
Optimized and Efficient Color Prediction Algorithms Using Mask R-CNN

Abstract
:1. Introduction
- The clustering algorithms are not exclusively designed for color prediction. They also excel in various machine learning applications;
- The K-value is not easy to predict in K-means algorithm, which does not go well with global clusters. In addition, the time complexity of K-means increases if the datasets are bigger;
- Mini batch K-means algorithm has lower accuracy than K-means;
- Time complexity is a major disadvantage in mean shift algorithm;
- GMM takes more time to converge and hence slower than K-means;
- Fuzzy C-means requires greater number of iterations for better results.
- A color prediction model called DCPCM that is exclusively designed by uniquely categorizing HSV domain values into 15 different color classes, to be used only for color prediction and not for any other purpose. The main aim of the given model is to reduce the color spectrum into 15 commonly used colors, thereby reducing the complexity and the runtime.
- Two new algorithms called AVW and PXS to selectively extract pixels from an image, using precomputed formulae, thereby reducing the runtime and maintaining the accuracy;
- Integration of Mask-RCNN algorithm with the proposed techniques for identifying the objects in the image prior to pixel extraction and dominant color prediction;
- Creation of benchmark data set with 200 images of single object, multi-object, uniformly colored, multicolored and of various sizes, to test the proposed algorithms and compare them with the existing clustering techniques stated above.
2. System Architecture
3. Dominant Color Prediction Color Map (DCPCM) Model
4. AVW and PXS Algorithms
4.1. Preprocessing Required for AVW and PXS Algorithms
- Masked Color, represents the RGB values of the mask chosen by Mask R-CNN, for the current object;
- Masked_Image, is the image obtained after application of the respective mask, Mask R-CNN, to the Original_Image;
- OriginalImageData, is the matrix that stores the pixel representations of the Original_Image in terms of RGB channels.
- MaskImageData, is the matrix that stores the pixel representations of the Masked_Image in terms of RGB channels.
- Color_Set, is an array that stores the predetermined colors, by allocations of an index to each of the 15 colors and represented as [CSET]1*15. This notation implies that the Color_Set, is a 1*15 matrix i.e., a 1-D array that stores all the 15 colors. [CSET] = [“Red”, “Orange”, “Yellow”, “Yellow-Green”, “Green”, “Green-Cyan”, “Cyan”, “Cyan-Blue”, “Blue”, “Violet”, “Magenta”, “Black”, “Pink”, “White”, “Gray”].
- R2H (r, g, b), represents a function that takes in the RGB values of a pixel and returns the respective HSV value.
- C_P (h, s, v), represents a function that takes in the HSV values of a pixel and returns the respective color class. This pertains to implementation of the DCPCM model, discussed in the previous section.
- [Gscale], is the grayscale representation of an original image [Io].
- Edgecanny (Am), represents the canny edge detector function, discussed previously in Section 1. It gives us the APW i.e., average number of pixels contributing to edges in the given matrix Am, where Am is the resultant output, after the [Gscale] passes through the edge_filter.
- Edge_filter filters out the pixels contributing to the unmasked portion of the current object. Since the uniformity is based on the edges, the pixel contributing to the unmasked portion inside the bounding box is converted to “white”. This operation will exclude the unmasked portion for uniformity prediction while maintaining the null spaces in the input matrix.
4.2. All-Pixel Approach
- Step-1:
- Initialize array A to zero.
- Step-2:
- Iterate through the current_object and increment the respective color of the pixel in [A], if the pixel is inside the bounding box of the current_object and the respective pixel of the masked image is equal to the Masked_Color.
- Step-3:
- Iterate through [A] and find the color with the maximum count which gives us the Dc (dominant color) of the image. Equation (9), represents the mathematical form of Step-3.
4.3. Average Windowing (AVW) Algorithm
- Step-1:
- Initialize [A] to zero.
- Step-2:
- Convert the input image into grayscale and store the data into [Gscale].
- Step-3:
- Iterate through the image and store the pixels from the OriginalImageData that contribute to the masked portion of the MaskedImageData and are inside the bounding box coordinates of the current_object in a list (L) represented in Equation (10).
- Step-4:
- Perform edge detection and predict “f” (Detailed in Section 4.3.1).
- Step-5:
- Iterate through the list and compute the average of the pixels in each window and increment the respective count in [A]. The mathematical representation of [A], and the result array [K], for AVW are shown in Equations (11) and (12). The representation of average of the HSV values for a particular window is shown in Equation (13).
- Step-6:
- Iterate through [A], and find the color with the maximum count, equivalent to the Dc (dominant color) of the image. The extraction of dominant color from the Color-set, is represented in Equation (14).
4.3.1. Predicting Window Size (“f”)
4.3.2. Pseudo Code of AVW
| AVW (L,f): //L is the list containing the extracted pixels of the object and “f” is the window size j = 0 while “j” < length (L) var h, s, v <- (0,0,0) //Defining variables h, s and v. for every “f” pixels. //Loop runs “f” times h, s, v <- (h + L[j][0], s + L[j][1], v + L[j][2]) increment “j” end for //At this point, h, s, and v variables contains sum of the current “f” pixel values. var h_avg,s_avg,v_avg <- (avg(h),avg(s),avg(v)) var l <- color prediction (h_avg,s_avg,v_avg) //l is the color predicted for the given values of h_avg,s_avg and v_avg. A[l]++//A is the array containing count of each of the 15 colors. At this step, we are inceasing the count of the color class “l” in the array A. end while return A |
4.3.3. Corner Cases for AVW
- Case-1:
- Object is completely uniform: In this case, the average of all the pixels in the object will give us the dominant color. So, “f” can be as high as possible.Proof: According to Equation (16),Image is completely uniform ⇒APW = 0.So, APW = 0 ⇒f→∞.
- Case-2:
- Object is 50% uniform: This is the case where every alternate pixel is an edge pixel. Hence, the average of two pixels should be considered for color prediction if according to the assumption that every window should have one edge pixel.Proof:Image is 50% uniform ⇒ APW = 50.Hence, f = 2.
- Case-3:
- Uniformity is above 50%: When uniformity is above 50%, the value of f tends to decrease below 2. Since the window size is a positive integer; “f” becomes 1 for uniformity greater than 50%. Hence, the algorithm changes into the all-pixel approach.
- Proof:
- Since f = 1, every window contains only one pixel whose average results in the same value. Hence, all pixels are considered for prediction and the threshold of APW for implementing the AVW algorithm is 50. For all other values, the algorithm turns into the all-pixel approach.
4.4. Pixel Skip (PXS) Algorithm
- Step-1:
- Initialize [A] to zero.
- Step-2:
- Convert the image into grayscale and store the data into [Gscale].
- Step-3:
- Iterate through the image and store the pixels from the OriginalImageData that contribute to the masked portion of the MaskedImageData and are inside the bounding box coordinates of current_object in a list(L) shown in Equation (17).
- Step-4:
- Perform edge detection and predict the PXS factor “S”. The number of pixels skipped is considered to be (S-2).
- Step-5:
- Let “p” be the current pixel. If [p] = [Mc] and C_P(p) = C_P (p − S + 1), skip the middle pixels assuming that they are of the same color and increment the count of the respective color by “S”. If, C_P(p) ≠ C_P (p − S + 1), skip the middle pixels without considering them for color prediction. If the pixel does not belong to the masked region, discard the current pixel and move to the next pixel and repeat the same step. The mathematical representation of [A] and [K] for PXS is shown in Equations (18) and (19).
- Step-6:
- Iterate through [A] and find the color with the maximum count that gives us the Dc (dominant color) of the image. The extraction of dominant color from the Color_set, is shown in Equation (20).
4.4.1. Predicting Skip Size (S)
4.4.2. Pseudo Code for PXS
| def.PXS (L,s): //L is the list containing the extracted pixels of the object and s is the skip size for “j” in length(L) var x = color_prediction(L[j]) var y = color_prediction(L[j + s-1]) if x = y, A[x] = A[x] + s else A[x]++ A[y]++ J = j + s end for return A |
4.4.3. Corner Cases
- Case-1:
- Object is completely uniform: In this case, if the first and last pixel colors are equal for an object, then the dominant color will be of the first and last pixel color; else the dominant color will be either first or last pixel color. So, S →∞.Proof:. (According to Equation (21))Image is completely uniform ⇒APW = 0.So, APW = 0 ⇒ S → ∞.
- Case-2:
- CUniformity is greater than or equal to 50%: When uniformity is greater than or equal to 50%, the value of “S” tends to be a negative value. Since, the number of pixels to be skipped is a non-negative integer (according to Equation (22)), (S-2) becomes 0, for uniformity greater than or equal to 50%. Hence, the algorithm transitions into the all-pixel approach.Proof: Since (S-2) = 0, every pixel is compared with the corresponding pixel. If the compared pixels belong to the same or different color each pixel will be considered for maximum color prediction of an object. Hence, the threshold of APW for implementation of the PXS algorithm is 50.
5. Experimental Results
6. Comparisons of Color Prediction Schemes
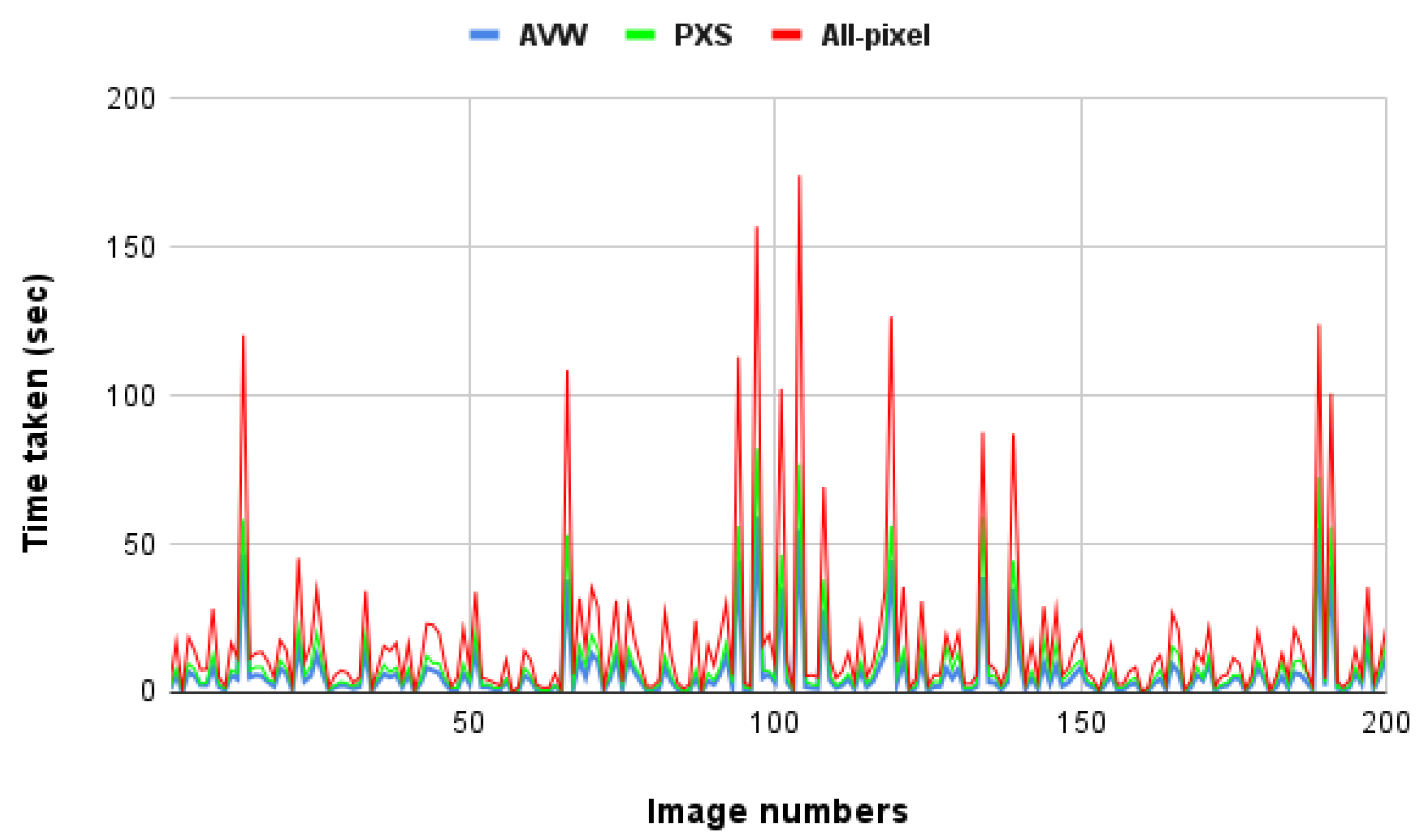
6.1. All-Pixel Approach
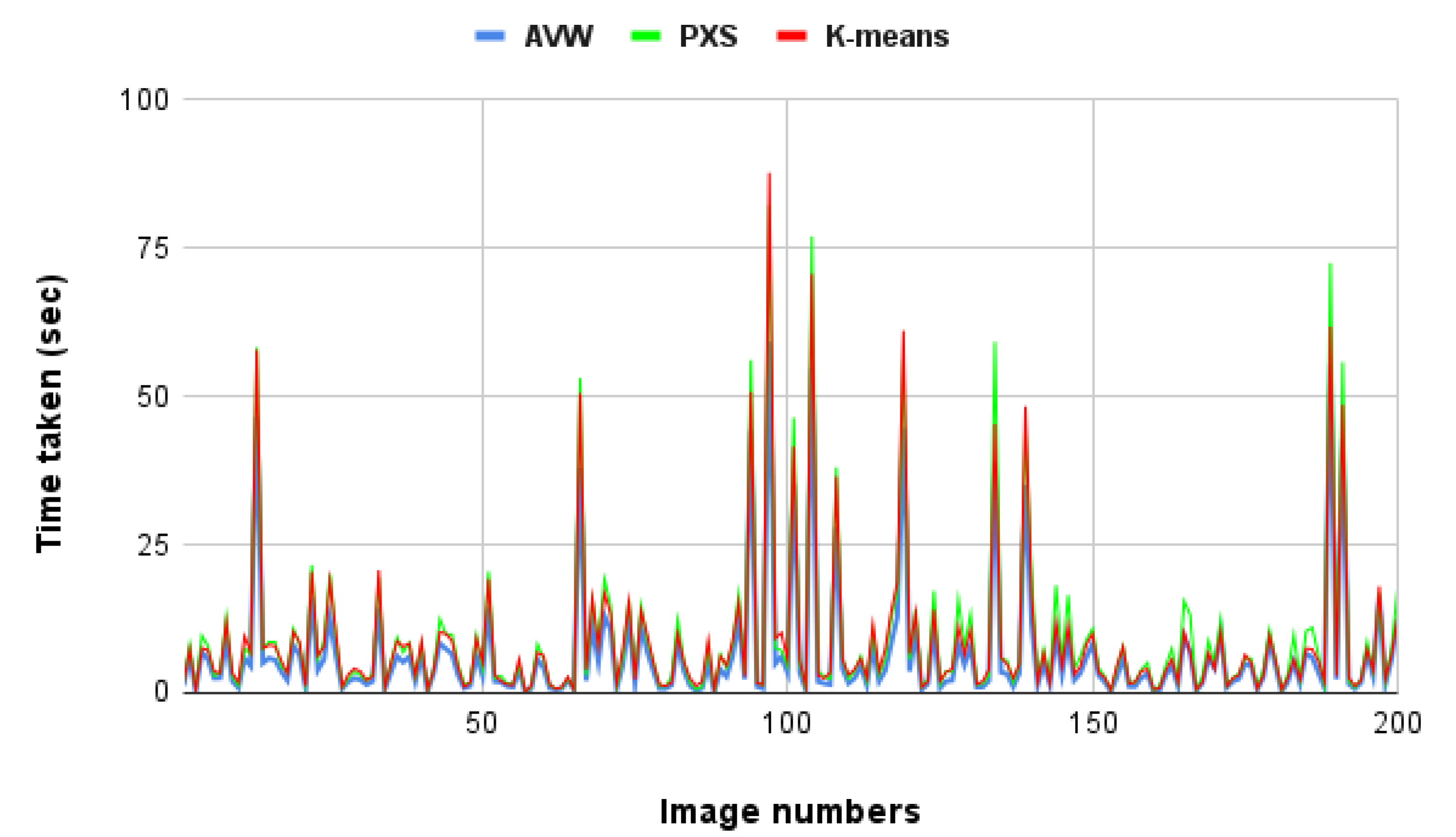
6.2. K-Means Clustering
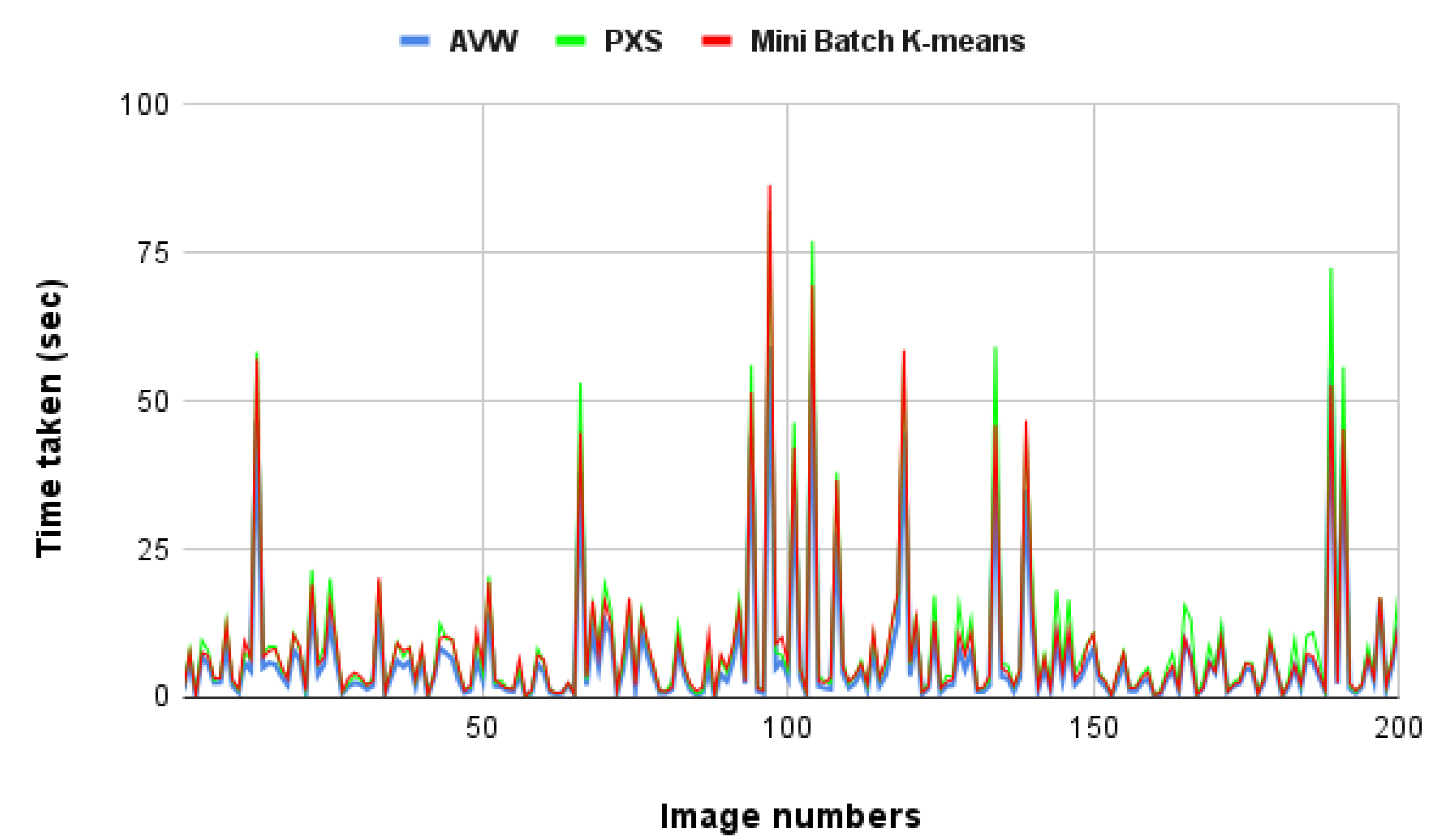
6.3. Mini Batch K-Means Algorithm
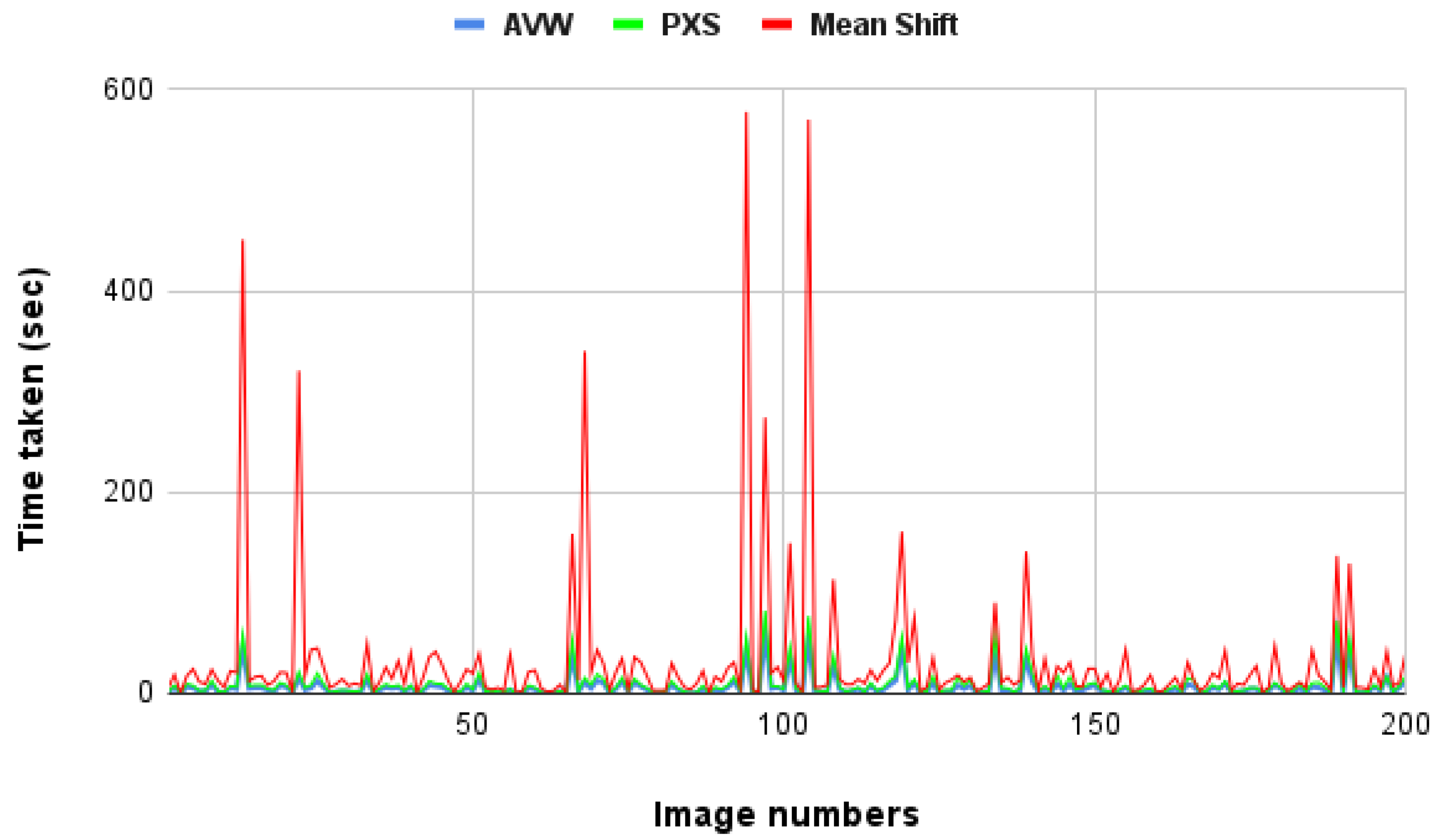
6.4. Mean-Shift Clustering
6.5. Gaussian Mixture Model
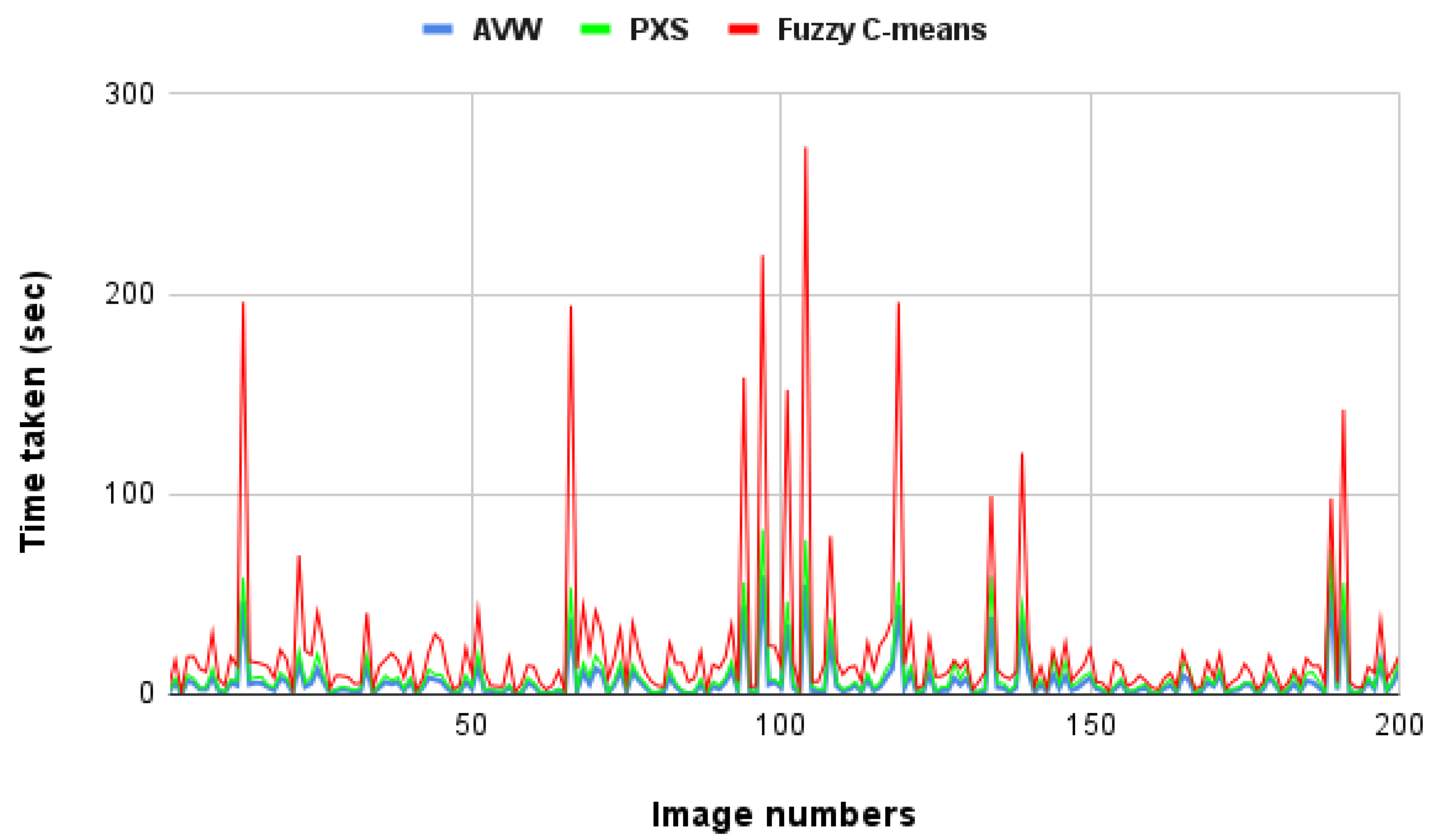
6.6. Fuzzy C-Means
- AVW and PXS algorithms have higher accuracies compared to all other appraised algorithms;
- PXS algorithm is the most accurate among all the other clustering algorithms;
- AVW algorithm has the highest reduction in time along with decent prediction accuracy;
- Negative values of “reduction in time” for mean shift and fuzzy C-means algorithms imply that they require much longer than the all-pixel approach for the color prediction task.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, J.H.; Kim, B.G.; Roy, P.P.; Jeong, D.M. Efficient Facial Expression Recognition Algorithm Based on Hierarchical Deep Neural Network Structure. IEEE Access 2019, 7, 41273–41285. [Google Scholar] [CrossRef]
- Jeong, D.; Kim, B.-G.; Dong, S.-Y. Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition. Sensors 2020, 20, 1936. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.-H.; Hong, G.-S.; Kim, B.-G.; Dogra, D.P. deepGesture: Deep learning-based gesture recognition scheme using motion sensors. Displays 2018, 55, 38–45. [Google Scholar] [CrossRef]
- Manju, K.; Aditya, G.; Ruben, G.C.; Verdú, E. Gesture Recognition of RGB and RGB-D Static Images using Convolutional Neural Networks. Int. J. Interact. Multimed. Artif. Intell. 2019, 5, 22–27. [Google Scholar] [CrossRef]
- Qummar, S.; Khan, F.G.; Shah, S.; Khan, A.; Shamshirband, S.; Rehman, Z.U.; Khan, I.A.; Jadoon, W. A Deep Learning Ensemble Approach for Diabetic Retinopathy Detection. IEEE Access 2019, 7, 150530–150539. [Google Scholar] [CrossRef]
- Shamshirband, S.; Mahdis, F.; Dehzangi, A.; Chronopoulos, A.T.; Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems: Taxonomies, challenges, and open issues. J. Biomed. Inform. 2021, 113, 103627. [Google Scholar] [CrossRef]
- Pillai, M.S.; Chaudhary, G.; Khari, M.; Crespo, R.G. Real-time image enhancement for an automatic automobile accident detection through CCTV using deep learning. Soft Comput. 2021, 25, 11929–11940. [Google Scholar] [CrossRef]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Procedia Comput. Sci. 2018, 132, 1706–1717, ISSN-1877-0509. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Srisuk, S.; Suwannapong, C.; Kitisriworapan, S.; Kaewsong, A.; Ongkittikul, S. Performance Evaluation of Real-Time Object Detection Algorithms. In Proceedings of the 2019 7th International Electrical Engineering Congress (IEECON), Hua Hin, Thailand, 6–8 March 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Kim, J.-A.; Sung, J.-Y.; Park, S.-H. Comparison of Faster-RCNN, YOLO, and SSD for Real-Time Vehicle Type Recognition. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics—Asia (ICCE-Asia), Seoul, Republic of Korea, 1–3 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, Z.-Y.; Ding, F.; Xu, Y.; Han, X. Background dominant colors extraction method based on color image quick fuzzy c-means clustering algorithm. Def. Technol. 2020, 17, 1782–1790. [Google Scholar] [CrossRef]
- Elavarasi, S.A.; Jayanthi, J.; Basker, N. Trajectory Object Detection using Deep Learning Algorithms. Int. J. Recent Technol. Eng. 2019, 8, C6564098319. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- Kaggle. Ideas for Image Features and Image Quality. Available online: https://www.kaggle.com/code/shivamb/ideas-for-image-features-and-image-quality (accessed on 1 January 2022).
- Vadivel, A.; Sural, S.; Majumdar, A.K. Human color perception in the HSV space and its application in histogram generation for image retrieval. In Color Imaging X: Processing, Hardcopy, and Applications; SPIE: Bellingham, WA, USA, 2005; Volume 5667. [Google Scholar]
- Ray, S.A. Color gamut transform pairs. ACM Sig-Graph Comput. Graph. 1978, 12, 12–19. [Google Scholar]
- Atram, P.; Chawan, P. Finding Dominant Color in the Artistic Painting using Data Mining Technique. Int. Res. J. Eng. Technol. 2020, 6, 235–237. [Google Scholar]
- Data Engineering and Communication Technology; Raju, K.S.; Senkerik, R.; Lanka, S.P.; Rajagopal, V. (Eds.) Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1079. [Google Scholar] [CrossRef]
- Guyeux, C.; Chrétien, S.; BouTayeh, G.; Demerjian, J.; Bahi, J. Introducing and Comparing Recent Clustering Methods for Massive Data Management on the Internet of Things. J. Sens. Actuator Netw. 2019, 8, 56. [Google Scholar] [CrossRef]
- Sai Satyanarayana Reddy, S.; Kumar, A. Edge Detection and Enhancement of Color Images Based on Bilateral Filtering Method Using K-Means Clustering Algorithm. In ICT Systems and Sustainability; Advances in Intelligent Systems and, Computing; Tuba, M., Akashe, S., Joshi, A., Eds.; Springer: Singapore, 2020; Volume 1077. [Google Scholar] [CrossRef]
- Peng, K.; Leung, V.C.M.; Huang, Q. Clustering Approach Based on Mini Batch K-means for Intrusion Detection System Over Big Data. IEEE Access 2018, 6, 11897–11906. [Google Scholar] [CrossRef]
- Liu, N.; Zheng, X. Color recognition of clothes based on k-means and mean shift Automatic Detection and High-End Equipment. In Proceedings of the 2012 IEEE International Conference on Intelligent Control, Beijing, China, 27–29 July 2012; pp. 49–53. [Google Scholar] [CrossRef]
- Mohit, N.A.; Sharma, M.; Kumari, C. A novel approach to text clustering using shift k-medoid. Int. J. Soc. Comput. Cyber-Phys. Syst. Int. J. Soc. Comput. Cyber-Phys. Syst 2019, 2, 106–118. [Google Scholar] [CrossRef]
- Balasubramaniam, P.; Ananthi, V.P. Segmentation of nutrient deficiency in incomplete crop images using intuitionistic fuzzy C-means clustering algorithm. Nonlinear Dyn. 2016, 83, 849–866. [Google Scholar] [CrossRef]
- Yin, S.; Zhang, Y.; Karim, S. Large Scale Remote Sensing Image Segmentation Based on Fuzzy Region Competition and Gaussian Mixture Model. IEEE Access 2018, 6, 26069–26080. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, Z.; Liu, H. An Adaptive and Robust Edge Detection Method Based on Edge Proportion Statistics. IEEE Trans. Image Process. 2020, 29, 5206–5215. [Google Scholar] [CrossRef]
- Latha, N.S.A.; Megalingam, R.K. Exemplar-based Learning for Recognition & Annotation of Human Actions. In Proceedings of the 2020 9th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 4–5 December 2020; pp. 91–93. [Google Scholar] [CrossRef]
- Wang, Y.; Luo, J.; Wang, Q.; Zhai, R.; Peng, H.; Wu, L.; Zong, Y. Automatic Color Detection of Grape Based on Vision Computing Method. In Recent Developments in Intelligent Systems and Interactive Applications IISA 2016; Advances in Intelligent Systems and, Computing; Xhafa, F., Patnaik, S., Yu, Z., Eds.; Springer: Cham, Switzerland, 2017; Volume 541. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, J.; Wang, L.; Zhang, J.; Wang, F.; Huang, D.; Zheng, N. Hierarchical and Interactive Refinement Network for Edge-Preserving Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Tang, D.; Guo, Y.; Do, M.N. Common Visual Pattern Discovery via Nonlinear Mean Shift Clustering. IEEE Trans. Image Process. 2015, 24, 5442–5454. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Ruan, C.; Sun, Y. Cucumber Fruits Detection in Greenhouses Based on Instance Segmentation. IEEE Access 2019, 7, 139635–139642. [Google Scholar] [CrossRef]
- Megalingam, R.K.; Sree, G.S.; Reddy, G.M.; Krishna, I.R.S.; Suriya, L.U. Food Spoilage Detection Using Convolutional Neural Networks and K Means Clustering. In Proceedings of the 2019 3rd International Conference on Recent Developments in Control, Automation & Power Engineering (RDCAPE), Noida, India, 10–11 October 2019; pp. 488–493. [Google Scholar] [CrossRef]
- Megalingam, R.K.; Karath, M.; Prajitha, P.; Pocklassery, G. Computational Analysis between Software and Hardware Implementation of Sobel Edge Detection Algorithm. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 529–533. [Google Scholar] [CrossRef]
- Megalingam, R.K.; Manoharan, S.; Reddy, R.; Sriteja, G.; Kashyap, A. Color and Contour Based Identification of Stem of Coconut Bunch. IOP Conf. Ser. Mater. Sci. Eng. 2017, 225, 012205. [Google Scholar] [CrossRef]
- Alexander, A.; Dharmana, M.M. Object detection algorithm for segregating similar colored objects and database formation. In Proceedings of the 2017 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Krishna Kumar, P.; Parameswaran, L. A hybrid method for object identification and event detection in video. In Proceedings of the 2013 4th National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Jodhpur, India,, 20–21 April 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Molada-Tebar, A.; Marqués-Mateu, Á.; Lerma, J.L.; Westland, S. Dominant Color Extraction with K-Means for Camera Characterization in Cultural Heritage Documentation. Remote Sens. 2020, 12, 520. [Google Scholar] [CrossRef]
- Khandare, A.; Alvi, A.S. Efficient Clustering Algorithm with Improved Clusters Quality. IOSR J. Comput. Eng. 2016, 48, 15–19. [Google Scholar] [CrossRef]
- Wu, S.; Chen, H.; Zhao, Z.; Long, H.; Song, C. An Improved Remote Sensing Image Classification Based on K-Means Using HSV Color Feature. In Proceedings of the 2014 Tenth International Conference on Computational Intelligence and Security, Kunming, China, 15–16 November 2014; pp. 201–204. [Google Scholar] [CrossRef]
- Haraty, R.A.; Dimishkieh, M.; Masud, M. An Enhanced k-Means Clustering Algorithm for Pattern Discovery in Healthcare Data. Int. J. Distrib. Sens. Netw. 2015, 11, 615740. [Google Scholar] [CrossRef]
- Bejar, J. K-Means vs. Mini Batch K-Means: A Comparison; LSI-13-8-R. 2013. Available online: http://hdl.handle.net/2117/23414 (accessed on 1 January 2020).
- Cheng, Y. Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef]
- Hung, M.-C.; Yang, D.-L. An efficient Fuzzy C-Means clustering algorithm. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 225–232. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Saturation (S1) | Value (V1) | Color |
|---|---|---|
| Low | Low | Black |
| Low | Medium | Gray |
| Low | High | White |
| Medium | Low | Black |
| Medium | Medium | Only Tertiary colors (3) |
| Medium | High | Secondary and Tertiary colors (4) |
| High | Low | Black |
| High | Medium | Primary and Tertiary colors (5) |
| High | High | All colors (6) |
| Saturation (S1) | Value (V1) |
|---|---|
| M | Length of the Original Image. |
| N | Width of the Original Image. |
| [Mc]1 × 3 | This represents the Masked Color of the Original Image. This notation implies that Im is a matrix of dimension 1 × 3 (since it has 3 channels i.e., R, G, B). |
| [Io]m × n | Original Image Data. This notation implies that Io is a matrix of size m × n. |
| [Im]m × n | Masked Image Data. This notation implies that Im is a matrix of size m × n. |
| R | Variable that iterates through rows of [Io] and [Im]. |
| C | Variable that iterates through columns of [Io] and [Im]. |
| Dc | Dominant color of the image. |
| [K]m × n × 15 | Matrix representing the result of DCPCM model for the respective pixel. The number 15 in the notation represents the predetermined colors. |
| T | Length of list containing masked pixels. |
| Algorithm | Minimum | Maximum | Mean |
|---|---|---|---|
| AVW | 0.0084 | 4.82 | 0.54 |
| PXS | 0.0069 | 5.82 | 0.75 |
| Algorithm | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|
| All-Pixel | 0.30 | 174.23 | 17.32 | 27.10 |
| AVW | 0.12 | 59.23 | 6.52 | 10.24 |
| PXS | 0.17 | 82.27 | 9.16 | 13.73 |
| Algorithm | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|
| AVW | 0.12 | 59.23 | 6.52 | 10.24 |
| PXS | 0.17 | 82.27 | 9.16 | 13.73 |
| K-means | 0.20 | 87.74 | 8.64 | 12.98 |
| Algorithm | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|
| AVW | 0.12 | 59.23 | 6.52 | 10.24 |
| PXS | 0.17 | 82.27 | 9.16 | 13.73 |
| Mini Batch K-means | 0.24 | 86.43 | 8.39 | 12.55 |
| Algorithm | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|
| AVW | 0.12 | 59.23 | 6.52 | 10.24 |
| PXS | 0.17 | 82.27 | 9.16 | 13.73 |
| Mean shift | 0.30 | 577.93 | 32.93 | 76.66 |
| Algorithm | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|
| AVW | 0.12 | 59.23 | 6.52 | 10.24 |
| PXS | 0.17 | 82.27 | 9.168 | 13.73 |
| Gaussian mixture model | 0.29 | 132.14 | 13.40 | 21.52 |
| Algorithm | Minimum | Maximum | Mean | Standard Deviation |
|---|---|---|---|---|
| AVW | 0.12 | 59.23 | 6.52 | 10.24 |
| PXS | 0.17 | 82.27 | 9.16 | 13.73 |
| Fuzzy C-means | 1.36 | 273.48 | 22.41 | 38.85 |
| Algorithm | Color Prediction Accuracy (%) | Reduction in Time Compared to All-Pixel (%) |
|---|---|---|
| AVW | 93.6 | 62 |
| PXS | 95.4 | 44.3 |
| K-means | 84.1 | 45.1 |
| Mini batch K-means | 83.8 | 47.5 |
| Mean shift | 85.2 | −70.7 |
| Fuzzy C-means | 85.9 | −53.4 |
| Gaussian mixture model | 88 | 22.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Megalingam, R.K.; Tanmayi, B.; Sree, G.S.; Reddy, G.M.; Krishna, I.R.S.; Pai, S.S. Optimized and Efficient Color Prediction Algorithms Using Mask R-CNN. Electronics 2023, 12, 909. https://doi.org/10.3390/electronics12040909
Megalingam RK, Tanmayi B, Sree GS, Reddy GM, Krishna IRS, Pai SS. Optimized and Efficient Color Prediction Algorithms Using Mask R-CNN. Electronics. 2023; 12(4):909. https://doi.org/10.3390/electronics12040909
Chicago/Turabian StyleMegalingam, Rajesh Kannan, Balla Tanmayi, Gadde Sakhita Sree, Gunnam Monika Reddy, Inti Rohith Sri Krishna, and Sreejith S. Pai. 2023. "Optimized and Efficient Color Prediction Algorithms Using Mask R-CNN" Electronics 12, no. 4: 909. https://doi.org/10.3390/electronics12040909
APA StyleMegalingam, R. K., Tanmayi, B., Sree, G. S., Reddy, G. M., Krishna, I. R. S., & Pai, S. S. (2023). Optimized and Efficient Color Prediction Algorithms Using Mask R-CNN. Electronics, 12(4), 909. https://doi.org/10.3390/electronics12040909