
Enhancing Multi-Objective Optimization with Automatic Construction of Parallel Algorithm Portfolios

Abstract
:1. Introduction
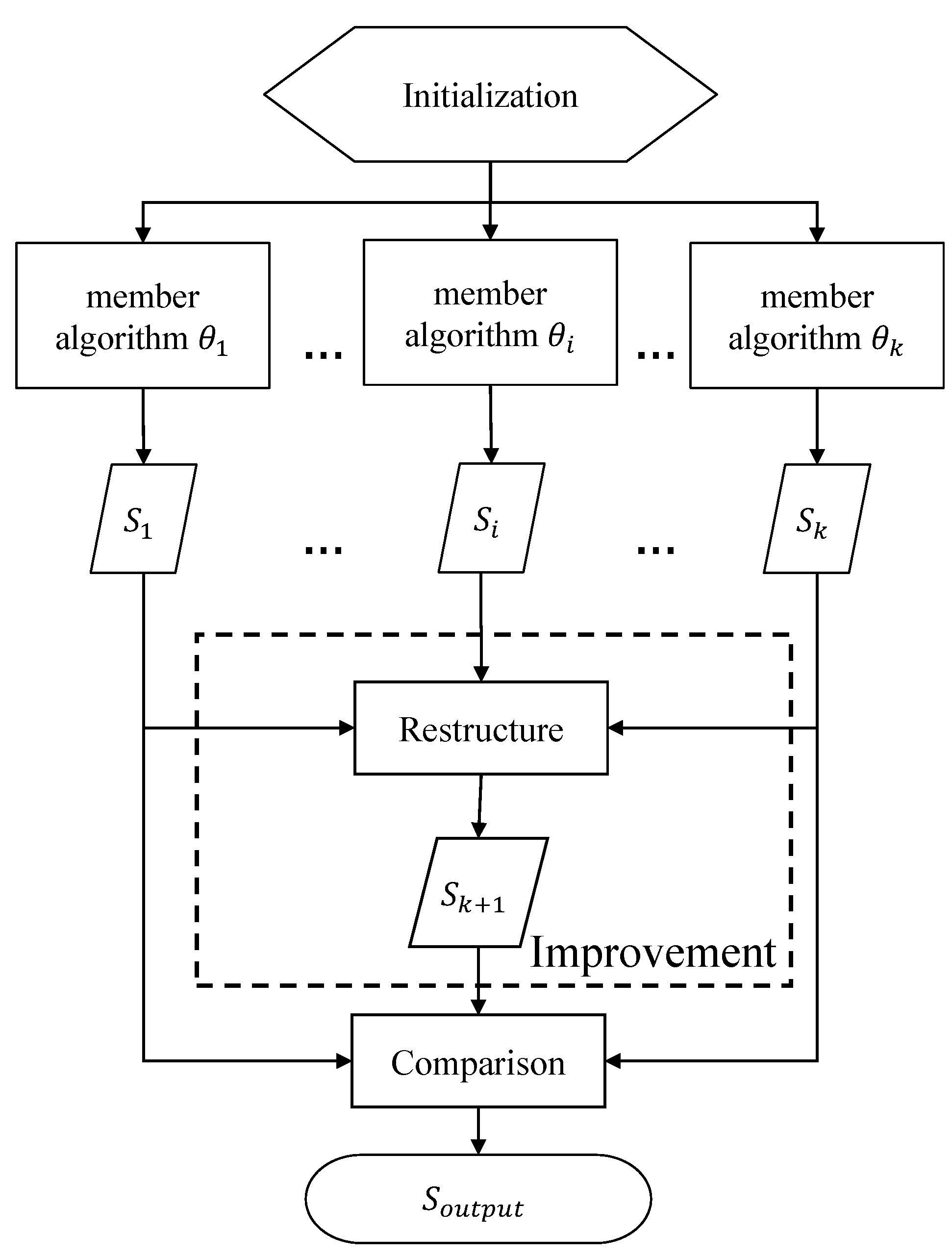
- Taking the characteristics of MOPs into account, we propose a novel variant form of PAP for MOPs, dubbed MOEAs/PAP. Its main difference from conventional PAPs lies in the method for determining the final output. MOEAs/PAP would compare the solution sets found by member algorithms and the solution set generated based on all the solutions found by member algorithms, and finally output the best solution set.
- We present an automatic construction approach for MOEAs/PAP with a novel metric that evaluates the performance of MOEAs/PAPs across multiple MOPs.
- Based on a training set of MOPs and an algorithm configuration space defined by several variants of NSGA-II, we use the proposed approach to construct an MOEAs/PAP, namely NSGA-II/PAP. Experimental results show that NSGA-II/PAP significantly outperforms existing single-operator-based MOEAs and the state-of-the-art multi-operator-based MOEAs designed by human experts. Such promising results indicate the huge potential of automatic construction of PAPs in multi-objective optimization.
2. Preliminaries and Related Work
2.1. Multi-Objective Optimization Problems
2.2. Multi-Objective Evolutionary Algorithms
2.3. Multi-Operator-Based MOEAs
2.4. PAPs and Automatic Construction of PAPs
3. MOEAs/PAP for MOPs
4. Automatic Construction of MOEAs/PAP
4.1. Algorithm Configuration Space and Training Set Z
4.2. Performance Metric
4.3. Automatic Construction Approach
| Algorithm 1: Automatic construction of MOEAs/PAP. |
 |
5. Experiments
5.1. Benchmark Sets
5.2. Construction of NSGA-II/PAP
5.3. Compared Algorithms and Experimental Protocol
5.4. Testing Results and Analysis
5.5. Performances of Member Algorithms
5.6. Effectiveness of the Restructure Procedure
6. Conclusions
- The algorithm configuration space used in this work is still defined based on the general algorithm framework of NSGA-II. In the literature, there have been some studies on developing highly parameterized MOEA frameworks [45,46]. It is valuable to apply our construction approach to these MOEA frameworks, hopefully leading to even better MOEAs/PAPs.
- When constructing MOEAs/PAPs, it is important to maintain the diversity among the member algorithms. Hence, the population diversity preservation schemes, such as negatively correlated search [47], can be introduced into the construction approach to promote cooperation between different member algorithms.
- In real-world applications, one may be unable to collect sufficient MOPs as training problems. How to automatically build powerful PAPs in these scenarios is also worth studying.
- The effectiveness of MOEAs/PAP has been primarily demonstrated through experimental evidence, but with an absence of theoretical analysis. A more thorough investigation of its exceptional performance is crucial for advancing our understanding, which, in turn, can lead to enhancements in its design and the development of a more comprehensive automatic construction algorithm.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, P.; Zhang, L.; Liu, H.; Li, G. Reducing idleness in financial cloud services via multi-objective evolutionary reinforcement learning based load balancer. arXiv 2023, arXiv:2305.03463. [Google Scholar]
- Liu, S.; Tang, K.; Yao, X. Memetic search for vehicle routing with simultaneous pickup-delivery and time windows. Swarm Evol. Comput. 2021, 66, 100927. [Google Scholar] [CrossRef]
- Liu, S.; Lu, N.; Hong, W.; Qian, C.; Tang, K. Effective and imperceptible adversarial textual attack via multi-objectivization. arXiv 2021, arXiv:2111.01528. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A Multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Zitzler, E.; Künzli, S. Indicator-based selection in multiobjective search. In Proceedings of the 8th International Conference on Parallel Problem Solving from Nature, PPSN’2004, Birmingham, UK, 18–22 September 2004; pp. 832–842. [Google Scholar]
- Zhou, A.; Qu, B.Y.; Li, H.; Zhao, S.Z.; Suganthan, P.N.; Zhang, Q. Multiobjective evolutionary algorithms: A survey of the state of the art. Swarm Evol. Comput. 2011, 1, 32–49. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. TIK Rep. 2001, 103. [Google Scholar]
- Coello, C.C.; Lechuga, M.S. MOPSO: A proposal for multiple objective particle swarm optimization. In Proceedings of the 2002 Congress on Evolutionary Computation, CEC’2002, Honolulu, HI, USA, 12–17 May 2002; pp. 1051–1056. [Google Scholar]
- Knowles, J.; Corne, D. The pareto archived evolution strategy: A new baseline algorithm for pareto multiobjective optimisation. In Proceedings of the 1999 Congress on Evolutionary Computation, CEC’99, Washington, DC, USA, 6–9 July 1999; pp. 98–105. [Google Scholar]
- Wang, C.; Xu, R.; Qiu, J.; Zhang, X. AdaBoost-inspired multi-operator ensemble strategy for multi-objective evolutionary algorithms. Neurocomputing 2020, 384, 243–255. [Google Scholar] [CrossRef]
- Gao, X.; Liu, T.; Tan, L.; Song, S. Multioperator search strategy for evolutionary multiobjective optimization. Swarm Evol. Comput. 2022, 71, 101073. [Google Scholar] [CrossRef]
- Elsayed, S.; Sarker, R.; Coello, C.A.C. Fuzzy rule-based design of evolutionary algorithm for optimization. IEEE Trans. Cybern. 2017, 49, 301–314. [Google Scholar] [CrossRef]
- Sun, J.; Liu, X.; Bäck, T.; Xu, Z. Learning adaptive differential evolution algorithm from optimization experiences by policy gradient. IEEE Trans. Evol. Comput. 2021, 25, 666–680. [Google Scholar] [CrossRef]
- Wang, W.; Yang, S.; Lin, Q.; Zhang, Q.; Wong, K.; Coello, C.A.C.; Chen, J. An effective ensemble framework for multiobjective optimization. IEEE Trans. Evol. Comput. 2019, 23, 645–659. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Lamont, G.B.; Van Veldhuizen, D.A. Evolutionary Algorithms for Solving Multi-Objective Problems; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Goh, C.K.; Tan, K.C.; Liu, D.S.; Chiam, S.C. A competitive and cooperative co-evolutionary approach to multi-objective particle swarm optimization algorithm design. Eur. J. Oper. Res. 2010, 202, 42–54. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Q. Multiobjective optimization problems with complicated Pareto sets, MOEA/D and NSGA-II. IEEE Trans. Evol. Comput. 2008, 13, 284–302. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential evolution: A Survey of the state-of-the-art. IEEE Trans. Evol. Comput. 2011, 15, 4–31. [Google Scholar] [CrossRef]
- Peng, F.; Tang, K.; Chen, G.; Yao, X. Population-based algorithm portfolios for numerical optimization. IEEE Trans. Evol. Comput. 2010, 14, 782–800. [Google Scholar] [CrossRef]
- Tang, K.; Peng, F.; Chen, G.; Yao, X. Population-based algorithm portfolios with automated constituent algorithms selection. Inf. Sci. 2014, 279, 94–104. [Google Scholar] [CrossRef]
- Asanovic, K.; Bodik, R.; Demmel, J.; Keaveny, T.; Keutzer, K.; Kubiatowicz, J.; Morgan, N.; Patterson, D.; Sen, K.; Wawrzynek, J.; et al. A view of the parallel computing landscape. Commun. ACM 2009, 52, 56–67. [Google Scholar] [CrossRef]
- Gebser, M.; Kaufmann, B.; Neumann, A.; Schaub, T. clasp: A conflict-driven answer set solver. In Proceedings of the 9th International Conference on Logic Programming and Nonmonotonic Reasoning, LPNMR’2007, Tempe, AZ, USA, 15–17 May 2007; pp. 260–265. [Google Scholar]
- Ralphs, T.K.; Shinano, Y.; Berthold, T.; Koch, T. Parallel solvers for mixed integer linear optimization. In Handbook of Parallel Constraint Reasoning; Hamadi, Y., Sais, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 283–336. [Google Scholar]
- Liu, S.; Tang, K.; Yao, X. Automatic construction of parallel portfolios via explicit instance grouping. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, AAAI’2019, Honolulu, HI, USA, 27 January–1 February 2019; pp. 1560–1567. [Google Scholar]
- Tang, K.; Liu, S.; Yang, P.; Yao, X. Few-shots parallel algorithm portfolio construction via co-evolution. IEEE Trans. Evol. Comput. 2021, 25, 595–607. [Google Scholar] [CrossRef]
- Liu, S.; Tang, K.; Yao, X. Generative adversarial construction of parallel portfolios. IEEE Trans. Cybern. 2022, 52, 784–795. [Google Scholar] [CrossRef]
- Hamadi, Y.; Wintersteiger, C.M. Seven Challenges in Parallel SAT Solving. AI Mag. 2013, 34, 99–106. [Google Scholar] [CrossRef]
- Liu, S.; Tang, K.; Lei, Y.; Yao, X. On performance estimation in automatic algorithm configuration. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, AAAI’2020, New York, NY, USA, 7–12 February 2020; pp. 2384–2391. [Google Scholar]
- Liu, S.; Zhang, Y.; Tang, K.; Yao, X. How good is neural combinatorial optimization? A systematic evaluation on the traveling salesman problem. IEEE Comput. Intell. Mag. 2023, 18, 14–28. [Google Scholar] [CrossRef]
- Liu, S.; Yang, P.; Tang, K. Approximately optimal construction of parallel algorithm portfolios by evolutionary intelligence. Sci. Sin. Technol. 2023, 53, 280–290. [Google Scholar] [CrossRef]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef]
- Deb, K.; Thiele, L.; Laumanns, M.; Zitzler, E. Scalable multi-objective optimization test problems. In Proceedings of the 2002 Congress on Evolutionary Computation, CEC’02, Honolulu, HI, USA, 12–17 May 2002; pp. 825–830. [Google Scholar]
- Huband, S.; Hingston, P.; Barone, L.; While, L. A review of multiobjective test problems and a scalable test problem toolkit. IEEE Trans. Evol. Comput. 2006, 10, 477–506. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhou, A.; Zhao, S.; Suganthan, P.N.; Liu, W.; Tiwari, S. Multiobjective Optimization test Instances for the CEC 2009 Special Session and Competition; Technical Report CES-487; University of Essex: Colchester, UK; Nanyang Technological University: Nanjing, China; Clemson University: Clemson, SC, USA, 2008; Volume 264, pp. 1–30. [Google Scholar]
- Bosman, P.A.; Thierens, D. The balance between proximity and diversity in multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 2003, 7, 174–188. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multiobjective optimization using evolutionary algorithms — A comparative case study. In Proceedings of the 5th International Conference on Parallel Problem Solving from Nature, PPSN’1998, Amsterdam, The Netherlands, 27–30 September 1998; pp. 292–301. [Google Scholar]
- Emmerich, M.; Beume, N.; Naujoks, B. An EMO algorithm using the hypervolume measure as selection criterion. In Proceedings of the 3rd International Conference on Evolutionary Multi-Criterion Optimizatio, EMO’2005, Guanajuato, Mexico, 9–11 March 2005; pp. 62–76. [Google Scholar]
- Rajagopalan, R.; Mohan, C.K.; Mehrotra, K.G.; Varshney, P.K. Emoca: An evolutionary multi-objective crowding algorithm. J. Intell. Syst. 2008, 17, 107–124. [Google Scholar] [CrossRef]
- Mezura-Montes, E.; Reyes-Sierra, M.; Coello, C.A.C. Multi-objective optimization using differential evolution: A survey of the state-of-the-art. In Advances in Differential Evolution; Springer: Berlin/Heidelberg, Germany, 2008; pp. 173–196. [Google Scholar]
- Deb, K. An efficient constraint handling method for genetic algorithms. Comput. Methods Appl. Mech. Eng. 2000, 186, 311–338. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Liu, S.; Peng, F.; Tang, K. Reliable robustness evaluation via automatically constructed attack ensembles. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, AAAI’2023, Washington, DC, USA, 7–14 February 2023; pp. 8852–8860. [Google Scholar]
- Lindauer, M.; Eggensperger, K.; Feurer, M.; Biedenkapp, A.; Deng, D.; Benjamins, C.; Ruhkopf, T.; Sass, R.; Hutter, F. SMAC3: A versatile bayesian optimization package for hyperparameter optimization. J. Mach. Learn. Res. 2022, 23, 2475–2483. [Google Scholar]
- Bezerra, L.C.T.; López-Ibáñez, M.; Stützle, T. Automatic component-wise design of multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 2016, 20, 403–417. [Google Scholar] [CrossRef]
- Bezerra, L.C.T.; López-Ibáñez, M.; Stützle, T. Automatically designing state-of-the-art multi- and many-objective evolutionary algorithms. Evol. Comput. 2020, 28, 195–226. [Google Scholar] [CrossRef] [PubMed]
- Tang, K.; Yang, P.; Yao, X. Negatively correlated search. IEEE J. Sel. Areas Commun. 2016, 34, 542–550. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Problem | Decision Vector Dimension | Objective Vector Dimension |
|---|---|---|
| ZDT1-3 | 30 | 2 |
| ZDT4 | 10 | 2 |
| ZDT5 | 11 | 2 |
| ZDT6 | 10 | 2 |
| DTLZ1-7 | 11 | 2 |
| WFG1-9 | 12 | 3 |
| UF1-7 | 30 | 2 |
| UF8-10 | 30 | 3 |
| Foundation Algorithm | Parameter | Value Range |
|---|---|---|
| SBX + PM | of SBX | |
| of PM | } | |
| rand/p | F | |
| p | ||
| best/p | F | |
| p | ||
| current-to-rand/p | F | |
| K | ||
| p | ||
| current-to-best/p | F | |
| K | ||
| p | ||
| Member Algorithm | Parameter |
|---|---|
| SBX + PM | of SBX , of PM |
| best/p | |
| rand/p | |
| best/p | |
| SBX + PM | of SBX , of PM |
| SBX + PM | of SBX , of PM |
| Algorithm | Operator | Parameter |
|---|---|---|
| NSGA-II | SBX + PM | of SBX , of PM |
| NSGA-II-DE | rand/1 | |
| NSGA-II/MOE | rand/1 | |
| rand/2 | ||
| current-to-rand/1 | ||
| SBX + PM | of SBX , of PM | |
| MOEA/D | SBX + PM | of SBX , of PM |
| MOEA/D | - | |
| Problem | NSGA-II/PAP | NSGA-II (Nsize) | NSGA-II (Ngen) | NSGA-II-DE (Nsize) | NSGA-II-DE (Ngen) | NSGA-II/MOE (Nsize) | NSGA-II/MOE (Ngen) |
|---|---|---|---|---|---|---|---|
| UF1 | 0.6770 ± 4.50 × 10 | 0.6147 ± 1.01 × 10 † | 0.6173 ± 3.64 × 10 † | 0.6283 ± 2.44 × 10 † | 0.6469 ± 1.83 × 10 † | 0.6574 ± 2.11 × 10 † | 0.6920 ± 5.54 × 10† |
| UF2 | 0.6957 ± 1.09 × 10 | 0.6814 ± 3.80 × 10 † | 0.6889 ± 5.04 × 10 † | 0.6749 ± 8.27 × 10 † | 0.6947 ± 2.74 × 10 | 0.6814 ± 1.68 × 10 † | 0.7003 ± 2.90 × 10† |
| UF5 | 0.2503 ± 2.17 × 10 | 0.1944 ± 7.70 × 10 † | 0.1755 ± 2.08 × 10 † | 0.2129 ± 1.20× 10 † | 0.1979 ± 1.32 × 10 † | 0.2041 ± 1.45 × 10 † | 0.1576 ± 4.19 × 10 † |
| UF8 | 0.4394 ± 1.08 × 10 | 0.2827 ± 1.67 × 10 † | 0.3142 ± 9.92 × 10 † | 0.2992 ± 1.19 × 10 † | 0.2794 ± 1.34 × 10 † | 0.4157 ± 1.19 × 10 † | 0.4252 ± 4.08 × 10 |
| UF9 | 0.7619 ± 1.92 × 10 | 0.7014 ± 9.52 × 10 † | 0.6452 ± 5.52 × 10 † | 0.7254 ± 1.92 × 10 † | 0.7127 ± 5.61 × 10 † | 0.5276 ± 1.31 × 10 † | 0.4190 ± 1.59 × 10 † |
| WFG2 | 0.9425 ± 1.13 × 10 | 0.9393 ± 6.09 × 10 † | 0.9410 ± 1.17 × 10 † | 0.9390 ± 4.45 × 10 † | 0.9392 ± 2.12 × 10 † | 0.9406 ± 3.33 × 10 † | 0.9408 ± 1.49 × 10 † |
| WFG3 | 0.6539 ± 5.95 × 10 | 0.6439 ± 6.25 × 10 † | 0.6395 ± 8.55 × 10 † | 0.6332 ± 4.57 × 10 † | 0.6119 ± 1.58 × 10 † | 0.6439 ± 3.06 × 10 † | 0.6350 ± 1.05 × 10 † |
| WFG4 | 0.5745 ± 1.43 × 10 | 0.5714 ± 6.99 × 10 † | 0.5651 ± 3.08 × 10 † | 0.5490 ± 1.73 × 10 † | 0.5372 ± 3.02 × 10 † | 0.5687 ± 1.10 × 10 † | 0.5583 ± 4.28 × 10 † |
| WFG7 | 0.1077 ± 3.61 × 10 | 0.1027 ± 2.88 × 10 † | 0.1114 ± 4.64 × 10† | 0.0276 ± 2.07 × 10 † | 0.0731 ± 3.85 × 10 † | 0.1025 ± 2.66 × 10 † | 0.1038 ± 8.77 × 10 † |
| WFG8 | 0.2121 ± 5.88 × 10 | 0.2261 ± 4.72 × 10 † | 0.2450 ± 2.21 × 10† | 0.0775 ± 1.92 × 10 † | 0.1360 ± 9.81 × 10 † | 0.2172 ± 5.12 × 10 † | 0.2378 ± 1.02 × 10 † |
| DTLZ1 | 0.5556 ± 5.79 × 10 | 0.5773 ± 9.67 × 10 † | 0.5812 ± 1.36 × 10 † | 0.0000 ± 0.00 × 10 † | 0.5816 ± 3.20 × 10† | 0.5581 ± 1.02 × 10 † | 0.4668 ± 5.18 × 10 † |
| DTLZ6 | 0.3465 ± 2.52 × 10 | 0.3451 ± 2.09 × 10 † | 0.3462 ± 6.18 × 10 † | 0.3451 ± 2.74 × 10 † | 0.3463 ± 5.14 × 10 † | 0.3448 ± 3.00 × 10 † | 0.3468 ± 6.28 × 10† |
| DTLZ7 | 0.2428 ± 1.23 × 10 | 0.2420 ± 4.04 × 10 † | 0.2405 ± 1.43 × 10 † | 0.2420 ± 6.57 × 10 † | 0.2425 ± 2.94 × 10 † | 0.2418 ± 8.32 × 10 † | 0.2383 ± 2.77 × 10 † |
| ZDT1 | 0.7198 ± 3.84 × 10 | 0.7164 ± 1.02 × 10 † | 0.7195 ± 5.31 × 10 † | 0.7164 ± 6.66 × 10 † | 0.7198 ± 2.83 × 10 | 0.7152 ± 1.61 × 10 † | 0.7188 ± 1.70 × 10 † |
| ZDT2 | 0.4442 ± 3.29 × 10 | 0.4414 ± 3.66 × 10 † | 0.4436 ± 6.48 × 10 † | 0.4409 ± 6.24 × 10 † | 0.4444 ± 1.52 × 10† | 0.4403 ± 1.19 × 10 † | 0.4438 ± 1.27 × 10 † |
| W-D-L | - | 13-0-2 | 12-0-3 | 15-0-0 | 11-2-2 | 13-0-2 | 10-1-4 |
| Problem | NSGA-II/PAP | MOEA/D (Ngen) | MOPSO (Ngen) | MOEA/D (Nsize) | MOPSO (Nsize) |
|---|---|---|---|---|---|
| UF1 | 0.6770 ± 4.50 × 10 | 0.6662 ± 4.52 × 10 † | 0.6708 ± 5.96 × 10 † | 0.6873 ± 1.91 × 10† | 0.6784 ± 6.74 × 10 |
| UF2 | 0.6957 ± 1.09 × 10 | 0.6972 ± 1.30 × 10 | 0.6997 ± 3.13 × 10 † | 0.7130 ± 8.17 × 10† | 0.7111 ± 9.78 × 10 † |
| UF5 | 0.2503 ± 2.17 × 10 | 0.1610 ± 4.70 × 10 † | 0.1088 ± 4.64 × 10 † | 0.2223 ± 2.45 × 10 † | 0.0900 ± 2.69 × 10 † |
| UF8 | 0.4394 ± 1.08 × 10 | 0.4545 ± 2.75 × 10 † | 0.4602 ± 2.97 × 10 † | 0.4847 ± 9.02 × 10 † | 0.5074 ± 7.02 × 10† |
| UF9 | 0.7619 ± 1.92 × 10 | 0.7504 ± 2.65 × 10 † | 0.5970 ± 1.17 × 10 † | 0.7554 ± 2.07 × 10 † | 0.7416 ± 3.71 × 10 † |
| WFG2 | 0.9425 ± 1.13 × 10 | 0.9364 ± 1.86 × 10 † | 0.9287 ± 4.76 × 10 † | 0.9411 ± 1.44 × 10 † | 0.9427 ± 4.49 × 10 |
| WFG3 | 0.6539 ± 5.95 × 10 | 0.6417 ± 6.74 × 10 † | 0.5362 ± 1.05 × 10 † | 0.6490 ± 5.13 × 10 † | 0.6290 ± 1.57 × 10 † |
| WFG4 | 0.5745 ± 1.43 × 10 | 0.5768 ± 1.06 × 10 | 0.5046 ± 1.02 × 10 † | 0.5905 ± 2.02 × 10† | 0.5622 ± 9.02 × 10 † |
| WFG7 | 0.2121 ± 5.88 × 10 | 0.0976 ± 5.07 × 10 † | 0.0106 ± 1.37 × 10 † | 0.1089 ± 1.74 × 10 † | 0.0160 ± 1.51 × 10 † |
| WFG8 | 0.5556 ± 5.79 × 10 | 0.2373 ± 2.12 × 10 † | 0.0627 ± 1.89 × 10 † | 0.2384 ± 1.84 × 10 † | 0.0659 ± 1.32 × 10 † |
| DTLZ1 | 0.5556 ± 5.79 × 10 | 0.5787 ± 6.39 × 10 † | 0.0000 ± 0.00 × 10 † | 0.5854 ± 1.75 × 10† | 0.0000 ± 0.00 × 10 † |
| DTLZ6 | 0.3465 ± 2.52 × 10 | 0.3438 ± 1.12 × 10 † | 0.3460 ± 2.34 × 10 | 0.3497 ± 4.04 × 10 † | 0.3498 ± 2.74 × 10† |
| DTLZ7 | 0.2428 ± 1.23 × 10 | 0.2412 ± 7.92 × 10 † | 0.2419 ± 1.61 × 10 † | 0.2433 ± 2.07 × 10 | 0.2430 ± 5.57 × 10 |
| ZDT1 | 0.7198 ± 3.84 × 10 | 0.7167 ± 6.31 × 10 † | 0.7149 ± 6.57 × 10 † | 0.7132 ± 5.01 × 10 † | 0.7129 ± 7.33 × 10 † |
| ZDT2 | 0.4442 ± 3.29 × 10 | 0.4413 ± 6.20 × 10 † | 0.4422 ± 4.95 × 10 † | 0.4427 ± 2.48 × 10 † | 0.4435 ± 6.31 × 10 † |
| W-D-L | - | 11-2-2 | 12-1-2 | 8-1-6 | 9-3-3 |
| Problem | NSGA-II/PAP | NSGA-II (Nsize) | NSGA-II (Ngen) | NSGA-II-DE (Nsize) | NSGA-II-DE (Ngen) | NSGA-II/MOE (Nsize) | NSGA-II/MOE (Ngen) |
|---|---|---|---|---|---|---|---|
| UF1 | 3.690 × 10 ± 2.88 × 10 | 8.938 × 10 ± 1.01 × 10 † | 8.911 × 10 ± 7.59 × 10 † | 7.501 × 10 ± 1.80 × 10 † | 5.993 × 10 ± 9.98 × 10 † | 4.614 × 10 ± 7.27 × 10 † | 2.234 × 10 ± 1.99 × 10† |
| UF2 | 2.180 × 10 ± 8.39 × 10 | 3.202 × 10 ± 1.68 × 10 † | 3.086 × 10 ± 1.42 × 10 † | 3.694 × 10 ± 4.02 × 10 † | 2.525 × 10 ± 4.63 × 10 † | 3.771 × 10 ± 3.65 × 10 | 1.998 × 10 ± 3.84 × 10† |
| UF5 | 2.677 × 10 ± 2.68 × 10 | 2.978 × 10 ± 6.01 × 10 † | 3.481 × 10 ± 6.97 × 10 † | 3.384 × 10 ± 2.41× 10 † | 3.439 × 10 ± 7.40 × 10 † | 3.090 × 10 ± 3.29 × 10 † | 3.772 × 10 ± 8.76 × 10 † |
| UF8 | 1.142 × 10 ± 2.93 × 10 | 2.408 × 10 ± 4.00 × 10 † | 1.900 × 10 ± 5.01 × 10 † | 1.959 × 10 ± 1.38 × 10 † | 2.037 × 10 ± 6.38 × 10 † | 1.733 × 10 ± 9.14 × 10 † | 1.530 × 10 ± 1.03 × 10 † |
| UF9 | 6.188 × 10 ± 3.61 × 10 | 1.024 × 10 ± 1.40 × 10 † | 1.465 × 10 ± 5.17 × 10 † | 7.863 × 10 ± 1.22 × 10 † | 8.271 × 10 ± 2.41 × 10 † | 2.498 × 10 ± 8.84 × 10 † | 3.536 × 10 ± 1.29 × 10 † |
| WFG2 | 9.415 × 10 ± 5.97 × 10 | 1.035 × 10 ± 1.84 × 10 † | 9.365 × 10 ± 5.39 × 10 | 1.017 × 10 ± 1.36 × 10 † | 9.319 × 10 ± 4.90 × 10 | 9.496 × 10 ± 1.20 × 10 | 9.308 × 10 ± 8.05 × 10 |
| WFG3 | 8.358 × 10 ± 4.31 × 10 | 8.584 × 10 ± 2.33 × 10 | 9.104 × 10 ± 3.87 × 10 † | 9.339 × 10 ± 5.40 × 10 † | 1.146 × 10 ± 2.33 × 10 † | 8.391 × 10 ± 4.48 × 10 | 8.785 × 10 ± 3.88 × 10 † |
| WFG4 | 1.157 × 10 ± 5.75 × 10 | 1.146 × 10 ± 2.93 × 10 | 1.242 × 10 ± 6.40 × 10 † | 1.347 × 10 ± 5.02 × 10 † | 1.669 × 10 ± 2.03 × 10 † | 1.156 × 10 ± 3.90 × 10 | 1.344 × 10 ± 4.64 × 10 † |
| WFG7 | 1.147 × 10 ± 6.21 × 10 | 1.156 × 10 ± 6.93 × 10 † | 1.145 × 10 ± 5.47 × 10† | 1.244 × 10 ± 1.55 × 10 † | 1.176 × 10 ± 6.13 × 10 † | 1.158 × 10 ± 6.41 × 10 † | 1.157 × 10 ± 6.12 × 10 † |
| WFG8 | 2.216 × 10 ± 5.05 × 10 | 2.182 × 10 ± 5.23 × 10 † | 2.149 × 10 ± 5.86 × 10† | 2.796 × 10 ± 1.03 × 10 † | 2.475 × 10 ± 1.80 × 10 † | 2.204 × 10 ± 5.52 × 10 † | 2.159 × 10 ± 3.14 × 10 † |
| DTLZ1 | 1.083 × 10 ± 6.97 × 10 | 3.900 × 10 ± 1.69 × 10 † | 2.250 × 10 ± 5.65 × 10† | 4.432 × 10 ± 6.57 × 10 † | 2.194 × 10 ± 5.87 × 10 † | 1.581 × 10 ± 3.93 × 10 † | 8.446 × 10 ± 3.04 × 10 † |
| DTLZ6 | 5.596 × 10 ± 9.35 × 10 | 8.356 × 10 ± 4.43 × 10 † | 5.887 × 10 ± 4.79 × 10 † | 8.817 × 10 ± 1.28 × 10 † | 5.767 × 10 ± 5.98 × 10 † | 1.019 × 10 ± 2.26 × 10 † | 5.208 × 10 ± 4.25 × 10† |
| DTLZ7 | 5.105 × 10 ± 2.05 × 10 | 8.745 × 10 ± 7.24 × 10 † | 2.097 × 10 ± 6.83 × 10 † | 8.962 × 10 ± 1.33 × 10 † | 6.744 × 10 ± 6.79 × 10 † | 9.539 × 10 ± 1.39 × 10 † | 3.609 × 10 ± 1.32 × 10 † |
| ZDT1 | 4.528 × 10 ± 3.32 × 10 | 7.800 × 10 ± 1.10 × 10 † | 4.660 × 10 ± 3.30 × 10 † | 7.732 × 10 ± 1.08 × 10 † | 4.593 × 10 ± 2.87 × 10 | 8.253 × 10 ± 1.52 × 10 † | 5.014 × 10 ± 1.16 × 10 † |
| ZDT2 | 4.748 × 10 ± 5.31 × 10 | 7.711 × 10 ± 4.20 × 10 † | 5.386 × 10 ± 6.72 × 10 † | 7.955 × 10 ± 7.53 × 10 † | 4.668 × 10 ± 3.52 × 10 | 9.236 × 10 ± 6.66 × 10 † | 5.077 × 10 ± 1.26 × 10 † |
| W-D-L | - | 11-2-2 | 11-1-3 | 15-0-0 | 12-3-0 | 11-4-0 | 10-1-4 |
| Problem | NSGA-II/PAP | MOEA/D (Ngen) | MOPSO (Ngen) | MOEA/D (Nsize) | MOPSO (Nsize) |
|---|---|---|---|---|---|
| UF1 | 3.690 × 10 ± 2.88 × 10 | 3.789 × 10 ± 2.31 × 10 † | 3.584 × 10 ± 2.16 × 10 † | 2.620 × 10 ± 1.63 × 10† | 3.087 × 10 ± 2.47 × 10 † |
| UF2 | 2.180 × 10 ± 8.39 × 10 | 2.754 × 10 ± 3.01 × 10 † | 2.790 × 10 ± 1.92 × 10 † | 2.185 × 10 ± 2.01 × 10 | 2.088 × 10 ± 6.01 × 10† |
| UF5 | 2.677 × 10 ± 2.68 × 10 | 4.470 × 10 ± 2.36 × 10 † | 5.405 × 10 ± 3.96 × 10 † | 2.821 × 10 ± 4.72 × 10 † | 6.174 × 10 ± 7.04 × 10 † |
| UF8 | 1.142 × 10 ± 2.93 × 10 | 1.142 × 10 ± 7.01 × 10 | 1.149 × 10 ± 9.64 × 10 † | 1.154 × 10 ± 3.17 × 10 † | 1.147 × 10 ± 3.63 × 10 † |
| UF9 | 6.188 × 10 ± 3.61 × 10 | 7.184 × 10 ± 3.67 × 10 † | 2.070 × 10 ± 9.66 × 10 † | 6.776 × 10 ± 1.08 × 10 † | 8.757 × 10 ± 3.96 × 10 † |
| WFG2 | 9.415 × 10 ± 5.97 × 10 | 1.281 × 10 ± 3.42 × 10 † | 9.076 × 10 ± 2.55 × 10 † | 8.935 × 10 ± 4.83 × 10 † | 3.913 × 10 ± 1.61 × 10† |
| WFG3 | 8.358 × 10 ± 4.31 × 10 | 1.283 × 10 ± 6.10 × 10 † | 1.544 × 10 ± 6.11 × 10 † | 8.353 × 10 ± 1.28 × 10 | 8.589 × 10 ± 4.04 × 10 † |
| WFG4 | 1.157 × 10 ± 5.75 × 10 | 1.235 × 10 ± 3.99 × 10 † | 2.104 × 10 ± 5.92 × 10 † | 9.481 × 10 ± 3.81 × 10† | 1.533 × 10 ± 7.97 × 10 † |
| WFG7 | 1.147 × 10 ± 6.21 × 10 | 1.278 × 10 ± 2.43 × 10 † | 1.290 × 10 ± 8.17 × 10 † | 1.267 × 10 ± 8.03 × 10 † | 1.264 × 10 ± 9.01 × 10 † |
| WFG8 | 2.216 × 10 ± 5.05 × 10 | 2.175 × 10 ± 2.79 × 10 † | 2.912 × 10 ± 4.51 × 10 † | 2.173 × 10 ± 9.51 × 10† | 2.889 × 10 ± 1.60 × 10 † |
| DTLZ1 | 1.083 × 10 ± 6.97 × 10 | 3.176 × 10 ± 7.46 × 10 † | 2.728 × 10 ± 2.44 × 10 † | 5.318 × 10 ± 2.49 × 10† | 3.789 × 10 ± 2.85 × 10 † |
| DTLZ6 | 5.596 × 10 ± 9.35 × 10 | 7.114 × 10 ± 3.14 × 10 † | 6.585 × 10 ± 1.76 × 10 † | 6.174 × 10 ± 1.62 × 10 † | 5.681 × 10 ± 1.52 × 10 |
| DTLZ7 | 5.105 × 10 ± 2.05 × 10 | 1.062 × 10 ± 2.15 × 10 † | 7.098 × 10 ± 1.92 × 10 † | 5.581 × 10 ± 8.04 × 10 † | 5.640 × 10 ± 1.39 × 10 † |
| ZDT1 | 4.528 × 10 ± 3.32 × 10 | 6.981 × 10 ± 4.99 × 10 † | 6.856 × 10 ± 1.61 × 10 † | 4.655 × 10 ± 4.97 × 10 † | 5.371 × 10 ± 2.10 × 10 † |
| ZDT2 | 4.748 × 10 ± 5.31 × 10 | 6.953 × 10 ± 2.93 × 10 † | 5.922 × 10 ± 7.65 × 10 † | 5.121 × 10 ± 2.46 × 10 † | 4.398 × 10 ± 3.50 × 10 † |
| W-D-L | - | 13-1-1 | 13-0-2 | 8-2-5 | 11-1-3 |
| Problem | Member Algorithm 1 | Member Algorithm 2 | Member Algorithm 3 | Member Algorithm 4 | Member Algorithm 5 | Member Algorithm 6 | No Restructure | NSGA-II/PAP |
|---|---|---|---|---|---|---|---|---|
| UF3 | 0.575877 | 0.384182 | 0.514065 | 0.427070 | 0.545803 | 0.577853 | 0.597666 | 0.630382 |
| UF4 | 0.981580 | 0.986358 | 0.984794 | 0.982849 | 0.981665 | 0.981615 | 0.986358 | 0.986358 |
| UF6 | 0.544830 | 0.378446 | 0.409731 | 0.603205 | 0.472694 | 0.504911 | 0.648320 | 0.791040 |
| UF7 | 0.805299 | 0.821830 | 0.789846 | 0.884180 | 0.768611 | 0.791250 | 0.890959 | 0.931463 |
| UF10 | 0.124504 | 0.442486 | 0.544413 | 0.171657 | 0.240853 | 0.113756 | 0.621673 | 0.621673 |
| WFG1 | 0.549970 | 0.116983 | 0.417594 | 0.136134 | 0.732619 | 0.500422 | 0.748021 | 0.757083 |
| WFG5 | 0.845592 | 0.837363 | 0.838631 | 0.841177 | 0.850955 | 0.843478 | 0.850955 | 0.852089 |
| WFG6 | 0.827467 | 0.869466 | 0.821787 | 0.890711 | 0.826054 | 0.813707 | 0.893355 | 0.893355 |
| WFG9 | 0.704421 | 0.582577 | 0.684037 | 0.662125 | 0.707536 | 0.705735 | 0.707590 | 0.707642 |
| DTLZ2 | 0.993334 | 0.994437 | 0.993827 | 0.994103 | 0.993781 | 0.993154 | 0.994510 | 0.994510 |
| DTLZ3 | 0.933205 | 0.000739 | 0.010216 | 0.001359 | 0.006734 | 0.785523 | 0.933205 | 0.944154 |
| DTLZ4 | 0.993408 | 0.994484 | 0.973001 | 0.994136 | 0.993670 | 0.993355 | 0.994495 | 0.994495 |
| DTLZ5 | 0.993334 | 0.994437 | 0.993826 | 0.994103 | 0.993781 | 0.993153 | 0.994510 | 0.994510 |
| ZDT3 | 0.993333 | 0.994189 | 0.888358 | 0.996239 | 0.975032 | 0.993530 | 0.996299 | 0.996299 |
| ZDT4 | 0.961404 | 0.115557 | 0.273397 | 0.062209 | 0.702779 | 0.965560 | 0.971306 | 0.972525 |
| ZDT5 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| ZDT6 | 0.989010 | 0.990608 | 0.312566 | 0.992934 | 0.971480 | 0.990346 | 0.993043 | 0.993043 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.; Liu, S.; Hong, W. Enhancing Multi-Objective Optimization with Automatic Construction of Parallel Algorithm Portfolios. Electronics 2023, 12, 4639. https://doi.org/10.3390/electronics12224639
Ma X, Liu S, Hong W. Enhancing Multi-Objective Optimization with Automatic Construction of Parallel Algorithm Portfolios. Electronics. 2023; 12(22):4639. https://doi.org/10.3390/electronics12224639
Chicago/Turabian StyleMa, Xiasheng, Shengcai Liu, and Wenjing Hong. 2023. "Enhancing Multi-Objective Optimization with Automatic Construction of Parallel Algorithm Portfolios" Electronics 12, no. 22: 4639. https://doi.org/10.3390/electronics12224639
APA StyleMa, X., Liu, S., & Hong, W. (2023). Enhancing Multi-Objective Optimization with Automatic Construction of Parallel Algorithm Portfolios. Electronics, 12(22), 4639. https://doi.org/10.3390/electronics12224639