
A Benchmark for Dutch End-to-End Cross-Document Event Coreference Resolution



Abstract
:1. Introduction
- [België neemt het op tegen Kroatië.] EN: Belgium takes on Croatia.
- [De laatste groepswedstrijd van de Rode Duivels.] wordt maar beter snel vergeten EN: The last group game of the Red Devils should better be forgotten.
2. Related Work
2.1. Resources
2.2. Methodology
3. Data
3.1. EventDNA
- 3.
- [[Moordenaar Kitty Van Nieuwenhuyse] komt niet vrij.] EN: Kitty Van Nieuwenhuyse’s murderer will not be released.
- 4.
- [De finale van het WK voetbal 2022.] EN: The final of the 2022 World Cup.
3.2. ENCORE
- 5.
- [[Moordenaar Kitty Van Nieuwenhuyse.] komt niet vrij] EN: Kitty Van Nieuwenhuyse’s murderer will not be released.
- 6.
- [De [finale] van het WK voetbal 2022.] EN: The final of the 2022 World Cup.
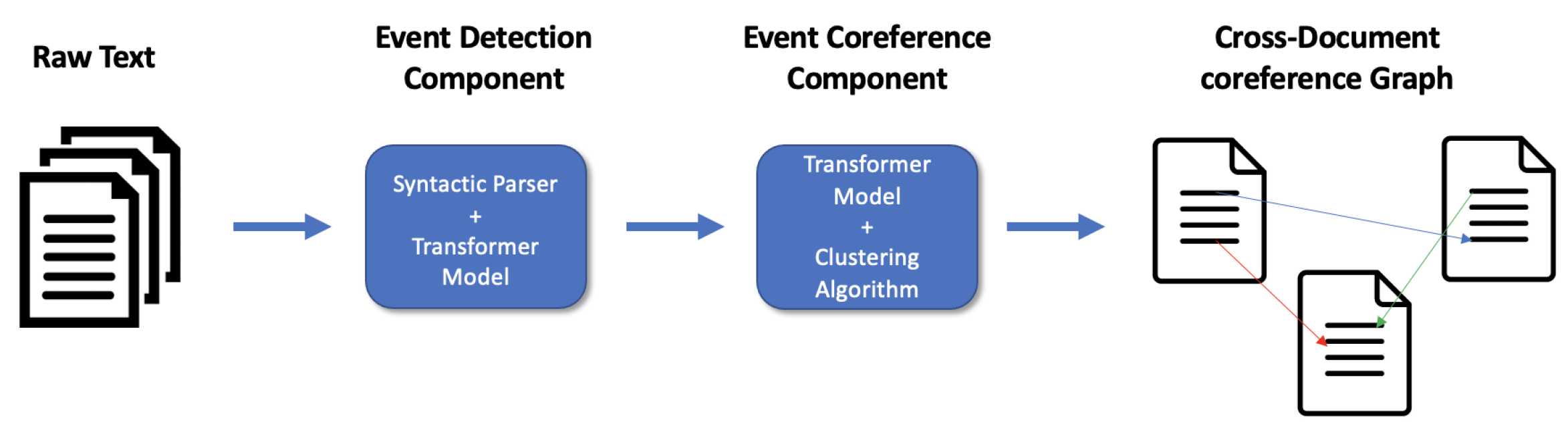
4. Experiments and Methodology
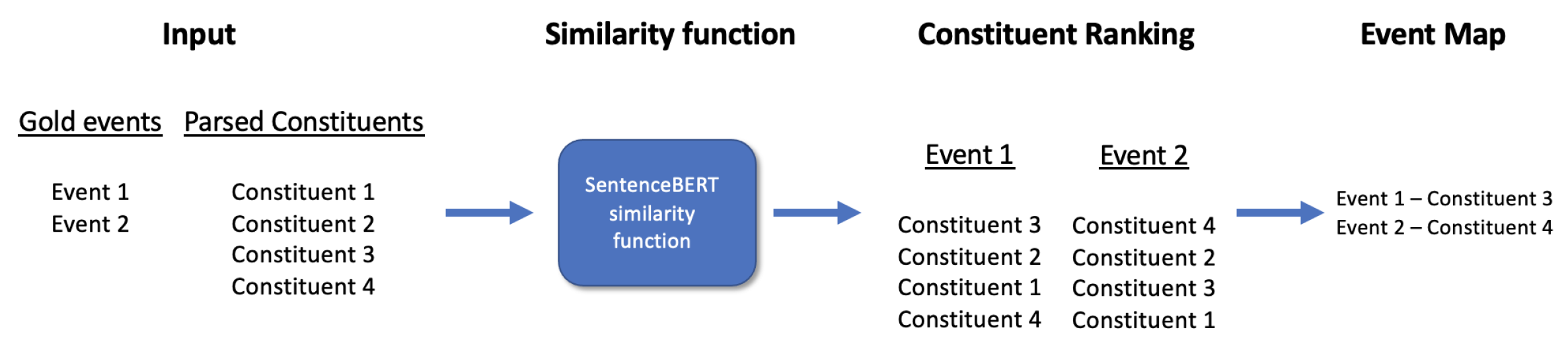
4.1. Event Extraction Model
4.1.1. Selection of Candidate Events
- 7.
- De wapenstilstand van 11 November maakte een einde aan de Eerste wereldoorlog. EN: The truce on the eleventh of November ended the first world war.
4.1.2. Classification of Candidate Events
- 8.
- [vakbond legt het werk neer op 21 December.] EN: Union will strike on 21 December.
- 9.
- [De nieuwe staking] doet denken aan [de vakbonsacties van December vorig jaar] EN: The new strike is reminiscent of the actions in December last year.
4.2. Event Coreference Model
4.3. Experimental Setup and Evaluation
4.3.1. Data and Upper Bound
4.3.2. Metrics
MUC
B3
CEAF
LEA
5. Results
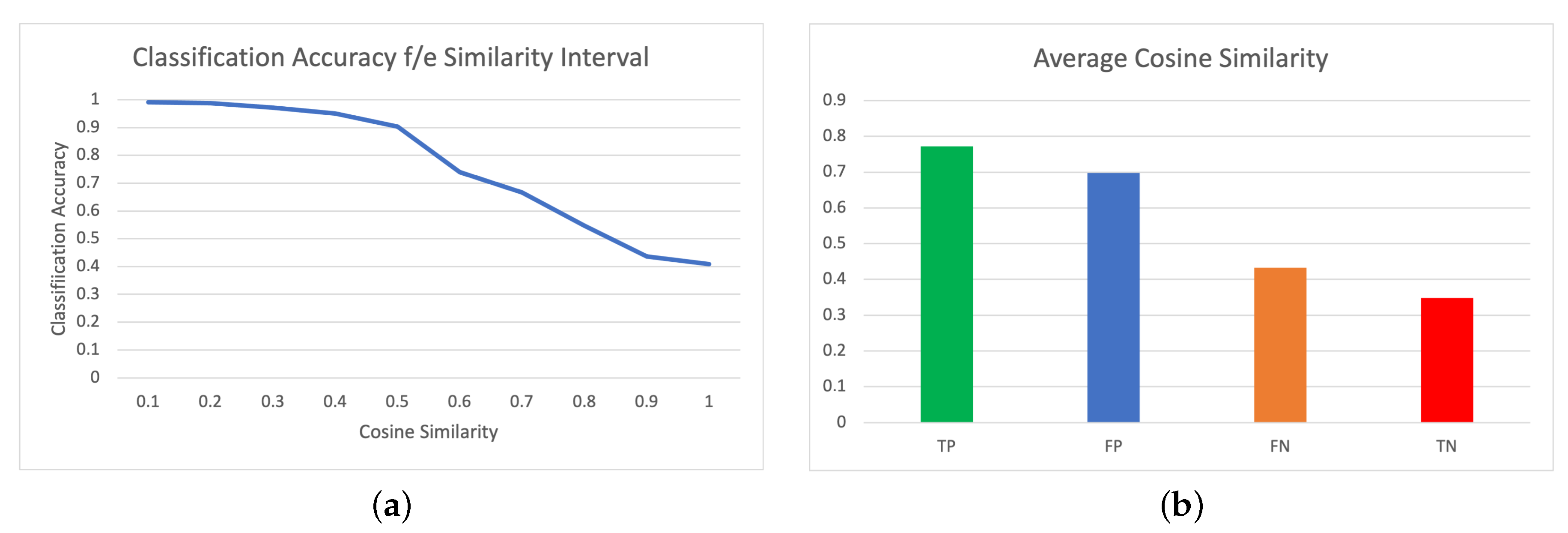
6. Analysis and Discussion
6.1. Event Detection Component: The Effect of Event Extraction Filtering
- 10.
- Fouad Belkacem zegt dat hij zich zal verzetten tegen de uitspraak. EN: Fouad Belkacem says he will resist the verdict.
6.2. Event Coreference Component: The Importance of Lexical Similarity in Transformer Models
- 11. (a)
- De Franse president Macron ontmoette de Amerikaanse president voor de eerste keer vandaag. EN: The French president Macron met with the American president for the first time today.
- (b)
- Frans President Sarkozy ontmoette de Amerikaanse president. EN: French President Sarkozy met the American president.
- 12. (a)
- De partij van Amerikaans president Trump verloor zwaar vandaag. EN: American president Trump’s party lost heavily today.
- (b)
- Trump lacht groen bij de midterms. EN: Sour laughter for Trump at the midterms.
7. Ablation Studies
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kang, Y.; Cai, Z.; Tan, C.W.; Huang, Q.; Liu, H. Natural language processing (NLP) in management research: A literature review. J. Manag. Anal. 2020, 7, 139–172. [Google Scholar] [CrossRef]
- Humphreys, K.; Gaizauskas, R.; Azzam, S. Event coreference for information extraction. In Proceedings of the ACL/EACL Workshop on Operational Factors in Practical, Robus Anaphora Resolution for Unrestricted Texts, Madrid, Spain, 11 July 1997; pp. 75–81. [Google Scholar]
- Ji, H.; Grishman, R. Knowledge base population: Successful approaches and challenges. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 1148–1158. [Google Scholar]
- Narayanan, S.; Harabagiu, S. Question Answering Based on Semantic Structures; Technical Report; International Computer Science Inst: Berkeley, CA, USA, 2004. [Google Scholar]
- De Marneffe, M.C.; Rafferty, A.N.; Manning, C.D. Finding contradictions in text. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 15–20 June 2008; pp. 1039–1047. [Google Scholar]
- Lu, J.; Ng, V. Conundrums in event coreference resolution: Making sense of the state of the art. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 1368–1380. [Google Scholar]
- Lu, J.; Ng, V. Event Coreference Resolution: A Survey of Two Decades of Research. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; International Joint Conferences on Artificial Intelligence Organization: Stockholm, Sweden, 2018; pp. 5479–5486. [Google Scholar] [CrossRef]
- Alsaedi, N.; Burnap, P.; Rana, O. Automatic summarization of real world events using twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Cologne, Germany, 17–20 May 2016; Volume 10, pp. 511–514. [Google Scholar]
- Kompan, M.; Bieliková, M. Content-based news recommendation. In LNBIP; Lecture Notes in Business Information Processing; Springer: Berlin/Heidelberg, Germany, 2010; Volume 61, pp. 61–72. [Google Scholar] [CrossRef]
- Pradhan, S.S.; Ramshaw, L.; Weischedel, R.; MacBride, J.; Micciulla, L. Unrestricted coreference: Identifying entities and events in ontonotes. In Proceedings of the International Conference on Semantic Computing (ICSC), Irvine, CA, USA, 17–19 September 2007; pp. 446–453. [Google Scholar] [CrossRef]
- Taylor, A.; Marcus, M.; Santorini, B. The Penn treebank: An overview. In Treebanks; Springer: Dordrecht, The Netherlands, 2003; pp. 5–22. [Google Scholar]
- Kingsbury, P.R.; Palmer, M. From treebank to propbank. In Proceedings of the Language Resources and Evaluation LREC, Las Palmas, Spain, 29–31 May 2002; pp. 1989–1993. [Google Scholar]
- Kingsbury, P.; Palmer, M. Propbank: The next level of treebank. In Proceedings of the Treebanks and lexical Theories, Växjö, Sweden, 14–15 November 2003; Volume 3. [Google Scholar]
- ACE English Annotation Guidelines for Events (v5.4.3); Linguistics Data Consortium: Philadelphia, PA, USA, 2008.
- Mitamura, T.; Yamakawa, Y.; Holm, S.; Song, Z.; Bies, A.; Kulick, S.; Strassel, S. Event Nugget Annotation: Processes and Issues. In Proceedings of the 3rd Workshop on EVENTS: Definition, Detection, Coreference and Representation, Denver, CO, USA, 4 June 2015; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 66–76. [Google Scholar] [CrossRef]
- Cybulska, A.; Vossen, P. Using a sledgehammer to crack a nut? Lexical diversity and event coreference resolution. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 4545–4552. [Google Scholar]
- Bejan, C.; Harabagiu, S. Unsupervised Event Coreference Resolution with Rich Linguistic Features. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 11–16 July 2010; pp. 1412–1422. [Google Scholar] [CrossRef]
- Song, Z.; Bies, A.; Strassel, S.; Riese, T.; Mott, J.; Ellis, J.; Wright, J.; Kulick, S.; Ryant, N.; Ma, X. From Light to Rich ERE: Annotation of Entities, Relations, and Events. In Proceedings of the 3rd Workshop on EVENTS at the NAACL-HLT, Denver, CO, USA, 4 June 2015; ACL: Denver, CO, USA, 2015; pp. 89–98. [Google Scholar]
- Eirew, A.; Cattan, A.; Dagan, I. WEC: Deriving a large-scale cross-document event coreference dataset from Wikipedia. arXiv 2021, arXiv:2104.05022. [Google Scholar]
- Minard, A.L.; Speranza, M.; Urizar, R.; van Erp, M.; Schoen, A.; van Son, C. MEANTIME, the NewsReader Multilingual Event and Time Corpus. In Proceedings of the 10th Language Resources and Evaluation Conference (LREC), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portorož, Slovenia, 2016; p. 6. [Google Scholar]
- Rahman, A.; Ng, V. Supervised models for coreference resolution. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 968–977. [Google Scholar]
- Chen, C.; Ng, V. SinoCoreferencer: An End-to-End Chinese Event Coreference Resolver. Lrec 2014, 2, 4532–4538. [Google Scholar]
- Cybulska, A.; Vossen, P. Translating Granularity of Event Slots into Features for Event Coreference Resolution. In Proceedings of the 3rd Workshop on EVENTS: Definition, Detection, Coreference, and Representation, Denver, CO, USA, 4 June 2015; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Meyers, A.; Grishman, R. New York University 2016 System for KBP Event Nugget: A Deep Learning Approach. In Proceedings of the TAC, Gaithersburg, MD, USA, 14–15 November 2016; p. 7. [Google Scholar]
- De Langhe, L.; De Clercq, O.; Hoste, V. Investigating Cross-Document Event Coreference for Dutch. In Proceedings of the Fifth Workshop on Computational Models of Reference, Anaphora and Coreference, Gyeongju, Republic of Korea, 16–17 October 2022. [Google Scholar]
- Joshi, M.; Levy, O.; Weld, D.S.; Zettlemoyer, L. BERT for coreference resolution: Baselines and analysis. arXiv 2019, arXiv:1908.09091. [Google Scholar]
- Kantor, B.; Globerson, A. Coreference resolution with entity equalization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 673–677. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Lu, J.; Ng, V. Learning Antecedent Structures for Event Coreference Resolution. In Proceedings of the Machine Learning and Applications (ICMLA), 2017 16th IEEE International Conference, Cancun, Mexico, 18–21 December 2017; pp. 113–118. [Google Scholar]
- Raghunathan, K.; Lee, H.; Rangarajan, S.; Chambers, N.; Surdeanu, M.; Jurafsky, D.; Manning, C. A Multi-Pass Sieve for Coreference Resolution. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; Association for Computational Linguistics: Cambridge, MA, USA, 2010; pp. 492–501. [Google Scholar]
- Lu, J.; Ng, V. Event Coreference Resolution with Multi-Pass Sieves 2016. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; p. 8. [Google Scholar]
- Liu, Z.; Araki, J.; Hovy, E.H.; Mitamura, T. Supervised Within-Document Event Coreference using Information Propagation. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 4539–4544. [Google Scholar]
- Choubey, P.K.; Huang, R. Event Coreference Resolution by Iteratively Unfolding Inter-Dependencies Among Events; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 2124–2133. [Google Scholar] [CrossRef]
- Lu, J.; Venugopal, D.; Gogate, V.; Ng, V. Joint inference for event coreference resolution. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 3264–3275. [Google Scholar]
- Chen, C.; Ng, V. Joint Inference over a Lightly Supervised Information Extraction Pipeline: Towards Event Coreference Resolution for Resource-Scarce Languages. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AR, USA, 12–17 February 2016; pp. 2913–2920. [Google Scholar]
- Araki, J.; Mitamura, T. Joint Event Trigger Identification and Event Coreference Resolution with Structured Perceptron. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 2074–2080. [Google Scholar] [CrossRef]
- Colruyt, C.; De Clercq, O.; Desot, T.; Hoste, V. EventDNA: A dataset for Dutch news event extraction as a basis for news diversification. Lang. Resour. Eval. 2022, 1–33. [Google Scholar] [CrossRef]
- Vermeulen, J. newsDNA: Promoting News Diversity: An Interdisciplinary Investigation into Algorithmic Design, Personalization and the Public Interest (2018–2022). In Proceedings of the ECREA 2018 Pre-Conference on Information Diversity and Media Pluralism in the Age of Algorithms, Lugano, Switzerland, 31 October 2018. [Google Scholar]
- De Langhe, L.; De Clercq, O.; Hoste, V. Constructing a cross-document event coreference corpus for Dutch. Lang. Resour. Eval. 2022, 1–30. [Google Scholar] [CrossRef]
- Cybulska, A.; Vossen, P. Guidelines for ECB+ Annotation of Events and Their Coreference; Technical Report NWR-2014-1; VU University Amsterdam: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Desot, T.; De Clercq, O.; Hoste, V. Event Prominence Extraction Combining a Knowledge-Based Syntactic Parser and a BERT Classifier for Dutch. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Varna, Bulgaria, 1–3 September 2021; pp. 346–357. [Google Scholar]
- Van Noord, G.J. At Last Parsing Is Now Operational. In Proceedings of the Actes de la 13ème Conférence sur le Traitement Automatique des Langues Naturelles, Leuven, Belgium, 30 June 2006. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Lin, C.; Miller, T.; Dligach, D.; Bethard, S.; Savova, G. A BERT-based universal model for both within-and cross-sentence clinical temporal relation extraction. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MI, USA, 7 June 2019; pp. 65–71. [Google Scholar]
- Chan, Y.H.; Fan, Y.C. A recurrent BERT-based model for question generation. In Proceedings of the 2nd Workshop on Machine Reading for Question Answering, Hong Kong, China, 4 November 2019; pp. 154–162. [Google Scholar]
- De Vries, W.; van Cranenburgh, A.; Bisazza, A.; Caselli, T.; van Noord, G.; Nissim, M. Bertje: A dutch bert model. arXiv 2019, arXiv:1912.09582. [Google Scholar]
- Oostdijk, N.; Reynaert, M.; Hoste, V.; Schuurman, I. The Construction of a 500-Million-Word Reference Corpus of Contemporary Written Dutch; Springer Publishing Company Incorporated: Berlin/Heidelberg, Germany, 2013; pp. 219–247. [Google Scholar] [CrossRef]
- Ordelman, R.; de Jong, F.; van Hessen, A.; Hondorp, G. TwNC: A Multifaceted Dutch News Corpus. ELRA Newsl. 2007, 12, 4–7. [Google Scholar]
- Allan, J. Topic Detection and Tracking; Kluwer Academic Publishers: Norwell, MA, USA, 2002; pp. 1–16. [Google Scholar]
- Allan, J. Topic Detection and Tracking: Event-based Information Organization; Springer Publishing Company Incorporated: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Boykin, S.; Merlino, A. Machine learning of event segmentation for news on demand. Commun. ACM 2000, 43, 35–41. [Google Scholar] [CrossRef]
- Chen, T.; He, T. Xgboost: Extreme Gradient Boosting. R Package Version 0.4-2. 2015, Volume 1. Available online: https://cran.microsoft.com/snapshot/2017-12-11/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 13 January 2023).
- Chang, K.W.; Samdani, R.; Rozovskaya, A.; Sammons, M.; Roth, D. Illinois-Coref: The UI system in the CoNLL-2012 shared task. In Proceedings of the Joint Conference on EMNLP and CoNLL-Shared Task, Jeju Island, Republic of Korea, 12–14 July 2012; pp. 113–117. [Google Scholar]
- Vilain, M.; Burger, J.D.; Aberdeen, J.; Connolly, D.; Hirschman, L. A model-theoretic coreference scoring scheme. In Proceedings of the Sixth Message Understanding Conference (MUC-6), Columbia, MA, USA, 6–8 November 1995. [Google Scholar]
- Moosavi, N.S.; Strube, M. Which coreference evaluation metric do you trust? a proposal for a link-based entity aware metric. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 632–642. [Google Scholar]
- Pradhan, S.; Luo, X.; Recasens, M.; Hovy, E.; Ng, V.; Strube, M. Scoring coreference partitions of predicted mentions: A reference implementation. In Proceedings of the Conference Association for Computational Linguistics, Baltimore, MA, USA, 22–27 June 2014; Volume 2014, p. 30. [Google Scholar]
- Luo, X. On coreference resolution performance metrics. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 25–32. [Google Scholar]
- Stoyanov, V.; Gilbert, N.; Cardie, C.; Riloff, E. Conundrums in Noun Phrase Coreference Resolution: Making Sense of the State-of-the-Art. Differences 2009, 656–664. [Google Scholar] [CrossRef]
- Poot, C.; van Cranenburgh, A. A benchmark of rule-based and neural coreference resolution in Dutch novels and news. arXiv 2020, arXiv:2011.01615. [Google Scholar]
- Colruyt, C. Event Extraction: What Is It and What’s Going on (14/03 Draft). 2018. Available online: https://www.netowl.com/what-is-event-extraction (accessed on 13 January 2023).
- Atefeh, F.; Khreich, W. A survey of techniques for event detection in twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Wang, L.; Cardie, C.; Marchetti, G. Socially-informed timeline generation for complex events. arXiv 2016, arXiv:1606.05699. [Google Scholar]
- Gottschalk, S.; Demidova, E. EventKG–the hub of event knowledge on the web–and biographical timeline generation. Semant. Web 2019, 10, 1039–1070. [Google Scholar] [CrossRef]
- Saggion, H. Automatic summarization: An overview. Rev. Fr. Aise Linguist. Appl. 2008, 13, 63–81. [Google Scholar] [CrossRef]
- De Langhe, L.; De Clercq, O.; Hoste, V. Towards Fine (r)-grained Identification of Event Coreference Resolution Types. Comput. Linguist. Neth. J. 2022, 12, 183–205. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C.D. What does bert look at? an analysis of bert’s attention. arXiv 2019, arXiv:1906.04341. [Google Scholar]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in pre-training distributed word representations. arXiv 2017, arXiv:1712.09405. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event Type | Event Subtype |
|---|---|
| Life | beBorn |
| Life | die |
| Life | divorce |
| Life | injure |
| Life | marry |
| EventDNA | ENCORE | |
|---|---|---|
| Documents | 1773 | 1015 |
| Tokens | 106,106 | 849,555 |
| Events | 7409 | 15,407 |
| Training | Development | Test | |
|---|---|---|---|
| EventDNA | 5927 | 741 | 741 |
| ENCORE | 10,785 | 2312 | 23,12 |
| Detection Component | Coreference Component | CONLL F1 | LEA F1 |
|---|---|---|---|
| CRF | XGBoost | 0.17 | 0.04 |
| CRF | BERTje | 0.21 | 0.05 |
| BERTje | XGBoost | 0.22 | 0.06 |
| BERTje | BERTje | 0.27 | 0.08 |
| CRF | BERTje | |||||
|---|---|---|---|---|---|---|
| CONLL | LEA | Events | CONLL | LEA | Events | |
| No_Pruning | 0.22 | 0.05 | 11089 | 0.27 | 0.08 | 10211 |
| Remove single-token events | 0.26 | 0.07 | 9581 | 0.29 | 0.10 | 9038 |
| Remove speech events | 0.28 | 0.07 | 7436 | 0.32 | 0.13 | 7015 |
| Remove background events | 0.31 | 0.13 | 5722 | 0.34 | 0.15 | 5813 |
| Remove background + speech | 0.35 | 0.20 | 5008 | 0.39 | 0.24 | 4487 |
| Gold mapped events | 0.38 | 0.22 | 1968 | 0.46 | 0.27 | 2003 |
| Model and Configuration | CONLL | LEA |
|---|---|---|
| CRF | 0.22 | 0.05 |
| BERTje | 0.27 | 0.08 |
| CRF | 0.29 | 0.10 |
| BERTje | 0.34 | 0.16 |
| CRF | 0.28 | 0.08 |
| BERTje | 0.37 | 0.18 |
| ENCORE | EventDNA + ENCORE | |||||
|---|---|---|---|---|---|---|
| CONLL | LEA | # Events | CONLL | LEA | # Events | |
| No_Pruning | 0.34 | 0.16 | 6481 | 0.37 | 0.18 | 5326 |
| Remove speech events | 0.36 | 0.18 | 5421 | 0.41 | 0.20 | 4750 |
| Remove background events | 0.40 | 0.21 | 4809 | 0.43 | 0.22 | 4750 |
| Remove background + Speech | 0.44 | 0.25 | 4677 | 0.46 | 0.26 | 4159 |
| Gold mapped events | 0.52 | 0.32 | 2061 | 0.54 | 0.36 | 2183 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Langhe, L.; Desot, T.; De Clercq, O.; Hoste, V. A Benchmark for Dutch End-to-End Cross-Document Event Coreference Resolution. Electronics 2023, 12, 850. https://doi.org/10.3390/electronics12040850
De Langhe L, Desot T, De Clercq O, Hoste V. A Benchmark for Dutch End-to-End Cross-Document Event Coreference Resolution. Electronics. 2023; 12(4):850. https://doi.org/10.3390/electronics12040850
Chicago/Turabian StyleDe Langhe, Loic, Thierry Desot, Orphée De Clercq, and Veronique Hoste. 2023. "A Benchmark for Dutch End-to-End Cross-Document Event Coreference Resolution" Electronics 12, no. 4: 850. https://doi.org/10.3390/electronics12040850
APA StyleDe Langhe, L., Desot, T., De Clercq, O., & Hoste, V. (2023). A Benchmark for Dutch End-to-End Cross-Document Event Coreference Resolution. Electronics, 12(4), 850. https://doi.org/10.3390/electronics12040850