3.1. Problem Definition
Few-shot class incremental learning (FSCIL) is a learning paradigm that involves continuously training a model using a sequential stream of few shot labeled samples. This approach assumes that old task samples are no longer accessible during the learning of new few-shot tasks. Formally, we define the training set, label set, and test set as X, Y, and Z, respectively. The training process involves a sequence of labeled training datasets denoted as , ,…,. Here represents the training set for the t-th session, represents the corresponding label set, and T represents the total number of incremental learning sessions. In each incremental session, the number of training samples is limited, and the task is described as “N-way K-shot”. This means that in each incremental session, the dataset is divided into N classes, with K samples in each class. The FSCIL base session involves initially training the model on a base task that includes a sufficient number of instances in the training set and the corresponding label set . Each training set is constructed such that it contains no repeated class labels in the incremental learning, i.e., and , . For each , the training set corresponds to a set of few-shot samples for new classes introduced in the t-th incremental learning session. It should be noted that the size of is smaller than the size of . For example, in the case of a 10-way 5-shot setting, each incremental process (i.e., ) would contain ten new classes each with only five training samples.
In few-shot class incremental learning, we encounter two key challenges: (i) Limited availability of training data for new classes poses difficulties in effectively learning knowledge about these classes. (ii) We need to mitigate catastrophic forgetting in order to ensure the retention of previously learned knowledge. In this work, our primary objective is to address these challenges by emphasizing two key aspects. Firstly, we can project the center of each class onto the Grassmann manifold as patterns and calculate the distances between training samples and their corresponding class patterns. This approach preserves the geometric properties of each class, reduces the risk of overfitting, and enhances adaptability to new classes during the incremental learning process, thereby facilitating better learning of new classes. Secondly, taking into consideration that human knowledge does not exist in isolation but rather within a knowledge structure [
17], our objective is to leverage the Grassmann manifold metric to construct a neighborhood graph. Additionally, we aim to preserve the inter-class structural information of the learned classes through the use of information entropy. This approach helps mitigate the occurrence of catastrophic forgetting during the incremental learning.
3.2. Overview
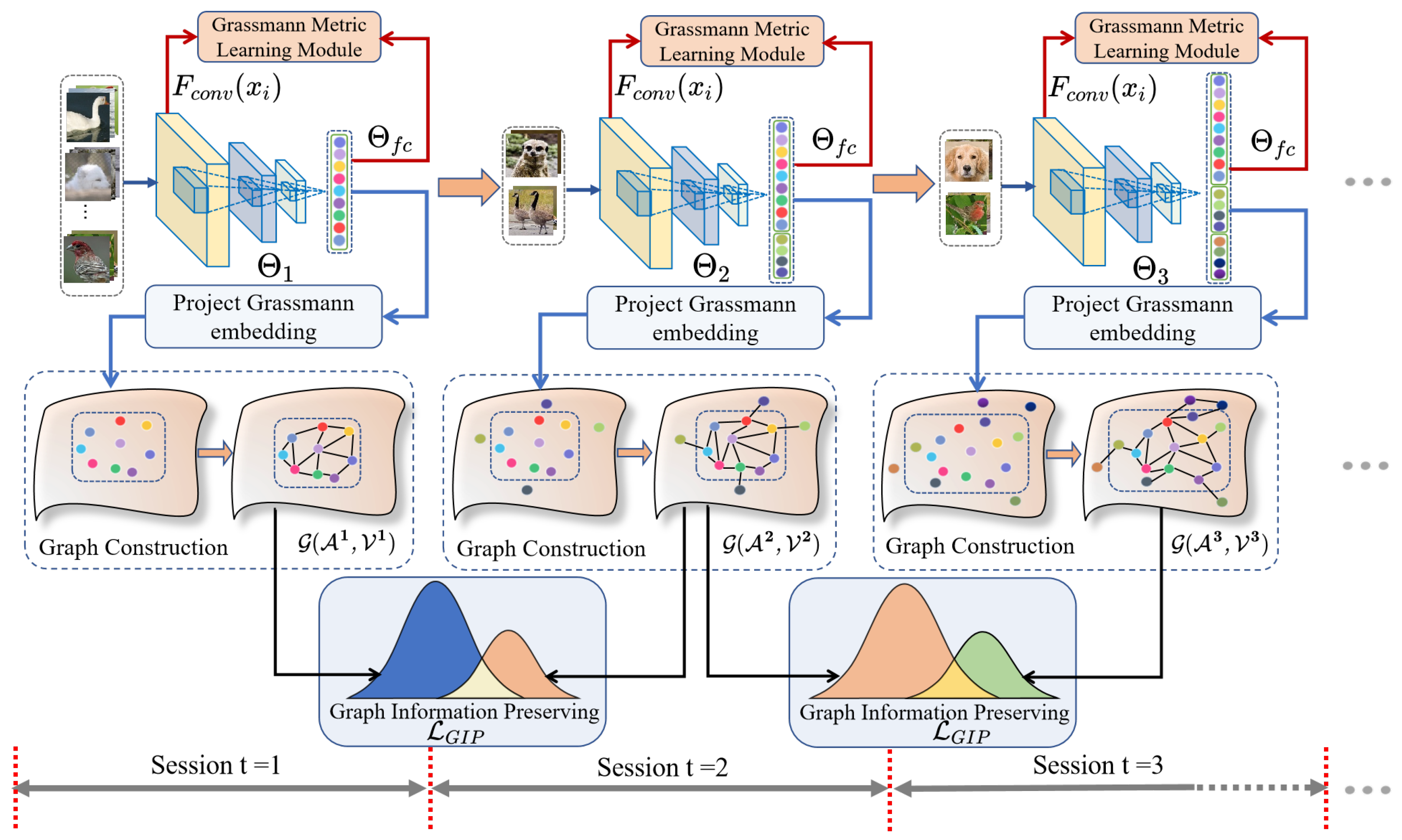
The proposed Grassmann Manifold and Information Entropy for Few-Shot Class Incremental Learning (GMIE-FSCIL) framework is presented in
Figure 1, and the Grassmann Metric Learning module is presented in
Figure 2. In general, the base network
is initially trained on a large training dataset
by the classical cross-entropy loss function on Euclidean space. However, during the incremental learning process (
), neural networks often encounter difficulties in effectively learning knowledge about new classes due to the limited samples. To mitigate this issue, we propose the Grassmann Metric Learning (GML) module, which addresses the problem by quantifying the distance between each training sample and its respective class pattern onto the Grassmann manifold. This method helps maintain the geometric properties of the samples, minimize the risk of overfitting, and enhance adaptability to new classes throughout the incremental learning process. As a result, it promotes the improved acquisition of knowledge related to new classes.
In incremental learning sessions, it is crucial to not only focus on learning new knowledge but also mitigate the issue of catastrophic forgetting. To address this issue, we designed the Graph Information Preserving (GIP) module to preserve the adjacency relationships among previously learned classes, thus preventing the network from forgetting the knowledge it has learned. Specifically, we embed network parameters onto the Grassmann manifold by an orthogonalization method. This approach allows for a better description of the properties of the parameter’s linear subspace while preserving the learned knowledge, ultimately enhancing adaptability to new classes with few shot samples. At each learning stage t, we utilize the metrics of the Grassmann manifold to construct a neighborhood graph that describes the adjacency relationships among the learned classes. Here, represents the adjacency weights, and represents class centers. The neighborhood graph depicts the correlations between learned classes and dynamically update on the Grassmann manifold. Subsequently, we employ information entropy to maintain the structural relationships with the neighborhood graph , further preserving the adjacency relationships among the previously learned classes, thus alleviating the problem of catastrophic forgetting. Therefore, this method proves viable throughout the incremental learning process, as it concurrently preserves both geometric characteristics and structural relationships.
3.3. Grassmann Metric Learning
In few-shot incremental learning, due to the limited samples for new classes, neural network often struggle to effectively learn knowledge about these new classes. We leverage the properties of the Grassmann manifold’s linear subspaces to enable the model to better acquire knowledge about the new classes during the incremental learning sessions. The Grassmann manifold, a special type of Riemannian manifold, is employed for the embedding of p-dimensional linear subspaces within a d-dimensional Euclidean space. Its mathematical formulation is defined as , which X denotes any point on the Grassmann manifold.
We have designed a Grassmann Metric Learning module that projects the pattern of each class
onto the Grassmann manifold. It metrics the distances between each training sample and the corresponding class pattern onto the Grassmann manifold, aiding the model in more effectively learning knowledge about new classes. Specifically, we employ Householder transformation [
37] to orthogonalize the pattern
of each class, enabling their projection onto the Grassmann manifold:
where,
represents the projection of class
c on the Grassmann manifold, and
denotes the set of each class patterns on the Grassmann manifold, respectively.
Subsequently, we calculate the distance between a convolutional feature of sample
and its corresponding class pattern
, transforming it into the Euclidean-to-Grassmann metric [
38], which can be expressed as:
By projecting the pattern of each class onto the Grassmann manifold and measuring the distance between each training sample and the pattern of the corresponding class onto the Grassmann manifold, we enhance the model’s learning ability, enabling it to better learn knowledge about new classes. Therefore, we refer to it as the Grassmann Metric Learning module:
The learning objective comprises the traditional cross-entropy loss and , with serving as a hyperparameter.
3.4. Graph Information Preserving
In few-shot class incremental learning, another key issue is the catastrophic forgetting of previously learned knowledge. It’s noteworthy that in the human brain, learned knowledge is not isolated; there exists a structure among the learned knowledge to maintain their relationships [
17]. Therefore, we propose a Graph Information Preserving module to embed the incremental model parameters onto the Grassmann manifold, better compensating for the drift in incremental model parameters. Additionally, this module maintains the structural relationships among previously learned classes by information entropy, thereby mitigating the catastrophic forgetting of previously learned knowledge.
To begin with, we aim to embed the parameters of each layer, denoted as
, from the incremental model
onto the Grassmann manifold. This necessitates the orthogonalization of each layer’s parameters, where
belongs to the
, and
l denotes the layer number (i.e.
). Consequently, we introduce an orthogonalization function
to perform orthogonalization on the parameters
and subsequently embed them onto the Grassmann manifold. Recall that for an orthogonalized matrix
, it should satisfy the condition:
. If we consider an arbitrary vector
, the orthogonalization function
can then be defined as:
Here,
, and
is a small value [
39]. To find the minimum of the function
, we can first define the spectral norm of the matrix
as:
. Subsequently, based on Equation (
4), the problem of parameter orthogonalization can be reformulated as the minimization of the spectral norm of the matrix
:
Embedding the parameters of the incremental model onto the Grassmann manifold aids in retaining the learned intra-class knowledge while enhancing its capacity to adapt to new tasks characterized by few shot samples.
In the next step, we establish structural relationships by constructing a neighborhood graph
on the Grassmann manifold. In the
t-th incremental session, a neighborhood graph
is constructed to denote the structural relationships among the learned knowledge on the Grassmann manifold, with
and
denoting the corresponding adjacency weight matrix and node set. We utilize the learned Grassmann embedding of the fully-connected layer parameters for the corresponding classes in the
t-th session to compose the graph node set
, expressed as
. where,
denotes the learned Grassmann embedding for the
k-th class, and
represents the total number of classes learned to the
t-th session. Subsequently, to effectively extract the inter-class structural relationships, leveraging the previously learned Grassmann embedding, we can calculate the adjacency weight
, which represents the correlation between the two learn class embedding
,
and
:
We can utilize the constructed neighborhood graph to maintain the structural relationships among the learned classes in previous sessions. This is achieved by imposing constraints on the Grassmann embedding of learned classes. To prevent the forgetting of knowledge from previously learned classes, we calculate information entropy between the
t-th and
-th sessions (i.e.,
) using the constructed neighborhood graph, thus preserving the structural relationships of the learned classes During each learning session
t, it is possible to efficiently retain the relevant node set
. This retained data can later be utilized in upcoming sessions to uphold the relative configurations of the Grassmann embedding of the classes learned during the
t-th stage. To provide a more specific example, in the
t-th incremental session, where
represents the matrix comprising the Grassmann embedding of all the learned classes, we can also calculate
based on the preserved
. Next, we introduce the application of the max mutual information method based on information entropy, which effectively maintains the structural relationships among different class embedding, expressed as:
where, the first
rows which corresponds to the classes learned in the
-th session of
as
,
represents the Shannon entropy information of
, while the conditional entropy
denotes the entropy of
under the condition of
. To solve Equation (
7), we can transform it into a maximum mutual information, which can be represented as follows:
where,
is a discriminant function.
represents the expectation of the joint distribution of
and
, while
denotes the expectation of the margin distributions of
and
. In the Graph Information Preserving module, we optimized the full connection parameters
through Grassmann embedding using an entropy-based approach to alleviate the catastrophic forgetting of learned knowledge.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}