
A Dual Convolutional Neural Network with Attention Mechanism for Thermal Infrared Image Enhancement

Abstract
:1. Introduction
- (1)
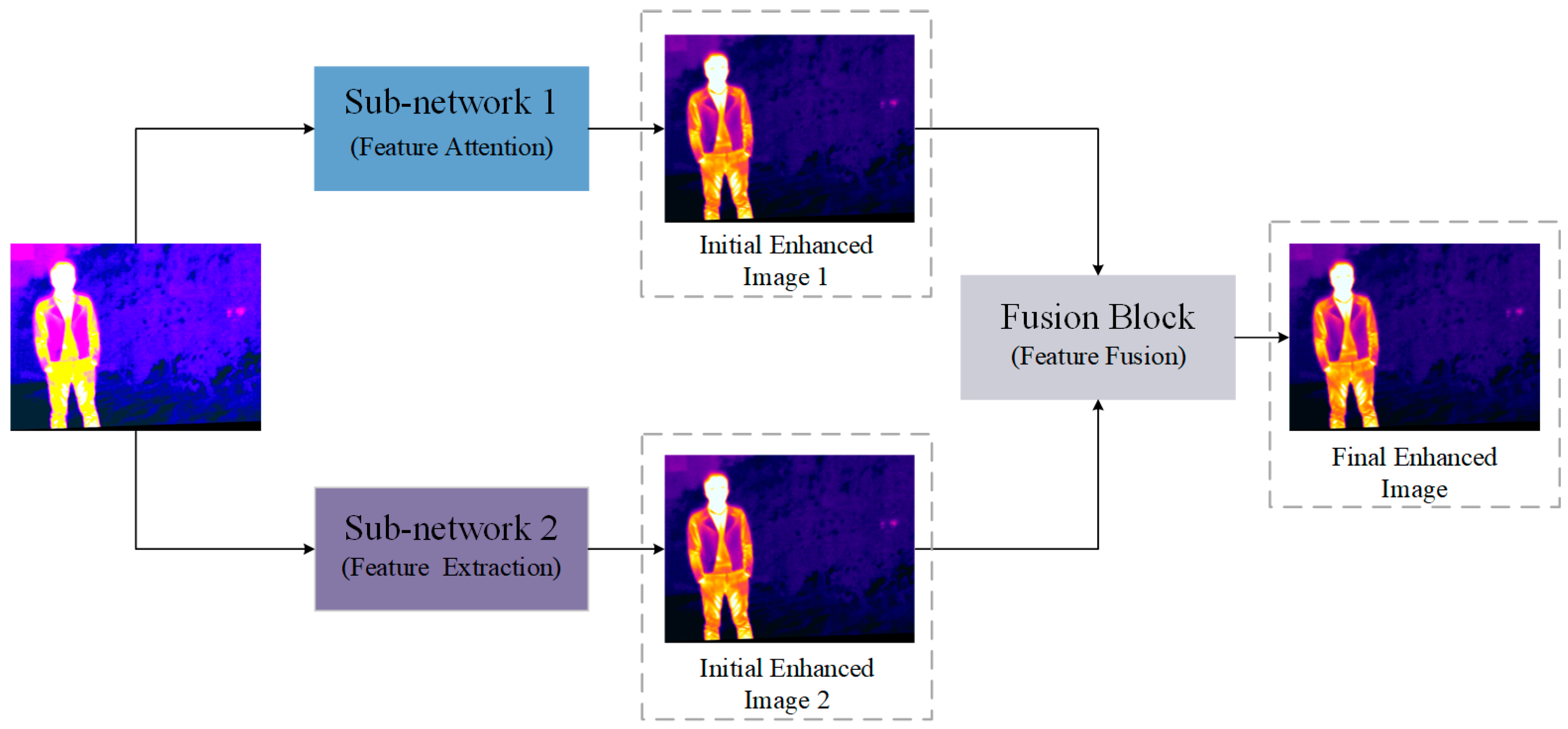
- We have introduced a dual convolutional neural network with an integrated attention mechanism for enhancing thermal infrared images. This network employs two parallel sub-networks to extract features at distinct scales. Furthermore, we utilize a fusion block to determine the optimal strategy for combining these features, resulting in enhanced images that boast rich details and improved visual quality.
- (2)
- The FA block is introduced to enhance the flexibility of network feature extraction, enabling it to adapt to complex scenes more effectively. Through the incorporation of both channel attention and pixel attention mechanisms, the FA block efficiently filters out irrelevant background information, directing the network’s attention toward meaningful features. This integration significantly enhances the network’s ability to handle complex scenarios.
- (3)
- The integration of the sparse mechanism using dilated convolutions is employed to enhance the network’s feature extraction capability. By utilizing dilated convolutions to expand the receptive field, the network can effectively capture information from a broader context, consequently enhancing its feature extraction capability.
2. Related Works
2.1. Traditional Image Enhancement Methods
2.2. Deep Learning-Based Image Enhancement Methods
3. Proposed Method
3.1. Overall Framework
3.2. Feature Attention
3.3. Sparse Mechanism
3.4. Fusion Block
3.5. Loss Function
4. Experiments
4.1. Dataset and Experimental Settings
4.2. The Experimental Results on the Dataset
4.3. The Experimental Results on Real-World Images
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Katırcıoğlu, F.; Çay, Y.; Cingiz, Z. Infrared image enhancement model based on gravitational force and lateral inhibition networks. Infrared Phys. Technol. 2019, 100, 15–27. [Google Scholar] [CrossRef]
- Liu, S.; Wang, S.; Liu, X.; Lin, C.-T.; Lv, Z. Fuzzy detection aided real-time and robust visual tracking under complex environments. IEEE Trans. Fuzzy Syst. 2020, 29, 90–102. [Google Scholar] [CrossRef]
- He, X.; Chen, C.Y.-C. Exploring reliable visual tracking via target embedding network. Knowl.-Based Syst. 2022, 244, 108584. [Google Scholar] [CrossRef]
- Abdar, M.; Fahami, M.A.; Rundo, L.; Radeva, P.; Frangi, A.F.; Acharya, U.R.; Khosravi, A.; Lam, H.-K.; Jung, A.; Nahavandi, S. Hercules: Deep hierarchical attentive multilevel fusion model with uncertainty quantification for medical image classification. IEEE Trans. Ind. Inform. 2022, 19, 274–285. [Google Scholar] [CrossRef]
- Zhang, H.; Li, M.; Miao, D.; Pedrycz, W.; Wang, Z.; Jiang, M. Construction of a feature enhancement network for small object detection. Pattern Recognit. 2023, 143, 109801. [Google Scholar] [CrossRef]
- Liu, J.; Zhou, X.; Wan, Z.; Yang, X.; He, W.; He, R.; Lin, Y. Multi-Scale FPGA-Based Infrared Image Enhancement by Using RGF and CLAHE. Sensors 2023, 23, 8101. [Google Scholar] [CrossRef] [PubMed]
- Hummel, R. Image enhancement by histogram transformation. Comput. Graph. Image Process. 1977, 6, 184–195. [Google Scholar] [CrossRef]
- Lee, J.-S. Digital image enhancement and noise filtering by use of local statistics. IEEE Trans. Pattern Anal. Mach. Intell. 1980, 2, 165–168. [Google Scholar] [CrossRef]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. Signal Process. Syst. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Vickers, V.E. Plateau equalization algorithm for real-time display of high-quality infrared imagery. Opt. Eng. 1996, 35, 1921–1926. [Google Scholar] [CrossRef]
- Kim, Y.-T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar]
- Kim, J.-Y.; Kim, L.-S.; Hwang, S.-H. An advanced contrast enhancement using partially overlapped sub-block histogram equalization. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 475–484. [Google Scholar]
- Singh, K.; Vishwakarma, D.K.; Walia, G.S.; Kapoor, R. Contrast enhancement via texture region based histogram equalization. J. Mod. Opt. 2016, 63, 1444–1450. [Google Scholar] [CrossRef]
- Sim, K.; Tso, C.; Tan, Y. Recursive sub-image histogram equalization applied to gray scale images. Pattern Recognit. Lett. 2007, 28, 1209–1221. [Google Scholar] [CrossRef]
- Parihar, A.S.; Verma, O.P. Contrast enhancement using entropy-based dynamic sub-histogram equalisation. IET Image Process. 2016, 10, 799–808. [Google Scholar] [CrossRef]
- Park, Y.; Sung, Y. Imitation Learning through Image Augmentation Using Enhanced Swin Transformer Model in Remote Sensing. Remote Sens. 2023, 15, 4147. [Google Scholar] [CrossRef]
- Pang, Z.; Liu, G.; Li, G.; Gong, J.; Chen, C.; Yao, C. An Infrared Image Enhancement Method via Content and Detail Two-Stream Deep Convolutional Neural Network. Infrared Phys. Technol. 2023, 132, 104761. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, N.; Hwang, S.; Kweon, I.S. Thermal image enhancement using convolutional neural network. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Lee, K.; Lee, J.; Lee, J.; Hwang, S.; Lee, S. Brightness-based convolutional neural network for thermal image enhancement. IEEE Access 2017, 5, 26867–26879. [Google Scholar] [CrossRef]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. MSR-net: Low-light Image Enhancement Using Deep Convolutional Network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Wang, W.; Wei, C.; Yang, W.; Liu, J. Gladnet: Low-light enhancement network with global awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 5–8 September 2018; Volume 220. [Google Scholar]
- Fan, Z.; Bi, D.; Xiong, L.; Ma, S.; He, L.; Ding, W. Dim infrared image enhancement based on convolutional neural network. Neurocomputing 2018, 272, 396–404. [Google Scholar] [CrossRef]
- Kuang, X.; Sui, X.; Liu, Y.; Chen, Q.; Gu, G. Single infrared image enhancement using a deep convolutional neural network. Neurocomputing 2018, 332, 119–128. [Google Scholar] [CrossRef]
- Wang, D.; Lai, R.; Guan, J. Target attention deep neural network for infrared image enhancement. Infrared Phys. Technol. 2021, 115, 103690. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. Proc. Conf. AAAI Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Barash, D. Fundamental relationship between bilateral filtering, adaptive smoothing, and the nonlinear diffusion equation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 844–847. [Google Scholar] [CrossRef]
- Paris, S.; Durand, F. A fast approximation of the bilateral filter using a signal processing approach. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Part IV 9. Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Pace, T.; Manville, D.; Lee, H.; Cloud, G.; Puritz, J. A multiresolution approach to image enhancement via histogram shaping and adaptive wiener filtering. In Visual Information Processing XVII; SPIE: Bellingham, WA, USA, 2008; Volume 6978, p. 697804. [Google Scholar]
- Li, Y.; Hou, C.; Tian, F.; Yu, H.; Guo, L.; Xu, G.; Shen, X.; Yan, W. Enhancement of infrared image based on the retinex theory. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Zhan, B.; Wu, Y. Infrared image enhancement based on wavelet transformation and retinex. In Proceedings of the 2010 Second International Conference on Intelligent Human-Machine Systems and Cybernetics, Washington, DC, USA, 26–28 August 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 1. [Google Scholar]
- Agaian, S.; Panetta, K.; Grigoryan, A. Transform-based image enhancement algorithms with performance measure. IEEE Trans. Image Process. 2001, 10, 367–382. [Google Scholar] [CrossRef] [PubMed]
- Li, X.M. Image enhancement in the fractional Fourier domain. In Proceedings of the 2013 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; IEEE: Piscataway, NJ, USA, 2013; Volume 1. [Google Scholar]
- Shcherbinin, A.; Kolchin, K.; Glazistov, I.; Rychagov, M. Sharpening image details using local phase congruency analysis. Electron. Imaging 2018, 30, 218-1–218-5. [Google Scholar] [CrossRef]
- Jiang, S.; Guan, M.; Wu, J.; Fang, G.; Xu, X.; Jin, D.; Liu, Z.; Shi, K.; Bai, F.; Wang, S.; et al. Frequency-domain diagonal extension imaging. Adv. Photonics 2020, 2, 036005. [Google Scholar] [CrossRef]
- Guo, C. The application of fractional wavelet transform in image enhancement. Int. J. Comput. Appl. 2021, 43, 684–690. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Li, Z.; Zuo, W.; Fei, L.; Liu, H. Attention-guided CNN for image denoising. Neural Netw. 2020, 124, 117–129. [Google Scholar] [CrossRef]
- Tian, C.; Xu, Y.; Zuo, W.; Du, B.; Lin, C.-W.; Zhang, D. Designing and training of a dual CNN for image denoising. Knowl.-Based Syst. 2021, 226, 106949. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tu, Z.; Ma, Y.; Li, Z.; Li, C.; Xu, J.; Liu, Y. RGBT salient object detection: A large-scale dataset and benchmark. In IEEE Transactions on Multimedia; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Liu, H.; Bao, C.; Xie, T.; Gao, S.; Song, X.; Wang, W. Research on the intelligent diagnosis method of the server based on thermal image technology. Infrared Phys. Technol. 2018, 96, 390–396. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ma, J.; Peng, C.; Tian, X.; Jiang, J. DBDnet: A deep boosting strategy for image denoising. EEE Trans. Multimed. 2021, 24, 3157–3168. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Metric | TEN | TIECNN | IE-GAN | DBDNet | Ours |
|---|---|---|---|---|---|---|
| VT5000 | PSNR (dB) | 20.58 | 22.73 | 25.83 | 30.65 | 36.58 |
| SSIM | 0.5291 | 0.5949 | 0.6597 | 0.7245 | 0.8269 | |
| Server | PSNR (dB) | 19.66 | 21.31 | 25.02 | 28.53 | 33.75 |
| SSIM | 0.5185 | 0.5809 | 0.6253 | 0.7013 | 0.7957 |
| Model | Dataset | |||
|---|---|---|---|---|
| VT5000 | Server | |||
| PSNR (dB) | SSIM | PSNR (dB) | SSIM | |
| Base | 31.74 | 0.7352 | 29.06 | 0.7119 |
| Base + DC | 32.85 | 0.7503 | 30.19 | 0.7364 |
| Base + FA | 35.61 | 0.7988 | 32.25 | 0.7739 |
| Ours (Base + DC + FA) | 36.58 | 0.8269 | 33.75 | 0.7957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, P.; Zhang, W.; Wang, Z.; Ma, H.; Lyu, Z. A Dual Convolutional Neural Network with Attention Mechanism for Thermal Infrared Image Enhancement. Electronics 2023, 12, 4300. https://doi.org/10.3390/electronics12204300
Gao P, Zhang W, Wang Z, Ma H, Lyu Z. A Dual Convolutional Neural Network with Attention Mechanism for Thermal Infrared Image Enhancement. Electronics. 2023; 12(20):4300. https://doi.org/10.3390/electronics12204300
Chicago/Turabian StyleGao, Pengfei, Weihua Zhang, Zeyi Wang, He Ma, and Zhiyu Lyu. 2023. "A Dual Convolutional Neural Network with Attention Mechanism for Thermal Infrared Image Enhancement" Electronics 12, no. 20: 4300. https://doi.org/10.3390/electronics12204300