


Recommendation Method of Power Knowledge Retrieval Based on Graph Neural Network

Abstract
:1. Introduction
- Making full use of the network topology of the knowledge graph, we adopt a graph neural network to realize the deep semantic embedding and knowledge inference of electric power knowledge. The completeness of the power knowledge map is improved by complementing the potential entity relationships of the existing knowledge map.
- We deeply mine the features of users’ retrieval behaviors and analyze users’ personality subgraphs and retrieval subgraphs through knowledge aggregation and similarity matching. Based on the path and topology of the subgraph, we reorder the power entities to achieve the accurate prediction of users’ retrieval intentions and avoid the problems of cold starts and information overload.
- We design comparison experiments on public datasets to verify the recommendation effectiveness of the graph-neural-network-based user retrieval recommendation method, demonstrate the recommendation basis of the model results, and enhance the interpretability of the algorithm.
2. Related Work
3. Recommendation Method for Power Knowledge Retrieval Based on GNNs
3.1. Power Knowledge Reasoning Based on Graph Neural Network
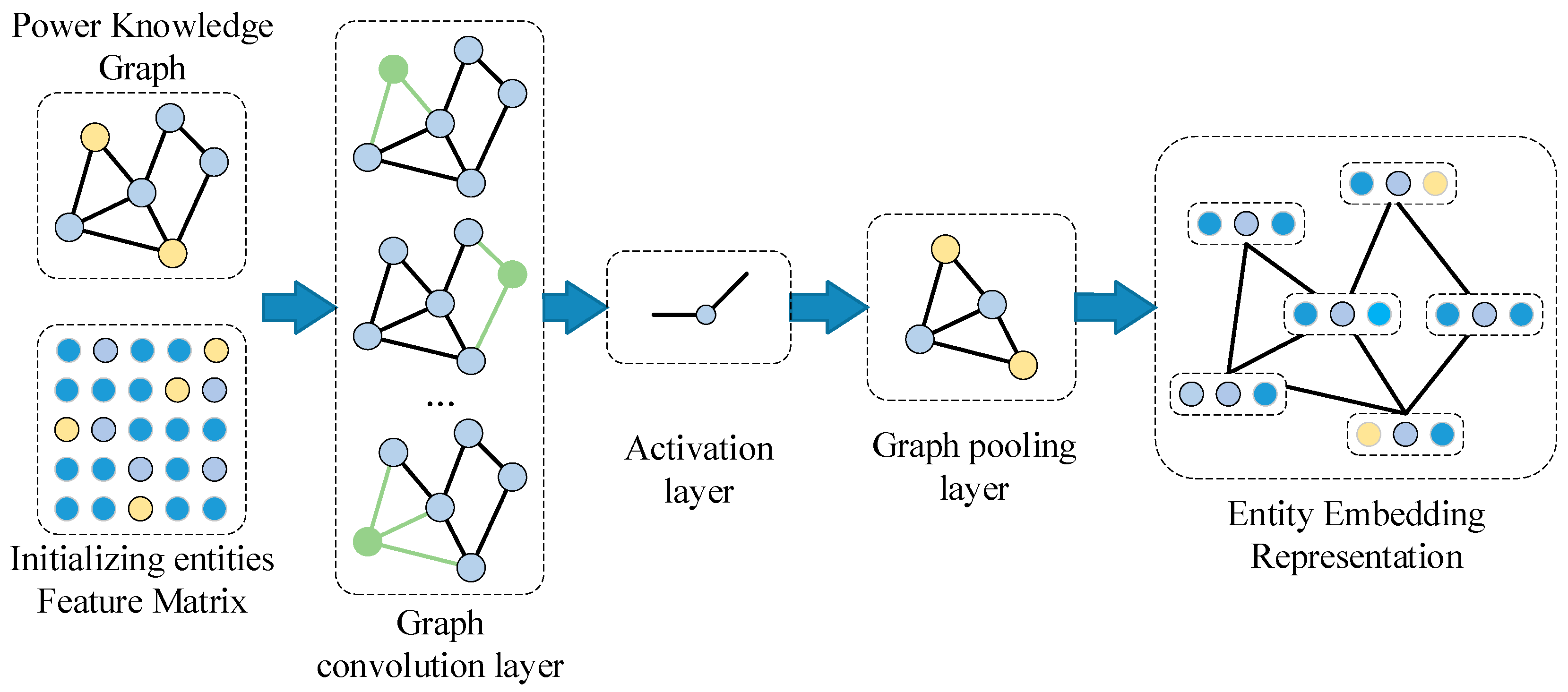
3.1.1. Graph Entity Embedding Based on Graph Neural Network
3.1.2. Knowledge Reasoning Incorporating Electricity Mapping Paths
3.2. Power Knowledge Retrieval and Recommendation Based on Knowledge Subgraph
4. Experimental Analysis
4.1. Experimental Datasets
4.2. Evaluation Metrics
4.3. Experimental Environment and Parameter Settings
4.4. Analysis of Experimental Results
4.4.1. Evaluation of Power Knowledge Reasoning
4.4.2. Electricity Knowledge Retrieval Recommendation Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Cao, J.; Luo, L. Current status and challenges of power text data mining. Zhejiang Electr. Power 2019, 38, 1–7. [Google Scholar]
- Shi, W.; Zhu, Y.; Huang, T.; Sheng, G.; Lian, Y.; Wang, G.; Chen, Y. An Integrated Data Preprocessing Framework Based on Apache Spark for Fault Diagnosis of Power Grid Equipment. J. Signal Process. Syst. 2017, 86, 221–236. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, H.; Wu, X. Application problems and countermeasures of knowledge mapping in error checking of power equipment defect text. J. Power Syst. Their Autom. 2022, 34, 113–119+128. [Google Scholar]
- Yu, H.; Zhang, J.; Wu, M.; Wu, X. A framework for rapid construction and application of domain knowledge graphs. J. Intell. Syst. 2021, 16, 15. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A Lite Bert for Self-Supervised Learning of Language Representations. In Proceedings of the International Conference on Learning Representations ICLR, Addis Ababa, Ethiopia, 26 April–1 May 2019; pp. 1–17. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 15th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Zhang, Y.; Wang, W.; Liu, H.; Gu, R.; Hao, Y. Collaborative filtering recommendation algorithm based on knowledge graph embedding. Comput. Appl. Res. 2021, 38, 3590–3596. [Google Scholar]
- Steffen, R. Factorization Machines with libFM. ACM Trans. Intell. Syst. Technol. 2012, 3, 1–22. [Google Scholar]
- Qu, Y.; Bai, T.; Zhang, W.; Nie, J.; Tang, J. An End-to-End Neighborhood-Based Interaction Model for Knowledge-Enhanced Recommendation. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, AK, USA, 5 August 2019; pp. 1–9. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & Deep learning for recommender systems. In Proceedings of the Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016. [Google Scholar]
- Li, T.; Liu, M.; Zhang, Y.; Xu, J.; Chen, Y. A review of entity linking research based on deep learning. J. Peking Univ. 2021, 57, 91–98. [Google Scholar]
- Ruan, C.; Qi, L.; Wang, H. Intelligent recommendation of demand response by fusing knowledge graph and neural tensor network. Power Grid Technol. 2021, 45, 2131–2140. [Google Scholar]
- Thagard, P. Collaborative Knowledge. Noûs 1997, 31, 242–261. [Google Scholar] [CrossRef]
- Gao, J. Research on the Diversification Method of Retrieval Results Based on Query Subintent Recognition. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2012; pp. 6–8. [Google Scholar]
- Liu, Q.; Qin, M. A collaborative matrix decomposition method based on knowledge representation learning. J. Beijing Univ. Technol. 2021, 41, 752–757. [Google Scholar]
- Xiong, C.; Shu, G.; Guo, H. A graph neural network recommendation model incorporating user preferences. Comput. Sci. 2022, 55, 1–37. [Google Scholar]
- Xu, Y.; Zhang, H.; Cheng, K.; Liao, X.; Zhang, Z.; Li, L. A review of knowledge graph embedding research. Comput. Eng. Appl. 2022, 13, 396. [Google Scholar]
- Guo, X.; Xia, H.; Liu, Y. A hybrid recommendation model fusing knowledge graph and graph convolutional network. Comput. Sci. Explor. 2022, 16, 1343. [Google Scholar]
- Jiao, J.; Wang, S.; Zhang, X.; Wang, L.; Wang, J. gMatch: Knowledge base question answering via semantic matching. Knowl. Based Syst. 2021, 228, 107270. [Google Scholar] [CrossRef]
- Wang, T.; Shi, D.; Wang, Z.; Xu, S.; Xu, H. MRP2Rec: Exploring Multiple-Step Relation Path Semantics for Knowledge Graph-Based Recommendations. IEEE Access 2020, 8, 134817–134825. [Google Scholar] [CrossRef]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d Knowledge Graph Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1811–1818. [Google Scholar]
- Afoudi, Y.; Lazaar, M.; Al Achhab, M. Hybrid recommendation system combined content-based filtering and collaborative prediction using artificial neural network. Simul. Model. Pract. Theory Int. J. Fed. Eur. Simul. Soc. 2021, 113, 102375. [Google Scholar] [CrossRef]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI 2017), Melbourne, VIC, Australia, 19–25 August 2017; pp. 1725–1731. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the International World Wide Web Conference, Perth, Australia, 3–7 May 2017; pp. 173–182. [Google Scholar]
- Fan, W.; Liu, X.; Jin, W.; Zhao, X.; Tang, J.; Li, Q. Graph Trend Filtering Networks for Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ‘22), Madrid, Spain, 11–15 July 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 112–121. [Google Scholar]
- Jiang, X.; Tian, B.; Tian, X. Retrieval and Ranking of Combining Ontology and Content Attributes for Scientific Document. Entropy 2022, 24, 810. [Google Scholar] [CrossRef]
- El-Gayar, M.; Mekky, N.; Atwan, A.; Soliman, H. Enhanced Search Engine Using Proposed Framework and Ranking Algorithm Based on Semantic Relations. IEEE Access 2019, 7, 139337–139349. [Google Scholar] [CrossRef]
- Lo, K.; Ishigaki, T. X-2ch: Quad-Channel Collaborative Graph Network over Knowledge-Embedded Edges. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR‘21), Online, 11–15 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2076–2080. [Google Scholar]
- Yan, S.; Ma, W.; Zhang, M.; Yiqun, L.; Shaoping, M. A deep reinforcement learning recommendation method combining users’ long- and short-term interests. Chin. J. Inf. 2021, 35, 107–116. [Google Scholar]
- Sun, Z.; Yang, J.; Zhang, J.; Alessandro, B.; Long-Kai, H.; Chi, X. Recurrent Knowledge Graph Embedding for Effective Recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 297–305. [Google Scholar]
- Jiang, Z.; Tian, C. Collaborative Filtering Algorithm of Graph Neural Network Based on Fusion Meta-Path. Comput. Syst. Appl. 2021, 30, 140–146. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Quanquan, G.; Bradley, S.; Urvashi, K.; Brandon, N.; Jiawei, H. Personalized Entity Recommendation: A Heterogeneous Information Net-Work Approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar]
- Wang, C.; An, J.; Mu, G. Power System Network Topology Identification Based on Knowledge Graph and Graph Neural Network. Front. Energy Res. 2021, 8, 613331. [Google Scholar] [CrossRef]
- Bin, Y.; Ruipeng, C.; Yu, F.; Zeshui, X. A graph convolutional network based on object relationship method under linguistic environment applied to film evaluation. Inf. Sci. 2022, 608, 1283–1300. [Google Scholar]
- Zhang, F.; Yuan, N.; Lian, D.; Xie, X.; Ma, W.Y. Collaborative Knowledge Base Embedding for Recommender Systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep Knowledge Aware Network for News Recommendation. In Proceedings of the Worldwide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; Liu, Q. SHINE: Signed Heterogeneous Information Network Embedding for Sentiment Link Prediction. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (WSDM ‘18). Association for Computing Machinery, New York, NY, USA, 5–9 February 2018; pp. 592–600. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Guo, M. RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM 2018, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Zhao, J.; Zhou, Z.; Guang, Z.; Xie, X.; Guo, M.; Liu, Q. Intentgc: A Scalable Graph Convolution Framework Fusing Heterogeneous Information for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2347–2357. [Google Scholar]
- Jiang, Y.; Cheng, Y.; Zhao, H.; Zhang, W.; Miao, X.; He, Y.; Wang, L.; Yang, Z.; Cui, B. Zoomer: Boosting Retrieval on Web-Scale Graphs by Regions of Interest. In Proceedings of the IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 2224–2236. [Google Scholar]
- Gao, C.; Sun, C.; Shan, L.; Lin, L.; Wang, M. Rotate3d: Representing Relations as Rotations in Three-Dimensional Space for Knowledge Graph Embedding. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020; pp. 385–394. [Google Scholar]
- Lu, H.; Hu, H.; Lin, X. DensE: An enhanced non-commutative representation for knowledge graph embedding with adaptive semantic hierarchy. Neurocomputing 2022, 476, 115–125. [Google Scholar] [CrossRef]
- Tai, C.; Wu, M.; Chu, Y.; Chu, S.Y.; Ku, L.W. Mvin: Learning Multiview Items for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 25–30 July 2020; SIGIR: Xi’an, China, 2020; pp. 99–108. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Entities | Relationships | Training | Validation | Test |
|---|---|---|---|---|---|
| FB15K-237 | 14,541 | 237 | 272,115 | 17,535 | 20,466 |
| WN18 | 40,943 | 18 | 141,442 | 5000 | 5000 |
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| PKG | 1550 | 16 | 4835 | 524 | 506 |
| Name | Users | Records | Training | Validation | Test |
|---|---|---|---|---|---|
| Movie Lens-1M | 6040 | 1,000,000 | 272,115 | 17,535 | 20,466 |
| Lastfm-360K | 360,000 | 17,000,000 | 141,442 | 5000 | 5000 |
| PKR | 210 | 9600 | 86,835 | 3034 | 3134 |
| Environment | Configuration |
|---|---|
| Operating System | Ubuntu 16.04 |
| RAM | 32 GB |
| GPU | GeForce RTX 3070ti × 2 |
| CPU | Intel Core i7-10700K @ 3.80 GHz |
| Language | Python 3.7 |
| Framework | Pytorch 1.12.0 |
| Dataset | Model | ConvE | Rotate3D | DensE | PKR-GNN |
|---|---|---|---|---|---|
| WN18 | MR | 374 | 214 | 245 | 231 |
| MRR | 94.3 | 95.1 | 96.1 | 96.3 | |
| Hit@1 | 93.5 | 94.5 | 94.1 | 94.4 | |
| Hit@10 | 95.6 | 96.1 | 96.3 | 96.5 | |
| WN18RR | MR | 4187 | 3328 | 3281 | 3261 |
| MRR | 43.0 | 48.9 | 47.5 | 47.6 | |
| Hit@1 | 40.0 | 44.2 | 43.2 | 43.5 | |
| Hit@10 | 44.0 | 57.9 | 59.2 | 59.3 | |
| FB15K-237 | MR | 244 | 165 | 155 | 153 |
| MRR | 32.5 | 34.7 | 39.1 | 38.5 | |
| Hit@1 | 23.7 | 25.0 | 27.5 | 27.3 | |
| Hit@10 | 50.1 | 54.3 | 53.2 | 56.3 | |
| PKG | MR | 671 | 435 | 517 | 329 |
| MRR | 83.0 | 79.0 | 90.1 | 89.3 | |
| Hit@1 | 76.2 | 73.6 | 78.3 | 82.7 | |
| Hit@10 | 81.1 | 85.4 | 83.1 | 84.2 |
| Dataset | Model | DeepFM | RippleNet | KGIN | PRR-KS |
|---|---|---|---|---|---|
| Movie Lens-1M | P | 77.1 | 73.6 | 76.8 | 76.5 |
| R | 73.4 | 71.2 | 72.9 | 74.2 | |
| F1 | 75.2 | 72.4 | 74.8 | 75.3 | |
| Lastfm-360K | P | 72.5 | 82.4 | 80.6 | 81.6 |
| R | 68.2 | 77.9 | 78.7 | 79.6 | |
| F1 | 70.3 | 80.1 | 79.6 | 80.5 | |
| PKR | P | 79.3 | 82.2 | 88.1 | 88.3 |
| R | 71.4 | 80.2 | 86.5 | 86.3 | |
| F1 | 75.1 | 81.2 | 87.2 | 87.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, R.; Zhang, Y.; Ou, Q.; Li, S.; He, Y.; Wang, H.; Zhou, Z. Recommendation Method of Power Knowledge Retrieval Based on Graph Neural Network. Electronics 2023, 12, 3922. https://doi.org/10.3390/electronics12183922
Hou R, Zhang Y, Ou Q, Li S, He Y, Wang H, Zhou Z. Recommendation Method of Power Knowledge Retrieval Based on Graph Neural Network. Electronics. 2023; 12(18):3922. https://doi.org/10.3390/electronics12183922
Chicago/Turabian StyleHou, Rongxu, Yiying Zhang, Qinghai Ou, Siwei Li, Yeshen He, Hongjiang Wang, and Zhenliu Zhou. 2023. "Recommendation Method of Power Knowledge Retrieval Based on Graph Neural Network" Electronics 12, no. 18: 3922. https://doi.org/10.3390/electronics12183922
APA StyleHou, R., Zhang, Y., Ou, Q., Li, S., He, Y., Wang, H., & Zhou, Z. (2023). Recommendation Method of Power Knowledge Retrieval Based on Graph Neural Network. Electronics, 12(18), 3922. https://doi.org/10.3390/electronics12183922