
A Study on the Rapid Detection of Steering Markers in Orchard Management Robots Based on Improved YOLOv7


 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset Production
2.1.1. Data Acquisition
2.1.2. Data Preprocessing
2.2. Improved YOLOv7 Algorithm
2.2.1. YOLOv7 Algorithm
2.2.2. Mosaic Data Enhancement Method
2.2.3. Cosine Annealing
2.2.4. Depthwise Separable Convolution
2.2.5. Focal Loss Function
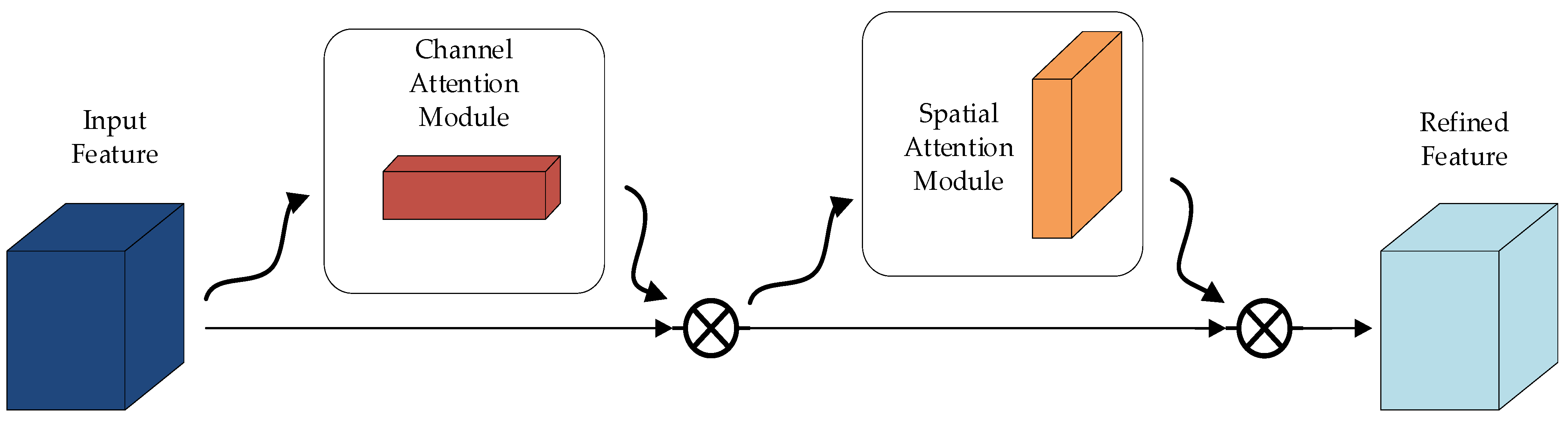
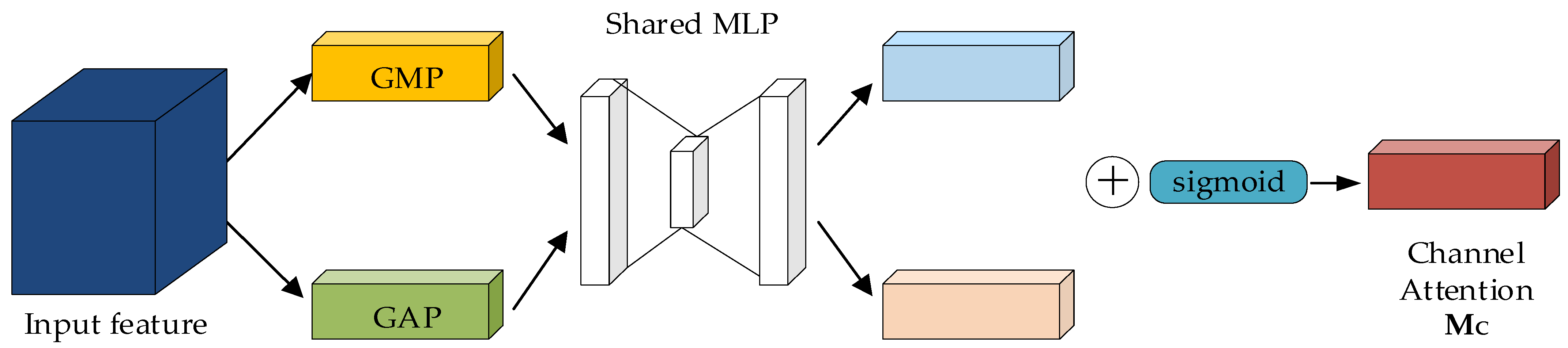
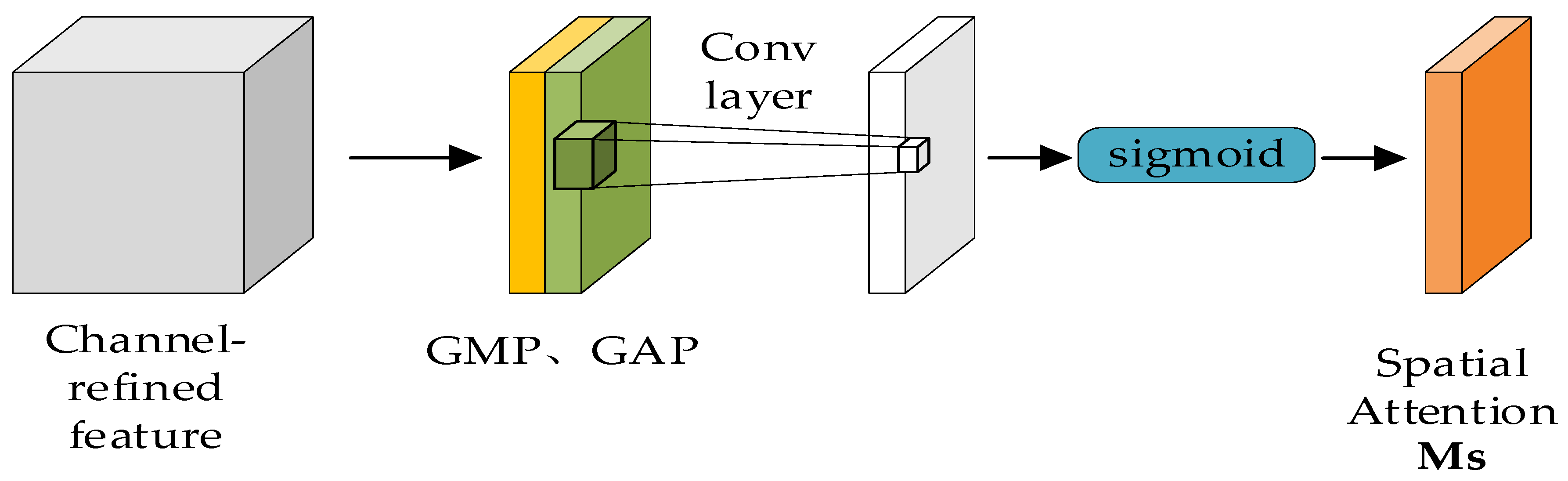
2.2.6. CBAM Attention Mechanism
2.2.7. DFC-YOLOv7 Network Model
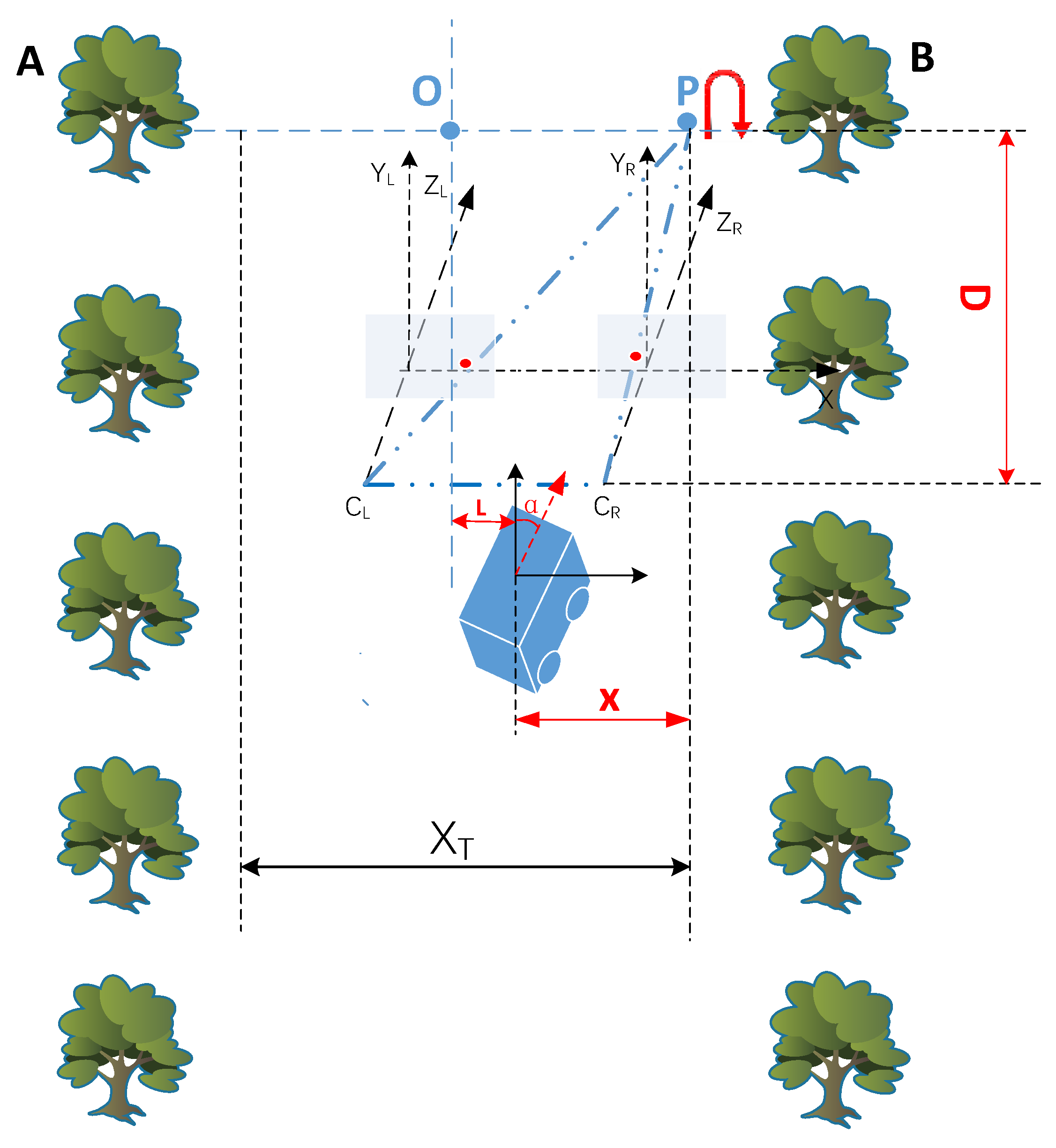
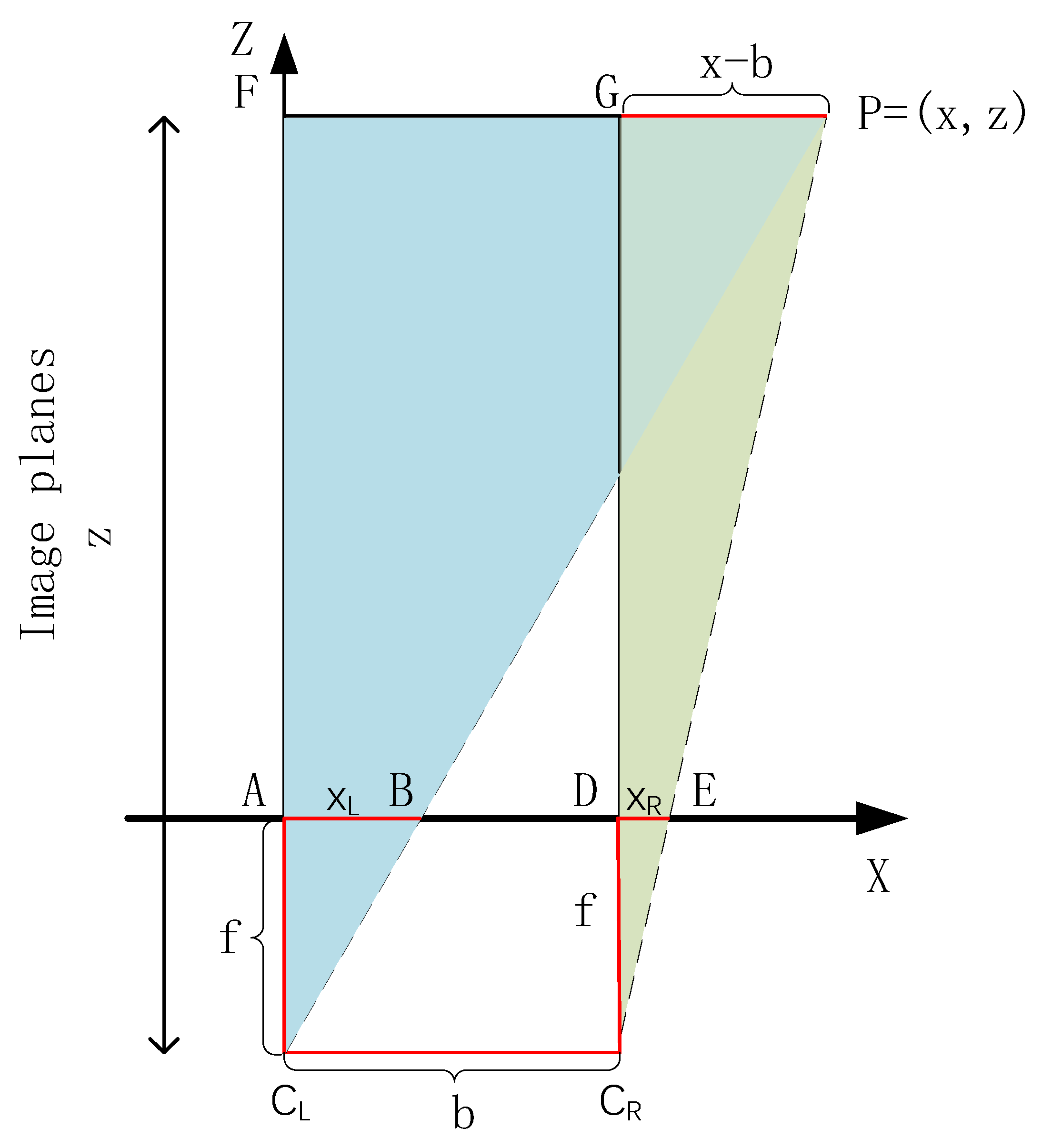
2.3. Steering Start Point Attitude Information Acquisition
3. Results and Analysis
3.1. Test Environment and Parameter Setting
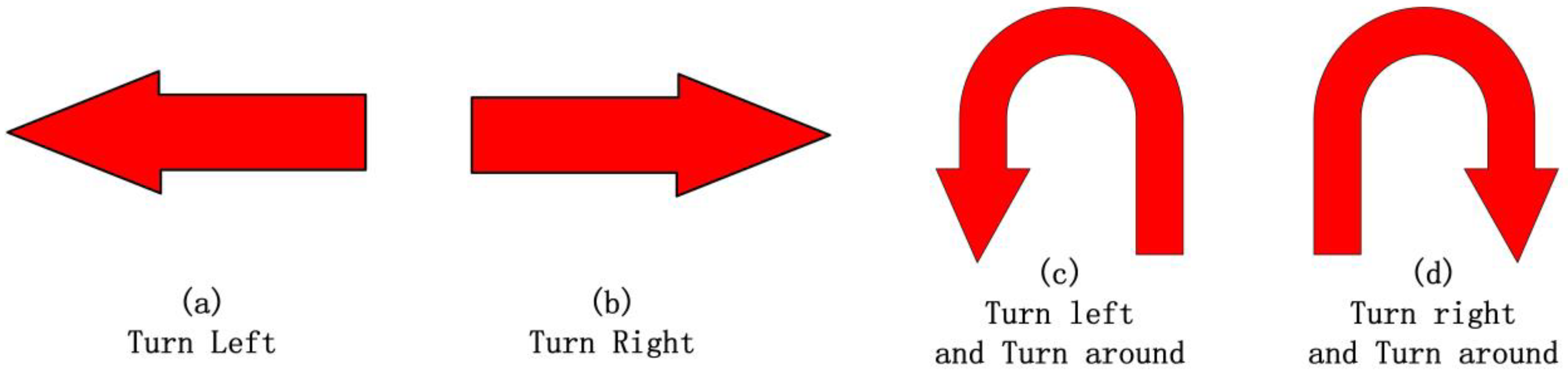
3.2. Evaluation Metrics for the Steering Mark Detection Test
3.3. Steering Marker Positioning Test Evaluation Method
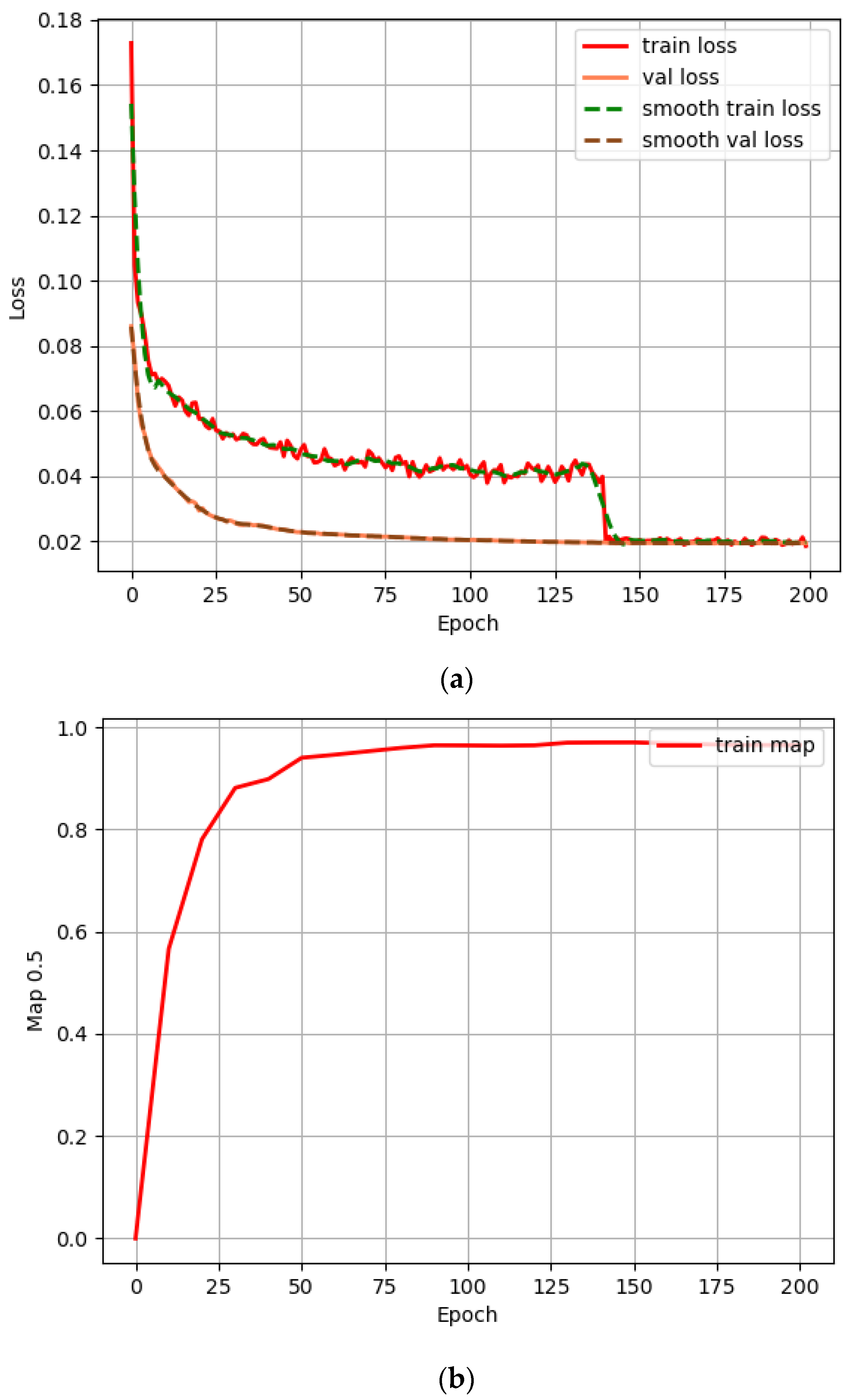
3.4. Steering Marker Detection Model Training Results
3.5. Impact of Focal Loss Function on Multi-Class Task Models
3.6. Performance Comparison of Different Attention Mechanisms
3.7. Ablation Experiment
3.8. Detection of Orchard Turning Mark by Different Models
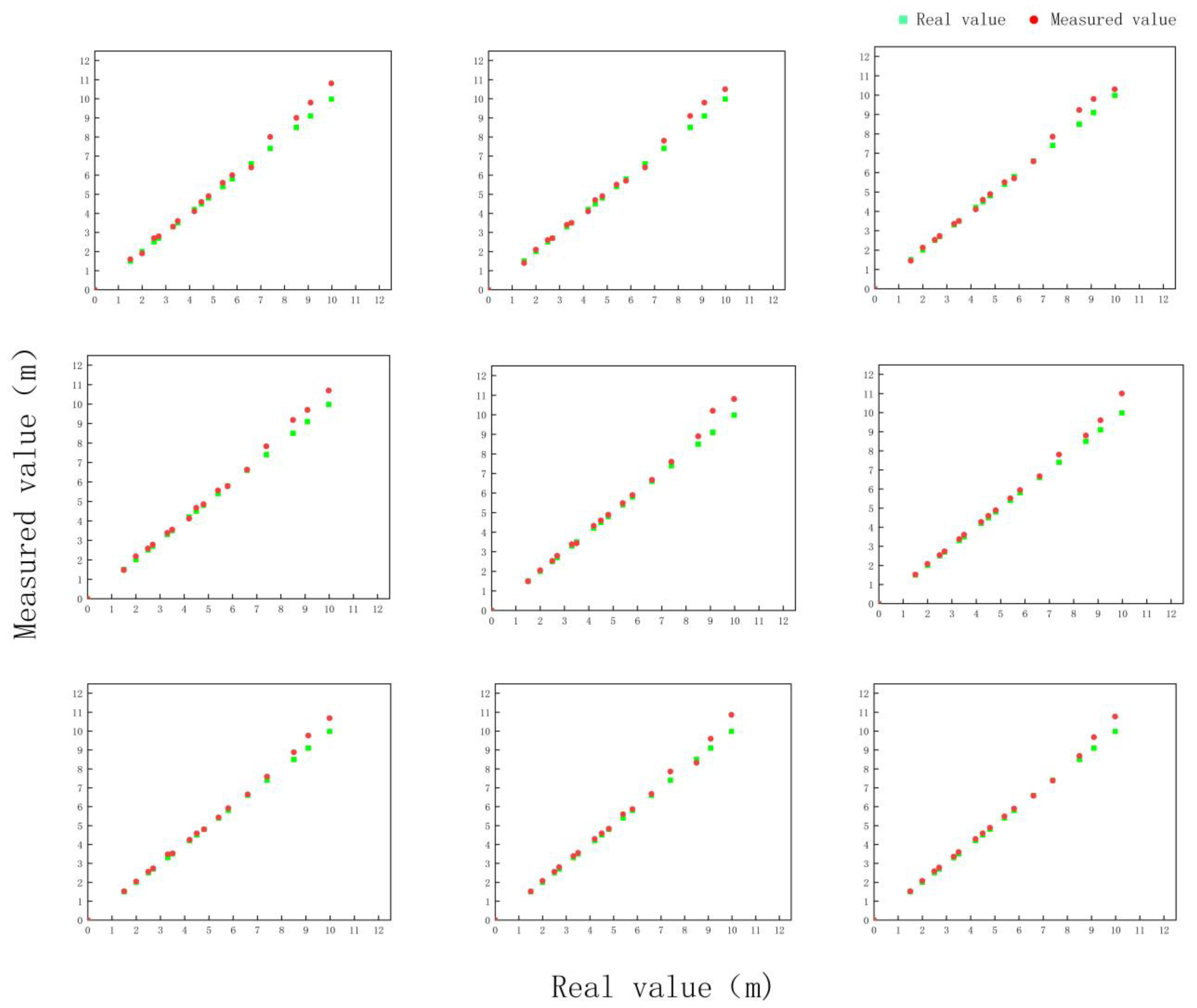
3.9. Binocular Camera Localization Results
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, F.; Wang, H.; Li, L. Status quo, problems and development countermeasures of China’s facility fruit tree industry. China Fruit Tree 2021, 217, 1–4. [Google Scholar]
- Barbara, A.; Łukasz, P.; Solomiia, K. Pioneering Metabolomic Studies on Diaporthe eres Species Complex from Fruit Trees in the South-Eastern Poland. Molecules 2023, 28, 1175. [Google Scholar]
- Sayyad-Amin, P. A Review on Breeding Fruit Trees Against Climate Changes. Erwerbs-Obstbau 2022, 64, 697–701. [Google Scholar] [CrossRef]
- Satyam, R.; Jens, F.; Thomas, H. Navigation and control development for a four-wheel-steered mobile orchard robot using model-based design. Comput. Electron. Agric. 2022, 202, 107410. [Google Scholar]
- Xing, W.; Han, W.; Hong, Y. Geometry-aware fruit grasping estimation for robotic harvesting in apple orchards. Comput. Electron. Agric. 2022, 193, 106716. [Google Scholar]
- Bell, J.; MacDonald, A.; Ahn, S. An Analysis of Automated Guided Vehicle Standards to Inform the Development of Mobile Orchard Robots. IFAC Pap. 2016, 49, 475–480. [Google Scholar] [CrossRef]
- Zhang, S. Research on Autonomous Obstacle Avoidance Motion Planning Method for Mobile Robots in Orchard. Master’s Thesis, Jiangsu University, Zhenjiang, China, 2022. [Google Scholar]
- Zhen, N.; Yi, D.; Qing, Y. Dynamic path planning method for headland turning of unmanned agricultural vehicles. Comput. Electron. Agric. 2023, 206, 107699. [Google Scholar]
- Qian, R.; Zhang, B.; Yue, Y. Traffic sign detection by template matching based on multilevel chain code histogram. In Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2400–2404. [Google Scholar]
- Liang, M.; Yuan, M.; Hu, X. Traffic sign detection by ROI extraction and histogram features-based recognition. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–8. [Google Scholar]
- Chen, Z.; Li, L.; Li, Z. Research on license plate recognition technology based on machine learning. Comput. Technol. Dev. 2020, 30, 13–18. [Google Scholar]
- Jiang, L.; Chai, X.; Li, L. Positioning study of contact network column signage between rail zones. Intell. Comput. Appl. 2020, 10, 154–157+160. [Google Scholar]
- Zhou, F.; Jin, L.; Dong, J. A review of convolutional neural network research. J. Comput. 2017, 40, 1229–1251. [Google Scholar]
- Jordan, M.; Mitchell, T. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Liang, W.; Ling, M.; Hao, W. Real-time vehicle identification and tracking during agricultural master-slave follow-up operation using improved YOLO v4 and binocular positioning. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2023, 237, 1393–1404. [Google Scholar]
- Matko, G.; Nikola, A.; Ivan, L. Detection and Classification of Printed Circuit Boards Using YOLO Algorithm. Electronics 2023, 12, 667. [Google Scholar]
- Tai, H.; Si, Y.; Qi, M. Lightweight tomato real-time detection method based on improved YOLO and mobile deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zhi, J.; Jin, F.; Jie, Z. An efficient SMD-PCBA detection based on YOLOv7 network model. Eng. Appl. Artif. Intell. 2023, 124, 106492. [Google Scholar]
- Zi, Y.; Aohua, S.; Si, Y. DSC-HRNet: A lightweight teaching pose estimation model with depthwise separable convolution and deep high-resolution representation learning in computer-aided education. Int. J. Inf. Technol. 2023, 15, 2373–2385. [Google Scholar]
- Emin, M. Hyperspectral image classification method based on squeeze-and-excitation networks, depthwise separable convolution and multibranch feature fusion. Earth Sci. Inform. 2023, 16, 1427–1448. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Woo, S.; Park, J.; Lee, J. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Auria, E.; Nairouz, F.; Uri, P. Temporal synchronization elicits enhancement of binocular vision functions. iScience 2023, 26, 105960. [Google Scholar]
- Yiping, S.; Zheng, S.; Bao, C. A Point Cloud Data-Driven Pallet Pose Estimation Method Using an Active Binocular Vision Sensor. Sensors 2023, 23, 1217. [Google Scholar]
- Shi, X.; Jiang, W.; Zheng, Z. Bolt loosening angle detection based on binocular vision. Meas. Sci. Technol. 2023, 34, 035401. [Google Scholar]
- Jia, K.; Peng, S.; Zhi, J. Research on a Real-Time Monitoring Method for the Three-Dimensional Straightness of a Scraper Conveyor Based on Binocular Vision. Mathematics 2022, 10, 3545. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| Operating System | Windows10 |
| CPU | Intel Core i5-12400F CPU 4.4 GHz |
| GPU | GeForce RTX 1080Ti 11 G |
| Running Memory | 16 G |
| Accelerate Environment | CUDA11.0 CuDNN7.6.5 |
| Pytorch | 1.7.1 |
| Attenuation Parameters γ | AP/% | mAP/% | |||
|---|---|---|---|---|---|
| A | B | C | D | ||
| 0 | 94.45 | 91.23 | 96.65 | 95.15 | 94.37 |
| 0.5 | 93.21 | 91.4 | 95.88 | 96.2 | 94.17 |
| 1.0 | 94.8 | 91.4 | 97.01 | 96.4 | 94.90 |
| 2.0 | 95.2 | 92.7 | 96.9 | 96.69 | 95.37 |
| 2.5 | 95.02 | 91.98 | 96.73 | 96.42 | 95.04 |
| Models | AP/% | mAP/% | Time/ms | |||
|---|---|---|---|---|---|---|
| A | B | C | D | |||
| Base | 95.2 | 92.7 | 96.9 | 96.69 | 95.37 | 15.21 |
| SE-Base | 94.45 | 91.23 | 96.65 | 95.15 | 94.37 | 15.44 |
| ECA-Base | 96.1 | 93.2 | 96.5 | 97.2 | 95.75 | 14.39 |
| CBAM-Base | 96.8 | 93.8 | 98.7 | 98.1 | 96.85 | 15.47 |
| Models | AP/% | MAP/% | Time/ms | |||
|---|---|---|---|---|---|---|
| A | B | C | D | |||
| YOLOv7 | 94.45 | 91.23 | 96.65 | 95.15 | 94.37 | 24.96 |
| DW-YOLOv7 | 94.32 | 91.33 | 96.7 | 95.61 | 94.49 | 13.48 |
| Focal-YOLOv7 | 95.2 | 92.7 | 96.9 | 96.69 | 95.37 | 26.87 |
| CBAM-YOLOv7 | 95.3 | 92.65 | 96.88 | 96.32 | 95.28 | 27.95 |
| DF-YOLOv7 | 95.12 | 92.79 | 96.89 | 96.98 | 95.46 | 15.21 |
| DC-YOLOv7 | 95.6 | 92.34 | 96.89 | 96.28 | 95.28 | 16.84 |
| FC-YOLOv7 | 96.4 | 93.7 | 98.27 | 97.98 | 96.59 | 29.44 |
| DFC-YOLOv7 | 96.8 | 93.8 | 98.7 | 98.1 | 96.85 | 15.47 |
| Models | AP/% | MAP/% | Time/ms | |||
|---|---|---|---|---|---|---|
| A | B | C | D | |||
| YOLOv4 | 91.07 | 94.45 | 93.04 | 93.17 | 92.93 | 26.47 |
| YOLOv4-tiny | 90.86 | 81.26 | 92.07 | 92.89 | 89.27 | 6.86 |
| YOLOv5-s | 94.12 | 84.65 | 97.67 | 93.81 | 92.56 | 11.68 |
| YOLOv7 | 94.45 | 91.23 | 96.65 | 95.15 | 94.37 | 24.96 |
| DFC-YOLOv7 | 96.8 | 93.8 | 98.7 | 98.1 | 96.85 | 15.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Tian, G.; Gu, B.; Zhao, J.; Liu, Q.; Qiu, C.; Xue, J. A Study on the Rapid Detection of Steering Markers in Orchard Management Robots Based on Improved YOLOv7. Electronics 2023, 12, 3614. https://doi.org/10.3390/electronics12173614
Gao Y, Tian G, Gu B, Zhao J, Liu Q, Qiu C, Xue J. A Study on the Rapid Detection of Steering Markers in Orchard Management Robots Based on Improved YOLOv7. Electronics. 2023; 12(17):3614. https://doi.org/10.3390/electronics12173614
Chicago/Turabian StyleGao, Yi, Guangzhao Tian, Baoxing Gu, Jiawei Zhao, Qin Liu, Chang Qiu, and Jinlin Xue. 2023. "A Study on the Rapid Detection of Steering Markers in Orchard Management Robots Based on Improved YOLOv7" Electronics 12, no. 17: 3614. https://doi.org/10.3390/electronics12173614
APA StyleGao, Y., Tian, G., Gu, B., Zhao, J., Liu, Q., Qiu, C., & Xue, J. (2023). A Study on the Rapid Detection of Steering Markers in Orchard Management Robots Based on Improved YOLOv7. Electronics, 12(17), 3614. https://doi.org/10.3390/electronics12173614