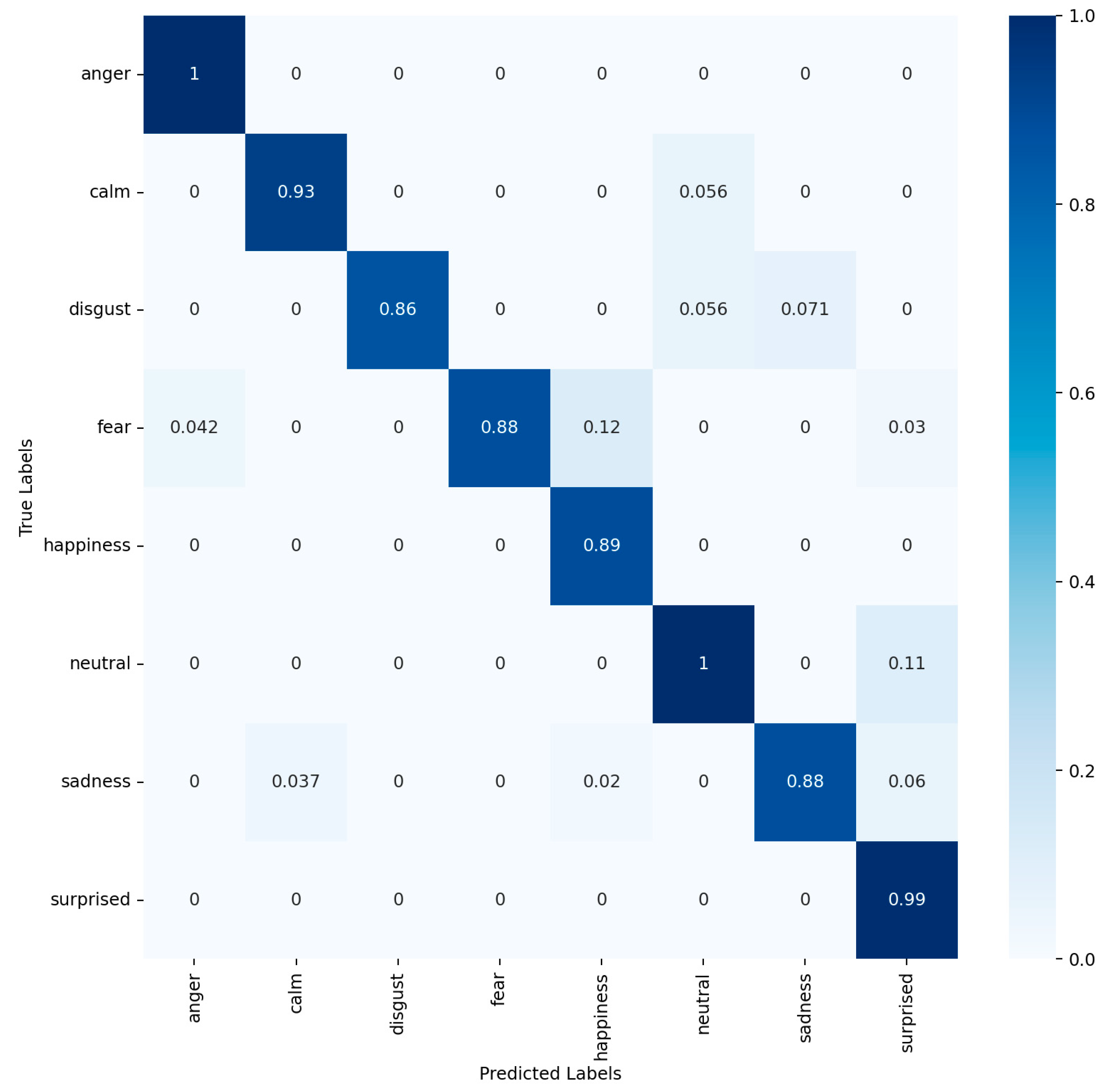
4.2. Comparison of Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schuller, B.; Rigoll, G.; Lang, M. Speech Emotion Recognition Combining Acoustic Features and Linguistic Information in a Hybrid Support Vector Machine-Belief Network Architecture. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 1, pp. I-577–I-580. [Google Scholar]
- France, D.J.; Shiavi, R.G.; Silverman, S.; Silverman, M.; Wilkes, M. Acoustical Properties of Speech as Indicators of Depression and Suicidal Risk. IEEE Trans. Biomed. Eng. 2000, 47, 829–837. [Google Scholar] [CrossRef] [PubMed]
- Hansen, J.H.L.; Cairns, D.A. ICARUS: Source Generator Based Real-Time Recognition of Speech in Noisy Stressful and Lombard Effect Environments. Speech Commun. 1995, 16, 391–422. [Google Scholar] [CrossRef]
- Goos, G.; Hartmanis, J.; van Leeuwen, J.; Hutchison, D.; Kanade, T.; Kittler, J.; Kleinberg, J.M.; Mattern, F.; Mitchell, J.C.; Naor, M.; et al. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1973. [Google Scholar]
- Ks, D.R.; Rudresh, G.S. Comparative Performance Analysis for Speech Digit Recognition Based on MFCC and Vector Quantiza-tion. Glob. Transit. Proc. 2021, 2, 513–519. [Google Scholar] [CrossRef]
- Alimuradov, A.K. Speech/Pause Segmentation Method Based on Teager Energy Operator and Short-Time Energy Analysis. In Proceedings of the 2021 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 13–14 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 45–48. [Google Scholar]
- Priyasad, D.; Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Attention Driven Fusion for Multi-Modal Emotion Recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–9 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3227–3231. [Google Scholar]
- Zhiyan, H.; Jian, W. Speech Emotion Recognition Based on Wavelet Transform and Improved HMM. In Proceedings of the 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 3156–3159. [Google Scholar]
- Rajasekhar, A.; Hota, M.K. A Study of Speech, Speaker and Emotion Recognition Using Mel Frequency Cepstrum Coefficients and Support Vector Machines. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 114–118. [Google Scholar]
- Ko, Y.; Hong, I.; Shin, H.; Kim, Y. Construction of a Database of Emotional Speech Using Emotion Sounds from Movies and Dramas. In Proceedings of the 2017 International Conference on Information and Communications (ICIC), Hanoi, Vietnam, 26–28 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 266–267. [Google Scholar]
- Han, Z.; Wang, J. Speech Emotion Recognition Based on Gaussian Kernel Nonlinear Proximal Support Vector Machine. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2513–2516. [Google Scholar]
- Zhao, J.; Mao, X.; Chen, L. Learning Deep Features to Recognise Speech Emotion Using Merged Deep CNN. IET Signal Proc. 2018, 12, 713–721. [Google Scholar] [CrossRef]
- Ying, X.; Yizhe, Z. Design of Speech Emotion Recognition Algorithm Based on Deep Learning. In Proceedings of the 2021 IEEE 4th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 19–21 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 734–737. [Google Scholar]
- Zhao, H.; Ye, N.; Wang, R. A Survey on Automatic Emotion Recognition Using Audio Big Data and Deep Learning Architectures. In Proceedings of the 2018 IEEE 4th International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Interna-tional Conference on High Performance and Smart Computing, (HPSC) and IEEE International Conference on Intelligent Data and Security (IDS), Omaha, NE, USA, 3–5 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 139–142. [Google Scholar]
- Singh, Y.B.; Goel, S. Survey on Human Emotion Recognition: Speech Database, Features and Classification. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 298–301. [Google Scholar]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on Speech Emotion Recognition: Features, Classification Schemes, and Databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Kumbhar, H.S.; Bhandari, S.U. Speech Emotion Recognition Using MFCC Features and LSTM Network. In Proceedings of the 2019 5th International Conference on Computing, Communication, Control And Automation (ICCUBEA), Pune, India, 19–21 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–3. [Google Scholar]
- Dhavale, M.; Bhandari, S. Speech Emotion Recognition Using CNN and LSTM. In Proceedings of the 2022 6th International Conference On Computing, Communication, Control And Automation ICCUBEA, Pune, India, 26 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–3. [Google Scholar]
- Mohan, M.; Dhanalakshmi, P.; Kumar, R.S. Speech Emotion Classification Using Ensemble Models with MFCC. Procedia Comput. Sci. 2023, 218, 1857–1868. [Google Scholar] [CrossRef]
- Yan, Y.; Shen, X. Research on Speech Emotion Recognition Based on AA-CBGRU Network. Electronics 2022, 11, 1409. [Google Scholar] [CrossRef]
- Zou, H.; Si, Y.; Chen, C.; Rajan, D.; Chng, E.S. Speech Emotion Recognition with Co-Attention Based Multi-Level Acoustic In-formation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23 May 2022. [Google Scholar]
- Chakroborty, S.; Saha, G. Improved Text-Independent Speaker Identification Using Fused MFCC & IMFCC Feature Sets Based on Gaussian Filter. Int. J. Signal Process. 2009, 5, 11–19. [Google Scholar]
- Bandela, S.R.; Kumar, T.K. Stressed Speech Emotion Recognition Using Feature Fusion of Teager Energy Operator and MFCC. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Gupta, A.; Gupta, H. Applications of MFCC and Vector Quantization in Speaker Recognition. In Proceedings of the 2013 International Conference on Intelligent Systems and Signal Processing (ISSP), Piscataway, NJ, USA, 1 May 2013. [Google Scholar]
- Aouani, H.; Ayed, Y.B. Speech Emotion Recognition with Deep Learning. Procedia Comput. Sci. 2020, 176, 251–260. [Google Scholar] [CrossRef]
- Wanli, Z.; Guoxin, L.; Lirong, W. Application of Improved Spectral Subtraction Algorithm for Speech Emotion Recognition. In Proceedings of the 2015 IEEE Fifth International Conference on Big Data and Cloud Computing, Dalian, China, 26–28 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 213–216. [Google Scholar]
- Yu, Y.; Kim, Y.-J. A Voice Activity Detection Model Composed of Bidirectional LSTM and Attention Mechanism. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Teager, H.M.; Teager, S.M. Evidence for Nonlinear Sound Production Mechanisms in the Vocal Tract. In Speech Production and Speech Modelling; Hardcastle, W.J., Marchal, A., Eds.; Springer: Dordrecht, The Netherlands, 1990; pp. 241–261. ISBN 978-94-010-7414-8. [Google Scholar]
- Hui, G.; Shanguang, C.; Guangchuan, S. Emotion Classification of Mandarin Speech Based on TEO Nonlinear Features. In Proceedings of the Eighth ACIS International Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing (SNPD 2007), Qingdao, China, 3 July–1 August 2007; IEEE: Piscataway, NJ, USA, 2017; pp. 394–398. [Google Scholar]
- Strope, B.; Alwan, A. A Model of Dynamic Auditory Perception and Its Application to Robust Word Recognition. IEEE Trans. Speech Audio Process. 1997, 5, 451–464. [Google Scholar] [CrossRef]
- Kaiser, J.F. On a Simple Algorithm to Calculate the “energy” of a Signal. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; IEEE: Piscataway, NJ, USA, 1990; pp. 381–384. [Google Scholar]
- Logan, B. Mel Frequency Cepstral Coefficients for Music Modeling. In Proceedings of the International Society for Music In-formation Retrieval Conference, Plymouth, MA, USA, 23–25 October 2000. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A Dynamic, Multimodal Set of Facial and Vocal Expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed]
- Parry, J.; Palaz, D.; Clarke, G.; Lecomte, P.; Mead, R.; Berger, M.; Hofer, G. Analysis of Deep Learning Architectures for Cross-Corpus Speech Emotion Recognition. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; ISCA: Buenos Aires, Argentina, 2019; pp. 1656–1660. [Google Scholar]
- Jalal, M.A.; Loweimi, E.; Moore, R.K.; Hain, T. Learning Temporal Clusters Using Capsule Routing for Speech Emotion Recognition. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; ISCA: Buenos Aires, Argentina, 2019; pp. 1701–1705. [Google Scholar]
- Koo, H.; Jeong, S.; Yoon, S.; Kim, W. Development of Speech Emotion Recognition Algorithm Using MFCC and Prosody. In Proceedings of the 2020 International Conference on Electronics, Information, and Communication (ICEIC), Barcelona, Spain, 19–22 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Pratama, A.; Sihwi, S.W. Speech Emotion Recognition Model Using Support Vector Machine Through MFCC Audio Feature. In Proceedings of the 2022 14th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 18 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 303–307. [Google Scholar]
- Yadav, A.; Vishwakarma, D.K. A Multilingual Framework of CNN and Bi-LSTM for Emotion Classification. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kha-Ragpur, India, 1–3 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Ayadi, S.; Lachiri, Z. A Combined CNN-LSTM Network for Audio Emotion Recognition Using Speech and Song Attributs. In Proceedings of the 2022 6th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sfax, Tunisia, 24 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Huang, L.; Shen, X. Research on Speech Emotion Recognition Based on the Fractional Fourier Transform. Electronics 2022, 11, 3393. [Google Scholar] [CrossRef]
- Pastor, M.A.; Ribas, D.; Ortega, A.; Miguel, A.; Lleida, E. Cross-Corpus Training Strategy for Speech Emotion Recognition Using Self-Supervised Representations. Appl. Sci. 2023, 13, 9062. [Google Scholar] [CrossRef]
- Yue, P.; Qu, L.; Zheng, S.; Li, T. Multi-Task Learning for Speech Emotion and Emotion Intensity Recognition. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1232–1237. [Google Scholar]
- Alisamir, S.; Ringeval, F.; Portet, F. Multi-Corpus Affect Recognition with Emotion Embeddings and Self-Supervised Representations of Speech. In Proceedings of the 2022 10th International Conference on Affective Computing and Intelligent Interaction (ACII), Nara, Japan, 18 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Chaudhari, A.; Bhatt, C.; Krishna, A.; Travieso-González, C.M. Facial Emotion Recognition with Inter-Modality-Attention-Transformer-Based Self-Supervised Learning. Electronics 2023, 12, 288. [Google Scholar] [CrossRef]
- Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.M.; Fernández-Martínez, F. A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action Units on RAVDESS Dataset. Appl. Sci. 2021, 12, 327. [Google Scholar] [CrossRef]
- Ye, J.; Wen, X.; Wei, Y.; Xu, Y.; Liu, K.; Shan, H. Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition. In Proceedings of the CASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Convolutional Layer Architecture | Structural Parameters |
|---|---|
| Conv1 | Filters: 32; Kernel_size: 9 padding: ‘same’; Maxpooling: 2 Dropout: 0.25 |
| Conv2 | Filters: 64; Kernel_size: 7 Padding: ‘same’; Maxpooling: 2 Dropout: 0.25 |
| Conv3 | Filters: 128; Kernel_size: 5 Padding: ‘same’; Maxpooling: 2 Dropout: 0.25 |
| Emotion Wav | Count |
|---|---|
| Neutral | 96 |
| Calm | 192 |
| Happy | 192 |
| Sad | 192 |
| Angry | 192 |
| Fearful | 192 |
| Disgust | 192 |
| Surprise | 192 |
| Total | 1440 |
| Layer (Type) | Output Shape | Param |
|---|---|---|
| Conv1D_1 | (None, 40, 32) | 320 |
| Batch_normalization_1 | (None, 40, 32) | 128 |
| Activation _1 | (None, 40, 32) | 0 |
| Max_pooling1d_1 | (None, 20, 32) | 0 |
| Dropout_1 | (None, 20, 32) | 0 |
| Conv1D_2 | (None, 20, 64) | 14,400 |
| Batch_normalization_2 | (None, 20, 64) | 256 |
| Activation_2 | (None, 20, 64) | 0 |
| Max_pooling1d_2 | (None, 10, 64) | 0 |
| Dropout_2 | (None, 10, 64) | 0 |
| Conv1D_3 | (None, 10, 128) | 41,088 |
| batch_normalization_3 | (None, 10, 128) | 512 |
| Activation_3 | (None, 10, 128) | 0 |
| Max_pooling1d_3 | (None, 5, 128) | 0 |
| Dropout_3 | (None, 5, 128) | 0 |
| LSTM | (None, 5, 32) | 20,608 |
| Flatten | (None, 160) | 0 |
| Dense | (None, 8) | 1288 |
| Paper | Feature | WA | UA |
|---|---|---|---|
| Parry et al. [34] | MFCCs + Mfcs + F0 + log-energy | - | 53.08% |
| Jalal et al. [35] | augmented by delta and delta-delta | - | 56.2% |
| Koo et al. [36] | MFCC+delta+ delta of acceleration | 64.47% | - |
| Pratama et al. [37] | MFCC | - | 71.16% |
| Yadav et al. [38] | MFCCS | - | 73% |
| Ayadi et al. [39] | MFCC | 73.33% | - |
| Huang et al. [40] | Frft_MFCC | 79.86% | 79.51% |
| This paper | TEOC&I_MFCC | 92.99% | 92.88% |
| Feature | WA | UA |
|---|---|---|
| MFCC | 75.64% | 76.46% |
| IMFCC | 79.92% | 79.79% |
| TEOC + MFCC | 73.73% | 73.54% |
| TEOC + iMFCC | 81.80% | 81.67% |
| TEOC + MFCC + IMFCC | 92.99% | 92.88% |
| Paper | Classification Model | WA | UA |
|---|---|---|---|
| Pastor et al. [41] | CNNSelfAtt | - | 70.92% |
| Yue et al. [42] | Wav2Vec 2.0 | 80.01% | 80.07% |
| Alisamir et al. [43] | W2V2-FT | - | 82.20% |
| Chaudhari et al. [44] | SSL+ transformer | 86.40% | - |
| Luna-Jiménez et al. [45] | xlsr-Wav2Vec2.0 + MLP | 86.70% | - |
| Ye et al. [46] | TIM-Net | 91.93% | 92.08% |
| This paper | CNN_LSTM | 92.99% | 92.88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Shen, X. Research on Speech Emotion Recognition Based on Teager Energy Operator Coefficients and Inverted MFCC Feature Fusion. Electronics 2023, 12, 3599. https://doi.org/10.3390/electronics12173599
Wang F, Shen X. Research on Speech Emotion Recognition Based on Teager Energy Operator Coefficients and Inverted MFCC Feature Fusion. Electronics. 2023; 12(17):3599. https://doi.org/10.3390/electronics12173599
Chicago/Turabian StyleWang, Feifan, and Xizhong Shen. 2023. "Research on Speech Emotion Recognition Based on Teager Energy Operator Coefficients and Inverted MFCC Feature Fusion" Electronics 12, no. 17: 3599. https://doi.org/10.3390/electronics12173599
APA StyleWang, F., & Shen, X. (2023). Research on Speech Emotion Recognition Based on Teager Energy Operator Coefficients and Inverted MFCC Feature Fusion. Electronics, 12(17), 3599. https://doi.org/10.3390/electronics12173599