3.2.2. Sequence Tagging Part
(1) Pre-trained Chinese BERT Model and Its Fine-tuning:
This research uses the BERT (Bidirectional Encoder Representations from Transformers) model as its foundational architecture. BERT is distinguished for its significant results in natural language processing (NLP) tasks, largely attributed to its self-supervised learning and profound semantic modeling capabilities. Its encoder design incorporates multiple layers of self-attention mechanisms intertwined with feed-forward neural networks, thereby understanding global semantics.
In our sequence tagging task, detailed examination is applied to every character within compound noun phrases. The initial step involves segmenting these phrases on a character-by-character basis and embedding them within the pre-trained BERT model. Subsequently, the attention mechanism used in this research dynamically weights each position using the positional data of the predicting character, as described in [
28]. This process combines the hidden state vectors into a richer representation. Through a multi-layer perceptron (MLP) classifier, labels are then assigned to the character in focus, resulting in precise sequence annotation.
This methodology not only benefits from the pre-training of the BERT model on voluminous unlabeled text corpora but also improves the accuracy of individual characters within compound noun phrases. This is achieved by combining the attention mechanism and an MLP classifier. The workflow combines the strong semantic extraction of pre-trained models with an efficient attention distribution process, facilitating the assignment of exact labels to each character within the phrases, improving the effectiveness of sequence labeling tasks. A visualization of this architecture can be found in
Figure 2.
Our design effectively combines BERT’s pre-training advantages with fine-tuning strategies. This, when paired with the attention mechanism and an MLP classifier, culminates in an optimized and precision-oriented framework for sequence labeling of compound noun phrases.
(2) Attention Mechanism:
In the model described in this paper, the prediction process for every character uses specific attention weights. These weights are determined by processing the output sequence obtained from the pre-trained BERT model.
To ensure accurate predictions of individual characters within compound noun phrases, it is essential to understand the full contextual meaning. While traditional attention mechanisms are commonly used in models, they may not be detailed enough for specific tasks, especially those focused on character-level predictions. In such tasks, it is vital to not only understand the general meaning but also to consider the positional importance of the currently predicted character. To address this, we propose a new attention mechanism based on a multi-layer perceptron (MLP) that combines the positional data of the character being considered. A key advantage of this method is its ability to dynamically assign appropriate contextual weights to each predicted character, improving prediction accuracy.
Initially, the hidden state vectors tied to the “[CLS]” and “[SEP]” tokens are removed from the BERT’s output sequence, preserving solely the hidden state vectors corresponding to each character within the compound noun phrases. In this study, our sequence tagging model is designed to predict an individual character within the sequence during each iteration. Therefore, the attention mechanism focuses on the character being predicted at each step. To clearly determine the tagging position of the character predicted during each iteration, we use the position embedding technique from the Transformer architecture [
14]. This technique gives a specific vector representation to each character that is to be predicted, combining it with the BERT output vector. This combination captures both the positional details and the general character context. The formulation for the positional encoding is provided in the following equation:
where
denotes the position of the character targeted for prediction within the sequence,
represents the index of the encoding dimension, and
corresponds to the model’s dimensionality. Unlike the Transformer’s conventional position embedding approach, our model applies identical positional encoding information across all output vectors for a singular prediction, representing the positional data of the character being predicted.
As illustrated in
Figure 3, a novel vector is fed into the multi-layer perceptron, producing attention weights for designated characters. Subsequently, these attention weights are used to reduce BERT’s two-dimensional contextual representation matrix into a singular dimensional vector. Each row in this matrix corresponds to a character within the compound noun phrase and contains its related contextual data. Through an element-wise multiplication with the attention weights, followed by summation, we obtain a combined representation, symbolized as
. Here,
designates a character within the compound noun phrase that correlates with BERT’s output, while
denotes the attention weights generated via the attention mechanism.
Given the custom attention mechanism used in this study to combine the hidden state vectors, we provide a detailed explanation of this mechanism in the following sections.
Let
be the semantic vector from BERT, represented by
. By combining this vector with the positional encoding of the character currently being predicted, we produce a semantic representation,
, which includes the immediate prediction position and is given by
. For each component
, its transformation after processing by the Attention MLP is as follows:
where,
is weight matrix,
,
,
;
is bias,
,
;
is the sigmoid activation function; and e is the base of natural logarithms.
After processing matrix
through the Attention MLP, the output is
. Using this attention mechanism to obtain a one-dimensional representation of the semantic matrix, we get the following result:
where
represents the attention weights:
In summary, our model computes attention weights for every character by excluding specific tokens, incorporating positional embeddings, compacting the BERT output leveraging the attention weights, and utilizing a multi-layer perceptron. This architecture efficiently uses positional data, augmenting the efficacy of sequence labeling endeavors.
(3) Classification Using Multilayer Perceptron:
In this phase, the hidden state vector, denoted as
, is input into a multi-layer perceptron (MLP). This is used to predict the classification category of the pertinent character via a ternary classifier. The output tags align with three distinct categories ‘g’, ‘z’, and ‘f’; these categories, respectively, signify characters shared across multiple entity names, characters exclusive to a solitary entity name, and characters serving as separators. The MLP model transposes the hidden state vector into an appropriate feature space, using a series of non-linear transformations combined with weight matrix multiplications. This optimizes the classification of character classes [
29].
where,
denotes the hidden state vector at the
th layer of the MLP.
is the corresponding weight matrix within the MLP, while
represents the bias vector. The symbol MLP designates the activation function. By concatenating multiple hidden layers, the MLP can extract more intricate feature representations. Subsequently, the classifier in the output layer predicts character categories.
3.2.3. Sequence Parsing Section
(1) Sequence Parsing Model
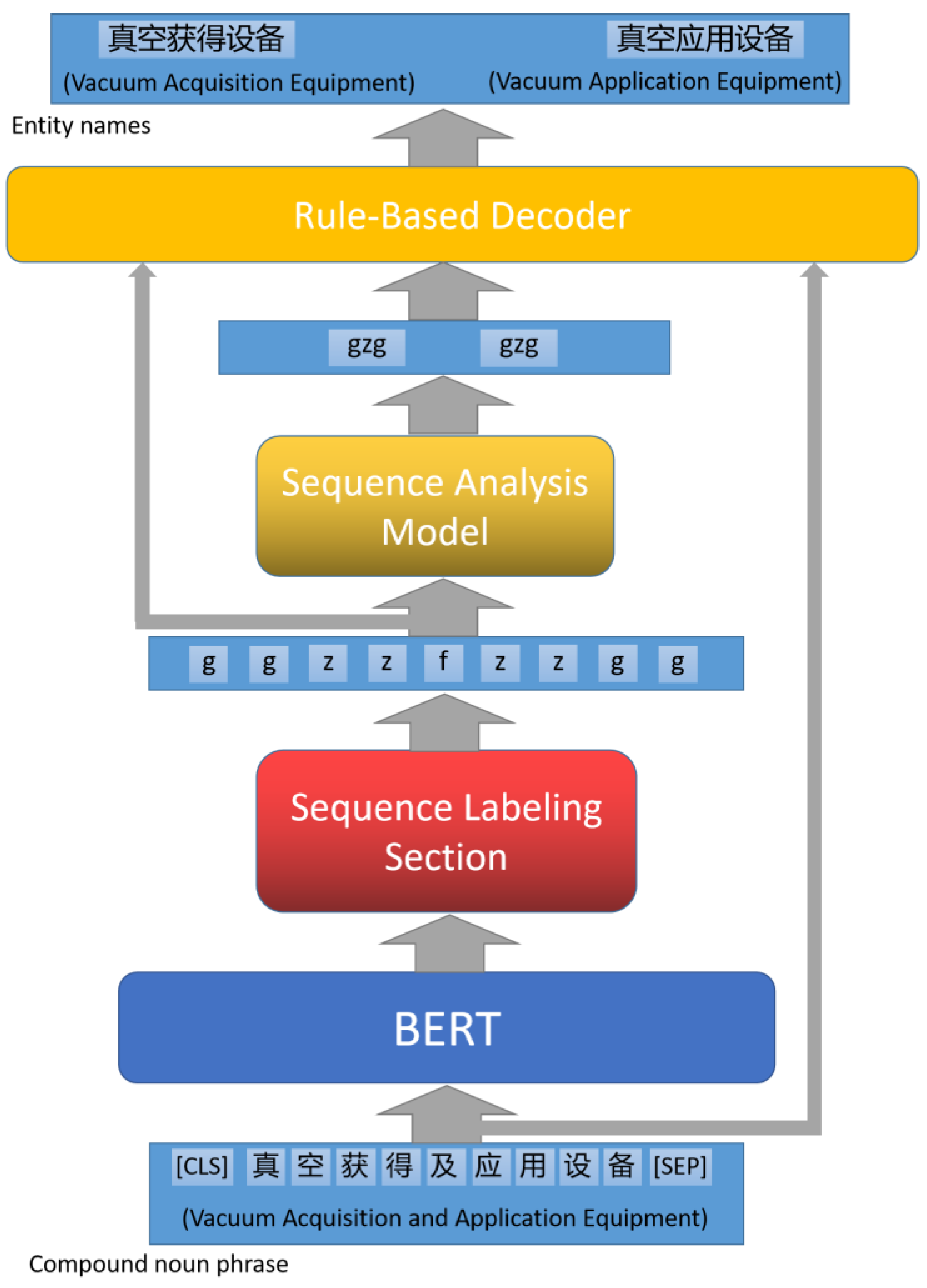
Given the constrained size of our dataset, we fine-tuned the input–output structure to capture all the entity name information within the compound noun phrases in the most succinct format. Specifically, the input sequence is reduced to two basic elements “g” and “z”. Each element in the simplified sequence corresponds to a segment of characters from the original sequence, as illustrated in
Figure 4. The output sequence represents six possible combinations of entity nouns in the compound noun phrase “z”, “g”, “zg”, “gz”, “gzg”, and “zgz”. Subsequent extraction is facilitated by a rule-based decoder that collaboratively interacts with the compound noun phrases and their respective annotation sequences to extract the comprehensive entity names from the model’s combinatorial outputs.
Initially, as illustrated in
Figure 4, we encode the characters embedded within the compound noun phrase according to their designated categories. This category sequence is then streamlined to accommodate the model’s input requirements. Post this step, we deploy an LSTM-based Seq2Seq model (as visualized in
Figure 5) to predict the patterns of character amalgamation [
19].
After the model’s prediction, a rule-based decoding strategy is employed to derive the comprehensive entity names from the compound noun phrases. This approach translates the model’s streamlined output to produce the entirety of the entity names embedded within the compound noun phrases.
Table 2 presents several examples of Sequence Labeling and Sequence Parsing.
(2) Decoding Strategy
The decoding strategy is pivotal in the extraction of entity names from compound noun phrases. Starting with the outputs from both the Sequence Labeling and Sequence Parsing Models, it thoroughly extracts the requisite entity names employing a structured set of rules.
The decoding strategy approach takes outputs of both the Sequence Labeling and Parsing Models. For example, the input phrase “半导体直、变流设备” (translated as “semiconductor DC and converter equipment”) yields a sequence labeling outcome of ‘gggzfzggg’. Further processing by the Sequence Parsing Model refines this to ‘gzg, gzg’.
(a) Decoding Mechanism for Entity Composition:
Each character from the Sequence Parsing Model (such as ‘g’ or ‘z’) corresponds to specific sections of the original compound noun phrase. For the phrase “半导体直、变流设备” (translated as “semiconductor DC and converter equipment”), the Sequence Parsing Model produces ‘gzg, gzg’. Here, the first ‘gzg’ pattern denotes the structure of the primary entity within the compound noun phrase. Both ‘g’ characters align with the ‘ggg’ tags for “半导体” and the ending ‘ggg’ of “流设备” in sequence labeling results. Here, ‘z’ refers to characters specific to its entity, so the ‘z’ in the primary ‘gzg’ matches the ‘z’ label from sequence tagging, representing “直”.
(b) Entity Name Reconstruction:
Sequential Reconstruction via Parsing Model Output: Using the patterns produced by the Sequence Parsing Model, we reconstruct segments from the original compound noun phrase. For the compound noun phrase “半导体直、变流设备” (translated as “semiconductor DC and converter equipment”), the parsed output “gzg, gzg” indicates that the first combination aligns sequentially with segments “半导体”, “直”, and “流设备”. Following this arrangement, we derive the entity “半导体直流设备” (translated as “semiconductor DC Equipment”) as the primary representation.
Entity Extraction via Iterative Decoding: Using iterative decoding across the full combinatorial sequence allows for the extraction of multiple entity names. Referring again to “半导体直、变流设备” and using the decoding strategy, we can extract the entities “半导体直流设备” (translated as “semiconductor DC Equipment”) and “半导体变流设备” (translated as “semiconductor converter equipment”).
The decoding strategy introduced in this study presents a notable advantage: it allows the Sequence Parsing Model to operate on streamlined sequences, substantially reducing the task’s complexity. As a consequence, even when working with a limited dataset, we are able to train a dependable model that delivers effective entity extraction outcomes. This adaptability is particularly crucial for smaller datasets, enabling us to attain high-precision entity extraction with reduced resource expenditure.
In essence, our approach facilitates the efficient extraction of entity names from compound noun phrases within the constraints of a smaller dataset. While the methodology does involve data streamlining and an intricate decoding strategy, it results in the development of a model adept at producing entity names, thereby providing significant value for tasks in entity recognition and generation.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}