Abstract
A recommendation algorithm combined with a knowledge graph enables auxiliary information on items to be obtained by using the knowledge graph to achieve better recommendations. However, the recommendation performance of existing methods relies heavily on the quality of the knowledge graph. Knowledge graphs often contain noise and irrelevant connections between items and entities in the real world. This knowledge graph sparsity and noise significantly amplifies the noise effects and hinders the accurate representation of user preferences. In response to these problems, an improved collaborative recommendation model is proposed which integrates knowledge embedding and graph contrastive learning. Specifically, we propose a knowledge contrastive learning scheme to mitigate noise within the knowledge graph during information aggregation, thereby enhancing the embedding quality of items. Simultaneously, to tackle the issue of insufficient user-side information in the knowledge graph, graph convolutional neural networks are utilized to propagate knowledge graph information from the item side to the user side, thereby enhancing the personalization capability of the recommendation system. Additionally, to resolve the over-smoothing issue in graph convolutional networks, a residual structure is employed to establish the message propagation network between adjacent layers of the same node, which expands the information propagation path. Experimental results on the Amazon-book and Yelp2018 public datasets demonstrate that the proposed model outperforms the best baseline models by 11.4% and 11.6%, respectively, in terms of the Recall@20 evaluation metric. This highlights the method’s efficacy in improving the recommendation accuracy and effectiveness when incorporating knowledge graphs into the recommendation process.
1. Introduction
Recommendation systems are designed to curate and disseminate relevant content to users from an extensive reservoir of accessible information. Traditional recommendation algorithms encompass various methodologies, including content-based, collaborative-filtering-based, and hybrid recommendation approaches. Among these, the collaborative-filtering-based method has particular significance, as it discerns latent user preferences through a comprehensive analysis of historical user interaction data [,,]. Nonetheless, this approach faces challenges related to cold-start scenarios and data sparsity concerns. In response to these challenges, an increasing number of scholars are dedicating their efforts to the integration of supplementary information into recommendation algorithms with the aim of enhancing their effectiveness. This supplementary information encompasses various aspects, such as user social interactions [], user profiles, and item attributes.
In recent years, knowledge graphs have emerged as a promising avenue for augmenting the precision and comprehensibility of recommendation systems. In this context, each node within the knowledge graph corresponds to diverse real-world entities, with interconnections between these entities signifying relational associations. This framework enables the mapping of items and their pertinent attributes onto the knowledge graph, thus illustrating inter-entity relationships. The recommendation algorithm, grounded in the knowledge graph paradigm, establishes connections between item relationships and user-item associations. This approach mitigates concerns related to data sparsity by harnessing semantic insights embedded within the knowledge graph, ultimately ameliorating the performance of recommendation systems.
Existing methodologies for knowledge-graph-based recommendations can be broadly categorized into three delineations: those reliant on conventional embeddings, those rooted in path analysis, and those founded upon information propagation strategies []. Traditional embedding-centric recommendation techniques [,] primarily employ knowledge graph embedding (KGE) methodologies, such as TransE [], TransR [], and TransH [], to pretrain embeddings for entities within the knowledge graph. These acquired node representations subsequently find application in downstream recommendation tasks. While embedding-centric approaches leverage the knowledge graph to provide supplementary information for recommendation systems, they predominantly focus on the acquisition of direct entity embeddings, potentially overlooking the intricate recommendation relationships between items. As a result, they are better suited for tasks such as link prediction.
In contrast, path-oriented methodologies [,,,] facilitate recommendation systems by revealing diverse association relationships inherent in the knowledge graph’s entity structure. However, these methods exhibit a notable dependence on the formulation of meta-paths, which tend to be context-specific. For example, a meta-path deemed suitable for news recommendations may prove unsuitable for movie recommendations. Furthermore, formulating these meta-paths requires domain-specific expertise, thereby diminishing their practicality.
Conversely, propagation-based strategies [,] enhance the feature representations of multi-hop entities through the iterative propagation of node attributes within the knowledge graph. For instance, RippleNet [] designates users’ historical interactions with items as seed nodes within the knowledge graph and propagates their feature information along the graph’s interconnected relationships. Conversely, KGCN [] employs graph convolutional neural networks to aggregate information from neighboring nodes within the knowledge graph, resulting in the derivation of item embeddings. These methods, by conducting neural network computations on the graph topology, exploit the interconnections between nodes to enrich feature representations, thereby elevating the performance of recommendation systems.
Despite the effectiveness of propagation-based methods in utilizing the structural information of knowledge graphs and capturing richer association relationships through node propagation, three key issues remain to be addressed. Firstly, existing methods tend to overlook the impact of noise in the knowledge graph on recommendation performance. Secondly, existing models tend to heavily emphasize embedding learning for the item side while neglecting semantic information propagation from the user side, leading to an information imbalance between the user and item sides. Finally, most of the existing models encounter the issue of over-smoothing, whereby, as the network layers increase, the node representations progressively converge, sometimes even becoming identical. This results in a reduction in distinctiveness among nodes.
To address these challenges, we propose an enhanced collaborative recommendation model that integrates knowledge embedding and graph contrastive learning, which we term IKEGCL. IKEGCL introduces a knowledge graph augmentation scheme and incorporates graph contrastive learning to mitigate noise during information aggregation, resulting in more robust representations of item knowledge awareness. The model leverages relation-aware attention networks to extract context information from the knowledge graph and employs graph convolutional neural networks to capture collaborative information from the bipartite graph. Additionally, the model incorporates residual structures to mitigate the over-smoothing problem, thereby enhancing the expressive power and performance of the recommendation system.
The contributions of this work are as follows:
- This work introduces the idea of combining knowledge graph learning with user-item interaction modeling under a joint self-supervised learning paradigm to enhance the robustness of recommendations and alleviate data noise and sparsity issues.
- To address the over-smoothing problem in graph convolutional networks, this paper introduces residual structures. By establishing residual connections between graph convolutional layers, the over-smoothing of node representations is effectively alleviated, improving the recommendation system’s modeling capability for item features.
- Extensive experiments on two public datasets demonstrate that the proposed recommendation model outperforms state-of-the-art models, showcasing the effectiveness and superiority of the proposed approach.
The structure of this article is as follows: In Section 1, the exposition commences by providing an introduction to the contextual background of the research subject matter, supported by an elucidation of its significance. Section 2 introduces the basic framework of graph convolutional neural networks and the graph contrastive learning framework used in this article. The following Section 3 is dedicated to a comprehensive presentation of our novel recommendation model. Subsequently, in Section 4, we conduct a thorough examination of the experimental results and perform comparative analyses. Finally, in Section 5, we provide the conclusions of the article.
2. Preliminaries
In a classical knowledge-graph-based recommendation task [], two types of graph data are involved: the user-item interaction matrix and the knowledge graph . Let represent the set of users, and represent the set of items. The user-item interaction matrix is denoted as , where indicates that there exists a historical interaction record between user u (representing any element from the user set ) and item i (representing any element from the item set ), such as watching, clicking, or collecting. Conversely, = 0 indicates no interaction record. The knowledge graph is defined as , where h, r, and t represent the head entity, relation, and tail entity in the knowledge graph triplet, respectively. E is the entity set of the knowledge graph, and R is the relationship set of the knowledge map. It is important to note that the item set I in the user-item interaction graph should be a subset of the entity set E in the knowledge graph, i.e., . This allows us to model the complex relationships between items and entities in the knowledge graph.
Based on the above definitions, we can formalize the knowledge-graph-based recommendation task as follows: Given a user-item interaction graph and the knowledge graph . Our objective is to learn a recommendation model denoted as , where M represents a model architecture with learnable parameters, . The model’s output, denoted as , represents the probability of interaction between user u and item i.
Before examining our proposed model, it is imperative to provide an elucidation of the graph contrastive learning framework that will serve as the foundation for our approach. Graph contrastive learning is instrumental in advancing the acquisition of node-embedding representations by discerning distinctions between positive and negative samples. A seminal instantiation of the graph contrastive learning framework is exemplified by DGI [], which incorporates the principles of Infomax [] into network representation learning to optimize node representation learning through the juxtaposition of local and global information.
The prevailing graph contrastive learning frameworks [,,,] are graphically illustrated in Figure 1. Initially, in the context of comprehensive graph data, we enhance the structural integrity of the graph data by perturbing the graph through random disruption, executing random walks, and introducing stochastic noise. This process culminates in the creation of two distinct subgraphs. Subsequently, we independently encode these two subgraphs, thereby yielding two sets of dissimilar node embeddings. These embeddings are then subjected to the InfoNCE (noise contrastive estimation) method, which facilitates the computation of the contrastive learning loss between the two sets of node embeddings. This computed loss is subsequently applied to downstream tasks.
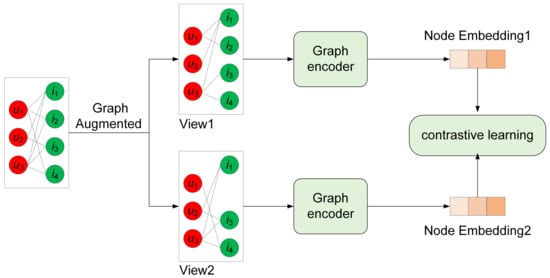
Figure 1.
Graph contrastive learning framework.
3. Methodology
Knowledge graph embedding: utilizing graph attention mechanisms to aggregate high-order connectivity information from the knowledge graph; Bipartite graph embedding: utilizing graph convolutional neural networks to capture high-order collaborative information between users and items based on their historical interactions; Multi-view contrastive learning: employing a random edge removal mechanism on both the knowledge graph and the user-item bipartite graph to generate two sets of subgraphs. The final representations of nodes are obtained by optimizing the node embedding representations based on the contrastive differences in different views. The framework of the IKEGCL model is depicted in Figure 2.
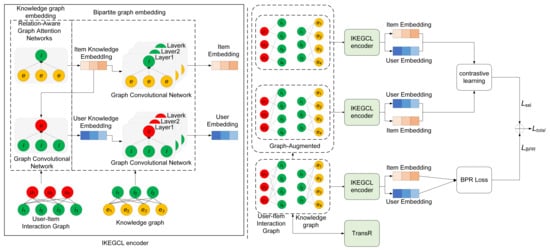
Figure 2.
Simplified diagram of IKEGCL model.
3.1. Knowledge Graph Embedding Layer
In contrast to previous methodologies that amalgamate the knowledge graph with the user-item interaction graph to create a collaborative knowledge graph (CKG), this investigation pursues an alternative approach. Initially, it involves conducting embedding learning specifically for the item nodes within the knowledge graph. Subsequently, by capitalizing on the relational interconnections within the user-item interaction graph, the acquired knowledge graph information stemming from the item nodes is disseminated to the user nodes. This method facilitates indirect access for user nodes to the knowledge-graph-derived information, thereby enhancing the efficacy of collaborative recommendation. Inspired by the principles underpinning graph attention networks (GAT) [] and knowledge graph attention networks (KGAT) [], this research introduces a knowledge graph attention graph encoder that is sensitive to relational attributes for embedding the item nodes. The fundamental concept revolves around the aggregation of information from neighboring nodes e for each item node i within the knowledge graph, employing a judiciously biased attention mechanism. The specific aggregation formula is explicated as follows:
where and represent the embedding vectors to be learned for item i and entity e, respectively. As the knowledge graph is unweighted, we introduce a calculation of the propagation weight from entity e to item i. Its computation is as follows:
where r represents the relationship between item i and entity e, and . By introducing the propagation weight, the model can effectively guide the aggregation of important neighboring node information, thereby enhancing the model’s interpretability. The introduction of a propagation weight allows the model to focus more on entities e that are relevant to item i and have significant relationships.
After completing the knowledge embedding for the item side, we utilize a graph convolutional neural network (GCN) to propagate the information from the knowledge graph to the user nodes. The propagation process is as follows:
where and represent the embedding of user x and item i, respectively. Nu represents the set of neighboring nodes of user u in the user–item interaction graph.
In order to enhance the multi-semantic representation learning between entities and items, this research adopts the TransR [] model, which embeds entities and their relationships from the knowledge graph into continuous vector spaces. The core idea of TransR is to improve representation learning by making the sum of the vector representations of the head entity and relationship approximate the vector representation of the tail entity, i.e., . Thus, for a given knowledge graph triplet , the confidence score is computed using the formula:
where represents the embedding vector of the head entity h, represents the embedding vector of the relationship r, and represents the embedding vector of the tail entity t. By minimizing the score , the TransR model can learn more semantically enriched representations of entities and relationships, thereby enhancing the multi-semantic expressive capability between entities and items in the knowledge graph.
3.2. Bipartite Graph Embedding
Figure 3 illustrates the embedding process of the bipartite graph embedding layer. In this layer, the output user embedding and item embedding from the knowledge graph embedding layer are used as inputs for the bipartite graph embedding layer.
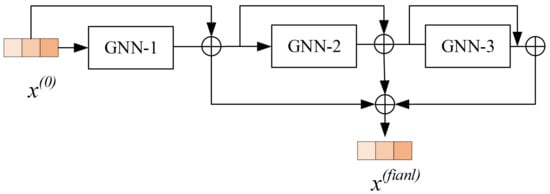
Figure 3.
Bipartite graph embedding layer.
Unlike LightGCN, this paper utilizes residual network connections between different layers; the propagation formulas are shown in Equations (6) and (7):
According to Equation (6), when calculating the user representation vector for the l-th layer, the residual connection within each node is achieved by adding it to the vector from the previous layer. This facilitates message propagation between layers, alleviating the over-smoothing problem in GCN. Finally, all layer embedding vectors are averaged and summed together, with the calculation process as follows:
3.3. Multi-View Contrastive Learning
Unlike most graph contrastive learning models, we integrate the knowledge graph embedding process into the contrastive learning process. Inspired by SGL [], the paper introduces random edge disruptions to the knowledge graph and the user-item interaction graph to obtain two sets of views. Subsequently, the training of the knowledge graph embedding layer and the bipartite graph embedding layer is performed on these two sets of views to obtain two sets of node embedding vectors, denoted as and . For each user or item node, different vector representations can be generated under different views. We consider the representation of the same node in different views as positive samples and the representations of different nodes as negative samples. The contrastive learning loss is calculated as follows:
where , and s represents the similarity function used to calculate the similarity between two node embeddings. In this paper, we use the cosine similarity function to measure the similarity between node embedding vectors. The temperature parameter is used to adjust the sensitivity of the similarity function. Unlike the original InfoNCE, this paper introduces the coefficient in the similarity weight. As positive samples typically exhibit higher similarity, introducing can assign larger weights to positive samples, thereby facilitating the contrastive learning process. By minimizing the loss function we can reduce the differences between representations of the same node under different views.
The final predicted score of user u for item i is given by:
3.4. Model Optimization
In the learning process of IKEGCL, we combine the widely used BPR-pairwise loss function in recommendation systems with the previously mentioned contrastive learning loss function. The computation of the BPR-pairwise loss is given by the formula:
In the equation, represents a negative sample, i.e., an item that the user u has not interacted with. represents the likelihood of establishing a connection between user u and item i, represents the sigmoid function.
To optimize both the contrastive loss and the BPR loss, we employ a joint learning approach with the following overall loss function:
4. Experiment Analysis
4.1. Experimental Datasets
To evaluate the recommendation performance of IKEGCL, we conducted experiments on two public datasets, Amazon-Book and Yelp2018. The Amazon-Book dataset is a widely used book recommendation dataset, and the Yelp2018 dataset is taken from the 2018 Yelp Challenge. In this dataset, we consider local business items, such as hotels and restaurants, as items. To ensure data quality, we removed users and items with fewer than 10 interactions. For the Amazon-book dataset, we adopt the method in [] to build a knowledge graph by linking items and Freebase entities through title matching. For Yelp2018, we adopt the method in [] to build a knowledge graph to extract item knowledge (e.g., category, location, and attributes) from the local business information network. For each dataset, we randomly selected 80% of the data as the training set and 20% as the test set for model training and evaluation. Table 1 presents the statistical attributes of the aforementioned pair of datasets.

Table 1.
Experimental dataset statistics.
4.2. Parameter Settings
The proposed IKEGCL model and all comparison models are implemented using PyTorch. To ensure fairness, the batch size of all models is set to 2048, and the Adam optimizer is used to optimize all models. Following [], we set the embedding size to 64. We employed an early stopping strategy, where training was stopped if the Recall@20 metric did not improve for 10 consecutive epochs. The hyperparameters and were tuned within the range of [0.1,1], and the graph convolutional layers k was tuned within the range of [1,8].
4.3. Evaluation Protocols
In the experiments, to evaluate the model’s performance in the top-K recommendation scenario, this paper utilized two commonly used evaluation metrics, and , where K is set to 20, as is common in previous recommendation models. These metrics are widely used to assess the model’s ability to recommend the most relevant items to users in the top 20 positions.
Recall calculates the recall rate, which represents the proportion of relevant items that are included in the top-K recommended results generated by the model. It is defined as follows:
represents the set of recommended items for user u predicted by the model. represents the set of items that are present in the test set and are relevant for user u (i.e., items that the user has interacted with or rated in the test set).
(The normalized discounted cumulative gain) is a metric used to measure the quality of the ranking of recommended items. is defined as follows:
normalizes the score by dividing it by the score, ensuring that the metric lies between 0 and 1. A higher value indicates a better ranking quality of the top-K recommendations, reflecting the model’s ability to rank relevant items higher in the recommendation list.
4.4. Baselines for Comparison
To evaluate the performance of IKEGCL in the recommendation task, it was compared with the following seven models:
- NCF []: A general recommendation framework that utilizes the multi-layer perceptron (MLP) to model non-linear feature interactions in collaborative filtering.
- LightGCN []: A recommendation model based on a simplified graph convolutional neural network (GCN), which removes feature transformation and non-linear activation functions from the NGCF model.
- KGCN []: A collaborative recommendation model based on a graph convolutional neural network, which leverages high-order dependencies in the knowledge graph to mine users’ latent features.
- KGAT []: A knowledge-graph-based recommendation model based on the graph attention network (GAT), which explicitly models high-order relationships in the graph attention network framework in an end-to-end manner.
- KGIN []: A knowledge-graph-based recommendation model that models user intent using attention to the semantic information of the knowledge graph, thereby improving the interpretability of the recommendation model.
- MVIN []: A multi-view knowledge-graph-based recommendation model that learns representations of the same item from unique and mixed views of users and entities for better item recommendations.
- SGL []: A contrastive-learning-based collaborative filtering recommendation model that achieves data augmentation through dropout on nodes and edges, thereby enhancing the recommendation performance of the model.
4.5. Overall Performance Comparison
Table 2 presents the experimental results of IKEGCL on the two publicly available datasets, where Imprv. denotes the improvement ratio of IKEGCL relative to the best-performing comparative model on the two metrics.
Table 2.
Performance comparison between IKEGCL and comparative models. Bold represents the best results, while underline represents the second-best results.
Based on the experimental results, it can be observed that most knowledge-graph-based models outperform collaborative filtering methods, indicating that incorporating knowledge graphs into recommendation systems can effectively enhance the model’s recommendation performance. Among them, the KGIN model performs better than other knowledge-graph-based recommendation methods. KGIN incorporates user intent into the knowledge graph embedding, improving the quality of user node representations while mining latent user intents. Additionally, SGL performs the best among the baseline models, demonstrating the effectiveness of data augmentation through dropout on the graph structure and highlighting the superiority of graph contrastive learning in enhancing the model’s recommendation performance.
Furthermore, the proposed IKEGCL model outperforms other baseline models on both datasets. Specifically, compared to the best-performing comparative model SGL, IKEGCL achieves an 11.4% and 10.3% improvement in and , respectively, on the Yelp2018 dataset. On the Amazon-Book dataset, IKEGCL achieves an 11.6% and 11.4% improvement in and , respectively, over SGL. This is mainly attributed to the following factors: First, IKEGCL combines knowledge graph embedding and bipartite graph embedding to alleviate data sparsity and cold-start issues in collaborative filtering. Second, IKEGCL introduces the graph contrastive learning mechanism into the knowledge graph embedding process to mitigate the impact of noise in the knowledge graph on recommendation performance. Lastly, IKEGCL utilizes residual network connections between different layers to address the issue of declining recommendation performance caused by increasing the depth of GCN layers.
Overall, the experimental results demonstrate that the IKEGCL model achieves significant performance improvement by integrating knowledge graphs and contrastive learning, enabling the recommendation model to better handle complex data and provide more accurate recommendations.
4.6. Model Parameter Analysis
In the recommendation model, KCLC, proposed in this paper, the number of convolution layers k, the temperature parameter , and the weight of the contrastive learning loss in the bipartite graph are three important hyperparameters. To analyze their impact on the model’s performance, sensitivity analysis experiments were conducted, and the results are shown in Figure 4, Figure 5 and Figure 6.
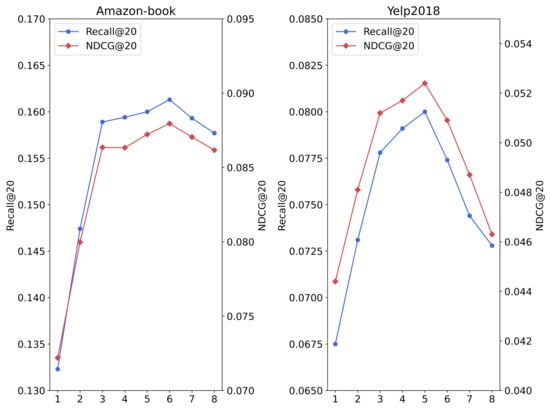
Figure 4.
The influence of the number of graph convolutional layers k on the experimental results.
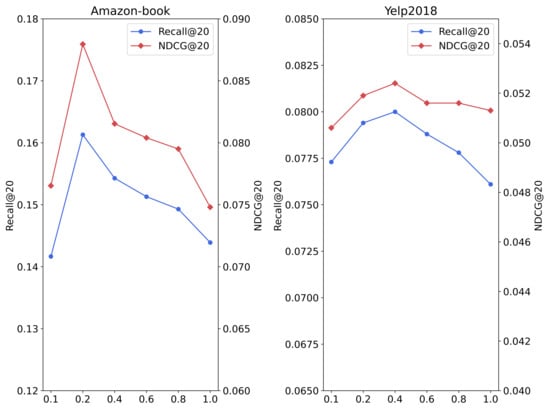
Figure 5.
Temperature parameters impact on the experimental results.
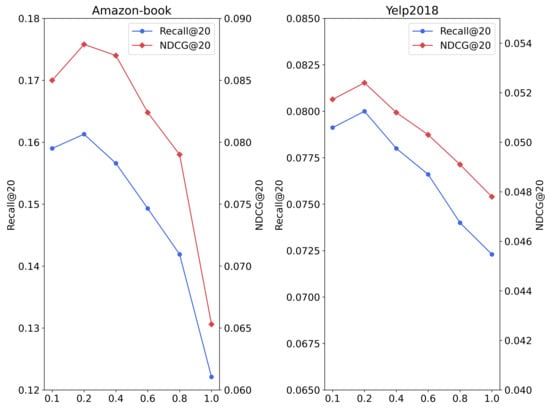
Figure 6.
impact on the experimental results.
From Figure 5, it can be found that when the number of graph convolutional layers k is set to 6 and 5, respectively, the model recommendation performance of IKEGCL reaches the highest, while most of the recommendation models based on GCN reach their best at 3 layers, which shows that IKEGCLN can alleviate the over-smoothing problem to a certain extent, which makes our model better able to aggregate the information of higher-order neighbor nodes, thereby improving the recommendation performance.
The temperature parameter in the model plays a role in adjusting the attention to negative samples. Figure 5 shows that when the temperature parameter is set to a larger value, the model pays less attention to negative samples, while setting to a smaller value results in less attention to negative samples. It can be seen from the figure that the model achieves the best performance when is set to 0.2 and 0.4, respectively.
The weight of the contrastive learning loss in the model controls the impact of the contrastive learning loss on the main space loss function. Figure 6 shows that the model achieves the best performance when is set to 0.2. Excessively large loss weights may cause the model to be biased in the recommendation task. Models may pay too much attention to the differences between individual positive and negative samples, resulting in unbalanced or inaccurate recommendations.
4.7. Analysis of Ablation Experiments
To analyze the performance of each component in IKECCL and verify the impact of knowledge graph contrastive learning, the KGE module, and the residual network on recommendation performance, we conducted comparative experiments with the following variant models:
- v1: Removing the knowledge graph contrastive learning process in IKEGCL.
- v2: Removing the residual network from the bipartite graph embedding process in IKEGCL.
- v3: Removing the TransR process in IKEGCL.
- v4: Removing the positive sample weights in contrastive learning.
From Table 3, it can be found that the original model outperforms all variant models. Although V1 utilizes the contextual relationship in the knowledge graph, the model is more susceptible to the noise of the knowledge graph due to the removal of the knowledge graph contrast learning module. V2 removes the residual structure, which makes it impossible to establish a message propagation link between adjacent layers of the same node, resulting in a decline in recommendation performance. V3 removed the KGE module, which caused the model to fail to model the representation correlation of knowledge graph triples, resulting in a decline in recommendation performance. The experimental results of the V4 variant model show that adding positive sample weights in the comparison experiment can help improve the recommendation.
Table 3.
Results of the ablation experiment. Bold represents the best results.
4.8. Experimental Analysis of Knowledge Graph Noise
To validate the impact of ineffective noise in the knowledge graph on the model’s recommendation performance, this study conducted experiments inspired by the SGL method. In both knowledge graphs, 10% random noise was added, meaning 10% of random triplets were added to the knowledge graph. The experimental results are shown in Table 4. From the table, it can be observed that, when facing random noise in the knowledge graph, IKEGCL’s average decay rate is much lower than the other three knowledge-graph-based methods. This indicates that noise in the knowledge graph can significantly affect the performance of knowledge-graph-based recommendation models. By introducing the graph contrastive learning mechanism, we can effectively mitigate the impact of noise in the knowledge graph on the recommendation performance.
Table 4.
Noise experiment results. Bold represents the best results.
4.9. Visualizing the Distribution of Representations
In this paper, one of the key contributions of IKEGCL is integrating the knowledge graph embedding process into the graph contrastive learning framework. To better understand the advantages of this approach, we utilized Gaussian kernel density estimation (KDE) to plot the distribution of project node embeddings learned by the model in a two-dimensional space, as shown in Figure 7.
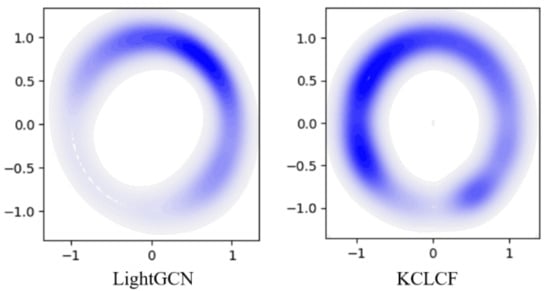
Figure 7.
Visualization of item node embedding vector.
From the graph, it is evident that the project node embeddings learned by IKEGCL exhibit a more uniform distribution, indicating that the model can better capture personalized preferences and characteristics among different nodes. Compared to other methods, it can be observed that the project node embeddings learned by IKEGCL are more scattered in the two-dimensional space, rather than being concentrated in a specific region. This suggests that IKEGCL can better capture the diversity and differences among project nodes, enabling the model to provide more accurate personalized recommendations for different users. Overall, by incorporating the knowledge graph embedding process into the graph contrastive learning framework, IKEGCL can better explore the personalized features of nodes, leading to superior performance in the recommendation task. This personalized modeling of different nodes contributes to improved recommendation performance and enhances the model’s adaptability to diverse and complex recommendation scenarios in the real world.
4.10. Case Analysis
To further analyze the role of knowledge graph embedding in the IKEGCL model, we conducted a comparative experiment to compare the effects of incorporating knowledge graph embedding and not incorporating it on the user’s recommendation list. In the experiment, a user node was randonly selected and generated a recommendation list for the user, with the length of the recommendation list set to five for a better comparison of the differences in the recommendation results. The experimental results are shown in Table 5. Figure 8 shows the local structure of items associated with the user in the knowledge graph. From the table, it can be observed that without knowledge graph embedding, four nodes disappeared from the recommendation list. These nodes were 10,940, 1493, 700, and 500. To further analyze the reason behind this phenomenon, we analyzed the edge relationships in the knowledge graph. It was found that nodes 500, 1493, and 700, which disappeared from the recommendation list, had edge relationships with items that the user had interacted with in the past. From this analysis, it can be inferred that by introducing knowledge graph embedding, these nodes related to items that the user had interacted with in the past can be better incorporated into the recommendation list, thereby improving the model’s recommendation performance.
Table 5.
Case study.
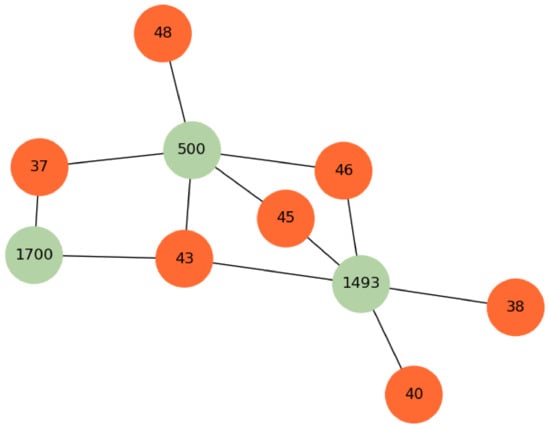
Figure 8.
Example from Amazon-Book knowledge graph. Green nodes represent item nodes, and orange nodes represent entity nodes in the knowledge graph.
This experimental result indicates that knowledge graph embedding plays a crucial role in the IKEGCL model. It effectively associates items that the user has interacted with in the past with relevant nodes in the knowledge graph, resulting in the generation of more accurate and personalized recommendation lists for users. By introducing knowledge graph embedding, the model can better utilize the information in the knowledge graph, enhance recommendation performance, and better cater to users’ personalized needs.
5. Conclusions
The paper introduces a collaborative recommendation model called IKEGCL, which combines knowledge graph embedding and graph contrastive learning. The key feature of this model is the integration of the knowledge graph embedding process into the graph contrastive learning framework, effectively addressing the issue of noise in the knowledge graph. Additionally, the model utilizes residual network connections between different layers of node vectors, successfully mitigating the over-smoothing problem in graph convolutional neural networks (GCNs) and improving recommendation performance through deeper GCN layers. In the experiments, the proposed model was extensively evaluated. The results on two publicly available datasets demonstrate that the proposed method outperforms other existing approaches in terms of recommendation performance, thus providing strong evidence for the effectiveness and superiority of the model in the context of recommendation systems.
While the proposed model, IKEGCL, demonstrates improved performance, there is a growing need for more interpretable recommendation models. Future research could explore ways to make the recommendations generated by such models more transparent and understandable to users. Developing techniques to visualize and explain the reasoning behind recommendations derived from knowledge-graph-enhanced models would be a valuable direction.
Author Contributions
L.J.: methodology, writing—review and editing; G.Y.: topic design, writing—review and editing, revision; H.L.: writing—review and revision; W.C.: data collection and revision. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (62062049), the Central Government Guided Local Funds for Science and Technology Development (22ZY1QA005), the Gansu Provincial Science and Technology Plan Project (21ZD8RA008), and the Natural Science Foundation for Young Scientists of Gansu Province (22JR5RA595).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated and/or analyzed during the current study are available in RecBole at https://github.com/RUCAIBox/RecSysDatasets (accessed on 3 May 2023).
Acknowledgments
Thanks to the anonymous reviewers and editors for their valuable comments and suggestions.
Conflicts of Interest
The authors declare that they have no conflict of interest to report regarding the present study.
References
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Liu, Y.; Wei, W.; Sun, A.; Miao, C. Exploiting geographical neighborhood characteristics for location recommendation. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 739–748. [Google Scholar]
- Li, Q.; Wang, X.; Wang, Z.; Xu, G. Be causal: De-biasing social network confounding in recommendation. ACM Trans. Knowl. Discov. Data 2023, 17, 1–23. [Google Scholar] [CrossRef]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Zhao, N.; Long, Z.; Wang, J.; Zhao, Z.D. AGRE: A knowledge graph recommendation algorithm based on multiple paths embeddings RNN encoder. Knowl.-Based Syst. 2023, 259, 110078. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Wang, X.; Wang, D.; Xu, C.; He, X.; Cao, Y.; Chua, T.S. Explainable reasoning over knowledge graphs for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 5329–5336. [Google Scholar]
- Yu, X.; Ren, X.; Sun, Y.; Gu, Q.; Sturt, B.; Khandelwal, U.; Norick, B.; Han, J. Personalized entity recommendation: A heterogeneous information network approach. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 283–292. [Google Scholar]
- Hu, B.; Shi, C.; Zhao, W.X.; Yu, P.S. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1531–1540. [Google Scholar]
- Xian, Y.; Fu, Z.; Muthukrishnan, S.; De Melo, G.; Zhang, Y. Reinforcement knowledge graph reasoning for explainable recommendation. In Proceedings of the 42nd international ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 285–294. [Google Scholar]
- Wang, K.; Liu, Y.; Sheng, Q.Z. Swift and sure: Hardness-aware contrastive learning for low-dimensional knowledge graph embeddings. In Proceedings of the ACM Web Conference 2022, Online, Lyon, France, 25–29 April 2022; pp. 838–849. [Google Scholar]
- Yang, Y.; Huang, C.; Xia, L.; Huang, C. Knowledge Graph Self-Supervised Rationalization for Recommendation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 3046–3056. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep graph infomax. arXiv 2018, arXiv:1809.10341. [Google Scholar]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the Proceedings of the 44th international ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 July 2021; pp. 726–735. [Google Scholar]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised heterogeneous graph neural network with co-contrastive learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Online, 14–18 August 2021; pp. 1726–1736. [Google Scholar]
- Li, C.; Xia, L.; Ren, X.; Ye, Y.; Xu, Y.; Huang, C. Graph Transformer for Recommendation. arXiv 2023, arXiv:2306.02330. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Wang, X.; Huang, T.; Wang, D.; Yuan, Y.; Liu, Z.; He, X.; Chua, T.S. Learning intents behind interactions with knowledge graph for recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 878–887. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Zhao, W.X.; He, G.; Yang, K.; Dou, H.; Huang, J.; Ouyang, S.; Wen, J.R. Kb4rec: A data set for linking knowledge bases with recommender systems. Data Intell. 2019, 1, 121–136. [Google Scholar] [CrossRef]
- Tai, C.Y.; Wu, M.R.; Chu, Y.W.; Chu, S.Y.; Ku, L.W. Mvin: Learning multiview items for recommendation. In Proceedings of the 43rd International ACM SIGIR Conf Erence on Research and Development in Information Retrieval, Online, 25–30 July 2020; pp. 99–108. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).