
PHNN: A Prompt and Hybrid Neural Network-Based Model for Aspect-Based Sentiment Classification


Abstract
:1. Introduction
- This paper utilizes the prompt technology to convert the input into cloze-type text, making the downstream ABSC task more suitable for the pre-trained model;
- This paper proposes an effective PHNN model, which utilizes RoBERTa to deal with the prompt inputs and then employs a hybrid neural network consisting of GCN, CNN, BiLSTM, and MHA to solve the ABSC task;
- Extensive experiments are conducted, and the results demonstrate that PHNN performs best on SemEval 2014 and Twitter datasets compared with other baseline modules.
2. Related Work
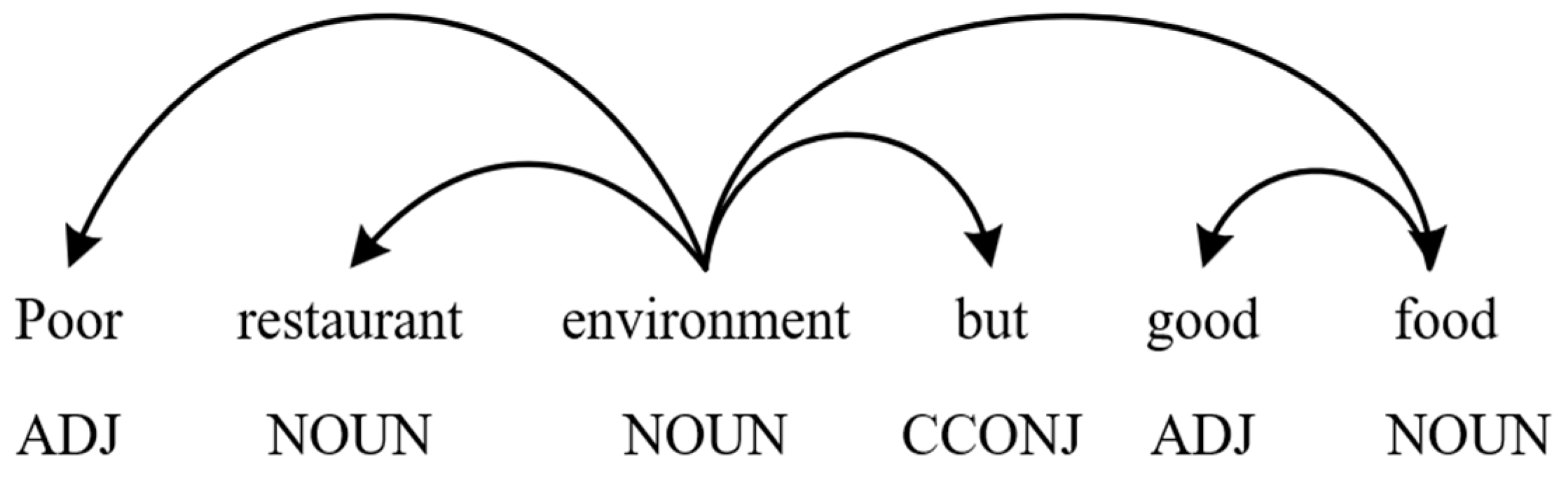
3. Methodology
3.1. Prompt Text Construction Layer
3.2. Syntactic and Semantic Encoding Layer
3.3. Sentiment Classification Layer
3.4. Training
4. Experiments
4.1. Datasets
4.2. Experimental Setting
4.3. Baseline Models
- AOA [28]. It borrows the idea of attention over attention (AOA) to model aspects and sentences, learning the representation of aspect terms and contexts.
- ATAE-LSTM [29]. It combines aspect and contextual word embeddings as the input, using LSTM and attention to process the hidden layer to obtain results.
- TD-LSTM [30]. It uses two LSTM networks to model the text, extending the LSTM for ABSA tasks.
- ASGCN [4]. It utilizes GCN to model the context, using syntactic information and interdependencies between words for ABSA tasks.
- IAN [3]. It uses interactive attention to model the relations between context and aspect words, learning the representation of both for ABSA tasks.
- BERT-SPC [31]. It changes the input of the BERT model to “[CLS] + context + [SEP] + aspect words + [SEP]” for sentence pair classification.
- AEN-BERT [31]. It utilizes a pre-trained BERT model, an attention-based encoder, to obtain results.
- R-GAT [18]. It reconstructs the dependency tree to remove redundant information, extending the original GNN to add a relational attention mechanism.
- R-GAT+BERT [18]. An R-GAT model that is based on pre-trained BERT.
- DualGCN [32]. It is a dual GCN model and utilizes orthogonal and differential regularizer methods to improve the ability of semantic correlations.
- DualGCN+BERT [32]. A DualGCN model that is based on pre-trained BERT.
- SSEGCN [33]. It is a syntactically and semantically enhanced GCN model for ABSA tasks that uses an aspect-aware attention mechanism with self-attention to obtain the attention score matrix of a sentence and enhanced node representations by executing GCN on the attention score matrix.
4.4. Main Results
4.5. Ablation Study
4.6. Case Study
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Model | Restaurant | Laptop | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | ||
| Our PHNN | Negative | 0.8657 | 0.8878 | 0.8766 | 0.6909 | 0.8906 | 0.7782 | 0.7368 | 0.7283 | 0.7326 |
| Netural | 0.8359 | 0.5459 | 0.6605 | 0.7417 | 0.6627 | 0.7000 | 0.7684 | 0.8150 | 0.7910 | |
| Positive | 0.8976 | 0.9753 | 0.9348 | 0.9286 | 0.8768 | 0.9020 | 0.7857 | 0.6994 | 0.7401 | |
| AOA | Negative | 0.6729 | 0.7347 | 0.7024 | 0.5174 | 0.8125 | 0.6322 | 0.5990 | 0.6994 | 0.6453 |
| Netural | 0.6591 | 0.2959 | 0.4085 | 0.6465 | 0.3787 | 0.4776 | 0.6979 | 0.7746 | 0.7342 | |
| Positive | 0.8301 | 0.9327 | 0.8784 | 0.8432 | 0.8358 | 0.8395 | 0.7547 | 0.4624 | 0.5735 | |
| ATAE-LSTM | Negative | 0.6742 | 0.6122 | 0.6417 | 0.4509 | 0.6094 | 0.5183 | 0.6488 | 0.6301 | 0.6393 |
| Netural | 0.6455 | 0.3622 | 0.4641 | 0.5607 | 0.3550 | 0.4348 | 0.7046 | 0.7514 | 0.7273 | |
| Positive | 0.8173 | 0.9341 | 0.8718 | 0.7709 | 0.8094 | 0.7897 | 0.6258 | 0.5607 | 0.5915 | |
| TD-LSTM | Negative | 0.6985 | 0.7092 | 0.7038 | 0.4615 | 0.6094 | 0.5253 | 0.7171 | 0.6301 | 0.6708 |
| Netural | 0.6667 | 0.3163 | 0.4291 | 0.5726 | 0.3964 | 0.4685 | 0.7238 | 0.7572 | 0.7401 | |
| Positive | 0.8213 | 0.9341 | 0.8740 | 0.8267 | 0.8534 | 0.8398 | 0.6573 | 0.6763 | 0.6667 | |
| ASGCN | Negative | 0.6575 | 0.7347 | 0.6940 | 0.5466 | 0.6875 | 0.6090 | 0.6848 | 0.6532 | 0.6686 |
| Netural | 0.6525 | 0.3929 | 0.4904 | 0.7129 | 0.4260 | 0.5333 | 0.7118 | 0.8208 | 0.7624 | |
| Positive | 0.8582 | 0.9231 | 0.8895 | 0.7979 | 0.8798 | 0.8368 | 0.7109 | 0.5260 | 0.6047 | |
| IAN | Negative | 0.6875 | 0.6735 | 0.6804 | 0.4877 | 0.7734 | 0.5982 | 0.6541 | 0.6994 | 0.6760 |
| Netural | 0.6935 | 0.2194 | 0.3333 | 0.6351 | 0.2781 | 0.3868 | 0.7114 | 0.7197 | 0.7155 | |
| Positive | 0.7945 | 0.9451 | 0.8632 | 0.7922 | 0.8387 | 0.8148 | 0.6178 | 0.5607 | 0.5879 | |
| R-GAT | Negative | 0.7539 | 0.7347 | 0.7442 | 0.6069 | 0.6875 | 0.6447 | 0.6936 | 0.6936 | 0.6936 |
| Netural | 0.6049 | 0.5000 | 0.5475 | 0.6972 | 0.4497 | 0.5468 | 0.7620 | 0.7312 | 0.7463 | |
| Positive | 0.8722 | 0.9190 | 0.8950 | 0.7917 | 0.8915 | 0.8386 | 0.6364 | 0.6879 | 0.6611 | |
| DualGCN | Negative | 0.7906 | 0.7704 | 0.7804 | 0.6104 | 0.7344 | 0.6667 | 0.7421 | 0.6982 | 0.7195 |
| Netural | 0.6031 | 0.5969 | 0.6000 | 0.7083 | 0.6108 | 0.6559 | 0.7294 | 0.8423 | 0.7818 | |
| Positive | 0.8951 | 0.9037 | 0.8994 | 0.8593 | 0.8516 | 0.8554 | 0.7462 | 0.5640 | 0.6424 | |
| SSEGCN | Negative | 0.7701 | 0.7347 | 0.7520 | 0.6438 | 0.7344 | 0.6861 | 0.7135 | 0.7219 | 0.7176 |
| Netural | 0.7674 | 0.5051 | 0.6092 | 0.7006 | 0.6587 | 0.6790 | 0.7725 | 0.8185 | 0.7948 | |
| Positive | 0.8643 | 0.9546 | 0.9072 | 0.8815 | 0.8605 | 0.8709 | 0.7467 | 0.6512 | 0.6957 | |
| BERT-SPC | Negative | 0.8287 | 0.7653 | 0.7958 | 0.6353 | 0.8438 | 0.7248 | 0.7112 | 0.7688 | 0.7389 |
| Netural | 0.6825 | 0.6582 | 0.6701 | 0.6846 | 0.6036 | 0.6415 | 0.7915 | 0.7572 | 0.7740 | |
| Positive | 0.9107 | 0.9382 | 0.9242 | 0.9185 | 0.8592 | 0.8879 | 0.7184 | 0.7225 | 0.7205 | |
| AEN-BERT | Negative | 0.7225 | 0.7704 | 0.7457 | 0.7653 | 0.5859 | 0.6637 | 0.6984 | 0.7630 | 0.7293 |
| Netural | 0.6703 | 0.3112 | 0.4251 | 0.6667 | 0.5917 | 0.6270 | 0.7486 | 0.8006 | 0.7737 | |
| Positive | 0.8537 | 0.9615 | 0.9044 | 0.8103 | 0.9267 | 0.8646 | 0.7594 | 0.5838 | 0.6601 | |
| R-GAT+ BERT | Negative | 0.7725 | 0.8316 | 0.8010 | 0.6386 | 0.8281 | 0.7211 | 0.7151 | 0.7399 | 0.7273 |
| Netural | 0.6911 | 0.6735 | 0.6822 | 0.7025 | 0.6568 | 0.6789 | 0.7863 | 0.7977 | 0.7920 | |
| Positive | 0.9262 | 0.9135 | 0.9198 | 0.9172 | 0.8446 | 0.8794 | 0.7346 | 0.6879 | 0.7104 | |
| DualGCN+ BERT | Negative | 0.8168 | 0.7959 | 0.8062 | 0.7462 | 0.7578 | 0.7519 | 0.7396 | 0.7396 | 0.7396 |
| Netural | 0.7616 | 0.5867 | 0.6628 | 0.6630 | 0.7305 | 0.6952 | 0.7590 | 0.8155 | 0.7862 | |
| Positive | 0.8945 | 0.9560 | 0.9242 | 0.9151 | 0.8635 | 0.8885 | 0.7755 | 0.6628 | 0.7147 | |
References
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Yadav, R.K.; Jiao, L.; Goodwin, M.; Granmo, O.-C. Positionless aspect based sentiment analysis using attention mechanism. Knowl. Based Syst. 2021, 226, 107136. [Google Scholar] [CrossRef]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive Attention Networks for Aspect-Level Sentiment Classification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4068–4074. [Google Scholar]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4567–4577. [Google Scholar]
- Huang, B.; Carley, K. Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5468–5476. [Google Scholar]
- Zhao, P.; Hou, L.; Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl. Based Syst. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 255–269. [Google Scholar]
- Fan, C.; Gao, Q.; Du, J.; Gui, L.; Xu, R.; Wong, K.-F. Convolution-based Memory Network for Aspect-based Sentiment Analysis. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1161–1164. [Google Scholar]
- Joshi, A.; Prabhu, A.; Shrivastava, M.; Varma, V. Towards Sub-Word Level Compositions for Sentiment Analysis of Hindi-English Code Mixed Text. In Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2482–2491. [Google Scholar]
- Xu, Q.; Zhu, L.; Dai, T.; Yan, C. Aspect-based sentiment classification with multi-attention network. Neurocomputing 2020, 388, 135–143. [Google Scholar] [CrossRef]
- Zhang, B.; Xiong, D.; Su, J.; Zhang, M. Learning better discourse representation for implicit discourse relation recognition via attention networks. Neurocomputing 2018, 275, 1241–1249. [Google Scholar] [CrossRef]
- Sun, K.; Zhang, R.; Mensah, S.; Mao, Y.; Liu, X. Aspect-Level Sentiment Analysis Via Convolution over Dependency Tree. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5678–5687. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3229–3238. [Google Scholar]
- Sun, C.; Huang, L.; Qiu, X. Utilizing BERT for aspect-based sentiment analysis via constructing auxiliary sentence. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 380–385. [Google Scholar]
- Yin, D.; Meng, T.; Chang, K.-W. SentiBERT: A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3695–3706. [Google Scholar]
- Alexandridis, G.; Korovesis, K.; Varlamis, I.; Tsantilas, P.; Caridakis, G. Emotion detection on Greek social media using Bidirectional Encoder Representations from Transformers. In Proceedings of the 25th Pan-Hellenic Conference on Informatics, Volos, Greece, 26–28 November 2021; pp. 28–32. [Google Scholar]
- Sirisha, U.; Chandana, B.S. Aspect based Sentiment & Emotion Analysis with ROBERTa, LSTM. Int. J. Adv. Comput. Sci. Appl. 2022, 11, 7. [Google Scholar] [CrossRef]
- Li, C.; Gao, F.; Bu, J.; Xu, L.; Chen, X.; Gu, Y.; Shao, Z.; Zheng, Q.; Zhang, N.; Wang, Y.; et al. SentiPrompt: Sentiment Knowledge Enhanced Prompt-Tuning for Aspect-Based Sentiment Analysis. arXiv 2021, arXiv:2109.08306. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 3816–3830. [Google Scholar]
- Hu, S.; Ding, N.; Wang, H.; Liu, Z.; Wang, J.; Li, J.; Wu, W.; Sun, M. Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 2225–2240. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 27–35. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive Recursive Neural Network for Target-dependent Twitter Sentiment Classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MA, USA, 22–27 June 2014; pp. 49–54. [Google Scholar]
- Huang, B.; Ou, Y.; Carley, K.M. Aspect Level Sentiment Classification with Attention-over-Attention Neural Networks. In Proceedings of the 2018 Conference on Social, Cultural, and Behavioral Modeling; Lecture Notes in Computer Science, Washington, DC, USA, 10–13 July 2018; pp. 197–206. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for Aspect-level Sentiment Classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Tang, D.; Qin, B.; Feng, X.; Liu, T. Effective LSTMs for Target-Dependent Sentiment Classification. In Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 3298–3307. [Google Scholar]
- Song, Y.; Wang, J.; Jiang, T.; Liu, Z.; Rao, Y. Attentional Encoder Network for Targeted Sentiment Classification. arXiv 2019, arXiv:1902.09314. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 6319–6329. [Google Scholar]
- Zhang, Z.; Zhou, Z.; Wang, Y. SSEGCN: Syntactic and Semantic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–16 July 2022; pp. 4916–4925. [Google Scholar]


| Dataset | Positive | Neutral | Negative | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| 1561 | 173 | 3127 | 346 | 1560 | 173 | |
| Restaurant | 2164 | 728 | 637 | 196 | 807 | 196 |
| Laptop | 994 | 341 | 464 | 169 | 870 | 128 |
| Model | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| AOA | 78.66 | 66.31 | 71.00 | 64.98 | 67.77 | 65.10 |
| ATAE-LSTM | 77.77 | 65.92 | 64.89 | 58.09 | 67.34 | 65.27 |
| TD-LSTM | 78.66 | 66.90 | 68.34 | 61.12 | 70.52 | 69.25 |
| ASGCN | 79.73 | 69.13 | 72.10 | 65.97 | 70.52 | 67.86 |
| IAN | 77.05 | 62.57 | 67.71 | 59.99 | 67.49 | 65.98 |
| R-GAT | 81.34 | 72.89 | 73.35 | 67.66 | 71.10 | 70.03 |
| DualGCN | 82.66 | 75.99 | 76.42 | 72.60 | 73.56 | 71.46 |
| SSEGCN | 83.74 | 75.61 | 78.16 | 74.53 | 75.18 | 73.60 |
| BERT-SPC | 85.89 | 79.67 | 78.84 | 75.14 | 75.14 | 74.45 |
| AEN-BERT | 81.43 | 69.17 | 76.96 | 71.84 | 73.70 | 72.11 |
| R-GAT+BERT | 85.71 | 80.10 | 79.31 | 74.68 | 75.58 | 74.32 |
| DualGCN+BERT | 86.33 | 79.77 | 80.70 | 77.85 | 75.78 | 74.69 |
| Our PHNN | 88.48 | 82.40 | 82.29 | 79.34 | 76.45 | 75.45 |
| Model | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Accuracy | Macro-F1 | Accuracy | Macro-F1 | Accuracy | Macro-F1 | |
| Our PHNN | 88.48 | 82.40 | 82.29 | 79.34 | 76.45 | 75.45 |
| prompt | 87.50 | 82.02 | 79.31 | 76.65 | 75.26 | 73.41 |
| GCN | 85.22 | 77.86 | 80.72 | 78.04 | 73.99 | 73.09 |
| CNN | 86.23 | 80.54 | 81.35 | 76.96 | 73.55 | 72.57 |
| BiLSTM | 86.25 | 81.62 | 81.50 | 77.98 | 73.28 | 72.42 |
| Sentence | Aspect Words | AEN_BERT | BERT_SPC | ATAE_LSTM | ASGCN | Our PHNN | True Label |
|---|---|---|---|---|---|---|---|
| The portions of the food that came out were mediocre. | portions of the food | ||||||
| The falafel was rather over cooked and dried but the chicken was fine. | falafel | ||||||
| chicken | |||||||
| Great food but the service was dreadful! | food | ||||||
| service | |||||||
| Other than not being a fan of click pads (industry standard these days) and the lousy internal speakers, it’s hard for me to find things about this notebook I don’t like, especially considering the $350 price tag. | click pads | ||||||
| price tag | |||||||
| internal speakers |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Luo, J.; Miao, Y.; Liu, P. PHNN: A Prompt and Hybrid Neural Network-Based Model for Aspect-Based Sentiment Classification. Electronics 2023, 12, 4126. https://doi.org/10.3390/electronics12194126
Zhu W, Luo J, Miao Y, Liu P. PHNN: A Prompt and Hybrid Neural Network-Based Model for Aspect-Based Sentiment Classification. Electronics. 2023; 12(19):4126. https://doi.org/10.3390/electronics12194126
Chicago/Turabian StyleZhu, Wenlong, Jiahao Luo, Yu Miao, and Peilun Liu. 2023. "PHNN: A Prompt and Hybrid Neural Network-Based Model for Aspect-Based Sentiment Classification" Electronics 12, no. 19: 4126. https://doi.org/10.3390/electronics12194126
APA StyleZhu, W., Luo, J., Miao, Y., & Liu, P. (2023). PHNN: A Prompt and Hybrid Neural Network-Based Model for Aspect-Based Sentiment Classification. Electronics, 12(19), 4126. https://doi.org/10.3390/electronics12194126