
Robust Visual Recognition in Poor Visibility Conditions: A Prior Knowledge-Guided Adversarial Learning Approach

Abstract
:1. Introduction
- We propose a novel deep learning-based approach, PKAL, to enhance the model robustness for visual recognition under various poor visibility conditions.
- The proposed feature matching module, FPMM, transfers typical prior knowledge widely used in low-level tasks to high-level ones.
- We design an adversarial min–max optimization strategy to enhance robust task-specific representations and to refine decision boundaries simultaneously.
- We evaluate our proposed approach on a diversity of poor visibility scenarios, including visual blur, fog, rain, snow, and low illuminance. The experiments demonstrate the efficacy and adaptability of our approach.
2. Related Work
2.1. Image Restoration for Poor Visibility Conditions
2.2. Data Augmentation for Poor Visibility Conditions
2.3. Unsupervised Domain Adaptation
3. Preliminaries
3.1. Setup
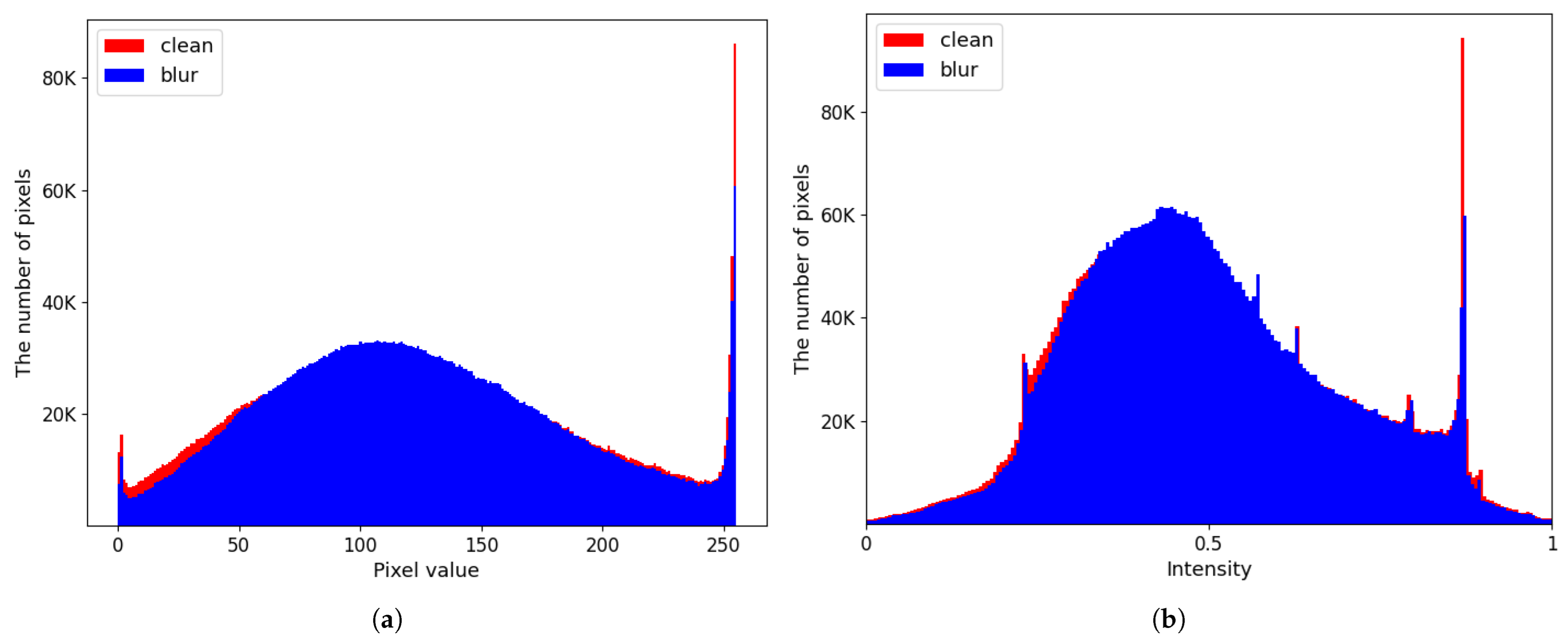
3.2. Dark and Bright Channel Priors
3.3. The Estimation of Mutual Information
4. Prior Knowledge-Guided Adversarial Learning
4.1. Feature Priors Matching Module
4.2. Mutual Information-Based Robust Training
| Algorithm 1: Prior Knowledge-guided Adversarial Learning |
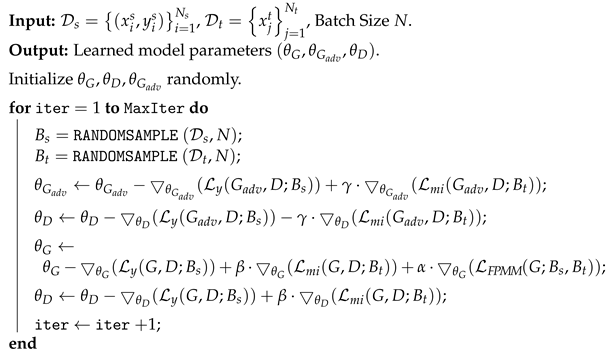 |
5. Experiments
5.1. Experiment Settings
5.1.1. Training Strategies
5.1.2. Comparison Methods
5.1.3. Visual Blur
5.1.4. Fog
5.1.5. Rain
5.1.6. Snow
5.1.7. Low Illuminance
5.2. Experiment Results
5.2.1. Evaluation on Visual Blur
5.2.2. Evaluation on Fog
5.2.3. Evaluation on Snow
5.2.4. Evaluation on Low Illuminance
5.2.5. Evaluation on Rain
6. Discussion
6.1. The Benefit of PKAL
6.2. The Effect of FPMM
6.3. The Effect of MIRT
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Pei, Y.; Huang, Y.; Zou, Q.; Lu, Y.; Wang, S. Does haze removal help cnn-based image classification? In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 682–697. [Google Scholar]
- VidalMata, R.G.; Banerjee, S.; RichardWebster, B.; Albright, M.; Davalos, P.; McCloskey, S.; Miller, B.; Tambo, A.; Ghosh, S.; Nagesh, S.; et al. Bridging the gap between computational photography and visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4272–4290. [Google Scholar] [CrossRef]
- Cai, J.; Zuo, W.; Zhang, L. Dark and bright channel prior embedded network for dynamic scene deblurring. IEEE Trans. Image Process. 2020, 29, 6885–6897. [Google Scholar] [CrossRef]
- Li, S.; Araujo, I.B.; Ren, W.; Wang, Z.; Tokuda, E.K.; Junior, R.H.; Cesar, R.; Zhang, J.; Guo, X.; Cao, X. Single image deraining: A comprehensive benchmark analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3838–3847. [Google Scholar]
- Zhu, H.; Peng, X.; Chandrasekhar, V.; Li, L.; Lim, J.H. Dehazegan: When image dehazing meets differential programming. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2019; pp. 1234–1240. [Google Scholar]
- Chen, W.T.; Fang, H.Y.; Hsieh, C.L.; Tsai, C.C.; Chen, I.; Ding, J.J.; Kuo, S.Y. All snow removed: Single image desnowing algorithm using hierarchical dual-tree complex wavelet representation and contradict channel loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4196–4205. [Google Scholar]
- Arruda, V.F.; Paixao, T.M.; Berriel, R.F.; De Souza, A.F.; Badue, C.; Sebe, N.; Oliveira-Santos, T. Cross-domain car detection using unsupervised image-to-image translation: From day to night. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Hendrycks, D.; Dietterich, T. Benchmarking neural network robustness to common corruptions and perturbations. arXiv 2019, arXiv:1903.12261. [Google Scholar]
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8340–8349. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Zhang, S.; Zhen, A.; Stevenson, R.L. GAN based image deblurring using dark channel prior. arXiv 2019, arXiv:1903.00107. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Flores, M.; Valiente, D.; Gil, A.; Reinoso, O.; Paya, L. Efficient probability-oriented feature matching using wide field-of-view imaging. Eng. Appl. Artif. Intell. 2022, 107, 104539. [Google Scholar] [CrossRef]
- Bei, W.; Fan, X.; Jian, H.; Du, X.; Yan, D. GeoGlue: Feature matching with self-supervised geometric priors for high-resolution UAV images. Int. J. Digit. Earth 2023, 16, 1246–1275. [Google Scholar] [CrossRef]
- Son, C.H.; Ye, P.H. New Encoder Learning for Captioning Heavy Rain Images via Semantic Visual Feature Matching. arXiv 2021, arXiv:2105.13753. [Google Scholar] [CrossRef]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Guo, Q.; Sun, J.; Juefei-Xu, F.; Ma, L.; Xie, X.; Feng, W.; Liu, Y.; Zhao, J. Efficientderain: Learning pixel-wise dilation filtering for high-efficiency single-image deraining. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1487–1495. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3937–3946. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Chen, L.; Fang, F.; Wang, T.; Zhang, G. Blind image deblurring with local maximum gradient prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1742–1750. [Google Scholar]
- Yan, Y.; Ren, W.; Guo, Y.; Wang, R.; Cao, X. Image deblurring via extreme channels prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4003–4011. [Google Scholar]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Bao, L.; Lau, R.W.; Yang, M.H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2521–2529. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1222–1230. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2019; pp. 702–703. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. Augmix: A simple data processing method to improve robustness and uncertainty. arXiv 2019, arXiv:1912.02781. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; pp. 443–450. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3723–3732. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. In Proceedings of the Advances in Neural Information Processing Systems 31, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Shu, R.; Bui, H.H.; Narui, H.; Ermon, S. A dirt-t approach to unsupervised domain adaptation. arXiv 2018, arXiv:1802.08735. [Google Scholar]
- Krause, A.; Perona, P.; Gomes, R. Discriminative clustering by regularized information maximization. In Proceedings of the Advances in Neural Information Processing Systems 23, Vancouver, BC, Canada, 6–9 December 2010. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Springenberg, J.T. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv 2015, arXiv:1511.06390. [Google Scholar]
- Poole, B.; Ozair, S.; Van Den Oord, A.; Alemi, A.; Tucker, G. On variational bounds of mutual information. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 5171–5180. [Google Scholar]
- Cheng, P.; Hao, W.; Dai, S.; Liu, J.; Gan, Z.; Carin, L. Club: A contrastive log-ratio upper bound of mutual information. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 13–18 July 2020; pp. 1779–1788. [Google Scholar]
- Wang, F.; Kong, T.; Zhang, R.; Liu, H.; Li, H. Self-Supervised Learning by Estimating Twin Class Distribution. IEEE Trans. Image Process. 2023, 32, 2228–2236. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 17–30 June 2016; pp. 770–778. [Google Scholar]
- Richardson, W.H. Bayesian-based iterative method of image restoration. JoSA 1972, 62, 55–59. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Liu, Y.; Jaw, D.W.; Huang, S.C.; Hwang, J.N. DesnowNet: Context-aware deep network for snow removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef] [PubMed]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning (PMLR), Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Nah, S.; Baik, S.; Hong, S.; Moon, G.; Son, S.; Timofte, R.; Mu Lee, K. Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Garg, K.; Nayar, S.K. Photorealistic rendering of rain streaks. ACM Trans. Graph. (TOG) 2006, 25, 996–1002. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Chen, X.; Wang, S.; Long, M.; Wang, J. Transferability vs. discriminability: Batch spectral penalization for adversarial domain adaptation. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 1081–1090. [Google Scholar]
- Cui, S.; Wang, S.; Zhuo, J.; Li, L.; Huang, Q.; Tian, Q. Towards discriminability and diversity: Batch nuclear-norm maximization under label insufficient situations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3941–3950. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | AlexNet | ResNet-18 | VGG19 | Avg. | |
|---|---|---|---|---|---|
| – | Baseline | 61.9 | 67.7 | 72.0 | 67.2 |
| Image Restoration | RL [54] | 53.9 | 54.8 | 48.5 | 52.4 |
| ECP [28] | 64.4 | 69.3 | 65.1 | 66.3 | |
| SRN [20] | 73.1 | 82.4 | 81.3 | 78.9 | |
| DeblurGAN [21] | 66.1 | 72.2 | 70.4 | 69.6 | |
| DeblurGANv2 [22] | 67.2 | 77.3 | 74.0 | 72.8 | |
| Statistical Features Alignment | DAN [39] | 65.9 | 68.4 | 68.4 | 67.6 |
| Deep CORAL [40] | 59.6 | 66.5 | 63.3 | 63.1 | |
| Adversarial Domain Adaptation | DANN [41] | 61.5 | 62.5 | 64.4 | 62.8 |
| CDAN [43] | 69.0 | 68.3 | 65.5 | 67.6 | |
| MCD [42] | 45.3 | 69.5 | 65.0 | 59.9 | |
| VADA [44] | 61.4 | 66.6 | 73.1 | 67.0 | |
| DIRT-T [44] | 65.7 | 67.7 | 76.9 | 70.1 | |
| W-DANN [58] | 64.0 | 73.0 | 78.3 | 71.8 | |
| Proposed method | FPMM | 64.7 | 69.3 | 70.8 | 68.3 |
| PKAL (FPMM+MIRT) | 75.8 | 79.1 | 84.6 | 79.8 |
| Methods | Clean | Motion Blur | Other Kinds of Blur | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | Defocus Blur | Zoom Blur | Glass Blur | |||
| Baseline | 74.1 | 63.3 | 52.8 | 36.3 | 21.7 | 15.3 | 26.7 | 31.0 | 29.0 | 38.9 |
| DAN [39] | 70.7 | 68.6 | 61.4 | 49.0 | 32.9 | 24.7 | 33.3 | 44.9 | 31.9 | 46.4 |
| Deep CORAL [40] | 71.6 | 66.7 | 59.0 | 45.9 | 30.9 | 22.4 | 32.8 | 43.1 | 29.6 | 44.7 |
| DANN [41] | 73.7 | 72.3 | 67.2 | 55.6 | 39.0 | 29.3 | 38.5 | 47.3 | 38.0 | 51.2 |
| W-DANN [58] | 74.2 | 72.8 | 68.1 | 56.5 | 39.3 | 28.6 | 37.6 | 48.5 | 36.0 | 51.3 |
| CDAN [43] | 71.6 | 73.7 | 67.7 | 61.2 | 45.6 | 34.3 | 37.6 | 47.6 | 38.9 | 53.1 |
| VADA [44] | 70.0 | 71.1 | 67.1 | 56.2 | 38.7 | 29.1 | 41.0 | 48.4 | 45.4 | 51.9 |
| RandAug [36] | 71.8 | 64.9 | 55.0 | 40.7 | 25.7 | 18.1 | 28.7 | 39.1 | 30.9 | 41.7 |
| AugMix [37] | 71.4 | 67.2 | 62.8 | 53.4 | 39.5 | 30.2 | 35.9 | 45.6 | 35.9 | 49.1 |
| FPMM | 74.9 | 72.2 | 66.1 | 54.7 | 37.7 | 27.6 | 38.9 | 43.3 | 31.8 | 49.7 |
| PKAL (FPMM+MIRT) | 73.4 | 72.9 | 69.7 | 61.9 | 48.1 | 37.9 | 42.4 | 49.0 | 38.8 | 54.9 |
| Methods | Avg. Clean | Web-FOG | ImageNet-RAIN | ImageNet-SNOW | ImageNet-DARK |
|---|---|---|---|---|---|
| Baseline | 79.3 | 57.4 | 34.9 | 32.8 | 25.5 |
| Image Restoration Module * | 79.3 | 59.7 | 64.4 | 44.5 | 40.8 |
| DAN [39] | 79.3 | 77.1 | 60.7 | 57.5 | 55.3 |
| Deep CORAL [40] | 79.6 | 75.7 | 59.4 | 54.5 | 54.0 |
| DANN [41] | 79.3 | 81.8 | 65.8 | 63.0 | 53.3 |
| W-DANN [58] | 79.4 | 81.0 | 62.5 | 60.6 | 55.1 |
| CDAN [43] | 80.0 | 81.7 | 65.6 | 63.2 | 55.9 |
| VADA [44] | 80.5 | 77.6 | 62.8 | 60.7 | 47.8 |
| DIRT-T [44] | 81.2 | 83.4 | 67.6 | 65.2 | 58.6 |
| RandAug [36] | 78.0 | 73.4 | 39.4 | 36.8 | 29.5 |
| AugMix [37] | 77.5 | 76.8 | 43.3 | 41.1 | 32.0 |
| FPMM | 80.3 | 76.5 | 54.3 | 49.1 | 49.0 |
| PKAL (FPMM+MIRT) | 80.7 | 88.7 | 68.3 | 67.3 | 58.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Yang, J.; Luo, L.; Wang, Y.; Wang, S.; Liu, J. Robust Visual Recognition in Poor Visibility Conditions: A Prior Knowledge-Guided Adversarial Learning Approach. Electronics 2023, 12, 3711. https://doi.org/10.3390/electronics12173711
Yang J, Yang J, Luo L, Wang Y, Wang S, Liu J. Robust Visual Recognition in Poor Visibility Conditions: A Prior Knowledge-Guided Adversarial Learning Approach. Electronics. 2023; 12(17):3711. https://doi.org/10.3390/electronics12173711
Chicago/Turabian StyleYang, Jiangang, Jianfei Yang, Luqing Luo, Yun Wang, Shizheng Wang, and Jian Liu. 2023. "Robust Visual Recognition in Poor Visibility Conditions: A Prior Knowledge-Guided Adversarial Learning Approach" Electronics 12, no. 17: 3711. https://doi.org/10.3390/electronics12173711
APA StyleYang, J., Yang, J., Luo, L., Wang, Y., Wang, S., & Liu, J. (2023). Robust Visual Recognition in Poor Visibility Conditions: A Prior Knowledge-Guided Adversarial Learning Approach. Electronics, 12(17), 3711. https://doi.org/10.3390/electronics12173711