
Joint Overlapping Event Extraction Model via Role Pre-Judgment with Trigger and Context Embeddings


Abstract
:1. Introduction
- (1)
- A role pre-judgment module is proposed to predict roles based on the correspondence between event types and roles, text embeddings, and trigger embeddings, which can significantly improve the recall rate of each subtask and provide a basis for extracting overlapping arguments.
- (2)
- ROPEE adopts a joint learning framework, and the designed loss function includes the losses of four modules, event-type detection, trigger extraction, role pre-judgment, and argument extraction, so as to effectively learn the interactive relationship between modules during training. Thus, error propagation issues can be alleviated in the prediction stage.
- (3)
- ROPEE outperforms the baseline model by 0.4%, 0.9%, and 0.6% in terms of F1 over TC, AI, and AC on the FewFC dataset. For sentences with overlapping triggers, ROPEE outperforms the baseline model by 0.9% and 1.2% in terms of F1 over AI and AC, respectively. In the case of overlapping arguments, ROPEE demonstrates superior performance compared to the baseline model, with improvements of 0.7% and 0.6%. This highlights the effectiveness of our suggested approach in managing overlapping occurrences of event phenomena.
2. Related Studies
3. ROPEE Model
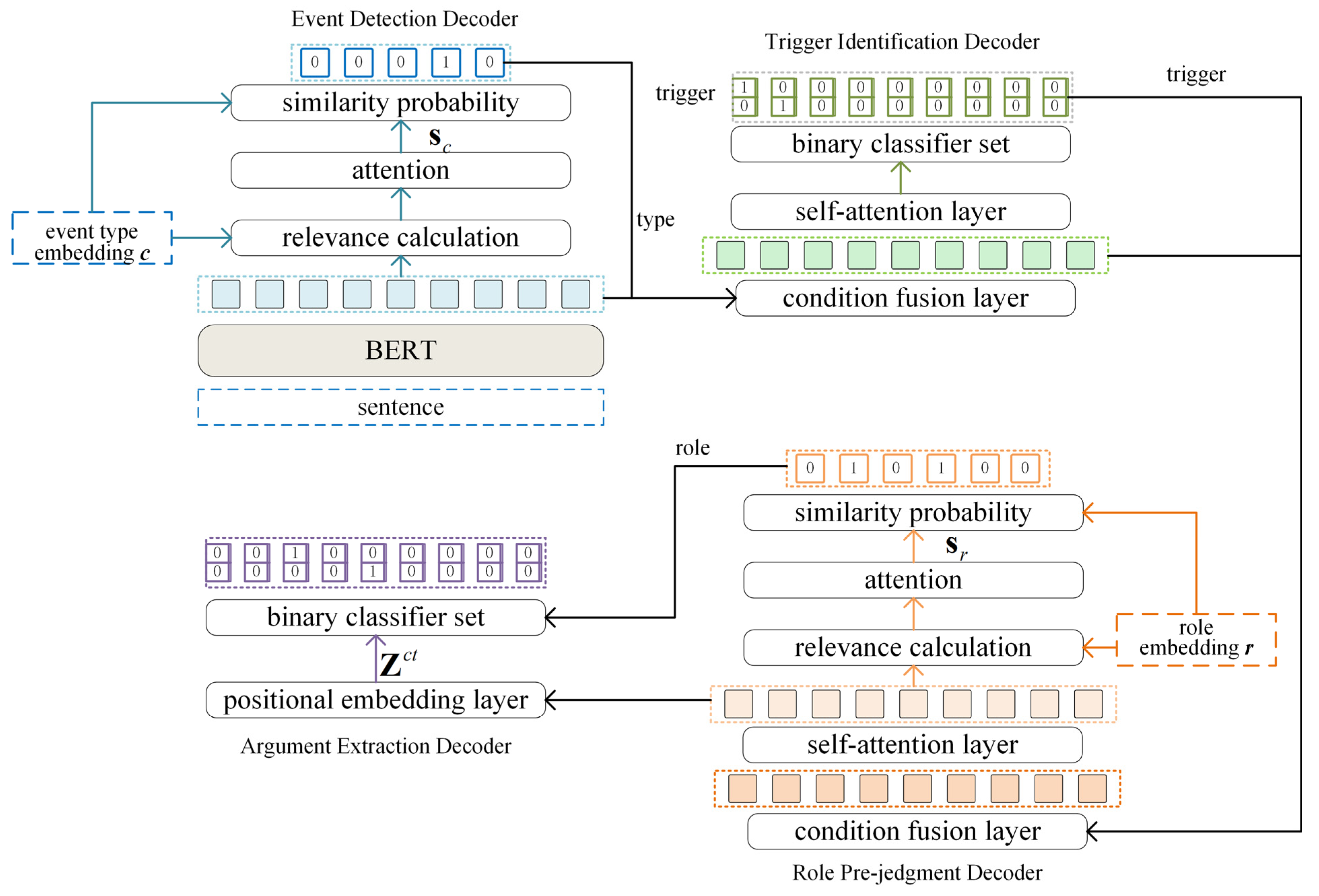
3.1. Encoder
3.2. Event Detection Decoder
3.3. Trigger Identification Decoder
3.4. Role Pre-Judgment Decoder
3.5. Argument Extraction Decoder
3.6. Model Training
4. Experiments and Analysis
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metric
4.4. Baselines
- (1)
- BERT-softmax [24]: It uses BERT to obtain the feature representation of words for the classification of both trigger and event arguments.
- (2)
- BERT-CRF [29]: It uses a CRF module based on BERT to catch the transfer rules between adjacent tags.
- (3)
- BERT-CRF-joint: It extends the classic BIO labeling scheme by merging tags of event types and roles for sequence annotation, such as BIO-type roles [30].
- (4)
- PLMEE [12]: It extracts triggers and arguments in a pipeline manner, and alleviates the argument overlapping issue by extracting role-aware arguments.
- (5)
- MQAEE: It is extended based on Li et al. [15]. It first predicts overlapping triggers through question and answer, and then predicts overlapping arguments based on typed triggers.
- (6)
- CasEE [9]: It performs all four subtasks sequentially with a cascade decoder based on the specific previous predictions.
4.5. Main Results
- (1)
- In contrast to the flattened sequence labeling methods, ROPEE achieves superior recall and F1 scores. Specifically, ROPEE outperforms BERT-CRF-joint by 15.7% and 4.9% on recall and the F1 score of AC. ROPEE also achieves significantly better than the sequence labeling method on recall because the sequence labeling method can only solve the flat event extraction problem, which can cause label conflicts. This shows that ROPEE can effectively solve the problem of overlapping event extraction.
- (2)
- Compared with the multi-stage methods for overlapping event extraction, the F1 scores of ROPEE in AI and AC are greater than that of CasEE by 0.9% and 0.6%, respectively. We believe that the role pre-judgment decoder in the model provides good help for argument extraction. In particular, ROPEE outperforms CasEE on the recall score of all four subtasks, especially AI and AC by 5.5% and 5.4%, respectively. This shows that the ROPEE model can better recall arguments that match the role type in the training of role pre-judgment. Overall, ROPEE outperforms all multi-stage methods for overlapping event extraction.
- (3)
- We also conducted comparative experiments on the large language model ChatGLM2-6B [31,32]. Some parameters of ChatGLM were fine-tuned using the P-Tuning-v2 method, but the final result was not ideal. ChatGLM is more accurate in extracting core arguments and triggers, but the span position it extracts is seriously inconsistent with the original text, indicating that ChatGLM fails to understand the boundary meaning represented by span.
4.6. Results of Overlapped EE
4.7. Ablation Studies
4.8. Case Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Katiyar, A.; Cardie, C. Investigating lstms for joint extraction of opinion entities and relations. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 919–929. [Google Scholar]
- Fei, H.; Zhang, M.; Ji, D. Cross-lingual semantic role labeling with high-quality translated training corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7014–7026. [Google Scholar]
- Li, J.; Xu, K.; Li, F.; Fei, H.; Ren, Y.; Ji, D. MRN: A locally and globally mention-based reasoning network for document-level relation extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1359–1370. [Google Scholar]
- Liu, Z.; Li, Y.; Zhang, Y.; Weng, Y.; Yang, K.; Wang, C. Effective Event Extraction Method via Enhanced Graph Convolutional Network Indication with Hierarchical Argument Selection Strategy. Electronics 2023, 12, 2981. [Google Scholar] [CrossRef]
- Bosselut, A.; Le Bras, R.; Choi, Y. Dynamic neuro-symbolic knowledge graph construction for zero-shot commonsense question answering. In Proceedings of the 35th AAAI conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 4923–4931. [Google Scholar]
- Xiang, G.; Shi, C.; Zhang, Y. An APT Event Extraction Method Based on BERT-BiGRU-CRF for APT Attack Detection. Electronics 2023, 12, 3349. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, L.; Liu, K.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 167–176. [Google Scholar]
- Sheng, J.; Guo, S.; Yu, B.; Li, Q.; Hei, Y.; Wang, L.; Liu, T.; Xu, H. CasEE: A joint learning framework with cascade decoding for overlapping event extraction. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 164–174. [Google Scholar]
- Cao, H.; Li, J.; Su, F.; Li, F.; Fei, H.; Wu, S.; Li, B.; Zhao, L.; Ji, D. OneEE: A one-stage framework for fast overlapping and nested event extraction. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 1953–1964. [Google Scholar]
- Zhou, Y.; Chen, Y.; Zhao, J.; Wu, Y.; Xu, J.; Li, J. What the role is vs. what plays the role: Semi-supervised event argument extraction via dual question answering. In Proceedings of the 35th AAAI conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 14638–14646. [Google Scholar]
- Yang, S.; Feng, D.; Qiao, L.; Kan, Z.; Li, D. Exploring pre-trained language models for event extraction and generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5284–5294. [Google Scholar]
- Xu, N.; Xie, H.; Zhao, D. A novel joint framework for multiple Chinese events extraction. In Proceedings of the China National Conference on Chinese Computational Linguistics, Hainan, China, 30 October–1 November 2020; pp. 174–183. [Google Scholar]
- Huang, K.H.; Yang, M.; Peng, N. Biomedical event extraction with hierarchical knowledge graphs. arXiv 2020, arXiv:2009.09335. [Google Scholar]
- Zhang, X.; Zhu, Y.H.; OuYang, K.; Kong, L.W. Chinese Event Extraction Based on Role Separation. J. Shanxi Univ. 2022, 45, 936–946. [Google Scholar]
- Yang, H.J.; Jin, X.Y. A general model for entity relationship and event extraction. Comput. Eng. 2023, 49, 143–149. [Google Scholar]
- Zhu, M.; Mao, Y.C.; Cheng, Y.; Chen, C.J.; Wang, L.B. Event Extraction Method Based on Dual Attention Mechanism. Ruan Jian Xue Bao/J. Softw. 2023, 34, 3226–3240. [Google Scholar]
- Li, Q.; Li, J.; Sheng, J.; Cui, S.; Wu, J.; Hei, Y.; Peng, H.; Guo, S.; Wang, L.; Beheshti, A.; et al. A survey on deep learning event extraction: Approaches and applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 14, 1–21. [Google Scholar] [CrossRef]
- Li, F.; Peng, W.; Chen, Y.; Wang, Q.; Pan, L.; Lyu, Y.; Zhu, Y. Event extraction as multi-turn question answering. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 829–838. [Google Scholar]
- Paolini, G.; Athiwaratkun, B.; Krone, J.; Ma, J.; Achille, A.; Anubhai, R.; Santos, C.N.d.; Xiang, B.; Soatto, S. Structured prediction as translation between augmented natural languages. In Proceedings of the Ninth International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Hsu, I.; Huang, K.-H.; Boschee, E.; Miller, S.; Natarajan, P.; Chang, K.-W.; Peng, N. DEGREE: A data-efficient generation-based event extraction model. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, DC, USA, 10–15 July 2022; pp. 1890–1908. [Google Scholar]
- Van Nguyen, M.; Min, B.; Dernoncourt, F.; Nguyen, T. Joint extraction of entities, relations, and events via modeling inter-instance and inter-label dependencies. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, DC, USA, 10–15 July 2022; pp. 4363–4374. [Google Scholar]
- Liu, J.; Liang, C.; Xu, J.; Liu, H.; Zhao, Z. Document-level event argument extraction with a chain reasoning paradigm. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 9570–9583. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yu, B.; Zhang, Z.; Sheng, J.; Liu, T.; Wang, Y.; Wang, Y.; Wang, B. Semi-open information extraction. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1661–1672. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Su, J.; Lu, Y.; Pan, S.; Murtadha, A.; Wen, B.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. arXiv 2021, arXiv:2104.09864. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Du, X.; Cardie, C. Document-level event role filler extraction using multi-granularity contextualized encoding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8010–8020. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint extraction of entities and relations based on a novel tagging scheme. arXiv 2017, arXiv:1706.05075. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X. Glm-130b: An open bilingual pre-trained model. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Du, Z.; Qian, Y.; Liu, X.; Ding, M.; Qiu, J.; Yang, Z.; Tang, J. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 320–335. [Google Scholar]
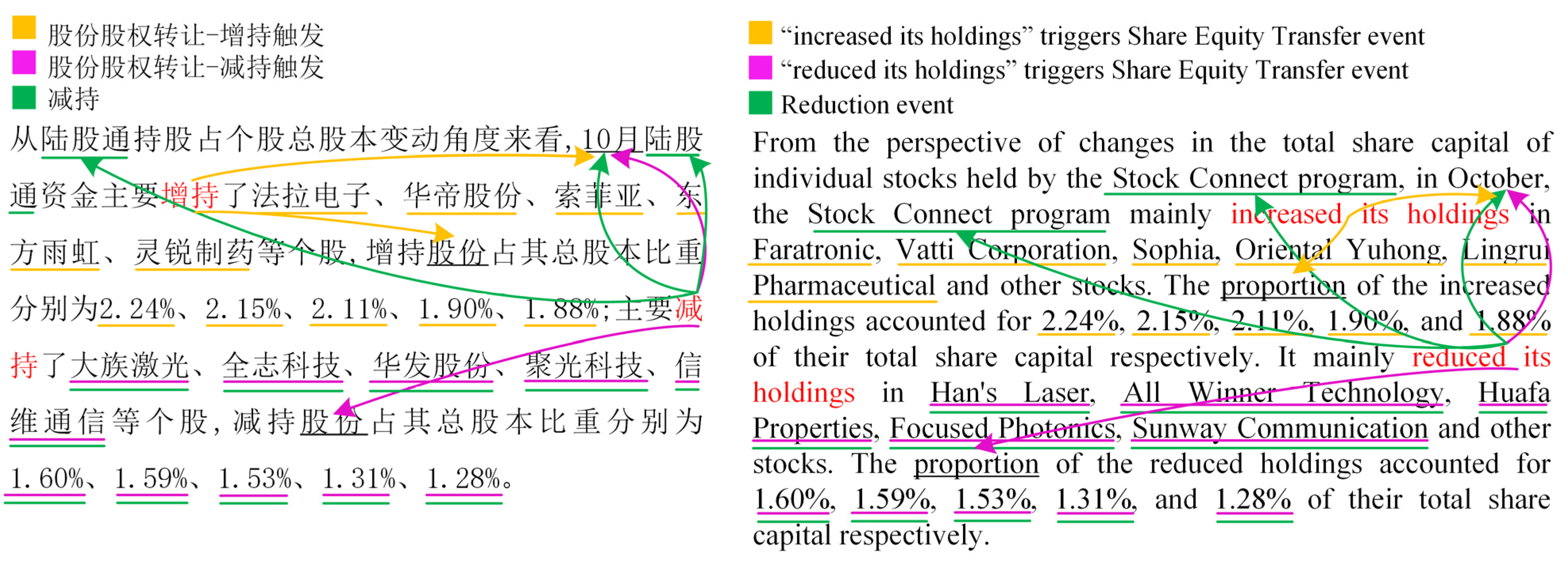


{kind=link}
{kind=link}
{kind=link}
| Trigger Overlap | Argument Overlap | Samples | Event | |
|---|---|---|---|---|
| Training | 1314 | 1541 | 7185 | 10,277 |
| Validation | 168 | 203 | 899 | 1281 |
| Testing | 168 | 209 | 898 | 1332 |
| All | 1650 | 1953 | 8982 | 12,890 |
| TI (%) | TC (%) | AI (%) | AC (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | |
| BERT-softmax | 89.8 | 79.0 | 84.0 | 80.2 | 61.8 | 69.8 | 74.6 | 62.8 | 68.2 | 72.5 | 60.2 | 65.8 |
| BERT-CRF | 90.8 | 80.8 | 85.5 | 81.7 | 63.6 | 71.5 | 75.1 | 64.3 | 69.3 | 72.9 | 61.8 | 66.9 |
| BERT-CRF-joint | 89.5 | 79.8 | 84.4 | 80.7 | 63.0 | 70.8 | 76.1 | 63.5 | 69.2 | 74.2 | 61.2 | 67.1 |
| PLMEE | 83.7 | 85.8 | 84.7 | 75.6 | 74.5 | 75.1 | 74.3 | 67.3 | 70.6 | 72.5 | 65.5 | 68.8 |
| MQAEE | 89.1 | 85.5 | 87.4 | 79.7 | 76.1 | 77.8 | 70.3 | 68.3 | 69.3 | 68.2 | 66.5 | 67.3 |
| CasEE | 89.4 | 87.7 | 88.6 | 77.9 | 78.5 | 78.2 | 72.8 | 73.1 | 72.9 | 71.3 | 71.5 | 71.4 |
| ROPEE | 88.8 | 88.2 | 88.5 | 74.7 | 82.8 | 78.6 | 69.5 | 78.6 | 73.8 | 67.6 | 76.9 | 72.0 |
| TI (%) | TC (%) | AI (%) | AC (%) | ||
|---|---|---|---|---|---|
| Trigger Overlap | CasEE | 92.5 | 82.8 | 75.5 | 74.2 |
| ROPEE | 92.0 | 82.4 | 76.4 | 75.4 | |
| Argument Overlap | CasEE | 88.6 | 78.2 | 74.2 | 72.8 |
| ROPEE | 89.2 | 78.7 | 74.9 | 73.4 |
| TI (%) | TC (%) | AI (%) | AC (%) | |
|---|---|---|---|---|
| type_emb | 88.6 | 78.2 | 72.9 | 71.4 |
| ROP-text_emb | 88.2 | 78.4 | 73.4 | 71.7 |
| ROPEE | 88.5 | 78.6 | 73.8 | 72.0 |
| TI (%) | TC (%) | AI (%) | AC (%) | |
|---|---|---|---|---|
| Role-1 | 88.1 | 77.6 | 71.7 | 69.4 |
| Role-2 | 88.5 | 77.7 | 72.7 | 70.6 |
| Role-3 | 88.4 | 78.1 | 73.5 | 71.7 |
| Role-4 | 87.8 | 76.6 | 72.0 | 70.3 |
| Role-5 | 88.2 | 77.2 | 72.4 | 70.7 |
| ROPEE | 88.5 | 78.6 | 73.8 | 72.0 |
| P (%) | R (%) | F1 (%) | ||
|---|---|---|---|---|
| ROPEE | AI | 69.5 | 78.6 | 73.8 |
| AC | 67.6 | 76.9 | 72.0 | |
| 20 epoch w/o trigger | AI | 71.4 | 72.6 | 72.0 |
| AC | 70.0 | 71.0 | 70.5 | |
| 50 epoch w/o trigger | AI | 70.9 | 73.5 | 72.2 |
| AC | 69.3 | 71.7 | 70.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Q.; Yang, K.; Guo, X.; Wang, S.; Liao, J.; Zheng, J. Joint Overlapping Event Extraction Model via Role Pre-Judgment with Trigger and Context Embeddings. Electronics 2023, 12, 4688. https://doi.org/10.3390/electronics12224688
Chen Q, Yang K, Guo X, Wang S, Liao J, Zheng J. Joint Overlapping Event Extraction Model via Role Pre-Judgment with Trigger and Context Embeddings. Electronics. 2023; 12(22):4688. https://doi.org/10.3390/electronics12224688
Chicago/Turabian StyleChen, Qian, Kehan Yang, Xin Guo, Suge Wang, Jian Liao, and Jianxing Zheng. 2023. "Joint Overlapping Event Extraction Model via Role Pre-Judgment with Trigger and Context Embeddings" Electronics 12, no. 22: 4688. https://doi.org/10.3390/electronics12224688
APA StyleChen, Q., Yang, K., Guo, X., Wang, S., Liao, J., & Zheng, J. (2023). Joint Overlapping Event Extraction Model via Role Pre-Judgment with Trigger and Context Embeddings. Electronics, 12(22), 4688. https://doi.org/10.3390/electronics12224688