1. Introduction
Steganography is a vital technology employed for covert communication by concealing secret information within cover data. It plays a crucial role in various domains such as information security and data communication, and its significance lies in ensuring data confidentiality and upholding social stability. Different types of data, including text, images, audio, and video, can be used as hidden covers. Among these, image-based steganography is the most widely utilized. In this method, the original image used for embedding secret information is referred to as the cover image, while the image after embedding the secret information is called the stego image [
1].
Image steganography is an efficient method for private communication that embeds secret information into a cover image while making minimal modifications to the image itself [
2]. By leveraging the high redundancy present in images, the secret information remains difficult to detect after embedding. Embedding secret messages into a cover image involves modifying certain pixel values, resulting in a difference between the modified and original images, known as distortion. Traditional content-adaptive steganographic schemes have been developed in the field of steganography, where each pixel is assigned a cost to quantify the modification impact, and the total distortion is evaluated by summing up these costs [
3]. As a general rule, embedding secret information in complex texture regions results in lower distortion compared to smooth regions. Therefore, smooth regions are typically avoided for embedding data, while complex regions and edges are preferred. Traditional content-adaptive steganography schemes, such as HUGO [
4], WOW [
5] and S-UNIWARD [
6], employ heuristic approaches to design distortion functions.
Steganalysis, on the other hand, refers to the process of detecting steganography. In the case of image steganography, steganalysis involves analyzing the statistical characteristics of a cover image to determine if it contains hidden information, estimating the amount of embedded data, and predicting the locations of data embedding [
7]. Steganalysis serves as an important tool for evaluating steganography algorithms. When the same secret information is embedded, the more robust a steganography algorithm’s data-hiding capability, the more effectively it can evade steganalysis detection. Traditional steganalysis methods require prior knowledge and involve applying filters to process images, such as the Spatial Rich Model (SRM) [
8] and its variant version maxSRMd2 [
9], which have proven to effectively detect image embedding modifications. StegExpose [
10] is a practical solution that utilizes steganalysis tools to efficiently analyze images for LSB steganography in bulk. Daniel et al. [
11] introduces an unsupervised steganalysis method that combines artificial training sets and supervised classification, presenting a formal framework for targeted steganalysis. Boroumand et al. [
12] presents a deep residual architecture for steganography detection that minimizes the use of heuristics and externally enforced elements.
With the advancements in deep learning, Convolution Neural Networks (CNNs) have demonstrated superior performance in image processing across various fields. Researchers have begun exploring the application of deep learning frameworks to image steganography. Unlike traditional steganography that relies on hand-designed high-pass filters for feature extraction, deep learning enables the construction of a learnable model consisting of multiple layers of linear network and nonlinear activation units. Building upon the combination of steganalysis and CNN, Xu et al. proposed Xu-Net [
13], which incorporates a batch normalization layer and a 1 × 1 convolutional layer. This model achieves a similar detection performance to the SRM scheme. Zhu et al. introduced Zhu-Net [
14], which utilizes two separable convolution blocks to replace the traditional convolution layer, and incorporates the spatial pyramid pool [
15] to compress feature mappings. This model demonstrates excellent detection accuracy compared to the SRM.
In addition to applying deep learning to steganalysis, research on integrating steganography with deep learning is also gaining traction. Atique et al. [
16] introduces a novel CNN-based encoder–decoder architecture for image steganography, standing out from previous methods by directly using images as payloads and employing encoder–decoder networks for embedding and recovery. Lu et al. [
17] introduces a large-capacity Invertible Steganography Network (ISN) that effectively increases payload capacity. Zhang et al. [
18] presents a novel technique utilizing generative adversarial networks for image steganography, achieving state-of-the-art payloads (4.4 bits per pixel). Tang et al. proposed ASDL-GAN [
19], a spatial grayscale image steganography distortion framework based on generative adversarial networks (GANs). In this framework, a steganography generator generates a stego image based on a learned distortion function, while a steganalysis discriminator distinguishes between cover images and generated stego images. To overcome the gradient disappearance problem during the backpropagation process, a dedicated Ternary Embedding Simulator (TES) subnetwork is proposed to replace the step function. However, this subnetwork requires pre-training, resulting in considerable time consumption. Yang et al. presented UT-GAN [
20], which replaces TES with a double Tanh simulator function, eliminating the need for pre-training. Moreover, a U-NET model is employed in the generator to expedite the convergence speed of this approach. Li et al. further introduced a cross-feedback mechanism in the generator [
21], which allows downsampling information to be directly transmitted to the extension layer through a feedback channel, generating a more intricate probability map that guides undetectable steganography. Experimental results demonstrate that this method significantly enhances the effectiveness and accuracy of loss learning while surpassing existing steganalysis methods in terms of anti-steganalysis capabilities.
Building upon the existing literature in the field of image steganography, our study aims to introduce innovative enhancements to the current approaches. This paper presents the following novel contributions.
Our steganographic network consists of a hidden network, an extraction network, and a steganalysis network. Specifically, we utilize a dual U-Net generative adversarial network (GAN) network, wherein both the hidden and extraction networks are constructed using the U-Net framework. Building upon the foundation of traditional dual convolutions, we expand the network width while employing 1 × 1 convolution kernels and dual 3 × 3 convolution kernels for convolution operations.
We introduce the Perceptual Path Length (PPL) into the loss function. PPL is used to evaluate the discrepancy between the distribution of generated images in the perceptual space and the distribution of real images, thereby assessing the level of difference between the generated images produced by the generator network and the real images.
In the field of hiding images within images, there is no consensus among previous studies regarding the evaluation metrics for networks. In this paper, we propose a comprehensive evaluation metric, namely the Modified Multi-Image Similarity Metric (MMISM), which takes into account the cover image, the stego image, the original secret image, and the extracted secret image, considering their Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Metric (SSIM) values.
The structure of this paper consists of five main sections.
Section 2 provides an overview of the current state-of-the-art steganography techniques based on Generative Adversarial Networks (GANs). In
Section 3, a thorough examination of the proposed model is presented, highlighting its key components and functionality.
Section 4 analyzes the experimental results obtained from the conducted evaluations. Finally, in
Section 5, we present our conclusions and discuss potential future directions for further research.
3. Methods
3.1. Network Architecture
The architecture of our model is illustrated in
Figure 1, wherein the steganography inherits the Y-channel steganographic process proposed by Zhang et al. [
23]. Building upon this foundation, and leveraging the edge prediction capability of U-Net [
28], we enhanced the network structures of both the hidden and extracted components.
This comprehensive framework encompassing steganography and steganalysis consists of three parts: sender, receiver and attacker. The attacker encompasses a steganalysis network designed to simulate potential attacks that a network might encounter in real-world scenarios, aiming to enhance the concealment capabilities of the model. The steganalysis network is tasked with discerning whether the transmitted image is a stego image containing concealed information or an unaltered cover image. The sender is comprised of a hidden network. Upon successful training of the model, the sender conceals the grayscale secret image (secret_Y image) within the Y channel of the cover image (cover_Y image), generating a grayscale stego image. To reintroduce color information, the grayscale stego image is combined with the U and V channels of the original cover image (cover_RGB image), resulting in a color stego image (stego_RGB image). The stego_RGB images are then transmitted through a public lossless channel to the receiver’s end. The receiver consists of the extracted network, which retrieves the grayscale secret image (secret2 image) from the stego_RGB image.
The key components of our network model consist of a hidden network, an extracted network, and a steganalysis network. Both the hidden network and extracted network are based on the U-Net architecture. The hidden network takes cover_Y image and secret_Y image as input, forming a two-channel tensor. On the other hand, the extracted network takes the stego_RGB image generated by the hidden network as input and produces the extracted secret information. For the steganalysis network, we employ Zhu-Net [
14] as our chosen architecture. It takes the concatenation of the single-channel stego image and the U/V channels of the original cover image as input. Through the utilization of this refined network, our model enhances the capabilities for concealing and extracting information.
3.1.1. Hidden Network and Extracted Network
In our hidden and extracted network, depicted in
Figure 2, we employ this architecture as the foundational structure for both the hidden network and the extracted network, serving the purpose of hiding and extracting steganographic images.
The U-Net architecture [
29] relies on downsampling and upsampling as its major components. The downsampling progressively reduces the input image into more abstract representations, while the upsampling gradually restores these representations to an output of the same size as the input image. U-Net has gained recognition for its exceptional performance in image segmentation tasks, as its network structure can effectively extract high-frequency region features, which aligns well with the nature of image steganography where significant frequency changes occur. Our network structure is an improvement based on the U-Net framework.
In our design, we incorporate eight ExtractionBlock modules during the upsampling and downsampling processes. This modification significantly reduces the number of parameters compared to the traditional U-Net architecture while maintaining the same level of feature extraction capability. Distinct from the conventional approach of using double convolutions for sampling, ExtractionBlock simultaneously applies double convolutions of size 3 × 3 and a 1 × 1 convolution to the input C × H × W image, resulting in higher-resolution feature maps. The ExtractionBlock enhances both the network’s width and its adaptability to different scales, thereby improving the effectiveness of image hiding and extraction. Besides, we utilize LeakyReLU as the activation function and apply batch normalization to address training biases.
The downsampling part consists of the ExtractionBlock modules and pooling layers, aiming to gradually decrease the spatial dimensions of the feature maps. This aids the network in learning more global and abstract features. Max pooling layers are utilized to perform downsampling. Employing 2 × 2 kernel size and a stride of 2 during pooling facilitates a progressive reduction in feature dimensions, aimed at retaining crucial information while reducing the image scale.
The upsampling part comprises a series of transpose convolutions and skip connections, connecting the corresponding layers of upsampling and downsampling. This architectural approach enables the upsampling component to effectively harness both low-level and high-level features, facilitating the recovery of intricate image details. Similar to the downsampling process, the upsampling process also utilizes our designed ExtractionBlock for feature extraction and restoration of the image. Employing transpose convolutions with a 2 × 2 kernel size, the upsampling process diligently restores the image features, refining them to dimensions of 256 × 256. Finally, the Tanh function is applied to activate the final output. The detailed structure of the network is shown in
Table 1.
3.1.2. Steganalysis
The security of image steganography is of paramount importance, where neural network steganalysis models are employed to discern hidden information that may evade detection by traditional steganalysis methods. In our framework, steganalysis assumes the role of an attacker entity, simulating potential eavesdropping during data transmission. Zhu-Net [
14], introduced in 2019, represents a more advanced approach for deep-learning-based steganalysis, offering enhanced monitoring capabilities. Zhu-Net applies separable convolutions to compress image content, thereby improving the signal-to-noise ratio of stego images. In comparison with other steganalysis networks such as Xu-Net [
13], SRM [
8], and SRNET [
9], Zhu-Net demonstrates exceptional performance in detecting general spatial domain steganography methods.
3.2. Training Strategy
In order to effectively train our proposed network, we employed a series of training techniques. Firstly, we implemented learning rate decay, which aids in optimizing the convergence and stability of the network. By gradually decreasing the learning rate, we were able to explore the space of the loss function more rapidly in the early stages of training, and then fine-tune the parameters more precisely in the later stages.
Additionally, we utilized Xavier weight initialization technique [
30]. The Xavier initialization method automatically sets appropriate initial weights based on the dimensions of the network’s inputs and outputs. This helps to mitigate issues such as vanishing or exploding gradients, making the network more prone to converging to a better local optimum.
During the optimization process, we followed the sequence outlined in Algorithm 1 to optimize the sub-networks. The gradients of the various parameters in the network were automatically computed through backpropagation using the total loss
, as represented by Equation (
3).
is computed as a weighted sum of the losses from the hiding network, extracted network, and steganalysis network. The gradient information of the loss function with respect to the parameters was propagated from the output layer to the input layer, determining the contribution of each parameter to the loss function.
| Algorithm 1: Training process |
| Input: A batch of secret images and cover images |
| Output: Our model after training |
| 1. for each batch do |
| 2. Generating n pairs of stego images and cover images using hidden network |
| 3. Optimizing the hidden network minimizes |
| 4. Optimizing the extracted network minimizes |
| 5. if batch % 5 0 |
| 6. Optimizing the Steganalysis minimizes |
Simultaneously, we employ optimizers within neural networks to calculate gradients of the loss with respect to these parameters and iteratively adjust the weights and biases. We aim to minimize the loss function and thereby enhance the model’s accuracy. One of the most widely used first-order optimization algorithms is gradient descent. In addition to the foundational gradient descent, numerous derivatives have been developed [
31], such as Batch Gradient Descent, Stochastic Gradient Descent, and Mini-Batch Gradient Descent. Prominent optimization techniques include Momentum [
32], Nesterov Accelerated Gradient [
33], Adagrad [
34], and Adam [
35]. Subsequently, we apply optimization algorithms to fine-tune the parameters of the hiding network, followed by a similar optimization process for the extracted network. Furthermore, the steganalysis component undergoes optimization at intervals of every 5 batch sizes in each epoch.
By employing techniques such as learning rate decay, Xavier weight initialization, and hierarchical gradient decay, we were able to effectively train the network and improve the accuracy of secret extraction. The application of these techniques has endowed our proposed network with enhanced performance and robustness in the field of steganalysis.
3.3. Perceived Path Length
Perceptual Path Length (PPL) [
36] is a measure of the variation in generated images when interpolating in the latent space of a generative model. The latent space refers to the space of possible styles that can be used to generate images. Interpolating in the latent space involves smoothly transitioning from one style to another, and the PPL quantifies the degree of variation in the generated images during this interpolation. This measure can be used to evaluate the quality of generated images and helps to identify regions in the latent space where changes in style result in large or small variations in the generated images. PPL is a valuable tool for analyzing and improving the performance of style-based image generation models.
In this study, we compute the perceptual distance between two VGG16 embeddings using a perceptual-based pairwise image distance calculation, weighted by the differences between the embeddings. The weights are chosen to align the metric with human perception of similarity. By dividing the latent space interpolation path into linear segments, we define the total perceptual length of the segmented path as the sum of perceptual differences between each segment, determined by the image distance metric. In practice, we approximate the total perceptual length by averaging over all possible endpoints in the latent space, instead of considering the limit of this sum under infinite fine subdivisions. Furthermore, we employ an approximation method using a small step size or epsilon value to discretize the paths and estimate PPL. Specifically, in our approach, we use
as an approximation for infinite subdivisions. The total PPL is defined as the sum of perceptual differences for each small segment, as represented by the following Equation (
2):
where
t follows a uniform distribution in the range (0, 1),
represents the fine subdivision,
denotes linear interpolation, G represents the output features of the generator for linear interpolation between input images
and
, and d represents the calculation of perceptual distance. Specifically, this involves extracting embeddings of the generated images corresponding to different interpolated latent codes using a VGG16 network with appropriate weights, and the difference in embeddings represents the value of d.
Perceptual loss is primarily used to analyze the similarity of high-level features between images. In simple terms, it involves feeding two images of interest into a pre-trained model to obtain their respective high-level features, followed by calculating the loss between these features. Unlike MSE and PSNR, the perceptual path length focuses more on high-level features rather than differences in specific pixels.
3.4. Loss Function
In order to generate higher-quality stego images that are more imperceptible while extracting higher-resolution secret information, this study incorporates three main components in its loss function Equation (
3): the loss of the hidden network, the loss of the extracted network, and the loss of the steganalysis. The overall loss function is composed of the individual losses from each subnetwork.
In this formula, H and E are designed to minimize the total loss, while D aims to maximize it. The parameters and are hyperparameters used to balance the importance of stego image quality and secret image extraction. The parameter is a random number between 0.8 and 1.2. The variables and represent the cover image and the stego image, respectively, while and represent the original secret image and the extracted secret image, respectively.
The losses of the hidden network and the extracted network are primarily determined by the statistical differences in image pixel values and structures. The loss of the hidden network measures the discrepancy between
and
, while the loss of the extracted network quantifies the difference between
and
. The loss function incorporates three components: Structural Similarity Index Metric (SSIM), Multi-scale Structural Similarity Index Measure (MSSIM), and Perceptual Path Length (PPL). The metrics for the basic steganographic network are as Equations (
4) and (
5). Here,
and
are hyperparameters that control the influence of the three metrics. By combining SSIM and MSSIM in the loss function, we aim to leverage their complementary nature. SSIM focuses on local similarity and texture preservation, while MSSIM captures the perceptual differences at multiple scales, considering the global consistency of the hidden and extracted images. This combination helps achieve a well-balanced evaluation of image quality in terms of both local and global aspects.
In detail, SSIM, as proposed in [
24], gauges image similarity across luminance, contrast, and structure dimensions.
and
denote the average pixel values of images
x and
y, while
and
represent their respective pixel deviations. Additionally,
signifies the standard deviation shared between images
x and
y. The inclusion of constants
,
, and
serves to ensure stability in cases where the denominator approaches zero. Meanwhile, positive parameters
l,
m, and
n allow for adjustments to the relative significance of these three constituents. The SSIM index spans [0,1], with higher values indicating greater image similarity. This index can be mathematically expressed as follows:
MSSIM, introduced by [
25], involves the utilization of a reference image and a distorted image as inputs. The process encompasses iterative utilization of low-pass filtering and downsampling by a factor of 1/2. Assuming the original image is at Scale 1, the highest scale reaches Scale
M after
iterations. At the j-th scale, contrast
and structural similarity
are computed, while luminance similarity
is solely calculated at Scale
M. This approach amalgamates image details at various resolutions to evaluate image quality. The computation is detailed as follows in Equation (
10).
The loss of the steganalysis aims to determine whether the input image has undergone processing and potentially contains hidden information. This task is formulated as a binary classification problem, and we employ the Binary Cross-Entropy (BCE) loss function for the discriminator. The BCE loss is defined as Equation (
11):
where
n is the batch size,
x represents the discriminator’s target labels, and
y represents the predicted outputs. The overall loss function is formulated as Equation (
12):
where
is a random number between 0.8 and 1.2, and
and
represent the cover image and the covert image, respectively.
4. Experiments and Results
Our network was trained on the PyTorch 1.13.1 deep learning framework, using Python 3.9.13 and an NVIDIA 2080Ti GPU. The operating system used was Linux Mint 21, and the CUDA version for the graphics card driver was 12.0.
For the experiments, we utilized the PASCAL VOC2012 dataset [
37]. The dataset consists of a total of 11,540 images, with 5770 images used as secret images and the remaining 5770 images as cover images for training. We randomly selected 5000 images for validation. Additionally, we also conducted tests on the Labeled Faces in the Wild (LFW) dataset [
38]. The LFW dataset contains 13,233 face images, each associated with a corresponding person’s name. There are 5749 unique individuals in the dataset, with the majority having only one image. We used 13,232 images for training, with the first 6616 images used as secret images and the remaining 6616 images used as cover images. Similar to the PASCAL VOC2012 dataset, we randomly selected 5000 images for validation. All images were normalized to a size of 256 × 256 pixels.
We employed the Adam optimizer for both the hidden network and the extracted network, while the steganalysis was optimized using SGD. The hyperparameters used were set as follows:
= 0.3,
= 0.9,
= 0.5,
= 0.85. The batch size was set to 4, and the initial learning rate was set to
. The learning rate was decreased every 3 epochs after the 15th epoch. The model achieved convergence after 15 epochs of training and reached stability after 50 epochs. The variations of the total loss during the training process are shown in
Figure 3. The
x-axis represents the training epochs, and the
y-axis represents the loss values.
In contrast to DGANS, which deploy a dual setup of GANs for adversarial training, and ISGANs, which incorporate the inception network, our network, constructed upon the U-Net architecture, exhibits expedited convergence. Through comparative evaluations of distinct network architectures, we have discerned pronounced advantages associated with the U-Net framework throughout the training regimen. This architectural configuration showcases remarkable feature propagation capacities, thereby adeptly preserving intricate details and mitigating image deterioration. The epoch where different methods start to converge in loss is shown in
Table 2. As documented in the literature, DGANS necessitates approximately 80 epochs to initiate convergence, while ISGANs require about 20 epochs. In contrast, our model experiences loss reduction initiation around 15 epochs and subsequently achieves prompt stabilization. Evidently, this signifies that our network’s convergence is characterized by swifter onset, enhancing training efficiency and attaining commendable image generation outcomes within a notably condensed time frame.
4.1. Steganographic Capacity Analysis
In
Table 3, we present the steganographic capacities of different steganographic methods measured in bits per pixel (bpp). Each pixel used one byte (8 bits) for storage. With a secret image size of 256 × 256 and a cover image size also of 256 × 256, we determined the total number of hidden bits by multiplying the number of pixels in the secret image by the bits per pixel. Then, we divided this total number of hidden bits by the total number of pixels in the cover image to obtain the bits per pixel value. Our proposed method achieves a steganographic capacity of 8 bpp, which is the same as the capacities of ISGAN and DGANS methods. This means that on average, each pixel can conceal 8 bits of information.
Analyzing the steganographic capacities of these methods reveals variations in the amount of information that can be hidden per pixel. Methods such as HUGO [
4] and X. Duan et al.’s [
39] exhibit lower capacities, while Baluja’s method [
22] and the GSN model [
40] fall within the intermediate range. On the other hand, ISGAN, DGANS, and our proposed method demonstrate higher capacities, allowing for the concealment of more information per pixel. These findings aid in selecting a suitable steganographic method that strikes a balance between information hiding and image quality, depending on specific requirements.
4.2. Stealth Analysis
4.2.1. Qualitative Comparison
Below are the detailed experimental results of the two sets of images on the LFW and Pascal VOC12 datasets, each consisting of 256 × 256-pixel images. In
Figure 4 and
Figure 5, the images are presented from left to right as follows: the stego image, the cover image, the original secret image, and the extracted secret image. The histograms of the corresponding Y channel are shown below each image. The red frames demonstrate that the differences in pixel values between the stego image and the cover image, as well as between the original secret image and the extracted secret image, are minimal.
Regarding the LFW dataset, the experimental results demonstrate the effectiveness of our approach in concealing and extracting secret information. The stego images maintain a visually similar appearance to the cover images, indicating successful embedding. The extracted secret images exhibit a high level of fidelity to the original secret images, demonstrating accurate retrieval of the hidden information. The Y-channel histograms further support these observations, showing minimal discrepancies between the cover and stego images, as well as between the original and extracted secret images.
On the Pascal VOC12 dataset, similar findings are observed. The stego images preserve the visual quality of the cover images, demonstrating the successful hiding of secret information. The extracted secret images exhibit a remarkable resemblance to the original secret images, indicating the reliable extraction of the concealed data. Consistent with the LFW dataset, the Y-channel histograms illustrate the close resemblance between the cover and stego images, as well as between the original and extracted secret images.
These results confirm the effectiveness and robustness of our proposed method in achieving secure and accurate secret information embedding and extraction, as validated by the visual comparisons and histogram analysis.
Upon closer inspection, the histogram data in the red box show that the extracted secret images do not perfectly match the original secret images in both sets of experiments on the LFW and Pascal VOC12 datasets. This discrepancy can be attributed to the inherent limitations of the embedding and extraction process, as well as the presence of noise and distortions introduced during the hiding and retrieval stages.
The imperfections observed in the extracted secret images can be attributed to various factors. Firstly, the embedding process involves manipulating the cover images to hide the secret information, which inherently introduces some level of distortion. Additionally, the extraction process relies on statistical analysis and decoding techniques, which may result in minor errors or loss of information. Furthermore, the presence of noise, compression artifacts, and other image-specific characteristics can also contribute to the differences between the original and extracted secret images. These factors can affect the fidelity of the extracted data and introduce small variations in pixel values, leading to discrepancies at the pixel level.
Despite these discrepancies, it is important to note that the overall visual quality and resemblance between the original and extracted secret images are still remarkable, indicating the successful retrieval of the hidden information. The histograms of the Y channel also demonstrate a strong similarity between the original and extracted images, further supporting the effectiveness of our approach in preserving the essential characteristics of the secret information.
Although the extracted secret images may not be identical to the original images, our experimental results illustrate the robustness and reliability of our proposed method in accurately recovering the concealed information considering the inherent challenges and limitations associated with the embedding and extraction processes. These findings highlight the trade-off between achieving high-capacity hiding and maintaining perfect fidelity in the extracted secret images, emphasizing the need to strike a balance between data concealment and visual quality.
4.2.2. Quantitative Analysis
The concealment evaluation of steganographic models often relies on the assessment of differences between cover images and stego images, as well as between the original secret images and the extracted secret images, utilizing metrics such as PSNR and SSIM. In practical applications, it is desirable to enhance the accuracy of secret information extraction while maintaining satisfactory concealment performance. Therefore, we propose the utilization of a Multi-Image Similarity Metric (MISM) as a comprehensive evaluation measure to assess the combined ability of the model in both concealing information and extracting the hidden secrets.
The definition of MISM is shown in Equation (
13), and it is calculated as follows:
The MISM is defined as the average of two components: the Sigmoid function applied to the PSNR divided by 10, and the SSIM. The Sigmoid function transforms the PSNR value, which represents the Peak Signal-to-Noise Ratio, into a normalized range between 0 and 1. The PSNR is calculated as the logarithm base 10 of the ratio between the maximum possible pixel value squared and the Mean Squared Error (MSE) between the original and the reconstructed image. The SSIM measures the structural similarity between two images. By combining these two components and taking their average, the MISM provides a comprehensive evaluation of the similarity between images, accounting for both the PSNR and SSIM measurements.
The equation above represents the Modified Multi-Image Similarity Metric (MMISM) as Equation (
14), which is calculated as the weighted average of two MISM values: MISM between cover images
and stego images
, MISM between secret images
and extracted images
. The weights
and
determine the relative importance assigned to each MISM component. By combining the MISM values for both cover and secret images with appropriate weighting, the MMISM provides a comprehensive evaluation of the overall similarity between multiple pairs of images, considering both hidden and extracted capabilities. For our evaluation, we choose
= 0.5 and
= 0.5.
To evaluate the contribution of perceptual path length, we aim to retrain the proposed model with four different loss functions.
Table 4 presents a comparison of steganographic capacity using different loss functions. The results indicate that the MSE (Mean Squared Error) loss function achieves (22.6427/0.9344) for revealed-secret images. Comparatively, the PPL loss function shows improved performance. Using PPL as a loss function in the extraction network exhibits a higher index of (27.7977/0.9793) and an MMISM of 0.9652. Similarly, using PPL in the hidden network achieves (27.0325/0.9760) and an MMISM of 0.9627. Notably, when using the PPL loss function for the entire process (including both hidden and extraction), the results are further enhanced. The stego-cover images achieve (38.6907/0.9760), and the revealed-secret images also show improved metrics with (33.5457/0.9872) and an MMISM of 0.9772.
Overall, the experimental results demonstrate that utilizing the PPL loss function for both hidden and extraction stages yields superior performance in terms of steganographic capacity, as indicated by the higher MMISM values. This suggests that the PPL loss function enhances both the hiding and extraction of secret information, leading to improved image quality and fidelity.
Table 5 presents a comparison of PSNR, SSIM, and MMISM values after stabilizing different models on the LFW dataset. Among the evaluated models, our proposed model stands out in terms of MMISM, which represents the overall evaluation of image similarity. In particular, we explicitly state that the results for ISGANs, DGANS and Atique were computed based on data provided by the authors in their respective papers. Additionally, the MMISM value was calculated using the data supplied by the authors.
Compared to the other model, our model achieves a significantly higher MMISM value of 0.9817. This indicates that our model demonstrates superior performance in terms of both hiding and extracting secret information, resulting in enhanced image quality and fidelity.
In summary, our proposed model exhibits a remarkable advantage over the other evaluated models, as demonstrated by the significantly higher MMISM value. This indicates the model’s superior ability to maintain steganographic capacity while achieving high-quality image reconstruction.
5. Discussion and Conclusions
In this study, we propose a GAN-based concealment approach for image hiding. Both our sender and receiver networks adopt a downsampling and upsampling architecture with multi-scale fusion, enabling the effective extraction of high-frequency features from images. To simulate realistic scenarios of potential detection, we employ Zhu-Net as an attacker to provide supervised detection of embedded secret information. The resulting framework exhibits high capacity, robust hiding capabilities, and accurate image recovery. Moreover, we enhance the loss function through the integration of perceptual path length methods. Furthermore, we advocate the adoption of the comprehensive metric MMISM to evaluate experimental outcomes. Research findings demonstrate the effective embedding of monochromatic secret images within equally sized cover images, concurrently ensuring precise secret image recovery. Validation experiments conducted on the Pascal VOC12 dataset and the LFW facial dataset illustrate the superiority of our approach over existing methods.
However, due to the intrinsic redundancy of image information and the inherent loss in secret image recovery by neural networks, this concealment technique may not be suitable for tasks requiring full secret information extraction. Additionally, the efficacy of this method is contingent upon strict transmission conditions; any attacks or disruptions during image transmission could potentially jeopardize the integrity of the embedded secret information, and while the use of the Y-channel-hidden method mitigates color loss and enhances concealment, it predominantly caters to monochromatic images. In practical applications, color images are more prevalent and encompass a broader information spectrum.
In our forthcoming work, we envisage investigating the robustness of enhanced network architectures, evaluating their resilience against image transformations, translations, noise attacks, and other perturbations. Furthermore, we contemplate exploring strategies to hide multiple images in distinct channels of a single image, thereby augmenting the network’s steganographic capacity.


 and
and 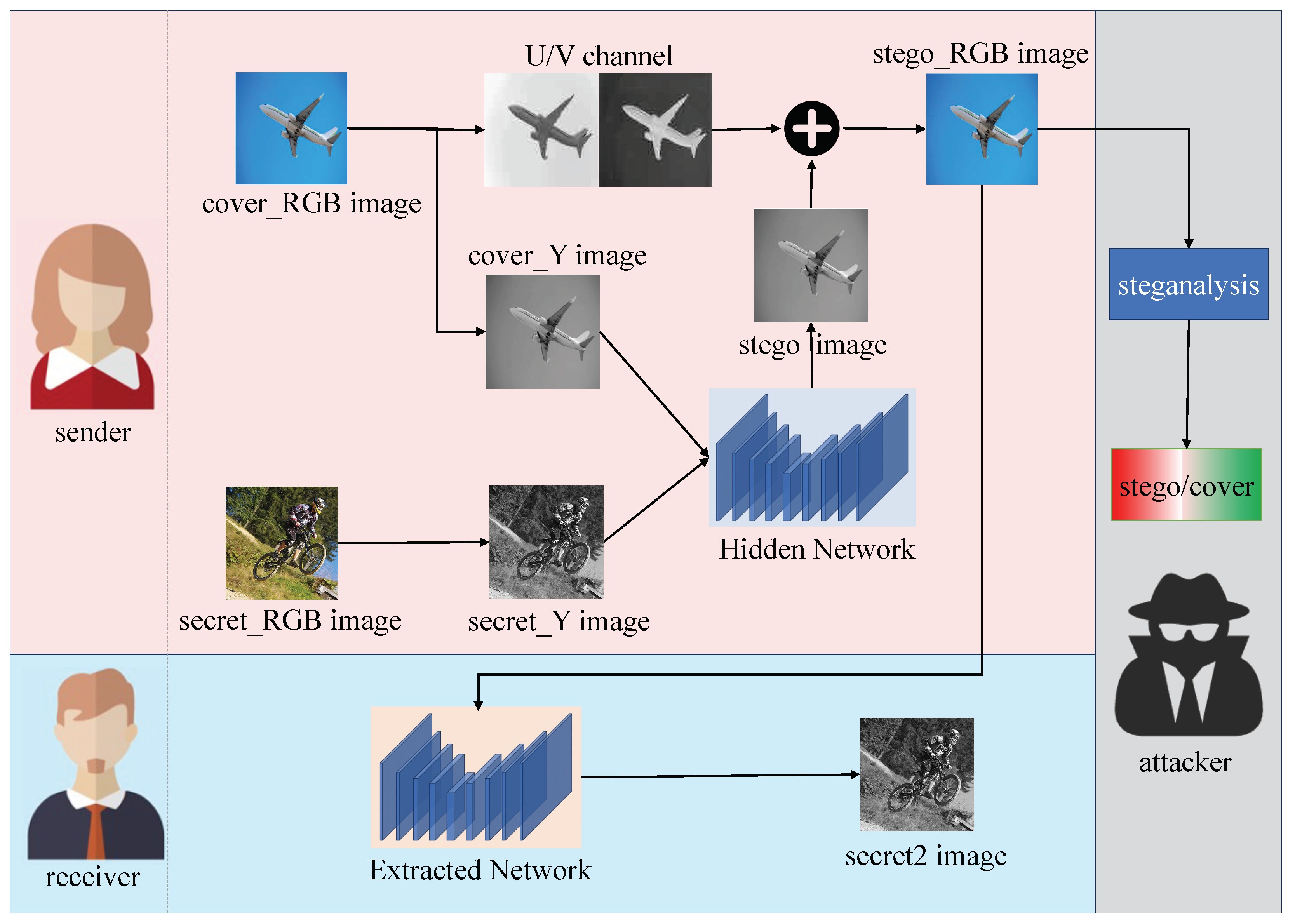





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}