

Improving the Performance of Cold-Start Recommendation by Fusion of Attention Network and Meta-Learning

Abstract
:1. Introduction
2. Related Work
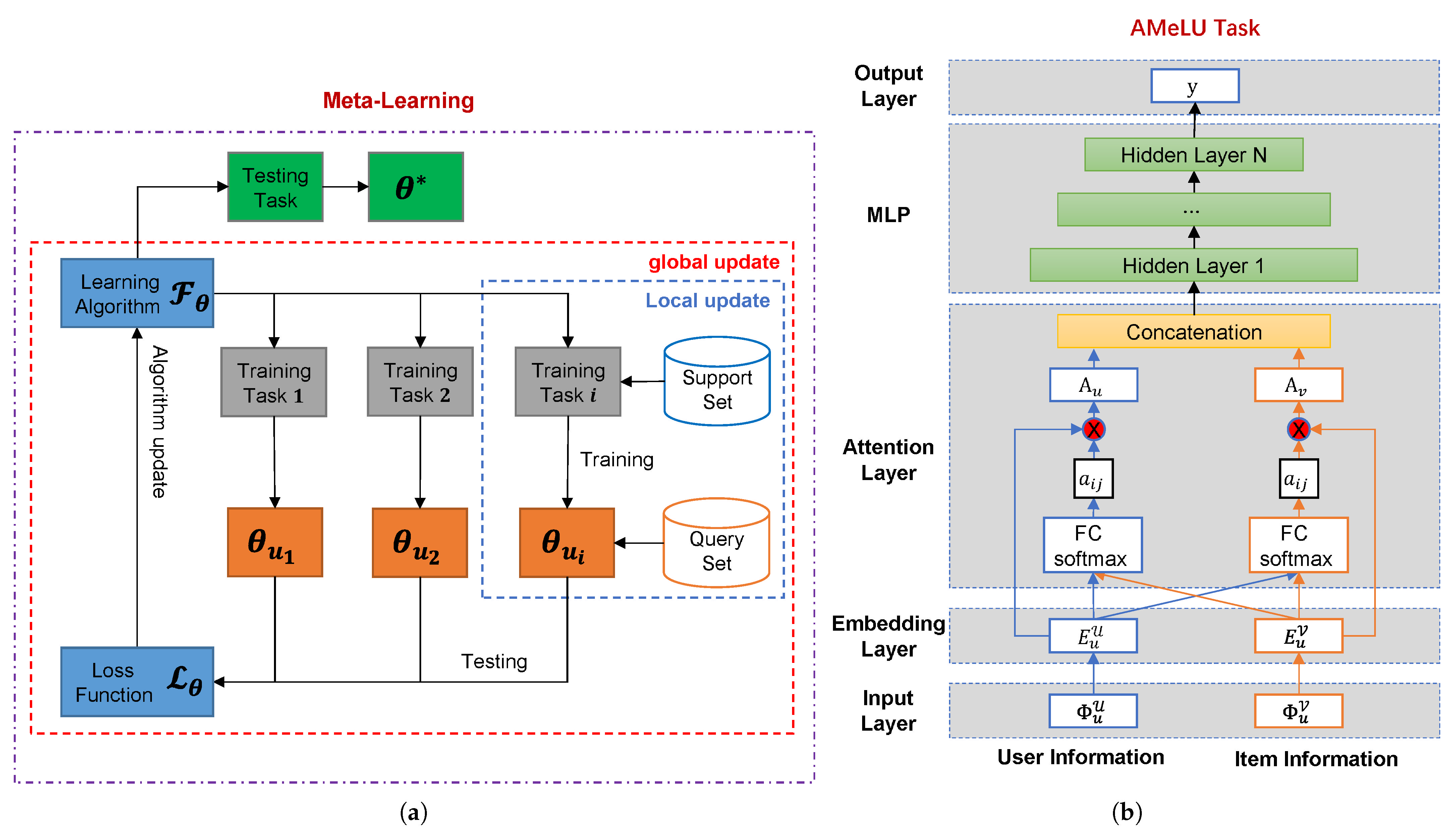
3. Attention Meta-Learning Recommendation Network
| Algorithm 1 MAML for User Preference Estimator |
Input:
|
AMeLU Task
4. Experiments
4.1. Dataset
4.2. Dataset Pre-Processing
4.3. Experimental Settings
4.4. Experimental Results
5. Application
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mooney, R.J.; Roy, L. Content-based book recommending using learning for text categorization. In Proceedings of the Fifth ACM Conference on Digital Libraries, San Antonio, TX, USA, 2–7 June 2000; pp. 195–204. [Google Scholar] [CrossRef]
- Venkatesan, T.; Saravanan, K.; Ramkumar, T. A Big Data Recommendation Engine Framework Based on Local Pattern Analytics Strategy for Mining Multi-Sourced Big Data. J. Inf. Knowl. Manag. 2019, 18, 1950009. [Google Scholar] [CrossRef]
- Nagarajan, R.; Thirunavukarasu, R. A Service Context-Aware QoS Prediction and Recommendation of Cloud Infrastructure Services. Arab. J. Sci. Eng. 2020, 45, 2929–2943. [Google Scholar] [CrossRef]
- Narducci, F.; Basile, P.; Musto, C.; Lops, P.; Caputo, A.; de Gemmis, M.; Iaquinta, L.; Semeraro, G. Concept-based item representations for a cross-lingual content-based recommendation process. Inf. Sci. 2016, 374, 15–31. [Google Scholar] [CrossRef]
- Kouki, P.; Fakhraei, S.; Foulds, J.; Eirinaki, M.; Getoor, L. Hyper: A flexible and extensible probabilistic framework for hybrid recommender systems. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 99–106. [Google Scholar] [CrossRef]
- Bharadhwaj, H. Meta-Learning for User Cold-Start Recommendation. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Mantovani, R.G.; Rossi, A.L.D.; Alcobaca, E.; Vanschoren, J.; de Carvalho, A.C. A meta-learning recommender system for hyperparameter tuning: Predicting when tuning improves SVM classifiers. Inf. Sci. 2019, 501, 193–221. [Google Scholar] [CrossRef] [Green Version]
- Collins, A.; Tkaczyk, D.; Beel, J. One-at-a-time: A Meta-Learning Recommender-System for Recommendation-Algorithm Selection on Micro Level. arXiv 2018, arXiv:1805.12118. [Google Scholar] [CrossRef]
- Huisman, M.; van Rijn, J.N.; Plaat, A. A survey of deep meta-learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Cunha, T.; Soares, C.; de Carvalho, A.C. Metalearning and Recommender Systems: A literature review and empirical study on the algorithm selection problem for Collaborative Filtering. Inf. Sci. 2018, 423, 128–144. [Google Scholar] [CrossRef]
- Zhang, F.; Zhou, Q. A Meta-learning-based Approach for Detecting Profile Injection Attacks in Collaborative Recommender Systems. JCP 2012, 7, 226–234. [Google Scholar] [CrossRef]
- Chen, F.; Luo, M.; Dong, Z.; Li, Z.; He, X. Federated Meta-Learning with Fast Convergence and Efficient Communication. arXiv 2019, arXiv:1802.07876. [Google Scholar] [CrossRef]
- Vilalta, R.; Drissi, Y. A perspective view and survey of meta-learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Lee, H.; Im, J.; Jang, S.; Cho, H.; Chung, S. Melu: Meta-learned user preference estimator for cold-start recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1073–1082. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Wang, H.; Zhao, Y. ML2E: Meta-learning embedding ensemble for cold-start recommendation. IEEE Access 2020, 8, 165757–165768. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar] [CrossRef] [Green Version]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI’17), Melbourne, Australia, 19–25 August 2017; pp. 3119–3125. [Google Scholar]
- Rendle, S. Factorization Machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar] [CrossRef] [Green Version]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar] [CrossRef]
- Zhou, G.; Mou, N.; Fan, Y.; Pi, Q.; Bian, W.; Zhou, C.; Zhu, X.; Gai, K. Deep Interest Evolution Network for Click-Through Rate Prediction. AAAI 2019, 33, 5941–5948. [Google Scholar] [CrossRef] [Green Version]
- Pujahari, A.; Sisodia, D.S. Pair-wise Preference Relation based Probabilistic Matrix Factorization for Collaborative Filtering in Recommender System. Knowl.-Based Syst. 2020, 196, 105798. [Google Scholar] [CrossRef]
- Natarajan, S.; Vairavasundaram, S.; Natarajan, S.; Gandomi, A.H. Resolving data sparsity and cold start problem in collaborative filtering recommender system using Linked Open Data. Expert Syst. Appl. 2020, 149, 113248. [Google Scholar] [CrossRef]
- Feng, J.; Xia, Z.; Feng, X.; Peng, J. RBPR: A hybrid model for the new user cold start problem in recommender systems. Knowl.-Based Syst. 2021, 214, 106732. [Google Scholar] [CrossRef]
- Panagiotakis, C.; Papadakis, H.; Papagrigoriou, A.; Fragopoulou, P. Improving recommender systems via a Dual Training Error based Correction approach. Expert Syst. Appl. 2021, 183, 115386. [Google Scholar] [CrossRef]
- Caron, S.; Bhagat, S. Mixing bandits: A recipe for improved cold-start recommendations in a social network. In Proceedings of the 7th Workshop on Social Network Mining and Analysis (SNAKDD ’13), Chicago, IL, USA, 11–14 August 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1–9. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-Learning with Memory-Augmented Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1842–1850. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few-Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Vartak, M.; Thiagarajan, A.; Miranda, C.; Bratman, J.; Larochelle, H. A Meta-Learning Perspective on Cold-Start Recommendations for Items. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Du, Z.; Wang, X.; Yang, H.; Zhou, J.; Tang, J. Sequential Scenario-Specific Meta Learner for Online Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD’ 19), Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2895–2904. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar] [CrossRef]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. (TIIS) 2015, 5, 1–19. [Google Scholar] [CrossRef]
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th International Conference on World Wide Web, Sydney, Australia, 23–24 December 2005; pp. 22–32. [Google Scholar] [CrossRef]
- Park, S.T.; Chu, W. Pairwise preference regression for cold-start recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 21–28. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Su, Y.; Yin, H.; Zhang, D.; He, J.; Huang, H.; Jiang, X.; Wang, X.; Gong, H.; Li, Z.; et al. An infrastructure with user-centered presentation data model for integrated management of materials data and services. npj Comput. Mater. 2021, 7, 88. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | MovieLens | BookCrossing |
|---|---|---|
| Number of users | 6040 | 278,858 |
| Number of items | 3706 | 271,379 |
| Number of ratings | 1,000,209 | 1,149,780 |
| Sparsity | 95.5316% | 99.9985% |
| User contents | Gender, Age, Occupation, Zip code | Age, Location |
| Item contents | Publication year, Rate, Genre, Director, Actor | Publication year, Author, Publisher |
| Range of ratings | 1∼5 | 1∼10 |
| Type | Method | MovieLens | BookCrossing | ||
|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | ||
| Recommendation of existing items for existing users | PPR | 0.1820 | 0.4756 | 3.8092 | 5.2367 |
| Wide and Deep | 0.9047 | 1.1033 | 1.6206 | 4.0802 | |
| MeLU | 0.7206 | 0.8763 | 1.3003 | 1.5604 | |
| AMeLU | 0.7277 | 0.8822 | 1.2737 | 1.5308 | |
| Recommendation of existing items for new users | PPR | 1.0748 | 1.3421 | 3.8430 | 2.5780 |
| Wide and Deep | 1.0694 | 1.1084 | 2.0457 | 2.6475 | |
| MeLU | 0.7446 | 0.9044 | 1.4621 | 1.7344 | |
| AMeLU | 0.7466 | 0.9039 | 1.2987 | 1.5521 | |
| Recommendation of new items for existing users | PPR | 1.2441 | 1.5600 | 3.6821 | 6.7846 |
| Wide and Deep | 1.2655 | 1.6453 | 2.2648 | 3.8564 | |
| MeLU | 0.9077 | 1.0877 | 1.7214 | 1.9811 | |
| AMeLU | 0.8836 | 1.0595 | 1.4155 | 1.6594 | |
| Recommendation of new items for new users | PPR | 1.2596 | 1.7779 | 3.7046 | 9.8854 |
| Wide and Deep | 1.3114 | 1.9012 | 2.3088 | 7.3998 | |
| MeLU | 0.8951 | 1.0732 | 1.7049 | 1.9696 | |
| AMeLU | 0.8742 | 1.0459 | 1.3959 | 1.6493 | |
| Characteristics | MGE-DATA |
|---|---|
| Number of users | 1452 |
| Number of items | 12,216,221 |
| Number of interactions | 104 |
| Number of search | 164,822 |
| Number of uploads | 12,691,965 |
| Sparsity | 99.9275% |
| User contents | UserID, Institution, Views, MaterialProjectID, MaterialSubjectID |
| Item contents | ItemID, Downloads, Views, Project, Subject, CategoryID, TemplateID |
| User-Item contents | Visit_user, Visit_data_meta_id, Search_params, Views, Upload_records |
| Type | Method | MGE-DATA | |
|---|---|---|---|
| MAE | RMSE | ||
| Recommendation of existing items for existing users | PPR | 0.7497 | 1.3721 |
| Wide and Deep | 0.8034 | 1.4896 | |
| MeLU | 0.7572 | 1.4904 | |
| AMeLU | 0.7549 | 1.4850 | |
| Recommendation of existing items for new users | PPR | 1.4847 | 1.6030 |
| Wide and Deep | 1.4616 | 1.5926 | |
| MeLU | 1.4195 | 1.5298 | |
| AMeLU | 1.4108 | 1.5106 | |
| Recommendation of new items for existing users | PPR | 1.6603 | 1.7170 |
| Wide and Deep | 1.6162 | 1.6986 | |
| MeLU | 1.5491 | 1.6196 | |
| AMeLU | 1.5269 | 1.6118 | |
| Recommendation of new items for new users | PPR | 1.9263 | 2.2658 |
| Wide and Deep | 1.8990 | 2.0936 | |
| MeLU | 1.7742 | 2.0830 | |
| AMeLU | 1.7739 | 2.0783 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Liu, Y.; Zhang, X.; Xu, C.; He, J.; Qi, Y. Improving the Performance of Cold-Start Recommendation by Fusion of Attention Network and Meta-Learning. Electronics 2023, 12, 376. https://doi.org/10.3390/electronics12020376
Liu S, Liu Y, Zhang X, Xu C, He J, Qi Y. Improving the Performance of Cold-Start Recommendation by Fusion of Attention Network and Meta-Learning. Electronics. 2023; 12(2):376. https://doi.org/10.3390/electronics12020376
Chicago/Turabian StyleLiu, Shilong, Yang Liu, Xiaotong Zhang, Cheng Xu, Jie He, and Yue Qi. 2023. "Improving the Performance of Cold-Start Recommendation by Fusion of Attention Network and Meta-Learning" Electronics 12, no. 2: 376. https://doi.org/10.3390/electronics12020376