
Design of Hardware IP for 128-Bit Low-Latency Arcsinh and Arccosh Functions

Abstract
:1. Introduction
- An analysis of the CORDIC algorithm in the hyperbolic coordinate system is conducted, presenting a new CORDIC algorithm that synchronizes rotation factors and employs branch parallel processing. This algorithm reduces latency without sacrificing precision;
- The 128-bit high-precision floating-point arcsinh and arccosh functions are decomposed, computed using an improved CORDIC algorithm, and implemented in hardware circuits;
- The hardware circuits for arcsinh and arccosh functions are implemented on an FPGA and subjected to logic synthesis and resource analysis in the TSMC 65 nm process. This work offers a novel solution for the high-precision ASIC chip design of transcendental functions.
2. CORDIC Algorithm and Enhancements for Arcsinh and Arccosh Functions
2.1. Principle of CORDIC Algorithm in Hyperbolic Coordinate System
2.2. Improved Low-Latency CORDIC Algorithm
3. Implementation of Hardware IP for Low-Latency Arcsinh and Arccosh Functions
3.1. Top-Level Module
3.2. Data_Preprocessing Module
- According to the format of quadruple-precision floating-point numbers in the IEEE standard, the 128-bit data is decomposed into the sign bit (out_s), the exponent part (out_e), and the mantissa part (out_m). Simultaneously, depending on the value of the exponent part, a compensatory precision bit of 1 or 0 is added in front of the mantissa part;
- Based on the exponent part and mantissa part, an assessment for data anomalies is conducted, resulting in the output of exceptional results and flags.
3.3. Preliminary_Calculation Module
3.4. Ln_CORDIC Module
3.5. Post_Processing Module
4. Simulation and Experimental Results
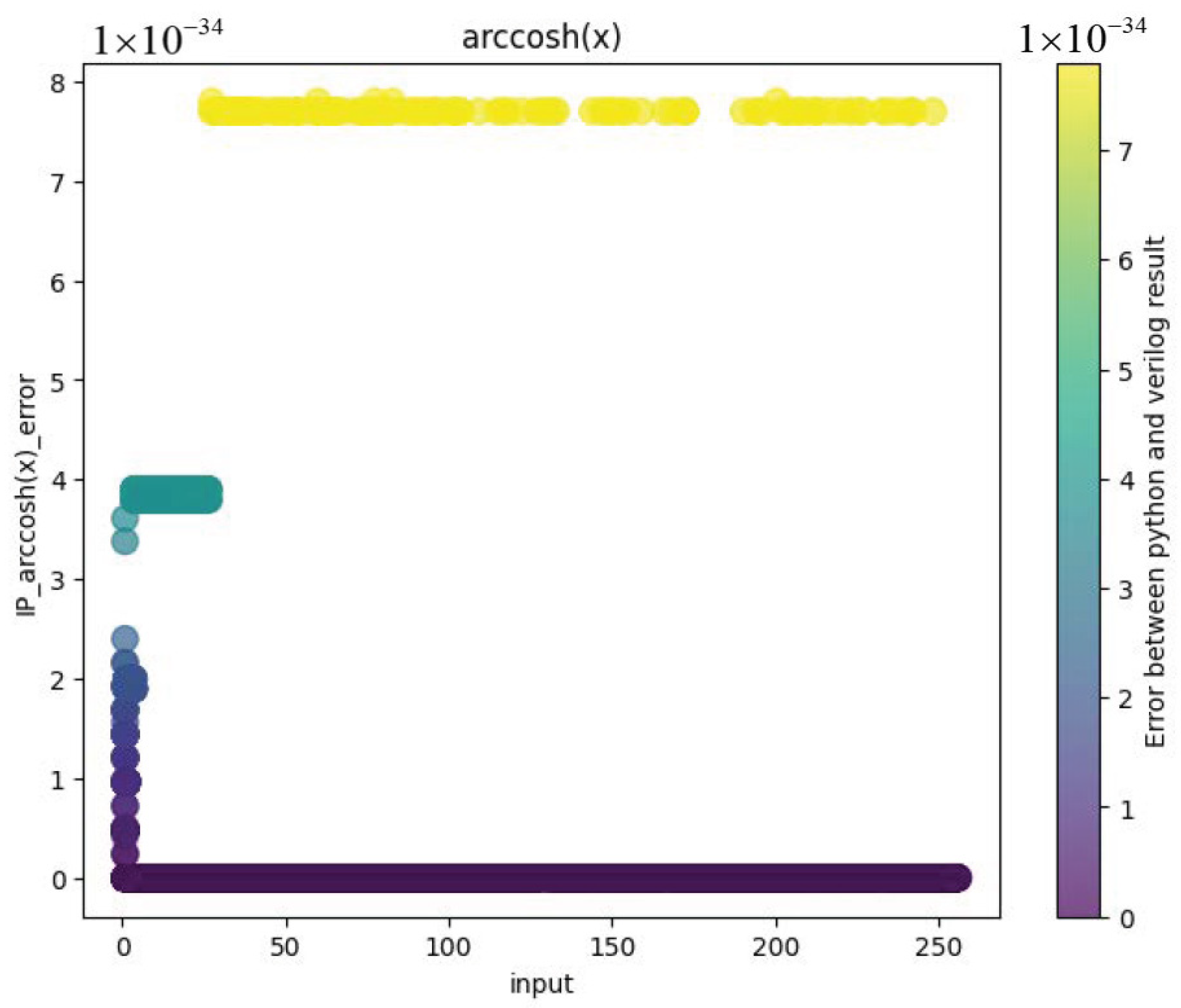
4.1. Analysis of Calculation Errors
4.2. Analysis of Hardware Implementation Results
5. Conclusions
- The designed hardware IP for arcsinh and arccosh will be further optimized, with a focus on performance improvements in terms of area and power consumption;
- The algorithm’s precision will be enhanced and made configurable, enabling its integration into various chipsets for different applications;
- More experiments and tests will be conducted to ensure the hardware IP’s optimal performance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Li, Y.; Dong, B. A novel velocity estimation method for robotic joints based on inverse hyperbolic sine tracing differential algorithm. In Proceedings of the 2017 Chinese Automation Congress, Jinan, China, 20–22 October 2017. [Google Scholar] [CrossRef]
- Jang, J.; Yun, J.D.; Yang, S. Modeling Non-Stationary Asymmetric Lens Blur by Normal Sinh-Arcsinh Model. IEEE Trans. Image Process. 2016, 25, 2184–2195. [Google Scholar] [CrossRef] [PubMed]
- Zhan, D.; Zeng, X.; Li, W.; Liu, Y.; Xiong, Z. Blur kernel estimation using normal sinh-arcsinh model based on simple lens system. In Proceedings of the 2017 IEEE 19th International Workshop on Multimedia Signal Processing, Luton, UK, 1–6 October 2017. [Google Scholar] [CrossRef]
- Tang, P.T.P. Table-lookup algorithms for elementary functions and their error analysis. In Proceedings of the 10th IEEE Symposium on Computer Arithmetic, Grenoble, France, 26–28 June 1991. [Google Scholar] [CrossRef]
- Gener, Y.S.; Gören, S.; Ugurdag, H.F. Lossless Look-Up Table Compression for Hardware Implementation of Transcendental Functions. In Proceedings of the 2019 IFIP/IEEE 27th International Conference on Very Large Scale Integration, Cuzco, Peru, 6–9 October 2019. [Google Scholar] [CrossRef]
- Nguyen, M.X.; Dinh-Duc, A.V. Hardware-based algorithm for Sine and Cosine computations using fixed point processor. In Proceedings of the 2014 11th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Nakhon Ratchasima, Thailand, 1–6 May 2014. [Google Scholar] [CrossRef]
- Brunelli, C.; Berg, H.; Guevorkian, D. Approximating sine functions using variable-precision Taylor polynomials. In Proceedings of the 2009 IEEE Workshop on Signal Processing Systems, Tampere, Finland, 7–9 October 2009. [Google Scholar] [CrossRef]
- Popov, B. Nonlinear best Chebyshev approximations and splines. In Proceedings of the 6th International Conference on Mathematical Methods in Electromagnetic Theory (MMET’96), Lviv, Ukraine, 10–13 September 1996. [Google Scholar] [CrossRef]
- Tian, Z.; Fan, F.; Zhang, J.; Ren, X.; Yang, W. High-Speed Transcendental Function Operation Unit Design. In Proceedings of the 2022 IEEE 9th International Conference on Cyber Security and Cloud Computing, Xi’an, China, 25–27 June 2022. [Google Scholar] [CrossRef]
- Chen, J.; Liu, X. A High-Performance Deeply Pipelined Architecture for Elementary Transcendental Function Evaluation. In Proceedings of the 2017 IEEE International Conference on Computer Design, Boston, MA, USA, 5–8 November 2017. [Google Scholar] [CrossRef]
- Volder, J.E. The CORDIC Trigonometric Computing Technique. IRE Trans. Electron. Comput. 1959, 8, 330–334. [Google Scholar] [CrossRef]
- Walther, J. A unified algorithm for elementary functions. In Proceedings of the Spring Joint Computer Conference, Atlantic City, NJ, USA, 18–20 May 1971; pp. 379–385. [Google Scholar] [CrossRef]
- Chinnathambi, M.; Bharanidharan, N.; Rajaram, S. FPGA implementation of fast and area efficient CORDIC algorithm. In Proceedings of the 2014 International Conference on Communication and Network Technologies, Sivakasi, India, 18–19 December 2014. [Google Scholar] [CrossRef]
- Chen, H.; Cheng, K.; Lu, Z.; Fu, Y.; Li, L. Hyperbolic CORDIC-Based Architecture for Computing Logarithm and Its Implementation. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 2652–2656. [Google Scholar] [CrossRef]
- Mishra, S.M.; Shekhawat, H.S.; Trivedi, G.; Jan, P.; Nemec, Z. Design and Implementation of a Low Power Area Efficient Bfloat16 based CORDIC Processor. In Proceedings of the 2022 32nd International Conference Radioelektronika, Kosice, Slovakia, 1–6 April 2022. [Google Scholar] [CrossRef]
- Vinh, T.Q.; Thanh, T.B.; Viet, D.H. FPGA Implementation of Trigonometric Function Using Loop-Optimized Radix-4 CORDIC. In Proceedings of the 2022 9th NAFOSTED Conference on Information and Computer Science, Ho Chi Minh City, Vietnam, 31 October–1 November 2022. [Google Scholar] [CrossRef]
- Sergiyenko, A.; Moroz, L.; Mychuda, L.; Samotyj, V. FPGA Implementation of CORDIC Algorithms for Sine and Cosine Floating-Point Calculations. In Proceedings of the 2021 11th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications, Cracow, Poland, 22–25 September 2021. [Google Scholar] [CrossRef]
- Juang, T.B. Low Latency Angle Recoding Methods for the Higher Bit-Width Parallel CORDIC Rotator Implementations. IEEE Trans. Circuits Syst. II Express Briefs 2008, 55, 1139–1143. [Google Scholar] [CrossRef]
- Jain, R.K.; Sharma, V.K.; Mahapatra, K.K. A new approach for high performance and efficient design of CORDIC processor. In Proceedings of the 2012 1st International Conference on Recent Advances in Information Technology, Dhanbad, India, 15–17 March 2012. [Google Scholar] [CrossRef]
- Sapper, A.N.; Soares, L.; Costa, E.; Bampi, S. Exploring the combination of number of bits and number of iterations for a power-efficient fixed-point CORDIC implementation. In Proceedings of the 2017 24th IEEE International Conference on Electronics, Circuits and Systems, Batumi, Georgia, 5–8 December 2017. [Google Scholar] [CrossRef]
- Changela, A.; Kumar, R. A Modified Radix-16 CORDIC Algorithm-based Direct Digital Frequency Synthesizer. In Proceedings of the 2022 5th International Conference on Contemporary Computing and Informatics, Uttar Pradesh, India, 14–16 December 2022. [Google Scholar] [CrossRef]
- Singh, A.K.; Singh, M.K.; Ray, K.C. Design and Implementation of Quadruple Floating-Point CORDIC. In Proceedings of the 2015 IEEE International Symposium on Nanoelectronic and Information Systems, Indore, India, 21–23 December 2015. [Google Scholar] [CrossRef]
- IEEE Std 754-2008; IEEE Standard for Floating-Point Arithmetic. IEEE: Piscataway, NJ, USA, 2008; pp. 1–70.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input_num | Result from IP | Results from Python |
|---|---|---|
| 40049c48799df21f8b7899d16dd1e0b0 | 400128ac3236f088986b53fb2017b38e | 400128ac3236f088986b53fb2017b38e |
| 4005389b2c7c4305b0d5c634e3e576a1 | 400143514fa11829eb20d48d3ff7740a | 400143514fa11829eb20d48d3ff7740a |
| 3fff92125bb82fc894f0cc84262761e1 | 3fff3bb9231c2956bf9ee54fd17acd2b | 3fff3bb9231c2956bf9ee54fd17acd2c |
| 40036bef97b5fb817f035279b094f793 | 4000e8b4d979a5ed7cac058eb314f7d8 | 4000e8b4d979a5ed7cac058eb314f7d8 |
| 4002dea9b97c11bcb714f3f3031eaf1b | 4000b323961b35968fd40c84e677a015 | 4000b323961b35968fd40c84e677a015 |
| Input_num | Result from IP | Results from Python |
|---|---|---|
| 40049c48799df21f8b7899d16dd1e0b0 | 400128a91c97e76cabc195e6f1b18d03 | 400128a91c97e76cabc195e6f1b18d03 |
| 4005389b2c7c4305b0d5c634e3e576a1 | 4001434ff843e3956efdaa1091cc1e68 | 4001434ff843e3956efdaa1091cc1e68 |
| 4001321fb3328e3c1bd5114513059bb0 | 40001fa26273ebb760a1997e033803c4 | 40001fa26273ebb760a1997e033803c4 |
| 4000367b2620532b69445b33a1e8b8eb | 3fff88a40b2fb18492b5d2518d3d05ae | 3fff88a40b2fb18492b5d2518d3d05af |
| 4002b0f1a5fb60f249cc6a2dba4b6b86 | 4000a5f8a88db52b94dbd54c5098903f | 4000a5f8a88db52b94dbd54c5098903f |
| Process | Frequency | Area | Power | Max Error |
|---|---|---|---|---|
| TSMC 65 nm | 300 MHZ | 2.1056 mm | 22.4 mW | 1 bit |
| Logic Utilization | Used | Available | Utilization |
|---|---|---|---|
| LUT | 513,528 | 547,600 | 93.78% |
| Reg | 6152 | 1,095,200 | 0.56% |
| DSP | 18 | 2520 | 0.71% |
| F7 MUX | 174,395 | 328,200 | 53.14% |
| F8 MUX | 83,860 | 164,100 | 51.10% |
| Logic Utilization | Used | Available | Utilization |
|---|---|---|---|
| LUT | 32,904 | 547,600 | 6.01% |
| Reg | 1082 | 1,095,200 | 0.10% |
| DSP | 9 | 2520 | 0.36% |
| F7 MUX | 441 | 328,200 | 0.13% |
| F8 MUX | 148 | 164,100 | 0.09% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, J.; Wang, M. Design of Hardware IP for 128-Bit Low-Latency Arcsinh and Arccosh Functions. Electronics 2023, 12, 4658. https://doi.org/10.3390/electronics12224658
Chang J, Wang M. Design of Hardware IP for 128-Bit Low-Latency Arcsinh and Arccosh Functions. Electronics. 2023; 12(22):4658. https://doi.org/10.3390/electronics12224658
Chicago/Turabian StyleChang, Junfeng, and Mingjiang Wang. 2023. "Design of Hardware IP for 128-Bit Low-Latency Arcsinh and Arccosh Functions" Electronics 12, no. 22: 4658. https://doi.org/10.3390/electronics12224658