1. Introduction
Digital image processing is the processing of image information to meet people’s visual and practical application needs [
1,
2]. In the Internet era, the equipment update speed is becoming increasingly fast, and people’s demand for information is more urgent. Digital images can express rich information, and digital image processing is thus a valuable research topic. High-quality images can convey rich content and information [
3], but in real life, due to the passage of time, the loss generated by image transmission and other factors lead to the lack of image information and quality degradation, so image inpainting has become a popular research direction in the field of digital image processing [
4,
5].
The purpose of image inpainting is to recover the missing information based on the known information of the image and fill in the missing pixels of the image in order to achieve the overall semantic structure consistency and visual realism [
6,
7]. This task has attracted considerable of attention over the years, and restorers tend to use the most appropriate way to restore images to their original state while ensuring the most desirable artistic effect [
8,
9]. High-quality image inpainting has a wide range of application areas, such as target removal, scratch removal, watermark removal, and inpainting of old photos [
10,
11,
12,
13].
Traditional image inpainting algorithms are mainly divided into two kinds. Structure-based image inpainting algorithms are based on the structural principle of image information, using the gradual diffusion of information to restore the image, mainly for the implementation of the PDE process of partial differential equations [
14]. The texture-based method has good repair effect when dealing with small areas of simple structure loss, but it lacks the constraints of high-level semantic information of the image, so the problem of inconsistent content texture occurs when dealing with large areas of broken images. Texture-based image inpainting algorithms select reasonable feature blocks from the known region of the damaged image to sample, synthesize, or copy and paste into the region to be restored [
15], and the core idea of the method is to search for the most similar image feature blocks in the known part of the image or dataset, so that the structure and texture information of the image can be retained better, but these kinds of algorithms usually requires a large amount of time, with low versatility and efficiency.
In recent years, deep learning has been highly valued for its powerful learning ability and rich application scenarios and has achieved outstanding success in the field of computer vision. Image inpainting techniques based on deep learning have been well developed [
16,
17,
18], thus promoting the significant improvement of the image inpainting effect. Pathak et al. [
19] proposed the first GAN-based inpainting algorithm, the Context Encoder (CE). The CE as a whole is a simple encoder–decoder structure that uses the fully connected layer channel to propagate information, acts as an intermediate connection between the encoder and decoder, and learns the relationships between all feature locations of the network to deepen the overall semantic understanding of the image. In order to ensure the results generated by image inpainting have reasonably clear texture and structure, Yu et al. [
20] proposed a two-stage network architecture with a coarse-to-fine structure. The first stage consists of null convolution to obtain a rough restored image, and the second stage uses a contextual attention layer to accomplish fine inpainting. The authors further developed the idea of copy and paste by proposing a contextual attention layer that is microscopically and fully convolutional. Partial convolution proposed by Liu et al. [
21] and gated convolution proposed by Yu et al. [
22] have provided new ideas for the use of partial convolution or gated convolution that can ignore invalid pixels, thus solving the problem whereby ordinary convolution treats all input pixels the same way, which produces the problem of many artificial and unnatural effects and high computation. Improvement based on convolution has become a major breakthrough in the field of image inpainting.
In 2019, Wang et al. [
23] proposed a generative multi-column convolutional neural network (GMCNN) for image inpainting using a multi-branch convolutional neural network that consists of three parallel encoder–decoder branches, with each branch using three different filter sizes to extend the importance of a sufficiently large receptive field for image inpainting to solve the boundary consistency problem. However, the use of large convolutional kernels in branch structures can lead to an increase in model parameters and still result in unreasonable or blurry repair results for high-resolution and complex background images. To overcome this problem, we designed a lightweight multi-level feature aggregation network that extracts features from convolutions with different expansion rates to obtain more feature information, thereby restoring more reasonable missing image content and ensuring that the model does not add additional parameters. Fourier convolution was designed and used to consider the global context in the shallow layer of the generator, improving the effectiveness of high-resolution image inpainting. In addition, self-guided regression loss was designed and used to enhance semantic details of missing regions, and a global local discriminator with two branches was used to promote consistency in global structure and morphology.
The remaining sections of this paper are organized as follows.
Section 2 describes the related inpainting work.
Section 3 describes the method proposed in this paper in detail.
Section 4 outlines the details of the experiment and compares it with other state-of-the-art methods.
Section 5 presents our conclusions.
2. Related Work
2.1. Generative Adversarial Networks
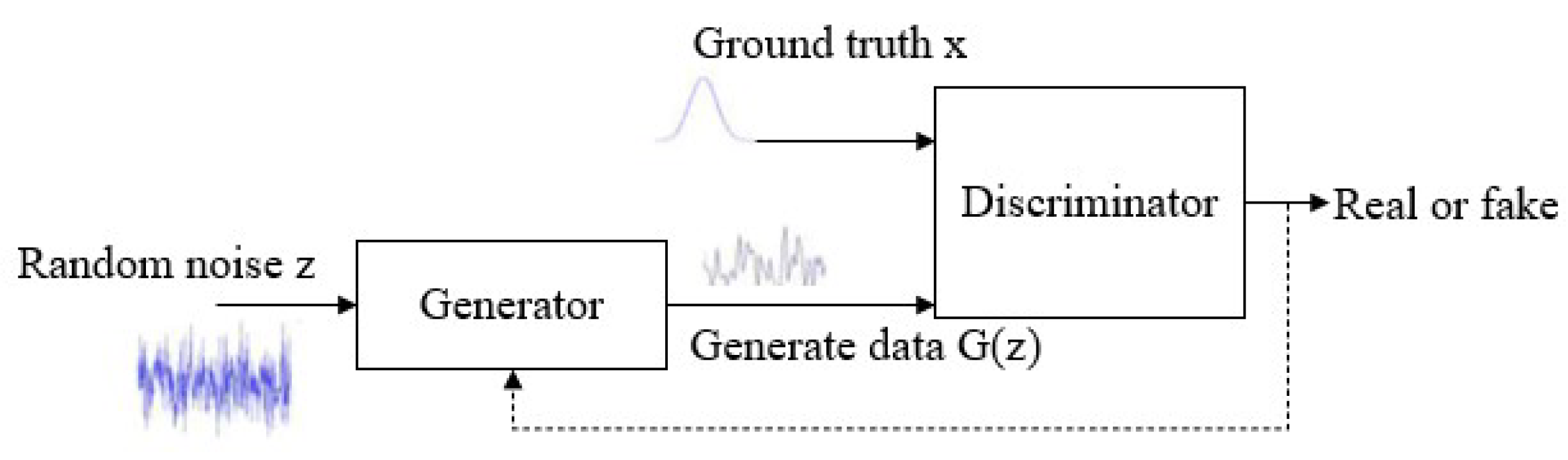
A generative adversarial network reaches the Nash equilibrium state through confrontation training and then obtains a generator and inputs the damaged picture into the generator to obtain the repair result of the damaged picture [
24]. The generative adversarial network consists of a generator and a discriminator. The generator is designed to transform an input incomplete image into a fully repaired image. And the purpose of the discriminator is to identify and distinguish the fake repair image generated by the generator from the real complete image, set the output of the synthetic image produced by the generator to 0, and set the output of the real complete image to 1. Generative adversarial networks are widely used in the field of computer vision due to their capacity for producing more realistic images. A GAN is shown in
Figure 1.
The generator and discriminator of the GAN rely on different loss methods for training. The formula for the loss function of the discriminator network is as follows.
The loss function formula of the generator network is as follows.
The model’s adversarial loss formula is as follows.
where
E represents the expectation,
represents the real sample,
G represents the generator network,
D represents the discriminator network, and
represents the input of the generator network.
We first trained the discriminator, and in the process of training the discriminator, the closer the value of to 1 and the closer the value of to 0, the better. After the parameters of the discriminator were updated, we set the parameters of the discriminator as fixed and proceeded to train the generator. In the training process of the generator, our objective is to bring the value of closer to 1, which indicates better performance.
2.2. Local Discriminator
The local discriminator is used to assist in network training to determine whether the generated image has complete consistency, with the main aim of maintaining local semantic consistency of the inpainting results. The local discriminator focuses on the restored region of the image and only focuses on small feature blocks to determine more details. During each training process of the GAN, the discriminator needs to be updated first to ensure that the discriminator can correctly distinguish the real samples from the training samples in the beginning period of training. The local discriminator network is shown in
Figure 2.
The local discriminator network is based on a convolutional neural network (CNN), which consists of five convolutional layers and one fully connected layer, and the input is a 128 × 128 image. The input to the network is an image centered on the repair region with five convolutional layers with a convolutional kernel size of 5 × 5 and a step size of 2 × 2. The final output is a 1024-dimensional vector representing the local context around the repair region.
2.3. Global Discriminator
Iizuka et al. [
25] proposed the inclusion of a global discriminator in the image inpainting model with the main purpose of maintaining the global semantic consistency of the inpainting results. The input to the global discriminator is the whole image, and the global consistency is judged by recognizing the input image. The global discriminator network has the same goal as the local discriminator network, which is to judge whether the input image is real or not. The global discriminator network is shown in
Figure 3.
The global discriminator network is composed of the same pattern, also based on a CNN, consisting of six convolutional layers and one fully connected layer, and the input is a 256 × 256 image. The network compresses the generated image with an overall pixel scaling of 256 × 256, where all six convolutional layers use a 5 × 5 convolutional kernel with a step size of 2 × 2 to achieve a lower image resolution while increasing the number of output filters. The output of the final network is fused together through a fully connected layer.
2.4. Perceptual Loss
Perceptual loss is a loss function proposed by Justin Johnson et al. [
26] in the style diversion task, which is mainly used in image super-resolution, image inpainting, etc. It first calculates the low-level feature loss, and then abstracts potential features via convolutional layers to perceive images that are closer to the feature space of human thinking. The features obtained from the convolution of the real image (generally extracted by the VGG network) are compared with the features obtained by the convolution of the generated image, the content and the high-level information of the global structure become closer, and the loss is calculated.
The feature reconstruction function calculation formula of perceptual loss is as follows.
where
represents the pre-trained network model,
represents the original damaged image, and
y represents the generated repaired image. The pre-trained network extracts the semantic message of the initial graph and the generated graph and calculates the L2 norm of the relevant location between the two to gain the perceptual loss. It can effectively raise the training result of the model by decreasing the perceptual loss.
3. Our Method
3.1. Network Structure
With the rapid development of the Internet, people’s requirements for image quality are increasing. Aiming at the problem of unreasonable or blurred inpainting results for images with complex geometric structure and high clarity, a multi-level feature aggregation network was designed in this study, as shown in
Figure 4. The network framework is based on a generative adversarial network, which consists of a generator and a discriminator with two branches. The input of the network is an image with a mask; firstly, the mask image is downsampled, the input image is shrunk, and after down-sampling the image to be repaired is repaired using a multi-level feature aggregation network. After the repair is completed, it is restored to the original size after the upper adoption, and then the repair result is input into the discriminator to determine whether it is true or false.
In the generation network, we input a mask image, first processing the mask image, and then using a lightweight multi-level feature aggregation network to extract suitable feature blocks for filling. At present, image inpainting tasks based on generative adversarial networks have achieved good results, but the restoration effect is still unsatisfactory for images with complex structures and high-definition pixels. For complex structured images, previous methods have not taken into account the semantic structure consistency of the results and expected targets, which can lead to a lack of clear semantic details in the restoration results. Therefore, we designed a multi-level feature aggregation module in the generation network to extract features from multiple levels, obtain multiple features, and recover more detailed information. For high-resolution images, we hope to retain very realistic and perfect details after processing, achieving high-quality repair results. Therefore, in the generation network, we designed and used a fast Fourier convolution (FFC) module to effectively solve the problem of poor generalization performance of the network model for high-resolution images.
In order to train the network model in this article and achieve better consistency, our discriminator uses global and local discriminators with two branches. Global and local discriminators are trained to distinguish between generated and real images, and the use of both global and local discriminators is crucial for obtaining realistic image restoration results. The global discriminator recognizes the region as the entire image, evaluates its coherence, and ensures the global consistency of the generated results. The local discriminator recognizes a small area of the image centered around the repaired part, evaluates its local coherence, and ensures local consistency of the generated results. Finally, a connection layer is used to combine the outputs of the global discriminator and the local discriminator, and the combined results are input into a fully connected layer for processing, outputting a continuous value that represents the probability that the image is true.
3.2. Multi-Level Feature Aggregation Network
A large and effective receptive field is crucial for understanding the global structure of the image and thus solving the inpainting problem. Previous algorithms have proposed a null convolution in order to obtain a larger receptive field, which introduces a dilation rate to the convolutional layer, a parameter that defines the spacing between the values of the convolutional kernel as it processes the data. This method expands the receptive field while maintaining the original number of parameters, but the cavity convolution is sparse and ignores many relevant pixels. Literature [
23] proposes the use of a GMCNN, which uses a network with large convolution kernels for multi-column results; however, this method introduces a large number of model parameters. To address this problem, the multi-level feature aggregation module in the generative network was designed in this study, which well balances the contradiction between expanding the receptive field and guaranteeing the convolutional density, and a multi-level feature extraction method was adopted to obtain a sufficiently large receptive field, which helps to recover more detailed information in the inpainting results. The multi-level feature aggregation module is shown in
Figure 5.
In the multi-level feature aggregation module designed in this study, conv-3 indicates that the convolution kernel is a 3 × 3 convolution, the first convolution layer is used to reduce the number of feature channels, and then features are extracted through four different branches using convolutions with different expansion rates: padding = 1 indicates that the expansion rate is 1, padding = 2 indicates that the expansion rate is 2, padding = 4 indicates that the expansion rate is 4, and padding = 8 indicates an expansion rate of 8. Each cavity convolution is followed by connecting the ReLU activation layer and the instance normalization layer (IN), ⊕ summing the elements. Finally, the features of the four branches are aggregated together, and the number of feature channels is expanded to 256 by fusing the aggregated features through a single 1 × 1 convolution, with the last convolution followed by connecting only the instance normalization layer without using the activation function.
3.3. Fast Fourier Convolution
We designed and used a new convolution module, fast Fourier convolution (FFC), in the generative network, which not only has a non-local receptive field but also achieves the fusion of cross-scale information inside the convolution, making the model consider the global contextual information in the early layers, which is suitable for high-resolution images. The structure of FFC is shown in
Figure 6.
FFC is a convolution operator which uses Fourier spectral theory to achieve non-local sensory fields in depth models. The proposed operator is also designed to achieve cross-scale fusion. FFC is based on Fast Fourier Transform (FFT) at the channel level. FFC is designed to be divided into two branches at the channel level. The local branch uses conventional convolution, and the global branch uses FFT to obtain the global contextual information. FFC can start to consider the global contextual information at the shallow level of the network, and it has a suitable fitting effect for high-resolution images. At the same time, FFC is also very suitable for the depth model effect and for capturing periodic structures.
3.4. Overall Loss
In deep-learning-based repair algorithms, the choice of loss function is crucial to optimize the network model by comparing predicted and true values to quantitative analysis.
Self-guided regression loss guides the feature mapping similarity metric of the pre-trained VGG19 network by calculating the difference between predicted and true values. The self-guided regression loss is not performed in the pixel space but in the shallow semantic space, which utilizes the difference maps of the true and false images as the bootstrap maps, increasing the penalty for the missing regions, which is used to enhance the repaired regions semantic details in and to improve the detail fidelity of the generated images. The self-guided regression loss function is shown below.
where
, C is the number of channels of the feature mapping
,
is the activation mapping of the given input
in the
layer,
is the activation mapping of the given input
in the
layer, ⊙ is the elemental product operator, and
takes values in the range of 0–1.
For image generation network training, we used VGG feature matching loss to compare the activation maps of the middle layer of the trained VGG19 network. In this study, the discriminator is global and local double branching, so we added local branching to the discriminator feature matching loss to ensure the consistency between the generated image and the real image in any dimensional space. The formula is shown below.
where local denotes a local branch and D denotes a discriminator.
denotes the activation mapping of the discriminator given input
at the
layer, and
denotes the activation mapping of the discriminator given input
at the
layer.
High receptive field perceptual loss (HRFPL) is suitable for network models with fast-growing receptive fields, it is compatible with the characteristics of perceptual loss by pre-training the network to extract and compare the differences between the generated image feature maps and the real image, and, at the same time, it helps the network to understand the global structure. The high sensory field perceptual loss function formula is as follows.
where
is the high sensory field base model,
is the element-by-element operation, and M is the sequential two-stage mean operation.
For the generator in this paper, the formula for the adversarial loss is shown below.
where
,
denotes the real image, C() denotes the discriminator network without the last sigmoid function,
denotes the generated image.
In summary, our total loss function formula is shown below.
where
,
,
,
, and
are the parameters given to adjust the weight of each loss in the overall loss.
5. Conclusions
With the rapid development of the Internet, image inpainting will face higher requirements and challenges. Image inpainting is an important research branch in the field of digital image processing, which aims at automatically recovering lost information based on the existing information in the image. In this paper, an image inpainting algorithm based on a multi-level feature aggregation network is proposed, which takes advantage of the disparity in the range of sensory fields of different expansion rate convolutions to construct a network with a larger sensory field so as to capture more feature information and recover the missing parts with clear semantics and reasonable structural content. In addition, FFC is used in the generative network, which takes global contextual information into full consideration, and cross-scale information fusion is carried out within the convolution to ensure the clarity and reasonableness of the generated results. The discriminator uses global and local discriminators with two branches, which are trained to distinguish between the generated image and the real image, which is crucial for obtaining realistic image inpainting results. In the experimental part of the study, extensive quantitative and qualitative comparative and ablation studies were conducted to demonstrate the advantages of our designed network in terms of performance and effectiveness.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}