1. Introduction
Earthquakes are powerful and destructive natural disasters, posing a significant threat to human life and property. In the 20th century, recorded earthquakes resulted in the deaths of more than 1.8 million people and caused damages exceeding USD 100 billion [
1]. For instance, the Tangshan and Wenchuan earthquakes, which were very serious disasters, killed countless people, caused serious economic losses, and affected the entire society [
2]. Therefore, earthquake prediction is important for reducing human casualties and economic losses, but it is also a very challenging task [
3].
Earthquakes are accompanied by some abnormal phenomena, such as electromagnetic anomalies [
4], changes in groundwater levels [
5], radon anomalies [
6], and geoacoustic anomalies [
7]. To observe the indicators of earthquakes, we developed a system, named AETA, to observe electromagnetic and geoacoustic signals; the parts of the observed signals are listed in
Figure 1. Geoacoustic activity is a key factor in earthquake induction, as it can reflect changes in crustal tension, and imbalances in crustal tension often lead to earthquakes [
8]. The significant changes in the frequency and intensity of geoacoustic data indicate a shift in the crustal tension state, suggesting a possible precursor to an earthquake. Lyu et al. [
9] implemented the sliding IQR to compute the abnormal feature of the Baer index sequence of geoacoustic data in AETA; however, the accuracy was not satisfactory. In [
10], to capture abnormal geoacoustic signals, a pattern recognition algorithm was designed, and the original geoacoustic data were converted into abnormal feature values. Subsequently, Guo et al. [
11] introduced FindCBLOF to extract anomalies from AETA geoacoustic signals. To extract effective geoacoustic signal feature vectors and discover anomalous signals, Lu et al. [
12] combined information entropy with the support vector machine (SVM) to construct a classification framework. Although SVM has achieved satisfactory performance, it cannot effectively separate signal from noise, impacting accuracy. Therefore, optimizing geoacoustic signal feature extraction becomes the key to solving this problem. In [
13], a one-class support vector machine (OCSVM) was introduced to detect the anomalies and particle swarm optimization (PSO) was applied to optimize the parameters of OCSVM, to improve the anomaly detection performance of OCSVM.
Unfortunately, these methods suffer from three major limitations.
High noise: There is too much noise in geoacoustic data, which makes anomaly feature extraction difficult.
Sample imbalance: Abnormal occurrences in earthquakes are small sample events, and sample imbalance will cause our classification model to have a serious bias.
Low accuracy: The performance of detectors and the characteristics of samples limit the accuracy of the anomaly detection model.
Therefore, we solve the above-mentioned drawbacks by focusing on two aspects: preprocessing the geoacoustic data and improving the performance of the anomaly detection model.
Motivation: This study proposes a CSA-OCSVM algorithm. Because OCSVM has advantages in dealing with the anomaly detection problem of imbalanced positive and negative samples, it can effectively distinguish between normal and abnormal geoacoustic signals. It is widely used in geoacoustic anomaly detection [
13]. However, traditional OCSVM has limitations in the selection of kernel parameters and penalty factor
C, which affects its accuracy. The clone selection algorithm (CSA) has the advantages of global optimization, dynamic adaptation, and parallel search. Therefore, it has been widely used to solve multi-objective optimization problems since it was proposed. It can also be applied to the OCSVM algorithm, which makes up for the shortcomings of OCSVM. It can take advantage of the CSA-OCSVM algorithm in geoacoustic anomaly detection and obtain higher detection accuracy, lower FAR, making it more suitable for solving geoacoustic detection problems. Meanwhile, a data preprocessing scheme has been designed and proposed, which includes signal denoising, missing value completion, addition of a time window, and abnormal feature extraction. A feature function is proposed in the abnormal feature extraction, which can significantly amplify the variation pattern of geoacoustic signals. Moreover, a detection model was constructed based on the preprocessing process and CSA-OCSVM algorithm. According to the geoacoustic signals of the AETA system, multiple comparative experiments were designed to verify the feature extraction ability, the optimization by the clone selection algorithm, and the overall effectiveness of the model.
The main contributions of this study are described as follows:
A novel paradigm, named CSA-OCSVM, is developed in this article. It is an effective method for discriminatively learning the hyperparameters of OCSVM. The learning process is inspired by the biological clone selection process, which can rapidly find the optimal solution; therefore, it is first introduced for OCSVM hyperparameter optimization.
We propose an efficient acoustic signal processing approach to process the original acoustic signal, which attempts to optimize the quality of collected geoacoustic data. In abnormal feature extraction, signal denoising, missing value completion, adding time windows, and feature functions are implemented, which can significantly amplify the variation patterns of geoacoustic signals.
The proposed CSA-OCSVM is applied to geoacoustic signal anomaly detection in Sichuan, Yunnan, Taiwan, Hebei, Guangdong, Qinghai, Jilin, and Beijing, where the samples are derived from AETA, a self-designed earthquake observation system.
The remainder of this study is summarized as follows:
Section 2 reviews the related works; the proposed CSA-OCSVM framework is introduced in
Section 3; the experimentation part, including baselines and comparison analysis, are demonstrated in
Section 4;
Section 5 describes the conclusion and future works.
2. Related Works
In the field of earthquake precursor signal research, studying earthquake prediction methods based on precursor data essentially involves the study of anomaly detection methods for this data. Various approaches have been adopted, including statistical methods, signal processing, machine learning, and artificial immune methods.
Statistical methods, such as mean square error, correlation analysis, differential detection, and step detection method, have been introduced for geoacoustic anomaly detection. These methods focus on the data itself and are aimed at studying outliers in earthquake precursor time series data. They are more effective for obvious jump points and step points but are not suitable for precursor signals with strong background interference and low signal-to-noise ratio, such as geoacoustic and electromagnetic signals. Lyu et al. [
9] introduced the Baer characteristic function to extract geoacoustic features and used IQR to analyze data anomalies, which proved that this method has a certain earthquake reflection effect; however, the accuracy of this method is not satisfactory. Mishchenko and Shevtsov [
14] adopted statistical methods to analyze the occurrence of abnormal disturbances in geoacoustic emissions and atmospheric electric fields before earthquakes, revealing relevant laws and trends in earthquake precursor physics, but this approach cannot handle big data. In 2021, Mishchenko et al. [
15] analyzed the acoustic response of rocks in large earthquake events on the east coast of the Kamchatka Peninsula and discovered the characteristics of low-frequency and high-frequency acoustic responses. They also used Spearman correlation analysis to discover the relationship between earthquake energy and the distance from the earthquake source to the observation site using a statistically significant relationship. These findings have great significance for understanding earthquake behavior and the development of earthquake prediction systems. Gapeev et al. proposed an empirical model of geoacoustic emission (GAE) signals constructed using statistical methods to help identify abnormal changes in GAE signals, which plays an important role in earthquake prediction [
16]. In 2022, Volvach et al. [
17] discussed the precursor phenomena of statistical changes in physical and biophysical fields related to earthquakes, providing important guidance for reducing losses caused by earthquakes and taking corresponding preventive measures. However, statistical methods also have limitations. They are usually analyzed based on the distribution of data and probability models, which require high data distribution assumptions. If the data does not conform to the assumed distribution, the effectiveness of statistical methods may be affected.
For signal processing methods, in 2019, Senkevich et al. [
18] introduced a method to describe signal segments through local extreme amplitude ratios and extreme interval matrices to solve the problem of geoacoustic signal feature selection. In 2020, Lukovenkova et al. [
19] utilized signal preprocessing, an adaptive matching pursuit algorithm, and a pulse classification method based on description matrix similarity to process geoacoustic signals. By encoding the pulses, a signal alphabet was formed, and the estimated values of the spectrum and signal alphabet were compared with those during earthquakes. The recorded signal analysis results were compared to provide more accurate predictions and analysis of earthquakes. In 2021, Marapulets and Lukovenkova [
20] adopted a development method based on the sparse approximation method for time–frequency analysis of geoacoustic data. Through a combined dictionary and adaptive matching pursuit algorithm, the geoacoustic signal was sparsely represented, revealing the seismic time–frequency structural characteristics in front geoacoustic data. Meanwhile, Lukovenkova and Solodchuk [
21] described a method for processing and analyzing pulsed geoacoustic emission signals, including signal detection, waveform recovery, and time–frequency analysis. The method uses an adaptive threshold scheme for signal detection and the wavelet threshold method to recover the pulse waveform. Time–frequency analysis is performed by a sparse approximation method. A new method is proposed to detect short-term precursors of strong earthquakes by monitoring rock acoustic emissions and analyzing their time–frequency content. A sparse approximation method based on an adaptive matching pursuit algorithm is used to conduct the time–frequency analysis of geoacoustic signals. The results show that the frequency of geoacoustic pulses changes before earthquakes, which is helpful for developing earthquake detection systems [
22]. Signal processing methods also have certain flaws; they mainly focus on the extraction and processing of earthquake precursor signals. Earthquake precursor signals are often very weak and suffer from high noise interference. Therefore, signal extraction and analysis require highly sensitive algorithms.
In terms of machine learning methods, in addition to the method that combines information entropy and SVM, as proposed by LU et al. [
12], in 2020, Lv et al. [
10] designed a pattern recognition algorithm to extract abnormal geoacoustic waveforms that frequently appear before and after earthquakes. Through comparative analysis of these characteristic values and surrounding earthquake events, it has been found that there is an obvious correlation between them. In 2021, Guo et al. [
11] proposed an anomaly detection method for AETA geoacoustic signals based on FindCBLOF. This method has high accuracy and recall rate, and effective anomaly extraction capabilities for AETA geoacoustic data. Then, Zhang et al. [
13] implemented OCSVM to detect anomalies and used PSO to optimize OCSVM parameters. This method obtained good geoacoustic anomaly detection effects. Xiong et al. [
23] developed a novel machine learning method, named inverse boosting pruned tree (IBPT), and compared the proposed method with other machine learning methods. The results showed that this method is better than other baseline methods. In 2022, Bhargava et al. [
24] demonstrated an earthquake detection and prediction method based on the long short-term memory (LSTM) deep neural network, which can capture the temporal characteristics of earthquake data and show good performance in the prediction of small and medium-sized earthquakes. It provides useful exploration for the application of deep learning in earthquake prediction. Asaly et al. [
25] used SVM and GPS ionospheric data to evaluate earthquake precursors. This method can identify signals before major earthquakes with high accuracy and is important for improving earthquake monitoring and early warning systems and mitigating earthquake disasters. However, machine learning methods require large amounts of labeled data for training, but obtaining accurate labeled data in earthquake prediction is difficult.
Computational immunity methods, such as the negative selection algorithm (NSA), artificial macrophage algorithm (AMA), and numerical differential artificial natural killer cell algorithm (NDANKA), have been used for anomaly detection. Xiong et al. used the concepts of “self” and “non-self” in immunology to apply them to normal and abnormal data in precursor observation data based on the NSA. They achieve more effective anomaly detection results than traditional BP neural networks and other algorithms [
26]. In 2020, Zhou et al. [
27] proposed an earthquake prediction method based on danger theory. They extracted eight indicators from earthquake data calculated by the Gutenberg–Richter inverse power law and used numerical differentiation based on the dendritic cell algorithm to predict earthquakes. In 2022, a new earthquake prediction method based on the AMA was proposed to identify noise and anomalies, and improve prediction accuracy through distance measurement and stochastic gradient descent. Experimental results show that AMA is better than existing earthquake prediction algorithms [
28]. Subsequently, a novel immune optimization-inspired NDANKA (using NDANKA and artificial antigen-presenting cell methods) was presented to predict earthquakes. The stochastic gradient descent was applied to optimize the parameters of NDANKA [
29]. Wang et al. [
30] proposed an earthquake prediction algorithm IM-NKA based on natural killer cells; the experiments show that IM-NKA is more effective than other earthquake prediction approaches. Computational immunity methods have certain advantages for anomaly detection, but there may be problems of high computational complexity when processing large-scale and complex seismic data, and more research is needed to improve the efficiency and accuracy of the algorithm.
Generally, different methods in seismic anomaly detection have some flaws or shortcomings, and further research and improvement are needed to improve the accuracy and reliability of predictions. This study proposes a novel seismic anomaly detection method, named CSA-OCSVM; this is a method that combines computational immunity with machine learning. It uses the CSA algorithm to optimize the parameters of the OCSVM algorithm, which makes up for the shortcomings of the OCSVM algorithm and has higher accuracy in geoacoustic anomaly detection.
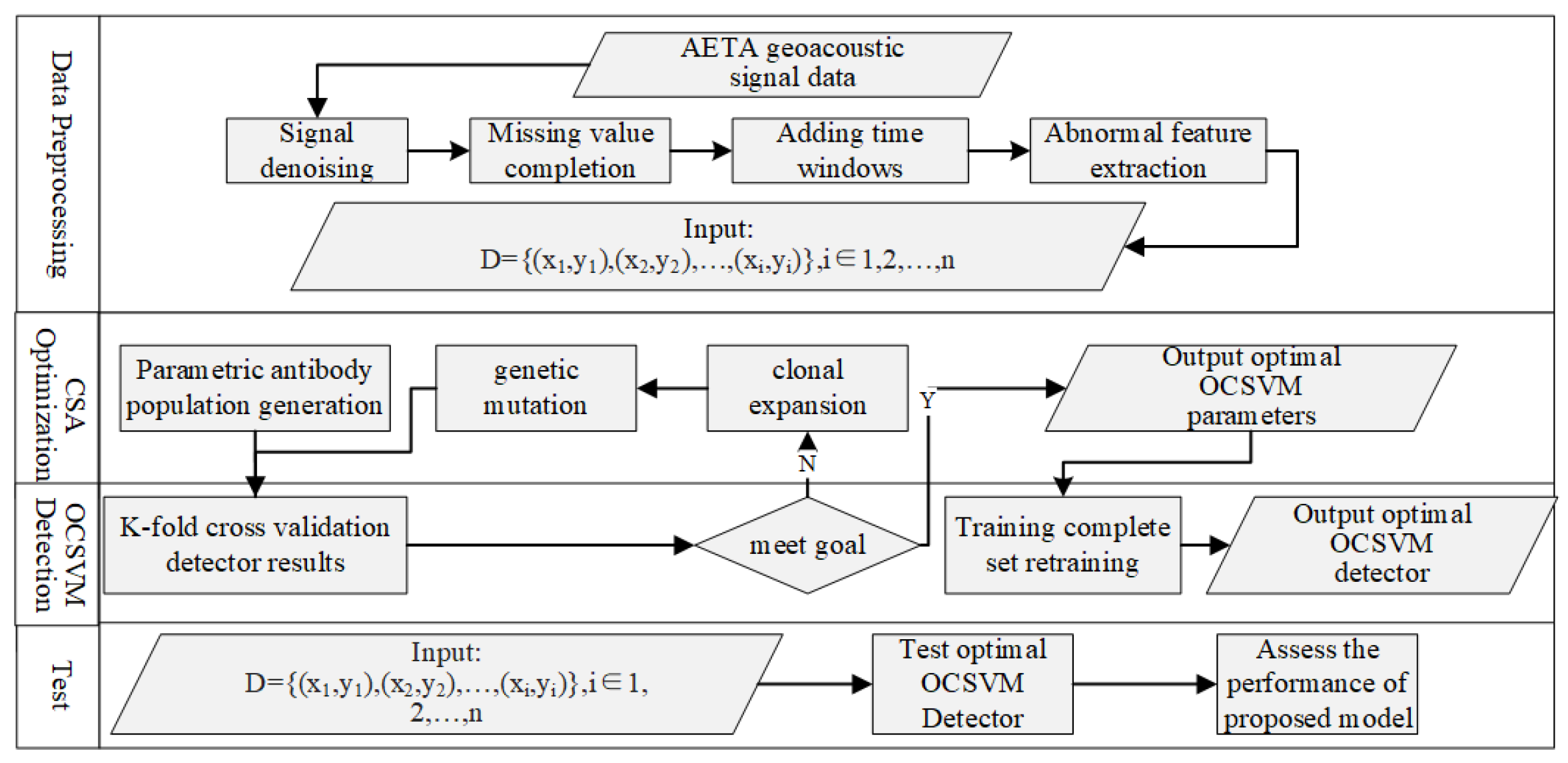
3. The Proposed CSA-OCSVM Geoacoustic Anomaly Detection Approach
To effectively solve the problem of geoacoustic anomaly detection, the proposed geoacoustic anomaly detection model based on the CSA-OCSVM algorithm is described in
Figure 2; it includes three parts: the data preprocessing stage, training process (including OCSVM detection, CSA parameter adjustment process), and testing process. Firstly, the geoacoustic signal data, which are collected and stored in the AETA system, serve as the original data. To solve the problems of noise and missingness in the original signal, processes such as signal denoising, missing value completion, time window addition, and abnormal feature extraction are carried out. Then, the detector training phase involves obtaining the optimal OCSVM detector through the training of geoacoustic signal sample sets and continuous parameter adjustment using CSA. It is mainly divided into two parts: the OCSVM detection process and the CSA parameter adjustment process. Finally, the detection phase aims to implement the optimal OCSVM detector selected in the previous stage to process the test sample set and isolate abnormal data that does not meet the feature indicators of normal geoacoustic signal data in the sample set.
3.1. Acoustic Signal Processing
The data preprocessing work of this model is divided into four steps: signal denoising, missing value completion, adding time windows, and abnormal feature extraction. The goal is to process the input geoacoustic signal original data and obtain a set of geoacoustic signals that can represent the geoacoustic signal within a period of time.
Signal denoising: The boxplot method is used to remove sudden jump points in the denoising stage to process the original data of geoacoustic signals. Based on the characteristic differences between real geoacoustic anomalies and background interference noise, obvious sudden jumps are identified for point and outlier removal. When drawing the boxplot of the original geoacoustic signal data, first, the number axis is determined according to the magnitude of the data, and the samples in the dataset are arranged in ascending order. Assume the size of the dataset is n; then the sorted set is described as . The points corresponding to the maximum sample and the minimum sample are marked on the number axis, and then the sizes of the first quartile , the median , and the third quartile are calculated, respectively. In addition, the distance between the first quartile and the third quartile is called the IQR. The length of the IQR is then adopted as the width of the rectangle, to draw a rectangular box between and , a line segment at the median to represent the data in the middle, and a line segment at and , respectively. Finally, a line segment parallel to the median line should be drawn at each position to identify abnormal sample data.
Missing value completion: The cubic spline interpolation method originated from the spline curve used by graphics engineers. It is an algorithm that fits a smooth continuous function curve through a set of discrete point changes. Suppose the cubic spline interpolation function containing
data points is
, then it satisfies: (1) Let
be the expression on the
ith monotonically increasing piecewise interval
of
, then
is a cubic polynomial; (2)
; (3)
and its first and second derivatives are continuous within a limited interval;
can be described as shown in Equation (
1),
where
,
,
, and
represent the undetermined coefficients of the function, respectively. Taking into account the continuity of
and the continuity of its first-order derivative and second-order derivative, let the second-order derivative value at both ends of the curve be 0. By substituting
data points into the solution,
is expressed as shown in Equation (
2),
where
is the step value of
, and
is the second derivative value at
. Through this interpolation calculation method, it is easy to complete the missing geoacoustic signal data to ensure the subsequent work of this model.
Adding time windows: After the above processes of denoising and interpolation, relatively complete and continuous geoacoustic signal time series data can be obtained, where each piece of data contains three characteristics: amplitude mean, ringing count, and peak frequency. When analyzing anomaly detection in time series data, it is usually necessary to use a time window to divide the time series data into a set of shorter sequences, and analyze whether there are abnormalities in the overall time series data through the characteristics of each sequence. After windowing processing, the original time series data containing 3-dimensional features are converted into a
data matrix
X due to the size of the
m time window, which can be described as shown in Equation (
3).
Abnormal feature extraction: The geoacoustic signal data matrix obtained through the above operations cannot be directly used as the input of the anomaly detection algorithm. It is also necessary to extract abnormal features, i.e., to extract those indicators that can better reflect the geoacoustic signal anomalies. Through preliminary analysis and experiments on geoacoustic signal data, this model extracts five geoacoustic anomaly characteristic indicators: characteristic function peak value (
), amplitude standard deviation (
), very poor amplitude (
), sum of ring counts (
), and peak frequency (
). The calculation methods of these indicators are described in
Table 1.
3.2. CSA-Based OCSVM
The detector training phase, named CSA-based OCSVM, aims to obtain the optimal OCSVM detector through continuous training of the training sample set and continuous parameter optimization of CSA, which can more effectively detect geoacoustic signal anomalies based on the extracted feature indicators. The main process is shown in
Figure 3, which mainly includes the OCSVM detection process and the CSA parameter adjustment process.
The OCSVM detection process aims to verify the validity of the parameters provided by the CSA algorithm, which is executed cyclically in this algorithm model until it reaches the detection effect threshold or iteration number threshold. The main input data of this process include the geoacoustic signal data feature set subset D obtained in the data preprocessing stage, the penalty factor C given by the CSA algorithm, and the RBF kernel function parameter K. The target output is the best value after the CSA parameter adjustment optimization and the optimal OCSVM detector.
The feature set
D in the input data can be directly processed using the OCSVM decision function, and its form can be described as shown in Equation (
4),
where
adopts the RBF kernel function; therefore,
y can be described as shown in Equation (
5).
Then, the OCSVM discriminant function that can be used for anomaly detection can be obtained. To reduce the model detection error, the K-fold cross-validation method is used to divide the original training set into K equal parts, so each part is used as a set of test sets, and the remaining parts are used as the training set. Thus, K training models are obtained, and then the average detection accuracy of these models is used as the detection effect score of the OCSVM model under this parameter. In addition, when the detection effect of OCSVM reaches the expected threshold, i.e., when the CSA parameter optimization is completed and the optimal parameters are obtained, the parameters at this time need to be used to detect the entire training set to obtain the optimal OCSVM detector.
The input data of the CSA parameter adjustment process are mainly the maximum evolution algebra and mutation probability p of the parameters related to the CSA algorithm. The former is used to ensure the convergence of the algorithm model to avoid falling into an infinite loop process due to the failure of finding the optimal solution, and the latter is used to control the mutation probability of each gene in the antibody. The output data of this process are the optimal parameters of OCSVM after parameter adjustment, including penalty factor C and the RBF kernel function parameter, . The entire parameter adjustment process can be divided into four key steps: antibody population generation, affinity calculation, clonal amplification, and genetic mutation.
Antibody population generation: The antibodies in this model correspond to the feasible C and parameter values of OCSVM. Based on literature experience and preliminary experimental exploration, the value ranges are controlled at [0.5, 127.5] and [0.7, 178.5], respectively. The two parameters are compiled into a total of 16-bit antibody genes in binary form, where the first 8 bits represent C and the last 8 bits represent . The initial antibody population is then composed of 20 machine-generated antibodies.
Calculate affinity: In this model, the affinity between the antibody and the target antigen is measured by the detection accuracy score obtained during the OCSVM detection process. When the affinity of the existing antibody reaches the threshold, i.e., the detection effect score reaches the expected value or the current evolution generation reaches the maximum evolution generation , CSA adjusts the parameters. The process ends and the current C and are output.
Clone expansion: Clonal expansion determines the number of species based on the affinity of individuals in the antibody population through a quantitative process. Arrange the various antibody types in the population according to their affinity. The total number of new clones of each type of antibody,
, can be described as shown in Equation (
6),
where
represents the clone amplification multiple,
i represents the ranking of the current antibody type in the affinity order, and
represents the number of previous antibody clones at position
i.
Genetic mutation: According to the inverse relationship between the antibody affinity and mutation rate, mutation operations are performed on individuals in the antibody population. The mutation rate
of each antibody type in the affinity order can be described as shown in Equation (
7),
where the current antibody with the highest affinity remains unchanged. The specific mutation operation involves randomly selecting the 16
gene from the
i-th antibody for mutation. Since it is binary coded, the mutation operation for the
j-th gene
of a certain antibody can be described as
.
To summarize, the pseudocode of CSA-OCSVM is depicted as Algorithm 1.
| Algorithm 1 CSA-OCSVM |
Input: Geoacoustic signal characteristic index dataset D, maximum number of iterations , mutation probability p, clone amplification multiple , deletion ratio , detection accuracy expectation threshold . Output: Abnormal label. Randomly generate 20 non-repeating random antibodies as the initial antibody population P; ; ; while true do for Each antibody in P do (first eight digits of antibodies) ∗ 0.5, ; (last eight digits of antibodies) ∗ 0.7, ; Divide D into abnormal sample set E and normal sample set N; Divide N into 5 disjoint subsets /; for Each subset of N do Use this subset together with the random half of the data in E as the test set T; the other 4 subsets are the training set S; Set C as the penalty factor and as the kernel parameter of the RBF kernel function; ; Mark abnormal ; Calculate TPR; end for 5 times the average TPR as antigen affinity; end for Sort the antibodies in P in descending order by ; Delete the antibodies with the lowest affinity (*number of antibodies); ; for do if then break; end if end for for each antigen type in P do the number of previous types/the affinity order of this type of antibody); Copy n copies of this antibody; end for for each antigen in P do if then continue; end if Random mutations in anti genes; end for ; end while Divide D into a training set S and a test set T, where all abnormal samples are put into T; Set C as the penalty factor and as the kernel parameter of the RBF kernel function; ; Label abnormal signals .
|
3.3. Detection and Assessment
The detection stage mainly uses the optimal OCSVM detector selected in the previous stage to process the test sample set, isolate abnormal data that do not meet the characteristic indicators of normal geoacoustic signal data in the sample set, and evaluate its abnormal detection results. The core issue at this stage is how to evaluate the effectiveness of the anomaly detection algorithm model. Since anomaly detection problems usually have the characteristic of an imbalance between positive and negative samples, the effect of anomaly detection cannot simply be evaluated by the ratio of identified normal samples to the total samples. Instead, the TPR and FPR should be used to evaluate the quality of the anomaly detection algorithm.
The TPR refers to the ratio of positive samples judged as positive by the algorithm model to the total number of actual positive samples. In the geoacoustic signal anomaly detection experiment, i.e., the ratio of the detected normal geoacoustic signal data to the total number of actual normal geoacoustic signals. TPR can be described as shown in Equation (
8).
In the same way, FPR refers to the ratio of negative samples misjudged as positive by the algorithm model to the total number of actual negative samples, which can be described as shown in Equation (
9).
This study will use the above-mentioned two evaluation indicators, TPR and FPR, to evaluate the effect of the CSA-OCSVM algorithm model on geoacoustic signal anomaly detection.
3.4. Time Complexity Analysis
The time complexity of CSA-OCSVM is , where is the number of algorithm iterations, and n is the number of data instances. CSA-OCSVM updates the weights in OCSVM. The main time costs focus on the OCSVM anomaly detection and CSA optimization process. In the OCSVM anomaly detection process, the algorithm performs operations of signal fusion and classification. The time complexity of OCSVM is . With the optimization process, the algorithm uses the CSA to adjust the weight of OCSVM. The number of calculation times does not exceed the iteration numbers , and the time costs are . Therefore, the total time complexity of the CSA-OCSVM is .
4. Experimentation
In this section, the experiments are introduced in detail, and the results of the proposed CSA-OCSVM and baselines on AETA geoacoustic datasets are demonstrated. Through several experiments, we comprehensively analyze the performance of the proposed CSA-OCSVM. All approaches are run in Python 3.6 and implemented on a machine with an Intel Xeon E5-2640 v3 8-Core CPU. All the algorithms are verified by a ten-fold cross-validation method, and the mean and standard deviations of each evaluation indicator are reported.
4.1. Datasets
The geoacoustic signal data required for the experiment come from the AETA multi-component seismic monitoring system, which is shown in
Figure 4. To reduce and avoid experimental bias caused by regional differences, 30 consecutive days of geoacoustic signal data from one observation station were selected in each of the eight provincial-level administrative regions, which were collected by various sensors we developed in AETA, i.e., Sichuan, Yunnan, Taiwan, Hebei, Guangdong, Qinghai, Jilin, and Beijing. Each observation station collected 144 data records every day. The original dataset contains a total of 34,560 geoacoustic signal data records. The specific observation stations and time selections are shown in
Table 2.
4.2. Data Preprocessing
The original data obtained from AETA require data preprocessing, including the following four steps: signal denoising, missing value completion, adding time windows, and abnormal feature extraction. The following phase uses the data from the Jinniu Town No. 2 Primary School Observation Station as an example to perform the preprocessing process of the original data of the geoacoustic signal. The original data are shown in
Table 3.
We should draw boxplots for the mean amplitude, ring count, and peak frequency in the original data of the low-frequency geoacoustic signal. Points outside the two line segments
and
in the figure are marked as suspected noise points. Then, only one of these suspected noise points is eliminated every 6 h. This approach minimizes noise interference caused by sudden jump points without significantly affecting the identification of earthquake-related abnormal signals. Missing values caused by equipment and the aforementioned denoising process were processed using cubic spline interpolation on a daily basis. Each day’s 144 pieces of data are numbered, and this serial number is used as shown in
Figure 4.
For anomaly detection and analysis of time series data, it is usually necessary to use a time window to divide the time series data into a set of shorter sequences. This allows analysis of whether there are anomalies in the overall time series data through the characteristics of each sequence. Preliminary experiments have verified that when 6 h is used as the length of a single time window, the true rate of the anomaly detection experiment reaches a relatively good level. Therefore, the experiment chose to divide the geoacoustic signal time series data into 6-h units. After normalization processing, a geoacoustic signal characteristic index dataset suitable for experiments was finally obtained, including a total of 960 sets of data from eight provinces and regions, as shown in
Table 4.
4.3. The Prototype Implementation
The geoacoustic signal anomaly detection in our study is a binary classification task; therefore, we introduce the IQR [
9], GA-OCSVM, and PSO-OCSVM [
13] for comparison with our proposed CSA-OCSVM. The advantage of IQR is that it is not affected by the 25% values at both ends. It can measure the degree of difference in the open group sequence and measure the representativeness of the median. The disadvantage is that it cannot reflect the degree of difference of all flag values. The GA has good global search capabilities and can quickly search out all solutions in the solution space without falling into the trap of the rapid decline of local optimal solutions. However, the local search ability of the genetic algorithm is limited, which makes the simple genetic algorithm more time-consuming and results in lower search efficiency in the later stages of evolution. In practical applications, genetic algorithms are prone to premature convergence problems. The PSO algorithm has a fast convergence speed and is easy to program and implement. However, its accuracy is not high.
In our experiments, the input signals are normalized between 0 and 1. In GA-OCSVM, the initial C is set to 1, the initial population size is 20, the max evolutionary number is 100, the cross rate is 0.5, and the mutation rate is 0.005. For the PSO-OCSVM approach, the max iteration is 100 and the population size is 20. The acceleration coefficients and are 0.49 and 0.51, respectively. The inertia weight is 0.5. In CSA-OCSVM, the initial antigen population size is 20, the max iteration is 100, and the mutation rate is 0.5. Other parameter settings of the comparison methods can be found in the relevant literature.
4.4. Results Analysis and Comparison
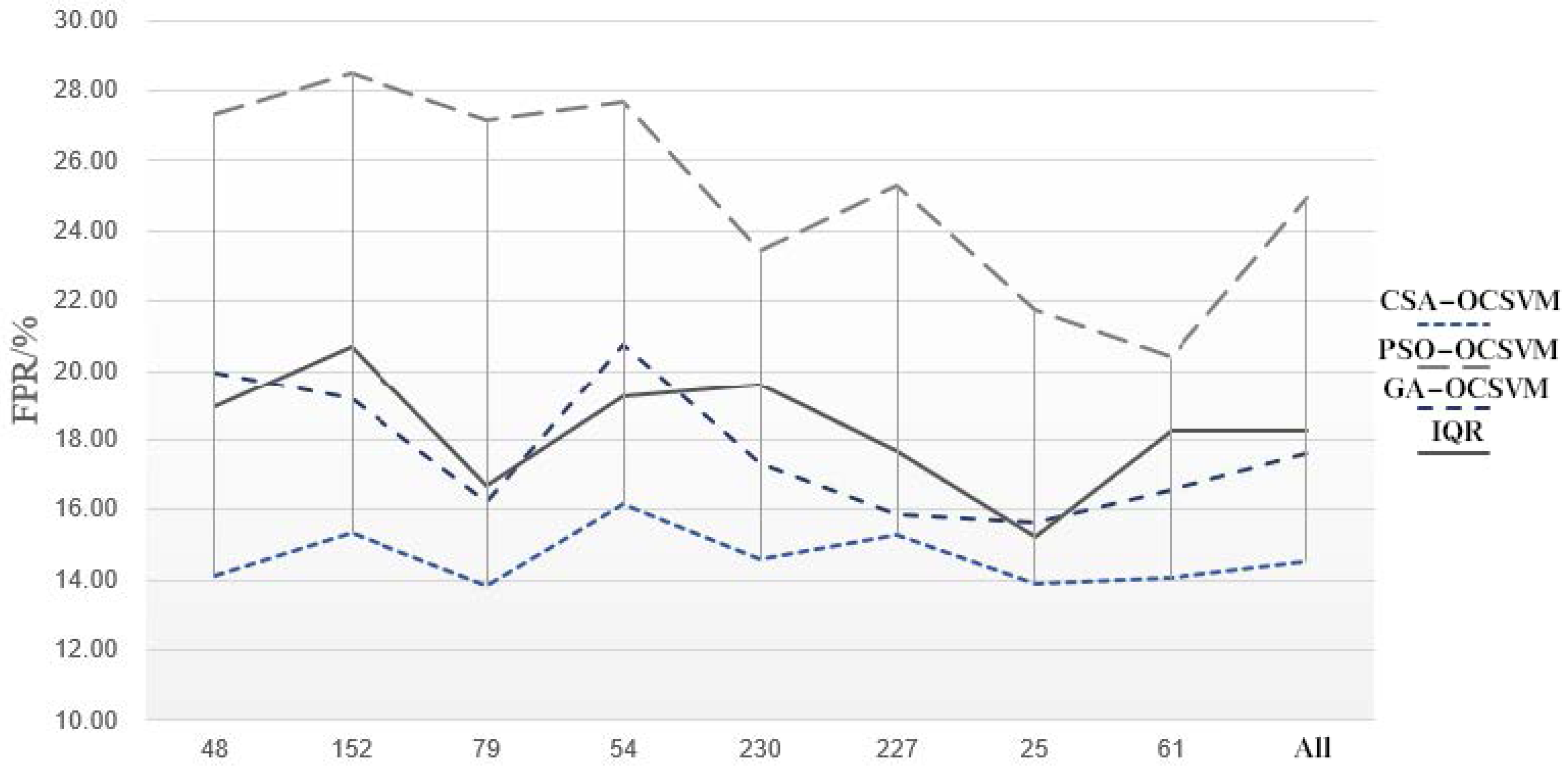
We conducted 10 anomaly detection experiments on 8 groups of datasets and the entire dataset using the experimental designs mentioned above, and recorded the average TPR and FPR of the 10 experiments. The experimental results are demonstrated in
Table 5 and
Table 6 and
Figure 5. Therefore, a more intuitive comparison chart of TPR and FPR in the experimental scenarios can be drawn, as shown in
Figure 6 and
Figure 7.
Based on the above experimental results, the following conclusions can be drawn.
There is an obvious difference in the experimental results between CSA-OCSVM and PSO-OCSVM. The detection results in PSO-OCSVM are poor, and the FPR is high. This is because CSA has the advantages of global optimization, dynamic adaptation, and parallel search and, therefore, can obtain more suitable hyperparameters for OCSVM.
From the comparison of the experimental results of CSA-OCSVM and GA-OCSVM, it can be seen that when the maximum number of iterations is the same, the OCSVM anomaly detector is more likely to reach the optimum under the optimization of the CSA than under the optimization of the GA. This verifies the effectiveness of the CSA for OCSVM algorithm optimization.
From the comparison of the experimental results of CSA-OCSVM and IQR, it can be seen that the anomaly detection effect of the model proposed in this study on the geoacoustic signal data in the AETA system can reach or even surpass the more mature sliding quartile method based on Baer features, which verifies the effectiveness of the geoacoustic signal anomaly detection model based on the CSA-OCSVM algorithm. In addition, according to the comparison between GA-OCSVM and IQR, it can also be found that when the CSVM parameters are not adjusted to an optimal level, the performance of the IQR method may be better than the OCSVM algorithm.
In addition, in other experiments on earthquake precursor data anomaly detection [
26], FPR was basically controlled below 10%. The FPR obtained from the four experimental scenarios in this study are all on the high side, indicating that the FPR of the anomaly detection experiment is high. The reason for this problem may be the low signal-to-noise ratio of the geoacoustic signal data. Although the data preprocessing stage, to a certain extent, reduces the interference of noise fluctuations on the results, limitations in our research level and research time mean there are still larger problems in this regard.
In summary, the geoacoustic anomaly detection model based on the CSA-OCSVM algorithm proposed in this paper can achieve satisfied anomaly detection results for low-frequency geoacoustic data in the AETA system.
4.5. Ablation Studies
In this study, CSA has an advantage in optimizing the parameters of a classification algorithm. Therefore, we introduce it into the optimization of OCSVM, and to verify its impact on the OCSVM, the accuracy results of OCSVM and CSA-NF-OCSCM are compared and analyzed on the above-mentioned nine datasets. CSA-NF-OCSCM is a model without the indicator. The CSA layer is combined with the OCSVM layer. For each sample, the CSA layer acquires normalized data from the input instance and is realized by a CSA process. The CSA-OCSVM is implemented according to the indicator module and CSA, with the indicator adopted to improve the performance of the AMM.
As shown in
Table 7, the layer-by-layer performance analysis shows that the performance improved to a certain extent after adding the
. The results of the ablation studies indicate that the
indicator and the CSA adjustment of parameters have a significant influence on the OCSVM. Generally, our proposed
indicator and the CSA optimization mechanism in this study are key components for improving the performance of the OCSVM. This is because scenario one uses the characteristic index
, which can better amplify the energy fluctuations and amplitude abnormalities of the geoacoustic signal. Experimental results show that after using the
index, the detector is less affected by noise and can significantly reduce the FAR, verifying the effectiveness of the feature extraction scheme in the model data preprocessing stage.
5. Conclusions and Future Work
This paper demonstrates a geoacoustic anomaly detection approach by integrating feature extraction strategies, OCSVM, and CSA. The main contribution of this paper is that it presents a novel CSA-OCSVM method to create a more suitable geoacoustic anomaly detection model. First, a data preprocessing scheme is designed to amplify the geoacoustic signal intensity and energy change rules, thereby reducing the interference of geoacoustic signal noise and intensity. Meanwhile, OCSVM is introduced for anomaly detection to address the imbalance of positive and negative samples in geoacoustic anomaly detection. Furthermore, in view of the optimization capabilities of the CSA, it is introduced to optimize the hyperparameters of OCSVM to improve its detection accuracy. Finally, the proposed approach is implemented for geoacoustic data anomaly detection in our self-developed AETA system to verify its effectiveness. The experimental results demonstrate that our proposed CSA-OCSVM is superior to the compared approaches.
In this study, the used CSA is derived from the function of B cells in the immune system. Unlike traditional geoacoustic signals anomaly detection methods, which lack adaptability, the proposed approach implements change adjustments based on the input sample. Meanwhile, the OCSVM can handle imbalanced samples, and the denotes the most significant geoacoustic signal. Moreover, with our self-collected geoacoustic signals by AETA, the real-world datasets have stronger credibility.
However, this study only focuses on the geoacoustic signals from AETA, neglecting other observed data, which are also important for earthquake prediction. Therefore, we will adopt other observed data with many more instances as our experimental data in future research. Moreover, future work will focus on enriching CSA and applying it to other earthquake-prone areas. We will further test CSA to improve other methods’ detection performance through subsequent experiments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}