
GRU- and Transformer-Based Periodicity Fusion Network for Traffic Forecasting



Abstract
:1. Introduction
- We present a novel and interpretable perspective for handling periodicity traffic prediction data, aiming to use the different features of various types of periodicity data fully. Specifically, we utilize hourly data to forecast the basic future traffic pattern and introduce the Pattern Induction Block, which enables the induction of regular future traffic patterns from daily and weekly data. Furthermore, we propose the Pattern Fusion Transformer to consolidate these disparate outputs effectively.
- We propose the Spatial Attention GRU encoder–decoder to simultaneously consider spatial and temporal relationships. This spatial attention mechanism facilitates the dynamic computation of inter-node relationships at each time step. Consequently, it enhances the representation of the current traffic status while effectively capturing the evolving spatial correlations.
- We conduct extensive experimental evaluations to assess the model’s performance on four PEMS datasets. The resulting experimental findings reveal that GTPFN performs better than state-of-the-art baselines on most horizons.
2. Related Work
2.1. Periodicity
2.2. Transformer
3. Preliminaries
3.1. Road Network
3.2. Traffic Feature Matrix
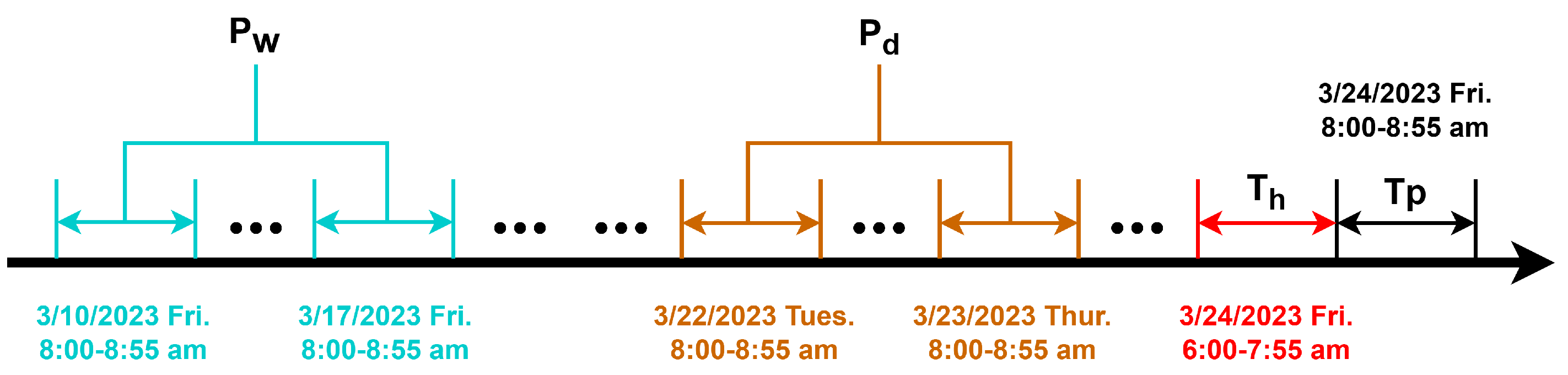
3.3. Problem Definition
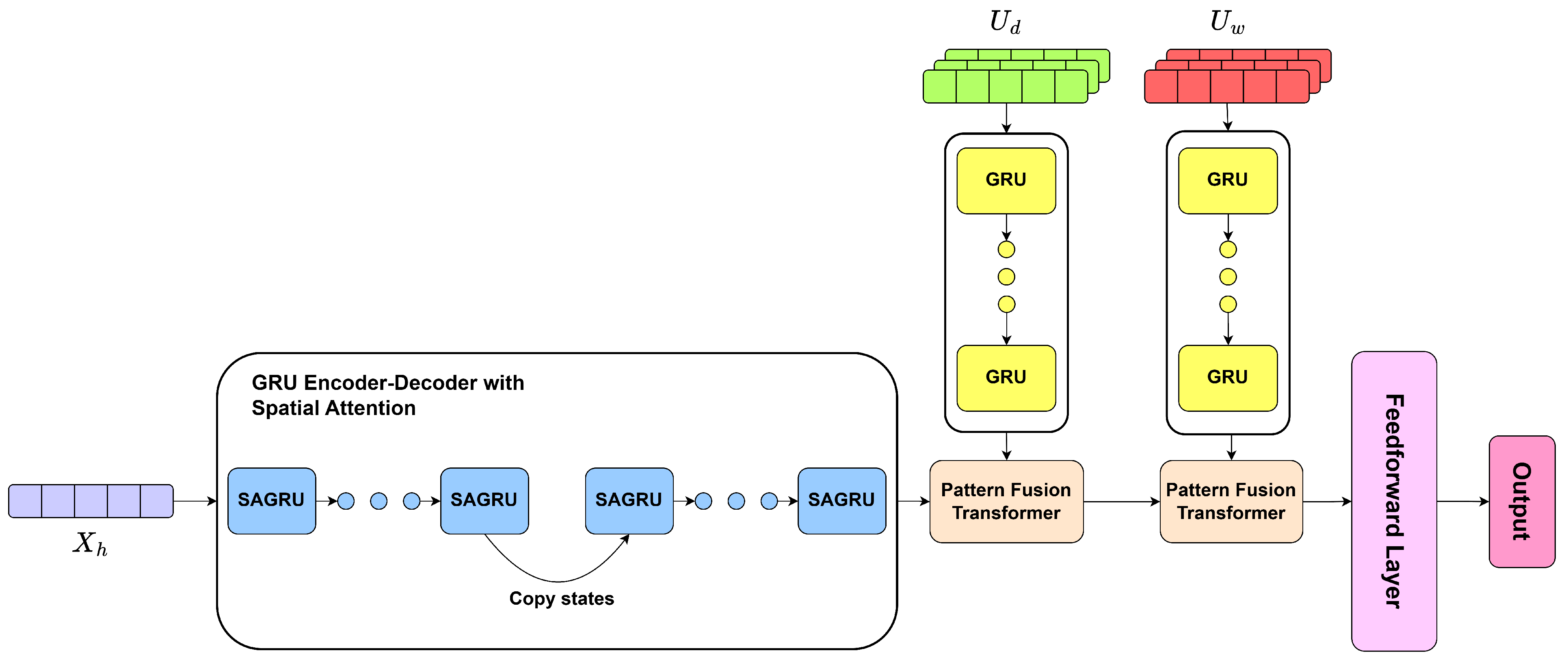
4. Methodology
4.1. Data Preparation and Processing
4.2. Overview
4.3. Spatial Attention GRU Encoder–Decoder
4.4. Pattern Induction Block
4.5. Pattern Fusion Transformer
5. Experiment
5.1. Datasets
5.2. Baselines
- HA: A statistical method that employs historical data averages to forecast forthcoming values.
- ARIMA [29]: A methodology that integrates autoregressive and moving average models to address time series forecasting challenges.
- VAR [30]: A statistical method used for modeling and analyzing the dynamic relationships among multiple time series variables.
- FC-LSTM [31]: A neural network architecture that combines fully connected layers with Long Short-Term Memory (LSTM) layers to handle sequential and non-sequential data.
- DCRNN [32]: A model that combines the bi-directional random walk on the distance-based graph with GRU in an encoder–decoder manner.
- Graph WaveNet [33]: A framework that combines the adaptive adjacency matrix into graph convolution with 1D dilated convolution.
- ASTGCN [16]: A model which utilizes attention and convolution to capture the spatio-temporal relationship with periodicity fusion.
- STGCN [13]: A method that utilizes graph convolution and casual convolution to learn the spatial and temporal dependencies.
- STSGCN [34]: A network that utilizes the localized spatio-temporal subgraph module to model localized correlations independently.
- STID [35]: A framework that leverages Spatial and Temporal IDentity information (STID) to address samples’ indistinguishability in the spatial and temporal dimensions based on multi-layer perceptrons.
5.3. Evaluation Metrics
5.4. Experiment Setting
5.5. Main Results
5.6. Ablation Study
- GTPFN w/o P: Removes the utilization of daily data and weekly data and only uses hourly data for predictions.
- GTPFN w/o T: Removes the Pattern Fusion Transformer and fuses the periodical data by linear layers instead.
- GTPFN w/o H: Removes the utilization of hourly data and only uses daily data and weekly data to induce the pattern.
- GTPFN w/o A: Removes the attention mechanism from the SAGRU encoder–decoder.
5.7. Hyperparameter Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guo, K.; Wu, Z.; Wang, W.; Ren, S.; Zhou, X.; Gadekallu, T.R.; Luo, E.; Liu, C. GRTR: Gradient Rebalanced Traffic Sign Recognition for Autonomous Vehicles. IEEE Trans. Autom. Sci. Eng. 2023, 1–13. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, W.; Liu, L.; Dev, K.; Qureshi, N.M.F. AoI Optimization in the UAV-Aided Traffic Monitoring Network Under Attack: A Stackelberg Game Viewpoint. IEEE Trans. Intell. Transp. Syst. 2023, 24, 932–941. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Q.C.; Yang, W.; Wei, N.; Dong, D. An Improved K-nearest Neighbor Model for Short-term Traffic Flow Prediction. Procedia Soc. Behav. Sci. 2013, 96, 653–662. [Google Scholar] [CrossRef]
- Zivot, E.; Wang, J. Vector Autoregressive Models for Multivariate Time Series. In Modeling Financial Time Series with S-Plus®; Springer: New York, NY, USA, 2003; pp. 369–413. [Google Scholar] [CrossRef]
- Ma, X.; Dai, Z.; He, Z.; Na, J.; Wang, Y.; Wang, Y. Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Wu, F.; ke, J.; Tang, X.; Jia, Y.; Lu, S.; Gong, P.; Ye, J. Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Qi, D. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 31. [Google Scholar] [CrossRef]
- Ubal Núñez, C.; Di-Giorgi, G.; Contreras-Reyes, J.; Salas, R. Predicting the Long-Term Dependencies in Time Series Using Recurrent Artificial Neural Networks. Mach. Learn. Knowl. Extr. 2023, 5, 1340–1358. [Google Scholar] [CrossRef]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph Convolutional Network for Traffic Prediction. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3848–3858. [Google Scholar] [CrossRef]
- Ye, J.; Sun, L.; Du, B.; Fu, Y.; Xiong, H. Coupled Layer-wise Graph Convolution for Transportation Demand Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–7 February 2021; Volume 35, pp. 4617–4625. [Google Scholar] [CrossRef]
- Xu, Y.; Cai, X.; Wang, E.; Liu, W.; Yang, Y.; Yang, F. Dynamic traffic correlations based spatio-temporal graph convolutional network for urban traffic prediction. Inf. Sci. 2022, 621, 580–595. [Google Scholar] [CrossRef]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, Stockholm, Sweden, 13–19 July 2018; AAAI Press Inc.: Menlo Park, CA, USA, 2018; pp. 3634–3640. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, C.; Tsung, F. Transformer Based Spatial-Temporal Fusion Network for Metro Passenger Flow Forecasting. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–17 August 2021; pp. 1515–1520. [Google Scholar]
- Tao, S.; Zhang, H.; Yang, F.; Wu, Y.; Li, C. Multiple Information Spatial-Temporal Attention based Graph Convolution Network for traffic prediction. Appl. Soft Comput. 2023, 136, 110052. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 922–929. [Google Scholar] [CrossRef]
- Zhu, C.; Yu, C.X.; Huo, J. Research on Spatio-Temporal Network Prediction Model of Parallel-Series Traffic Flow Based on Transformer and Gcat. SSRN Electron. J. 2022. [Google Scholar] [CrossRef]
- Huang, X.; Ye, Y.; Yang, X.; Xiong, L. Multi-view dynamic graph convolution neural network for traffic flow prediction. Expert Syst. Appl. 2023, 222, 119779. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the NIPS’17: 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Xu, M.; Dai, W.; Liu, C.; Gao, X.; Lin, W.; Qi, G.J.; Xiong, H. Spatial-Temporal Transformer Networks for Traffic Flow Forecasting. arXiv 2020, arXiv:2001.02908. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. arXiv 2022, arXiv:2106.13008. [Google Scholar]
- Liu, Y.; Wu, H.; Wang, J.; Long, M. Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting. arXiv 2022, arXiv:2205.14415. [Google Scholar]
- Jiang, J.; Han, C.; Zhao, W.X.; Wang, J. PDFormer: Propagation Delay-Aware Dynamic Long-Range Transformer for Traffic Flow Prediction. arXiv 2023, arXiv:2301.07945. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Chen, C.; Varaiya, P.P. Freeway Performance Measurement System (Pems); PATH Research Report; Sage: Thousand Oaks, CA, USA, 2002. [Google Scholar]
- Box, G.E.P.; Jenkins, G. Time Series Analysis, Forecasting and Control; Holden-Day, Inc.: Oakland, CA, USA, 1990. [Google Scholar]
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, Macao, China, 10–16 August 2019; AAAI Press Inc.: Menlo Park, CA, USA, 2019; pp. 1907–1913. [Google Scholar] [CrossRef]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-Temporal Synchronous Graph Convolutional Networks: A New Framework for Spatial-Temporal Network Data Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 914–921. [Google Scholar] [CrossRef]
- Shao, Z.; Zhang, Z.; Wang, F.; Wei, W.; Xu, Y. Spatial-Temporal Identity: A Simple yet Effective Baseline for Multivariate Time Series Forecasting. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Sensors | Granularity | #Time Step | Time Range |
|---|---|---|---|---|
| PEMS-Bay | 325 | 5 min | 52,116 | 01/01/2017–06/31/2017 |
| PEMS04 | 307 | 5 min | 16,992 | 01/01/2018–02/28/2018 |
| PEMS07 | 883 | 5 min | 28,224 | 05/01/2017–08/31/2017 |
| PEMS08 | 170 | 5 min | 17,856 | 07/01/2016–08/31/2016 |
| Datasets | Methods | Horizon 3 | Horizon 6 | Horizon 12 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | ||
| PEMS-Bay | HA | 2.88 | 5.59 | 6.77% | 2.88 | 5.59 | 6.77% | 2.88 | 5.59 | 6.77% |
| ARIMA | 1.62 | 3.30 | 3.50% | 2.33 | 4.76 | 5.40% | 3.38 | 6.50 | 8.30% | |
| VAR | 1.74 | 3.16 | 3.60% | 2.32 | 4.25 | 5.00% | 2.93 | 5.44 | 6.50% | |
| FC-LSTM | 2.05 | 4.19 | 4.80% | 2.20 | 4.55 | 5.20% | 2.37 | 4.96 | 5.70% | |
| DCRNN | 1.39 | 2.80 | 2.73% | 1.66 | 3.81 | 3.75% | 1.98 | 4.64 | 4.75% | |
| Graph WaveNet | 1.39 | 2.80 | 2.69% | 1.65 | 3.75 | 3.65% | 1.97 | 4.58 | 4.63% | |
| ASTGCN | 1.52 | 3.13 | 3.22% | 2.01 | 4.27 | 4.48% | 2.61 | 5.42 | 6.00% | |
| STGCN | 1.35 | 2.86 | 2.86% | 1.69 | 3.83 | 3.85% | 2.00 | 4.56 | 4.74% | |
| STSGCN | 1.44 | 3.01 | 3.04% | 1.83 | 4.18 | 4.17% | 2.26 | 5.21 | 5.40% | |
| STID | 1.30 | 2.81 | 2.73% | 1.62 | 3.72 | 3.68% | 1.89 | 4.40 | 4.47% | |
| GTPFN | 1.31 | 2.75 | 2.65% | 1.62 | 3.65 | 3.52% | 1.90 | 4.35 | 4.29% | |
| PEMS04 | HA | 30.26 | 60.93 | 72.24% | 30.26 | 60.93 | 72.24% | 30.26 | 60.93 | 72.24% |
| ARIMA | 21.98 | 35.21 | 16.52% | 25.38 | 39.21 | 21.03% | 26.67 | 40.74 | 22.43% | |
| VAR | 21.94 | 34.40 | 16.42% | 23.72 | 36.58 | 18.02% | 26.76 | 40.28 | 20.94% | |
| FC-LSTM | 21.37 | 33.31 | 15.21% | 23.72 | 36.58 | 18.02% | 26.76 | 40.28 | 20.94% | |
| DCRNN | 19.65 | 31.29 | 15.17% | 21.80 | 34.11 | 16.83% | 26.20 | 39.91 | 18.43% | |
| Graph WaveNet | 18.75 | 29.80 | 14.14% | 20.40 | 31.91 | 15.85% | 23.21 | 35.41 | 19.43% | |
| STGCN | 19.70 | 31.15 | 14.83% | 20.70 | 32.86 | 15.28% | 22.14 | 34.99 | 16.92% | |
| ASTGCN | 20.16 | 31.53 | 14.13% | 22.29 | 34.27 | 15.65% | 26.23 | 40.12 | 19.19% | |
| STSGCN | 19.80 | 31.58 | 13.41% | 21.30 | 33.84 | 14.27% | 24.47 | 38.84 | 16.27% | |
| STID | 17.52 | 28.48 | 12.00% | 18.29 | 29.86 | 12.46% | 19.58 | 31.79 | 13.38% | |
| GTPFN | 17.72 | 29.74 | 11.82% | 18.51 | 31.24 | 12.18% | 19.87 | 33.42 | 13.00% | |
| PEMS07 | HA | 37.59 | 51.65 | 21.83% | 37.59 | 51.65 | 21.83% | 37.59 | 51.65 | 21.83% |
| ARIMA | 32.02 | 48.83 | 18.30% | 35.18 | 52.91 | 20.54% | 38.12 | 55.64 | 20.77% | |
| VAR | 20.09 | 32.13 | 13.61% | 25.58 | 40.41 | 17.44% | 32.86 | 52.05 | 26.00% | |
| FC-LSTM | 20.42 | 33.21 | 8.79% | 23.18 | 37.54 | 9.80% | 28.73 | 45.63 | 12.23% | |
| DCRNN | 19.45 | 31.39 | 8.29% | 21.18 | 34.42 | 9.01% | 24.14 | 38.84 | 10.42% | |
| Graph WaveNet | 18.69 | 30.69 | 8.02% | 20.26 | 33.37 | 8.56% | 22.79 | 37.11 | 9.73% | |
| STGCN | 20.33 | 32.73 | 8.68% | 21.66 | 35.35 | 9.16% | 22.74 | 37.94 | 9.71% | |
| ASTGCN | 21.36 | 32.91 | 8.87% | 22.63 | 36.45 | 9.86% | 24.51 | 37.97 | 11.03% | |
| STSGCN | 20.21 | 31.65 | 8.46% | 21.45 | 33.95 | 8.96% | 23.99 | 39.36 | 10.13% | |
| STID | 18.31 | 30.39 | 7.72% | 19.59 | 32.90 | 8.30% | 21.52 | 36.29 | 9.15% | |
| GTPFN | 17.32 | 29.88 | 7.16% | 18.38 | 31.96 | 7.56% | 20.00 | 34.74 | 8.32% | |
| PEMS08 | HA | 29.52 | 44.03 | 16.59% | 29.52 | 44.03 | 16.59% | 29.52 | 44.03 | 16.59% |
| ARIMA | 19.56 | 29.78 | 12.45% | 22.35 | 33.43 | 14.43% | 26.27 | 38.86 | 17.38% | |
| VAR | 19.52 | 29.73 | 12.54% | 22.25 | 33.30 | 14.23% | 26.17 | 38.97 | 17.32% | |
| FC-LSTM | 17.38 | 26.27 | 12.63% | 21.22 | 31.97 | 17.32% | 30.96 | 43.96 | 25.72% | |
| DCRNN | 16.62 | 25.48 | 10.04% | 17.88 | 17.63 | 11.38% | 22.51 | 34.21 | 14.17% | |
| Graph WaveNet | 14.22 | 22.96 | 9.45% | 15.94 | 24.72 | 9.77% | 17.27 | 26.77 | 11.26% | |
| STGCN | 15.45 | 25.13 | 9.98% | 17.79 | 27.38 | 11.03% | 21.46 | 33.71 | 13.34% | |
| ASTGCN | 16.45 | 25.18 | 11.13% | 18.76 | 28.57 | 12.33% | 22.53 | 33.69 | 15.34% | |
| STSGCN | 16.65 | 25.40 | 10.90% | 17.82 | 27.31 | 11.60% | 19.77 | 31.43 | 13.12% | |
| STID | 13.28 | 21.66 | 8.62% | 14.21 | 23.57 | 9.24% | 15.58 | 25.89 | 10.33% | |
| GTPFN | 12.95 | 21.93 | 8.94% | 13.57 | 23.28 | 9.41% | 14.47 | 25.40 | 10.34% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Liu, S.; Zhang, P.; Li, B. GRU- and Transformer-Based Periodicity Fusion Network for Traffic Forecasting. Electronics 2023, 12, 4988. https://doi.org/10.3390/electronics12244988
Zhang Y, Liu S, Zhang P, Li B. GRU- and Transformer-Based Periodicity Fusion Network for Traffic Forecasting. Electronics. 2023; 12(24):4988. https://doi.org/10.3390/electronics12244988
Chicago/Turabian StyleZhang, Yazhe, Shixuan Liu, Ping Zhang, and Bo Li. 2023. "GRU- and Transformer-Based Periodicity Fusion Network for Traffic Forecasting" Electronics 12, no. 24: 4988. https://doi.org/10.3390/electronics12244988
APA StyleZhang, Y., Liu, S., Zhang, P., & Li, B. (2023). GRU- and Transformer-Based Periodicity Fusion Network for Traffic Forecasting. Electronics, 12(24), 4988. https://doi.org/10.3390/electronics12244988