
Facial Wrinkle Detection with Multiscale Spatial Feature Fusion Based on Image Enhancement and ASFF-SEUnet



Abstract
:1. Introduction
- An image enhancement method combined with deep learning for full-face wrinkle detection is proposed, which can realize the high-precision recognition of wrinkle detection images in complex environments.
- A novel ASFF-SEUnet model is proposed. The model takes Unet as the main body and replaces the encoder part of it with EfficientNet, increasing the network depth, width, and output resolution of the encoder part as a way to improve the feature extraction capability of the network. Subsequently, the SE attention mechanism is implemented to direct the network feature extraction to prioritize wrinkle features. Finally, the ASFF structure is added to realize the adaptive fusion of multiscale features, which solves the problem of wrinkles with different scale sizes and complex morphology.
- The method achieves high detection accuracy compared to traditional detection methods and deep neural networks without image enhancement.
2. Materials and Methods
2.1. Wrinkle Detection Method Based on Multiscale Spatial Feature Fusion
- An EfficientNet is utilized as an encoder to achieve simultaneous adjustment of the width, depth, and resolution of the network and to improve the feature extraction capability of the network.
- The SE attention mechanism is implemented to increase the network’s performance on wrinkle feature extraction and reduce the effect of redundant features.
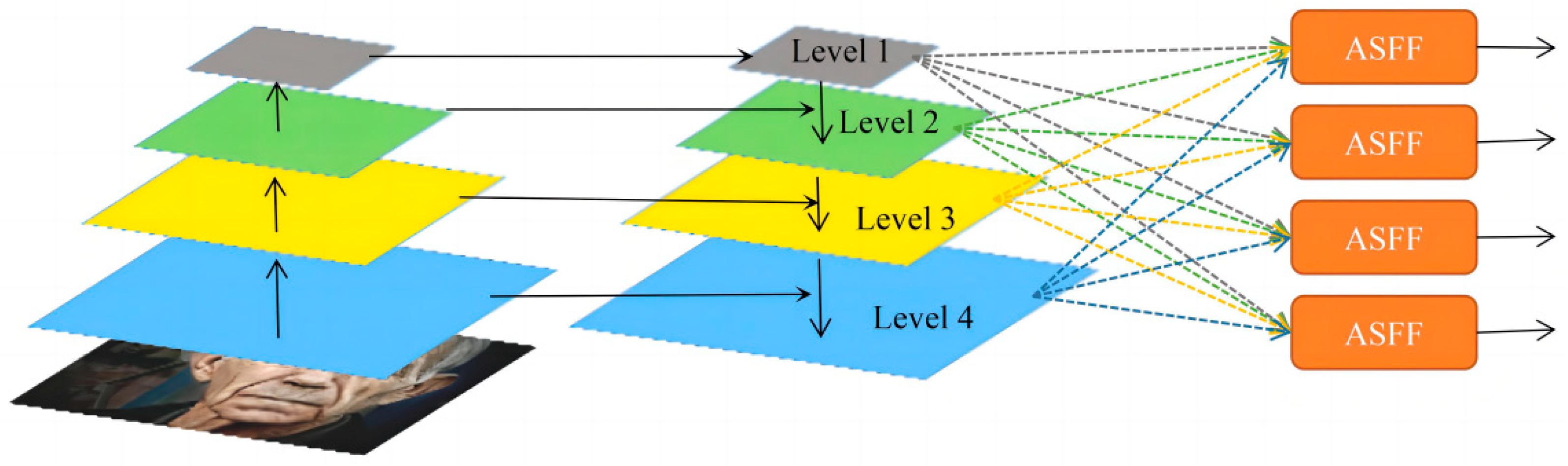
- An ASFF structure is organically integrated to achieve the adaptive fusion of multiscale wrinkle features, which boosts the detection of multiscale wrinkles.
2.2. Graphic Gathering
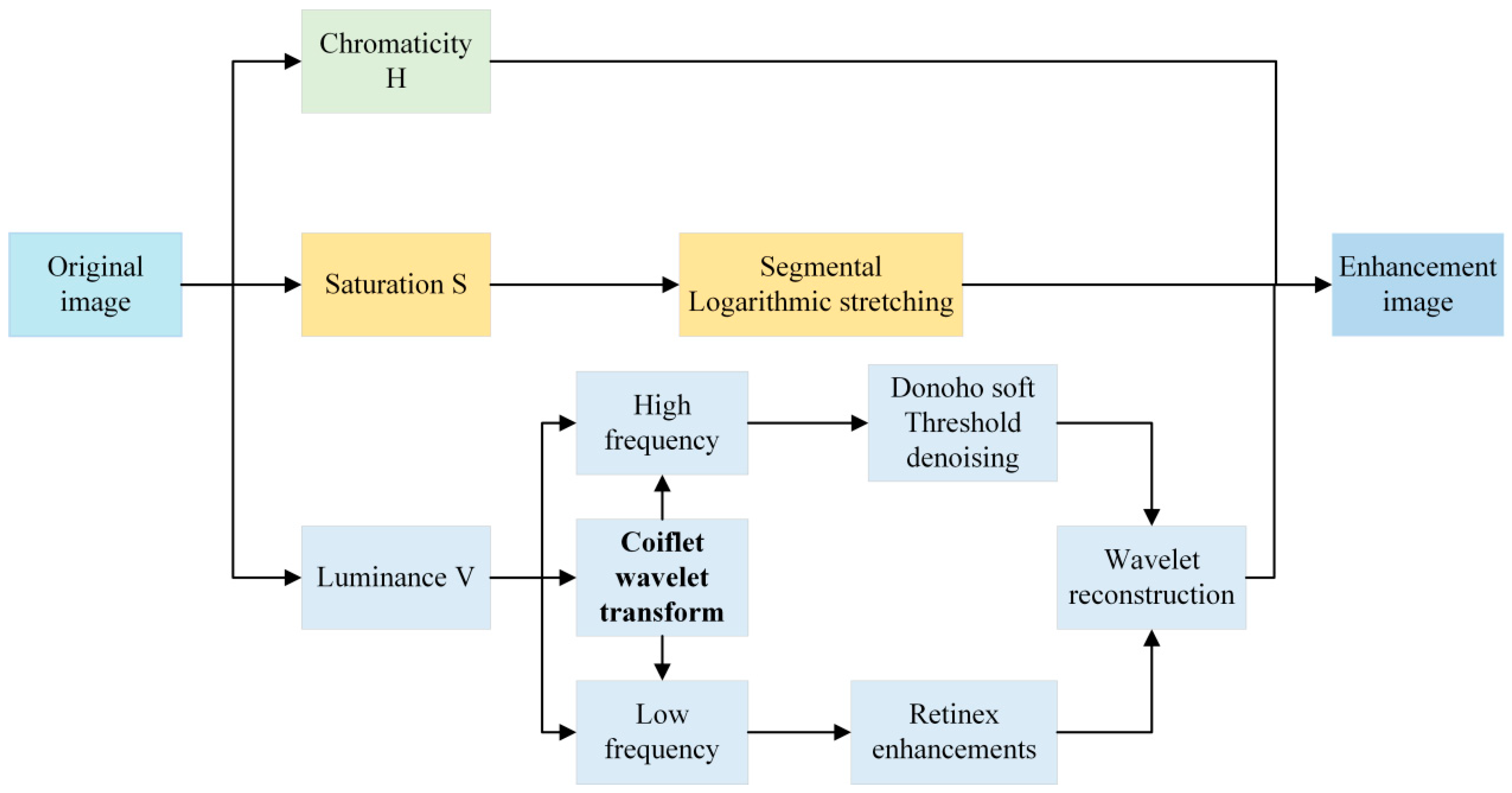
2.3. CT-DIR Wrinkle Image Enhancement Algorithm
- Capable of handling sharp changes: Coiflet wavelets are irregular wavelets that can effectively capture and represent sharp changes in an image and are particularly suitable for denoising images with sharp edges or details.
- An improved quantity of vanishing moments: Coiflet wavelets have a higher number of vanishing moments compared to Sym wavelets, providing a more accurate representation of the signal and better preservation of important features of the image during denoising.
- Tight support: Coiflet wavelets have tight support, which means that they are localized in both the time and frequency domains. This property allows for efficient and localized denoising, as wavelet coefficients outside the support region can be safely discarded without affecting important information in the image.
- Resolution flexibility: Coiflet wavelets provide balanced resolution at any time and frequency, which can provide a good trade-off between time and frequency localization, allowing for more accurate analysis of images at different scales.
2.4. CT-DIR Wrinkle Image Enhancement Algorithm Theory
- Step 1: Color space conversion
- Step 2: Coiflet wavelet transform
- Step 3: Low-frequency coefficient enhancement
- Step 4: High-Frequency Coefficient Denoising
- Step 5: Logarithmic transformation
- Step 6: Reconstruct the image
2.5. ASFF-SEUnet
2.6. ASFF-SEUnet theory
2.6.1. EfficientNet
2.6.2. SE Attention Mechanism
2.6.3. ASFF Module
3. Application and Results Analysis
3.1. Evaluation Metrics
3.2. Experimental Setup
3.3. Ablation Experiment
3.4. Comparative Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fu, Y.; Guo, G.; Huang, T.S. Age synthesis and estimation via faces: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1955–1976. [Google Scholar] [PubMed]
- Luu, K.; Dai Bui, T.; Suen, C.Y.; Ricanek, K. Combined local and holistic facial features for age-determination. In Proceedings of the IEEE 2010 11th International Conference on Control Automation Robotics & Vision, Singapore, 7–10 December 2010; pp. 900–904. [Google Scholar]
- Ng, C.C.; Yap, M.H.; Cheng, Y.T.; Hsu, G.S. Hybrid ageing patterns for face age estimation. Image Vis. Comput. 2018, 69, 92–102. [Google Scholar] [CrossRef]
- Cula, G.O.; Bargo, P.R.; Nkengne, A.; Kollias, N. Assessing facial wrinkles: Automatic detection and quantification. Skin Res. Technol. 2013, 19, 243–251. [Google Scholar] [CrossRef] [PubMed]
- Batool, N.; Chellappa, R. Detection and inpainting of facial wrinkles using texture orientation fields and Markov random field modeling. IEEE Trans. Image Proc. 2014, 23, 3773–3788. [Google Scholar] [CrossRef] [PubMed]
- Ng, C.C.; Yap, M.H.; Costen, N.; Li, B. Automatic wrinkle detection using hybrid hessian filter. In Proceedings of the 12th Asian Conference on Computer Vision (ACCV 2014), Singapore, 1–5 November 2014; Revised Selected Papers, Part III 12. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 609–622. [Google Scholar]
- Xie, W.; Shen, L.; Jiang, J. A novel transient wrinkle detection algorithm and its application for expression synthesis. IEEE Trans. Multimed. 2016, 19, 279–292. [Google Scholar] [CrossRef]
- Batool, N.; Chellappa, R. Fast detection of facial wrinkles based on Gabor features using image morphology and geometric constraints. Pattern Recognit. 2015, 48, 642–658. [Google Scholar] [CrossRef]
- Elbashir, R.M.; Hoon Yap, M. Evaluation of automatic facial wrinkle detection algorithms. J. Imaging 2020, 6, 17. [Google Scholar] [CrossRef] [PubMed]
- Molinara, M.; Cancelliere, R.; Di Tinno, A.; Ferrigno, L.; Shuba, M.; Kuzhir, P.; Maffucci, A.; Micheli, L. A Deep Learning Approach to Organic Pollutants Classification Using Voltammetry. Sensors 2022, 22, 8032. [Google Scholar] [CrossRef] [PubMed]
- Jeyakumar, J.P.; Jude, A.; Priya Henry, A.G.; Hemanth, J. Comparative Analysis of Melanoma Classification Using Deep Learning Techniques on Dermoscopy Images. Electronics 2022, 11, 2918. [Google Scholar] [CrossRef]
- Pintelas, E.; Livieris, I.E. XSC—An eXplainable Image Segmentation and Classification Framework: A Case Study on Skin Cancer. Electronics 2023, 12, 3551. [Google Scholar] [CrossRef]
- Qin, H.; Deng, Z.; Shu, L.; Yin, Y.; Li, J.; Zhou, L.; Zeng, H.; Liang, Q. Portable Skin Lesion Segmentation System with Accurate Lesion Localization Based on Weakly Supervised Learning. Electronics 2023, 12, 3732. [Google Scholar] [CrossRef]
- Wei, M.; Wu, Q.; Ji, H.; Wang, J.; Lyu, T.; Liu, J.; Zhao, L. A Skin Disease Classification Model Based on DenseNet and ConvNeXt Fusion. Electronics 2023, 12, 438. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, C.; Dong, M.; Le, J.; Rao, M. Using ranking-CNN for age estimation. In Proceedings of the IEEE 2017 Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5183–5192. [Google Scholar]
- Alarifi, J.S.; Goyal, M.; Davison, A.K.; Dancey, D.; Khan, R.; Yap, M.H. Facial skin classification using convolutional neural networks. In Proceedings of the 14th International Conference of Image Analysis and Recognition (ICIAR 2017), Montreal, QC, Canada, 5–7 July 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 479–485. [Google Scholar]
- Sabina, U.; Whangbo, T.K. Nasolabial Wrinkle Segmentation Based on Nested Convolutional Neural Network. In Proceedings of the IEEE 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; pp. 483–485. [Google Scholar]
- Deepa, H.; Gowrishankar, S.; Veena, A. A Deep Learning-Based Detection of Wrinkles on Skin. In Proceedings of the Computational Vision and Bio-Inspired Computing (ICCVBIC 2021), Online, 25–26 November 2021; Springer: Singapore, 2022; pp. 25–37. [Google Scholar]
- Chang, T.R.; Tsai, M.Y. Classifying conditions of speckle and wrinkle on the human face: A deep learning approach. Electronics 2022, 11, 3623. [Google Scholar] [CrossRef]
- Lv, M.; Zhou, G.; He, M.; Chen, A.; Zhang, W.; Hu, Y. Maize leaf disease identification based on feature enhancement and DMS-robust alexnet. IEEE Access 2020, 8, 57952–57966. [Google Scholar] [CrossRef]
- Hevia-Montiel, N.; Haro, P.; Guillermo-Cordero, L. and Perez-Gonzalez, J. Deep Learning–Based Segmentation of Trypanosoma cruzi Nests in Histopathological Images. Electronics 2023, 12, 4144. [Google Scholar] [CrossRef]
- You, Z.; Yu, H.; Xiao, Z.; Peng, T.; Wei, Y. CAS-UNet: A Retinal Segmentation Method Based on Attention. Electronics 2023, 12, 3359. [Google Scholar] [CrossRef]
- Mehta, D.; Skliar, A.; Ben Yahia, H.; Borse, S.; Porikli, F.; Habibian, A.; Blankevoort, T. Simple and Efficient Architectures for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2628–2636. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th Medical Image Computing and Computer-Assisted Intervention International Conference (MICCAI 2015), Munich, Germany, 5–9 October 2015; Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2019; pp. 4401–4410. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age progression/regression by conditional adversarial autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5810–5818. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 2019 International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE 2018 Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, T.; Zhang, L.; Zhou, G.; Cai, W.; Cai, C.; Li, L. BC-DUnet-based segmentation of fine cracks in bridges under a complex background. PLoS ONE 2022, 17, e0265258. [Google Scholar] [CrossRef] [PubMed]
- Cao, H.; Gao, Y.; Cai, W.; Xu, Z.; Li, L. Segmentation Detection Method for Complex Road Cracks Collected by UAV Based on HC-Unet++. Drones 2023, 7, 189. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Specific Operations | Methods |
|---|---|---|
| Flipping | Horizontal flip, vertical flip, horizontal–vertical flip | Flipping |
| Rotation | Random rotation at a certain angle with the image center as the origin (0°, 90°, 180°, 270°) | Rotation |
| Methods | Number | Proportion |
|---|---|---|
| Young people | 1175 | 21.4% |
| Middle-aged people | 3470 | 63.1% |
| Older people | 855 | 15.5% |
| Layer | Parameter | Follow-Up Action | |
|---|---|---|---|
| Input | 512 × 512 × 3 | ||
| Encoder EfficientNet | Down-sampling 1 | Depthwise filter (3 × 3), 1 stride (MBConv1) | Feat1 (SE + ASFF) |
| Down-sampling 2 | Depthwise filter (3 × 3), 2 strides (MBConv2) Depthwise filter (3 × 3), 2 strides (MBConv3) | Feat2 (SE + ASFF) | |
| Down-sampling 3 | Depthwise filter (5 × 5), 2 strides (MBConv4) Depthwise filter (5 × 5), 2 strides (MBConv5) | Feat3 (SE + ASFF) | |
| Down-sampling 4 | Depthwise filter (3 × 3), 2 strides (MBConv6) Depthwise filter (3 × 3), 2 strides (MBConv7) Depthwise filter (3 × 3), 2 strides (MBConv8) Depthwise filter (5 × 5), 1 stride (MBConv9) Depthwise filter (5 × 5), 1 stride (MBConv10) Depthwise filter (5 × 5), 1 stride (MBConv11) | Feat4 (SE + ASFF) | |
| Down-sampling 5 | Depthwise filter (5 × 5), 2 strides (MBConv12) Depthwise filter (5 × 5), 2 strides (MBConv13) Depthwise filter (5 × 5), 2 strides (MBConv14) Depthwise filter (5 × 5), 2 strides (MBConv15) Depthwise filter (5 × 5), 1 stride (MBConv16) | Feat5 | |
| Decoder | Up-sampling 1 | Deconv filter (2 × 2), 2 strides (Deconv1) Concat (feat1 (SE+ASFF), Deconv1) Convolution filter (3 × 3), 1 stride (conv1) Convolution filter (3 × 3) 1 strides (conv2) | |
| Up-sampling 2 | Deconv filter (2 × 2), 2 strides (Deconv2) Concat (feat2 (SE + ASFF), Deconv2) Convolution filter (3 × 3), 1 stride (conv3) Convolution filter (3 × 3) 1 stride (conv4) | ||
| Up-sampling 3 | Deconv filter (2 × 2), 2 strides (Deconv3) Concat (feat3 (SE + ASFF) Convolution filter (3 × 3), 1 stride (conv5) Convolution filter (3 × 3), 1 stride (conv6) | ||
| Up-sampling 4 | Deconv filter (2 × 2), 2 strides (Deconv4) Concat (feat4 (SE + ASFF), Deconv4) Convolution filter (3 × 3), 1 stride (conv7) Convolution filter (3 × 3), 1 stride (conv8) | ||
| Output | 512 × 512 × 3 | Softmax | |
| Structure | Stage | Operator | Resolution | Channels | Layers |
|---|---|---|---|---|---|
| Stem | 1 | Conv3 × 3 | 224 × 224 | 32 | 1 |
| Blocks | 2 | MBconv1, k3 × 3 | 112 × 112 | 16 | 1 |
| 3 | MBconv6, k3 × 3 | 112 × 112 | 24 | 2 | |
| 4 | MBconv6, k3 × 3 | 56 × 56 | 40 | 2 | |
| 5 | MBconv6, k3 × 3 | 28 × 28 | 80 | 3 | |
| 6 | MBconv6, k3 × 3 | 14 × 14 | 112 | 3 | |
| 7 | MBconv6, k3 × 3 | 14 × 14 | 192 | 4 | |
| 8 | MBconv6, k3 × 3 | 7 × 7 | 320 | 1 | |
| Head | 9 | Conv1 × 1&Pooling&FC | 7 × 7 | 1280 | 1 |
| Network | PA | MIoU | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Unet | 98.44% | 52.29% | 62.77% | 75.8% | 68.67% |
| Unet + EfficientNet | 98.60% | 53.11% | 64.77% | 74.6% | 69.68% |
| Unet + EfficientNet + SE | 99.4% | 56.42% | 67.27% | 77.78% | 71.56% |
| ASFF-SEUnet | 99.6% | 56.77% | 69.64% | 75.44% | 72.42% |
| Network | PA | MioU | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| NCNN | 98.9% | 54.36% | 63.32% | 73.52% | 69.49% |
| FCN-4s | 98.5% | 37.5% | 43% | 74.54% | 54.54% |
| PspNet | 99.5% | 48.35% | 66.13% | 64.25% | 65.18% |
| DeeplabV3+ | 99.2% | 50.23% | 68.12% | 68.2% | 68.1% |
| BC-Dunet | 99.2% | 54.45% | 68.33% | 64.22% | 68.3% |
| HC-Unet++ | 99.3% | 55.42% | 68.76% | 74.55% | 71.85% |
| ASFF-SEUnet | 99.6% | 56.77% | 69.64% | 75.44% | 72.42% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; He, M.; Cai, W. Facial Wrinkle Detection with Multiscale Spatial Feature Fusion Based on Image Enhancement and ASFF-SEUnet. Electronics 2023, 12, 4897. https://doi.org/10.3390/electronics12244897
Chen J, He M, Cai W. Facial Wrinkle Detection with Multiscale Spatial Feature Fusion Based on Image Enhancement and ASFF-SEUnet. Electronics. 2023; 12(24):4897. https://doi.org/10.3390/electronics12244897
Chicago/Turabian StyleChen, Jiang, Mingfang He, and Weiwei Cai. 2023. "Facial Wrinkle Detection with Multiscale Spatial Feature Fusion Based on Image Enhancement and ASFF-SEUnet" Electronics 12, no. 24: 4897. https://doi.org/10.3390/electronics12244897
APA StyleChen, J., He, M., & Cai, W. (2023). Facial Wrinkle Detection with Multiscale Spatial Feature Fusion Based on Image Enhancement and ASFF-SEUnet. Electronics, 12(24), 4897. https://doi.org/10.3390/electronics12244897