1. Introduction
The rapid advancement in Virtual Reality (VR) and Augmented Reality (AR) technologies has imposed a compelling requirement for expanded data capacities to underpin immersive experiences. These technologies depend on high-resolution visuals, 3D models, and frequent real-time interactions, all of which necessitate substantial data transfers. Alongside the advancement in ultra-high-speed internet services, the nature of information delivery is evolving from simple text characters to large capacity multimedia. This transformation has led to an increased demand for high-performance routers and high- speed links.
A high-performance router is a networking device designed to efficiently manage and route data traffic between various devices within a local network and between the local network and the broader internet. The router’s function involves retrieving Internet Protocol (IP) addresses from a lookup table and forwarding packets to their destinations. This role has become a crucial factor in determining the communication efficiency of advanced networks, as it depends on how quickly data within the lookup table can be searched and processed. In recent years, numerous studies on content-addressable memory (CAM)-based lookup tables have been conducted to overcome router time delays and achieve high-speed packet transmission. CAM-based lookup table technology is a specialized memory architecture designed to expedite data search and retrieval operations.
CAM is categorized as an associative memory and is often contrasted with RAM. CAM serves as a specialized type of memory primarily used for rapid data searches and retrievals. It is designed to swiftly determine whether a specific data value or pattern exists within its memory cells. Conversely, random access memory (RAM) is a general-purpose volatile memory employed to temporarily store data actively used by the computer’s Central Processing Unit (CPU). These differences can be illustrated by comparing the memory architectures shown in
Figure 1.
As shown
Figure 1a, CAM executes high-speed search operations due to its parallel readout logic. In other words, CAM is given the search data, and in return, it provides the address where those data are stored. This capability makes it highly efficient for tasks such as searching and pattern matching. On the other side, as shown
Figure 1b, RAM is organized into cells with unique addresses, and data are accessed using these addresses. RAM holds program instructions and the data currently being processed. In contrast to RAM, to which the operating system provides a memory address to access data sequentially, the CAM searches for all the words that make up the array in a single cycle [
1].
For this operation, the CAM requires a data line driver to simultaneously apply search data, a Match Line Sense Amplifier (MLSA), and an encoder to determine and output search results. CAM is more complex and expensive to manufacture than traditional RAM due to its specialized search capabilities. Due to these differences, CAMs have disadvantages in terms of both area and power.
CAM is classified into binary CAM (BCAM) and ternary CAM (TCAM) based on the search results.
BCAM is a type of memory that searches for patterns consisting of 0 s and 1 s within received data and returns the address of the exact matching pattern. The CAM serves as an effective hardware device for information retrieval applications with a fixed length of fields. A clear distinction exists between BCAM and TCAM in that TCAM allows a third matching state of ‘don’t care’ (X), in addition to 0 s and 1 s, as a search result. The X state, representing a wildcard or mask bit, can yield a matched result based on the mask condition even when the search word and stored data do not match each other. As a result, TCAM not only enhances search engine throughput by extending the search range of patterns, but also offers search flexibility, such as pattern matching [
2].
TCAM is widely employed as hardware for selecting the longest matching prefix (LMP) in a lookup table, which permits variable-length prefixes in the context of classless interdomain routing (CIDR), introduced to increase flexibility in the IP address domain. Furthermore, the search efficiency expands the application scope to various mobile network systems, including motion detection, security, and even artificial neural networks [
3].
Conclusively, TCAM is an associative memory that performs a search operation with data input to output the matched address of the stored data in a single cycle. TCAM possesses an advantage of including an X state (don’t care state) in comparison to conventional binary CAM (BCAM).
TCAM has faced criticism due to its significant power consumption, despite its fast search performance. The power issue becomes increasingly important as the operating frequency of TCAM applications and the memory density requirements rise [
3].
The primary sources of power consumption in TCAM are the toggling of search lines (SL) and discharging through match lines (ML) [
4]. In the prevalent NOR-type TCAM, all MLs are pre-charged and most of them are discharged in each comparison cycle. Consequently, MLs contribute the most to power consumption, with the toggling of SLs following MLs in terms of power consumption [
5,
6].
Therefore, numerous approaches have been proposed to decrease power consumption in MLs, including reducing the voltage swing of MLs and modifying the structure and operation of TCAM. Implementing an adaptive pre-charging strategy based on changes in search keys can prove to be an effective method of conserving power [
7].
The Selective pre-charging of Match Lines (SML) algorithm proposed in this paper operates by selectively pre-charging the MLs through a comparison of the search keys. To achieve this selective pre-charging based on the search keys, a sequence of search keys must be compared, and the pre-charging method to be employed needs to be determined through this comparison process.
In the latter part of this paper, the approach for establishing the comparison range of the search keys is outlined, and the implementation method of the SML algorithm is detailed. Additionally, the power-saving effects demonstrated by the simulation results are presented.
2. Basic Operation of Conventional TCAM
To enhance packet forwarding performance in line with high-speed link-to-link communication, a rapid address lookup capability is imperative. To achieve this, the existing TCAM architecture utilizes a parallel search configuration, ensuring high-speed operations as depicted in
Figure 2.
Upon input of the search pattern, the data line driver propels the search word along the vertical DL/DLB (data line). The data line in a TCAM is a fundamental component responsible for carrying and transmitting search patterns and comparison results within the TCAM structure.
Subsequently, the search operation commences. The match line, situated horizontally, shares memory cells that store one word of the data while being maintained in a floating state, VDD. Simultaneously with the search operation, the driven DL/DLB performs a comparison function against the data stored in the memory cells. The resulting mismatched cell forms a discharge current path for the ML, causing the voltage level of the ML to drop to VSS. Conversely, when all bits of a word match, the ML can maintain a pre-charge state at VDD. The sense amplifier connected to each ML gauges whether the stored word corresponds to the search word by assessing the voltage level of the ML. Ultimately, the priority encoder delivers the address index of the matched ML.
3. Power Analysis of TCAM
The power consumption on the MLs occurs during the discharge of the pre-charged current in the mismatched cell. The discharging current is influenced by factors such as the number of mismatched cells, the count of mismatched MLs, and the operating frequency of the TCAM. A higher number of mismatched cells on the ML results in increased discharging current. Similarly, the discharging current rises in direct proportion to the quantity of mismatched MLs, the operating VDD, and the TCAM’s operating frequency.
To analyze TCAM’s power consumption, we conducted simulations using the 180 nm CMOS technology. We constructed a TCAM array with a word length (WL) of 12 × 64 bits. Operating at a frequency of 250 MHz and VDD of 1.8 V, the power consumption is approximately 2.02 mW.
Figure 3 represents the simulation results of power consumption for the conventional TCAM across the VDD range from 1.2 V to 1.8 V. An analysis of these results is then conducted.
Figure 4 shows the computed power consumption of a 12 × 64 SRAM-based TCAM. In
Figure 4a, the portion of power consumption attributed to MLs is depicted, specifically when only 1 bit mismatches within a word. The power consumed by the match lines accounts for 69.2% of the total power consumption. Moving to
Figure 4b, it demonstrates how this consumption varies when the search pattern matches the stored data. That is, when the ML matches, the power consumed by the match line accounts for 82.3% of the total power consumption. Therefore, from
Figure 4a,b, it becomes evident that the power consumed by the ML varies based on whether the ML is matched or mismatched.
Figure 4c breaks down the total power dissipation by MLs into portions for matched and mismatched MLs. In the mismatched ML, 99.3% of the total power was consumed by the ML. In summary, as highlighted in
Figure 4, MLs account for the most significant power consumption within the TCAM, with most of the power being dynamically dissipated through MLs in the event of mismatched words.
Simulation results indicate that the power consumption arising from the charging and discharging of MLs constitutes approximately 69% of the total power budget. This is because TCAM’s ML is more likely to consist primarily of mismatched lines after the search operation, with the match case consuming significantly less power in comparison to the mismatch case. The proposed methods for reducing the power consumed by the MLs can be roughly categorized into three approaches. These methods involve reducing the swing voltage, segregating the MLs, implementing a hierarchical ML structure, and partitioning the TCAM entries into separate sub-banks.
Reducing the voltage swing is a way to reduce the amount of discharging current by lowering the voltage on the MLs. For this method, an additional sensing circuit is needed to compensate for this to check whether it is a match. Separating the operations of the MLs or using hierarchical MLs is a way to reduce the occurrence probability of discharging current.
This method has high complexity when constructing a TCAM cell array. The method of using a sub-bank involves classifying the cell array of TCAM into a sub-bank, and operating only a cell array which requires operation. The method may be applicable only to special entry [
8].
In comparison to the conventional method, SML holds the advantage of providing flexibility in constructing TCAM entries, and the additional circuitry requires a small area. And SML can optimize power saving by pre-charging necessary MLs through a comparison of a series of search keys.
4. Results
SML proceeds by comparing the Nth search key with the (N-1)th search key, and the pre-charging is performed by reflecting the previous matching result for the next search cycle.
4.1. Proposed SML
4.1.1. Architecture
Figure 5 shows the flow chart of SML. When the TCAM operation starts and the search key is loaded, SML compares the columns of the search key corresponding to the column where there is no X cell in the TCAM entry. The reason the X cell determines the location for comparison is to optimize the comparison based on the TCAM entry and the search keys. Optimized comparisons can maximize power savings.
For the power saving, it is necessary to determine the location of the X cell of the TCAM entry. Once the location of the X cell is defined, the location is stored in the Mask Register (MR), and the search key is masked and compared with the previous masked search key.
If the Nth search key and the (N-1)th search key are the same, the SML pre-charges only the matched MLs at the (N-1)th search. On the contrary, if the comparison result is not the same, only the mismatched MLs are pre-charged. When pre-charging is complete, the search key is driven and the search proceeds. Since only MLs that require search are pre-charged, the number of MLs to be discharged can be reduced. Of course, if additional circuitry is configured, the (N-1)th search result can be returned directly if both the Nth search key and the (N-1)th search key are perfectly identical.
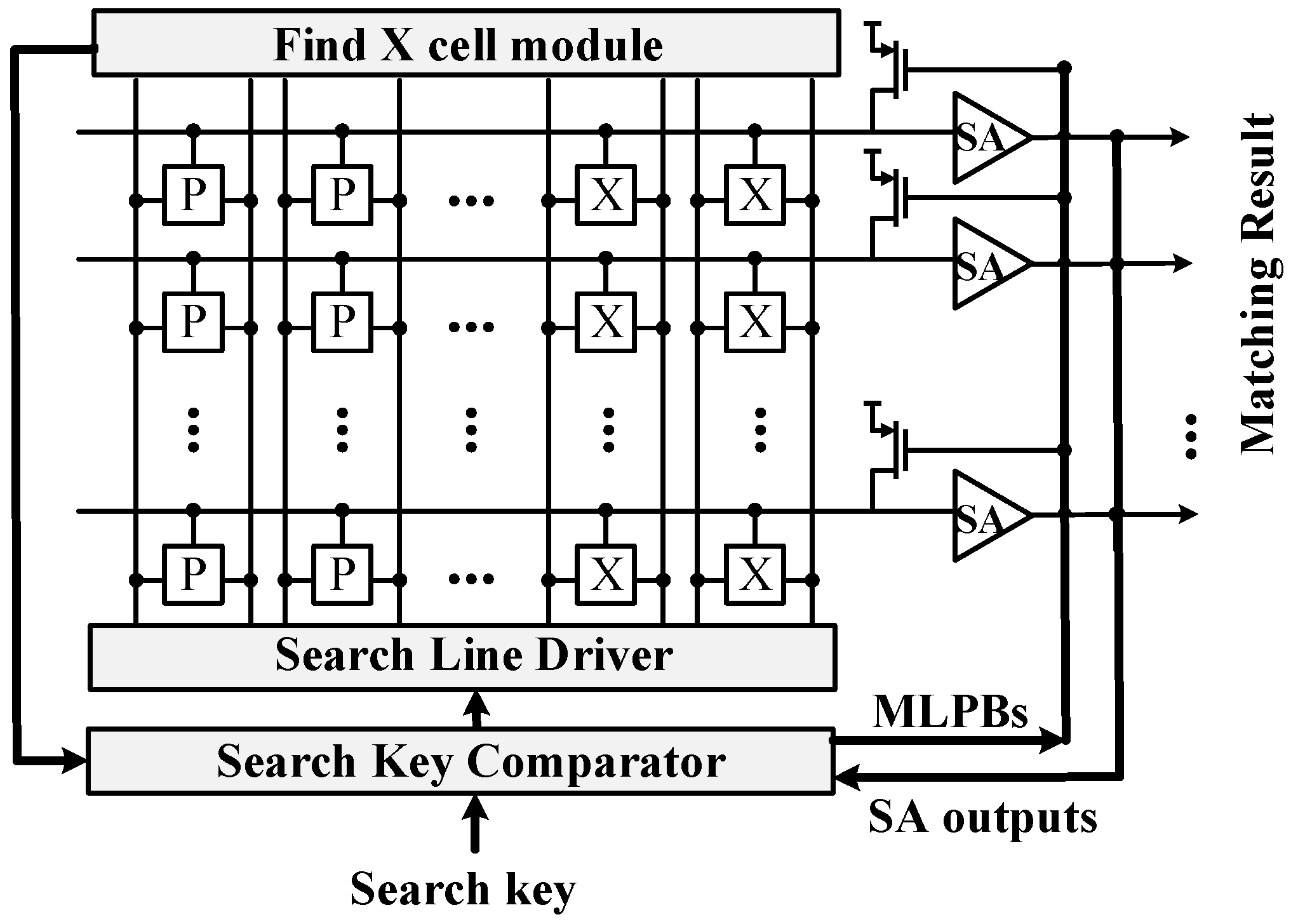
To implement this algorithm, SML only requires a Search Key Comparator (SKC) and a Find X cell Module (FXM) compared to existing TCAM architectures.
Figure 6 shows the architecture of the TCAM with SML.
SKC receives the search result from the sense amplifier (SA) and the location of the X cell in the FXM. It then performs a comparison between the (N-1)th search key and the Nth search key. After comparison, Match Line Pre-charging Bar (MLPB) signals are generated based on the result of the comparison. Subsequently, SKC stores the received search key from external sources and transmits it to the search line driver (SLD) to proceed with the search.
The reason SKC receives the position of the X cell from the FXM is to ensure that only the column corresponding to the CAM entry without the X cell is compared. This comparison helps determine whether the successive search key matches or differs.
When MLPBs are generated by SKC and pre-charging is completed only for the MLs which need to be compared, SLD drives the search key and the search proceeds. The result of the search is shown at the output of the SA.
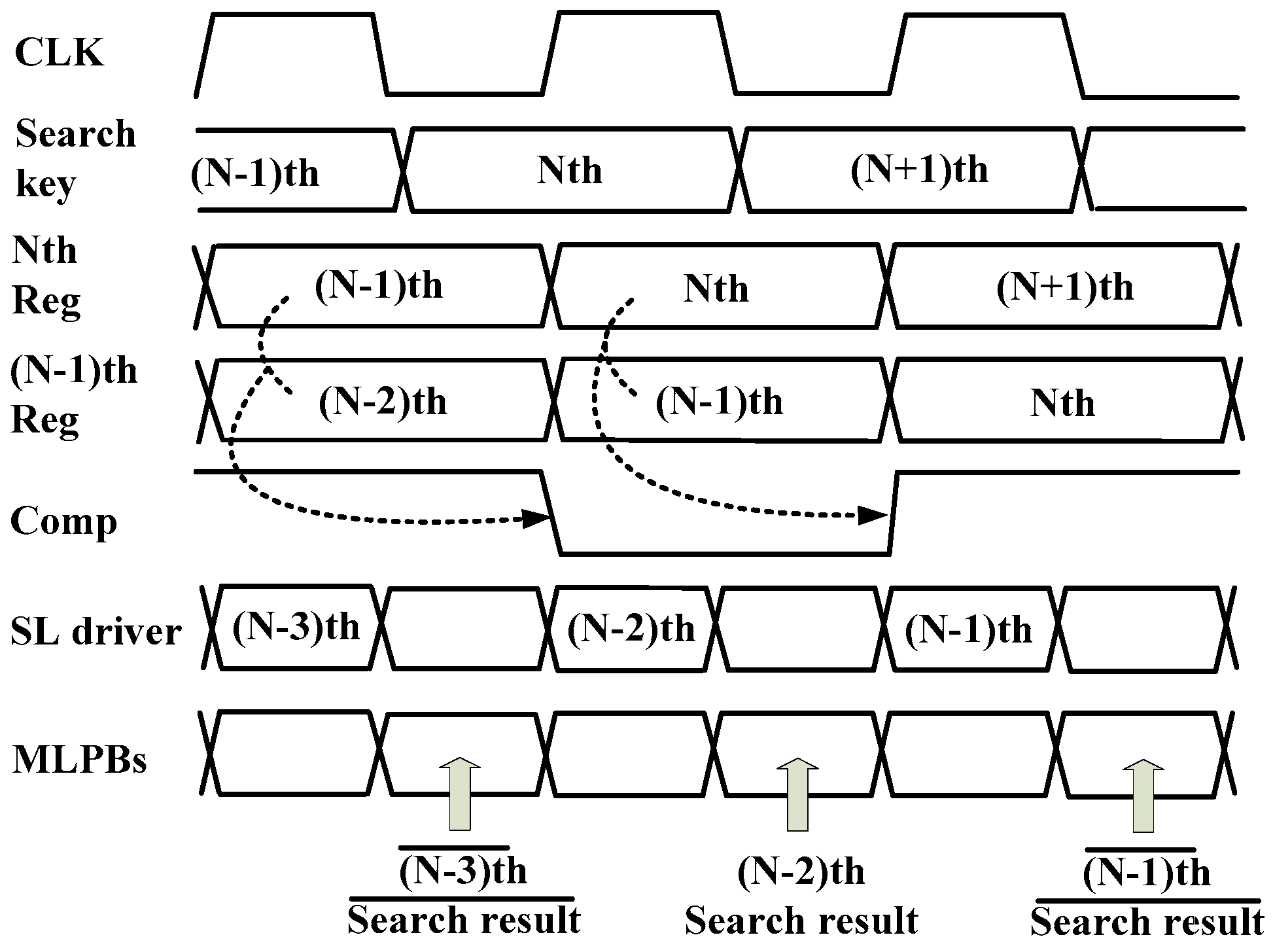
Figure 7 shows the timing diagram of SML. The high section of CLK represents the evaluation phase and the low section represents the pre-charging phase. When an external search key enters the SKC, it is stored in the Nth reg. In the next CLK, the value of the Nth reg is transferred to the (N-1)th reg.
SKC compares the values of two registers and generates a signal named Comp. If the Comp is high, it means that two consecutive search keys are the same, and only MLs matched in the previous search are pre-charged. Conversely, if the Comp is low, it means that two consecutive search keys are different and only the mismatch ML in the previous search is pre-charged.
There is a time interval of 1.5~2 clk between the search key forced from the outside and the search key driving from the search line driver. However, in the search line drive, one cycle search operation is maintained because the continuous search proceeds in burst mode.
4.1.2. Details of Circuits
In an SRAM-based TCAM, two SRAM cells are employed to store a single bit. The data storage of two adjacent SRAM cells as ‘11’ represents the X state. When complementary bits are stored in adjacent SRAM cells, they indicate ‘0’ or ‘1’. In the case of an X cell, the AND result of the adjacent two-bit lines (BLs) is only ‘1’, enabling the identification of the X cell’s position through these BLs.
Figure 8 shows a block diagram of a circuit for the FXM. SML uses the update time of the TCAM entry to find the X cell. The X cell can be found using BLs connected to each cell. When writing a row of the TCAM by selecting a specific row, the output of the AND gate connected to each BL indicates the position of the X cell, and this output is stored in the X cell reg. To explain this in detail using a 4-bit data example, it performs an AND operation between two SRAM cells and subsequently outputs the resulting value. Following that, it proceeds to sequentially execute another AND operation on the Word Line (WL) to determine the precise location of cell X.
Before writing the next row, the value of the Nth X cell reg is replaced with the (N-1)th X cell reg. When the next row is written, the result of the AND gates is stored in the Nth X cell reg.
The Nth X cell reg and the (N-1)th X cell reg indicate the positions of X cells in two consecutive rows of the TCAM. And the result of the OR operation of the two registers indicates a column in which there is at least one X cell in two adjacent rows.
To find the X cell position of the entire CAM entry, the above operation should be repeated, and the value of the MR must be fed back into the input of the OR operation. After the update of the TCAM entry is complete, the value of the MR will indicate the position of the column in which the X cell is located.
Figure 9 shows the circuit of SKC. SKC consists of compare logic, search key regs, and the Mux stage. Search key regs store a series of two search keys’ values. The values are masked by the MR’s value and directed to the input of the comparison logic.
In the compare logic, it is judged whether the masked value is the same, and this passes to the input of the selection part of the Mux.
The output of the Mux is connected to MLPBs.
4.1.3. Power Saving of SML
For verifying the effect of SML, a 12 × 64 CAM entry was constructed, and the lower 61 bits maintained the matching state and controlled the upper 3 bits to examine the effect of SML.
Figure 10 shows the difference in discharge between conventional TCAM and TCAM with SML. As the search proceeds, it is shown that the minimum value of the discharging current of TCAM with SML is small or equal.
Figure 11 shows the effect of TCAM with SML when performing successive searches. The first search has the same value, and the subsequent searches have been randomly searched.
The first search shows the same amount of discharge because SML is not applied. However, as the subsequent search proceeds, the TCAM with SML has a smaller or equal amount of discharging, and the cumulative amount of discharge gradually makes a difference in power saving. If Comp stays high continuously, the power saving will be maximized, but otherwise it will be affected by how the composition of the CAM entry and the series of searches was performed.
Figure 11c shows the amount of discharge when the Comp value remains high.
Figure 12 shows the change in cumulative discharging while increasing the number of searches. As the number of searches increases, the saving of the discharge increases. The cumulative amount gradually converges to a specific value as the number of searches increases, demonstrating a saving effect of approximately 58% based on a hundred random searches. The power saving effect could be different depending on the CAM entry configuration and search sequence.
4.2. Proposed ADVANCED SML
SML has some limitations when constructing TCAM entries. If all the other columns have the same value and only one column is different, X and values other than X cannot coexist in that column. In fact, since X can replace ‘0’ and ‘1’, it is difficult for the above case to exist. However, if this is necessary, advanced SML (ASML) can be used to remove restrictions on TCAM entry configuration.
4.2.1. Architecture
ASML performs searches by separating the primary search and post search at time intervals. The columns corresponding to the columns of the TCAM entry with no X precede the primary search, and the remaining columns precede the post search. To perform this operation, the ASML internally requires a delayed clock, and some structural change in the architecture, and SLD for a search with a time difference is required.
Figure 13 shows the timing diagram of ASML. As the edge of CLK rises, the primary search takes place, and following the worst evaluation time, CLK_dly is utilized to store the primary search outcome. Once the primary search result is stored, a post-search operation follows. The primary search result dictates the pre-charging of the subsequent search, and the post-search process is executed to acquire the search result.
4.2.2. Details of Circuits
The SLD of ASML refers to the value of the MR of the FXM. The SLD has a Mux that can determine the primary search and the post search by referring to the MR’s value. One of the two inputs of the Mux is a non-delayed search key for performing a primary search, and the other is for performing a post search. When a search is determined through the Mux, the output of the Mux is transferred to the TCAM cell array through the inverter chain. See
Figure 14 for an illustration of the SLD of ASML.
Since the post search should be performed following the worst evaluation time after the primary search is performed, the delayed input should save this time. The worst evaluation time is a 1-bit mismatch case, which is about 4 ns in a 12 × 64 TCAM.
The two inputs of the Mux have a discharging circuit that takes the value of inversion of CLK as input, which prevents SLs from driving in the pre-charging phase.
4.2.3. Comparison of Conventional TCAM and ASML
On average, ASML’s power-saving effect is comparable to that of SML’s. There is a difference in the part where the discharge progresses according to the time difference. Consequently, there exists a benefit of reducing temporary power consumption, as it involves the distribution of discharging over a time differential.
ASML has the advantage of addressing the entry configuration limitation of TCAM when compared to SML. However, it also has the drawback of prolonging search times due to its execution of both primary and post searches.
If the operational frequency period is shorter than this threshold, a single-cycle search is feasible. Nevertheless, exceeding this operational frequency period might impose restrictions on the operation.
Table 1 presents a comparison between conventional TCAM and ASML. Specifically, TCAM with ASML demonstrates a 58% reduction in power consumption compared to conventional TCAM, while simultaneously increasing the size of the 1 K array by 3% over conventional TCAM.
5. Conclusions
The paper proposed a dynamic power-efficient algorithm named SML and implemented the corresponding circuits and structures. Additionally, the power savings achieved on MLs through the utilization of SML have been verified.
SML denotes an algorithm that selectively pre-charges only those MLs necessitated for searching, determined through the comparison of the preceding search key with the current one. This comparison process, based on the TCAM entry, offered the advantage of optimized power conservation.
While SML demonstrated effectiveness, it exhibited certain limitations during TCAM entry construction. The extent of power reduction achievable with SML depended on the configuration of TCAM entries, the sequence of search keys, and the outcomes of search key comparisons. To address this, an algorithm termed ASML was introduced. ASML had to be limited in its maximum speed because it conducted two searches per cycle, but a single-cycle search was possible if the operating frequency period was shorter than this threshold.
Despite the mentioned drawbacks, ASML boasted a significant advantage in dynamic power savings. The efficacy of ASML was manifested in the reduction in pre-charged MLs, consequently diminishing the count of mismatched MLs.
On average, the simulation results showcased a remarkable 58% decrease in power consumption, while simultaneously increasing the size of the 1 K array by 3% compared to conventional TCAM.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}