
ZSE-VITS: A Zero-Shot Expressive Voice Cloning Method Based on VITS


Abstract
:1. Introduction
- It uses the end-to-end speech synthesis model VITS [22] as the backbone network, which is better than the two-stage speech synthesis method of synthesizer plus vocoder.
- The current speaker recognition model TitaNet [23] with excellent performance is used as the speaker encoder to provide speaker embeddings with richer speaker information for the voice cloning model.
- To solve the problem of speaker and prosody information decoupling, explicit prosody information, such as pitch, energy, and duration is used to realize the prosody transfer of different speakers.
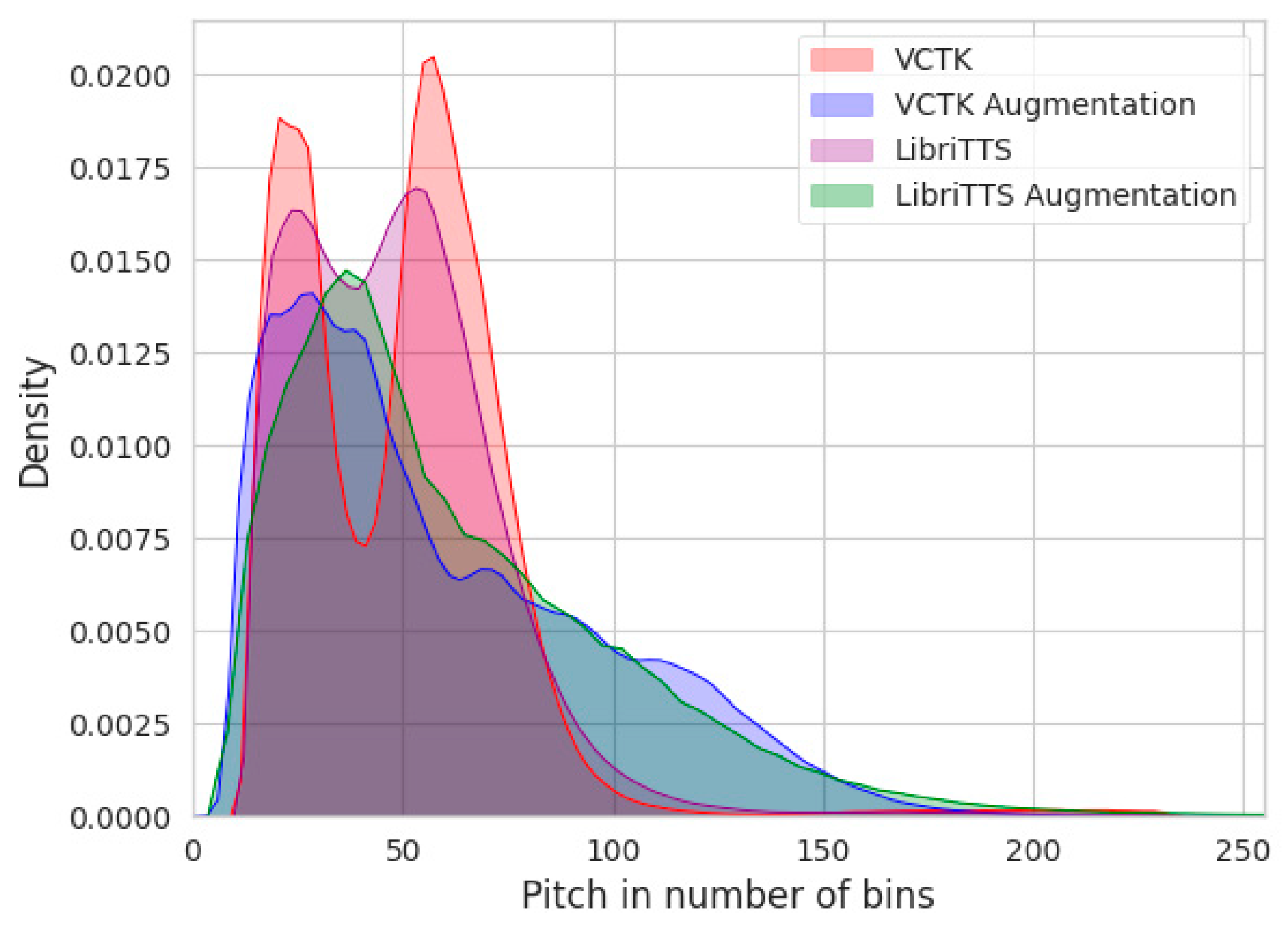
- To improve the generalization ability of the prosody model of unseen speakers, pitch augmentation is used to widen the pitch distribution of the corpus.
- The explicit prosody features of speech can be adjusted directly by using the methods of explicit prosody information prediction and prosody fusion, which does not affect the speaker information of synthesized speech.
- Most of the training corpus is reading-style, and the prosody expressiveness is not as intense as emotion corpus. We fine-tuned the prosody predictor alone in the emotion corpus ESD [24] to learn prosody prediction of various styles, demonstrating the extensibility of the model prosody style prediction.
2. Related Work
2.1. Voice Cloning
2.2. Expressive Speech Synthesis
3. Proposed Method
3.1. Speaker Encoder
3.2. Posterior Encoder
3.3. Prior Encoder
3.3.1. Text Encoder
3.3.2. Prosody Style Extractor
3.3.3. Duration Predictor
3.3.4. Prosody Prediction and Prosody Fusion Module
3.3.5. Normalizing Flow
3.4. Decoder
4. Experiments and Results
4.1. Experiment Settings
4.1.1. Datasets and Preprocessing
4.1.2. Implementation Details
4.1.3. Comparison Method
- (1)
- Ground truth speech: speech segments selected from training and test sets.
- (2)
- VITS: VITS model trained with speaker lookup table can only synthesize speech with corresponding speaker timbre in the lookup table.
- (3)
- EVC: We reimplemented EVC based on Mellotron. The speaker encoder in the original paper uses d-vector and we replaced it with a pretrained TitaNet. The original vocoder uses WaveGlow [2]. We replaced it with HiFi-GAN for higher generation quality. Datasets for training were consistent with our proposed method.
- (4)
- ZS-VITS: The VITS model was trained using speaker embedding extracted by pre-trained TitaNet, which was used as the baseline system to verify the effectiveness of prosody modeling in this paper.
- (5)
- ZSE-VITS: The expressive voice cloning model proposed in this paper.
4.1.4. Evaluation Metric
4.2. Cloned Speech Naturalness and Similarity
4.3. Pitch and Energy Control of Cloned Speech
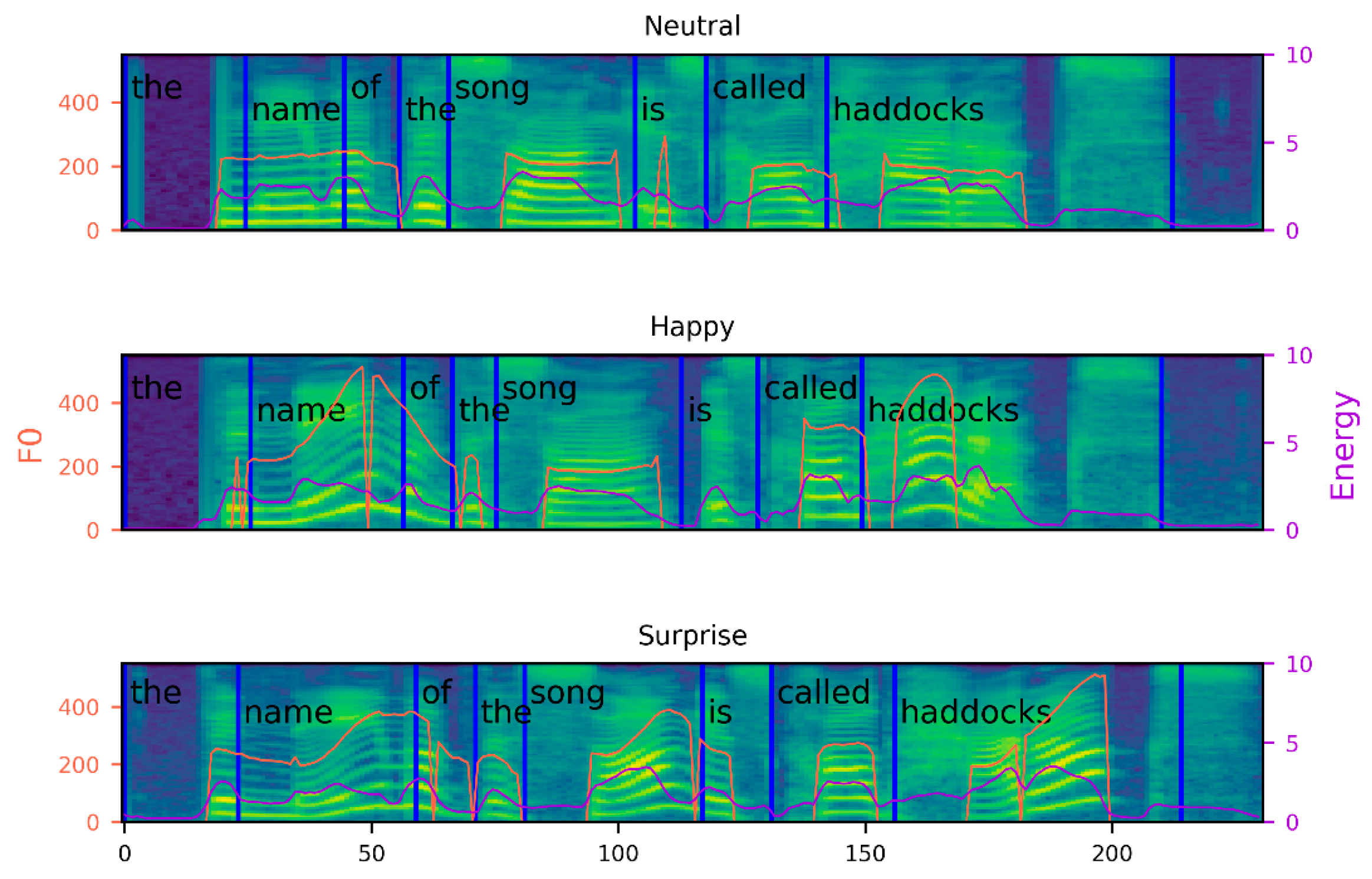
4.4. Prosody Prediction
4.5. Decoupling of Prosody Information and Speaker Timbre
4.6. Local Prosody Adjustment
4.7. Influence of Scaling Factor Change on Speech Quality
5. Conclusions
5.1. Practical Application
5.2. Limitations and Future Development
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. In Proceedings of the 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016; ISCA: Baixas, France, 2016; p. 125. [Google Scholar]
- Prenger, R.; Valle, R.; Catanzaro, B. Waveglow: A Flow-Based Generative Network for Speech Synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 3617–3621. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Ryan, R.-S.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway Township, NJ, USA, 2018; pp. 4779–4783. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Kong, J.; Kim, J.; Bae, J. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In Advances in Neural Information Processing Systems 33, Proceedings of the Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.-F., Lin, H.-T., Eds.; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2020. [Google Scholar]
- Arik, S.Ö.; Chen, J.; Peng, K.; Ping, W.; Zhou, Y. Neural Voice Cloning with a Few Samples. In Advances in Neural Information Processing Systems 31, Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2018; pp. 10040–10050. [Google Scholar]
- Wang, T.; Tao, J.; Fu, R.; Yi, J.; Wen, Z.; Zhong, R. Spoken Content and Voice Factorization for Few-Shot Speaker Adaptation. In Interspeech 2020, Proceedings of the 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; Meng, H., Xu, B., Zheng, T.F., Eds.; ISCA: Baixas, France, 2020; pp. 796–800. [Google Scholar]
- Chen, M.; Tan, X.; Li, B.; Liu, Y.; Qin, T.; Zhao, S.; Liu, T.-Y. AdaSpeech: Adaptive Text to Speech for Custom Voice. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Yan, Y.; Tan, X.; Li, B.; Qin, T.; Zhao, S.; Shen, Y.; Liu, T.-Y. Adaspeech 2: Adaptive Text to Speech with Untranscribed Data. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway Township, NJ, USA, 2021; pp. 6613–6617. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.J.; Wang, Q.; Shen, J.; Ren, F.; Chen, Z.; Nguyen, P.; Pang, R.; Lopez-Moreno, I.; et al. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. In Advances in Neural Information Processing Systems 31, Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2018; pp. 4485–4495. [Google Scholar]
- Cooper, E.; Lai, C.-I.; Yasuda, Y.; Fang, F.; Wang, X.; Chen, N.; Yamagishi, J. Zero-Shot Multi-Speaker Text-To-Speech with State-Of-The-Art Neural Speaker Embeddings. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway Township, NJ, USA, 2020; pp. 6184–6188. [Google Scholar]
- Choi, S.; Han, S.; Kim, D.; Ha, S. Attentron: Few-Shot Text-to-Speech Utilizing Attention-Based Variable-Length Embedding. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; Meng, H., Xu, B., Zheng, T.F., Eds.; ISCA: Baixas, France, 2020; pp. 2007–2011. [Google Scholar]
- Min, D.; Lee, D.B.; Yang, E.; Hwang, S.J. Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, Honolulu, HI, USA, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2021; Volume 139, pp. 7748–7759. [Google Scholar]
- Skerry-Ryan, R.J.; Battenberg, E.; Xiao, Y.; Wang, Y.; Stanton, D.; Shor, J.; Weiss, R.J.; Clark, R.; Saurous, R.A. Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Dy, J.G., Krause, A., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2018; Volume 80, pp. 4700–4709. [Google Scholar]
- Wang, Y.; Stanton, D.; Zhang, Y.; Skerry-Ryan, R.J.; Battenberg, E.; Shor, J.; Xiao, Y.; Jia, Y.; Ren, F.; Saurous, R.A. Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Dy, J.G., Krause, A., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2018; Volume 80, pp. 5167–5176. [Google Scholar]
- Hono, Y.; Tsuboi, K.; Sawada, K.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Hierarchical Multi-Grained Generative Model for Expressive Speech Synthesis. In Proceedings of the Interspeech 2020, 21st Annual Conference of the International Speech Communication Association, Virtual Event, Shanghai, China, 25–29 October 2020; Meng, H., Xu, B., Zheng, T.F., Eds.; ISCA: Baixas, France, 2020; pp. 3441–3445. [Google Scholar]
- Li, X.; Song, C.; Li, J.; Wu, Z.; Jia, J.; Meng, H. Towards Multi-Scale Style Control for Expressive Speech Synthesis. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czechia, 30 August–3 September 2021; Hermansky, H., Cernocký, H., Burget, L., Lamel, L., Scharenborg, O., Motlícek, P., Eds.; ISCA: Baixas, France, 2021; pp. 4673–4677. [Google Scholar]
- Neekhara, P.; Hussain, S.; Dubnov, S.; Koushanfar, F.; McAuley, J.J. Expressive Neural Voice Cloning. In Proceedings of the Asian Conference on Machine Learning, ACML 2021, Virtual Event, Singapore, 17–19 November 2021; Balasubramanian, V.N., Tsang, I.W., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2021; Volume 157, pp. 252–267. [Google Scholar]
- Valle, R.; Li, J.; Prenger, R.; Catanzaro, B. Mellotron: Multispeaker Expressive Voice Synthesis by Conditioning on Rhythm, Pitch and Global Style Tokens. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway Township, NJ, USA, 2020; pp. 6189–6193. [Google Scholar]
- Liu, S.; Su, D.; Yu, D. Meta-Voice: Fast Few-Shot Style Transfer for Expressive Voice Cloning Using Meta Learning. arXiv 2021, arXiv:2111.07218. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Kim, J.; Kong, J.; Son, J. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, Virtual Event, Honolulu, HI, USA, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2021; Volume 139, pp. 5530–5540. [Google Scholar]
- Koluguri, N.R.; Park, T.; Ginsburg, B. TitaNet: Neural Model for Speaker Representation with 1D Depth-Wise Separable Convolutions and Global Context. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual, Singapore, 23–27 May 2022; IEEE: Piscataway Township, NJ, USA, 2022; pp. 8102–8106. [Google Scholar]
- Zhou, K.; Sisman, B.; Liu, R.; Li, H. Seen and Unseen Emotional Style Transfer for Voice Conversion with A New Emotional Speech Dataset. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway Township, NJ, USA, 2021; pp. 920–924. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Lopez-Moreno, I. Generalized End-to-End Loss for Speaker Verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway Township, NJ, USA, 2018; pp. 4879–4883. [Google Scholar]
- Cai, W.; Chen, J.; Li, M. Exploring the Encoding Layer and Loss Function in End-to-End Speaker and Language Recognition System. In Proceedings of the Odyssey 2018: The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018; Larcher, A., Bonastre, J.-F., Eds.; ISCA: Baixas, France, 2018; pp. 74–81. [Google Scholar]
- Casanova, E.; Weber, J.; Shulby, C.D.; Júnior, A.C.; Gölge, E.; Ponti, M.A. YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for Everyone. In Proceedings of the International Conference on Machine Learning, ICML 2022, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., Sabato, S., Eds.; PMLR: Mc Kees Rocks, PA, USA, 2022; Volume 162, pp. 2709–2720. [Google Scholar]
- Chien, C.-M.; Lee, H. Hierarchical Prosody Modeling for Non-Autoregressive Speech Synthesis. In Proceedings of the IEEE Spoken Language Technology Workshop, SLT 2021, Shenzhen, China, 19–22 January 2021; IEEE: Piscataway Township, NJ, USA, 2021; pp. 446–453. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27, Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, Quebec, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Yamagishi, J.; Veaux, C.; MacDonald, K. Cstr Vctk Corpus: English Multi-Speaker Corpus for Cstr Voice Cloning Toolkit (Version 0.92); University of Edinburgh, The Centre for Speech Technology Research (CSTR): Edinburgh, UK, 2019. [Google Scholar]
- Zen, H.; Dang, V.; Clark, R.; Zhang, Y.; Weiss, R.J.; Jia, Y.; Chen, Z.; Wu, Y. LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; Kubin, G., Kacic, Z., Eds.; ISCA: Baixas, France, 2019; pp. 1526–1530. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Xie, W.; Zisserman, A. Voxceleb: Large-Scale Speaker Verification in the Wild. Comput. Speech Lang 2020, 60, 101027. [Google Scholar] [CrossRef]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. In Proceedings of the Interspeech 2018, 19th Annual Conference of the International Speech Communication Association, Hyderabad, India, 2–6 September 2018; Yegnanarayana, B., Ed.; ISCA: Baixas, France, 2018; pp. 1086–1090. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MOS | Evaluation Criterion |
|---|---|
| 1.0 | Not clear and intolerable |
| 2.0 | Barely audible and unnatural |
| 3.0 | Moderately clear and natural |
| 4.0 | Very clear and natural |
| 5.0 | Extremely clear and natural |
| SMOS | Evaluation Criterion |
|---|---|
| 1.0 | Not at all similar |
| 2.0 | Slightly similar |
| 3.0 | Moderately similar |
| 4.0 | Very similar |
| 5.0 | Extremely similar |
| Method | Seen Speaker | Unseen Speaker | ||
|---|---|---|---|---|
| MOS | SMOS | MOS | SMOS | |
| Ground Truth Speech | 4.46 ± 0.08 | 4.58 ± 0.07 | 4.46 ± 0.08 | 4.58 ± 0.07 |
| VITS | 4.32 ± 0.07 | 4.42 ± 0.07 | - | - |
| ZS-VITS | 4.28 ± 0.06 | 4.24 ± 0.08 | 4.10 ± 0.09 | 3.54 ± 0.08 |
| EVC | 4.16 ± 0.05 | 4.20 ± 0.08 | 4.08 ± 0.09 | 3.44 ± 0.08 |
| ZSE-VITS | 4.31 ± 0.06 | 4.33 ± 0.06 | 4.22 ± 0.08 | 3.79 ± 0.06 |
| Method | MCD↓ | VDE↓ | GPE↓ | FFE↓ |
|---|---|---|---|---|
| EVC | 49.43 | 21.32 | 2.32 | 22.13 |
| ZS-VITS | 30.12 | 22.74 | 29.53 | 39.56 |
| ZSE-VITS | 8.12 | 9.55 | 0.72 | 9.95 |
| Ref. | Happy | Angry | Sad | Surprise |
|---|---|---|---|---|
| Result | ||||
| Happy | 0.51 | 0.08 | 0.02 | 0.08 |
| Angry | 0.10 | 0.43 | 0.02 | 0.06 |
| Sad | 0.01 | 0.01 | 0.58 | 0.01 |
| Surprise | 0.10 | 0.10 | 0.01 | 0.53 |
| Other | 0.28 | 0.38 | 0.37 | 0.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, L. ZSE-VITS: A Zero-Shot Expressive Voice Cloning Method Based on VITS. Electronics 2023, 12, 820. https://doi.org/10.3390/electronics12040820
Li J, Zhang L. ZSE-VITS: A Zero-Shot Expressive Voice Cloning Method Based on VITS. Electronics. 2023; 12(4):820. https://doi.org/10.3390/electronics12040820
Chicago/Turabian StyleLi, Jiaxin, and Lianhai Zhang. 2023. "ZSE-VITS: A Zero-Shot Expressive Voice Cloning Method Based on VITS" Electronics 12, no. 4: 820. https://doi.org/10.3390/electronics12040820
APA StyleLi, J., & Zhang, L. (2023). ZSE-VITS: A Zero-Shot Expressive Voice Cloning Method Based on VITS. Electronics, 12(4), 820. https://doi.org/10.3390/electronics12040820