Abstract
With the explosion of delay-sensitive and computation-intensive vehicular applications, traditional cloud computing has encountered enormous challenges. Vehicular edge computing, as an emerging computing paradigm, has provided powerful support for vehicular networks. However, vehicle mobility and time-varying characteristics of communication channels have further complicated the design and implementation of vehicular network systems, leading to increased delays and energy consumption. To address this problem, this article proposes a hybrid task offloading algorithm that combines deep reinforcement learning with convex optimization algorithms to improve the performance of the algorithm. The vehicle’s mobility and common signal-blocking problems in the vehicular edge computing environment are taken into account; to minimize system overhead, firstly, the twin delayed deep deterministic policy gradient algorithm (TD3) is used for offloading decision-making, with a normalized state space as the input to improve convergence efficiency. Then, the Lagrange multiplier method allocates server bandwidth to multiple users. The simulation results demonstrate that the proposed algorithm surpasses other solutions in terms of delay and energy consumption.
1. Introduction
In recent years, the rapid advancement of 5G networks has propelled the increasing utilization of the Internet of Vehicles (IoV) across multiple applications [1], including autonomous driving, panoramic navigation, traffic prediction, and road safety [2,3]. These applications often demand substantial computational resources and are highly sensitive to latency. However, most vehicles possess limited resources, and some tasks may not be completed or may take too long to complete, affecting the quality of service for vehicle users or even leading to vehicle congestion and collisions. Furthermore, vehicles themselves confront the challenge of high energy consumption when processing tasks. Vehicle Edge Computing (VEC), along with the continued maturation of Mobile Edge Computing (MEC) technology [4,5], has become a research hotspot to address these issues [6]. Vehicle Edge Computing enables vehicles to acquire computational and caching resources at the network’s edge [7]. Complex tasks are offloaded to the edge server through the Roadside Unit (RSU), enabling real-time processing of vehicle tasks reducing task processing delay and energy consumption [8,9], and improving user quality of service [10]. Computation offloading, as a pivotal technology within Vehicle Edge Computing, refers to the practice of transferring a portion or the entirety of computational tasks from the vehicles to the MEC server, consequently resolving the computational resource, real-time, and energy consumption challenges faced by vehicles. When the computational resources of the vehicle are insufficient to meet the task requirements, the computation-intensive and latency-sensitive tasks can be offloaded to the edge servers through computation offloading, which fully utilizes the available resources of the servers to process the tasks, effectively improves the quality of the vehicle service, and reduces the overall cost of the system [11,12].
IoV task offloading still faces many challenges. Due to the time-varying nature of the IoV environment, the location of the vehicles, the state of the communication channel constantly changing, and the varied size of the tasks generated by the vehicles, resulting in the time required to process the tasks in the communication area of the MEC server. However, most of the existing literature focuses on considering the selection of offloading strategies but rarely considers the dynamic nature of the IoV environment, which cannot be realized in a real IoV environment.
In this paper, a dynamic hybrid task offloading algorithm HTCO is proposed as a solution to the above problem. The primary contributions are summarized below:
- A multi-user vehicular network (VNET) model based on VEC has been developed for complex and changing VNET scenarios, which considers dynamic factors such as vehicle mobility, task size, channel state, and the distance between vehicles and servers to formulate a joint optimization problem that ensures the system efficiency to reduce the system cost by optimizing the offloading decision and bandwidth allocation;
- In this paper, we propose a novel Hybrid Task Computing Offloading (HTCO) algorithm, which innovatively combines a deep reinforcement learning (DRL) algorithm with a convex optimization algorithm and can perform computation offloading and bandwidth allocation in an arbitrary ratio. Specifically, this paper first transforms the dynamic task offloading problem into a Markov decision problem, uses the (TD3) algorithm to make offloading decisions, and brings the offloading decision variables into the convex optimization algorithm to obtain the bandwidth, which jointly optimizes the system’s latency and energy consumption, resulting in the lowest total cost of the system.
- The effectiveness of the HTCO algorithm is demonstrated by comparison experiments with the TD3 algorithm and other single-scene algorithms. The cost is reduced by 9%, 22%, and 54% compared to other algorithms.
The remaining work is presented as follows. We summarize the relevant work in Section 2. Section 3 describes the IoV system model and defines the offloading problem. Section 4 presents the specific details of the HTCO algorithm. Section 5 describes the experimental setup and validates the performance of the proposed algorithm. We summarize our paper and outline future work in Section 6.
2. Related Work
With the increasing scale of tasks and the time-varying characteristics of the IoV channel, obtaining the optimal offloading decision is a key problem that VEC needs to solve [10,13]. Numerous academics and research organizations both domestically and internationally have investigated the offloading of Mobile Edge Computing. The authors in [14] proposed a reverse offloading framework to reduce the burden on the VEC server and further reduce the system latency by fully utilizing the computational resources of the vehicle. It was solved by a conventional optimization algorithm. The authors in [15] studied the problem of latency minimization in IoV by establishing a software architecture based on Software Defined Networking (SDN) and proposing an approximate computational offloading scheme to minimize the total processing latency of all computational tasks under a maximum allowable latency constraint. The authors in [16] proposed an energy model for multi-resource computing offload. They designed an energy optimization scheme based on a task scheduling algorithm, considering that some offloading strategies proposed in the existing literature consider only a single computing resource. Reference [17] proposed an intelligent optimization algorithm, the Fish Swarm Algorithm, to optimize the solution in terms of computational offload and communication channel, but the authors did not consider the mobility of the device nor the use of a proportional offloading strategy. The authors of [18] combined the allocation of a wireless network and offloading services to minimize energy consumption while satisfying the task delay constraints and cost budgets and decomposed the problem into convex subproblems to obtain an approximate solution but lacked the combined consideration of delay and energy consumption.
However, the optimization algorithms considered in the aforementioned literature are based on treating the situation of the whole system model as a known condition. Due to the ever-changing nature of the vehicle environment, complete and accurate environmental parameters may not be obtained in a real IoV environment. Thus, the aforementioned optimization methods may not be fully effective or require great cost in real vehicular edge computing environments.
DRL has achieved success in several areas by utilizing the perceptual and decision-making ability of deep learning and reinforcement learning [6,19]. Therefore, many scholars have considered using DRL as a decision-making algorithm. The researchers in [20] propose a dynamic pricing strategy that utilizes stationary vehicles as computing service merchants. The goal is to optimize the service provider’s computing income while reducing the user’s energy usage. However, because the value-based Q-learning algorithm is used, there are significant limitations in selecting the action space to achieve the best results. The researchers in [21] examined a multi-user Mobile Edge Computing network with time-varying fading channels and proposed an improved DQN-based offloading strategy for the offloading decision and resource allocation problems. The researchers in [22] recommended a vehicle-end-edge cloud architecture to offload task computations, utilizing an A3C-based offloading method to ascertain the optimal decision. This approach considers both efficiency and fairness. The authors in [23] considered the user’s budgetary restrictions while designing a vehicular network system based on MEC to minimize delays. The proposed approach combines DQN and a convex optimization algorithm with deep reinforcement learning. The authors in [24] proposed a multitask, multi-user MEC system, developed a computational model for joint task offloading and caching, and, finally, optimized the offloading and caching strategies using a DQN-based deep reinforcement learning algorithm. The authors in [25] encouraged vehicles to share idle compute resources, classify tasks by task size and priority, and finally achieve task offloading by maximizing the average utility of the considered network. The authors in [26] considered the utilization of the idle resources of the vehicle; the hybrid task offloading is performed by the V2V and V2I modes to maximize the utilization efficiency of the resources. The authors of [27] jointly optimized service caching and computation offloading in a time-varying IoV environment, formulating the problem using long-run mixed-integer nonlinear programming (MINLP) and solving it using deep reinforcement learning algorithms to minimize latency. The authors in [28] proposed a multi-intelligence-based task offloading scheme to optimize the offloading and resource allocation strategy according to the task priority size to improve the average utility of the vehicle, but less consideration was given to the energy consumption aspect of task offloading.
Although the above method using DRL can be effectively implemented in a dynamic IoV environment, it does not consider the time-varying characteristics of the channel in the IoV environment and the reasonable allocation of bandwidth resources, and it lacks the consideration of the need to optimize the computational offloading delay and energy expenditure. This paper presents a novel approach to task offloading that combines deep reinforcement learning and convex optimization. It can adaptively allocate bandwidth resources and offloading ratios for vehicle mobility, task size, and channel characteristics to minimize both system delay and energy consumption and effectively reduce system overhead.
3. System Model
In this section, we detail the task-offloading system model for the IoV scenario and formulate the task-offloading and resource allocation problem as an optimization problem.
3.1. System Framework
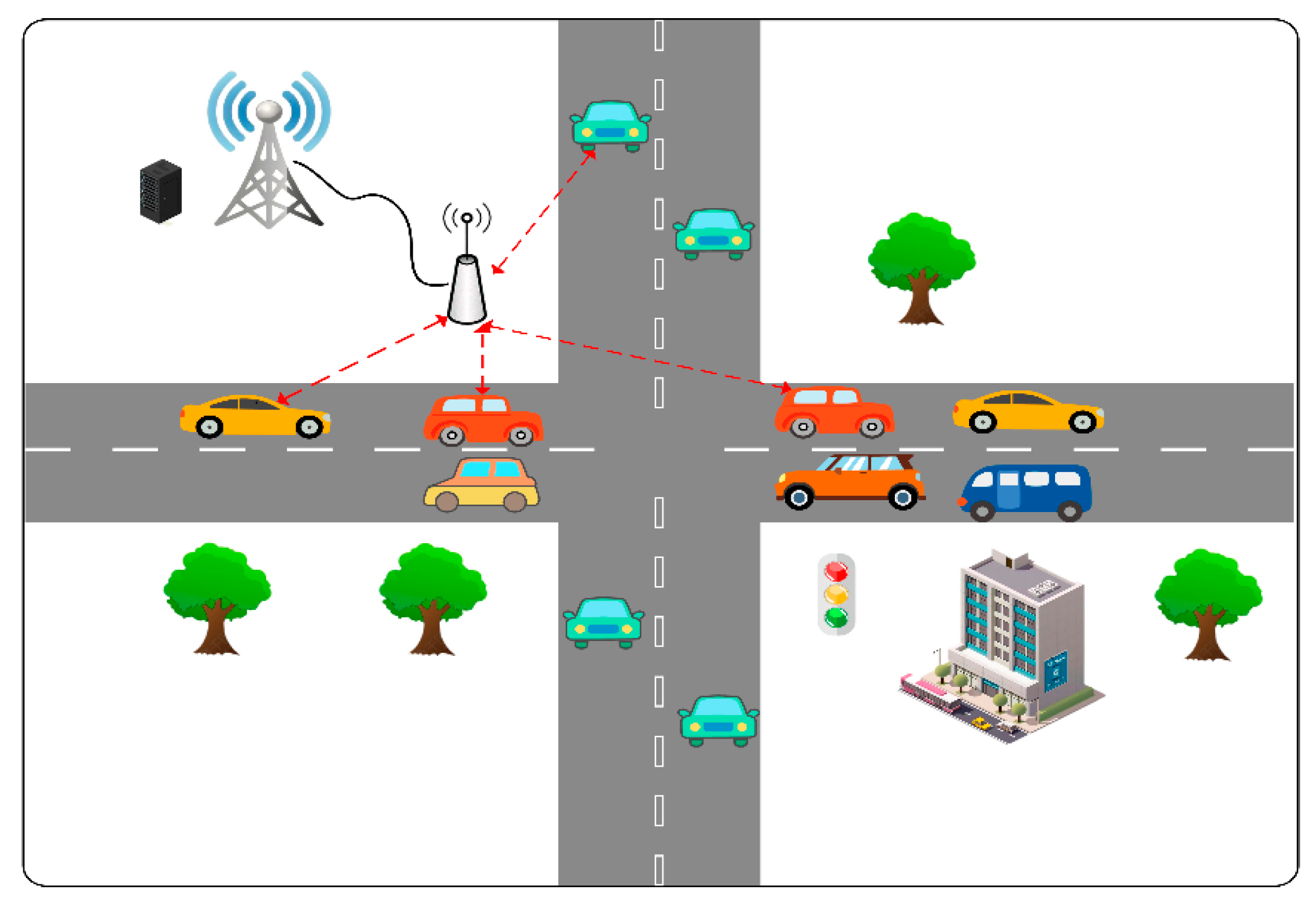
Regarding the vehicle offloading model, as shown in Figure 1, this article designs a multi-user VEC-assisted vehicle networking model, where the RSU (Road Side Unit) is located at the side of the intersection and a MEC server is deployed near the RSU to provide computational services to the vehicles. The RSU is connected to the MEC via a cable, and the RSU is responsible for accepting the offload request and transmitting it to the MEC server for processing. The set of vehicles denoted as randomly generates computational tasks of different sizes and sends offload requests to the MEC server, which has powerful computational capabilities and is equipped with artificial intelligence algorithms to act as a global control center that autonomously makes offload decisions based on the distance between the vehicles and the MEC server, the current channel congestion, and the size of the tasks.
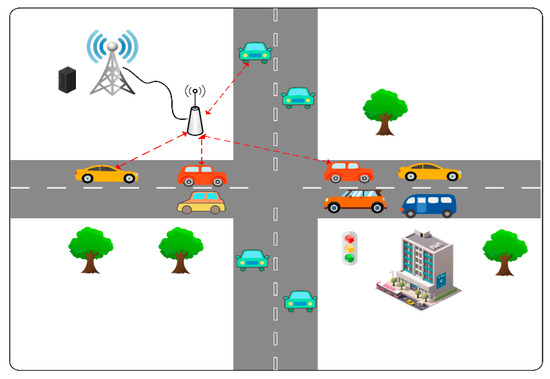
Figure 1.
Vehicular edge computing network model.
The system assumes that the tasks are divisible and that system optimality can be achieved through a partial offloading strategy. The system model adopts a discrete-time model with a time duration of , the time set is denoted by , and there is a computational task to be processed in each time slot, and each task is denoted by a dichotomy of , where represents the number of CPU cycles required to process a 1-bit task and represents the size of the task.
3.2. Communication Model
In the IoV task offloading situation, each task can be handled locally or offloaded to the edge server to decrease the delay and enhance the speed of task completion. The server location can be expressed as , and represents the height of the base station. If at any moment , the position of the task vehicle can be denoted as , and the direction of travel of the vehicle does not change during each time slot interval , then the position of the vehicle at is represented as
where represents the vehicle speed, represents the angle at which the vehicle is traveling, and represents the time interval.
Considering that in real IoV scenarios, the signal may be blocked by obstacles during transmission, we add the signal blocked or not flagged to distinguish the transmission capability of the signal in different situations. When the task is transmitted to the edge server, the wireless transmission rate is
where is the bandwidth of the vehicle , is the channel gain when the reference distance is 1 m, represents the current transmission power of the vehicle, is the noise power, is the transmission loss power, is used to indicate whether the current signal is blocked or not, represents that the signal is blocked, and represents that the signal is in good condition and not blocked.
3.3. Task Model
When the task generated by the vehicle requires hybrid computation, the computational delay of the task in the local processing section is
In addition, the energy consumption of the locally computed task is calculated as follows:
where denotes the proportion of the task that is computed locally, denotes the number of CPU cycles required to complete the task , denotes the vehicle’s computational power, and denotes the power units consumed by the vehicle’s local computation.
However, if the tasks are simply processed locally, not only can the quality of the processed tasks not be guaranteed, but also some computation-intensive tasks will generate a lot of energy consumption, so we consider offloading the tasks to the MEC server. When a task is selected to be offloaded to the MEC server, the total waiting time for processing the task consists of three parts: the time it takes to upload the task data from the vehicle to the MEC server, the time it takes for the MEC server to process the task using local computing resources, and the time it takes to download the data from the MEC server to the task vehicle. The download delay of the data is not considered in this paper, as the size of the downloaded data (execution result) is negligible in comparison to the uploaded data.
When offloading some of the tasks to the server, the transmission delay and energy consumption of the task are as follows:
where represents the offload ratio, represents the amount of data offloaded to the MEC server for the portion of the task, and represents the power units consumed for upward transmission.
The calculation delay of processing tasks on the MEC server is :
where represents the number of CPU cycles required to process the task and is the edge server computational power. The energy consumption of the MEC server to perform the task in the time slot is given by the following equation:
The power unit utilized by the MEC server computation is denoted as .The hybrid offloading strategy’s delay and energy consumption can be expressed as such:
3.4. Problem Formulation
In this paper, we take a combined view of delay and power consumption when considering system cost, both of which are important performance metrics in VEC networks. Therefore, the optimization objective of the hybrid task offloading problem is to minimize the system cost by obtaining the optimal offloading strategy and allocation of wireless bandwidth resources; the joint optimization problem is denoted as
denotes the offloading decision of each vehicle user, denotes that the sum of the bandwidths of all vehicle users is equal to the total server bandwidth. and represent the current importance of latency and power consumption to the system, which satisfies . When is 1, it means that the system only considers the minimum delay without considering the energy consumption.
4. Hybrid Task Offloading Algorithm (HTCO) Design
4.1. Markov Decision Model for Offloading
For the problem , we propose a hybrid task offloading algorithm that combines TD3 and convex optimization algorithms (HTCO) to obtain the best offloading decision for the dynamically changing IoV environment using the TD3-based approach and subsequently bring the obtained offloading decision to the convex optimization approach to obtain the bandwidth resource allocation strategy.
In the considered system model, the various parameters of the on-board network are constantly changing between different time slots and, although the current environment condition is known, the next state and the future are unknown; to solve the problem of the changing environment, we transform the task offloading and bandwidth allocation problem into a Markov Decision Process (MDP) problem [29]. The MDP generally contains three basic elements: , where and represents the state space and action space, and represents the reward. To find the optimal offloading decision, it is necessary to choose the appropriate state, action, and reward functions, which are defined as follows:
- State: In DRL, the state space is used to reflect the environmental conditions of the vehicle. The state of the time slot is shown below:
represents the location coordinates of all task vehicles. represents the size of the task generated by the vehicle that needs to be processed. represents whether the vehicle signal is blocked or not.
The large range of values for some states during the training process of the neural network will cause the training speed to slow down. Therefore, in this paper, the values of the states are normalized to avoid the problem that the convergence of the whole system deteriorates due to the large difference between different state types, which may even lead to the non-convergence of the neural network. The normalized state is as follows:
where represents the maximum range covered by the server and represents the maximum value of randomly generated task data.
- 2.
- Action: Based on the purpose of immediate reward maximization, the vehicle takes an action based on the current system status . The action is denoted as
The entire action space of the system consists of vehicle-selected actions, which are used to decide whether to offload the target task or to process it locally and what percentage of the offloading is selected.
- 3.
- Reward: When the action is performed, the system enters the next state and the vehicle receives a reward from the environment.
This scheme integrates the joint optimization of system offloading delay and energy consumption as a reward function; represents the average cost of the vehicle, where represents the number of vehicles generating tasks for each time slot, and is specifically calculated by (11) computing:
4.2. Offloading Decision Based on DRL Algorithm
The TD3 algorithm is a more robust version of the DDPG algorithm that is less sensitive to parameters. TD3 tackles the problem of DDPG overestimating the Q-value and enhances the algorithm’s stability through the introduction of three optimizations:
- Tailoring the dual-Q network:
The use of a single critic network to estimate the Q function in the DDPG algorithm can lead to an overestimation of the Q function, which may cause the intelligence to learn an error-prone strategy. In contrast, in TD3, inspired by deep dual Q learning [30], the Q function is estimated using two critic networks, with the smaller Q value being chosen as the estimate.
- 2.
- Delayed update of strategy:
The DDPG algorithm typically maintains a consistent update frequency for both the actor and critic networks, whereas the TD3 algorithm empirically demonstrates that this operation typically results in an unstable training process or even fails to reach the accurate value. Consequently, the TD3 algorithm recommends reducing the frequency of updating the actor network and increasing the frequency of updating the critic network to minimize the error before policy updates.
- 3.
- Target strategy smoothing:
The TD3 algorithm mitigates the impact of the function error on the target value update by introducing extra noise to the target action, thus making it harder for the strategy to take advantage of the function error [31]:
where denotes the action that is integrated with random noise during agent exploration to avoid a local optimum:
is the added random noise, indicates that the noise we added is normally distributed, is the standard deviation, and represents the range of values of the noise.
The target networks are updated using soft updates:
where represents the learning rate.
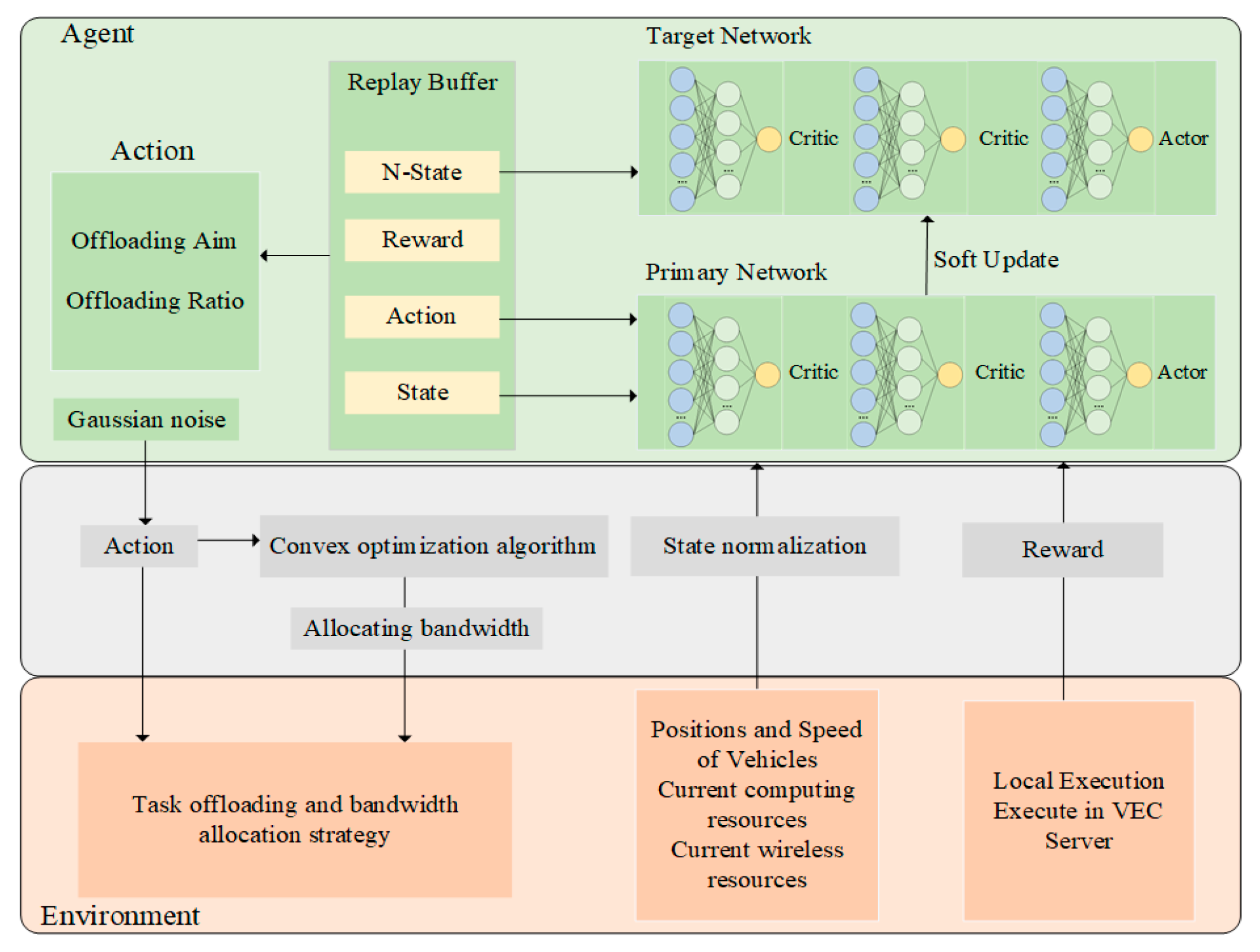
Aiming at the problem of a large number of continuous time-varying variables in Vehicle Edge Computing scenarios, this paper proposes a method of TD3 combined with convex optimization, which is named HTCO. As shown in Figure 2, the primary network is composed of three deep neural networks, comprising two critic networks and one actor network. The actor network is tasked with examining the policy and selecting the most advantageous policy as the present one. The two critic networks need to appraise the action as either favorable or unfavorable and safeguard the data. The target network adopts a soft update strategy concerning the main network, which reduces error fluctuations, inputs the state stored in the experience replay buffer pool, and outputs the training results. While actions are being output to the environment, these actions are fed into the convex optimization algorithm to determine the bandwidth that the system allocates to different tasks, which are output to the environment along with the actions. Finally, the system takes an action, receives a new state and a reward for the action taken, and then the reward and the regularized state are output to the agent and stored in the experience replay buffer. The experience replay buffer contains the current state, the action taken, the reward received, and the state at the next moment; the action contains the offload aim and the offload bandwidth; the state contains the vehicle’s position, its speed, and the computational and communication resources of the vehicle and the server; the reward is determined by the magnitude of the vehicle’s average cost. To minimize the effect of data dependency, the empirical data were randomly sampled when training the main and target networks. The next section describes the specific process of convex optimizations for bandwidth allocation.
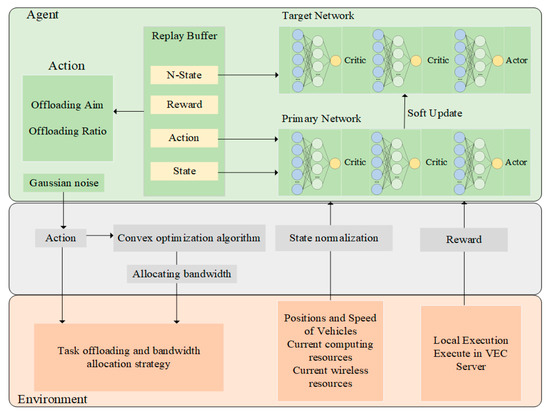
Figure 2.
HTCO-based computational offloading process.
4.3. Bandwidth Allocation Based on Convex Optimization
When the optimal offloading ratio is obtained by the deep reinforcement learning algorithm, the offloading ratio is brought into and can be transformed into :
As can be seen from , the minimization problem is affected by the server bandwidth. However, it is difficult to solve directly. To reduce the computational complexity, we further transform into :
The problem is a strict ceiling problem of the problem ; to solve the problem , we can use the Lagrange multiplier method to introduce the constraints into the form of an objective function to obtain a new objective function. By minimizing this new objective function, we can obtain the optimal solution to the problem :
where is the Lagrange multiplier. Then, find the first order partial derivatives of concerning and , and then make them zero:
For convenience, is used to denote
The specific offloading execution process of the HTCO algorithm is shown in Algorithm 1. First, the environment parameters of IoV are entered into the algorithm, the network structure and network parameters of the actor and critic are initialized, and the experience playback buffer is initialized. Then, the system will perform 1000 episodes of iterations; each iteration will reinitialize all the parameters of the system environment, each episode will be divided into T time slots, and each time slot will have some vehicle generation tasks that need to be considered whether to be offloaded or processed locally. The actor network in the algorithm gives the offloading action; after executing the action, a new state is obtained, the critic network evaluates the goodness of the action and stores the result in the experience replay buffer, the output is the offloading decision, and the allocated bandwidth. Before the start of each time slot, the vehicle moves a distance and generates new tasks until the end of the iteration.
| Algorithm 1. HTCO Algorithm |
| Input: vehicle edge computing environment parameter Output: action selected by HTCO algorithm and allocated bandwidth 1: Randomly initialize the network parameters and 2: Initialize the target network parameters and 3: Initialize the experience replay buffer 4: for each episode do 5: Random reset environmental parameters and receive the initial observation state s1 6: for each time slot do 7: Observe state s(t) and select action with exploration noise: 8: Use the Lagrange multiplier method to calculate the bandwidth by (27) 9: Execute action and obtain a reward and the next state 10: Store in the experience replay buffer 11: If is not full: store the data in the experience buffer 12: Else: randomly replace other experiences in the buffer 13: Select N samples from the experience replay buffer 14: Compute the value of the target network: 15: Backpropagation to update weights 16: Soft update of the target network 17: 18: 19: end for 20: end for |
5. Experimental Results
5.1. Simulation Environment and Parameter Settings
To simulate as much as possible the real IoV environment, this paper refers to [32] for the environment parameter settings, with appropriate modifications. A model of an IoV system consisting of a single edge server and multiple task vehicles was simulated using Python 3.6 and TensorFlow 1.14.0. The HTCO algorithm was deployed on the MEC server, which contains one actor network and two critic networks, all of which are four-layer fully-connected layer neural networks using ReLU as the activation function. The experience buffer size is set to 10,000, and a total of 1000 episodes of training are performed. and are set to 0.5, indicating that current latency and power consumption are equally important. Table 1 displays the remaining parameters.

Table 1.
System environment and related parameters of HTCO algorithm.
To verify the performance of the HTCO algorithm, the following three offloading strategies are compared in this paper from four aspects: number of user vehicles, server bandwidth, server computing power, and vehicle generation task size:
- All-Local: The task vehicle processes all tasks locally;
- All-MEC: The task vehicle processes all tasks on the MEC server;
- TD3: A deep reinforcement learning offload approach that disregards bandwidth distribution and determines the offload ratio of a task based on task size, channel conditions, distance, and other elements.
5.2. Analysis of Experimental Results
The selection of certain parameters in the HTCO algorithm will have an impact on its convergence and stability. The best algorithm parameters are selected in this paper through the following two experiments.
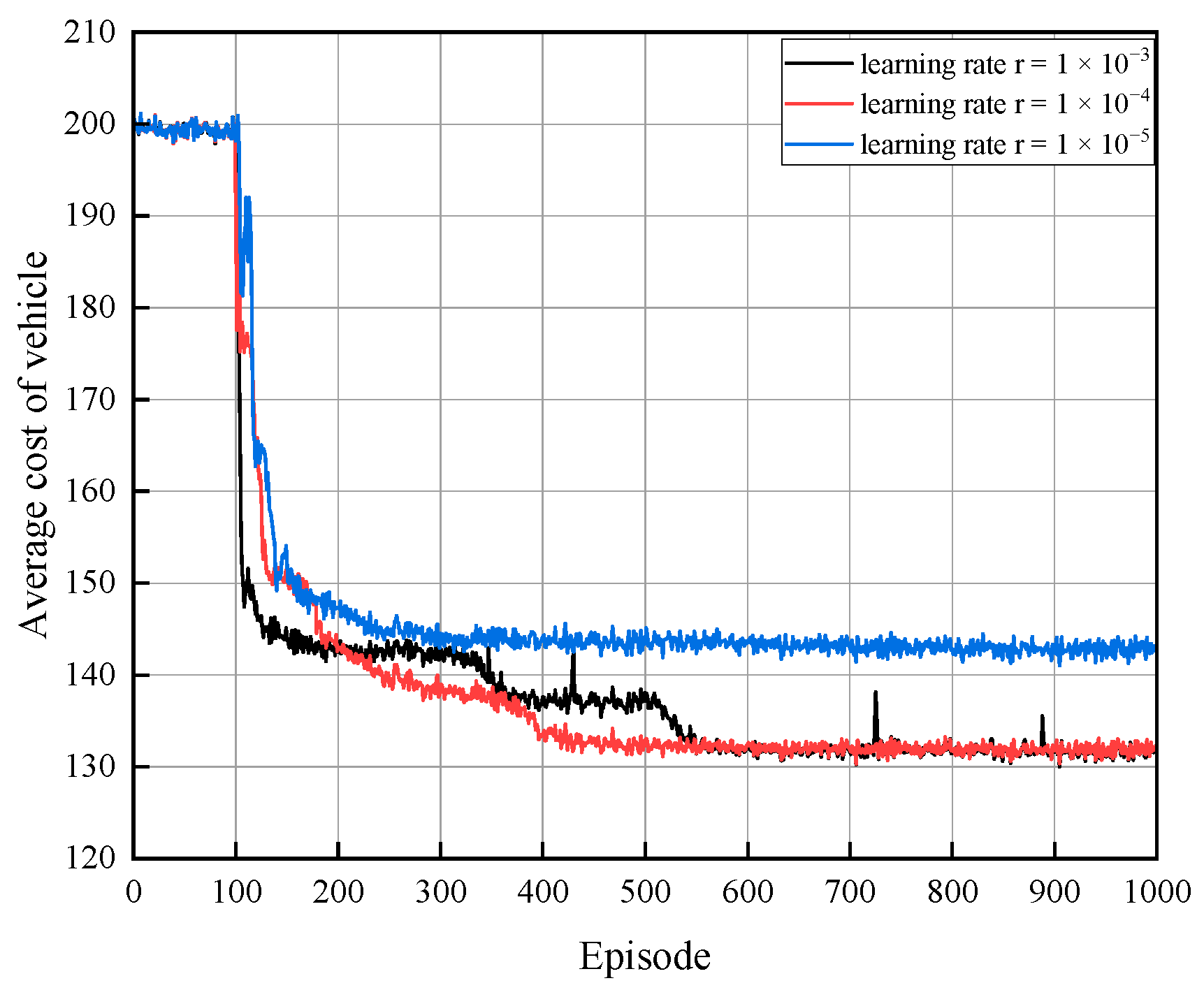
The HTCO algorithm’s neural network training and updating are impacted by the rate of learning. If the learning rate is too high, it can cause the optimal solutions to be overlooked and the stability to be compromised during the optimization process, whereas if the learning rate is too low, it may result in a local optimum or slower convergence. The number of trainings is depicted on the horizontal axis in Figure 3, while the total cost of processing the task in T timeslots for any vehicle is represented by the average cost of the vehicles on the vertical axis. When the learning rate of the network is 1 × 10−5, the average cost of vehicles decreases with the number of iterations, but its optimal solution is not as good as when the learning rate is 1 × 10−4 and 1 × 10−3. A higher learning rate results in an increased update rate for both the actor and the critical network, whereas the optimal solution necessitates minimal updates. A learning rate of 1 × 10−3 can yield the optimal solution, yet it is prone to becoming ensnared in the local optimal solution due to the insufficient learning rate. Consequently, we choose 1 × 10−4 as the learning rate. When the learning rate of the network is 1 × 10−4, the system will be able to achieve an optimal solution that is both converged and stable after 400 iterations.
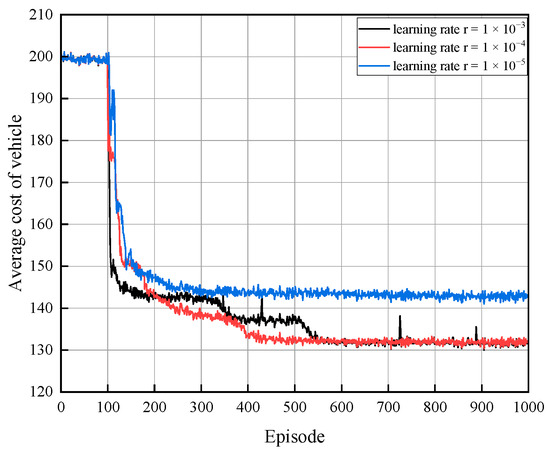
Figure 3.
Average cost of vehicle with different learning rates.
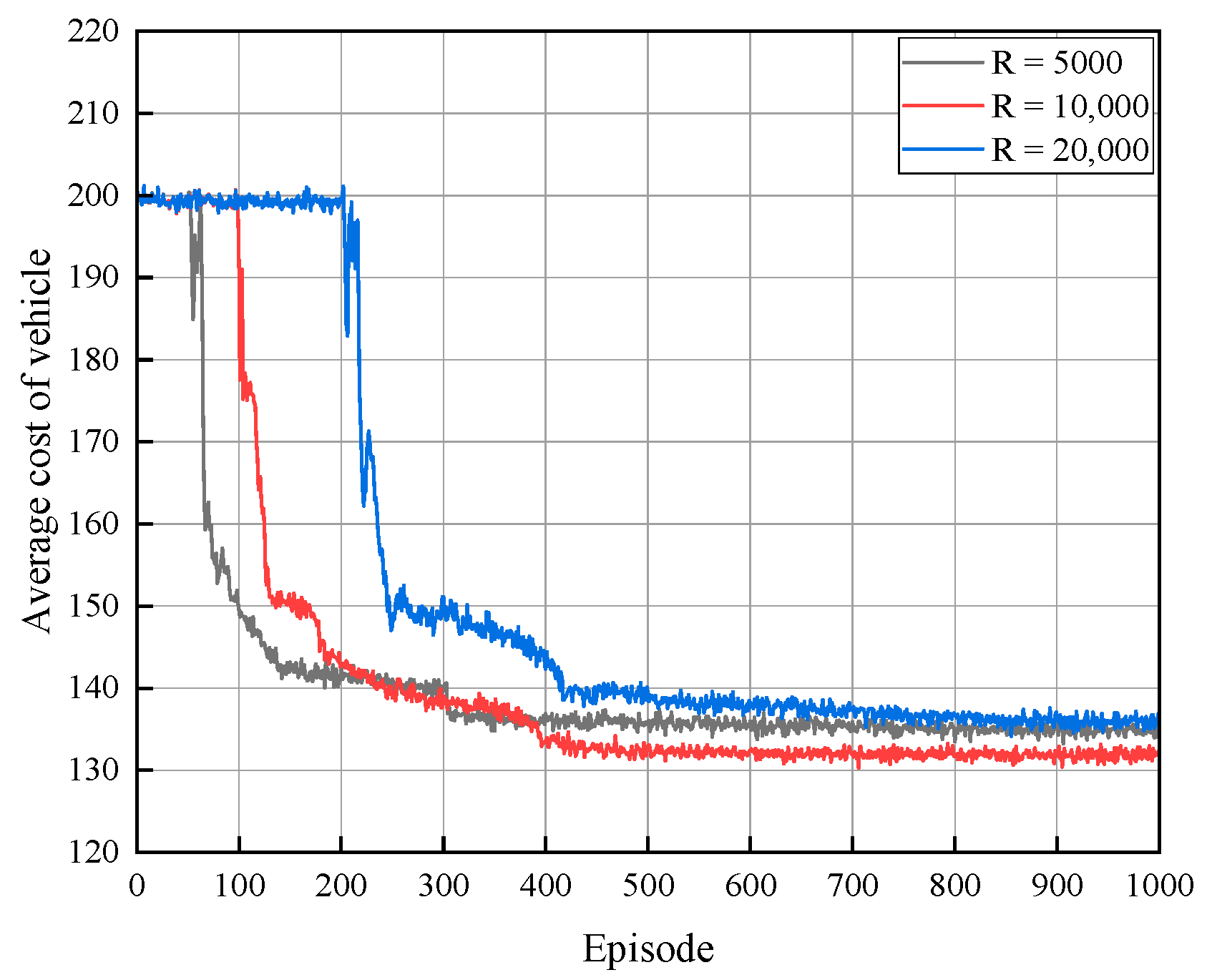
The experience replay buffer has an impact on the algorithm’s training time, optimality, and convergence. As shown in Figure 4, when the experience replay buffer is 5000, the local optimal solution can be attained after 300 iterations, yet the global optimal solution cannot be attained in the end due to the empirical buffer being relatively small, which has an impact on the feature information of the extracted data, and the optimal strategy cannot be acquired. Once the experience replay buffer is 10,000, the optimal solution can be attained after 400 cycles. When the experience replay buffer is 20,000, the global optimal solution is not obtained, which is due to the relatively slow update of the data because the buffer is too large. Consequently, we adjusted the experience replay buffer parameter to 10,000.
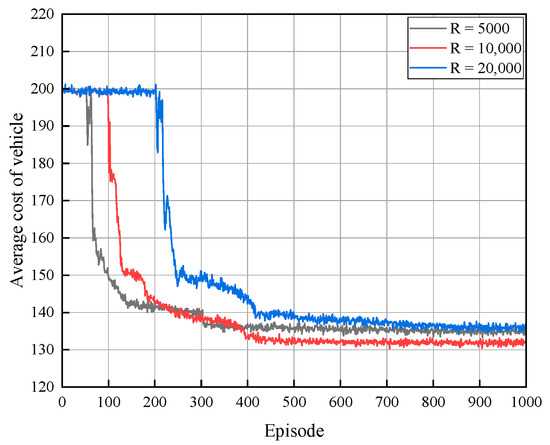
Figure 4.
Average cost of vehicle with different replay buffer sizes.
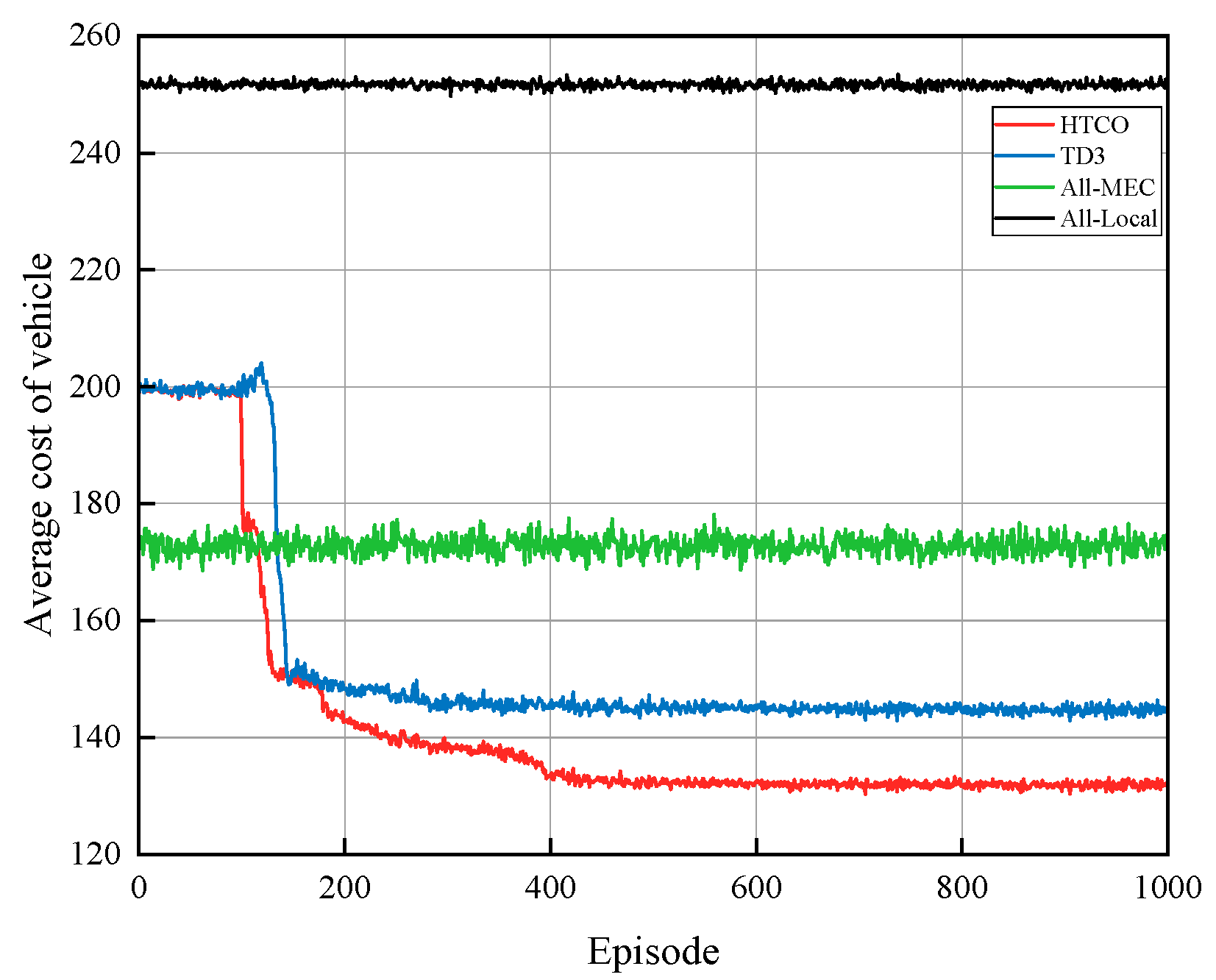
When the total bandwidth is 10 MHz and the number of vehicle users is five, Figure 5 illustrates the efficacy of the HTCO algorithm. We compare it to the other three offloading algorithms. All-MEC implies that all tasks are sent to the server for processing, All-Local implies that all tasks are computed locally; TD3 implies that the offloading decision is made through the DRL algorithm, and then the bandwidth is evenly divided among all tasks. This paper puts forward HTCO as the proposed offloading scheme that begins with the utilization of DRL to make offloading decisions, followed by the implementation of convex optimization to assign bandwidth. It can be seen that the costs of All-Local computations and All-MEC computations do not fluctuate much, the TD3 algorithm remains stable after about 300 iterations, while the HTCO algorithm proposed in this paper performs the best in terms of cost reduction because the HTCO algorithm optimally allocates the server bandwidth resources through convex optimization, which reduces the transmission time. This experiment demonstrates the efficacy of this method by showing that after 400 iterations, a successful offloading decision and bandwidth allocation scheme can be achieved, resulting in a 14%, 25%, and 48% reduction in the average cost of the vehicle when compared to TD3, All-MEC, and All-Local, respectively.
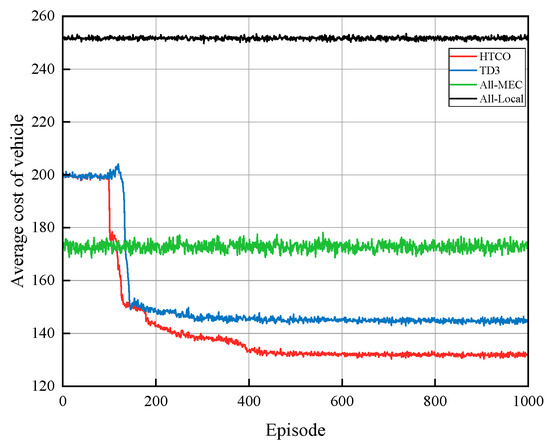
Figure 5.
Average cost of vehicle under different algorithms.
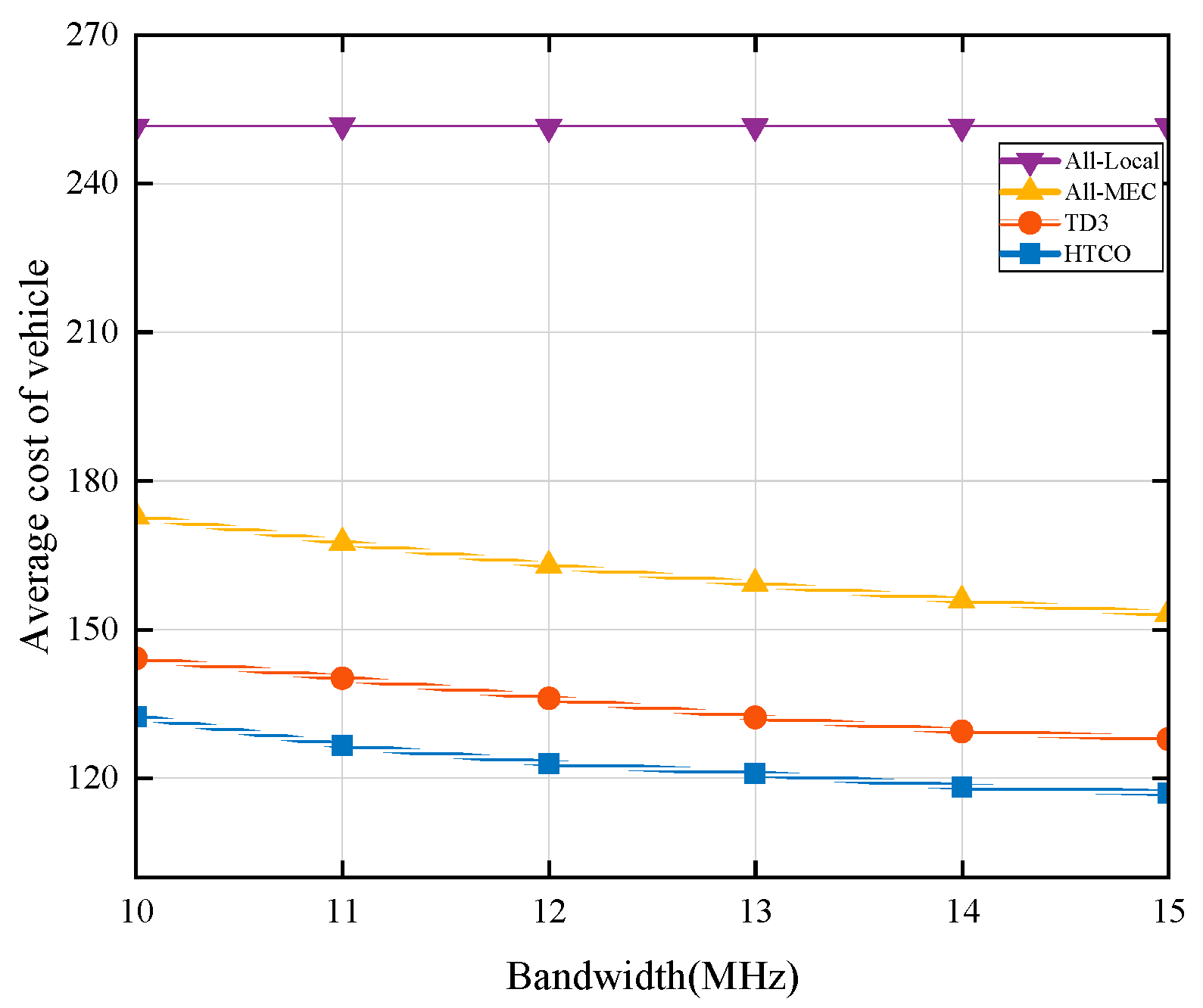
Figure 6 shows the effect on the average vehicle cost when the number of vehicle users is five and the bandwidth size varies from 10 MHz to 15 MHz. From the figure, it can be seen that as the wireless bandwidth resource increases, the average vehicle cost decreases for the HTCO, TD3, and All-MEC schemes, while the average vehicle cost remains stable for the All-Local scheme. This is because as the bandwidth increases, the transmission rate of the vehicle task also increases, resulting in a decrease in transmission delay. The average cost of the All-Local scheme remains unchanged because it only uses the computational resources within the vehicle to process the tasks. Compared to the TD3 scheme, the HTCO algorithm proposed in this paper has a lower system cost for different system bandwidths because the HTCO algorithm optimally allocates the bandwidth resources in advance according to the task size, which reduces the transmission delay of the tasks. At a total bandwidth of 15 MHz, the average cost of the HTCO strategy is reduced by about 9%, 22%, and 54% compared to TD3, All-MEC, and All-Local, respectively. These results show that the scheme proposed in this paper performs well in reducing the system overhead.
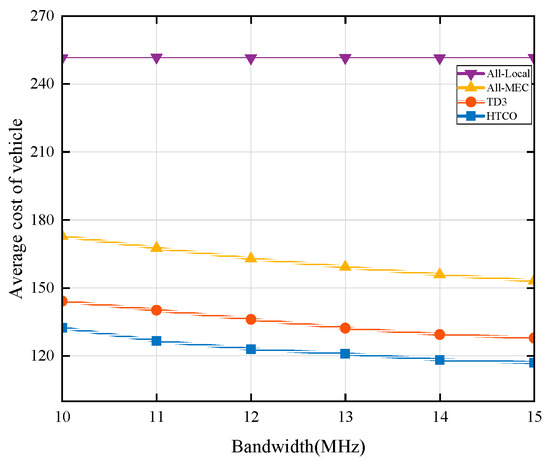
Figure 6.
Comparison of average vehicle cost at different bandwidths.
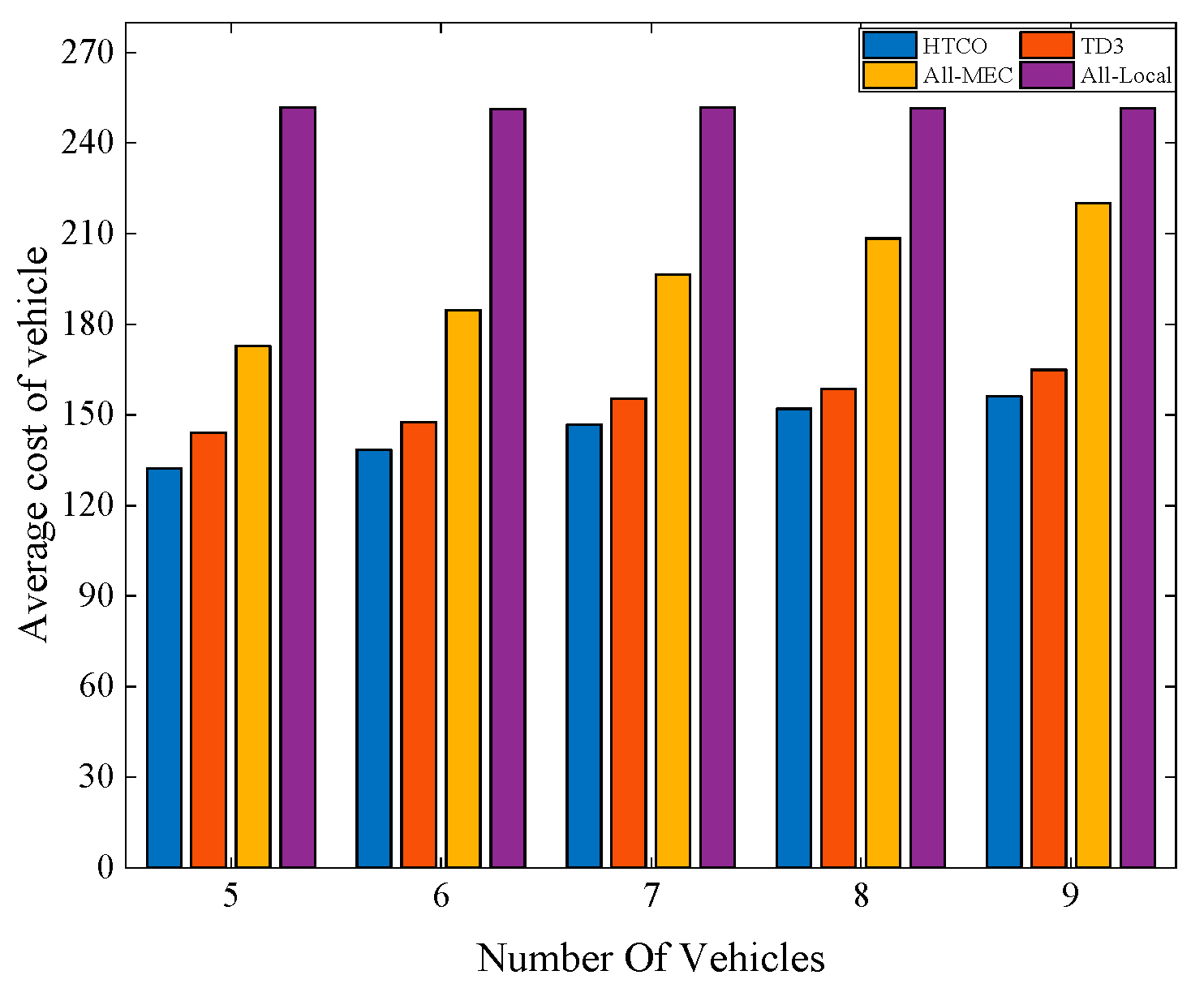
Figure 7 illustrates the average cost of vehicles for the four offloading schemes for different numbers of vehicle users, with a total system bandwidth of 10 MHz and several vehicles between 5 and 9. It can be seen that as the number of users increases, the average cost of the vehicles increases for all but the local processing task, while the cost of local processing remains essentially constant. This is because the bandwidth available to be allocated to each user decreases with the increase in the number of users, while the total bandwidth of the system remains unchanged, and the decrease in bandwidth leads to a decrease in the transmission rate of the system, which, in turn, leads to an increase in the transmission latency, while the local processing remains essentially unchanged because it does not need to transmit the computational tasks and only uses the computational resources local to the vehicle for processing. When the number of vehicles is nine, the scheme proposed in this paper outperforms the other schemes by reducing the average vehicle cost by about 8%, 28%, and 37% compared to TD3, All-MEC, and All-Local, respectively. This further demonstrates the advantage of the proposed algorithm in reducing the vehicle cost.
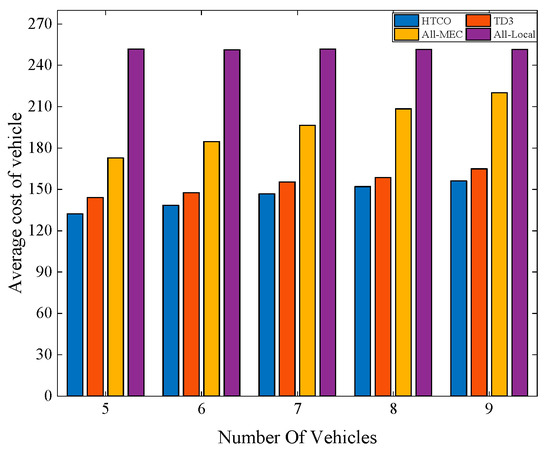
Figure 7.
Average cost of the vehicle with different numbers of vehicles.
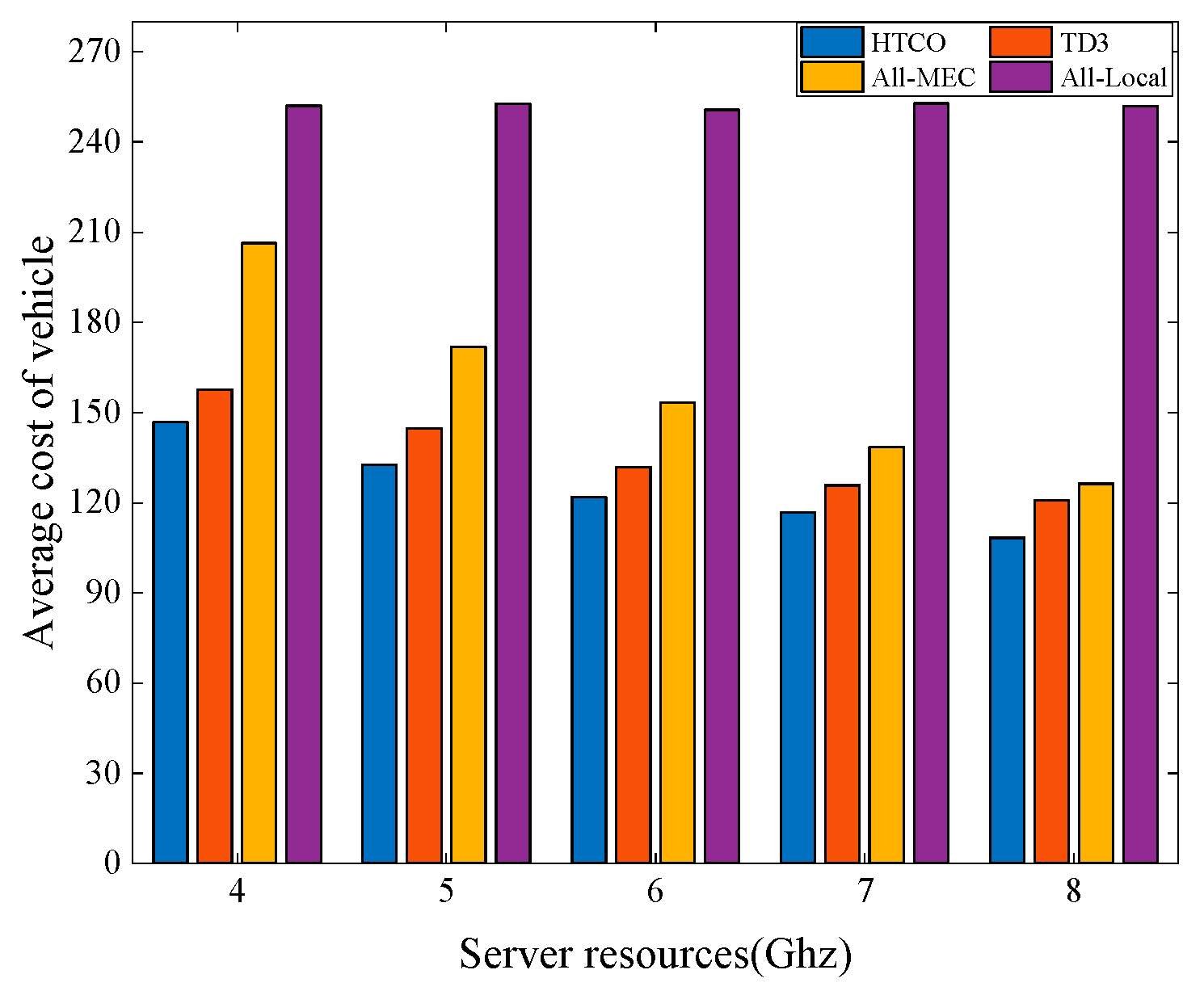
Figure 8 shows the average vehicle cost for the four offloading schemes under different server computing frequencies, with a total system bandwidth of 10 MHz and the number of task vehicles is five. From Figure 8, it is clear that the cost of all schemes except All-Local processing decreases as the MEC computation frequency increases. This is because MEC with more computing power can help users to compute tasks quickly, thus reducing system latency, while local processing does not use server computing resources, so the average cost is unchanged. Compared with TD3, All-MEC, and All-Local, the average cost of the scheme in this paper is reduced by about 11%, 13%, and 57%, respectively. With different server computing power, it is clear that the approach suggested in this research has the lowest overall system cost.
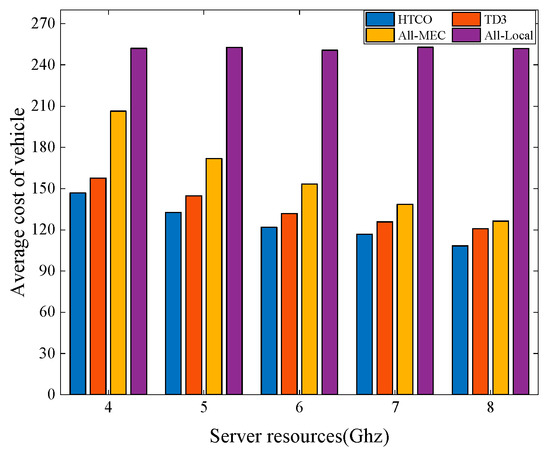
Figure 8.
Average cost of the vehicle with different calculation frequencies of servers.
Figure 9 shows the average cost of the vehicles for the four offloading schemes for different task data volumes. From the experimental results, it is clear that an increase in the amount of computational task data affects the average cost of the vehicle by affecting the processing time and transmission time of the task, and, thus, the average cost of the vehicle. Tasks must be transmitted to the MEC server for execution via wireless communication, which increases the time cost of transmission. As the number of computational tasks increases, HTCO can achieve better performance than TD3, All-Local, and All-MEC due to HTCO’s ability to allocate bandwidth resources and normalize input states. When the task data size is 70M, HTCO achieves better performance than TD3, All-Local, and All-MEC by approximately 9.1%, 31%, and 103%, respectively.
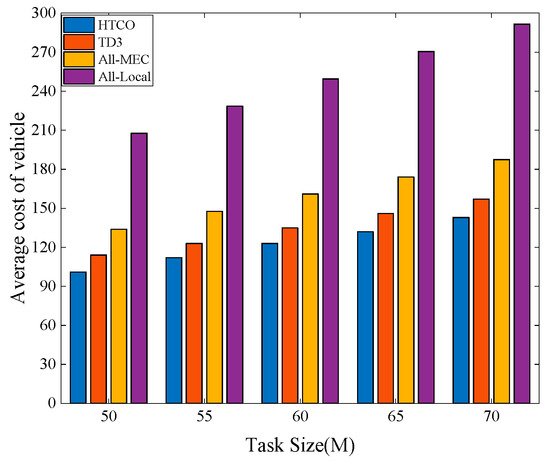
Figure 9.
Average cost of the vehicle with different task sizes.
After the above experiments, it can be seen that under the premise of changing environmental parameters, such as the number of vehicles, bandwidth size, and server computing resources, the HTCO algorithm proposed in this paper always outperforms the other comparative algorithms because the algorithm proposed in this paper can make a better offloading decision under different environmental conditions compared to the other algorithms, and it can optimally allocate the communication resources to reduce the cost of the vehicles and improve the average utility of the vehicles.
6. Conclusions
The multi-user offloading system in IoV scenarios was studied in this paper, and we proposed a novel deep reinforcement learning combined with convex optimization for the dynamic edge hybrid task offloading method, HTCO, to reduce the energy consumption and delay of computing offloading strategies while taking into account the mobility of vehicles and the time-varying characteristics of the channel. The proposed algorithm can select different offloading decisions for different task characteristics and network states, construct the dynamic computational offloading problem as an MDP, make the offloading decisions through deep reinforcement learning, and then use convex optimization for bandwidth allocation. Simulation experiments show that the HTCO algorithm can effectively reduce task processing delay and energy consumption. The algorithm has a great application prospect in the combined consideration of delay and energy consumption in dynamic vehicle networking scenarios; however, the algorithm only investigates the offloading strategy for multi-vehicle users under a single server, which is not able to continue the task offloading once it exceeds the coverage of the server, and it does not consider the security problem during offloading; therefore, the joint optimization problem in multi-server environments will be considered later, as well as offloading problems in conjunction with privacy preservation.
Author Contributions
Conceptualization, Z.J., Z.L. and X.P.; methodology, Z.J., Z.L. and X.P.; software, Z.L. and Z.J.; validation, Z.L. and X.P.; formal analysis, Z.L.; investigation, Z.J. and Z.L.; resources, Z.J. and Z.L.; writing—original draft preparation, Z.J.; writing—review and editing, Z.J. and Z.L.; visualization, Z.J.; supervision, Z.J. All authors have read and agreed to the published version of this manuscript.
Funding
This work was supported by the National Natural Science Foundation of China Youth Fund (62202145).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Storck, C.R.; Duarte-Figueiredo, F. A Survey of 5G Technology Evolution, Standards, and Infrastructure Associated with Vehicle-to-Everything Communications by Internet of Vehicles. IEEE Access 2020, 8, 117593–117614. [Google Scholar] [CrossRef]
- Feng, C.; Han, P.; Zhang, X.; Yang, B.; Liu, Y.; Guo, L. Computation offloading in mobile edge computing networks: A survey. J. Netw. Comput. Appl. 2022, 202, 103366. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and resource allocation with general task graph in mobile edge computing: A deep reinforcement learning approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Arena, F.; Pau, G.J. When Edge Computing Meets IoT Systems: Analysis of Case Studies. China Commun. 2020, 17, 14. [Google Scholar] [CrossRef]
- Li, Y.; Ma, H.; Wang, L.; Mao, S.; Wang, G. Optimized Content Caching and User Association for Edge Computing in Densely Deployed Heterogeneous Networks. IEEE Trans. Mob. Comput. 2020, 21, 2130–2142. [Google Scholar] [CrossRef]
- Zhang, J.; Ben Letaief, K. Mobile Edge Intelligence and Computing for the Internet of Vehicles. Proc. IEEE 2019, 108, 246–261. [Google Scholar] [CrossRef]
- Khan, W.U.; Nguyen, T.N.; Jameel, F.; Jamshed, M.A.; Pervaiz, H.; Javed, M.A.; Jäntti, R. Learning-based resource allocation for backscatter-aided vehicular networks. IEEE Trans. Intell. Transp. Syst. 2021, 23, 19676–19690. [Google Scholar] [CrossRef]
- Fatemidokht, H.; Rafsanjani, M.K.; Gupta, B.B.; Hsu, C.H. Efficient and Secure Routing Protocol Based on Artificial Intelligence Algorithms With UAV-Assisted for Vehicular Ad Hoc Networks in Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4757–4769. [Google Scholar] [CrossRef]
- Yue, X.; Liu, Y.; Wang, J.; Song, H.; Cao, H. Software Defined Radio and Wireless Acoustic Networking for Amateur Drone Surveillance. IEEE Commun. Mag. 2018, 56, 90–97. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Zhang, D.; Gong, C.; Zhang, T.; Zhang, J.; Piao, M. A new algorithm of clustering AODV based on edge computing strategy in IOV. Wirel. Netw. 2021, 27, 2891–2908. [Google Scholar] [CrossRef]
- Zhang, D.; Piao, M.; Zhang, T.; Chen, C.; Zhu, H. New algorithm of multi-strategy channel allocation for edge computing. Int. J. Electron. Commun. 2020, 126, 153372. [Google Scholar] [CrossRef]
- Wang, S.; Hu, L.; Cao, L.; Huang, X.; Lian, D.; Liu, W. Attention-based transactional context embedding for next-item recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Feng, W.; Zhang, N.; Li, S.; Lin, S.; Ning, R.; Yang, S.; Gao, Y. Latency Minimization of Reverse Offloading in Vehicular Edge Computing. IEEE Trans. Veh. Technol. 2022, 71, 5343–5357. [Google Scholar] [CrossRef]
- Zhang, J.; Guo, H.; Liu, J.; Zhang, Y. Task Offloading in Vehicular Edge Computing Networks: A Load-Balancing Solution. IEEE Trans. Veh. Technol. 2020, 69, 2092–2104. [Google Scholar] [CrossRef]
- Xu, J.; Li, X.; Ding, R.; Liu, X. Energy efficient multi-resource computation offloading strategy in mobile edge computing. Jisuanji Jicheng Zhizao Xitong/Comput. Integr. Manuf. Syst. 2019, 25, 954–961. [Google Scholar]
- Yang, L.; Zhang, H.; Li, M.; Guo, J.; Ji, H. Mobile edge computing empowered energy efficient task offloading in 5G. IEEE Trans. Veh. Technol. 2018, 67, 6398–6409. [Google Scholar] [CrossRef]
- Chen, H.; Todd, T.D.; Zhao, D.; Karakostas, G.J. Wireless and Service Allocation for Mobile Computation Offloading with Task Deadlines. arXiv 2023, arXiv:2301.12088. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Liao, Y.; Qiao, X.; Yu, Q.; Liu, Q. Intelligent dynamic service pricing strategy for multi-user vehicle-aided MEC networks. Futur. Gener. Comput. Syst. 2021, 114, 15–22. [Google Scholar] [CrossRef]
- Wu, Y.C.; Dinh, T.Q.; Fu, Y.; Lin, C.; Quek, T.Q.S. A Hybrid DQN and Optimization Approach for Strategy and Resource Allocation in MEC Networks. IEEE Trans. Wirel. Commun. 2021, 20, 4282–4295. [Google Scholar] [CrossRef]
- Chen, C.; Li, H.; Li, H.; Fu, R.; Liu, Y.; Wan, S. Efficiency and Fairness Oriented Dynamic Task Offloading in Internet of Vehicles. IEEE Trans. Green Commun. Netw. 2022, 6, 1481–1493. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Xia, J.; Gao, C.; Zhu, F.; Fan, C.; Ou, J. DQN-based mobile edge computing for smart Internet of vehicle. EURASIP J. Adv. Signal Process. 2022, 2022, 45. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.Z.; He, H.; Gupta, B.B.; Abd El-Latif, A.A. Joint computation offloading and task caching for multi-user and multi-task MEC systems: Reinforcement learning-based algorithms. Wirel. Netw. 2021, 27, 2023–2038. [Google Scholar] [CrossRef]
- Hazarika, B.; Singh, K.; Biswas, S.; Li, C.P. DRL-Based Resource Allocation for Computation Offloading in IoV Networks. IEEE Trans. Ind. Inform. 2022, 18, 8027–8038. [Google Scholar] [CrossRef]
- Wu, C.; Huang, Z.; Zou, Y. Delay Constrained Hybrid Task Offloading of Internet of Vehicle: A Deep Reinforcement Learning Method. IEEE Access 2022, 10, 102778–102788. [Google Scholar] [CrossRef]
- Xue, Z.; Liu, C.; Liao, C.; Han, G.; Sheng, Z. Joint Service Caching and Computation Offloading Scheme Based on Deep Reinforcement Learning in Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2023, 72, 6709–6722. [Google Scholar] [CrossRef]
- Hazarika, B.; Singh, K.; Biswas, S.; Mumtaz, S.; Li, C.P. Multi-Agent DRL-Based Task Offloading in Multiple RIS-Aided IoV Networks. IEEE Trans. Veh. Technol. 2023, 1–15. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X. Decentralized computation offloading for multi-user mobile edge computing: A deep reinforcement learning approach. J. Wireless Commn. Netw. 2020, 2020, 188. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing Function Approximation Error in Actor-Critic Methods. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Hu, X.; Huang, Y. Deep reinforcement learning based offloading decision algorithm for vehicular edge computing. PeerJ Comput. Sci. 2022, 8, e1126. [Google Scholar] [CrossRef]
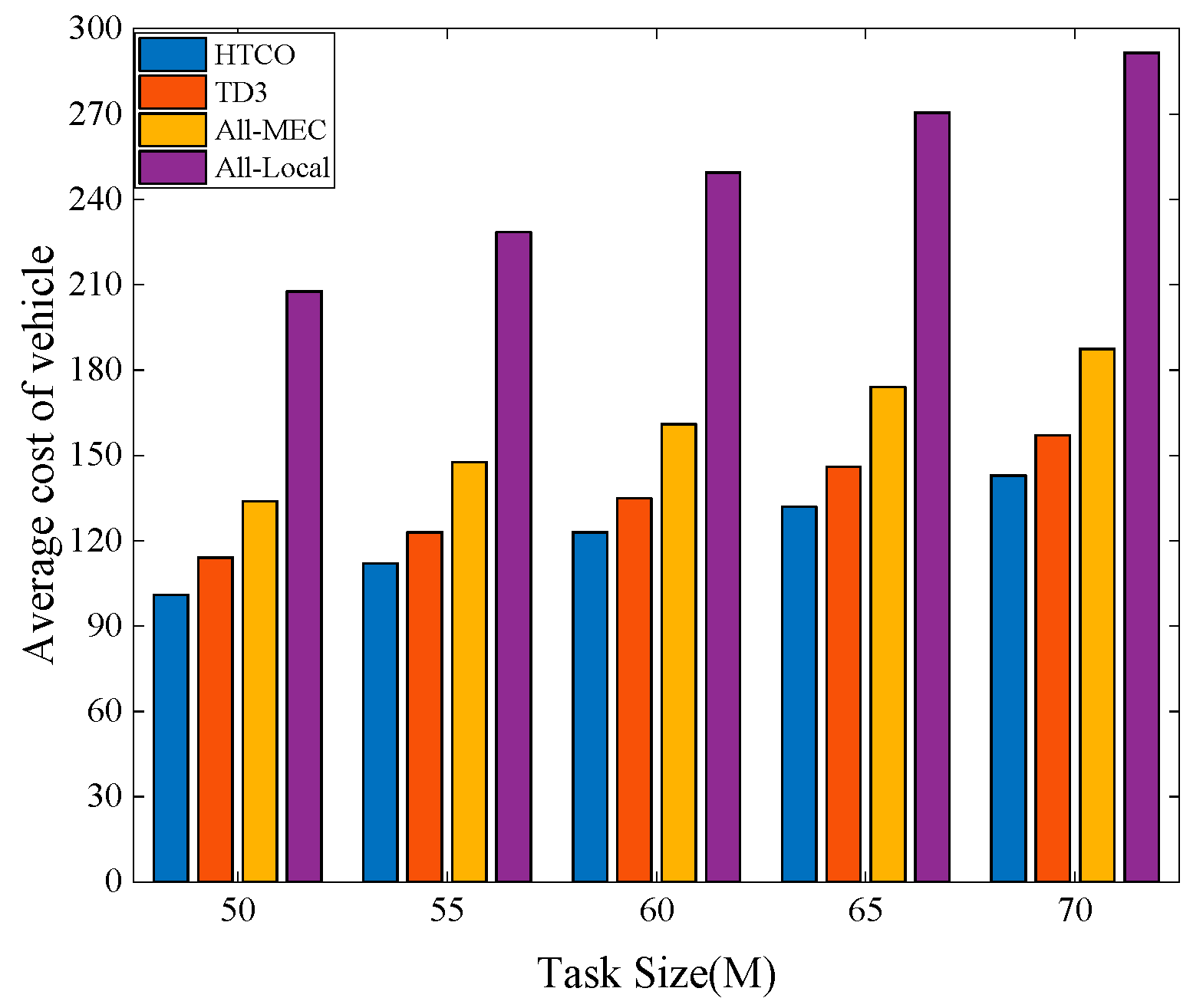
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).