
Improving the Detection and Positioning of Camouflaged Objects in YOLOv8


Abstract
:1. Introduction
- (1)
- We propose a feature enhancement network. In the feature extraction network, an edge enhancement module was built to alleviate the issue of deep networks being insensitive to edge information. A multi-branch convolution module was introduced to help the model capture local details while also perceiving global contextual information of camouflaged objects.
- (2)
- We introduce a novel non-maximum suppression (NMS) algorithm that combines intersection-over-union and an attenuation function to reduce the detection loss rate of the target.
- (3)
- We present a shape-enhanced data augmentation method specifically designed for camouflaged objects, which effectively improved the model’s perception of shape features in natural camouflaged object datasets.
2. Related Work
2.1. Camouflaged Object Detection (COD)
2.2. Object Detection
2.3. Data Augmentation
3. Materials and Methods
3.1. YOLOv8 Model
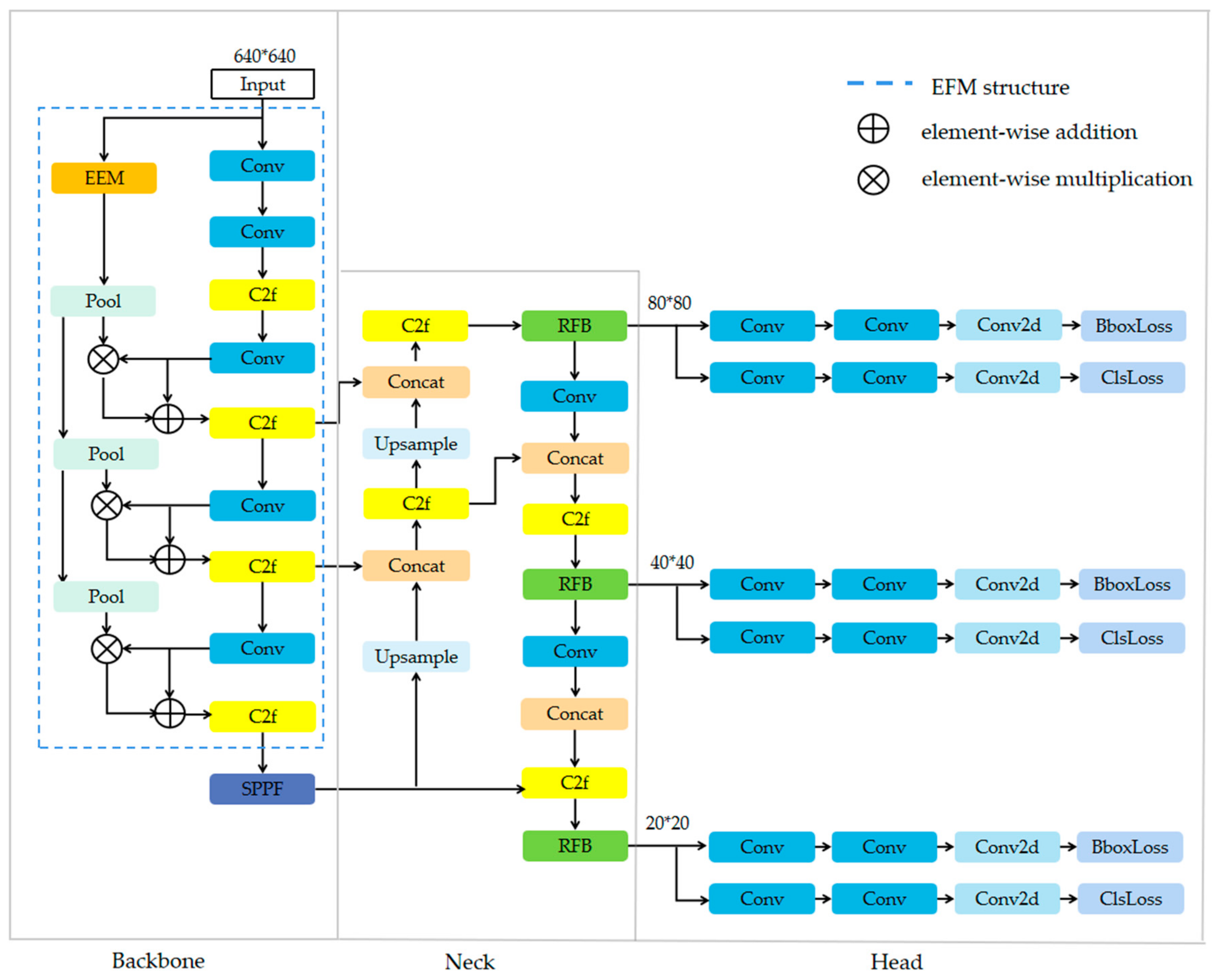
3.2. Improved Network Architecture
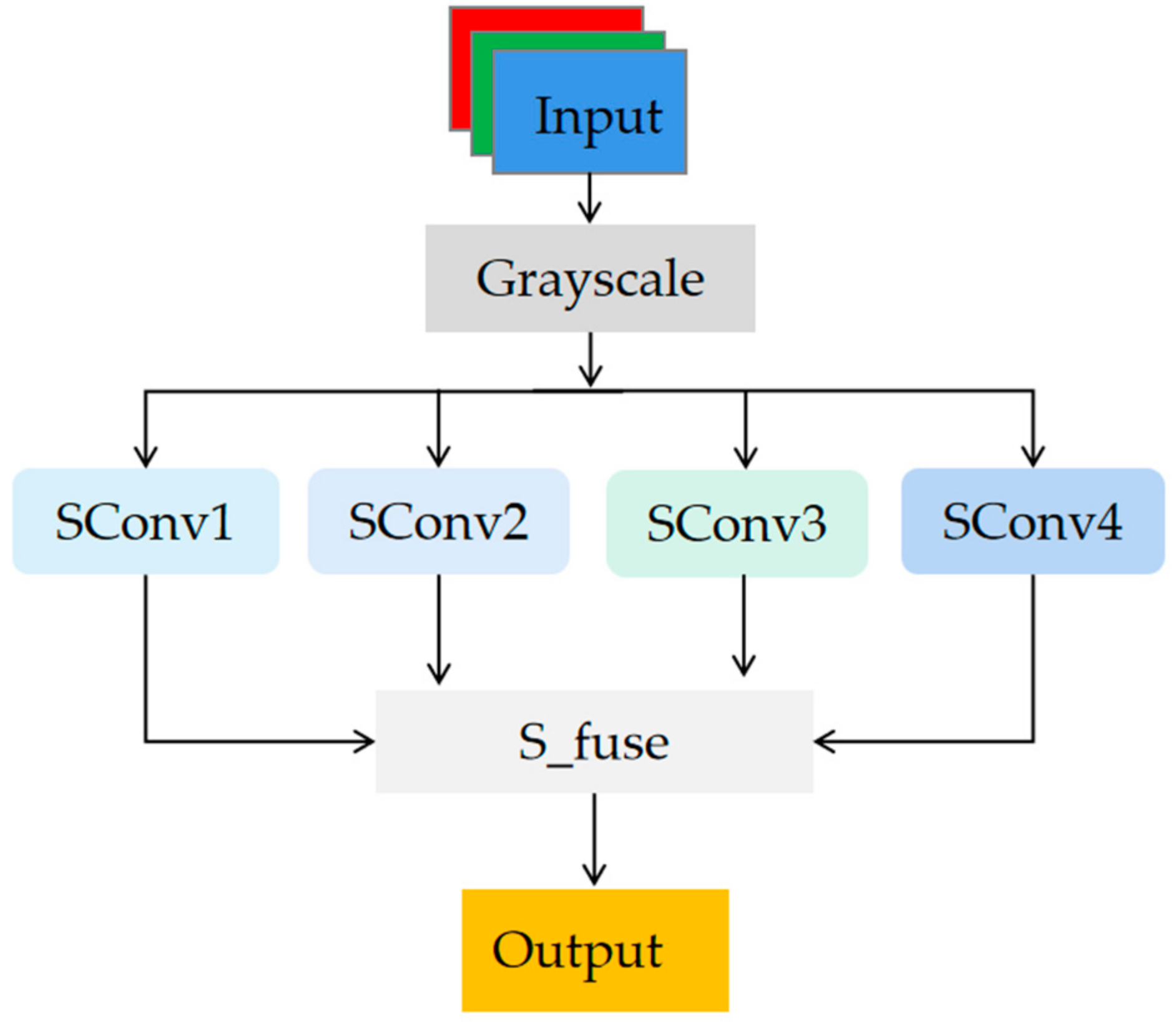
3.2.1. Edge Feature Enhancement Module
3.2.2. Multi-Branch Convolution
3.3. Improved NMS Algorithm
3.4. Shape-Enhanced Data Augmentation Method
| Algorithm 1. SPatch |
| Input: Image , Array E for storing patches, Array P for recording positions, , Amplitude Output: 1. , , 2. , 3. 4. while patch (i, j) ∈ Q 5. 6. 7. While T > 0.96 8. 9. 10. end while 11. end while 12. E = Shuffle (E) 13. while t ∈ E and (i, j) ∈ P do 14. 15. end while 16. return |
4. Experiment
4.1. Setup
4.1.1. Datasets
4.1.2. Evaluation Criteria
4.1.3. Details
4.2. Comparison with the State-of-the-Arts
4.3. Ablation Study
4.3.1. Network
4.3.2. Non-Maximum Suppression Algorithm
4.3.3. Data Augmentation
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M. Camouflaged object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2777–2787. [Google Scholar]
- Qin, X.; Fan, D.P.; Huang, C.; Diagne, C.; Zhang, Z.; Sant’Anna, A.C.; Suarez, A.; Jagersand, M.; Shao, L. Boundary-aware segmentation network for mobile and web applications. arXiv 2021, arXiv:2101.04704. [Google Scholar]
- Zhai, Q.; Li, X.; Yang, F.; Chen, C.; Cheng, H.; Fan, D.P. Mutual graph learning for camouflaged object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 12997–13007. [Google Scholar]
- Li, A.; Zhang, J.; Lv, Y.; Liu, B.; Zhang, T.; Dai, Y. Uncertainty-aware Joint Salient Object and Camouflaged Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10066–10076. [Google Scholar]
- Yan, J.; Le, T.N.; Nguyen, K.D.; Do, T.T.; Nguyen, T.V. Mirrornet: Bio-inspired camouflaged object segmentation. IEEE Access 2021, 9, 43290–43300. [Google Scholar] [CrossRef]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.P. Camouflaged Object Segmentation with Distraction Mining. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8768–8777. [Google Scholar]
- Lin, J.; Tan, X.; Xu, K.; Ma, L.; Lau, R.W. Frequency-aware camouflaged object detection. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–16. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.Q.; He, K.M.; GIRSHICK, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9656–9665. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14449–14458. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2999–3007. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- YOLOv5 Code. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 May 2023).
- Li, C.; Li, L.; Jiang, H. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- YOLOv8 Code. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 August 2023).
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zhang, H.Y.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Goodfellow, I.J.; Pouget-ABADIE, J.; Mirza, M. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. Proc. AAAI Conf. Artif. Intell. 2017, 34, 13001–13008. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Li, X.; Lv, C.; Wang, W.; Li, G.; Yang, L.; Yang, J. Generalized focal loss: Towards efficient representation learning for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3139–3153. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 404–419. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Li, S.; Li, C.; Chen, G.; Bourbakis, N.G.; Lo, K.T. A general quantitative cryptanalysis of permutation-only multimedia ciphers against plaintext attacks. Signal Process. Image Commun. 2008, 23, 212–223. [Google Scholar] [CrossRef]
- Qu, L.; Chen, F.; He, H.Y.Y.; Yuan, Y. Security Analysis of Image Encryption Algorithm Based on Bit Plane-Pixel Block Scrambling. J. Appl. Sci. 2019, 37, 631–642. [Google Scholar]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.-T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da, S.E. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and IMAGE Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Samples | Category | Training Samples | Testing Samples |
|---|---|---|---|---|
| COD10K | 5050 | Cam/Background | 4035 | 1015 |
| CAMO | 1250 | Cam/Background | 1000 | 250 |
| Model | Year | COD10K | CAMO | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|
| Faster R-CNN | NeurIPS2015 | 0.579 | 0.50 | 41.8 | 270 | 20 |
| RetinaNet | ICCV2017 | 0.55 | 0.465 | 32.2 | 254 | 23 |
| RepPoints | ICCV2019 | 0.628 | 0.523 | 35.6 | 152 | 19 |
| YOLOv5s | 2020 | 0.576 | 0.511 | 7.2 | 15.8 | 136 |
| Sparse R-CNN | CVPR2021 | 0.705 | 0.617 | 98.2 | 128.2 | 23 |
| YOLOv6s | 2022 | 0.614 | 0.533 | 16.4 | 44.7 | 104 |
| YOLOv7 | 2022 | 0.628 | 0.579 | 37.2 | 103.1 | 72 |
| DINO | ICLR2023 | 0.667 | 0.596 | 45.1 | 238 | 24 |
| YOLOv8s | 2023 | 0.622 | 0.549 | 11.2 | 28.8 | 108 |
| Ours | 0.705 | 0.64 | 13.1 | 32.3 | 75 |
| EC-Net | E-Soft-NMS | SPatch | COD10K | CAMO | |
|---|---|---|---|---|---|
| RFB | EFM | ||||
| 0.622 | 0.549 | ||||
| √ | 0.64 | 0.583 | |||
| √ | 0.637 | 0.565 | |||
| √ | 0.671 | 0.603 | |||
| √ | √ | 0.65 | 0.594 | ||
| √ | √ | 0.682 | 0.617 | ||
| √ | √ | 0.676 | 0.62 | ||
| √ | √ | √ | 0.686 | 0.632 | |
| √ | √ | √ | √ | 0.705 | 0.64 |
| Net | COD10K | CAMO | Params (M) | ||
|---|---|---|---|---|---|
| mAP | r | mAP | r | ||
| YOLOv8s | 0.622 | 0.555 | 0.549 | 0.526 | 11.2 |
| YOLOv8m | 0.668 | 0.61 | 0.571 | 0.568 | 25.9 |
| EC-Net | 0.65 | 0.604 | 0.594 | 0.569 | 13.1 |
| Algorithm | COD10K | CAMO | ||
|---|---|---|---|---|
| mAP | r | mAP | r | |
| NMS | 0.622 | 0.555 | 0.549 | 0.526 |
| EIoU-NMS | 0.644 | 0.571 | 0.578 | 0.534 |
| Soft-NMS | 0.662 | 0.599 | 0.59 | 0.572 |
| E-Soft-NMS | 0.671 | 0.607 | 0.603 | 0.57 |
| Method | COD10K | CAMO |
|---|---|---|
| - | 0.622 | 0.549 |
| SPatch | 0.644 | 0.568 |
| flip | 0.64 | 0.552 |
| rotate | 0.617 | 0.538 |
| crop | 0.63 | 0.534 |
| swap | 0.611 | 0.538 |
| erasing | 0.629 | 0.525 |
| cj | 0.63 | 0.552 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, T.; Cao, T.; Zheng, Y.; Chen, L.; Wang, Y.; Fu, B. Improving the Detection and Positioning of Camouflaged Objects in YOLOv8. Electronics 2023, 12, 4213. https://doi.org/10.3390/electronics12204213
Han T, Cao T, Zheng Y, Chen L, Wang Y, Fu B. Improving the Detection and Positioning of Camouflaged Objects in YOLOv8. Electronics. 2023; 12(20):4213. https://doi.org/10.3390/electronics12204213
Chicago/Turabian StyleHan, Tong, Tieyong Cao, Yunfei Zheng, Lei Chen, Yang Wang, and Bingyang Fu. 2023. "Improving the Detection and Positioning of Camouflaged Objects in YOLOv8" Electronics 12, no. 20: 4213. https://doi.org/10.3390/electronics12204213
APA StyleHan, T., Cao, T., Zheng, Y., Chen, L., Wang, Y., & Fu, B. (2023). Improving the Detection and Positioning of Camouflaged Objects in YOLOv8. Electronics, 12(20), 4213. https://doi.org/10.3390/electronics12204213