
Explained Learning and Hyperparameter Optimization of Ensemble Estimator on the Bio-Psycho-Social Features of Children and Adolescents




Abstract
:1. Introduction
- Find more conclusive evidence of the role that BMI plays in the healthy development of children and adolescents or to
- Find other features that could substitute or amend it.
2. Materials and Methods
2.1. Data Pre-Processing
- Neuromuscular Fitness (NMF),
- Muscular Fitness (MF), and
- Cardiorespiratory Fitness (CRF).
2.2. Basic Model Training on Whole Datasets
- max_features: 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 705;
- n_estimators: 100, 121, 144, 169, 196, 225, 256, 289;
- max_depth: 4, 9, 16, 25, 36, 49.
- max_features: 1, 2, 4, 8, 16;
- n_estimators: 32, 64, 128;
- max_depth: 4, 9, 16.
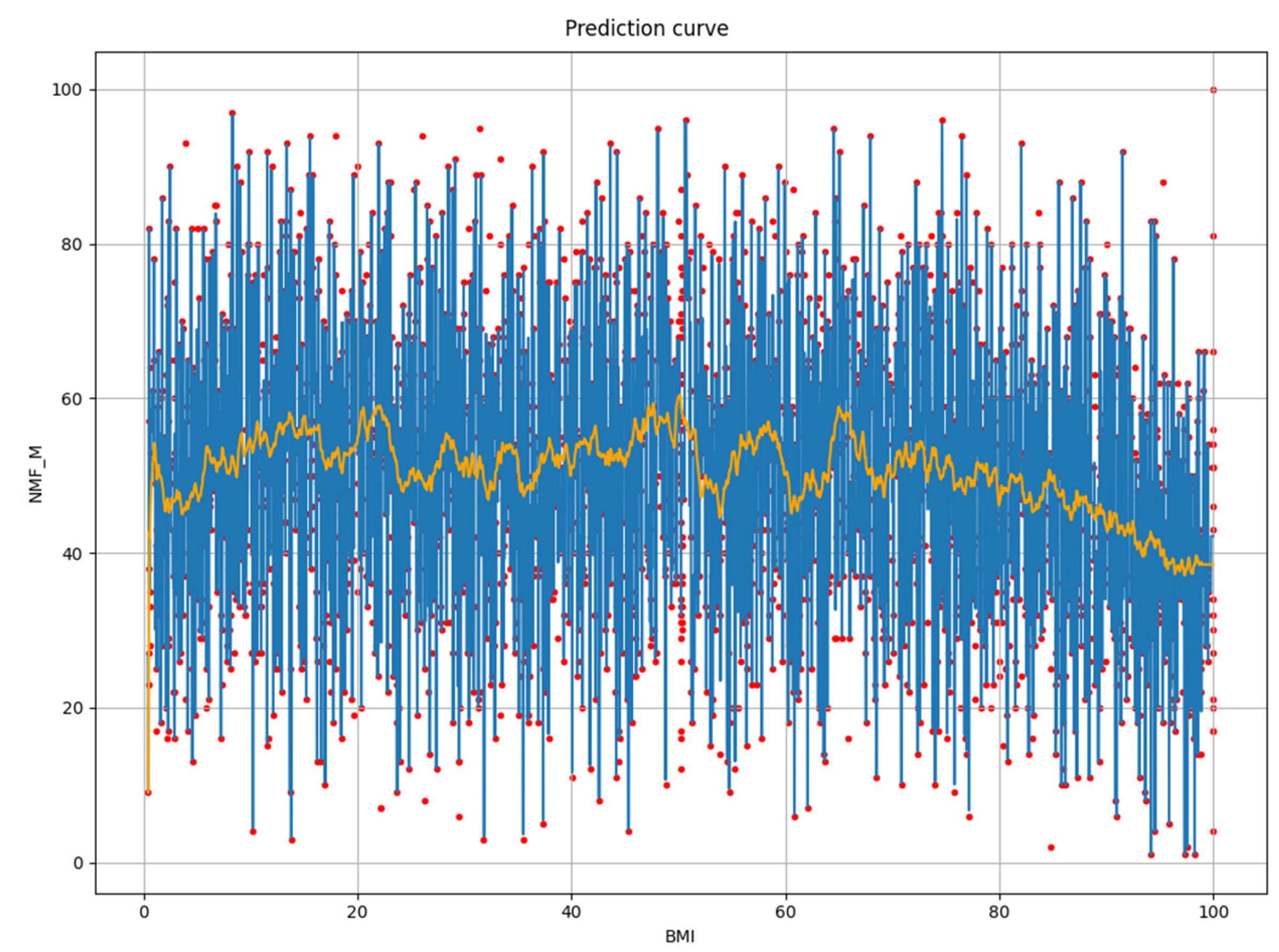
3. Results
3.1. Basic Model Training Evaluation
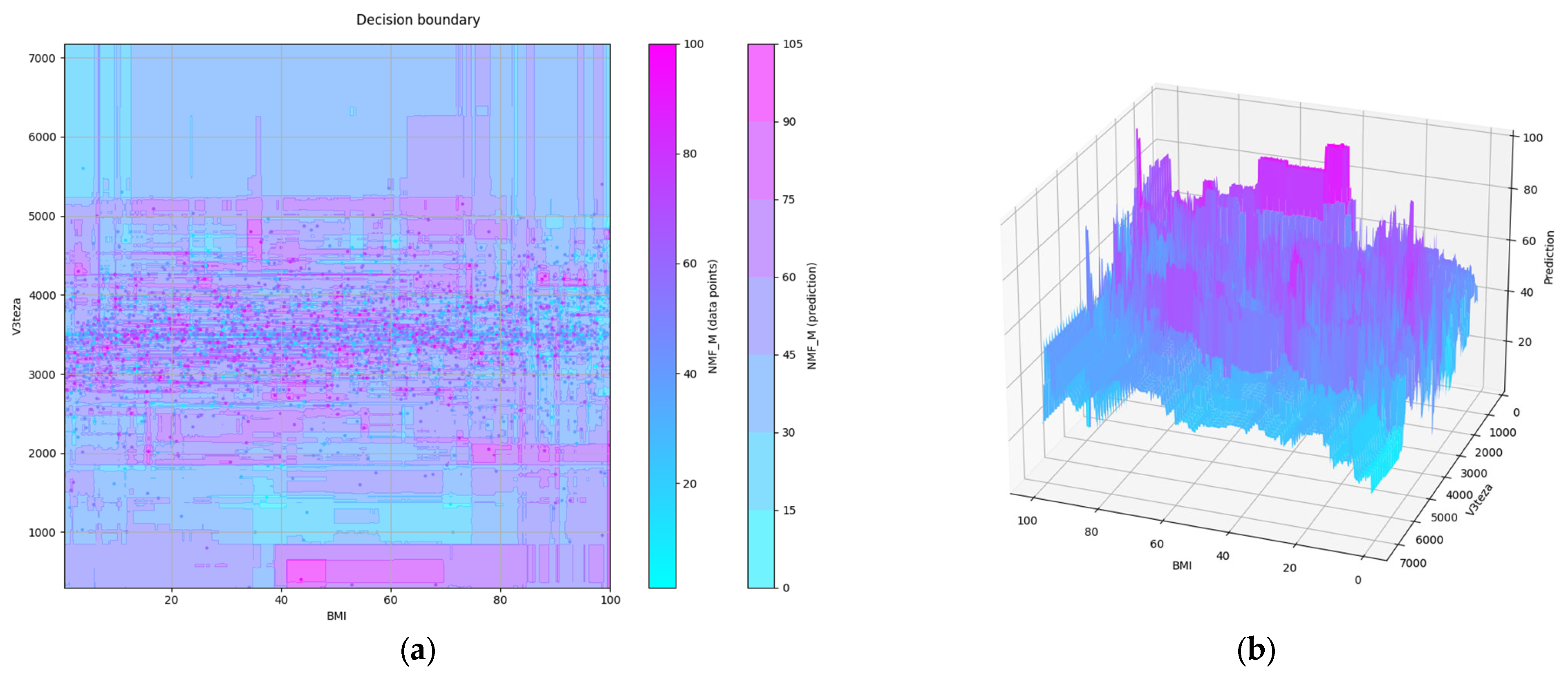
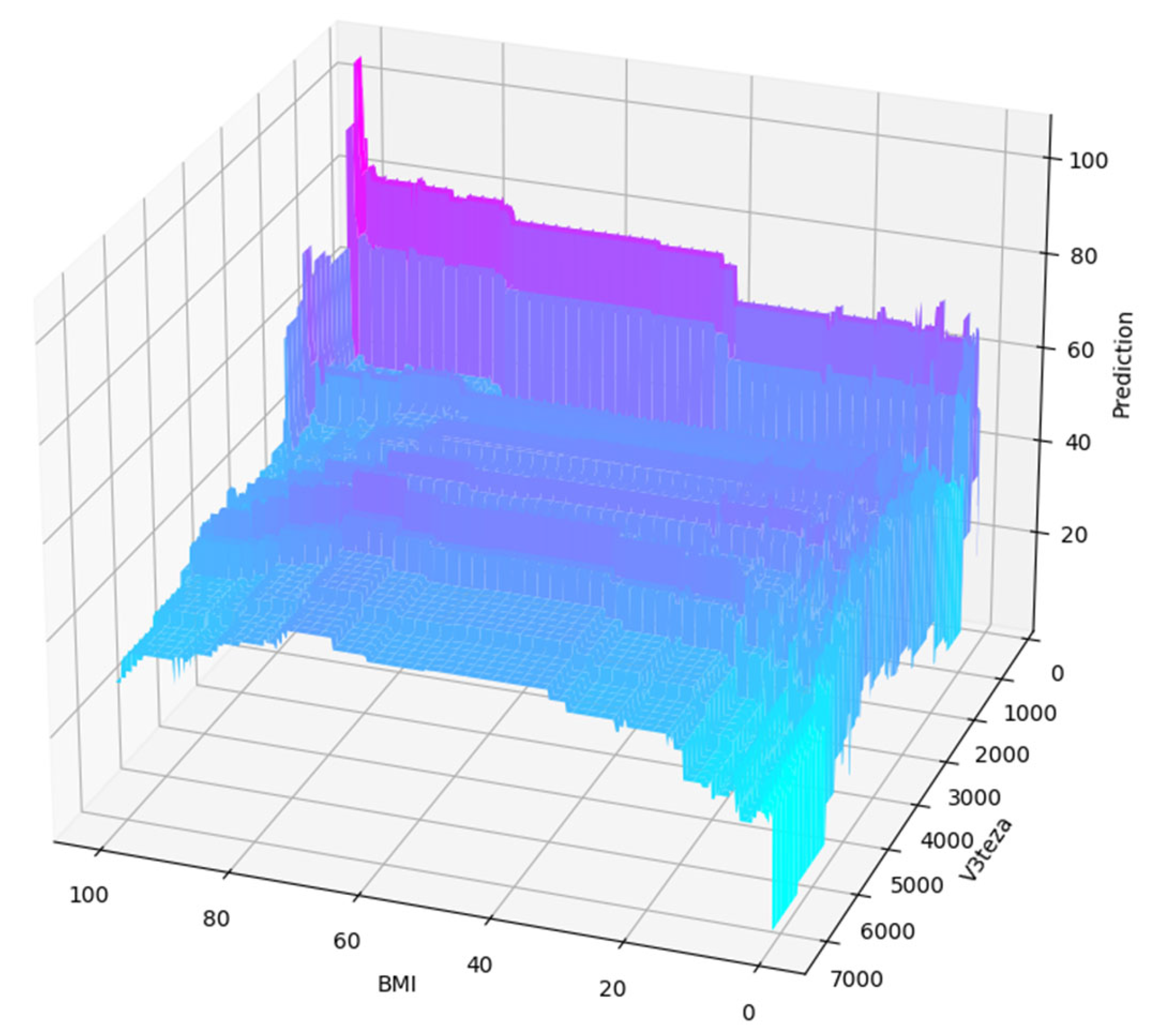
3.2. Feature Selection and Evaluation of Selected Features
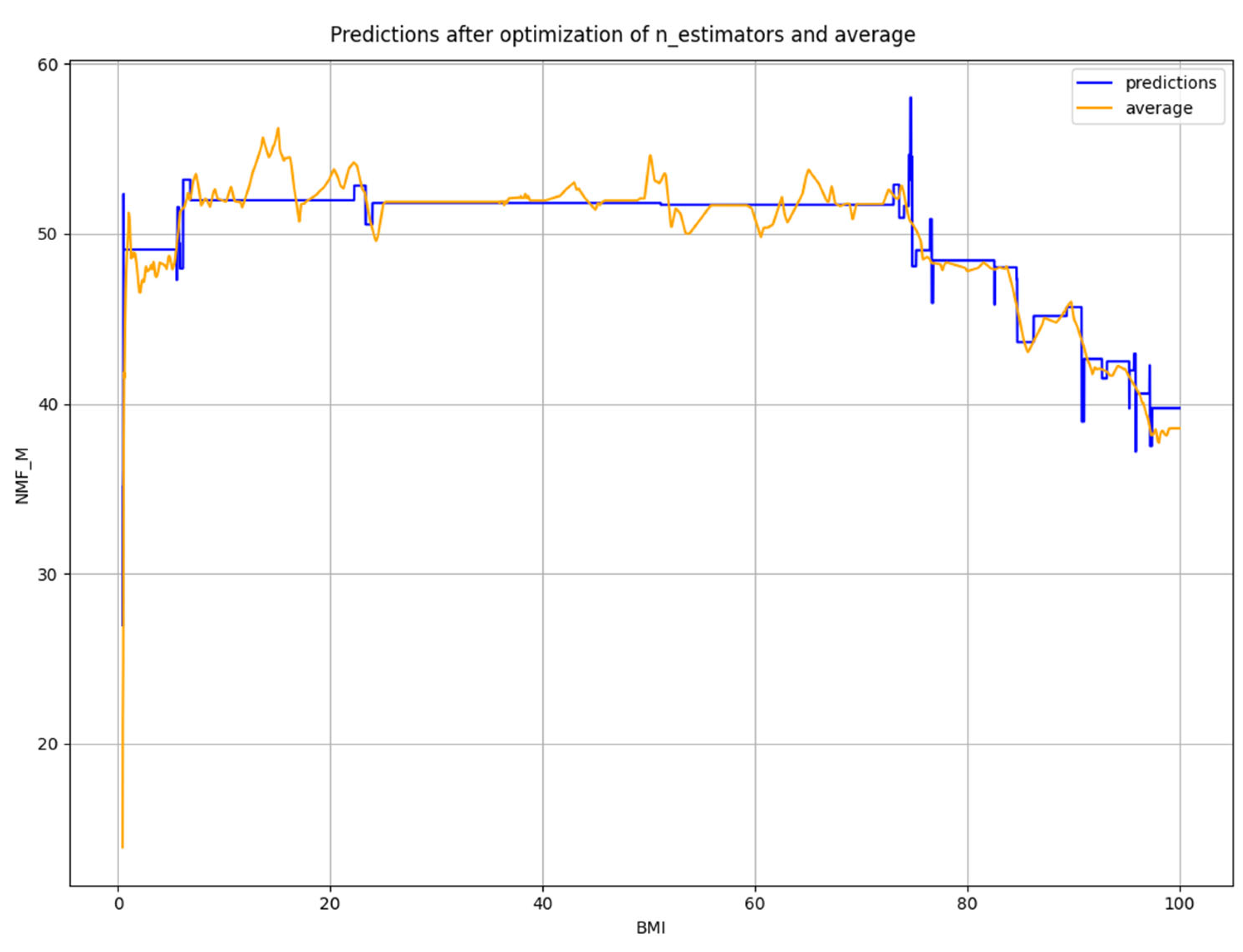
3.3. Tuning by Optimization
3.4. Spearman’s Rank Coefficient as a Source of Feature Importance Information
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wijnstok, N.J.; Hoekstra, T.; Van Mechelen, W.; Kemper, H.C.; Twisk, J.W. Cohort Profile: The Amsterdam Growth and Health Longitudinal Study. Int. J. Epidemiol. 2013, 42, 422–429. [Google Scholar] [CrossRef] [PubMed]
- Starc, G.; Kovač, M.; Strel, J.; Pajek, M. The ACDSi 2014—A decennial study on adolescents’ somatic, motor, psycho-social development and healthy lifestyle: Study protocol. Anthropol. Noteb. 2015, 21, 107–123. [Google Scholar]
- Cole, T.J. Establishing a standard definition for child overweight and obesity worldwide: International survey. BMJ 2000, 320, 1240. [Google Scholar] [CrossRef] [PubMed]
- Cole, T.J.; Flegal, K.M.; Nicholls, D.; Jackson, A.A. Body mass index cut offs to define thinness in children and adolescents: International survey. BMJ 2007, 335, 194. [Google Scholar] [CrossRef] [PubMed]
- Freedman, D.S.; Horlick, M.; Berenson, G.S. A comparison of the Slaughter skinfold-thickness equations and BMI in predicting body fatness and cardiovascular disease risk factor levels in children. Am. J. Clin. Nutr. 2013, 98, 1417–1424. [Google Scholar] [CrossRef] [PubMed]
- Drobnič, F.; Kos, A.; Pustišek, M. On the Interpretability of Machine Learning Models and Experimental Feature Selection in Case of Multicollinear Data. Electronics 2020, 9, 761. [Google Scholar] [CrossRef]
- Reuter, C.P.; da Silva, P.T.; Renner, J.D.P.; de Mello, E.D.; de Moura Valim, A.R.; Pasa, L.; da Silva, R.; Burgos, M.S. Dyslipidemia is Associated with Unfit and Overweight-Obese Children and Adolescents. Arq. Bras. Cardiol. 2016, 106, 188–193. [Google Scholar] [CrossRef] [PubMed]
- Okosun, I.S.; Boltri, J.M.; Lyn, R.; Davis-Smith, M. Continuous Metabolic Syndrome Risk Score, Body Mass Index Percentile, and Leisure Time Physical Activity in American Children. J. Clin. Hypertens. 2010, 12, 636–644. [Google Scholar] [CrossRef] [PubMed]
- DuBose, K.D.; Eisenmann, J.C.; Donnelly, J.E. Aerobic Fitness Attenuates the Metabolic Syndrome Score in Normal-Weight, at-Risk-for-Overweight, and Overweight Children. Pediatrics 2007, 120, e1262–e1268. [Google Scholar] [CrossRef] [PubMed]
- Gutin, B. Diet vs exercise for the prevention of pediatric obesity: The role of exercise. Int. J. Obes. 2011, 35, 29–32. [Google Scholar] [CrossRef] [PubMed]
- Adam, C.; Klissouras, V.; Ravazzolo, M.; Renson, R.; Tuxworth, W.; Kemper, H.C.; van Mechelen, W.; Hlobil, H.; Beunen, G.; Levarlet-Joye, H. EUROFIT—European Test of Physical Fitness, 2nd ed; Council of Europe, Committee for the Development of Sport: Strasbourg, France, 1993. [Google Scholar]
- SLOfit. Available online: https://en.slofit.org/ (accessed on 26 June 2023).
- Praprotnik, M.; Gantar, I.S.; Krivec, U.; Lucovnik, M.; Berlot, J.R.; Starc, G. Physical fitness trajectories from childhood to adolescence in extremely preterm children: A longitudinal cohort study. Pediatr. Pulmonol. 2023, 58, 1904–1911. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 2011, 2825–2830. [Google Scholar]
- Scikit-Learn: Out of Bag Estimates. Available online: https://scikit-learn.org/stable/modules/grid_search.html#out-of-bag-estimates (accessed on 26 June 2023).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2009. [Google Scholar]
- Servén, D.C.; Brummitt, H.A. Hlink, Dswah/pyGAM: v0.8.0; Zenodo: Geneva, Switzerland, 2018. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Andrei, A.; Kendziorski, C. An efficient method for identifying statistical interactors in gene association networks. Biostatistics 2009, 10, 706–718. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Guo, M.; Wang, C.; Liu, X.; Zou, Q. An overview of SNP interactions in genome-wide association studies. Brief. Funct. Genom. 2015, 14, 143–155. [Google Scholar] [CrossRef] [PubMed]
- MWright, N.; Ziegler, A.; König, I.R. Do little interactions get lost in dark random forests? BMC Bioinform. 2016, 17, 145. [Google Scholar] [CrossRef]
- Cordell, H.J. Detecting gene–gene interactions that underlie human diseases. Nat. Rev. Genet. 2009, 10, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Virolainen, S.J.; VonHandorf, A.; Viel, K.C.M.F.; Weirauch, M.T.; Kottyan, L.C. Gene–environment interactions and their impact on human health. Genes Immun. 2022, 24, 1–11. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MEI Component | Feature List | Feature Descriptions |
|---|---|---|
| Neuromuscular Fitness (NMF) | MTAP20 | Arm Plate Tapping |
| MPON | Backwards Obstacle Course | |
| MBOB | 20-s Drumming Test | |
| MFLAM | Flamingo Balance Test | |
| MPRKS | Sit and Reach | |
| MVZI | Bent Arm-hang | |
| Muscular Fitness (MF) | MT30 | 30-m Dash |
| MSDM | Standing Long Jump | |
| MDINAM | Hand Grip | |
| MVZG | Bent Arm-hang | |
| MDT20 | 20-s Sit-ups | |
| Cardiorespiratory Fitness (CRF) | M600Mcas | 600-m Run |
| VO2maxMaharKvadrat | VO2max (by T. Mahar, 2011) |
| Estimator | Best Score | Approx. Learning Time (mm:ss) | Best Hyperparameters | ||
|---|---|---|---|---|---|
| max_features | n_estimators | max_depth | |||
| RFR—M | −42.5296 | 21:12 | 128 | 196 | 49 |
| RFR—F | −42.8821 | 19:56 | 64 | 256 | 49 |
| ETR—M | −42.3239 | 13:09 | 512 | 225 | 49 |
| ETR—F | −42.9873 | 12:30 | 705 | 256 | 36 |
| GBR—M | −1.2543 × 10−24 | 32:38 | 705 | 289 | 49 |
| −0.00016 | 00:06 | 16 | 128 | 16 | |
| GBR—F | −1.3177 × 10−24 | 25:16 | 705 | 289 | 36 |
| −7.4307 × 10−5 | 00:06 | 16 | 128 | 16 | |
| Max_depth | N_estimators | Score (MSE) at the First Step | Most Important Feature |
|---|---|---|---|
| Auto (GFS) = 16 | Auto (GFS) = 128 | −57.8407 | BMI |
| 9 | 225 | −96.3913 | BMI |
| 6 | 225 | −172.6295 | BMI |
| 5 | 225 | −199.7296 | BMI |
| 4 | 225 | −241.0850 | BMI |
| 3 | 225 | −276.6921 | BMI |
| 2 | 10000 | −51.6795 | BMI |
| 2 | 3200 | −133.0671 | BMI |
| 2 | 225 | −304.6900 | BMI |
| 1 | 10000 | −311.9504 | AKGNb |
| 1 | 225 | −329.6298 | AOSG |
| 16 | 100 | −67.9481 | BMI |
| 16 | 50 | −114.7980 | BMI |
| 16 | 25 | −178.4560 | ATT |
| 16 | 12 | −205.6439 | ATT |
| 16 | 6 | −244.0879 | ATT |
| 16 | 3 | −284.1534 | ATT |
| 16 | 2 | −302.2829 | ATT |
| 16 | 1 | −324.9178 | ATT |
| NMF—M | NMF—F | MF—M | MF—F | CVF—M | CVF—F | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature | Value | Feature | Value | Feature | Value | Feature | Value | Feature | Value | Feature | Value |
| AKGBb | −0.1913 | AKGHb | −0.2123 | AKGBb | −0.3305 | AKGHb | −0.2900 | BMI | −0.5327 | BMI | −0.4740 |
| AKGT1b | −0.1783 | AKGGb | −0.2101 | AKGNb | −0.3141 | AKGBb | −0.2886 | AOB | −0.5009 | AKGHb | −0.4438 |
| AKGGb | −0.1757 | AKGBb | −0.1935 | AKGT1b | −0.3020 | AKGNb | −0.2813 | AOSG | −0.4862 | AOPA | −0.4269 |
| AKGNb | −0.1736 | V9M | 0.1826 | AKGHb | −0.3012 | AKGGb | −0.2805 | AOPA | −0.4771 | AOSG | −0.4238 |
| AKGHb | −0.1588 | AKGNb | −0.1821 | AKGGb | −0.2998 | AKGT1b | −0.2396 | AKGT1b | −0.4536 | AOB | −0.4221 |
| Q33 | −0.1459 | AKGT1b | −0.1767 | AOPA | −0.2213 | BMI | −0.2290 | AOG | −0.4515 | AKGGb | −0.4219 |
| AOSG | −0.1457 | AOPA | −0.1628 | BMI | −0.2180 | AOPA | −0.2208 | AKGHb | −0.4501 | AKGBb | −0.4218 |
| SDQII3h | −0.1448 | SDQII4d | 0.1621 | PSDQ3 | 0.2142 | V5 | −0.2142 | AKGGb | −0.4493 | AKGT1b | −0.4196 |
| AOPA | −0.1401 | BMI | −0.1588 | AOSG | −0.2029 | Q33 | −0.2051 | AKGBb | −0.4475 | AKGNb | −0.4174 |
| SDQII4d | 0.1397 | SDQII2l | 0.1566 | AOB | −0.2012 | SDQII4d | 0.1949 | AKGNb | −0.4469 | ATT | −0.4096 |
| AOB | −0.1392 | Q69 | 0.1565 | V5 | −0.2004 | SDQII2l | 0.1924 | ATT | −0.4321 | AOG | −0.3916 |
| AOG | −0.1346 | V9O | 0.1546 | Q33 | −0.1874 | V9M | 0.1921 | AOSS | −0.4184 | AOSS | −0.3773 |
| V5 | −0.1339 | V5 | −0.1465 | Q18 | 0.1814 | AOSG | −0.1921 | AOP | −0.4085 | AOP | −0.3656 |
| BMI | −0.1330 | SDQII6g | −0.1432 | Q29b | 0.1787 | AOB | −0.1721 | V5 | −0.3738 | V5 | −0.3468 |
| Q29b | 0.1304 | SDQII1e | 0.1355 | ASZ | 0.1765 | Q69 | 0.1642 | Q18 | 0.3110 | ASM | −0.2889 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Drobnič, F.; Starc, G.; Jurak, G.; Kos, A.; Pustišek, M. Explained Learning and Hyperparameter Optimization of Ensemble Estimator on the Bio-Psycho-Social Features of Children and Adolescents. Electronics 2023, 12, 4097. https://doi.org/10.3390/electronics12194097
Drobnič F, Starc G, Jurak G, Kos A, Pustišek M. Explained Learning and Hyperparameter Optimization of Ensemble Estimator on the Bio-Psycho-Social Features of Children and Adolescents. Electronics. 2023; 12(19):4097. https://doi.org/10.3390/electronics12194097
Chicago/Turabian StyleDrobnič, Franc, Gregor Starc, Gregor Jurak, Andrej Kos, and Matevž Pustišek. 2023. "Explained Learning and Hyperparameter Optimization of Ensemble Estimator on the Bio-Psycho-Social Features of Children and Adolescents" Electronics 12, no. 19: 4097. https://doi.org/10.3390/electronics12194097
APA StyleDrobnič, F., Starc, G., Jurak, G., Kos, A., & Pustišek, M. (2023). Explained Learning and Hyperparameter Optimization of Ensemble Estimator on the Bio-Psycho-Social Features of Children and Adolescents. Electronics, 12(19), 4097. https://doi.org/10.3390/electronics12194097