5.1. Baseline System
In order for our model to learn we need to choose a loss function and an optimizer. We used
AdamW optimizer due to its fast convergence and the usage of
L2 regularization. As for the loss function, we chose BCE, as we defined before, which can be defined as BCE
= BCE(
) =
, where
y is the true value and
p is the predicted probability of belonging to the class:
The set of hyperparameters for our baseline model is presented in
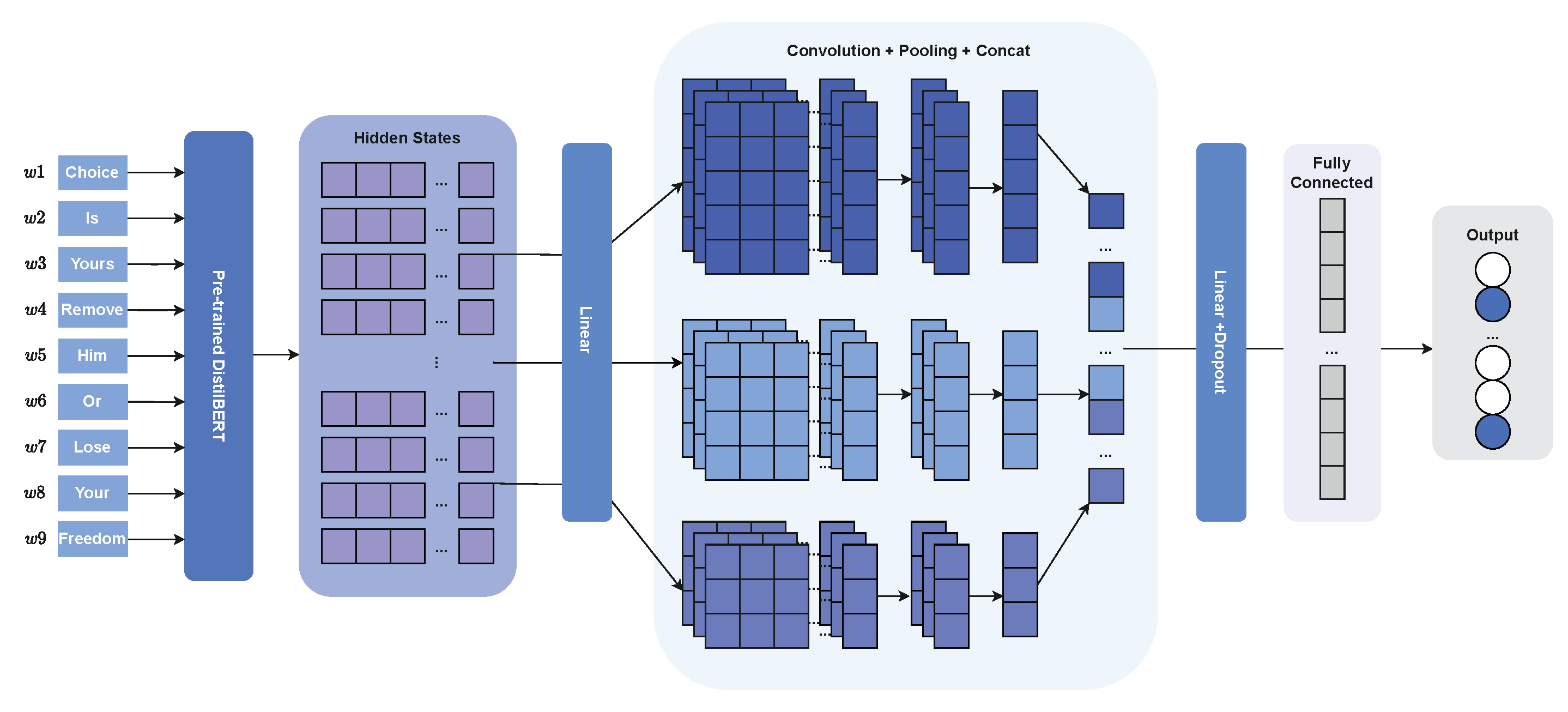
Table 4. The values chosen, except for kernel dimensions and hidden layer dimension, were not chosen for any particular reason apart from being in a range of common values for each hyperparameter. Kernel dimension’s value was the one chosen by [
14] and, for the hidden layer dimension, we went with the same dimension as the DistilBERT hidden state.
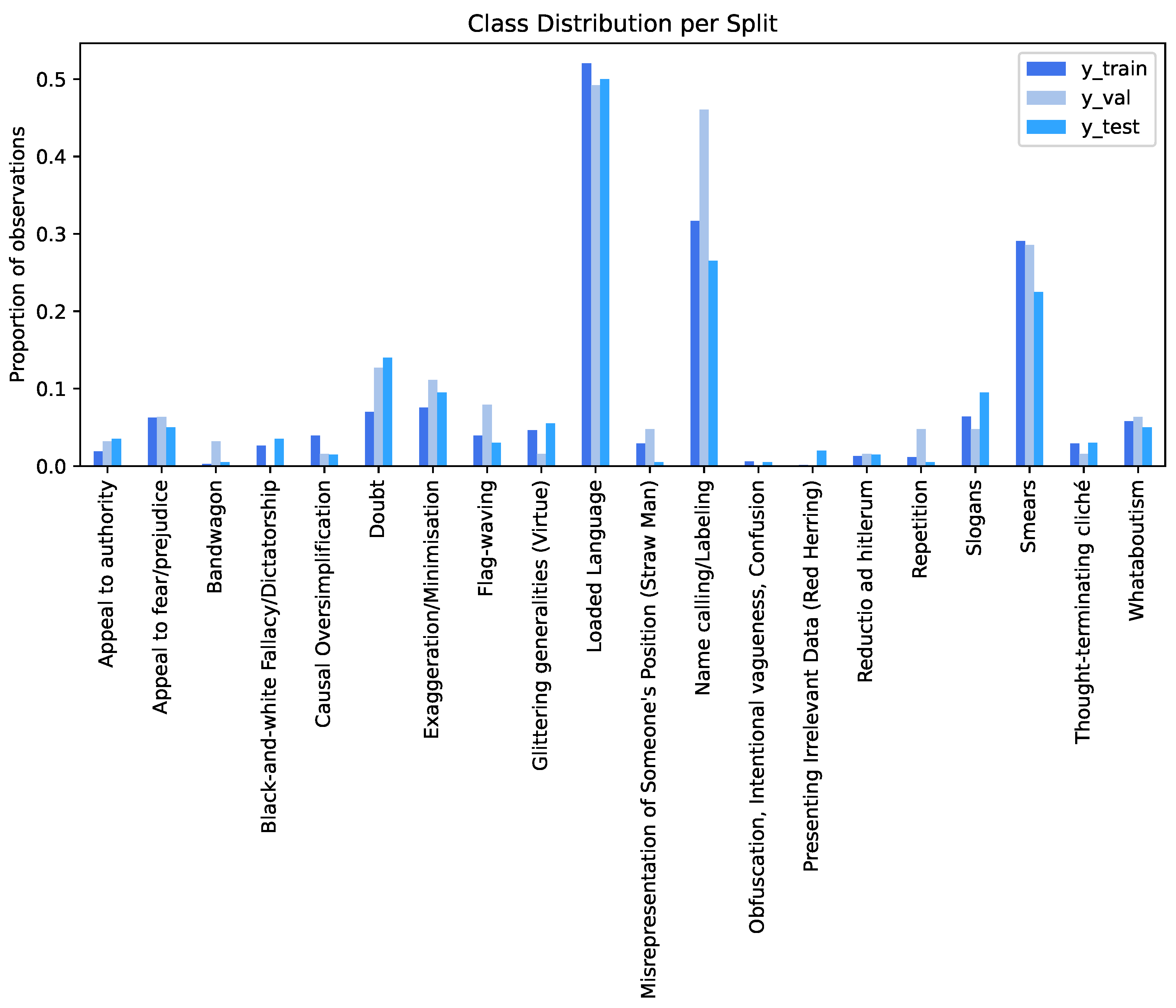
By running the experiments for the baseline model, we confirmed the expected: a great improvement over the experiments on
Section 3 with a Micro F1-score of 0.516, yet there was still some inability to make correct predictions for the least represented classes, with 13 out of 20 classes having an F1-score of 0, as can be observed in
Table 5. This inability is greatly reflected on the Macro F1-score (0.116), which gives the same weight to each class.
5.2. Loss Functions
When dealing with imbalanced datasets in multi-label classification tasks the choice of the loss function can have a huge impact on the model’s performance, especially on the least represented classes [
4]. Although Binary Cross Entropy can be used, it might not be the most suitable loss function for this problem as it does not deal with the imbalanced data problem. By not doing so, the system will struggle to properly compute the gradient for less popular classes, which will result in the inability to accurately predict in the cases that are hardest to classify.
Hard-to-classify examples are defined as misclassified ones (for instance a false positive). This issue was addressed in [
16] where the researchers took Binary Cross Entropy as a starting point and added a modulating factor of
. This type of loss would be called
FL and would be given by
Setting reduces the relative loss for well-classified examples, putting more focus on hard misclassified examples. When an example is misclassified (), the modulating factor is nearer to 1 and the loss is unaffected. As gets closer to 1 the factor goes to 0 and the loss for well-classified examples is down-weighted.
In the original paper [
16], the researchers found
produced the best results, and, because of that, we also set the parameter with the same value.
Although effective when it comes to classify hard to predict classes, Focal Loss presents a trade-off: Setting high
to sufficiently down-weight the contribution from easy negatives may eliminate the gradients from the rare positive samples. This behaviour can be troublesome, especially in situations where predicting a false negative is more costly. To address this issue a new loss function was proposed:
ASL [
17].
Asymmetric Loss relies on two principles, Asymmetric Focusing and Asymmetric Probability Shifting. The first principle decouples the focusing levels of the positive and negative samples so that
and
are the respective focusing parameters. Using it, we can redefine the loss as follows:
This mechanism is able to reduce the contribution of negative samples to the loss when their probability is low; however, it might not be very effective when class imbalance is very high. Rather than just reducing the contributions, Asymmetric Probability Shifting fully discards negative samples when their probability is very low. This principle,
, is given by:
where the probability margin
is a tunable hyperparameter.
By integrating
into
, we obtain the definition of Asymmetric Loss:
With ASL, we use both soft thresholding and hard thresholding to reduce the loss function contribution of easy negative samples. Soft thresholding uses the focusing parameters , and hard thresholding uses the probability margin m.
For our experiments, we followed the values suggested by the original paper [
17] researchers, with
,
and
. By setting
, the positive samples will incur simple cross entropy loss, and control the level of asymmetric focusing via a single hyperparameter,
.
Table 6 presents the F1-score per class in models using Focal Loss and Asymmetric Loss. These experiments show the importance of choosing the right loss function, as both Focal Loss and Asymmetric Loss improved our model’s performance, especially when considering the less represented classes. This statement is confirmed when comparing
Table 5 and
Table 6.
Moving from the analysis per label to the overall performance, when training using Focal Loss and using Asymmetric Loss, the model assessment results are displayed in
Table 7.
5.3. Final Evaluation
In order to compare our system’s results with the ones from SemEval, we trained our model in the dev+train set and used the test set for evaluation.
When we compare the results between our model (FM) and the best system in the SemEval challenge (MinD), we realize that they are very similar for most of the classes, as we can see in
Table 8. With the two most represented classes (Loaded Language and Name Calling) achieving very good results and other classes such as Smears and five other classes having acceptable results. Nonetheless, the model is still unable to predict classes such as Red Herring and Bandwagon, which re-affirms the impact of having few samples in an imbalanced dataset.
The system’s Micro and Macro F1-scores are presented in
Table 9, where our model would be placed in 3rd. It performed worse than two other models; however, it should be taken into account that it is also the smallest model, containing the fewest tunable hyperparameters of all three. The MinD [
8] model uses an ensemble of five transformers, such as RoBERTa and BERT and XLNET. The Volta [
9] model is smaller when compared with MinD, since it uses only one transformer followed by two linear layers and dropout, but the base transformer is a RoBERTa Large, which has 355 million tunable parameters. In comparison, our whole model has around 68 million parameters.






{kind=link}
{kind=link}