Abstract
In today’s digital era, the realms of virtual reality (VR), augmented reality (AR), and mixed reality (MR) collectively referred to as extended reality (XR) are reshaping human–computer interactions. XR technologies are poised to overcome geographical barriers, offering innovative solutions for enhancing emotional and social engagement in telecommunications and remote collaboration. This paper delves into the integration of (AI)-powered 3D talking heads within XR-based telecommunication systems. These avatars replicate human expressions, gestures, and speech, effectively minimizing physical constraints in remote communication. The contributions of this research encompass an extensive examination of audio-driven 3D head generation methods and the establishment of comprehensive evaluation criteria for 3D talking head algorithms within Shared Virtual Environments (SVEs). As XR technology evolves, AI-driven 3D talking heads promise to revolutionize remote collaboration and communication.
1. Introduction
In today’s digital world, virtual reality (VR), augmented reality (AR), and mixed reality (MR) are changing the way we perceive and interact with digital environments. These rapidly developing technologies, often grouped under the general term of extended reality (XR) [1], have the potential to push the boundaries of traditional human–computer communication and interaction. As we immerse ourselves in these dynamic digital spaces, new horizons are emerging, offering innovative solutions to long-standing challenges in telecommunications and remote collaboration, such as emotional and social engagement and remote team collaboration [2]. One of the most significant issues stems from the physical separation of users within these XR spaces. While XR has the power to bridge vast geographical distances, the methods of communication currently in place often fall short of delivering truly immersive and natural interactions.
To meet this need, innovative solutions are needed. They need to build on the legacy of data transmission and visualization, fostering connections that are comparable in authenticity to face-to-face meetings. The goal is to achieve a level of fidelity in remote interactions that not only transcends the limitations of distance, but also reproduces the details of human communication, thereby unlocking the full potential of XR technologies. As technology advances, artificial intelligence (AI) is beginning to revolutionize XR [3]. AI, with its capacity to learn, adapt, and perform human-like interaction, is a tool to overcome the obstacles posed by VR, AR, and MR. Among the countless applications of AI, we can highlight the integration of 3D talking heads in telecommunication systems [4].
The application of 3D talking heads within telecommunication AR, VR, and MR systems represents a significant leap forward. These lifelike avatars, powered by AI, have the potential to elevate remote communication to unprecedented levels of realism and engagement. By harnessing AI-driven algorithms, these digital entities can replicate human expressions, gestures, and speech patterns with remarkable accuracy, erasing the physical boundaries that have long separated remote collaborators [5].
1.1. Research Motivations
In recent years, much attention has been paid to methods and algorithms for creating audio-driven 2D [6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32] and 2.5D [33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52] talking faces. A detailed and extended analysis of existing methods and algorithms for this purpose is needed, as well as their possibility of implementation in virtual, augmented, and mixed reality systems. It should be noted that in traditional VR (or some AR), direct communication face to face is not possible due to the hidden face of the VR/AR helmet. One of the possibilities provided by the talking face is its implementation as a basic component in future conference systems with telepresence.
Moreover, it is worth noting that existing articles that review talking head technologies typically do not consider their application contexts. This omission underscores the research gap we aim to fill by conducting an in-depth analysis of 3D talking head technology within the contexts of VR, AR, and MR. This research will provide valuable insights into the potential integration of 3D talking heads as fundamental components in future telepresence conference systems, addressing a critical need in the field.
1.2. Research Contribution
The main contributions of our paper are as follows:
- We prepare a deep and extensive analysis of current research approaches for audio-driven 3D head generation. We show that some of these techniques can be used in the proposed architecture;
- We propose general evaluation criteria for 3D talking head algorithms in terms of their Shared Virtual Environment application.
1.3. Literature Review and Survey Methodology
The Preferred Reporting Items for Systematic Reviews and Meta-Analyses, often known as PRISMA [53], served as a base for the current comprehensive literature review that was conducted. The standard guidelines developed by Kitchenham [54] were utilized, and Figure 1 presents an illustration of the screening and selection procedure for the studies.

Figure 1.
Selection and screening process: a comprehensive overview. A total of 21 articles are finally included in the review of 3D talking head algorithm application as of a telecommunication system.
We searched for papers about 3D talking heads in the Google Scholar database. During the screening process, we employed the following keywords and word combinations: 3D talking head, 3D talking face generation, audio-driven 3D talking face, applications, VR, AR, MR, telepresence, XR, and others. The search resulted in 96 articles, of which 19 were from our previous research. Then, 75 were excluded based on the following criteria: articles published more than 5 years ago (5), review articles (2), extended abstracts (2 pages in total) (6) or additional materials (Appendix A) (3) and based on a head model, not fully 3D (59). Finally, the content of 21 articles was examined in detail; these articles were considered as the most relevant on the topic and included in the review of 3D talking head algorithm application as of a telecommunication system.
1.4. Paper Structure
The structure of the article is illustrated in Figure 2. Section 1 contains a brief introduction to the topic. In Section 2, the talking head animation representation in Shared Virtual Environments for this research is given. Section 3 presents assessment criteria for 3D talking head algorithm applications in Shared Virtual Environments. Finally, the article is concluded in Section 4.

Figure 2.
Paper structure. The article is divided into five sections: Introduction, two sections where the main contributions of the article are presented and a Conclusion.
2. Talking Head Animation in Shared Virtual Environments
The idea of a talking head might be interpreted as a dynamic interaction of shared virtual spaces and artificial intelligence. Regardless of the fact that it is a computer representation of a human head, it plays a crucial role in digital connections and transcends the conventional barriers that are present among existing forms of communication.
2.1. An Overview of Talking Head Animation
The term talking head is related to an artificial model of a human head and is also commonly used to describe a form of video or 3D visual presentation in which an individual’s head and shoulders are displayed [55]. This format is frequently employed to present a speech. Moreover, it provides more realistic speech interaction, representing the system as an intelligent being. It should also be noted that some users have problems accepting notifications via only the voice, so a visually realistic representation of a talking head can also be beneficial. In addition, employing gestures from talking heads for human–computer interaction can also serve as a valuable aid for individuals with disabilities.
Advances in SVEs are currently focused on creating 2D, 2.5D, and 3D talking faces that can generate realistic human facial expressions in response to text or audio inputs. In [56], we introduce a classification system for techniques involving 3D speaking human faces, organizing them into three categories: GAN-based [8,57], NeRF-based [14], and DLNN-based methods [58], where algorithms utilize 2.5D or 3D models of the head. A Generative Adversarial Network (GAN) is an instrument that is both promising and effective, and it can be used to accomplish unsupervised learning of data distribution. Neural radiance fields, also known as NeRF, are a type of Neural Network that is completely linked and possesses the potential to generate novel viewpoints of complex 3D settings while employing only a select group of 2D images as input.
From the current review, where we examine only algorithms working with full 3D head models, it can be concluded that no particular Deep Learning Neural Network (DLNN) architecture for 3D head animation is preferred. For learning temporal dependencies, standard convolutions are used [59], as well as Long Short-Term Memory (LSTM) networks [60], multi-head attention and dedicated approaches [61]. Three-dimensional spatial information is encoded and decoded using Gated Recurrent Unit (GRU) layers [62], a U-net type decoder [63], and multi-layer perceptron (MLP), convolutional neural networks, or a combination of the two [59,61]. There appears to be no one best approach to creating Neural Network-based head animation, judging by the variety of methods that have been proposed in the literature.
2.2. Conceptualization of Shared Virtual Environments and Their Applications
Shared Virtual Environments (SVEs) are computer-simulated environments that are shared by several users. They can be used for different purposes, such as collaboration, entertainment, and education. The realism in these artificial environment is a key aspect when it comes to usability, but implementing it is a major challenge. This is due to the numerous characteristics that must be taken into account, such as the degree of detail, the realism of the physics, and user behavior. To address these and other difficulties, multiple approaches for representing reality in SVEs are proposed in the literature. One popular method is to employ photorealistic graphics [64]. This involves creating a realistic picture of the area using high-resolution images. Photorealistic graphics, on the other hand, can be computationally expensive and may not be required for all applications. Stylized graphics is another option [65]. This is accomplished by employing simplified or abstract representations of the environment. Stylized graphics can be less computationally expensive than photorealistic graphics and more expressive as well. In addition to the graphics, the physics of the SVE contributes to the impression of realism. The physics should be realistic enough to allow users natural interaction with their surroundings. However, the physics must be simplified enough to be computationally efficient. Finally, user behavior influences the perception of realism in an SVE. Users should be able to interact naturally with one another and with their surroundings. This requires careful design of the user interface and interaction mechanics. The field of expressing reality in SVEs is still in its early stages. There is no one technique that is suitable for all purposes. The optimal solution is determined by the SVE requirements.
- Characteristics of Virtual, Augmented and Mixed Realities
The concept of being in the same reality refers to several types of digital meetings where users can actively participate in an immersive experience, enhancing user engagement, collaboration, and involvement. These encounters include a range of interactions, spanning from the physical world (reality) to digital representations and simulations in VR, AR, and MR. However, there are important variances. VR is a computer-generated immersive world, where a headset displays the virtual world and blocks out the real world. AR may be used to provide real-world information, which overlays digital data on the physical environment through a phone, tablet, or headset. Augmented Virtuality (AV) is a less widely used term that relates to the concept of incorporating real-world elements into a primarily virtual environment. MR blends augmented and virtual reality to offer a seamless and engaging experience. The origins of such immersive technologies can be traced back to the 1960s and subsequent decades [66]. Ivan Sutherland’s groundbreaking contributions [67] brought forth innovative approaches to human–computer interaction, exemplified by the Sketchpad system. Sutherland’s system initiated a profound shift in communication methods, enabling swift exchanges through line drawings. The term AR was coined by Tom Caudell [68] at around the same time, during his tenure at Boeing in 1990, showcasing the ability to seamlessly integrate digital information into the physical environment, thereby enhancing industrial operations. In addition, Myron Krueger’s contributions [69] laid the groundwork for the concept of artificial reality, playing a pivotal role in shaping the evolution of mixed reality. The taxonomy introduced by Milgram and Kishino in 1994 [70] made significant strides in comprehending mixed reality displays, elucidating the intricate interplay between real and virtual elements. These pivotal advancements provided the bedrock for the emergence of immersive technologies like virtual reality, augmented reality, and mixed reality. Consequently, these technologies reshaped the notion of Shared Virtual Spaces and fundamentally transformed the way humans interact with technology.
One prominent application of VR/AR/MR might be its utilization for facilitating remote collaboration among individuals in a contextualized environment. These computer-generated worlds, populated by multiple users, enabled real-time interactions facilitated by intuitive computer tools, marking the advent of Digital Virtual Environments (DVEs) [71]. The notion of DVEs was expanded via the popularity of Shared Virtual Spaces (SVSs), and these settings now offer an intuitive platform for people to engage collaboratively [72]. The evolution of Shared VE introduced tools like the Immersive Discussion Tool (IDT), an asynchronous collaborative system. This tool facilitates productive design exchanges within SVSs, enabling participants to reason about 3D models through various communication modes, such as diagrammatic marks, dynamic simulations, and text annotations [73]. Study [74] investigated the behavior of small participant groups within extensive distributed collaborative virtual environments (CVEs). Representing the largest study, the authors examined complex collaborative puzzle-solving tasks. The outcomes indicate a positive link between the sense of place-presence, co-presence, and group cohesion. Furthermore, the notion of ”togetherness” proposed by Durlach and Slater [75] relies on the sense of collective presence within a shared spaces—a counterpart to an individual’s presence in a VE (virtual environment). The authors’ emphasis on the role of tactile communication aligns with their exploration of the dynamics between place-presence, co-presence, and group harmony. While the term ”Shared Virtual Spaces” was introduced in the article’s title [76], its actual context relates to the paper’s exploration of collaborative design. This emphasizes the intricacies of problem space development and transformation, highlighting the roles of unstructured verbal and graphic communication in these processes. The introduction of the Immersive Discussion Tool (IDT), an asynchronous collaborative system, serves the purpose of facilitating productive design exchanges. Compared to alternatives like audio conferencing and video conferencing, Digital Virtual Environments emerged as a promising solution, presenting unique advantages and diverse potential applications [77]. Collaborative virtual environments found use in various domains, including distributed simulations, 3D multiplayer games, collaborative engineering software, and collaborative learning applications [78].
- Introduction in Shared Virtual Environments
SVEs are an intriguing subset of the broader field of immersive technology. We aim to provide insights into the idea of Shared Virtual Environments, distinguishing them from Shared Virtual Spaces (SVSs), and investigating their applications across various realities such as VR, AR, MR, and telepresence. Before diving into applications, it is important to understand the difference between SVEs and SVSs. The terminology introduced in the literature through the years related to digital technology supporting immersive remote collaboration is not strict, as presented so far. Two notions stand out, namely “environment” and “space”. These notions include many modalities via which digital interactions occur within the virtual world. The primary objective of the Shared Virtual Environment is to establish an interactive and collaborative environment where users may actively engage with one another and their surrounding elements. The fundamental goal of this environment is to encourage users to engage in quick interactions, which are aided by the use of avatars and items. The degree of engagement is important, enabling users to actively engage in a multitude of activities. Realism is attained by employing realistic avatars, precise physics models, and lifelike interactions, rendering SVE well-suited for applications such as multiplayer games and collaborative workspaces.
On the other hand, the term “Shared Virtual Space” pertains to a computer-generated representation of a setting that may or may not provide comparable degrees of interactivity when compared to SVE. While retaining the functionality for users to interact with a virtual environment, the focus may shift towards enhancing the visual fidelity and complexity of graphics and environmental elements rather than prioritizing substantial real-time interactions. This approach has the potential to be employed in several applications, including, but not limited to, 3D art galleries and 360-degree virtual tours. These example applications allow users engagement with and navigation through the environment, enabling them to gain a diverse and immersive experience. A fundamental comparison between “environment” and “space”, in the context of immersive remote collaboration, is presented in Table 1. Based on this comparison, it can be observed that there exists a certain degree of interconnectedness between the two concepts under consideration. However, it is crucial to emphasize that notable distinctions can be discerned concerning realism and applications. In line with the objective of this article, the term “Shared Virtual Environment” is consistently utilized as more appropriate. In considering this comparative study, the inclusion of additional attributes of Shared Virtual Spaces (SVS) to SVE is considered to be an advantage, in particular encompassing digital representation and immersive visual graphics. Thus, we focus on the term Shared Virtual Environment in our paper from now on. We now offer a brief discussion regarding the relations between SVEs and each of the environments, namely VR, AR, and MR.

Table 1.
Shared Virtual Environment and Shared Virtual Space definition and comparison.
- Shared Virtual Environments in VR, AR, and MR Applications
Technologies such as talking head animation can be used to effectively solve existing problems in Shared Virtual Environments. SVEs present various technological limitations that can potentially impede immersive user experiences [79]. These challenges have a direct impact on user interactions, collaboration, and overall satisfaction within such environments [80]. Despite the advancements in Virtual Environment (VE) technology, challenges persist, especially concerning the accurate representation of topographical data visualization [81]. Factors such as hardware constraints, algorithmic complexities, human factors, and integration challenges play pivotal roles in the effective implementation of VR technology [82,83]. One significant hurdle is the generation of real-time natural language instructions within virtual 3D worlds [84,85]. Additionally, creating lifelike virtual entities requires sophisticated behavior simulation and interactions [86,87]. The exploration of leveraging the human brain for creating immersive VR illusions continues to be an intriguing avenue of research [88,89]. Complex interactions within immersive environments, like the CAVE system, highlight the significance of addressing design challenges [90]. Furthermore, the integration of virtual worlds into educational settings demands solutions for content delivery, user engagement, and achievement [91]. In the era of XR technology, interdisciplinary collaboration becomes crucial for shaping impactful experiences and addressing the broader societal implications [92]. Meeting these multifaceted challenges necessitates innovative solutions and a user-centered design approach [93,94].
In VR, SVEs refer to the ability of multiple users to inhabit and interact within the same virtual space at the same time. Users wearing VR headsets can enter the same virtual world for social interactions, team-based gaming, collaborative work and training scenarios, and so on. Avatars or representations of users are frequently used in these shared VR environments, allowing them the possibility to communicate, interact, and collaborate within the digital realm.
In AR, SVEs allow multiple users interaction with augmented content in the same physical space. Participants in shared AR can view and interact with the same digital objects or information that is superimposed on their real-world surroundings. Collaborative AR applications can include shared visualizations, real-time annotations, or guided tours in which multiple users employ their AR devices to share a common augmented view. AR and SVEs can both help to improve telepresence experiences in different ways. For example, AR can improve telepresence by allowing remote users the ability to see and interact with a distant location’s real-world surroundings. Users can feel telepresent in a digital environment where they can interact with others and virtual objects by using Shared Virtual Spaces. This is frequently used in online meetings, online events, and virtual social gatherings.
Regarding MR, SVEs blend elements from the real and virtual worlds, allowing multiple users interaction with virtual objects and each other in a shared physical space. Devices with transparent displays allow user participation in shared mixed reality experiences in which holograms or virtual objects can be seen and interacted with by all participants.
The growth of applications of SVE is intrinsically linked with the advancement of immersive technologies. One such application and typical example is the Cave Automated Virtual Environment (CAVE), which is a system that is room-based and offers a fully immersive experience. The technology described by Galambos et al. [95] serves as a prime example of SVE, as it encompasses key features such as advanced configurations, a wide range of input and output devices, and various types of human interaction. Another example is the telepresence application of SVE, where individuals can fully engage with distant environments, effectively reducing the gap between physical and virtual realities. In contrast to virtual reality, augmented reality, and mixed reality technologies, telepresence possesses distinctive properties that facilitate a deep sensation of presence, effectively integrating the physical and digital realms [56]. A recently emerged example of SVE is the metaverse [96]. It is a conceptual framework that is frequently characterized as an intermediary layer connecting our physical reality with the virtual realm. It proposes a three-dimensional shared environment where augmented and virtual reality technologies enable a wide range of activities. The metaverse notion, as described by Damar [97], encompasses the prospective future of a dynamic and interconnected digital existence. When examining the topic of telepresence, metaverse, and immersive technologies like the CAVE, the progression of Shared Virtual Environments presents a range of potential combining actual, virtual, and augmented forms of contact. SVEs are related to VR, AR, and MR in that they can be utilized alongside with or as a component of these immersive technologies to enable collaborative (telepresence) experiences.
2.3. Aspects on Usability of Talking Head Animation in SVE
The utilization of talking heads in Shared Virtual Environments introduces a novel facet to communication and engagement. This multisensory encounter facilitates active participation and cooperation among individuals. Moreover, the integration of talking heads with spatial audio has the potential to enhance the perception of presence [98]. By providing users with the ability to visually and audibly perceive each other’s representations of themselves, the virtual environment effectively replicates the dynamics of human interaction in the physical world, leading to an increased sense of immersion. Although animated talking heads cannot fully replace human interactions, they provide a simplified and authentic representation of users, hence reducing the challenges associated with reproducing realistic avatar movements and behaviors [99]. The incorporation of talking heads featuring dynamic facial expressions and synchronized lip movements has the potential to greatly improve the overall quality of interactions and increase user happiness [100]. To emphasize applications with heightened immersion, we now place greater emphasis on 3D talking head animations, shifting our focus away from 2D talking heads moving forward. Figure 3 provides a conceptual representation of how 3D talking heads are employed across VR, AR, AV, and MR applications, irrespective of the specific use case.

Figure 3.
Fundamental representation of talking head in terms of VR, AR, and MR. A representation of how the talking head is integrated into each type of environment, highlighting the variations in virtual representation based on whether the environment is fully synthetic or extended to the real world.
Representation of realism: The first aspect of this representation is the selection of two potential sources of animated talking heads in terms of realism. In particular, the talking head can be of a person whose head has already been scanned and transformed into a 3D object, with animation abilities that should be able to represent realistic lip movements, facial expressions, and possibly changing the position of the head. Furthermore, the 3D talking head can take the shape of a graphical representation, such as an avatar, representing a user distinct from the individual, or it can manifest as an animated fictional character model. The choice between the usage of a 3D avatar or an animated 3D model depends on several factors related to the specifics of the application. Although the avatar of the talking head can be of a real human, it can also be of a fictional character. The fictional character can be used when the system does not support 3D model scanning and the ability to make the model dynamic, so the usage of a predefined avatar can be beneficial. Another usage of avatars might be applicable in cases of privacy restrictions, namely when an avatar can provide a layer of separation between a user’s real identity and their online or virtual presence. However, the utilization of a real 3D animated model of the user’s head is preferable to achieve a realistic and immersive experience.
Integration in VR, AV, AR, and MR environments: The second aspect of the utilization of a talking head is related to its integration in each possible environment. In terms of SVEs, the first two left-down pictures in Figure 3 represent an artificial environment, where either an avatar (in case of VR) or an animated model (in case of AV) is overlayed. When the real environment (in the case of AR) is used (the last two right-down pictures in Figure 3), the focus of virtual environment sharing shifts slightly, so that a 3D representation of the real scene is shared instead of the virtual one, and the avatar or the animated model of a talking head is superimposed. In the last scenario, it is important to clarify that we are referring to a distant real environment rather than a local one, in which case the rendering of the environment is not applicable in AR.
The examination of communication modalities is closely linked to the ongoing discourse surrounding the question of whether communication and processing should be confined to local systems or expanded to cloud-based solutions. Through an analysis of the existing environment, characterized by a prominent emphasis on local user-oriented systems, we recognize the inherent constraints and possibilities presented by various methods of implementation. The decision about the use of local or cloud solutions should be based on factors such as latency, real-time interaction, and the desired level of quality for the shared virtual experience.
The manifestations of 3D talking heads depending on real-time information processing: The success of a talking head algorithm depends not only on its ability to communicate effectively but also on its efficiency in using computational resources. In particular, the generation of communication data must be performed efficiently to ensure real-time interaction while minimizing the computational load. To address this challenge, we explore four different talking head communication scenarios, considering the ways in which the 3D avatar model and audio information are generated and processed.
An essential aspect of real-time communication is the synchronization of sound with the corresponding lip movements of the 3D avatar model. This synchronicity contributes greatly to the feeling of authenticity and naturalness in the dialogue. The presented scenarios serve as illustrative examples of different approaches for implementing talking head communication, with an emphasis on whether the 3D model, the audio information, or both are generated or processed in real time or offline. Each scenario represents a different combination of real-time and offline processing for these elements, impacting critical factors such as responsiveness, realism, and system complexity. Table 2 provides a summary of these four scenarios:
Table 2.
Scenarios for talking head communication.
- Scenario 1:
- Implies the real-time 3D model of the talking head and the audio information are simultaneously generated and processed. This approach enables dynamic and coordinated communication, improving the user experience.
- Scenario 2:
- Involves the real-time generation of the 3D model of the talking head while the audio information is processed offline. While the visual component benefits from the dynamics, there can be potential challenges in synchronizing with the audio.
- Scenario 3:
- The 3D model of the talking head is generated offline, followed by real-time processing of the audio input. This scenario ensures synchronization in the audio, although the visual representation may lack real-time dynamics.
- Scenario 4:
- Involves offline generation of the 3D model and audio information. While real-time dynamics may be limited, it allows for the combination of pre-designed elements. This scenario has been implemented by multiple authors.
Each scenario offers different advantages and trade-offs, making it essential to choose an approach that is consistent with the specific requirements and limitations of the communication system.
Concerning the scenarios presented so far, several articles from the literature can be grouped and examined. Real-time conversation, in the context of a talking head, refers to the accurate and rapid synchronization and generation of the audio-visual representation of a virtual character’s voice, facial emotions, and movements in response to another user. The virtual character’s reaction is delayed if the talking head generation is not a real-time one. Immersion and the feeling of natural conversation can be hindered by this delay. The overall experience can suffer if users perceive the contact as less genuine and responsive. For example, if there is a certain delay between the user’s verbal input and the virtual character’s response, the encounter may lose its authenticity and appear artificial. When interacting with virtual characters, real-time generation is critical to providing a realistic and immersive user experience. This allows for direct and normal communication and presence, as achieved by [59,61,101,102] (Scenario 1). The computational complexity required to rapidly process and render realistic audio-visual input makes it difficult to achieve real-time talking head production [58,62,103] (Scenario 4). To provide users with a more realistic and interesting experience, it is necessary to reduce lag and improve performance. As a solution to this problem, we propose the use of a pre-prepared participant-driven 3D model by real-time speech capture (Scenario 3).
2.4. Criteria for Usability of 3D Talking Head Animation in Shared Virtual Environments
The present section aims to outline certain evaluation criteria for talking head algorithms within the context of Shared Virtual Environments.
2.4.1. Aspects Related to Talking Head Evaluation
There are different features and requirements for VR, MR/AR, and a Mixed Reality Telepresence System with a talking face. These features are crucial for various aspects of talking head applications:
Facial tracking pertains to the capability of monitoring and tracing facial movements. Virtual reality necessitates the use of sensors, whereas mixed reality and augmented reality rely on precise tracking to achieve realistic avatars and interactions. Facial tracking plays a crucial role in the telepresence system as it is vital for the creation of authentic avatars and the accurate portrayal of facial expressions.
Face animation refers to the process of animating face emotions. In the realm of VR, the incorporation of lifelike interactions is considered necessary. MR and AR necessitate the utilization of lifelike animation to provide immersive interactions. The telepresence system utilizes advanced technology to display the facial expressions of the user onto avatars.
Realistic rendering pertains to the level of graphical fidelity and the extent to which the VE can be interacted with. VR technology employs visual graphics. MR and AR necessitate active engagement with the surrounding world and the occurrence of occlusion. The integration of 3D avatars with the surrounding environment is a crucial requirement for the telepresence system.
Lip synchronization is the process of coordinating the movements of one’s lips with the spoken words being produced. The importance of this aspect is significant across all three technologies. VR encompasses the synchronization of real-time facial expressions and the spatialization of audio. The technologies of MR and AR, along with the telepresence system, primarily emphasize the analysis and coordination of lip movements and speech.
User interaction comprises several approaches by which users engage with a system or interface. VR encompasses the utilization of hand gestures, head tracking, and gaze detection as integral components of the immersive experience. MR and AR technologies employ several interaction modalities, including voice commands, gestures, touch interfaces, and methods for engagement. The telepresence system utilizes many methods, such as gestures, touch, and other modalities, to facilitate contact.
Performance optimization refers to the process of enhancing the efficiency and effectiveness of technology performance. VR encompasses the utilization of rendering pipelines and reducing the impact of delay. MR and AR necessitate minimal latency to facilitate smooth and uninterrupted user interactions. The telepresence system requires a low level of latency to facilitate smooth interaction between the user and the avatar.
Spatial mapping refers to the process of representing the actual environment within a virtual area. VR does not necessitate correct physical environment visualization; however, MR and AR do require it. The telepresence system is responsible for the mapping of the remote environment to facilitate the integration of virtual items.
Robust network connection is crucial for facilitating real-time communication in the context of MR and AR. To achieve effective synchronization of avatars, the telepresence system necessitates the utilization of low-latency communication.
Realistic avatars, which are digital representations of users capable of projecting facial expressions, find application in MR/AR environments as well as telepresence systems. The inclusion of this functionality is not necessary for virtual reality applications.
2.4.2. 3D Talking Head Algorithm Criteria for VR/AR/MR/Telepresence Application
- Key Considerations as a Justification of the Criteria
When developing and deploying virtual reality, augmented reality, mixed reality, and telepresence applications, we can highlight three important system-related factors to consider, namely latency, availability of computing resources, and feasibility [104]. These factors affect the user experience, the technical feasibility of deploying the system in the various Shared Virtual Environments, and the overall success of the talking head algorithms.
In the context of immersive telepresence, latency refers to the time that elapses between the moment a user acts or moves and the moment the system reacts or provides feedback in response to those actions or movements. When it comes to talking head communication, latency is the time that elapses between the moment the user speaks or inputs information and the moment the talking head generates the corresponding audio and video (motion) response. Minimizing latency is essential for achieving natural, real-time dialogues. Users expect timely and adaptive responses from the talking head, ensuring a seamless and engaging experience.
The availability of computing resources represents the amount of processing power that is required to maintain the functionality of the system. It can also refer to the hardware and software capabilities required to support the talking head communication system. This includes the amount of memory as well as processing power and graphics capabilities. The creation of realistic facial expressions, lip syncing, and overall talking head behavior relies on sophisticated algorithms and models. Efficient resource utilization is key to ensuring smooth, responsive interactions while maintaining audio and visual integrity.
When evaluating the feasibility of deploying an algorithm in a cloud infrastructure or on a device such as smart glasses, it is critical to assess the ability of the algorithm to run efficiently on these individual platforms. In a cloud environment characterized by sufficient computing resources, the algorithm can work with increased efficiency, making it easier to offer voice and visual processing capabilities for the talking head.
On the other hand, in the context of using the algorithm on a device with limited resources, such as smart glasses, it is imperative to evaluate the feasibility of optimizing and modifying the algorithm to perform well within these constraints. This procedure may involve optimizing the code, implementing more efficient algorithms, or using existing hardware accelerators.
Setting the stage for a more immersive digital experience includes placing a strong emphasis on realism, particularly as a means of mitigating the challenges posed by the “Uncanny Valley” phenomenon [59]. For immersive telepresence, realism should be considered as the degree to which the virtual environment and representations of remote participants appear and behave in a way that is consistent with reality. This includes aspects such as realistic sound quality, correct representation of emotions and facial movements, realistic 3D models, and spatially appropriate positioning of virtual elements. The realistic and natural authenticity of the virtual representation should be taken into account while evaluating the realistic qualities of talking head communication. This includes elements such as correct facial expressions, lip movements that match the sound, and realistic behavior on the part of the character. The user’s ability to immerse themselves in and engage with the experience can be enhanced by achieving a high level of realism. Users expect the talking head to behave and look as realistically as possible, like a real person.
- Effective Implementation Under Different SVEs: User-centered Evaluation
When it comes to augmented reality applications, the effective implementation of the talking head algorithm depends on the fulfillment of several basic criteria. First of all, the algorithm should offer animation independence, allowing the user the choice from a wide variety of expressive animations that can be easily integrated into the extended world. In addition, the algorithm should contribute to the enhancement of reality. This should ensure that the talking head blends naturally with real-world objects, thereby enhancing the user’s impression of the environment around them. One of the most important requirements is the ability to integrate digital technologies with physical objects. Furthermore, it should enhance the depth of immersion by enabling users to engage with virtual elements and environments in an adaptable manner, thereby amplifying the sensation of presence. In addition, the ability of the algorithm to assist the user in navigating the environment, as specified by the navigation process requirement, is essential for AR applications. In the field of MR applications, the talking head algorithm is required to fulfill specific requirements to achieve optimal performance in an ever-changing environment. The flexibility of the animation is still very important since it enables the talking head to display a wide variety of animations that blend inconspicuously into both virtual and actual components. The algorithm should contribute to the depth of immersion by enabling it to interact naturally with both virtual and actual items that are contained inside the mixed environment. This should result in an enhanced sensation of immersion. It must be able to effectively operate within the actual physical or natural context. This ensures a seamless integration of the talking head into the diverse surroundings. In addition to these goals, the algorithm ought to improve the user’s sense of presence within the mixed reality world by producing a powerful impression of being there.
We address the key elements that contribute to the quality and effectiveness of immersive technologies, emphasizing user engagement, sensory feedback, and the blending of digital and physical worlds to create compelling experiences. In Table 3, we provide the criteria against which we evaluate a given talking head algorithm to determine whether it is suitable for MR, VR, or AR. We should mention, however, that this can be considered as a standard for evaluating the usability of a given system, especially in communication applications.
Table 3.
Comparison of evaluation criteria for talking head algorithms in different application types.
Among the main criteria is User presence. It plays a fundamental role in making users feel truly present and engaged in the virtual environment. This heightened sense of presence adds greatly to immersion and realism. Animation flexibility criteria is a key element to deliver realistic user presence and determine the adaptability of the talking head in conveying messages and emotions in different Shared Virtual Environments [44,48,105]. Diverse animated movements not only enhance authenticity, but also captivate users, making this aspect a productivity challenge. The Enhancement of reality criteria measures how effectively the talking head seamlessly integrates into the user’s environment. This assessment directly influences the creation of an experience that is not only coherent but also compelling and engaging. Due to the importance of realism, we added a separate column in Table 4 to show how it is achieved. The Depth of immersion criteria, in turn, is a measure of the talking head’s impact on the user’s sense of immersion and realism.
Table 4.
Evaluation of proposed algorithms for a 3D talking head according criteria listed in Table 3.
Assessing how effectively users can Operate effectively within the actual physical or natural context is paramount. This assessment ensures a seamless and integrated user experience across the virtual and physical realms. The inclusion of Haptic capabilities feedback systems adds another important layer. The criterion for Interaction with virtual objects shows how these systems allow users the interplay through tactile sensations, which greatly improves realism and interactivity. A key consideration is how well the talking head integrates with physical objects in the user’s environment. This is tracked through Integrating digital technologies with physical objects, which is compelling and enhances the overall user experience. To prevent interference and create a harmonious coexistence with the physical world, alignment with the real environment is crucial. This criterion ensures that the talking head blends effectively with the user’s surroundings. The Navigation process evaluation assesses how well the talking head helps users navigate and interact with their physical environment. Real-time navigation guidance enhances the usability and practicality of the entire experience.
The level of immersion allows interactions with virtual elements and environments that are adaptable, which expands the sensation of being there. In a manner analogous to augmented reality, the algorithm ought to contribute to the improvement of reality by incorporating a human-like interaction component into the digital world. It is necessary to have the potential to properly support haptic capabilities by aligning with haptic feedback systems. This allows for better VR interactions. In addition to that, the algorithm ought to allow for interaction with virtual items, offering users to experience real conversations. Last but not least, it needs to firmly foster user presence, by heightening the sensation of being present within a virtual world.
The importance of the talking head algorithm in telepresence applications cannot be understated. Its main role lies in its ability to facilitate communication between physically separated individuals. Animation flexibility stands out as a key requirement that allows the algorithm the ability to deliver expressive animations that facilitate effective communication and emotional expression, especially in remote meeting scenarios. By contributing to the enhancement of reality and creating a human-like presence in virtual communication, the speaking algorithm effectively bridges the gap between geographically distant participants. Additionally, its ability to enhance user presence promotes deeply engaging and immersive remote interactions, ultimately enhancing the overall sense of immersion.
3. Assessment at 3D Talking Head Algorithms in SVE
In the evaluation of 3D talking head algorithms for their application in Shared Virtual Environments, it is crucial to delve into their capabilities and suitability across diverse VEs. In this section, we review the talking head algorithms based on the criteria we have introduced so far. To comprehensively present their performance, Table 4 offers a detailed overview covering a set of criteria presented in Table 3, their focus in terms of their understanding of improving realism, and computational resources, where presented by the authors. It is essential to note that these three interrelated components together form a multidimensional evaluation framework for talking head algorithms. These methods aim to achieve heightened realism and seamless integration within diverse SVEs, and the assessment encompasses all aspects to ensure their effective deployment.
3.1. Realism Implementation
Also, it is of particular importance to derive information about user perception through user studies related to the generated talking heads [57,108]. Such an evaluation of the interaction between the virtual characters and the user reveals details and possible problems, the resolution of which would contribute to a more immersive and engaging user experience. Striving for excellence, the result of the talking head algorithm needs to be as realistic as possible. This need for a comprehensive set of strategies is required to be employed throughout the development process. This requires a set of comprehensive approaches that need to be used throughout the development process. These strategies are aimed at enhancing different aspects of realism and immersion, contributing to the creation of a convincing and engaging virtual experience using realistic audio-visual fusion [109], facial expressions and head pose consistency [116], 3D facial animation [103,106], synchronized audio and high-resolution 3D sequences [114], coherent poses and motion matching speech [107,111], lip synchronization and realistic expressions [58,61,62,113], audio quality and spatial realism [60], highly realistic motion synthesis [63], emotion transfer and user perception [108], improved visual appearance [57], realistic representation and spatial alignment [59].
Whether visemes are spoken by native speakers or not is another crucial question that has not been fully investigated. Visemes are the visual representations of various speech sounds created by facial muscles such as the tongue, lips, jaw, and jaw muscles. To create a believable talking head, precise lip synchronization and true mouth movements are essential. When performed by a native speaker of the language, the accuracy and proficiency of visemes pronunciation can be greatly improved. The correctness of viseme production is directly influenced by the natural command of phonetics, intonation, and speech rhythm that native speakers have. Visemes are created with the help of a native speaker to make sure that the virtual character’s lip movements and the spoken words are perfectly in sync. This creates a more accurate and convincing visual depiction of speech. Missing out on this detail could result in stuttering, awkward lip movements, and a general loss of realism in the talking head’s delivery. The paradox in this situation is that if the speaker is a non-native speaker and the natural speaker’s lip movement is influenced by the non-native speaker’s mother tongue, the same thing may still happen. Although the viseme in this instance will not be realistic, it will be real to the non-native speaker.
These considerations can be included in future research to produce more thorough and accurate findings, guaranteeing that the virtual character’s interactions are accurate not only aesthetically and vocally but also culturally and linguistically. The research can contribute to a comprehensive approach to generating fully lifelike and culturally aware virtual characters that are more accurate with a diverse range of users by addressing cultural quirks and integrating native speakers in visual pronunciation.
3.2. Covered Criteria for Talking Head Implementation
Regardless of the context of the talking head application, VR, AR, MR, or Telepresence, two criteria are not only common and inherent, but they can be referred to as the base, namely the enhancement of reality and the presence of the user in the virtual environment. According to the directionality of algorithms proposed in the scientific literature, the number of specific criteria increases. Meeting all these criteria should not be seen as a prerequisite, but rather these criteria should be regarded as interrelated elements to increase interest and enhance the comprehensive application of these technologies. The ability to develop innovative methods that increase the realism of virtual experiences increases interest in building different approaches aimed at creating immersive and engaging interactions between individuals and virtual objects. The realization of this concept has been revealed to varying degrees or adopted through different approaches. The coverage and perception of evaluation criteria are subjective, as the same algorithm criteria can be assigned to one or more implementation criteria. Hereafter, in this section, we offer our perspective on results, presented in Table 4.
A crucial aspect of achieving realism lies in the area of realistic facial animation, as shown in Table 4. These methods use a variety of techniques, from lip-synced 3D facial animation based on audio inputs to the synthesis of authentic 3D talking heads with realistic facial expressions and emotions. A sense of realism can be created through realistic 3D lip-synced facial animation from audio [112] and raw audio [113] inputs. Similarly, Tzirakis et al. [107] focus on the synthesis of realistic 3D facial motion, highlighting the commitment to increasing the authenticity of virtual characters and their interactions. The method of Liu et al. [103] contributes to improving the realism of facial animations based on audio inputs. The synthesis of authentic 3D talking heads combined with realistic facial animations [58,60,63] and emotions [108] creates a sense of reality in the virtual environment. In [61], the enhancement of reality is manifested through the creation of immersive and realistic scenarios. Similarly, Xing et al. [110] introduce the innovative CodeTalker method, which aims to generate realistic facial animations from speech signals, enhancing the reality of virtual characters. Further, Peng et al. [102] consider emotional expressions as a means of using animations with a heightened sense of reality. In particular, Haque and Yumak [62] combine speech-driven facial expressions with enhanced realism, offering users a more convincing and authentic experience. A significant step towards augmented reality is realized in [111], where the synthesis of 3D body movements, facial expressions, and hand gestures from speech is materialized into more tangible virtual characters. By combining synchronized audio with high-resolution 3D mesh sequences, the proposed techniques can contribute to enhancing reality in applications such as VR, AR, and filmmaking [114]. Realistic facial expressions and emotions can make virtual characters feel more relatable, thereby enhancing the sense of reality for users. The method in [114] creates avatars with talking faces that try to bridge the gap between reality and virtuality, especially in applications such as VR, AR, and Telepresence. Zhou et al. [101] pave the way for enhanced authenticity, generating speech animations that present virtual characters with real expressions and emotions. The drive for more lifelike animations is further supported by Liu et al. [116], where a focus on realistic facial expressions and head movements adds an enhanced sense of reality. Finally, Yang et al. [109] use a comprehensive approach, interweaving audio-visual content and facial animation to create a more authentic virtual environment, achieving the desired reality enhancement. By replicating natural facial expressions and movements, an environment is created where users feel fully engaged and connected.
Overall engagement with user presence is outlined in [59], as the article wraps around the idea of virtual characters effectively engaging with users in their virtual environment. This allows for realistic interactions where users are not just observers but active participants. Such immersive and engaging user experiences are also addressed by Nocentini et al. [113], where attention is directed to user presence in the context of virtual interactions. Different speaking styles, expressive movements, and related characters that work collectively to create a strong sense of user presence are important [114]. This is of particular importance for VR and AR applications [106], where the nature of these technologies consists of immersing the user in a digital environment, further contributing to the concept. Individual elements can contribute to an increased sense of user presence, such as realistic facial expressions and natural virtual representations [107], the generation of animations [60,63,110], emphasizing the immersion factor, creating an atmosphere in which users feel connected and engaged. The focus on enhancing emotional expressions [102] speaks to the authenticity of the virtual character’s responses, which resonate more truly with users. This resonance not only enhances the user experience, but also contributes to a heightened sense of presence. The generation of realistic and coherent movements contributes to the sense of presence and interaction with virtual characters [62,111,112]. By creating virtual objects that reflect human responses, these architectures create environments where users feel more engaged. Ma et al. [115] focus on the generation of realistic and controllable face avatars, enhancing the sense of user presence, especially in immersive environments such as VR and AR.
From the architectures discussed in Table 4, it is clear that there is no one-size-fits-all approach. Different algorithms prioritize different criteria, and the coverage of these criteria varies. However, they all share the common goal of creating more immersive, engaging, and realistic interactions in Shared Virtual Environments. This diversity highlights the multidimensional nature of the evaluation of talking head algorithms, as no single algorithm can outperform all dimensions simultaneously. This overview provides valuable insight into the strengths and weaknesses of different architectures, enabling further progress in creating realistic and engaging virtual experiences across a wide range of applications.
3.3. Seamless Integration within SVE
To present the obtained results, we use a coordinate system whose center is at coordinates placed on a Venn diagram (Figure 4). For each of the algorithms presented in Table 4, we calculate the degree of convergence of its application in Shared Virtual Environments using the criteria. Let us respectively denote the total number of covered criteria for virtual environment (where for s: 1 is AR, 2 is MR, 3 is VR, and 4 is telepresence). For each , we calculate the score based on criteria (common and particular for the VE) fulfillment:

Figure 4.
The type of space designed. Visual representation of the obtained results by means of a Venn diagram. For each of the algorithms presented in Table 4, the degree of convergence of its application in shared virtual environments (AR, VR, MR) was calculated using the criteria presented in Table 3. Those algorithms that cover 100% the criteria for telepresence are colored in blue, and the rest are colored black [57,58,60,63,106,107,108,109,111,116].
After that, we normalize the scores and bring them on the same scale , represented in %:
where n denotes the number of common or certain criteria for . We propose to assign equal weight to both general and specific criteria, that is, to divide the maximum value of the interval, one, by two, the number of the two sets of criteria. Therefore, the resulting sum for each group is multiplied by a weighting factor of . All common criteria for AR, VR, and MR are five in total, and the maximum possible number of specific criteria is in accordance with the number of criteria for the given VE (see Table 3). For telepresence, there are four criteria, all with equal weight of . To compare the scores and to determine the virtual environment possible application,
The visualization criterion is as follows: we compare the obtained results for MR, VR, and AR and take the two that are most fulfilled and cover at least one specific criteria (see Table A1). Please note that the criteria for telepresence are covered by a part of those for MR, VR, and AR. If they are fulfilled, then we mark it in blue. If , the one that covers more space-specific criteria is chosen. If it cannot be determined there, we assume that it is equally applicable to both virtual environments. They are marked in orange in the figure, and the position is in one of the two (arbitrarily chosen), or, in other words, the point should be symmetrical about the axis and equidistant from the center of the coordinate system. It is noteworthy that in the case of a tie, a higher percentage of covered criteria is always MR and the ties are with AR and VR, respectively. The higher the percentage of criteria covered, the more applicable the algorithm, and the closer it is to the center of the coordinate system. This presentation, in its essence, cannot fully represent the progress towards restoration of met criteria. For example, the most applicable AR algorithm is [57], respectively for (AR), (MR), (VR), and (telepresence). The most specific criteria, respectively, for both AR and MR are covered by [106], where (AR), (MR), (VR), and (telepresence). However, it covers only two general criteria, in contrast to [57], where all five are considered. Apart from telepresence criteria, which is fully covered by [57,58,60,62,63,107,108,109,111,112,114,115,116], there are no other 3D talking head algorithms that fully meet the all VE criteria. This gives reason to focus on the pervasiveness of the application of talking head algorithms and the trend toward VE telepresence.
4. Conclusions
This work aims, in addition to an extended analysis of the existing approaches to creating a talking face, to propose general evaluation criteria for 3D talking head algorithms in terms of their Shared Virtual Environment application. In future work, we will propose a conceptual scheme for an algorithm to generate a 3D pattern mesh of participants in a virtual environment that allows audio-only control using low-bandwidth channels, which would preserve the immersive experience of face-to-face 3D communication. Using a low-bandwidth communication channel dedicated only to audio links can offer several advantages, especially when implementing audio-driven 3D talking head algorithms. As an advantage, compared to high-bandwidth alternatives, it is more cost effective to implement and maintain, and enables real-time communication.
Author Contributions
Conceptualization, N.C. and K.T.; methodology, N.C. and K.T.; formal analysis, N.C. and N.N.N.; investigation, N.C. and N.N.N.; resources, K.T.; data curation, N.C. and N.N.N.; writing—original draft preparation, N.C., N.N.N. and K.T.; writing—review and editing, N.C., N.N.N. and K.T.; supervision, A.M.; project administration, A.M.; funding acquisition, A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research is financed by the European Union-Next Generation EU, through the National Recovery and Resilience Plan of the Republic of Bulgaria, project № BG-RRP-2.004-0005: “Improving the research capacity and quality to achieve international recognition and resilience of TU-Sofia” (IDEAS).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 3D | Three-dimensional |
| AI | Artificial Intelligence |
| AR | Augmented Reality |
| AV | Augmented Virtuality |
| CAVE | Cave Automated Virtual Environment |
| CNN | Convolutional Neural Network |
| Com. res | Computational resource |
| CVEs | Collaborative Virtual Environments |
| DLNN | Deep Learning Neural Network |
| DVEs | Digital Virtual Environments |
| GAN | Generative Adversarial Network |
| LSTM | Long-Short Term Memory |
| MLP | Multi-layer Perceptron |
| MR | Mixed Reality |
| NeRF | Neural Radiance Fields |
| NN | Neural Network |
| Oper. eff. within the actual PoNC | Operates effectively within the actual physical or natural context |
| PRISMA | Preferred Reporting Items for Systematic Reviews |
| and Meta-Analyses | |
| SVEs | Shared Virtual Environments |
| SVSs | Shared Virtual Spaces |
| VE | Virtual Environment |
| VR | Virtual Reality |
| XR | Extended Reality |
Appendix A
Table A1.
Scores and determination of the possible application of the virtual environment.
Table A1.
Scores and determination of the possible application of the virtual environment.
| Architecture | AR | MR | VR | Telepresence |
|---|---|---|---|---|
| Karras et al. [106], 2018 | 70 | 70 | 20 | 50 |
| Zhou et al. [101], 2018 | 30 | 30 | 30 | 75 |
| Cudeiro et al. [59], 2019 | 30 | 46.7 | 30 | 75 |
| Tzirakis et al. [107], 2019 | 50 | 66.7 | 50 | 100 |
| Liu et al. [103], 2020 | 20 | 20 | 20 | 50 |
| Zhang et al. [57], 2021 | 75 | 66.7 | 50 | 100 |
| Wang et al. [108], 2021 | 40 | 56.7 | 40 | 100 |
| Richard et al. [63], 2021 | 40 | 56.7 | 40 | 100 |
| Fan et al. [58], 2022 | 50 | 66.7 | 50 | 100 |
| Li et al. [60], 2022 | 40 | 56.7 | 40 | 100 |
| Yang et al. [109], 2022 | 50 | 66.7 | 50 | 100 |
| Fan et al. [61], 2022 | 20 | 36.7 | 20 | 50 |
| Peng et al. [102], 2023 | 40 | 40 | 40 | 75 |
| Xing et al. [110], 2023 | 30 | 30 | 30 | 75 |
| Haque and Yumak [62], 2023 | 30 | 46.7 | 30 | 100 |
| Yi et al. [111], 2023 | 50 | 66,7 | 50 | 100 |
| Bao et al. [112], 2023 | 40 | 40 | 40 | 100 |
| Nocentini et al. [113], 2023 | 30 | 30 | 30 | 75 |
| Wu et al. [114], 2023 | 50 | 50 | 50 | 100 |
| Ma et al. [115], 2023 | 50 | 50 | 50 | 100 |
| Liu et al. [116], 2023 | 40 | 56.7 | 40 | 100 |
References
- Ratcliffe, J.; Soave, F.; Bryan-Kinns, N.; Tokarchuk, L.; Farkhatdinov, I. Extended reality (XR) remote research: A survey of drawbacks and opportunities. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online, 8–13 May 2021; pp. 1–13. [Google Scholar]
- Maloney, D.; Freeman, G.; Wohn, D.Y. “Talking without a Voice” Understanding Non-verbal Communication in Social Virtual Reality. Proc. ACM Hum.-Comput. Interact. 2020, 4, 175. [Google Scholar] [CrossRef]
- Reiners, D.; Davahli, M.R.; Karwowski, W.; Cruz-Neira, C. The combination of artificial intelligence and extended reality: A systematic review. Front. Virtual Real. 2021, 2, 721933. [Google Scholar] [CrossRef]
- Zhang, Z.; Wen, F.; Sun, Z.; Guo, X.; He, T.; Lee, C. Artificial intelligence-enabled sensing technologies in the 5G/internet of things era: From virtual reality/augmented reality to the digital twin. Adv. Intell. Syst. 2022, 4, 2100228. [Google Scholar] [CrossRef]
- Chamola, V.; Bansal, G.; Das, T.K.; Hassija, V.; Reddy, N.S.S.; Wang, J.; Zeadally, S.; Hussain, A.; Yu, F.R.; Guizani, M.; et al. Beyond Reality: The Pivotal Role of Generative AI in the Metaverse. arXiv 2023, arXiv:2308.06272. [Google Scholar]
- Wiles, O.; Koepke, A.; Zisserman, A. X2face: A network for controlling face generation using images, audio, and pose codes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–686. [Google Scholar]
- Yu, L.; Yu, J.; Ling, Q. Mining audio, text and visual information for talking face generation. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 787–795. [Google Scholar]
- Vougioukas, K.; Petridis, S.; Pantic, M. Realistic speech-driven facial animation with GANs. Int. J. Comput. Vis. 2020, 128, 1398–1413. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Y.; Liu, Z.; Luo, P.; Wang, X. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9299–9306. [Google Scholar]
- Jamaludin, A.; Chung, J.S.; Zisserman, A. You said that?: Synthesising talking faces from audio. Int. J. Comput. Vis. 2019, 127, 1767–1779. [Google Scholar] [CrossRef]
- Yi, R.; Ye, Z.; Zhang, J.; Bao, H.; Liu, Y.-J. Audio-driven talking face video generation with learning-based personalized head pose. arXiv 2020, arXiv:2002.10137. [Google Scholar]
- Wang, K.; Wu, Q.; Song, L.; Yang, Z.; Wu, W.; Qian, C.; He, R.; Qiao, Y.; Loy, C.C. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 700–717. [Google Scholar]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Cham, Switzerland; pp. 716–731. [Google Scholar]
- Guo, Y.; Chen, K.; Liang, S.; Liu, Y.; Bao, H.; Zhang, J. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5784–5794. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4176–4186. [Google Scholar]
- Ji, X.; Zhou, H.; Wang, K.; Wu, Q.; Wu, W.; Xu, F.; Cao, X. Eamm: One-shot emotional talking face via audio-based emotion-aware motion model. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; ACM: New York, NY, USA, 2022; pp. 1–10. [Google Scholar]
- Liang, B.; Pan, Y.; Guo, Z.; Zhou, H.; Hong, Z.; Han, X.; Han, J.; Liu, J.; Ding, E.; Wang, J. Expressive talking head generation with granular audio-visual control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3387–3396. [Google Scholar]
- Zeng, B.; Liu, B.; Li, H.; Liu, X.; Liu, J.; Chen, D.; Peng, W.; Zhang, B. FNeVR: Neural volume rendering for face animation. Adv. Neural Inf. Process. Syst. 2022, 35, 22451–22462. [Google Scholar]
- Zheng, Y.; Abrevaya, V.F.; Bühler, M.C.; Chen, X.; Black, M.J.; Hilliges, O. Im avatar: Implicit morphable head avatars from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13545–13555. [Google Scholar]
- Tang, A.; He, T.; Tan, X.; Ling, J.; Li, R.; Zhao, S.; Song, L.; Bian, J. Memories are one-to-many mapping alleviators in talking face generation. arXiv 2022, arXiv:2212.05005. [Google Scholar]
- Yin, Y.; Ghasedi, K.; Wu, H.; Yang, J.; Tong, X.; Fu, Y. NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 8539–8548. [Google Scholar]
- Alghamdi, M.M.; Wang, H.; Bulpitt, A.J.; Hogg, D.C. Talking Head from Speech Audio using a Pre-trained Image Generator. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; ACM: New York, NY, USA, 2022; pp. 5228–5236. [Google Scholar]
- Du, C.; Chen, Q.; He, T.; Tan, X.; Chen, X.; Yu, K.; Zhao, S.; Bian, J. DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder. arXiv 2023, arXiv:2303.17550. [Google Scholar]
- Shen, S.; Zhao, W.; Meng, Z.; Li, W.; Zhu, Z.; Zhou, J.; Lu, J. DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1982–1991. [Google Scholar]
- Ye, Z.; Jiang, Z.; Ren, Y.; Liu, J.; He, J.; Zhao, Z. Geneface: Generalized and high-fidelity audio-driven 3D talking face synthesis. arXiv 2023, arXiv:2301.13430. [Google Scholar]
- Ye, Z.; He, J.; Jiang, Z.; Huang, R.; Huang, J.; Liu, J.; Ren, Y.; Yin, X.; Ma, Z.; Zhao, Z. GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation. arXiv 2023, arXiv:2305.00787. [Google Scholar]
- Xu, C.; Zhu, J.; Zhang, J.; Han, Y.; Chu, W.; Tai, Y.; Wang, C.; Xie, Z.; Liu, Y. High-fidelity generalized emotional talking face generation with multi-modal emotion space learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6609–6619. [Google Scholar]
- Zhong, W.; Fang, C.; Cai, Y.; Wei, P.; Zhao, G.; Lin, L.; Li, G. Identity-Preserving Talking Face Generation with Landmark and Appearance Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 9729–9738. [Google Scholar]
- Liu, P.; Deng, W.; Li, H.; Wang, J.; Zheng, Y.; Ding, Y.; Guo, X.; Zeng, M. MusicFace: Music-driven Expressive Singing Face Synthesis. arXiv 2023, arXiv:2303.14044. [Google Scholar]
- Wang, D.; Deng, Y.; Yin, Z.; Shum, H.-Y.; Wang, B. Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17979–17989. [Google Scholar]
- Zhang, W.; Cun, X.; Wang, X.; Zhang, Y.; Shen, X.; Guo, Y.; Shan, Y.; Wang, F. SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York, NY, USA, 2023; pp. 8652–8661. [Google Scholar]
- Tang, J.; Wang, K.; Zhou, H.; Chen, X.; He, D.; Hu, T.; Liu, J.; Zeng, G.; Wang, J. Real-time neural radiance talking portrait synthesis via audio-spatial decomposition. arXiv 2022, arXiv:2211.12368. [Google Scholar]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing Obama: Learning lip sync from audio. ACM Trans. Graph. (ToG) 2017, 36, 95. [Google Scholar] [CrossRef]
- Fried, O.; Tewari, A.; Zollhöfer, M.; Finkelstein, A.; Shechtman, E.; Goldman, D.B.; Genova, K.; Jin, Z.; Theobalt, C.; Agrawala, M. Text-based editing of talking-head video. ACM Trans. Graph. (TOG) 2019, 38, 68. [Google Scholar] [CrossRef]
- Gafni, G.; Thies, J.; Zollhofer, M.; Nießner, M. Dynamic neural radiance fields for monocular 4D facial avatar reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8649–8658. [Google Scholar]
- Zhang, Z.; Li, L.; Ding, Y.; Fan, C. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3661–3670. [Google Scholar]
- Wu, H.; Jia, J.; Wang, H.; Dou, Y.; Duan, C.; Deng, Q. Imitating arbitrary talking style for realistic audio-driven talking face synthesis. In Proceedings of the 29th ACM International Conference on Multimedia, Online, 20–24 October 2021; pp. 1478–1486. [Google Scholar]
- Habibie, I.; Xu, W.; Mehta, D.; Liu, L.; Seidel, H.-P.; Pons-Moll, G.; Elgharib, M.; Theobalt, C. Learning speech-driven 3D conversational gestures from video. In Proceedings of the 21st ACM International Conference on Intelligent Virtual Agents, Online, 14–17 September 2021; pp. 101–108. [Google Scholar]
- Lahiri, A.; Kwatra, V.; Frueh, C.; Lewis, J.; Bregler, C. Lipsync3d: Data-efficient learning of personalized 3D talking faces from video using pose and lighting normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2755–2764. [Google Scholar]
- Tang, J.; Zhang, B.; Yang, B.; Zhang, T.; Chen, D.; Ma, L.; Wen, F. Explicitly controllable 3D-aware portrait generation. arXiv 2022, arXiv:2209.05434. [Google Scholar] [CrossRef] [PubMed]
- Khakhulin, T.; Sklyarova, V.; Lempitsky, V.; Zakharov, E. Realistic one-shot mesh-based head avatars. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 345–362. [Google Scholar]
- Liu, X.; Xu, Y.; Wu, Q.; Zhou, H.; Wu, W.; Zhou, B. Semantic-aware implicit neural audio-driven video portrait generation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23-27 October 2022; Springer: Cham, Switzerland, 2022; pp. 106–125. [Google Scholar]
- Chatziagapi, A.; Samaras, D. AVFace: Towards Detailed Audio-Visual 4D Face Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16878–16889. [Google Scholar]
- Wang, J.; Zhao, K.; Zhang, S.; Zhang, Y.; Shen, Y.; Zhao, D.; Zhou, J. LipFormer: High-Fidelity and Generalizable Talking Face Generation With a Pre-Learned Facial Codebook. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13844–13853. [Google Scholar]
- Xu, C.; Zhu, S.; Zhu, J.; Huang, T.; Zhang, J.; Tai, Y.; Liu, Y. Multimodal-driven Talking Face Generation via a Unified Diffusion-based Generator. CoRR 2023, 2023, 1–4. [Google Scholar]
- Li, W.; Zhang, L.; Wang, D.; Zhao, B.; Wang, Z.; Chen, M.; Zhang, B.; Wang, Z.; Bo, L.; Li, X. One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17969–17978. [Google Scholar]
- Huang, R.; Lai, P.; Qin, Y.; Li, G. Parametric implicit face representation for audio-driven facial reenactment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12759–12768. [Google Scholar]
- Saunders, J.; Namboodiri, V. READ Avatars: Realistic Emotion-controllable Audio Driven Avatars. arXiv 2023, arXiv:2303.00744. [Google Scholar]
- Ma, Y.; Wang, S.; Hu, Z.; Fan, C.; Lv, T.; Ding, Y.; Deng, Z.; Yu, X. Styletalk: One-shot talking head generation with controllable speaking styles. arXiv 2023, arXiv:2301.01081. [Google Scholar] [CrossRef]
- Jang, Y.; Rho, K.; Woo, J.; Lee, H.; Park, J.; Lim, Y.; Kim, B.; Chung, J. That’s What I Said: Fully-Controllable Talking Face Generation. arXiv 2023, arXiv:2304.03275. [Google Scholar]
- Song, L.; Wu, W.; Qian, C.; He, R.; Loy, C.C. Everybody’s talkin’: Let me talk as you want. IEEE Trans. Inf. Forensics Secur. 2022, 17, 585–598. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, J.; Zhang, W.Q. Expressive Speech-driven Facial Animation with Controllable Emotions. arXiv 2023, arXiv:2301.02008. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering–a systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Burden, D.; Savin-Baden, M. Virtual Humans: Today and Tomorrow; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Christoff, N.; Tonchev, K.; Neshov, N.; Manolova, A.; Poulkov, V. Audio-Driven 3D Talking Face for Realistic Holographic Mixed-Reality Telepresence. In Proceedings of the 2023 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Istanbul, Turkey, 4–7 July 2023; pp. 220–225. [Google Scholar]
- Zhang, C.; Ni, S.; Fan, Z.; Li, H.; Zeng, M.; Budagavi, M.; Guo, X. 3D talking face with personalized pose dynamics. IEEE Trans. Vis. Comput. Graph. 2021, 29, 1438–1449. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Lin, Z.; Saito, J.; Wang, W.; Komura, T. Joint audio-text model for expressive speech-driven 3D facial animation. Proc. ACM Comput. Graph. Interact. Tech. 2022, 5, 16. [Google Scholar] [CrossRef]
- Cudeiro, D.; Bolkart, T.; Laidlaw, C.; Ranjan, A.; Black, M.J. Capture, learning, and synthesis of 3D speaking styles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10101–10111. [Google Scholar]
- Li, X.; Wang, X.; Wang, K.; Lian, S. A novel speech-driven lip-sync model with CNN and LSTM. In Proceedings of the IEEE 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Taizhou, China, 28–30 October 2021; pp. 1–6. [Google Scholar]
- Fan, Y.; Lin, Z.; Saito, J.; Wang, W.; Komura, T. Faceformer: Speech-driven 3D facial animation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18770–18780. [Google Scholar]
- Haque, K.I.; Yumak, Z. FaceXHuBERT: Text-less Speech-driven E (X) pressive 3D Facial Animation Synthesis Using Self-Supervised Speech Representation Learning. arXiv 2023, arXiv:2303.05416. [Google Scholar]
- Richard, A.; Zollhöfer, M.; Wen, Y.; De la Torre, F.; Sheikh, Y. Meshtalk: 3D face animation from speech using cross-modality disentanglement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1173–1182. [Google Scholar]
- Junior, W.C.R.; Pereira, L.T.; Moreno, M.F.; Silva, R.L. Photorealism in low-cost virtual reality devices. In Proceedings of the IEEE 2020 22nd Symposium on Virtual and Augmented Reality (SVR), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 406–412. [Google Scholar]
- Lins, C.; Arruda, E.; Neto, E.; Roberto, R.; Teichrieb, V.; Freitas, D.; Teixeira, J.M. Animar: Augmenting the reality of storyboards and animations. In Proceedings of the IEEE 2014 XVI Symposium on Virtual and Augmented Reality (SVR), Salvador, Brazil, 12–15 May 2014; pp. 106–109. [Google Scholar]
- Sutherland, I.E. Sketchpad: A man-machine graphical communication system. In Proceedings of the Spring Joint Computer Conference, Detroit, MI, USA, 21–23 May 1963; ACM: New York, NY, USA, 1963; pp. 329–346. [Google Scholar]
- Sutherland, I.E. A head-mounted three dimensional display. In Proceedings of the Fall Joint Computer Conference, San Francisco, CA, USA, 9–11 December 1968; Part I. ACM: New York, NY, USA, 1968; pp. 757–764. [Google Scholar]
- Caudell, T. AR at Boeing. 1990; Retrieved 10 July 2002. Available online: http://www.idemployee.id.tue.nl/gwm.rauterberg/presentations/hci-history/sld096.htm (accessed on 2 November 2014).
- Krueger, M.W.; Gionfriddo, T.; Hinrichsen, K. VIDEOPLACE—An artificial reality. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Francisco, CA, USA, 22–27 April 1985; Association for Computing Machinery: New York, NY, USA, 1985; pp. 35–40. [Google Scholar]
- Milgram, P.; Kishino, F. A taxonomy of mixed reality visual displays. IEICE Trans. Inf. Syst. 1994, 77, 1321–1329. [Google Scholar]
- Waters, R.C.; Barrus, J.W. The rise of shared virtual environments. IEEE Spectr. 1997, 34, 20–25. [Google Scholar] [CrossRef]
- Chen, C.; Thomas, L.; Cole, J.; Chennawasin, C. Representing the semantics of virtual spaces. IEEE Multimed. 1999, 6, 54–63. [Google Scholar] [CrossRef]
- Craig, D.L.; Zimring, C. Support for collaborative design reasoning in shared virtual spaces. Autom. Constr. 2002, 11, 249–259. [Google Scholar] [CrossRef]
- Steed, A.; Slater, M.; Sadagic, A.; Bullock, A.; Tromp, J. Leadership and collaboration in shared virtual environments. In Proceedings of the IEEE Virtual Reality (Cat. No. 99CB36316), Houston, TX, USA, 13–17 March 1999; pp. 112–115. [Google Scholar]
- Durlach, N.; Slater, M. Presence in shared virtual environments and virtual togetherness. Presence Teleoperators Virtual Environ. 2000, 9, 214–217. [Google Scholar] [CrossRef]
- Kraut, R.E.; Gergle, D.; Fussell, S.R. The use of visual information in shared visual spaces: Informing the development of virtual co-presence. In Proceedings of the 2002 ACM Conference on Computer Supported Cooperative Work, New Orleans, LA, USA, 16–20 November 2002; pp. 31–40. [Google Scholar]
- Schroeder, R.; Heldal, I.; Tromp, J. The usability of collaborative virtual environments and methods for the analysis of interaction. Presence 2006, 15, 655–667. [Google Scholar] [CrossRef]
- Sedlák, M.; Šašinka, Č.; Stachoň, Z.; Chmelík, J.; Doležal, M. Collaborative and individual learning of geography in immersive virtual reality: An effectiveness study. PLoS ONE 2022, 17 10, e0276267. [Google Scholar] [CrossRef]
- Santos-Torres, A.; Zarraonandia, T.; Díaz, P.; Aedo, I. Comparing visual representations of collaborative map interfaces for immersive virtual environments. IEEE Access 2022, 10, 55136–55150. [Google Scholar] [CrossRef]
- Ens, B.; Bach, B.; Cordeil, M.; Engelke, U.; Serrano, M.; Willett, W.; Prouzeau, A.; Anthes, C.; Büschel, W.; Dunne, C.; et al. Grand challenges in immersive analytics. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; ACM: New York, NY, USA, 2021; pp. 1–17. [Google Scholar]
- Aamir, K.; Samad, S.; Tingting, L.; Ran, Y. Integration of BIM and immersive technologies for AEC: A scientometric-SWOT analysis and critical content review. Buildings 2021, 11, 126. [Google Scholar]
- West, A.; Hubbold, R. System challenges for collaborative virtual environments. In Collaborative Virtual Environments: Digital Places and Spaces for Interaction; Springer: London, UK, 2001; pp. 43–54. [Google Scholar]
- Eswaran, M.; Bahubalendruni, M.R. Challenges and opportunities on AR/VR technologies for manufacturing systems in the context of industry 4.0: A state of the art review. J. Manuf. Syst. 2022, 65, 260–278. [Google Scholar] [CrossRef]
- Koller, A.; Striegnitz, K.; Byron, D.; Cassell, J.; Dale, R.; Moore, J.; Oberlander, J. The first challenge on generating instructions in virtual environments. In Conference of the European Association for Computational Linguistics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 328–352. [Google Scholar]
- Uddin, M.; Manickam, S.; Ullah, H.; Obaidat, M.; Dandoush, A. Unveiling the Metaverse: Exploring Emerging Trends, Multifaceted Perspectives, and Future Challenges. IEEE Access 2023, 11, 87087–87103. [Google Scholar] [CrossRef]
- Thalmann, D. Challenges for the research in virtual humans. In Proceedings of the AGENTS 2000 (No. CONF), Barcelona, Spain, 3–7 June 2000. [Google Scholar]
- Malik, A.A.; Brem, A. Digital twins for collaborative robots: A case study in human-robot interaction. Robot. Comput. Integr. Manuf. 2021, 68, 102092. [Google Scholar] [CrossRef]
- Slater, M. Grand challenges in virtual environments. Front. Robot. AI 2014, 1, 3. [Google Scholar] [CrossRef]
- Price, S.; Jewitt, C.; Yiannoutsou, N. Conceptualising touch in VR. Virtual Real. 2021, 25, 863–877. [Google Scholar] [CrossRef]
- Muhanna, M.A. Virtual reality and the CAVE: Taxonomy, interaction challenges and research directions. J. King Saud-Univ.-Comput. Inf. Sci. 2015, 27, 344–361. [Google Scholar] [CrossRef]
- González, M.A.; Santos, B.S.N.; Vargas, A.R.; Martín-Gutiérrez, J.; Orihuela, A.R. Virtual worlds. Opportunities and challenges in the 21st century. Procedia Comput. Sci. 2013, 25, 330–337. [Google Scholar] [CrossRef]
- Çöltekin, A.; Lochhead, I.; Madden, M.; Christophe, S.; Devaux, A.; Pettit, C.; Lock, O.; Shukla, S.; Herman, L.; Stachoň, Z.; et al. Extended reality in spatial sciences: A review of research challenges and future directions. ISPRS Int. J. Geo-Inf. 2020, 9, 439. [Google Scholar] [CrossRef]
- Lea, R.; Honda, Y.; Matsuda, K.; Hagsand, O.; Stenius, M. Issues in the design of a scalable shared virtual environment for the internet. In Proceedings of the IEEE Thirtieth Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 1997; Volume 1, pp. 653–662. [Google Scholar]
- Santhosh, S.; De Crescenzio, F.; Vitolo, B. Defining the potential of extended reality tools for implementing co-creation of user oriented products and systems. In Proceedings of the Design Tools and Methods in Industrial Engineering II: Proceedings of the Second International Conference on Design Tools and Methods in Industrial Engineering (ADM 2021), Rome, Italy, 9–10 September 2021; Springer International Publishing: Cham, Switzerland, 2022; pp. 165–174. [Google Scholar]
- Galambos, P.; Weidig, C.; Baranyi, P.; Aurich, J.C.; Hamann, B.; Kreylos, O. Virca net: A case study for collaboration in shared virtual space. In Proceedings of the 2012 IEEE 3rd International Conference on Cognitive Infocommunications (CogInfoCom), Kosice, Slovakia, 2–5 December 2012; pp. 273–277. [Google Scholar]
- Mystakidis, S. Metaverse. Encyclopedia 2022, 2, 486–497. [Google Scholar] [CrossRef]
- Damar, M. Metaverse shape of your life for future: A bibliometric snapshot. J. Metaverse 2021, 1, 1–8. [Google Scholar]
- Tai, T.Y.; Chen, H.H.J. The impact of immersive virtual reality on EFL learners’ listening comprehension. J. Educ. Comput. Res. 2021, 59, 1272–1293. [Google Scholar] [CrossRef]
- Roth, D.; Bente, G.; Kullmann, P.; Mal, D.; Purps, C.F.; Vogeley, K.; Latoschik, M.E. Technologies for social augmentations in user-embodied virtual reality. In Proceedings of the 25th ACM Symposium on Virtual Reality Software and Technology, Parramatta, NSW, Australia, 12–15 November 2019; pp. 1–12. [Google Scholar]
- Yalçın, Ö.N. Empathy framework for embodied conversational agents. Cogn. Syst. Res. 2020, 59, 123–132. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, Z.; Landreth, C.; Kalogerakis, E.; Maji, S.; Singh, K. VisemeNet: Audio-driven animator-centric speech animation. ACM Trans. Graph. (TOG) 2018, 37, 161. [Google Scholar] [CrossRef]
- Peng, Z.; Wu, H.; Song, Z.; Xu, H.; Zhu, X.; Liu, H.; He, J.; Fan, Z. EmoTalk: Speech-driven emotional disentanglement for 3D face animation. arXiv 2023, arXiv:2303.11089. [Google Scholar]
- Liu, J.; Hui, B.; Li, K.; Liu, Y.; Lai, Y.-K.; Zhang, Y.; Liu, Y.; Yang, J. Geometry-guided dense perspective network for speech-driven facial animation. IEEE Trans. Vis. Comput. Graph. 2021, 28, 4873–4886. [Google Scholar] [CrossRef] [PubMed]
- Poulkov, V.; Manolova, A.; Tonchev, K.; Neshov, N.; Christoff, N.; Petkova, R.; Bozhilov, I.; Nedelchev, M.; Tsankova, Y. The HOLOTWIN project: Holographic telepresence combining 3D imaging, haptics, and AI. In Proceedings of the IEEE 2023 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Phuket, Thailand, 22–25 March 2023; pp. 537–541. [Google Scholar]
- Pan, Y.; Zhang, R.; Cheng, S.; Tan, S.; Ding, Y.; Mitchell, K.; Yang, X. Emotional Voice Puppetry. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2527–2535. [Google Scholar] [CrossRef] [PubMed]
- Karras, T.; Aila, T.; Laine, S.; Herva, A.; Lehtinen, J. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Trans. Graph. (TOG) 2018, 36, 94. [Google Scholar] [CrossRef]
- Tzirakis, P.; Papaioannou, A.; Lattas, A.; Tarasiou, M.; Schuller, B.; Zafeiriou, S. Synthesising 3D facial motion from “in-the-wild” speech. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Online, 16–20 November 2020; pp. 265–272. [Google Scholar]
- Wang, Q.; Fan, Z.; Xia, S. 3D-talkemo: Learning to synthesize 3D emotional talking head. arXiv 2021, arXiv:2104.12051. [Google Scholar]
- Yang, D.; Li, R.; Peng, Y.; Huang, X.; Zou, J. 3D head-talk: Speech synthesis 3D head movement face animation. Soft Comput. 2023. [Google Scholar] [CrossRef]
- Xing, J.; Xia, M.; Zhang, Y.; Cun, X.; Wang, J.; Wong, T.-T. Codetalker: Speech-driven 3D Facial Animation with Discrete Motion Prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12780–12790. [Google Scholar]
- Yi, H.; Liang, H.; Liu, Y.; Cao, Q.; Wen, Y.; Bolkart, T.; Tao, D.; Black, M.J. Generating holistic 3D human motion from speech. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 469–480. [Google Scholar]
- Bao, L.; Zhang, H.; Qian, Y.; Xue, T.; Chen, C.; Zhe, X.; Kang, D. Learning Audio-Driven Viseme Dynamics for 3D Face Animation. arXiv 2023, arXiv:2301.06059. [Google Scholar]
- Nocentini, F.; Ferrari, C.; Berretti, S. Learning Landmarks Motion from Speech for Speaker-Agnostic 3D Talking Heads Generation. arXiv 2023, arXiv:2306.01415. [Google Scholar]
- Wu, H.; Jia, J.; Xing, J.; Xu, H.; Wang, X.; Wang, J. MMFace4D: A Large-Scale Multi-Modal 4D Face Dataset for Audio-Driven 3D Face Animation. arXiv 2023, arXiv:2303.09797. [Google Scholar]
- Ma, Z.; Zhu, X.; Qi, G.; Lei, Z.; Zhang, L. OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16901–16910. [Google Scholar]
- Liu, B.; Wei, X.; Li, B.; Cao, J.; Lai, Y.K. Pose-Controllable 3D Facial Animation Synthesis using Hierarchical Audio-Vertex Attention. arXiv 2023, arXiv:2302.12532. [Google Scholar]
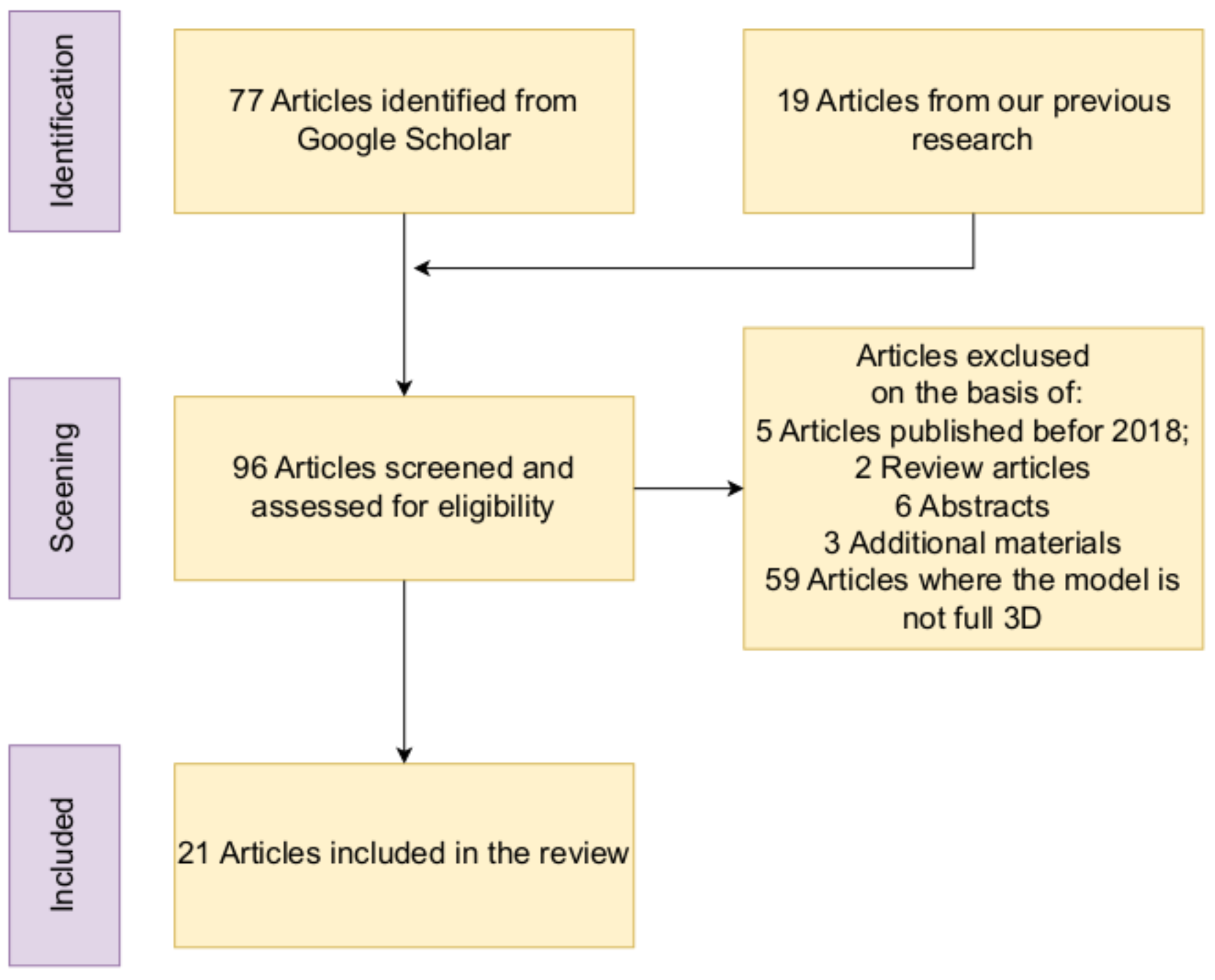
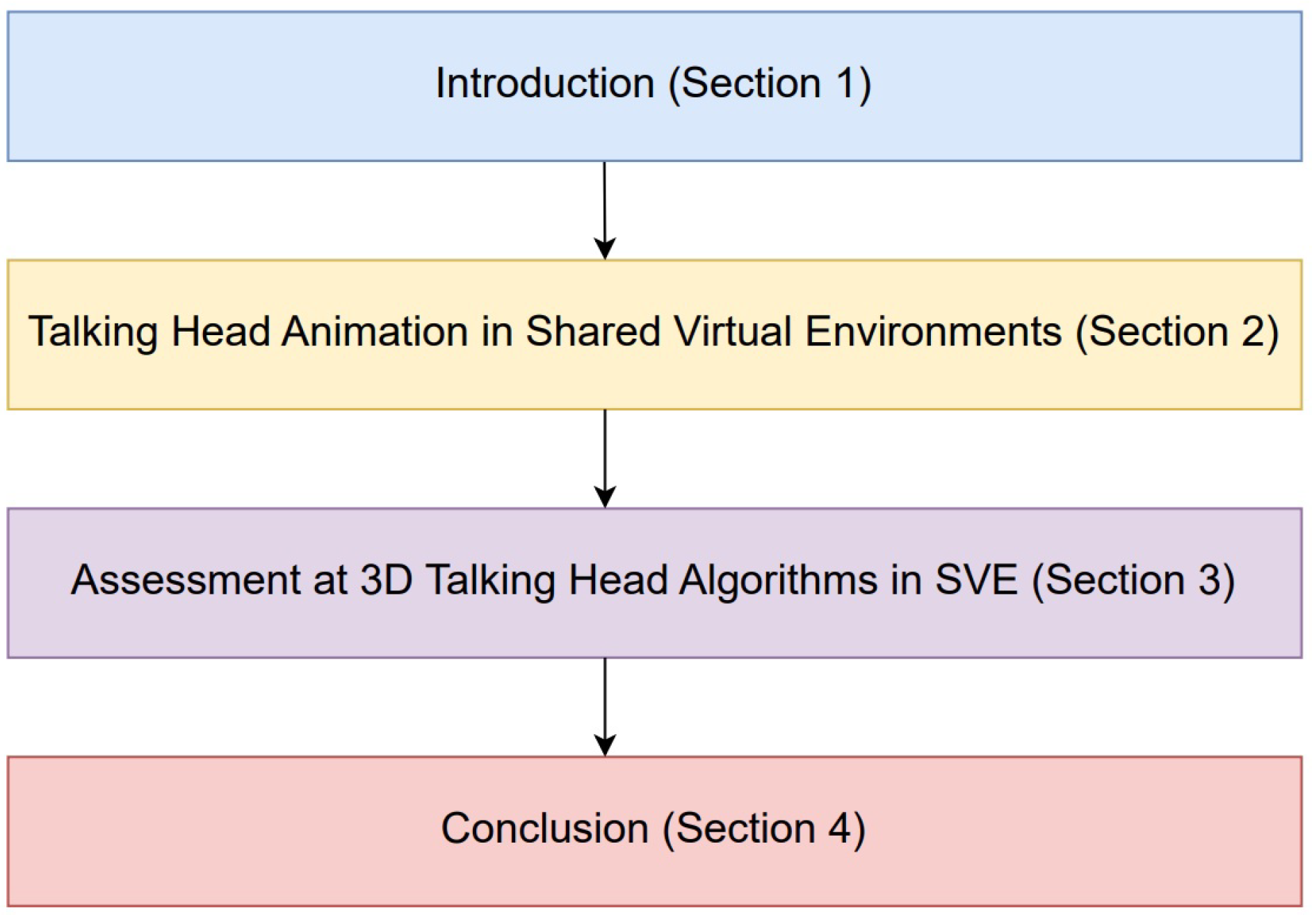
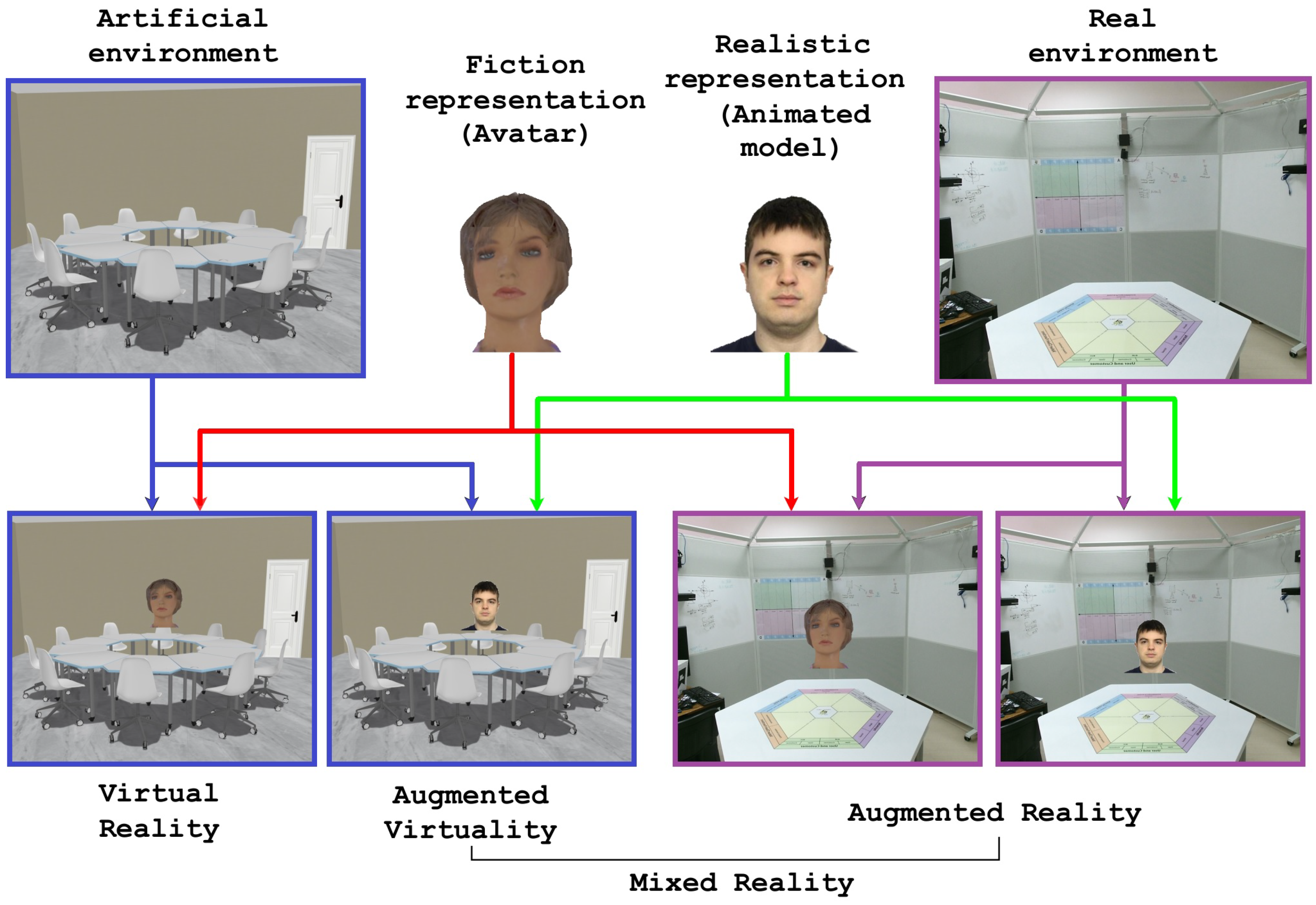
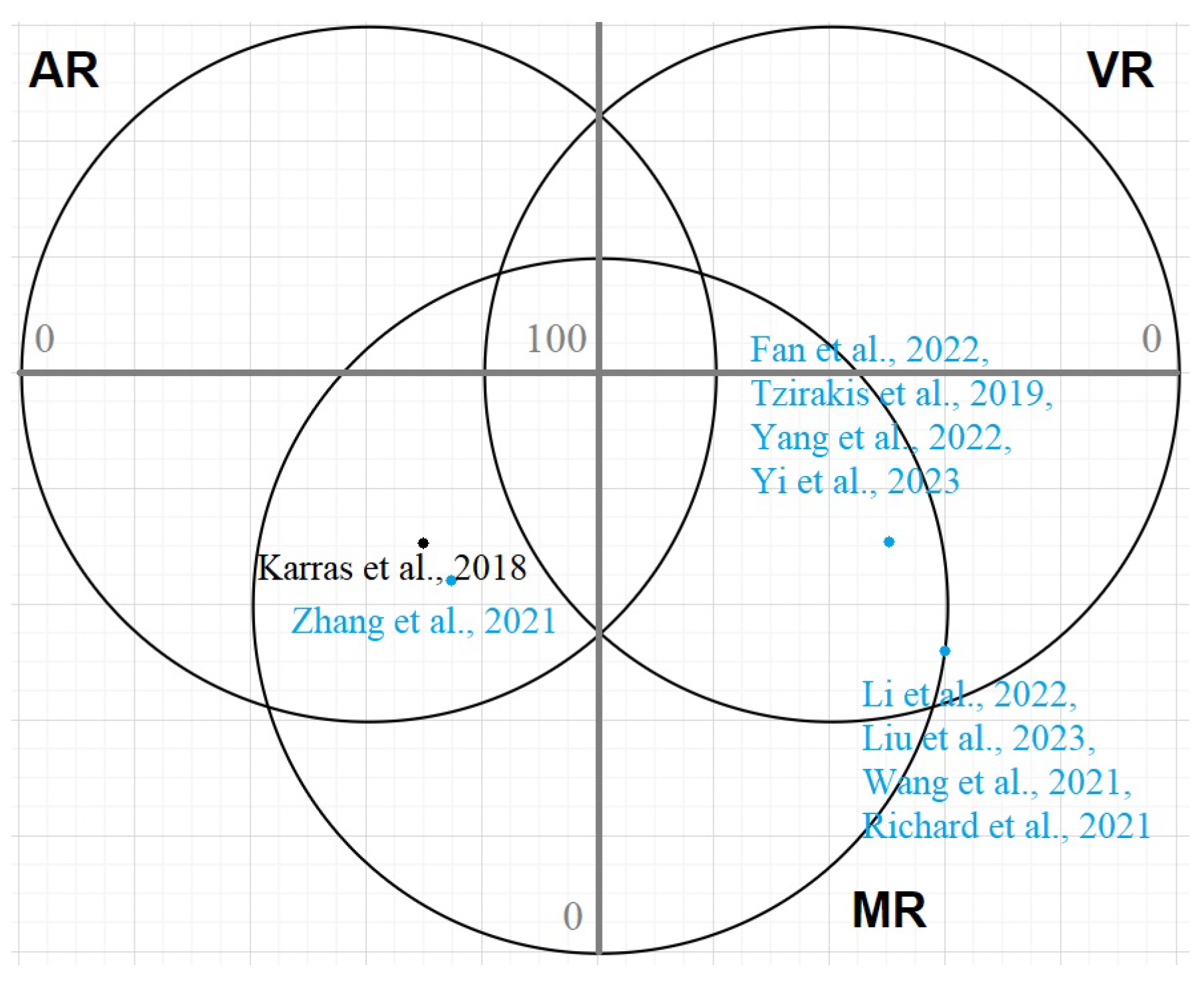
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).