

CANARY: An Adversarial Robustness Evaluation Platform for Deep Learning Models on Image Classification

 ,
,
Abstract
:1. Introduction
- We propose novel evaluation methods for model robustness, attack/defense effectiveness, and attack transferability and develop a scoring framework including 26 (sub)metrics. We first use IRT to calculate these metrics into scores that reflect their real capabilities, making it possible for us to compare and rank model robustness and the effectiveness of the attack method.
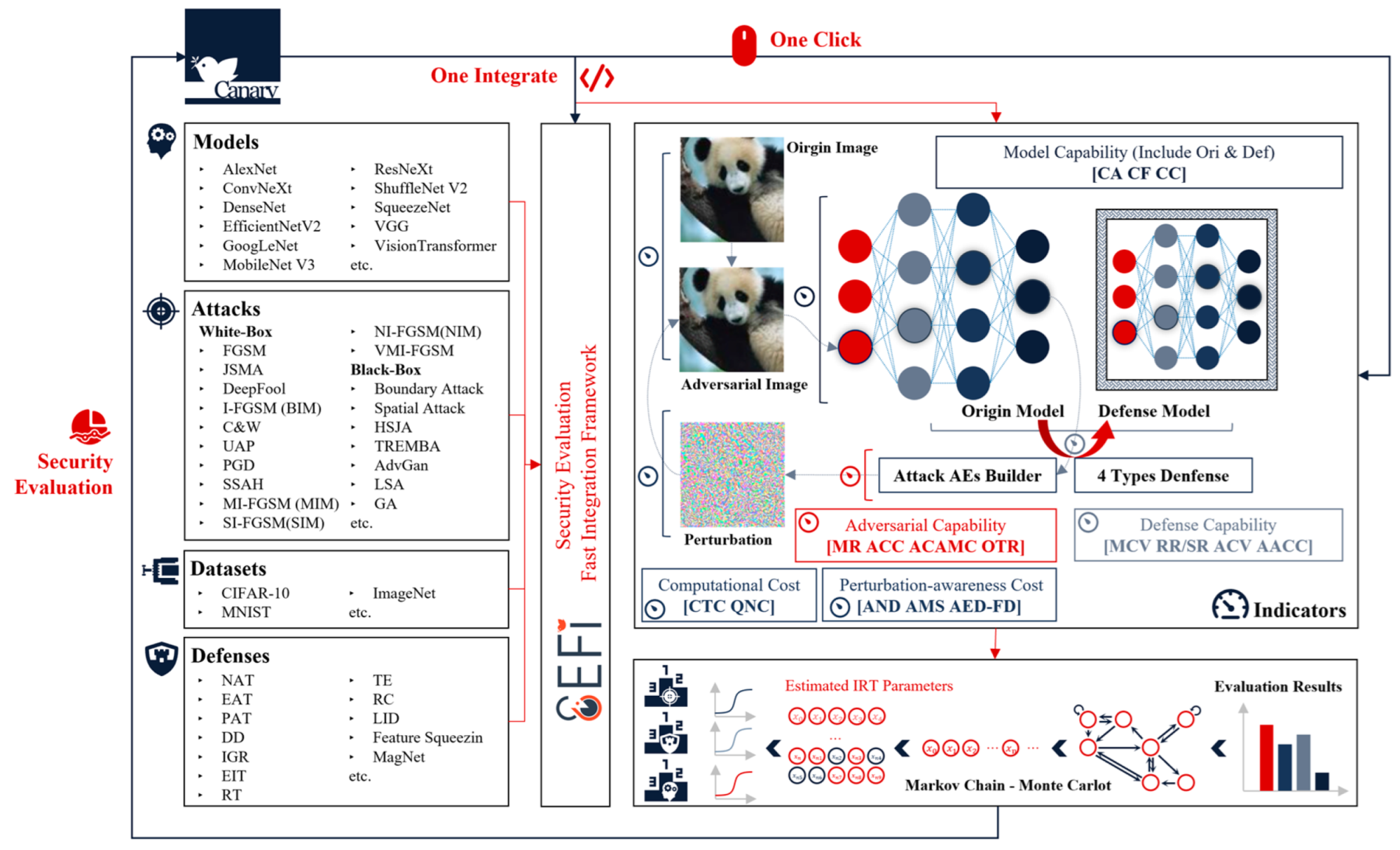
- We design and open-source an advanced evaluation platform called Canary, including 17K lines of code. The platform contains at least 30 attacks, including 15 white-box attacks and 15 black-box attacks. To our knowledge, this is one of the best platforms that can allow users to freely integrate any CNN model or any attack or defense method.
- Based on Canary and the scoring framework, we conducted the largest-scale cross-evaluation experiment of “model-attack” to date and obtained a series of interesting and insightful findings. In particular, we revealed the significantly different performances of different models under the same attack and the substantial differences of different attack methods in attacking the same model. These findings may promote the development of the adversarial learning field.
- We have collated the test results into a database and open-sourced it with a view to providing a valid baseline for other researchers, which will be the second baseline for model robustness since RobustBench.
Notations
2. Related Works
2.1. Methods of Adversarial Attack and Defense
2.2. The Robustness Evaluation of DL Model
3. Measurement Metrics and Evaluation Methods
3.1. Measurement Metrics
3.1.1. Model Capability Measurement Metrics
3.1.2. Attack Effectiveness Measurement Metrics
3.1.3. Cost of Attack Measurement Metrics
- (1)
- Computational cost
- (2)
- Perturbation-awareness cost
3.1.4. Effectiveness of Defense Measurement Metrics
3.2. Evaluation Methods
3.2.1. Evaluation Example Selection
- When restricting the perturbations of the evaluation examples, inappropriate perturbation restrictions may prevent the attack method from achieving its full performance. As in Figure 2b,c, the data point to be determined is measured under a randomly selected perturbation, and we cannot determine whether it is an appropriate evaluation example based on this point alone. As in Figure 2b, when we add perturbations, there are two possibilities at this point:
- (1)
- The new data point is . Since has a significantly higher misclassification rate compared to , it can be argued that the perturbation restriction prevents the misclassification rate from increasing, and using for the evaluation would compromise the fairness of the evaluation. Therefore, the pending point is updated to and the perturbation test needs to continue to be added.
- (2)
- The new data point is . As there is no significant change in the misclassification rate of compared to , it can be argued that has reached its limit, and the significant increase in the perturbation budget has degraded the example quality, and using would compromise the fairness of the evaluation. Therefore, the point to be determined remains unchanged.
Similarly, as in Figure 2c, when we reduce the perturbation, the pending point is updated from to if the new data point is ; if the new data point is , then the pending point remains unchanged.After adding a perturbation, if the pending point has not changed, then we reduce the perturbation until it does not change anymore, and the reached point is the appropriate evaluation example point; if the pending point changes, then we continue to increase until it does not change anymore, and the reached point is the appropriate evaluation example point. - In limiting the misclassification rate of the evaluation examples, we note that some of the attack methods limit the failure of examples, i.e., reduce the adversarial perturbation budget while always ensuring that the examples can attack successfully, thus we default to no upper limit on the misclassification rate of the attacks, and the final iteration completed is the appropriate evaluation example point.
3.2.2. Evaluation Data Collection
3.2.3. Two-Way “Attack Effectiveness–Model Robustness” Evaluation Strategy
3.2.4. Transferability Evaluation
3.3. Evaluation Results Ranking
- Unidimensionality Assumption: This assumption posits that various test items in the evaluation collectively measure a single latent trait encompassed within all test items. The subject’s performance on the assessment can be explained solely by one underlying trait.
- Local Independence Assumption: This assumption posits that the subjects’ responses to the test items are influenced solely by their individual ability levels and specific properties, without affecting other subjects or their reactions to other test items. In other words, the ability factor in the item response model is the sole factor influencing the subject’s responses to the test items.
- Monotonicity Assumption: This assumption posits that the expected scores of the subjects on the test items are expected to increase monotonically with their ability levels.
| Algorithm 1. MCMC-based parameter estimation algorithm for the IRT model |
| Input: Number of subjects N, Number of test items m, Subject score matrix , Markov Chain length L and stability period M 1: for k do 2: At the kth moment, sampling for each subject (i = 1,2,…,N) 3: Sampling from uniform distribution 4: if 1 then 5: Accept to transfer, 6: else 7: Reject to transfer, 8: Sampling of each item parameter (j=1,2,…,m): 10: if 1 then 11: Accept to transfer, 12: else 13: Reject to transfer, 14: Discarding the burn-in period data, we obtain: |
| 1 This is the transfer condition for the Markov Chain in the algorithm for estimating IRT parameter values using the MCMC method. |
4. Open-Source Platform
- Component Modifiers. Component modifiers can modify four types of components: attack methods, defense methods, models, and datasets. The component modifiers allow researchers to easily test and evaluate their implementations of attacks, defenses, or models using SEFI. A large library of pre-built components, Canary Lib, is also available for researchers.
- Security Testing Module. The security testing module consists of five sub-modules: Attack Unit, Model Inference Unit, Adv Disturbance-Aware Tester, Image Processing Unit, and Model Training Unit. The combination of these test modules will provide the necessary data to support the security evaluation.
- Security Evaluation Module. The security evaluation module consists of three sub-modules: attack evaluation, model-baseline evaluation, and defense evaluation:
- (1)
- Attack Evaluation: This module contains the Attack Cost Evaluator (Adv Example Disturbance-aware and Cost Evaluator) and the Attack Deflection Capability Evaluator. In this module, we implement the calculation of 17 numerical metrics for adversarial attacks (see Section 3.1.2 and Section 3.1.3 for details). The attack evaluation allows the user to evaluate how well the generated adversarial examples transfer the inference results of the target model, the quality of the examples themselves, and how well these adversarial examples transfer against non-target models.
- (2)
- Model-baseline Evaluation: This module contains the Model Inference Capability Analyzer. In this module, we implement three common baseline metrics of model inference capability (see Section 3.1.1 for details). The model-baseline evaluation allows the user to evaluate the model’s performance to be tested and to make better trade-offs between model quality and robustness.
- (3)
- Defense Evaluation: This module contains the Defense Capability Analyzer. In this module, we have implemented four (classes of) common baseline metrics of model inferential capabilities (see Section 3.1.4 for more details; due to the nature of defense evaluation, most of the relevant sub-metrics are presented in the form of pre- and post-defense differences, so we will not repeat them here). The defense evaluation allows the user to evaluate the effectiveness of the defense method to be tested.
- System Module. The system modules include the SQLite access module, the disk file access module, the web service module, the exception detection module, the interruption recovery module, and so on. These modules are mainly used to access test data, interact with experimental data and progress to the visualization interface, provide error information when an error occurs, and resume the experimental task from the point of interruption.
- A library of pre-built components. The in-built library is integrated using component modifiers. The presets library contains three types of components that have been pre-implemented:
- (1)
- Attack methods. We have integrated 30 adversarial attack methods in the presets library, including 15 white-box attacks and 15 black-box attacks. These attack methods have been selected, considering attack specificity, attack paths, and perturbation characteristics to make the coverage as comprehensive as possible.
- (2)
- Defense methods. We have integrated 10 adversarial defenses in the pre-built library, including 4 image processing defenses, 4 adversarial training, and 2 adversarial example identification defenses. The selection of these methods takes into account the path of defense, the target of the defense, and the cost of the defense so that the coverage is as comprehensive as possible.
- (3)
- Models. We integrated 18 artificial intelligence models in the pre-built library and provided them with pre-training parameters based on ImageNet, CIFAR-10/100 datasets.
In selecting these pre-built components, we focused on the importance of discussion and relevant contributions in the open-source community and finally selected those algorithms, models, and datasets that are being widely discussed and used. - In-built benchmarking database. We have conducted a comprehensive cross-test of 15 models and 20 attack methods and constructed the results into an open benchmark database. For details, please refer to Section 5 of this paper.
5. Evaluations
5.1. Experimental Setup
5.2. Evaluation of Adversarial Attack Effectiveness
5.2.1. Evaluation of Attack Effectiveness
5.2.2. Evaluation of Computational Cost
5.2.3. Evaluation of Perturbation-Awareness Cost
5.3. Evaluation of Transferability
5.4. Evaluation of Model Robustness
5.4.1. Evaluation of Model Capabilities
5.4.2. Evaluation of Under-Attack Effectiveness
5.4.3. IRT-Based Comprehensive Evaluation
5.4.4. Black- and White-Box Attack Differences
5.5. Attack vs. Model
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Details of the Main Adversarial Attack Algorithms in Our Evaluations
Appendix A.1. White-Box Attacks
Appendix A.2. Query-Based Black-Box Attacks
Appendix A.3. Transferable Black-Box Attacks
Appendix B. Open-Source Platform Structure and Metrics Calculation Process
- -
- Fairness—the platform’s evaluation of model security and attack and defense effectiveness should be conducted on an equal footing or with the introduction of necessary parameters to eliminate discrepancies, resulting in a fair score and ranking.
- -
- Universality—the platform should include comprehensive and rigorous metrics that can be universally applied to all types of models and the most representative baseline models, attack, and defense methods to draw comprehensive conclusions.
- -
- Extensibility—the platform should be fully decoupled from the attack/defense methods library, making it easy to integrate new attack/defense methods while reducing intrusion into the target code.
- -
- Clearness—the platform should give intuitive, clear, and easy-to-understand final evaluation results and be able to accurately measure the distance of the model or method under test against a baseline and against other models or methods.
- -
- Quick Deployability—the platform should be quickly deployable to any device without the need for cumbersome configuration and coding and without creating baselines, repeatedly allowing for rapid evaluation results.




References
- Hu, Y.; Yang, J.; Chen, L.; Li, K.; Sima, C.; Zhu, X.; Chai, S.; Du, S.; Lin, T.; Wang, W. Planning-oriented autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17853–17862. [Google Scholar]
- Liu, Y.; Yang, J.; Gu, X.; Guo, Y.; Yang, G.-Z. EgoHMR: Egocentric Human Mesh Recovery via Hierarchical Latent Diffusion Model. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), ExCel, London, UK, 29 May–2 June 2023; pp. 9807–9813. [Google Scholar]
- Shin, H.; Kim, H.; Kim, S.; Jun, Y.; Eo, T.; Hwang, D. SDC-UDA: Volumetric Unsupervised Domain Adaptation Framework for Slice-Direction Continuous Cross-Modality Medical Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7412–7421. [Google Scholar]
- Liu, F.; Wu, X.; Ge, S.; Fan, W.; Zou, Y. Exploring and distilling posterior and prior knowledge for radiology report generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13753–13762. [Google Scholar]
- Jaszcz, A.; Połap, D. AIMM: Artificial intelligence merged methods for flood DDoS attacks detection. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 8090–8101. [Google Scholar] [CrossRef]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object Detection on Drone Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13435–13444. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Huang, H.; Chen, Z.; Chen, H.; Wang, Y.; Zhang, K. T-sea: Transfer-based self-ensemble attack on object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 20514–20523. [Google Scholar]
- Wei, Z.; Chen, J.; Wu, Z.; Jiang, Y.-G. Enhancing the Self-Universality for Transferable Targeted Attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12281–12290. [Google Scholar]
- Wang, X.; Zhang, Z.; Tong, K.; Gong, D.; He, K.; Li, Z.; Liu, W. Triangle attack: A query-efficient decision-based adversarial attack. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–28 October 2022; pp. 156–174. [Google Scholar]
- Frosio, I.; Kautz, J. The Best Defense is a Good Offense: Adversarial Augmentation against Adversarial Attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4067–4076. [Google Scholar]
- Addepalli, S.; Jain, S.; Sriramanan, G.; Venkatesh Babu, R. Scaling adversarial training to large perturbation bounds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–28 October 2022; pp. 301–316. [Google Scholar]
- Połap, D.; Jaszcz, A.; Wawrzyniak, N.; Zaniewicz, G. Bilinear pooling with poisoning detection module for automatic side scan sonar data analysis. IEEE Access 2023, 11, 72477–72484. [Google Scholar] [CrossRef]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A. Technical report on the cleverhans v2. 1.0 adversarial examples library. arXiv 2016, arXiv:1610.00768. [Google Scholar]
- Rauber, J.; Brendel, W.; Bethge, M. Foolbox: A python toolbox to benchmark the robustness of machine learning models. arXiv 2017, arXiv:1707.04131. [Google Scholar]
- Nicolae, M.-I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H. Adversarial Robustness Toolbox v1. 0.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Ding, G.W.; Wang, L.; Jin, X. AdverTorch v0. 1: An adversarial robustness toolbox based on pytorch. arXiv 2019, arXiv:1902.07623. [Google Scholar]
- Ling, X.; Ji, S.; Zou, J.; Wang, J.; Wu, C.; Li, B.; Wang, T. Deepsec: A uniform platform for security analysis of deep learning model. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; pp. 673–690. [Google Scholar]
- Goodman, D.; Xin, H.; Yang, W.; Yuesheng, W.; Junfeng, X.; Huan, Z. Advbox: A toolbox to generate adversarial examples that fool neural networks. arXiv 2020, arXiv:2001.05574. [Google Scholar]
- Dong, Y.; Fu, Q.-A.; Yang, X.; Pang, T.; Su, H.; Xiao, Z.; Zhu, J. Benchmarking adversarial robustness on image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 321–331. [Google Scholar]
- Croce, F.; Andriushchenko, M.; Sehwag, V.; Debenedetti, E.; Flammarion, N.; Chiang, M.; Mittal, P.; Hein, M. Robustbench: A standardized adversarial robustness benchmark. arXiv 2020, arXiv:2010.09670. [Google Scholar]
- Guo, J.; Bao, W.; Wang, J.; Ma, Y.; Gao, X.; Xiao, G.; Liu, A.; Dong, J.; Liu, X.; Wu, W. A comprehensive evaluation framework for deep model robustness. Pattern Recognit. 2023, 137, 109308. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, NV, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the British Machine Vision Conference 2016, BMVC 2016, York, UK, 19–22 September 2016. [Google Scholar]
- Embretson, S.E.; Reise, S.P. Item Response Theory; Psychology Press: Vermont, UK, 2013. [Google Scholar]
- Geyer, C.J. Practical markov chain monte carlo. Stat. Sci. 1992, 7, 473–483. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Congress Center Saar, Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar]
- Lin, J.; Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, X.; He, K. Enhancing the transferability of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, Nashville, TN, USA, 20–25 June 2021; pp. 1924–1933. [Google Scholar]
- Chen, P.-Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.-J. Ead: Elastic-net attacks to deep neural networks via adversarial examples. In Proceedings of the AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Luo, C.; Lin, Q.; Xie, W.; Wu, B.; Xie, J.; Shen, L. Frequency-driven imperceptible adversarial attack on semantic similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 15315–15324. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Narodytska, N.; Kasiviswanathan, S.P. Simple black-box adversarial perturbations for deep networks. arXiv 2016, arXiv:1612.06299. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bhagoji, A.N.; He, W.; Li, B.; Song, D. Exploring the space of black-box attacks on deep neural networks. arXiv 2017, arXiv:1712.09491. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 1277–1294. [Google Scholar]
- Alzantot, M.; Sharma, Y.; Chakraborty, S.; Zhang, H.; Hsieh, C.-J.; Srivastava, M.B. Genattack: Practical black-box attacks with gradient-free optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, CECCO 2019, Prague, Czech Republic, 13–17 July 2019; pp. 1111–1119. [Google Scholar]
- Uesato, J.; O’donoghue, B.; Kohli, P.; Oord, A. Adversarial risk and the dangers of evaluating against weak attacks. In Proceedings of the International Conference on Machine Learning, ICML 2018, Jinan, China, 26–28 May 2018; pp. 5025–5034. [Google Scholar]
- Chen, P.-Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.-J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, AISec 2017, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.-Y.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 3905–3911. [Google Scholar]
- Huang, Z.; Zhang, T. Black-Box Adversarial Attack with Transferable Model-based Embedding. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Croce, F.; Hein, M. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; pp. 2206–2216. [Google Scholar]
- Lorenz, P.; Strassel, D.; Keuper, M.; Keuper, J. Is robustbench/autoattack a suitable benchmark for adversarial robustness? arXiv 2021, arXiv:2112.01601. [Google Scholar]
- Ma, L.; Juefei-Xu, F.; Zhang, F.; Sun, J.; Xue, M.; Li, B.; Chen, C.; Su, T.; Li, L.; Liu, Y. Deepgauge: Multi-granularity testing criteria for deep learning systems. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, ASE 2018, Montpellier, France, 3–7 September 2018; pp. 120–131. [Google Scholar]
- Yan, S.; Tao, G.; Liu, X.; Zhai, J.; Ma, S.; Xu, L.; Zhang, X. Correlations between deep neural network model coverage criteria and model quality. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2020, Virtual Event, 8–13 November 2020; pp. 775–787. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, ICML, Virtual Event, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Shensa, M.J. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Zhang, B.; Sander, P.V.; Bermak, A. Gradient magnitude similarity deviation on multiple scales for color image quality assessment. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), ICASSP 2017, New Orleans, LA, USA, 5–9 March 2017; pp. 1253–1257. [Google Scholar]
- Xue, W.; Zhang, L.; Mou, X.; Bovik, A.C. Gradient magnitude similarity deviation: A highly efficient perceptual image quality index. IEEE Trans. Image Process. 2013, 23, 684–695. [Google Scholar] [CrossRef]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image quality assessment: Unifying structure and texture similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Comparison of full-reference image quality models for optimization of image processing systems. Int. J. Comput. Vis. 2021, 129, 1258–1281. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the Thirty-First Conference on Neural Information Processing Systems, NeurIPS 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4312–4321. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Jandial, S.; Mangla, P.; Varshney, S.; Balasubramanian, V. Advgan++: Harnessing latent layers for adversary generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, ICCVW 2019, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 2730–2739. [Google Scholar]
- Wang, Z.; Guo, H.; Zhang, Z.; Liu, W.; Qin, Z.; Ren, K. Feature importance-aware transferable adversarial attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 7639–7648. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| is the set of original images, where denotes the th image in the set. | |
| is the set of original images corresponding to ground-truth labels, where denotes the label of the th image in the set , and . | |
| , | is a deep-learning-based image k-class classifier that has when classified correctly. |
| is the Softmax layer of , . | |
| denotes the probability that is inferred to be by , also known as the confidence level, where . | |
| is the adversarial example, where is generated by the attack method. | |
| For targeted attacks only, is the label of the specified target. |
| Algorithm | Perturbation Measurement | Attacker’s Knowledge | Attack Approach | |
|---|---|---|---|---|
| FGSM [32] | white-box | gradient | ||
| JSMA [33] | white-box | gradient | ||
| DeepFool [34] | white-box | gradient | ||
| I-FGSM (BIM) [35] | white-box | gradient | ||
| C&W Attack [23] | white-box | gradient | ||
| Projected Gradient Descent (PGD) [36] | white-box | gradient | ||
| MI-FGSM (MIM) [37] | transferable black-box | transfer, gradient | ||
| SI-FGSM (SIM) [38] | transferable black-box | transfer, gradient | ||
| NI-FGSM (NIM) [38] | transferable black-box | transfer, gradient | ||
| VMI-FGSM (VMIM) [39] | transferable black-box | transfer, gradient | ||
| Elastic-Net Attack (EAD) [40] | white-box | gradient | ||
| SSAH [41] | - | white-box | gradient | |
| One-pixel Attack (OPA) [42] | black-box | query, score | Soft Label | |
| Local Search Attack (LSA) [43] | black-box | query, score | Soft-Label | |
| Boundary Attack (BA) [44] | black-box | query, decision | Hard-Label | |
| Spatial Attack (SA) [45] | - | black-box | query | Hard-Label |
| Hop Skip Jump Attack (HSJA) [46] | black-box | query, decision | Hard-Label | |
| Gen Attack (GA) [47] | black-box | query, score | Soft-Label | |
| SPSA [48] | black-box | query, score | Soft-Label | |
| Zeroth-Order Optimization (ZOO) [49] | black-box | query, score | Soft-Label | |
| AdvGan [50] | black-box | query, score | Soft-Label | |
| TREMBA [51] | - | black-box | query, score | Soft-Label |
| Tool | Type | Publication Time | Researcher | Support Framework 3 | Test Dataset 3 | Attack Algorithm 3 | Defense Algorithm 3 | Number of Evaluation Metrics 3 | In-built Model 3 | Filed |
|---|---|---|---|---|---|---|---|---|---|---|
| CleverHans [14] | Method Toolkit | 2016 | Pennsylvania State University | 3 | × | 16 | 1 | × | × | Image Classification |
| Foolbox [15] | Method Toolkit | 2017 | University of Tübingen | 3 | × | >30 | 1 | 3 | × | Image Classification |
| ART [16] | Method Toolkit | 2018 | IBM Research Ireland | 10 | × | 28 1 | >20 1 | 6 | × | Image Classification Target Detection Target Tracking Speech Recognition |
| AdverTorch [17] | Evolution Framework | 2019 | Borealis AI | 1 | × | 21 | 7 | × | × | Image Classification |
| DEEPSEC [18] | Evolution Framework | 2019 | Zhejiang University | 1 | 2 | 16 | 13 | 14 | 4 | Image Classification |
| AdvBox [19] | Method Toolkit | 2020 | Baidu Inc. | 7 | × | 10 | 6 | × | × | Image Classification Target Detection |
| Ares [20] | Evolution Framework | 2020 | Tsinghua University | 1 | 2 | 19 | 10 | 2 | 15 | Image Classification |
| RobustBench [21] | Evolution Framework | 2021 | University of Tübingen | × | 3 | 1 | × | × | 120+ 2 | Image Classification |
| AISafety [22] | Evolution Framework | 2023 | Beijing University of Aeronautics and Astronautics | 1 | 2 | 20 | 5 | 23 | 3 | Image Classification |
| Canary (Ourselves) | Evolution Framework | 2023 | Beijing Institute of Technology | 1 | 4 | >30 | 10 | 26 | 18 | Image Classification |
| Attack | Attack Effects | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Attack Type | Attacks | MR | ACC | ACAMC | OTR 1 | ||||
| AIAC | ARTC | ACAMCA | ACAMCT | Simple | Full | ||||
| White Box | FGSM | 79.1% | 21.4% | 64.3% | 0.895 | 0.900 | 32.47% | - | |
| JSMA | 75.3% | 23.1% | 45.1% | 0.811 | 0.955 | 6.86% | - | ||
| DeepFool | 99.9% | 38.3% | 49.7% | 0.893 | 0.985 | 0.61% | - | ||
| I-FGSM | 96.9% | 80.6% | 74.6% | 0.841 | 0.871 | 3.22% | - | ||
| C&W Attack | 98.4% | 33.6% | 43.7% | 0.884 | 0.987 | 0.61% | - | ||
| PGD | 96.4% | 78.8% | 74.4% | 0.843 | 0.880 | 3.23% | - | ||
| EAD | 99.4% | 45.5% | 59.4% | 0.904 | 0.956 | 5.98% | - | ||
| SSAH | 78.4% | 20.1% | 62.2% | 0.930 | 0.841 | 1.74% | - | ||
| Black Box (Transferable Attack) | MI-FGSM | ϵ = 1 | 95.6% | 70.5% | 74.2% | 0.886 | 0.841 | 3.84% | - |
| ϵ = 16 | 100.0% | 96.0% | 75.8% | 0.829 | 0.612 | - | 39.1% | ||
| VMI-FGSM | ϵ = 1 | 93.8% | 62.4% | 73.4% | 0.890 | 0.850 | 4.53% | - | |
| ϵ = 16 | 99.9% | 95.3% | 75.8% | 0.838 | 0.605 | - | 62.1% | ||
| NI-FGSM | ϵ = 1 | 97.2% | 82.3% | 74.6% | 0.872 | 0.839 | 3.39% | - | |
| ϵ = 16 | 100.0% | 96.4% | 75.8% | 0.828 | 0.597 | - | 33.2% | ||
| SI-FGSM | ϵ = 1 | 95.2% | 71.0% | 73.8% | 0.886 | 0.835 | 4.36% | - | |
| ϵ = 16 | 100.0% | 96.4% | 75.8% | 0.826 | 0.596 | - | 38.3% | ||
| Black Box | AdvGan | 94.8% | 50.6% | 69.5% | 0.808 | 0.896 | 26.92% | - | |
| LSA | 55.1% | 6.8% | 35.2% | 0.931 | 0.963 | 22.63% | - | ||
| BA | 73.1% | 12.1% | 44.3% | 0.907 | 0.978 | 1.15% | - | ||
| SA | 42.6% | 12.3% | 21.5% | 0.958 | 0.975 | 12.05% | - | ||
| SPSA | 58.5% | 20.2% | 44.9% | 0.937 | 0.959 | 10.05% | - | ||
| HSJA | 51.2% | −18.3% | 55.4% | 0.916 | 0.946 | 32.05% | - | ||
| GA | 22.0% | −20.1% | 35.8% | 0.956 | 0.975 | 4.50% | - | ||
| TREMBA | 61.8% | 32.5% | 32.7% | 0.932 | 0.976 | 3.63% | - | ||
| Attack | Calculate Cost | Disturbance-Aware Cost | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attack Type | Attacks | CTC 1 | QNC 1 | AND | AED-FD | AMS | ||||||
| QNCF | QNCB | APCR | AED (10−2) | AMD (10−1) | FDL (10−2) | FDH (10−2) | ADMS (10−1) | ALMS (10−1) | ||||
| White Box | FGSM | Very Fast | 1 | 1 | 98.3% | 3.528 | 0.627 | 6.840 | 0.831 | 2.611 | 0.994 | |
| JSMA | Slow | ~1300 | ~1300 | 0.7% | 1.434 | 7.890 | 3.174 | 1.387 | 0.872 | 0.499 | ||
| DeepFool | Very Fast | ~100 | ~100 | 32.3% | 0.091 | 0.089 | 0.241 | 0.055 | 0.041 | 0.007 | ||
| I-FGSM | Very Fast | ~100 | ~100 | 76.2% | 0.186 | 0.039 | 0.443 | 0.097 | 0.139 | 0.015 | ||
| C&W Attack | Very Slow | - | - | 11.0% | 0.033 | 0.116 | 0.137 | 0.035 | 0.020 | 0.003 | ||
| PGD | Very Fast | ~100 | ~100 | 77.0% | 0.188 | 0.039 | 0.441 | 0.098 | 0.134 | 0.015 | ||
| EAD | Slow | ~10,000 | ~5000 | 9.3% | 0.930 | 1.972 | 2.667 | 1.345 | 0.448 | 0.150 | ||
| SSAH | Fast | - | - | 68.9% | 0.351 | 0.289 | 0.869 | 0.027 | 0.268 | 0.016 | ||
| Black Box (Transferable Attack) | MI-FGSM | ϵ = 1 | Fast | ~100 | ~100 | 85.1% | 0.203 | 0.039 | 0.477 | 0.103 | 0.166 | 0.017 |
| ϵ = 16 | 99.0% | 2.996 | 0.627 | 5.953 | 0.873 | 2.213 | 0.877 | |||||
| VMI-FGSM | ϵ = 1 | Slow | ~2000 | ~2000 | 84.3% | 0.202 | 0.039 | 0.477 | 0.103 | 0.185 | 0.017 | |
| ϵ = 16 | 97.4% | 2.992 | 0.628 | 5.990 | 0.903 | 2.369 | 0.980 | |||||
| NI-FGSM | ϵ = 1 | Very Fast | ~100 | ~100 | 77.0% | 0.188 | 0.039 | 0.448 | 0.099 | 0.146 | 0.016 | |
| ϵ = 16 | 99.4% | 2.165 | 0.627 | 4.638 | 0.660 | 1.861 | 0.617 | |||||
| SI-FGSM | ϵ = 1 | Fast | ~300 | ~300 | 80.2% | 0.194 | 0.039 | 0.465 | 0.103 | 0.176 | 0.016 | |
| ϵ = 16 | 99.4% | 2.262 | 0.627 | 4.736 | 0.709 | 1.946 | 0.681 | |||||
| Black Box | AdvGan | - | - | - | 93.0% | 2.462 | 2.868 | 5.814 | 0.938 | 2.778 | 0.589 | |
| LSA | Normal | ~200 | 0 | 5.3% | 5.310 | 9.125 | 9.384 | 3.527 | 1.963 | 1.404 | ||
| BA | Normal | ~10,000 | 0 | 81.3% | 1.117 | 0.815 | 1.756 | 0.188 | 0.597 | 0.129 | ||
| SA | Very Fast | ~120 | 0 | 96.0% | 17.058 | 9.591 | 16.919 | 25.327 | 2.458 | 3.058 | ||
| SPSA | Slow | ~200 | 0 | 97.3% | 2.617 | 0.688 | 4.475 | 0.746 | 1.756 | 0.419 | ||
| HSJA | Very Fast | ~200 | 0 | 93.0% | 8.865 | 1.891 | 13.031 | 1.420 | 3.526 | 1.387 | ||
| GA | Normal | ~10,000 | 0 | 95.6% | 2.244 | 0.629 | 3.840 | 0.452 | 1.589 | 0.311 | ||
| TREMBA | - | - | - | 97.2% | 0.846 | 0.157 | 2.009 | 0.287 | 0.894 | 0.151 | ||
| Attacks | Observable Transfer | |||
|---|---|---|---|---|
| MR | ACC | |||
| AIAC | ARTC | |||
| MI-FGSM | Hot Map |  | ||
| Average | 39.113% | 5.310% | 34.187% | |
| NI-FGSM | Hot Map |  | ||
| Average | 33.175% | 2.190% | 30.077% | |
| SI-FGSM | Hot Map |  | ||
| Average | 38.256% | 4.320% | 34.247% | |
| VMI-FGSM | Hot Map |  | ||
| Average | 62.132% | 17.287% | 51.870% | |
| Model | Model Capability | ||
|---|---|---|---|
| CA | CF | CC | |
| AlexNet | 53.6% | 0.413 | 44.3% |
| VGG | 72.4% | 0.612 | 65.1% |
| GoogLeNet | 68.5% | 0.567 | 54.3% |
| InceptionV3 | 79.1% | 0.694 | 68.4% |
| ResNet | 74.4% | 0.643 | 67.2% |
| DenseNet | 78.8% | 0.692 | 73.4% |
| SqueezeNet | 54.8% | 0.441 | 43.3% |
| MobileNetV3 | 71.7% | 0.611 | 66.6% |
| ShuffleNetV2 | 74.2% | 0.636 | 38.2% |
| MNASNet | 77.0% | 0.672 | 29.9% |
| EfficientNetV2 | 87.0% | 0.813 | 63.2% |
| VisionTransformer | 73.9% | 0.627 | 60.0% |
| RegNet | 81.2% | 0.723 | 76.6% |
| SwinTransformer | 84.0% | 0.766 | 72.2% |
| ConvNeXt | 85.0% | 0.781 | 57.6% |
| Model | Attack Effects | Disturbance-Aware Cost | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MR | ACC | ACAMC | AND | AED-FD | AMS | ||||||||
| AIAC | ARTC | ACAMCA | ACAMCT | APCR | AED (10−2) | AMD (10−1) | FDL (10−2) | FDH (10−2) | ADMS (10−1) | ALMS (10−1) | |||
| White | AlexNet | 96.5% | 50.3% | 65.9% | 0.925 | 0.950 | 65.1% | 0.815 | 1.221 | 1.805 | 0.432 | 0.620 | 0.204 |
| VGG | 98.2% | 70.4% | 76.1% | 0.886 | 0.938 | 59.5% | 0.700 | 1.016 | 1.574 | 0.302 | 0.725 | 0.147 | |
| GoogLeNet | 96.1% | 45.3% | 65.2% | 0.933 | 0.942 | 60.8% | 0.749 | 1.148 | 1.675 | 0.328 | 0.614 | 0.218 | |
| InceptionV3 | 90.3% | 53.8% | 73.5% | 0.923 | 0.920 | 59.7% | 1.063 | 1.300 | 2.370 | 0.530 | 0.678 | 0.270 | |
| ResNet | 96.5% | 66.7% | 74.4% | 0.924 | 0.963 | 60.3% | 0.767 | 1.160 | 1.684 | 0.360 | 0.687 | 0.198 | |
| DenseNet | 96.1% | 71.4% | 77.2% | 0.933 | 0.970 | 61.3% | 0.777 | 1.178 | 1.708 | 0.392 | 0.725 | 0.219 | |
| SqueezeNet | 98.4% | 57.3% | 64.7% | 0.931 | 0.969 | 60.3% | 0.743 | 1.253 | 1.611 | 0.330 | 0.609 | 0.176 | |
| MobileNetV3 | 97.0% | 69.1% | 77.7% | 0.880 | 0.852 | 62.3% | 0.752 | 1.022 | 1.757 | 0.306 | 0.716 | 0.200 | |
| ShuffleNetV2 | 94.5% | 34.1% | 42.7% | 0.807 | 0.862 | 56.2% | 0.681 | 1.035 | 1.557 | 0.264 | 0.486 | 0.137 | |
| MNASNet | 91.2% | 31.3% | 31.7% | 0.801 | 0.882 | 57.4% | 0.700 | 0.971 | 1.574 | 0.346 | 0.643 | 0.150 | |
| EfficientNetV2 | 82.1% | 48.4% | 57.3% | 0.766 | 0.884 | 58.9% | 0.921 | 1.114 | 2.287 | 0.784 | 0.527 | 0.211 | |
| ViT | 86.8% | 40.5% | 61.7% | 0.754 | 0.837 | 66.6% | 0.978 | 1.296 | 2.326 | 0.822 | 0.703 | 0.278 | |
| RegNet | 95.4% | 70.5% | 78.5% | 0.889 | 0.953 | 59.8% | 0.745 | 1.080 | 1.568 | 0.314 | 0.682 | 0.160 | |
| SwinT | 91.9% | 63.8% | 68.7% | 0.877 | 0.880 | 55.8% | 0.847 | 1.297 | 1.743 | 0.399 | 0.654 | 0.188 | |
| ConvNeXt | 91.6% | 49.6% | 55.7% | 0.575 | 0.898 | 61.7% | 0.812 | 1.156 | 1.792 | 0.582 | 0.579 | 0.168 | |
| Black | AlexNet | 67.8% | 13.6% | 49.8% | 0.938 | 0.961 | 81.1% | 4.922 | 3.130 | 6.636 | 4.715 | 1.760 | 0.899 |
| VGG | 63.6% | 15.2% | 52.6% | 0.910 | 0.962 | 79.0% | 4.900 | 3.130 | 6.573 | 4.385 | 1.729 | 0.888 | |
| GoogLeNet | 55.7% | −0.5% | 42.8% | 0.971 | 0.989 | 82.1% | 5.561 | 3.271 | 7.456 | 4.868 | 1.893 | 0.996 | |
| InceptionV3 | 39.1% | −6.3% | 43.0% | 0.968 | 0.984 | 78.9% | 6.770 | 3.995 | 8.996 | 5.294 | 1.910 | 1.186 | |
| ResNet | 49.9% | 5.0% | 40.0% | 0.967 | 0.986 | 80.8% | 5.251 | 3.205 | 7.037 | 4.635 | 1.812 | 0.959 | |
| DenseNet | 53.2% | 12.4% | 43.9% | 0.975 | 0.989 | 81.2% | 5.632 | 3.289 | 7.534 | 4.802 | 1.920 | 1.018 | |
| SqueezeNet | 74.9% | 14.4% | 50.4% | 0.954 | 0.977 | 79.2% | 4.471 | 3.010 | 5.973 | 4.497 | 1.575 | 0.810 | |
| MobileNetV3 | 53.5% | 8.6% | 46.8% | 0.912 | 0.952 | 81.5% | 5.199 | 3.209 | 7.236 | 4.337 | 1.816 | 0.975 | |
| ShuffleNetV2 | 50.5% | −1.4% | 26.6% | 0.937 | 0.977 | 80.4% | 5.240 | 3.223 | 7.158 | 4.387 | 1.804 | 0.955 | |
| MNASNet | 49.0% | −1.4% | 19.7% | 0.949 | 0.978 | 80.4% | 5.196 | 3.191 | 7.033 | 4.646 | 1.787 | 0.961 | |
| EfficientNetV2 | 32.9% | −0.6% | 25.2% | 0.943 | 0.976 | 78.6% | 6.597 | 4.069 | 8.604 | 4.702 | 1.761 | 1.138 | |
| ViT | 50.7% | 6.3% | 35.5% | 0.817 | 0.872 | 80.8% | 5.974 | 3.365 | 8.091 | 4.737 | 1.966 | 1.087 | |
| RegNet | 50.9% | 12.4% | 44.0% | 0.934 | 0.978 | 80.7% | 5.392 | 3.230 | 7.214 | 4.710 | 1.900 | 0.977 | |
| SwinT | 44.1% | 8.1% | 33.0% | 0.972 | 0.987 | 81.1% | 5.995 | 3.426 | 8.243 | 4.453 | 2.022 | 1.064 | |
| ConvNeXt | 37.8% | 1.6% | 25.0% | 0.868 | 0.950 | 81.0% | 6.116 | 3.422 | 8.327 | 4.637 | 2.006 | 1.075 | |
| Model | CA ↑ Rank 1 | MR ↓ | IRT ↑ | ||||
|---|---|---|---|---|---|---|---|
| White Rank 1 | Black Rank 1 | White | Black | ||||
| Score (Θ) | Rank 1 | Score (Θ) | Rank 1 | ||||
| SqueezeNet | 2 | 1 | 1 | 0.07 | 2 | 0 | 1 |
| MobileNet V3 | 4 | 3 | 5 | 0 | 1 | 0.35 | 4 |
| VGG | 5 | 2 | 3 | 0.08 | 3 | 0.2 | 3 |
| AlexNet | 1 | 4 | 2 | 0.18 | 5 | 0.1 | 2 |
| ShuffleNet V2 | 7 | 9 | 9 | 0.16 | 4 | 0.47 | 6 |
| MNASNet | 9 | 12 | 11 | 0.38 | 7 | 0.52 | 7 |
| ResNet | 8 | 5 | 10 | 0.38 | 7 | 0.55 | 8 |
| ConvNeXt | 14 | 11 | 14 | 0.31 | 6 | 0.76 | 12 |
| GoogLeNet | 3 | 6 | 4 | 0.4 | 9 | 0.57 | 9 |
| ViT | 6 | 14 | 8 | 0.76 | 13 | 0.36 | 5 |
| RegNet | 12 | 8 | 7 | 0.47 | 10 | 0.6 | 10 |
| DenseNet | 10 | 7 | 6 | 0.67 | 12 | 0.66 | 11 |
| SwinT | 13 | 10 | 12 | 0.59 | 11 | 0.91 | 13 |
| Inception V3 | 11 | 13 | 13 | 0.99 | 14 | 1 | 15 |
| EfficientNet V2 | 15 | 15 | 15 | 1 | 15 | 0.93 | 14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Chen, L.; Xia, C.; Zhang, D.; Huang, R.; Qiu, Z.; Xiong, W.; Zheng, J.; Tan, Y.-A. CANARY: An Adversarial Robustness Evaluation Platform for Deep Learning Models on Image Classification. Electronics 2023, 12, 3665. https://doi.org/10.3390/electronics12173665
Sun J, Chen L, Xia C, Zhang D, Huang R, Qiu Z, Xiong W, Zheng J, Tan Y-A. CANARY: An Adversarial Robustness Evaluation Platform for Deep Learning Models on Image Classification. Electronics. 2023; 12(17):3665. https://doi.org/10.3390/electronics12173665
Chicago/Turabian StyleSun, Jiazheng, Li Chen, Chenxiao Xia, Da Zhang, Rong Huang, Zhi Qiu, Wenqi Xiong, Jun Zheng, and Yu-An Tan. 2023. "CANARY: An Adversarial Robustness Evaluation Platform for Deep Learning Models on Image Classification" Electronics 12, no. 17: 3665. https://doi.org/10.3390/electronics12173665
APA StyleSun, J., Chen, L., Xia, C., Zhang, D., Huang, R., Qiu, Z., Xiong, W., Zheng, J., & Tan, Y.-A. (2023). CANARY: An Adversarial Robustness Evaluation Platform for Deep Learning Models on Image Classification. Electronics, 12(17), 3665. https://doi.org/10.3390/electronics12173665