Frame Duplication Forgery Detection in Surveillance Video Sequences Using Textural Features



Abstract
:1. Introduction
- We introduce a robust and efficient inter-frame duplication forgery detection method for digital video sequences.
- We apply single-level 2-D discrete wavelet transform (2DWT) decomposition for each frame in the forged video sequences.
- We employ GLCM for the DWT coefficients to extract textural features from each frame. Then, we combine it with other statistical features for the features’ representation.
- We evaluate the proposed method performance compared with other SOTA methods on two established datasets. The experimental results show the efficacy of the proposed method for detecting frame duplication forgery from the surveillance videos.
2. Related Work
3. Proposed Method
3.1. 2-D Wavelet Decomposition
3.2. Frame Textural Feature Extraction
3.3. Frame Feature Matching
4. Experimental Results and Analysis
4.1. Dataset Preparation
4.2. Implementation Details
4.3. Evaluation Metrics
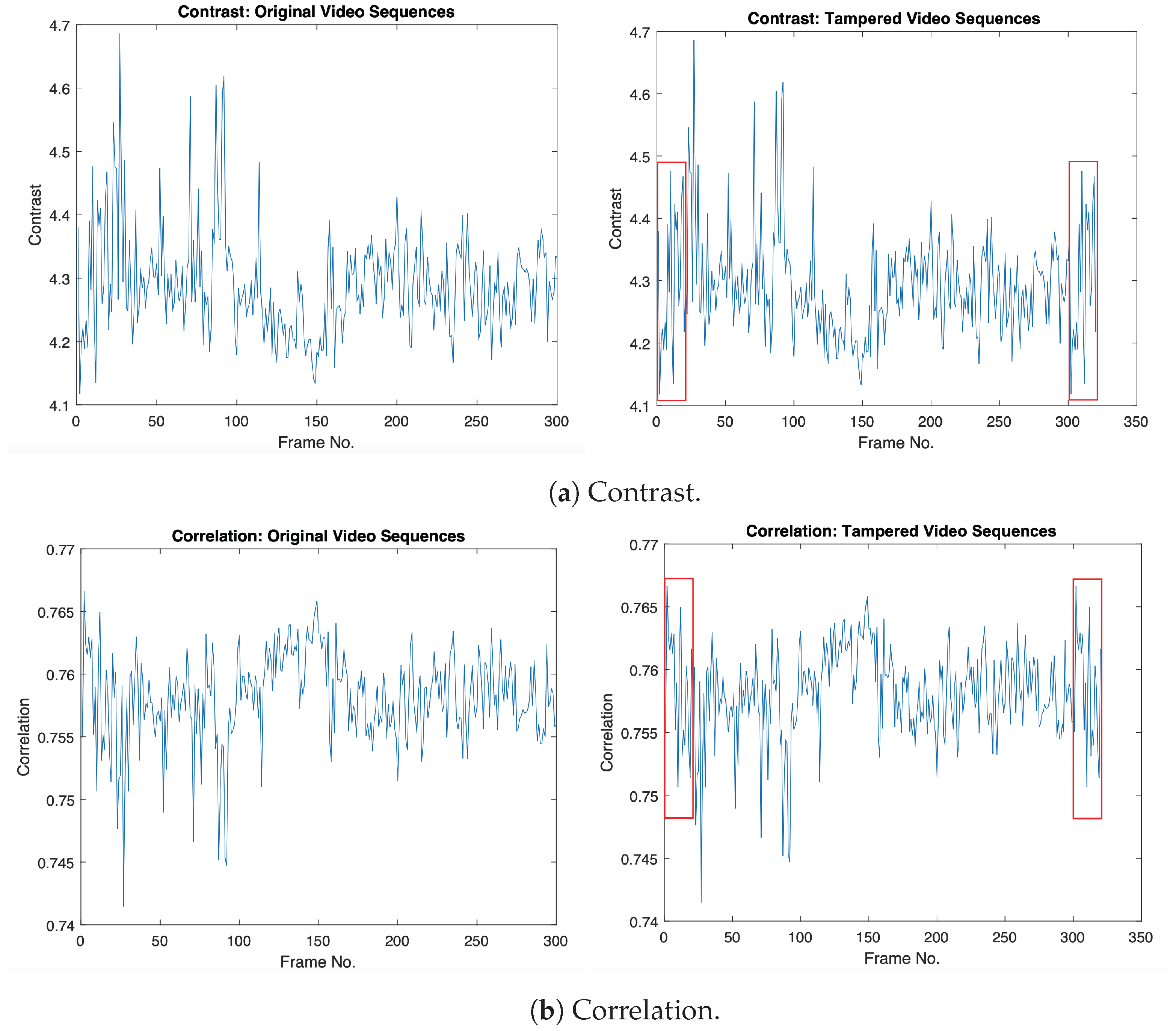
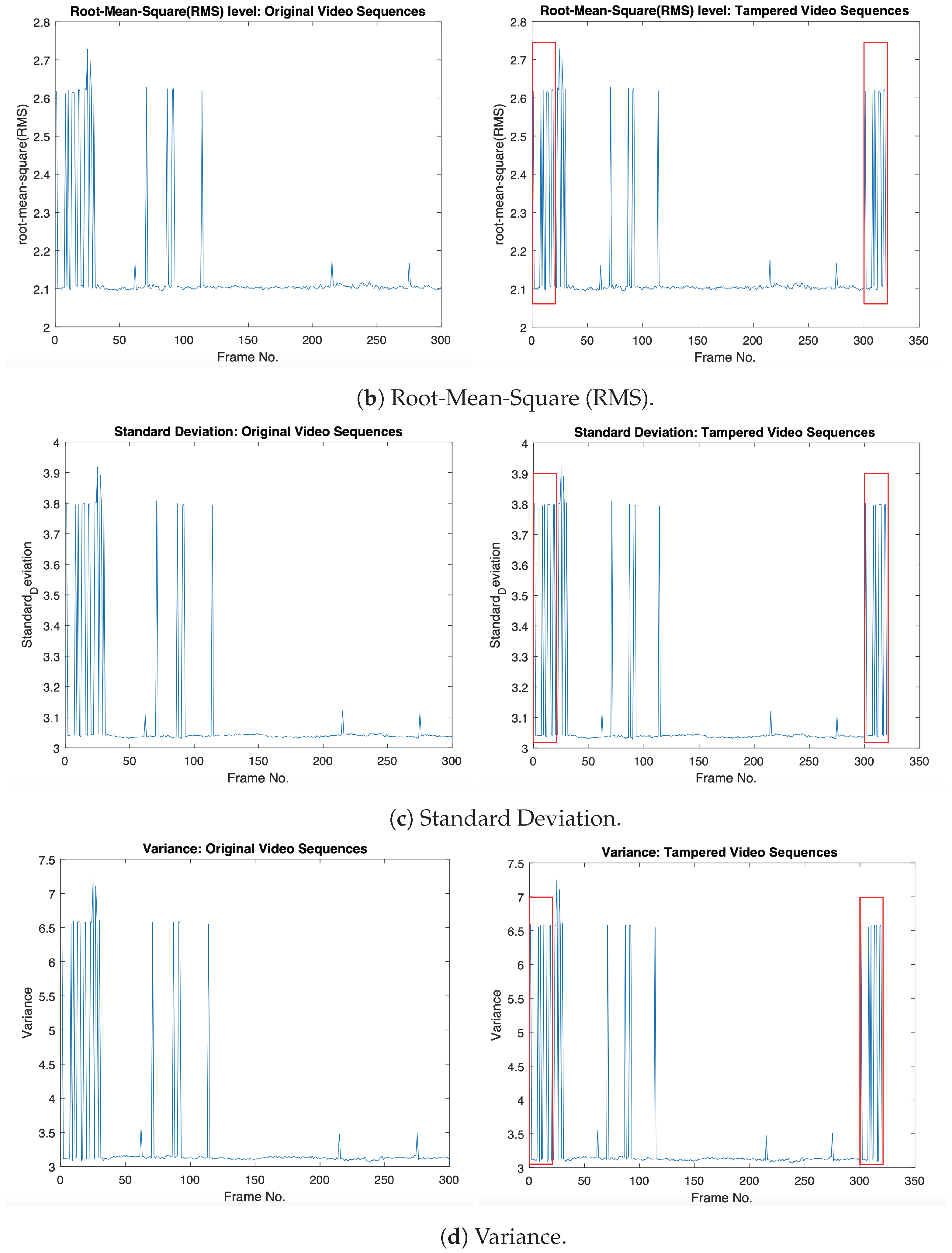
4.4. Visualization Results
4.5. Performance Evaluation and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vennam, P.; T. C., P.; B. M., T.; Kim, Y.-G.; B. N., P.K. Attacks and preventive measures on video surveillance systems: A review. Appl. Sci. 2021, 11, 5571. [Google Scholar] [CrossRef]
- Milani, S.; Fontani, M.; Bestagini, P.; Barni, M.; Piva, A.; Tagliasacchi, M.; Tubaro, S. An overview on video forensics. APSIPA Trans. Signal Inf. Process. 2012, 1, e2. [Google Scholar] [CrossRef]
- El-Shafai, W.; Fouda, M.A.; El-Rabaie, E.S.M.; El-Salam, N.A. A comprehensive taxonomy on multimedia video forgery detection techniques: Challenges and novel trends. Multimed. Tools Appl. 2023, 1–67. [Google Scholar] [CrossRef] [PubMed]
- Shelke, N.A.; Kasana, S.S. A comprehensive survey on passive techniques for digital video forgery detection. Multimed. Tools Appl. 2021, 80, 6247–6310. [Google Scholar] [CrossRef]
- Johnston, P.; Elyan, E. A review of digital video tampering: From simple editing to full synthesis. Digit. Investig. 2019, 29, 67–81. [Google Scholar] [CrossRef]
- Akhtar, N.; Saddique, M.; Asghar, K.; Bajwa, U.I.; Hussain, M.; Habib, Z. Digital video tampering detection and localization: Review, representations, challenges and algorithm. Mathematics 2022, 10, 168. [Google Scholar] [CrossRef]
- Qadir, G.; Yahaya, S.; Ho, A. Surrey University Library for Forensic Analysis (SULFA) of video content. In Proceedings of the IET Conference on Image Processing (IPR 2012), London, UK, 3–4 July 2012; p. 121. [Google Scholar]
- Emam, M.; Han, Q.; Niu, X. PCET based copy-move forgery detection in images under geometric transforms. Multimed. Tools Appl. 2016, 75, 11513–11527. [Google Scholar] [CrossRef]
- Emam, M.; Han, Q.; Zhang, H. Two-stage Keypoint Detection Scheme for Region Duplication Forgery Detection in Digital Images. J. Forensic Sci. 2018, 63, 102–111. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Farid, H. Exposing Digital Forgeries in Video by Detecting Duplication. In Proceedings of the 9th Workshop on Multimedia & Security MM&Sec ’07; Association for Computing Machinery: New York, NY, USA, 2007; pp. 35–42. [Google Scholar] [CrossRef]
- Lin, G.S.; Chang, J.F.; Chuang, C.H. Detecting frame duplication based on spatial and temporal analyses. In Proceedings of the 2011 6th International Conference on Computer Science & Education (ICCSE), Singapore, 3–5 August 2011; pp. 1396–1399. [Google Scholar]
- Li, F.; Huang, T. Video copy-move forgery detection and localization based on structural similarity. In Proceedings of the 3rd International Conference on Multimedia Technology (ICMT 2013); Springer: Berlin, Germany, 2014; pp. 63–76. [Google Scholar]
- Singh, V.K.; Pant, P.; Tripathi, R.C. Detection of frame duplication type of forgery in digital video using sub-block based features. In Proceedings of the Digital Forensics and Cyber Crime: 7th International Conference, ICDF2C 2015, Seoul, Republic of Korea, 6–8 October 2015; Revised Selected Papers 7. Springer: Berlin, Germany, 2015; pp. 29–38. [Google Scholar]
- Sitara, K.; Mehtre, B.M. Digital video tampering detection: An overview of passive techniques. Digit. Investig. 2016, 18, 8–22. [Google Scholar] [CrossRef]
- Yang, J.; Huang, T.; Su, L. Using similarity analysis to detect frame duplication forgery in videos. Multimed. Tools Appl. 2016, 75, 1793–1811. [Google Scholar] [CrossRef]
- Fadl, S.M.; Han, Q.; Li, Q. Authentication of surveillance videos: Detecting frame duplication based on residual frame. J. Forensic Sci. 2018, 63, 1099–1109. [Google Scholar] [CrossRef] [PubMed]
- Shelke, N.A.; Kasana, S.S. Multiple forgery detection and localization technique for digital video using PCT and NBAP. Multimed. Tools Appl. 2022, 81, 22731–22759. [Google Scholar] [CrossRef]
- Bozkurt, I.; Ulutaş, G. Detection and localization of frame duplication using binary image template. Multimed. Tools Appl. 2023, 82, 31001–31034. [Google Scholar] [CrossRef]
- VTL Video Trace Library. Available online: http://trace.eas.asu.edu/yuv/index.html (accessed on 24 July 2023).
- Schremmer, C. Decomposition strategies for wavelet-based image coding. In Proceedings of the Sixth International Symposium on Signal Processing and its Applications (Cat. No. 01EX467), Kuala Lumpur, Malaysia, 13–16 August 2001; Volume 2, pp. 529–532. [Google Scholar]
- Mokji, M.; Bakar, S.A. Gray Level Co-Occurrence Matrix Computation Based on Haar Wavelet; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Guo, T.; Zhang, T.; Lim, E.; Lopez-Benitez, M.; Ma, F.; Yu, L. A review of wavelet analysis and its applications: Challenges and opportunities. IEEE Access 2022, 10, 58869–58903. [Google Scholar] [CrossRef]
- Chan, F.P.; Fu, A.C.; Yu, C. Haar wavelets for efficient similarity search of time-series: With and without time warping. IEEE Trans. Knowl. Data Eng. 2003, 15, 686–705. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Li, J.; Shi, J.; Su, H.; Gao, L. Breast cancer histopathological image recognition based on pyramid gray level co-occurrence matrix and incremental broad learning. Electronics 2022, 11, 2322. [Google Scholar] [CrossRef]
- Aouat, S.; Ait-hammi, I.; Hamouchene, I. A new approach for texture segmentation based on the Gray Level Co-occurrence Matrix. Multimed. Tools Appl. 2021, 80, 24027–24052. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame Localization Results | |||||
|---|---|---|---|---|---|
| Test Video * | Forgery Location | Wang et al. [10] | Li et al. [12] | Bozkurt et al. [18] | Ours |
| akiyo.avi | frames 1–20 are copied to 301–320 | Authentic video | Original frames 1–20, Duplication 301–320 with 192 false-matched pairs | Original frames 1–20. Duplication 301–320 | Original frames 1–20. Duplication 301–320 |
| coastguard.avi | frames 1–20 are copied to 301–320 | Authentic video, with 6 false-matched frame pairs | Original frames 1–20, Duplication 301–320 | Original frames 1–20. Duplication 301–320 | Original frames 1–20, Duplication 301–320 |
| container.avi | frames 1–20 are copied to 301–320 | Authentic video | Original frames 1–20, Duplication 301-320 with 39 false-matched frames | Original frames 1–20, Duplication 301–320, with 7 false-matched frame pairs | Original frames 1–20, Duplication 301–320 |
| flower.avi | frames 1–20 are copied to 251–270 | Original frames 1–20, Duplication 251–270, with 61 false-matched frame pairs | Original frames 1–20, Duplication 251–270 | Original frames 1–20, Duplication 251–270 | Original frames 1–20, Duplication 251–270 |
| foreman.avi | frames 1–20 are copied to 301–320 | Original frames 1–20, Duplication 301–320, with 17 false-matched frame pairs | Original frames 1–20, Duplication 301–320 | Original frames 1–20, Duplication 301–320, with 11 false-matched frame pairs | Original frames 1–20, Duplication 301–320 |
| hall.avi | frames 1–20 are copied to 301–320 | Authentic video | Original frames 1–20, Duplication 301–320 | Original frames 1–20, Duplication 301–320, with 21 false-matched frame pairs | Original frames 1–20, Duplication 301–320 |
| mobile.avi | frames 1–20 are copied to 301–320 | Original frames 1–20, Duplication 301–320, with 407 false-matched frame pairs | Original frames 1–20, Duplication 301–320 | Original frames 1–20, Duplication 301–320 | Original frames 1–20, Duplication 301–320 |
| mother daughter.avi | frames 1–20 are copied to 301–320 | Authentic video | Original frames 1–20, Duplication 301–320, with 57 false-matched frame pairs | Original frames 1–20, Duplication 301–320, with 102 false-matched frame pairs | Original frames 1–20, Duplication 301–320 |
| silent.avi | frames 1–20 are copied to 301–320 | Original frames 11–18, Duplication 311–318 | Original frames 1–20, Duplication 301–320, with 24 false-matched frame pairs | Original frames 1–16, Duplication 301–316 | Original frames 1–20, Duplication 301–320 |
| waterfall.avi | frames 1–20 are copied to 261–280 | Original frames 186–190, Duplication 193–197 | Original frames 1–20, Duplication 261–280 | Original frames 1–12, Duplication 261–272 | Original frames 1–20, Duplication 261–280 |
| Dataset | Method | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Dataset 1 * | Wang and Farid [10] | 88.90 | 87.67 | 88.28 |
| Lin et al. [11] | 92.13 | 65.42 | 76.51 | |
| Li and Huang [12] | 80.59 | 96.32 | 87.80 | |
| Singh et al. [13] | 95.64 | 79.74 | 86.97 | |
| Yang et al. [15] | 96.51 | 87.30 | 91.67 | |
| Fadl et al. [16] | 97.59 | 96.93 | 97.25 | |
| Shelke and Kasana [17] | 97.58 | 94.56 | 96.05 | |
| Bozkurt et al. [18] | 97.33 | 96.64 | 96.98 | |
| Ours | 99.60 | 100 | 99.80 | |
| Dataset 2 ** | Wang and Farid [10] | 50.01 | 35.87 | 41.78 |
| Lin et al. [11] | 72.39 | 39.76 | 51.33 | |
| Li and Huang [12] | 76.18 | 89.34 | 82.24 | |
| Singh et al. [13] | 82.94 | 40.00 | 53.97 | |
| Yang et al. [15] | 92.83 | 53.26 | 67.69 | |
| Fadl et al. [16] | 96.54 | 95.83 | 96.18 | |
| Shelke and Kasana [17] | 96.82 | 94.40 | 95.59 | |
| Bozkurt et al. [18] | 95.00 | 92.94 | 93.96 | |
| Ours | 98.42 | 96.17 | 97.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Lu, J.; Zhang, S.; Mohaisen, L.; Emam, M. Frame Duplication Forgery Detection in Surveillance Video Sequences Using Textural Features. Electronics 2023, 12, 4597. https://doi.org/10.3390/electronics12224597
Li L, Lu J, Zhang S, Mohaisen L, Emam M. Frame Duplication Forgery Detection in Surveillance Video Sequences Using Textural Features. Electronics. 2023; 12(22):4597. https://doi.org/10.3390/electronics12224597
Chicago/Turabian StyleLi, Li, Jianfeng Lu, Shanqing Zhang, Linda Mohaisen, and Mahmoud Emam. 2023. "Frame Duplication Forgery Detection in Surveillance Video Sequences Using Textural Features" Electronics 12, no. 22: 4597. https://doi.org/10.3390/electronics12224597
APA StyleLi, L., Lu, J., Zhang, S., Mohaisen, L., & Emam, M. (2023). Frame Duplication Forgery Detection in Surveillance Video Sequences Using Textural Features. Electronics, 12(22), 4597. https://doi.org/10.3390/electronics12224597