1. Introduction
Network-based intrusion detection and prevention systems (IDPS) have played a pivotal role in cybersecurity [
1,
2,
3]. Located at network gateways or critical points in enterprise networks, they inspect every packet to find suspicious activities or cyberattacks. For decades, the IDPS has evolved to include more than thousands of detection rules, or signatures, most of which are represented as strings or regular expressions. Whenever an IDPS finds any signature from a packet, it triggers an alert. If the packet is really related to cyberattacks, the alert becomes a
true alert; otherwise, a
false alert occurs, also called a false positive.
Unfortunately, IDPSs have been notorious for their false alerts, resulting in a phenomenon called
alert fatigue, a huge number of false alerts overwhelming security analysts to ignore or fail to respond to a small number of true alerts [
4,
5]. Because writing intrusion detection rules is a challenging task, finding the right balance between an overly specific rule and an overly general one is hard to determine [
1]. Most rules are developed to catch general attacks or vulnerabilities because IDPSs can be deployed in any environment. This means that IDPSs would generate alerts when a packet includes a suspicious string, and therefore a tremendous volume of false alerts is inevitable.
The sheer number of alerts has consistently overwhelmed human resources, or security analysts, leading to the pervasive issue of alert fatigue. Reducing alert fatigue is a challenging yet essential task for the security industry, particularly in security operations centers (SOC) where alerts are gathered from numerous monitoring sensors and a limited number of analysts work around the clock, 365 days a year [
6,
7]. Despite decades of efforts by researchers and industries to address the alert fatigue problem in IDPSs [
4,
5,
6,
8,
9,
10], a comprehensive solution has not been achieved yet.
Existing Solutions. Security analysts can usually analyze only a small portion of alerts. Recent studies show that one analyst can investigate 76 alerts per day, but the number of daily alerts is greater than 10,000 [
4]. Therefore, some true alerts of real threats should be selected first with a high priority whereas false alerts should be filtered out automatically. In this sense, a number of solutions have been proposed, which can be classified into three categories as follows:
First, additional context information very specific to a particular site can be used to automatically filter out some alerts. For example, a security analyst may ignore any alert about Windows Internet Information Services (IIS) if he/she knows the site information that the victim is an Apache web server [
4]. However, very detailed context information should be timely updated, which is often impossible in practice because of scarce human resources or poor cooperation between security and operation teams.
Second, extra data or Cyber Threat Intelligence (CTI) information from other sources can be used. For example, additional server logs, alerts from other IDPSs, or blacklists of IP addresses of well-known attackers, can give a hint as to whether the alert is true or false [
5,
6,
8]. However, extra cost and effort are required to purchase and fully utilize CTI information.
Third, alerts can be classified into multiple groups by security analysts and some groups are filtered out together automatically. This heuristic is widely used in the industry because many false alerts can be suppressed at once. The current grouping method is generally based on only the alert name and IP address, which are available from most of the IDPS alerts [
9,
10]. This approach can be implemented easily because security administrators can write filtering rules consisting of alert names and IP addresses. A group of alerts satisfying the same rule can be automatically ignored together. We call it the state-of-the-art (SOTA) method to mitigate the alert fatigue problem. However, a new security hole appears with SOTA; any detection of real attacks to the same IP address and alert name is automatically filtered out, and the possible detection would be evaded because of the coarse-grained filtering rule. We call this new problem of SOTA as
coarse-grained alert-filtering problem.
Proposed Solution. We observe that the coarse-grained alert-filtering problem arises because the current filtering practice lacks precision, relying solely on alert names and IP addresses. In this paper, we present a new fine-grained filtering scheme that can more precisely identify groups of false alerts by considering the alert name, the IP address, and the clustering results from the packet payloads of the IDPS alerts via semi-supervised learning. The new scheme identifies a number of large clusters, and only a few samples from each cluster are manually analyzed to determine if the cluster consists of only false alerts, true alerts, or a mix of both. If the cluster includes either false or true alerts only, the alerts of the same cluster can be processed the same way without further manual analysis; otherwise, the alerts of the cluster can be handed over to security analysts for individual analysis. We refer to our scheme as Semi-supervised Alert Filtering (SAFI). The contribution of this paper can be summarized as follows:
We introduce the important and practical coarse-grained alert-filtering problem and reveal the limitations of SOTA.
We introduce SAFI, a new alert-filtering scheme, not only to process alerts more precisely but also to save security analysts’ time and efforts. This improvement comes from the new features extracted from packet payloads embedded in most IDPS alerts and their semi-supervised clustering results.
Both public and private datasets are used in experiments to show that SAFI outperforms SOTA in terms of the accuracy of data analysis as well as the analysis cost.
Encrypted traffic. Most alerts are generated by IDPSs when network packets include suspicious strings or patterns. If the packets are encrypted and the IDPS is not entrusted with decryption keys, some alerts cannot be triggered, whereas a separate decryption box can be deployed to convert encrypted packets into plain ones for IDPSs in enterprise networks [
11]; this incurs extra cost and privacy issues. The fundamental limitations of IDPSs, specifically network-based monitoring devices, are beyond the scope of this paper. Here, we focus on an IDPS alert with a packet payload, which amounts to a large volume of data overwhelming security analysts.
The rest of the paper is organized as follows. We introduce the problem and motivation in
Section 3. The new scheme is presented in
Section 4, and the experimental results are discussed in
Section 5.
Section 2 and
Section 6 cover related work and conclusions, respectively.
2. Related work
Alert Fatigue and SOC. Alert fatigue is a common problem for SOCs where threat detection systems such as IDPS and SIEM generate high rates of false alerts [
4,
5,
12,
13]. Commercial products adopt general rules to cover more threats than specific exploits. These general rules cause a significant number of false alerts [
1,
13,
14]. Recent threat detection products provide a tuning method to reduce false alerts [
9,
10], or SOCs have their own heuristics for determining and fixing false alerts [
15]. However, over-tuning causes missing real attacks [
9,
10,
15]. In this paper, we present the first semi-automatic tuning method to reduce alert fatigue by introducing new features from alerts.
Network Intrusion Detection and Prevention. A network-based intrusion detection system (IDS) inspects packets to find cyberattacks and suspicious activities. An intrusion prevention system (IPS) not only identifies threats but also blocks the threat [
16]. Although these systems have played a pivotal role in cybersecurity in recent decades [
1,
2,
3,
14,
17], there are two issues; first, as more network packets are encrypted, IDPSs cannot look up attack signatures. To tackle this problem, a decryption box can be deployed to obtain plain packets [
11], or anomaly detection can be used [
18,
19]. Second, too many false alerts are generated, resulting in alert fatigue [
4,
5], the main topic of this paper.
Machine Learning for Network Intrusion Detection. Given the huge numbers of alerts from IDPSs, machine learning has become an alternative to expensive manual analysis [
20,
21,
22,
23,
24,
25]. Although there are many machine learning approaches for network IDPSs, RAID is the first to use new features from packet payloads of alerts and provide clustering-based tuning to reduce alert fatigue.
We emphasize that there have been a lot of research attempts to reduce false alerts, but to the best of our knowledge, this paper is the first that filters out false alerts on the content of an IDPS packet.
3. Problem and Motivation
Alert fatigue, or threat alert fatigue, is an information overload problem in which security analysts miss true attack alerts hidden in the noise of false alarms [
5]. Alerts are generated not only by network-based IDPSs [
1], but also by other security devices such as host-based IDPSs [
26], Endpoint/Network Detection and Response (EDR/NDR), Web Application Firewalls (WAF), and Security Information and Event Management (SIEM). This paper focuses on alerts of network-based IDPSs, but the main idea can be applied to other types of security devices.
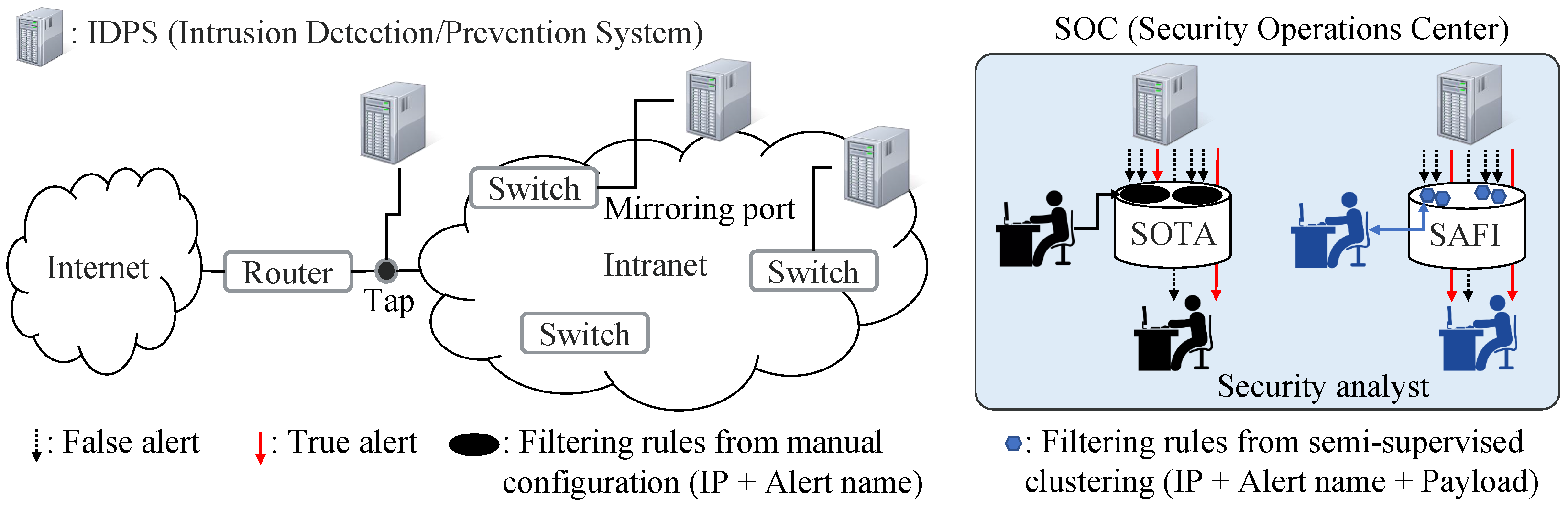
We assume that IDPSs are deployed at a gateway and critical points in enterprise networks and they inspect every packet to find suspicious activities or attacks as shown in
Figure 1. A network tapping device can copy packets to IDPSs, or a mirroring port of a network switch can provide the IDPS with any packet going through the switch. If a packet contains any attack signatures, the IDPS generates an alert or event. In this paper, we use alerts and events interchangeably.
If an alert is triggered by real attacks, we call it a true alert; otherwise, it is called a false alert. In this sense, a true alert is a true positive whereas a false alert is a false positive. An alert generally consists of several fields of time, a source IP address, a destination IP address, a source port number, a destination port number, an alert name, and a packet payload that has triggered the alert. Although a packet payload is optional for an IDPS alert, we observe that most IDPSs provide it to give security analysts additional information about the alert. We denote an alert as alert:={time, sIP, dIP, sPort, dPort, alert name, payload}. A maximum packet payload is around 1600 bytes in length.
Figure 1 shows that a security operations center (SOC) collects alerts from IDPSs where security analysts review the alerts for further analysis. The number of alerts always overwhelms the number of analysts or human resources. Therefore, an alert-filtering step is essential for automatically processing insignificant alerts. If the filtering step is not designed carefully, true alerts may also be filtered out or ignored mistakenly. This may cause a serious security hole.
Coarse-grained alert-filtering problem. Latest IDPS and SIEM products provide a simple and practical method for tuning false alerts by establishing a list of exception or filtering rules; the current best practice is that frequent alerts of the same alert name and IP address are grouped together and ignored at once [
9,
10]. For example,
,
, and
have the same internal destination IP address and alert name in
Figure 2. After manual investigation, a security operator or analyst concludes that these alerts are not real threats and adds a new filtering rule that consists of the IP address and alert name,
. This filtering rule would suppress or remove any alert of the same group. However, this simple filtering rule may cause a serious problem; a real attack is detected by an IDPS as
later, but this alert would be falsely and automatically ignored by the filtering rule. We call it a
coarse-grained alert-filtering alert problem that really happened with the Target data breach in 2013 [
7]. The problem still exists because a filtering rule still consists of an alert name and an IP address, too coarse-grained to accurately distinguish a true alert and a false alert.
Analysis cost and accuracy. We assume that a huge number of m IDPS alerts are given to security analysts. If there were infinite human resources, all of the m alerts could be manually analyzed. If there are no human mistakes, the analysis accuracy would be perfect. Because this is impossible, filtering rules are essential in automatically ignoring as many alerts as possible; then, the remaining alerts are manually analyzed by security analysts. For example, in SOTA, after a few sample alerts are randomly chosen from a group of alerts with the same alert name and IP address, only the samples are manually analyzed. If all of the samples are proven to be false (true) alerts, all alerts from the same group would be considered or predicted as false (true) alerts, and therefore no human resources are spent except the samples. If the samples consist of both true and false alerts, the group is called a mixed group. Ideally, all alerts from the mixed group should be manually analyzed to prevent any security holes. This strategy of SOTA may cause two problems; first, the prediction based on the samples would be wrong. Second, alerts from the mixed groups are too many to be manually analyzed. In practice, only a small portion of these alerts are analyzed, and the others are ignored. In addition, because the critical decision is totally dependent on the heuristics of security analysts, no consistent policy is established in alert filtering.
In this paper, we define the analysis cost for SOTA as the ratio of the number of alerts that security analysts manually analyze to the number of total alerts. For the mixed group, all alerts of the group should be analyzed; otherwise, only sample alerts are analyzed. We also define accuracy as the ratio of the number of correctly estimated alerts on whether they are true or false to the number of total alerts. In this sense, the purpose of SOTA and SAFI is to minimize the analysis cost and to maximize the accuracy.
Motivation. In this paper, we argue that a packet payload embedded inside an alert makes good features for fine-grained filtering rules. The intuition is that frequent false alerts are often caused by similar packet payloads that include the same alert name and the same server IP address. On the contrary, we also observed that the packet payload of a true alert is generally quite different from those of repetitive false alerts as in
Figure 2. This motivated us to study a new clustering method that divides a group of alerts of the same name and IP address into multiple subgroups based on the content of a packet payload, which has not been studied in previous work.
4. SAFI: Semi-Supervised Alert Filtering
We present SAFI to mitigate the coarse-grained alert-filtering problem; SAFI distinguishes false alerts and potential true alerts by clustering alerts of the same group into smaller and homogeneous subgroups, or clusters, based on the new features from a packet payload inside an alert. The key idea is to analyze a few samples per cluster rather than per group in a fine-grained way; if all the samples from a cluster are either true alerts or false alerts, all alerts of the cluster are automatically processed the same way to save human resources or analysis costs.
There are two main steps for SAFI to cluster alerts into fine-grained subgroups. Each subgroup has alerts of not only the same alert name and IP address but also similar packet payloads. In this paper, two packets are considered to have similar payloads if their byte sequences are similar to each other. The first step of SAFI is to simply divide alerts into groups of the same alert name and IP address the same as in SOTA [
9,
10]. Then, SAFI extracts features from packet payloads of alerts, and the features are converted into a fixed-size vector. In this paper, we use Term Frequency-Inverse Document Frequency (TF-IDF) for vectorization (
https://scikit-learn.org, accessed on 17 November 2023), but any other schemes can be used instead. In the second step, the fixed-size vectors are used to cluster alerts from the same group into multiple subgroups. Then,
n-samples per cluster are selected and manually analyzed. Depending on the analysis results, each cluster is considered as a true-alert cluster, or a false-alert cluster, or a mixed cluster. If the cluster is a true-alert cluster or a false-alert cluster, all alerts of the cluster are considered the same way. We explain each step in detail, and provide how to compare SAFI with SOTA in terms of the accuracy and analysis cost.
4.1. Vectorization and Clustering
In SAFI, each alert is represented as a fixed-size vector. The vector is constructed from a packet payload embedded in an alert. The packet payload of an alert is a byte sequence less than 1600 bytes; we use the TF-IDF vectorization scheme to transform the payload into a fixed-size vector because of its simplicity and efficiency. In this sense, we treat the payload of an alert as a text. We believe that two alerts of very similar packet payloads with the same alert name and IP address would be either true alerts or false alerts. Therefore, a cluster of similar packet payloads can be safely filtered out as either a true-alert cluster or a false-alert cluster.
The soundness of SAFI comes from our observation on real IDPS alert datasets; the same false alerts are repeatedly generated if a certain attack signature or string appears repeatedly. For example, a furniture website may include the string of “drop table” as a furniture type, but this may cause IDPSs to trigger an alert of a SQL injection attack [
23]. The problem is that the same alerts repeat whenever that web page is reached by innocent clients. These repeated alerts should often include the same server IP address and alert name. The packet payloads of the alerts probably have very similar contents except a few bytes. The difference can be caused by the packet size or meta information of the packets.
When we apply TF-IDF vectorizer to these packets, the resulting vectors look very similar to each other, and therefore the distance between them is also small. This means that they should form a dense cluster when a clustering algorithm is applied. In this paper, we use a prototype clustering algorithm of [
27] because the algorithm is fast and its performance was confirmed against a security dataset. However, any clustering algorithm can be used instead for SAFI.
We explain the prototype clustering in details [
27,
28]. The quality of clustering results depends on how to properly choose the prototypes. The first prototype alert is randomly selected. Then, for this current prototype vector, we find those vectors that are similar to the prototype; two vectors of
and
are considered similar only if their cosine similarity is larger than
, a predefined threshold. All the similar vectors to the current prototype alert make a new cluster. Then, the next prototype alert is selected. According to the heuristic algorithm of [
27], we select an alert with the largest distance to the current prototype as the next prototype. Then, the new prototype and its similar vectors make the second new cluster. A vector that already belongs to any cluster is excluded for the next step. This process is repeated until every vector belongs to its cluster. Finally, the clustering algorithm merges two clusters if the similarity of their prototype alerts is beyond
. The algorithm starts with individual prototypes as singleton clusters before successively merging the two closest clusters. The algorithm terminates when the distance between the closest clusters is larger than (
[
27,
28]. The default value of
is set to 0.9.
Figure 3 shows the difference between SOTA and SAFI; only an alert name and an IP address are used to group alerts in SOTA, which in this example are 10.12.1.2 and XSS (Cross-Site Scripting) attack. On the contrary, additional information about the packet payload is also used in SAFI, which can distinguish true alerts and false alerts.
4.2. Sampling and Filtering
After clustering on alert vectors is finished, a number of clusters are generated. We define the number of samples per cluster, denoted as n, to randomly select alert samples for each cluster. In SAFI, we conservatively conclude that a cluster is a mixed cluster if at least one sample out of n is different from the others in terms of a true or false alert. If a cluster includes less than n alerts, all alerts of the cluster become samples.
If a cluster is a mixed cluster, we assume that all alerts should be manually analyzed to prevent any security holes. When n becomes larger, we decide the type of cluster more carefully. For example, suppose that n is set to 10. Then, only when 10 sample alerts are all true (false) alerts, the cluster is determined as a true (false) cluster and the automatic filtering can be applied to the other alerts from the cluster. On the contrary, the cluster type is determined only with one sample when n is set to one. It is interesting that the accuracy of SAFI still remains high even with because there are many dense clusters of similar packet payloads.
4.3. Comparison of SAFI and SOTA
We compare SAFI and SOTA in terms of the analysis cost and accuracy. A combination of an alert name and an IP address makes different alert groups in SOTA [
9,
10]. In SAFI, each group of SOTA is further divided into subgroups, or clusters, via clustering on the packet payload of an alert. Therefore, the number of clusters of SAFI is bigger than the number of groups of SOTA. We assume that
n alert samples are randomly selected from a SAFI cluster and a SOTA group, and these samples are manually analyzed. In this sense, the analysis cost of SAFI might be higher than that of SOTA. This is actually true when
. However, the accuracy of SOTA is expected low because many groups from SOTA must be mixed up with true alerts and false alerts.
When n is greater than 1, multiple samples are randomly selected from a SOTA group. Therefore, these multiple samples may reveal that the group is mixed, and in this paper, we leave the alerts of the group to security analysts. This increases the analysis cost of SOTA, and the analysis cost of SAFI becomes lower than that of SOTA.
In this paper, we define the analysis cost as the ratio of the number of alerts that requires manual analysis to the number of total alerts. The analysis cost ranges from 0 to 1; when all alerts are manually analyzed, the cost becomes 1. We assume that a manual analysis correctly determines if the given alert is true or false.
For accuracy, SAFI outperforms SOTA because there are many dense clusters in SAFI. A dense cluster often includes false alerts of similar packet payloads. Therefore, the sample alerts represent the original cluster quite well. The definition of accuracy, precision, recall, and F1 score is as follows: accuracy is the ratio of the number of correctly predicted labels to the total number of alerts. The precision is the ratio of the number of correctly predicted true alerts to the number of alerts that are predicted as true alerts. The recall is the ratio of the number of correctly predicted true alerts to the number of true alerts. It is well known that IDPS alert datasets may include a small number of true alerts but a large number of false alerts. In this case, if SAFI or SOTA predicts all alerts as false, the accuracy and precision would become high but the recall would be low. On the contrary, if SAFI or SOTA predicts all alerts as true, the recall would become high but the precision would be low. Actually, the precision and recall are a trade-off. Therefore, the F1 score is a good choice to measure the quality of label prediction, which is defined as . In this paper, we use the F1 score when comparing SAFI and SOTA.







{kind=link}
{kind=link}
{kind=link}
{kind=link}