
Dynamic Malware Detection Using Parameter-Augmented Semantic Chain


Abstract
:1. Introduction
- In this paper, a new API feature extraction approach is proposed from the perspective of semantic information and the characteristics of API sequences. This approach maximizes the description of the behavior of the samples by referring to both the semantic information of the API itself and its parameters. We semantically decompose the APIs and use the parameters of the APIs as an augmentation of the semantic information to extract a semantic chain containing complete semantic information from the API sequences.
- This paper refers to the common practice in recommender systems and applies feature hash to behavior-based dynamic malware detection to solve the dynamic input problem caused by API parameters. It enables the malware detection system to handle unknown inputs more efficiently, thus alleviating the problem of an aging detection system to a certain extent.
- A new API sequence information compression method is proposed. Therefore, this paper borrows the method of dealing with extra-long sequences in NLP, i.e., using key sentences instead of whole paragraphs. The statistical information of the sequence is used as the “key sentence” of the whole sequence, which is used as the complement of the API sequence and solves the problem of losing the key behavior caused by truncating the API sequence. The final experimental results prove that this approach is very effective in dynamic detection.
- We evaluate the recognition performance of this method on a competition dataset. Comparison experiments with other baseline models are also conducted. The final experimental results show that our method is significantly better than various baseline models.
2. Related Work
2.1. Static Analysis
2.2. Dynamic Analysis
2.2.1. API-Sequence-Based Methods
2.2.2. Deep-Learning- and Sequence-Encoding-Based Methods
3. Methodology
3.1. Overview of the Design
3.2. Feature Vector Generation
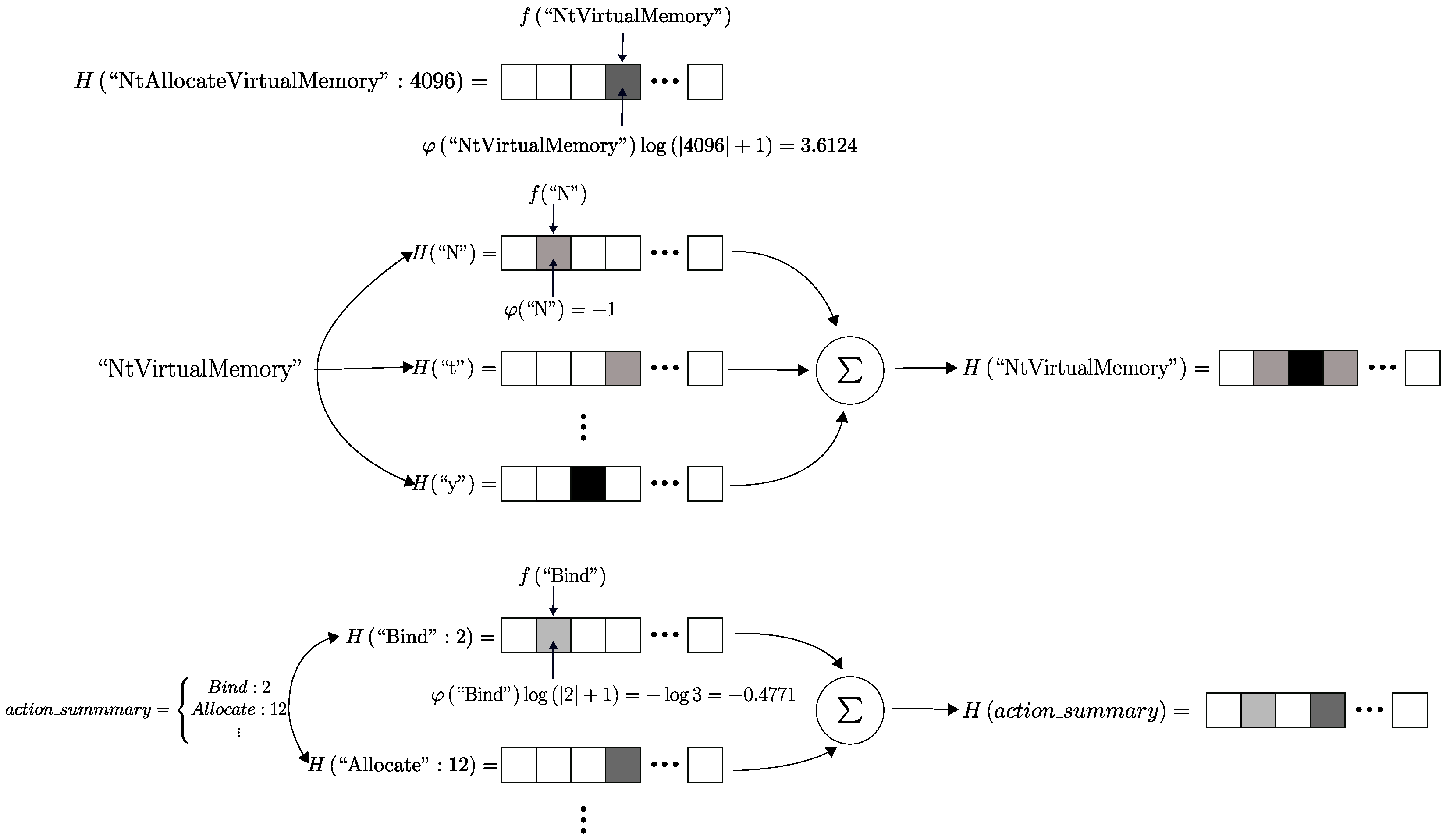
3.3. Action and Object
3.4. Parameters
3.5. Action and Object Summary
3.6. Deep Learning Network Architecture
3.6.1. Gated CNN
3.6.2. Bi-LSTM
3.6.3. Attention
4. Experiment
4.1. Experimental Environment
4.2. Dataset
4.3. Hyperparameters
4.4. Metrics
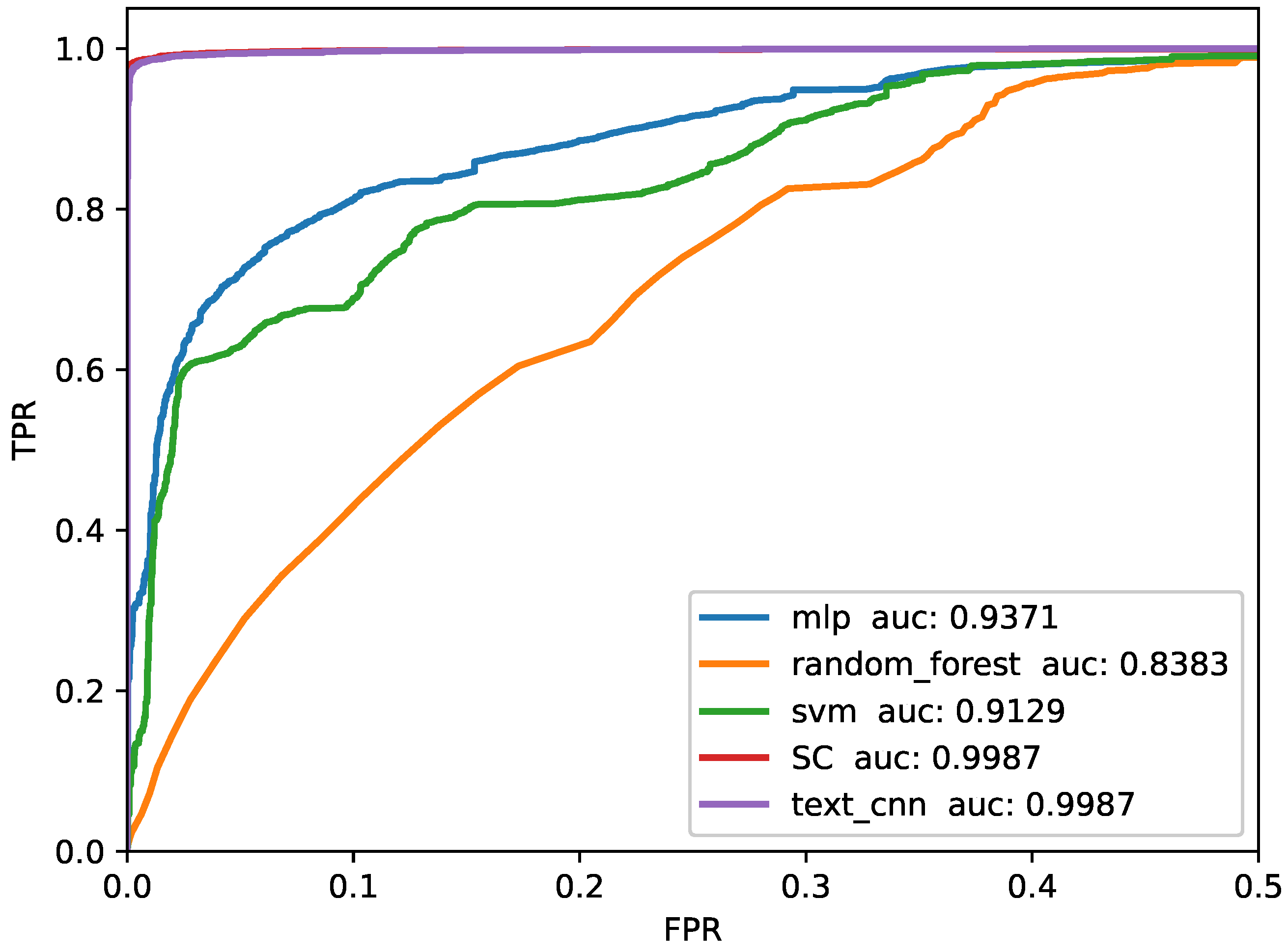
4.5. Baselines
5. Discussion
5.1. Robustness to Unknown Input
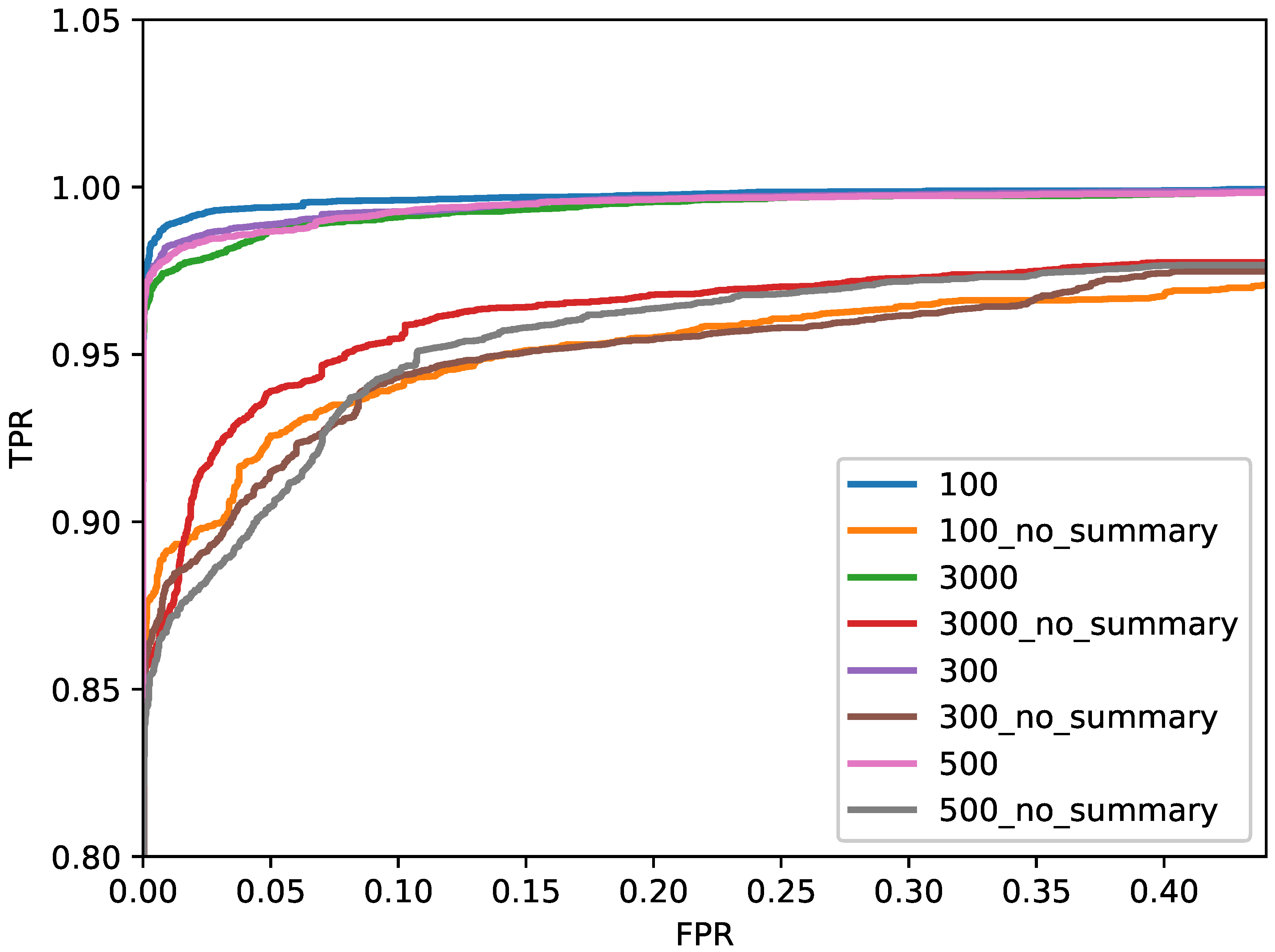
5.2. Influence of Summary
5.3. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- AV-TEST. AV-TEST Report. 2022. Available online: https://www.av-test.org/en/statistics/malware/ (accessed on 1 December 2022).
- Santos, I.; Penya, Y.K.; Devesa, J.; Bringas, P.G. N-grams-based file signatures for malware detection. In International Conference on Enterprise Information Systems; SCITEPRESS: Setúbal, Portugal, 2009; Volume 9, pp. 317–320. [Google Scholar]
- Griffin, K.; Schneider, S.; Hu, X.; Chiueh, T.C. Automatic generation of string signatures for malware detection. In Proceedings of the International Workshop on Recent Advances in Intrusion Detection, Saint-Malo, France, 23–25 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 101–120. [Google Scholar]
- You, I.; Yim, K. Malware obfuscation techniques: A brief survey. In Proceedings of the 2010 International Conference on Broadband, Wireless Computing, Communication and Applications, Fukuoka, Japan, 4–6 November 2010; pp. 297–300. [Google Scholar]
- Bilge, L.; Dumitraş, T. Before we knew it: An empirical study of zero-day attacks in the real world. In Proceedings of the 2012 ACM conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 833–844. [Google Scholar]
- Damodaran, A.; Troia, F.D.; Visaggio, C.A.; Austin, T.H.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 1–12. [Google Scholar] [CrossRef]
- Thantharate, P. IntelligentMonitor: Empowering DevOps Environments with Advanced Monitoring and Observability. In Proceedings of the 2023 International Conference on Information Technology (ICIT), Amman, Jordan, 9–10 August 2023; pp. 800–805. [Google Scholar]
- Herrera-Silva, J.A.; Hernández-Álvarez, M. Dynamic feature dataset for ransomware detection using machine learning algorithms. Sensors 2023, 23, 1053. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Qi, P.; Wang, W. Dynamic malware analysis with feature engineering and feature learning. AAAI Conf. Artif. Intell. 2020, 34, 1210–1217. [Google Scholar] [CrossRef]
- Amer, E.; Zelinka, I. A dynamic Windows malware detection and prediction method based on contextual understanding of API call sequence. Comput. Secur. 2020, 92, 101760. [Google Scholar] [CrossRef]
- Catak, F.O.; Yazı, A.F.; Elezaj, O.; Ahmed, J. Deep learning based Sequential model for malware analysis using Windows exe API Calls. PeerJ Comput. Sci. 2020, 6, e285. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, R.; Stokes, J.W.; Marinescu, M.; Selvaraj, K. Neural sequential malware detection with parameters. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2656–2660. [Google Scholar]
- Chen, X.; Hao, Z.; Li, L.; Cui, L.; Zhu, Y.; Ding, Z.; Liu, Y. CruParamer: Learning on Parameter-Augmented API Sequences for Malware Detection. IEEE Trans. Inf. Forensics Secur. 2022, 17, 788–803. [Google Scholar] [CrossRef]
- Salehi, Z.; Sami, A.; Ghiasi, M. MAAR: Robust features to detect malicious activity based on API calls, their arguments and return values. Eng. Appl. Artif. Intell. 2017, 59, 93–102. [Google Scholar] [CrossRef]
- Li, C.; Lv, Q.; Li, N.; Wang, Y.; Sun, D.; Qiao, Y. A novel deep framework for dynamic malware detection based on API sequence intrinsic features. Comput. Secur. 2022, 116, 102686. [Google Scholar] [CrossRef]
- Downing, E.; Mirsky, Y.; Park, K.; Lee, W. DeepReflect: Discovering Malicious Functionality through Binary Reconstruction. In Proceedings of the USENIX Security Symposium, Online, 11–13 August 2021; pp. 3469–3486. [Google Scholar]
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; pp. 11–20. [Google Scholar]
- Raff, E.; Barker, J.; Sylvester, J.; Brandon, R.; Catanzaro, B.; Nicholas, C. Malware detection by eating a whole exe. arXiv 2017, arXiv:1710.09435. [Google Scholar]
- Lee, H.; Cho, S.j.; Han, H.; Cho, W.; Suh, K. Enhancing Sustainability in Machine Learning-based Android Malware Detection using API calls. In Proceedings of the 2022 IEEE Fifth International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 19–21 September 2022; pp. 131–134. [Google Scholar]
- Ahmadi, M.; Sami, A.; Rahimi, H.; Yadegari, B. Malware detection by behavioural sequential patterns. Comput. Fraud. Secur. 2013, 2013, 11–19. [Google Scholar] [CrossRef]
- Ravi, C.; Manoharan, R. Malware detection using windows api sequence and machine learning. Int. J. Comput. Appl. 2012, 43, 12–16. [Google Scholar] [CrossRef]
- Cheng, J.Y.C.; Tsai, T.S.; Yang, C.S. An information retrieval approach for malware classification based on Windows API calls. In Proceedings of the 2013 International Conference on Machine Learning and Cybernetics, Tianjin, China, 14–17 July 2013; Volume 4, pp. 1678–1683. [Google Scholar]
- Fang, Y.; Yu, B.; Tang, Y.; Liu, L.; Lu, Z.; Wang, Y.; Yang, Q. A new malware classification approach based on malware dynamic analysis. In Proceedings of the Australasian Conference on Information Security and Privacy, Auckland, New Zealand, 3–5 July 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 173–189. [Google Scholar]
- Tian, R.; Islam, R.; Batten, L.; Versteeg, S. Differentiating malware from cleanware using behavioural analysis. In Proceedings of the 2010 5th International Conference on Malicious and Unwanted Software, Nancy, France, 19–20 October 2010; pp. 23–30. [Google Scholar]
- Zhang, H.; Zhang, W.; Lv, Z.; Sangaiah, A.K.; Huang, T.; Chilamkurti, N. MALDC: A depth detection method for malware based on behavior chains. World Wide Web 2020, 23, 991–1010. [Google Scholar] [CrossRef]
- Tran, T.K.; Sato, H. NLP-based approaches for malware classification from API sequences. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 101–105. [Google Scholar]
- Hart, J.M. Win32 Systems Programming; Addison-Wesley Longman Publishing Co., Inc.: Reading, MA, USA, 1997. [Google Scholar]
- Weinberger, K.; Dasgupta, A.; Langford, J.; Smola, A.; Attenberg, J. Feature hashing for large scale multitask learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1113–1120. [Google Scholar]
- Jindal, C.; Salls, C.; Aghakhani, H.; Long, K.; Kruegel, C.; Vigna, G. Neurlux: Dynamic malware analysis without feature engineering. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 444–455. [Google Scholar]
- Avllazagaj, E.; Zhu, Z.; Bilge, L.; Balzarotti, D.; Dumitraș, T. When Malware Changed Its Mind: An Empirical Study of Variable Program Behaviors in the Real World. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Virtual, 11–13 August 2021; pp. 3487–3504. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30, Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Foundation, C. Cuckoo Sandbox. 2019. Available online: https://cuckoosandbox.org/ (accessed on 1 January 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actions | # |
|---|---|
| Bind, Accept, Acquire, Add, Adjust, Allocate, analyze, Assign, check, Close, Compress, Connect, Control, Copy, Crack, Create, Decode, Decompress, Decrypt, Delete, Detect, Download, Draw, Duplicate, Encode, Encryp, Enum, Exec, Exit, Export, Find, First, Free, Gen, Get, Hash, inject, Initialize, Is, Ki, listen, Load, Lookup, Make, Map, Move, Next, Obtain, Open, power, Protect, Put, Query, Queue, Read, Recv, Register, Remove, Resume, Save, Search, Select, Send, Set, shutdown, Sizeof, Socket, Start, Status, suspend, Terminate, Unhook, Uninitialize, Unload, Unmap, unpack, Unprotect, Write | 78 |
| Hardware | Configuration |
|---|---|
| CPU | i7-10700 |
| Cores | 8 |
| Threads | 16 |
| GPU | GeForce RTX 3060 |
| Memory | 12 GB |
| RAM | 32 GB |
| Disk | 2 TB |
| Name | Version | Function |
|---|---|---|
| torch | 1.8.0 | A deep learning framework open-sourced by Facebook, which supports GPU-based tensor computation and automatic gradient calculation. |
| numpy | 1.19.4 | The fundamental package for scientific computing with Python, providing a large number of matrix calculation functions. |
| math | 3.10.10 | Performs various advanced mathematical operations. |
| pandas | 0.25.1 | Used for simplifying large-scale structured data operation and analysis, supporting various matrix operations, data cleaning, and other functions. |
| matplotlib | 3.1.1 | A commonly used plotting library in Python for data visualization and creation of various charts. |
| scikit-learn | 0.21.3 | A third-party module that encapsulates commonly used machine learning methods, used for learning classification, regression, dimensionality reduction, and clustering the four major machine learning algorithms. |
| Methods | Accuracy | Presicion | Recall | F1-Score |
|---|---|---|---|---|
| SVM | 86.9190 | 86.7813 | 96.0866 | 91.1972 |
| RandomForest | 84.8239 | 85.3460 | 94.7479 | 89.8015 |
| MLP | 87.0827 | 89.0900 | 93.0815 | 91.0420 |
| Embedding + TextCNN | 98.5599 | 99.6882 | 98.2652 | 98.9716 |
| Proposed method | 99.1925 | 99.5428 | 99.3054 | 99.4264 |
| Methods | Accuracy | Presicion | Recall | F1-Score |
|---|---|---|---|---|
| Embedding + TextCNN | 75.21 | 78.68 | 76.26 | 84.97 |
| Proposed method (without API parameters) | 74.03 | 79.34 | 81.74 | 83.63 |
| Proposed method | 86.32 | 84.54 | 85.30 | 91.59 |
| Length of API | With Summary | Without Summary |
|---|---|---|
| 100 | 99.20 | 92.79 |
| 300 | 98.90 | 92.35 |
| 500 | 98.19 | 91.53 |
| 1000 | 98.21 | 91.12 |
| 3000 | 98.26 | 90.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Wang, H.; Kou, L.; Li, Z.; Zhang, J. Dynamic Malware Detection Using Parameter-Augmented Semantic Chain. Electronics 2023, 12, 4992. https://doi.org/10.3390/electronics12244992
Zhao D, Wang H, Kou L, Li Z, Zhang J. Dynamic Malware Detection Using Parameter-Augmented Semantic Chain. Electronics. 2023; 12(24):4992. https://doi.org/10.3390/electronics12244992
Chicago/Turabian StyleZhao, Donghui, Huadong Wang, Liang Kou, Zhannan Li, and Jilin Zhang. 2023. "Dynamic Malware Detection Using Parameter-Augmented Semantic Chain" Electronics 12, no. 24: 4992. https://doi.org/10.3390/electronics12244992
APA StyleZhao, D., Wang, H., Kou, L., Li, Z., & Zhang, J. (2023). Dynamic Malware Detection Using Parameter-Augmented Semantic Chain. Electronics, 12(24), 4992. https://doi.org/10.3390/electronics12244992