Abstract
Human parsing has great application prospects in the field of computer vision, but there are still many problems. In the existing algorithms, the problems of small-scale target location and the problem of background occlusion have not been fully resolved, which will lead to wrong segmentation or incomplete segmentation. Compared with the existing practice of feature concatenation, using the correlation between two factors can make full use of edge information for refined parsing. This paper proposes the mechanism of correlation edge and parsing network (MCEP), which uses the spatial aware and two max-pooling (SMP) module to capture the correlation. The structure mainly includes two steps, namely (1) collection operation, where, through the mutual promotion of edge features and parsing features, more attention is paid to the region of interest around the edge of the human body, and the spatial clues of the human body are collected adaptively, and (2) filtering operation, where parallel max-pooling is adopted to solve the background occlusion problem. Meanwhile, semantic context feature extraction capability is endowed to enhance feature extraction capability and prevent small target detail loss. Through a large number of experiments on multiple single-person and multi-person datasets, this method has greater advantages.
1. Introduction
Human parsing [1,2,3] is the pixel-level recognition of human body composition categories at the pixel-level, which has a wide range of application scenarios and has a strong application prospect in the related fields of behavior recognition, such as automatic driving, character tracking, and athlete-assisted training [4,5,6]. In the case of complex field scenes, due to the characteristics of the human structure, there are common problems, such as occlusion, posture deformation, and differences in the size of different categories. If the existing semantic segmentation method is adopted, it will be difficult to maintain the comparison’s high accuracy, resulting in unsatisfactory human parsing results, and it is difficult to meet our needs.
Semantic context information plays a vital role in improving segmentation performance. DeepLab [7] uses atrous convolution to expand the receptive field to capture human details. Atrous spatial pyramid pooling (ASPP) is an important method to extract multiple scales of context information. Furthermore, PSPnet [8] uses the pyramid pooling module (PPM) to carry out multi-level average pooling to gather context information of different regions to excavate global context information. The PPM is added after the last layer Res5 in feature extraction, and the high-level features are encoded to obtain multi-scale context information and improve the parsing results.
Different from semantic segmentation, the label prediction of adjacent categories is incorrect due to pixel confusion between adjacent categories in humans, as shown in Figure 1b. The CE2P [9] approach uses the low-level features Res2, Res3, and Res4 to predict the contour of the human body edge, and adds the edge information as auxiliary information to the parsing task, which can solve the problem of boundary confusion. After joining the edge information, the neighbors of the hand and the background, the boundaries of the arms, and the body are well distinguished. However, because the correlation between edge structure and human body structure is not fully explored, the pixel of the human boundary cannot be completely predicted; the details are shown in Figure 1c. Ke Gong and Xiaodan Liang [10] proposed that although edge and segmentation are two different tasks, they are highly correlated, and PGNnet promotes the information flow of edge and segmentation through learning to realize mutual assistance between the two tasks. For example, small-scale categories (such as gloves, scarf, and hats) can be corrected by edge detection when the segmentation branch is not located, or the wrong edge branch detection can be corrected by the segmentation branch. However, when the environment is complex, the interference of background information will have a serious impact on the parsing results. The FEAnet [11] can weaken the interference of background information by combining foreground information and edge information, so as to solve the problem of background occlusion in complex environments, but it is still not accurate enough for small-scale category localization.
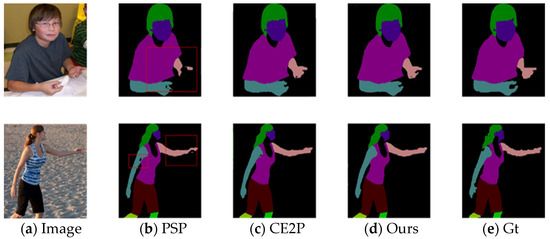
Figure 1.
Illustration of parsing errors and our motivation. (a) Input images. (b) Result of PSPnet. (c) Result of CE2P. (d) Result of our method. (e) Ground truth. From (b) (red box), the fuzzy boundary of the human body leads to inconsistencies with the parsing results. From (c), we can observe that partial prediction of the hand was found after combining the edge, but it still existed to blend with the background, and was not completely separated from the background. However, our method can predict the area shown in the red box in a better and more complete way, mainly because the SMP module we proposed can highlight the area of the human body more and separate it from the background, which is better than the simple feature concatenation of (c).
Aiming at the shortcomings of the existing methods, a human parsing algorithm based on a MCEP network is proposed in this paper, which uses the edge information of the human body to help human parsing, and learns the correlation between the two tasks implicitly after the two branch features are concatenated. We combine edge features with human semantic information, and the spatial information and contextual semantics of human structure can be fully mined through our SMP module. The parallel max-pooling adopted in the SMP module can filter out the interference of background information and highlight the foreground information to obtain a more complete human structure. As shown in Figure 1d, the structure of the parts marked by the red box is more complete, and the classification of boundary pixels is more accurate. In summary, the main contributions of this paper are as follows:
- We propose a new MCEP network that can make full use of the edge information of the human body, so that the model can better learn the fine-grained features and obtain a more complete structure of the target.
- Experiments on look into person (LIP) [12] by adding our SMP module to the mainstream network PSPnet show that the proposed SMP module can be applied to other segmentation tasks related to small-scale targets.
2. Related Work
2.1. Semanticsegmentation
Semantic segmentation [13,14,15] is to assign a label to each pixel in the image according to the object it belongs to. Since the fully convolutional neural network [16,17] shows a good effect in pixel-level prediction, more and more methods based on the convolutional neural network have been proposed but, with the deepening of the convolution depth, continuous downsampling will lead to the loss of spatial detail information. Because small-scale objects are very sensitive to their position, many researchers have proposed en-/decode structures [18,19] to recover high-resolution images through upsampling or deconvolution [20]. DeepLab [7] uses dilated convolution to enlarge the receptive field so as to maintain high-resolution features. The attention mechanism is used to tell a model where is important and where is not. For the feature map, each region in the space is equally important, but for the parsing task, the influence is different. Through parameter back-propagation, the network can learn the areas in the picture that need to be focused on. The attention mechanism has been widely used to improve the performance of the network. For example, CBAM [21], BAM [22], and Senet [23] have been used as mobile networks that can be randomly plugged into various networks. High-resolution features [24,25] are important for the prediction of small-scale objects, such as gloves, skirts, scarves, and other small-scale categories. Different from the upsampling and deconvolution methods in the previous en-/decode network, HRNet [26] fuses multiple different resolutions on each branch in a parallel way to realize the fusion of deep features and shallow feature information. In the whole network, the resolution is always maintained at a high level, which fully maintains the spatial detail information of features.
2.2. Utilizing Pose for Human Parsing
Due to the symmetry of the human body, some occlusion and self-similar semantic classification errors will result in the wrong classification that does not conform to the human body structure. Therefore, in order to improve the performance of human parsing, human pose information [1,27,28] is at the core of the semantic information extracted from images. Human pose information can provide structural information about the human body and constrain the position changes in various types of the human body. Dan Zeng et al. [1] employ NPPnet to simultaneously handle human pose estimation and analysis tasks. Zhou et al. [29] introduced a top-down approach, which uses structural information from different categories of the human body through joint learning of human parsing and human pose to ease the difficulty of classification. Wang et al. [30] analyzed three types of reasoning processes in the hierarchy of human body, namely direct inference, top-down inference, and top-down inference, and then used the CNIF framework to combine the information from the three inference processes, so as to obtain rich geometric features.
2.3. Utilizing Edge for Human Parsing
Image edge [31] is an important feature of information in the image, and edge contour can be used to distinguish different objects and regions. In human parsing tasks, more accurate results can be obtained by adding human edge features. In recent works, CE2P [9] uses edge information to assist human parsing. After adding edge information, boundary pixels can be well located. However, edge information has not been fully utilized in existing research methods, and the extracted edge features are simply concatenated. Ke Gong et al. [10] found that two discrepant optimization targets of edge detection and parsing lead to error accumulation for the final results, but it ignores the problem of background occlusion. The FEAnet [11] approach solves the background occlusion problem by combining foreground information and edge information, While maintaining the human body boundary, it can reduce the pixels occupied by the non-human target. However, the localization of a small-scale target is not accurate. Based on the above analysis, this paper proposes a MCEP network-based human parsing method, which can promote the parsing results by filtering out background information while jointly learning edge and human parsing.
3. Proposed Method
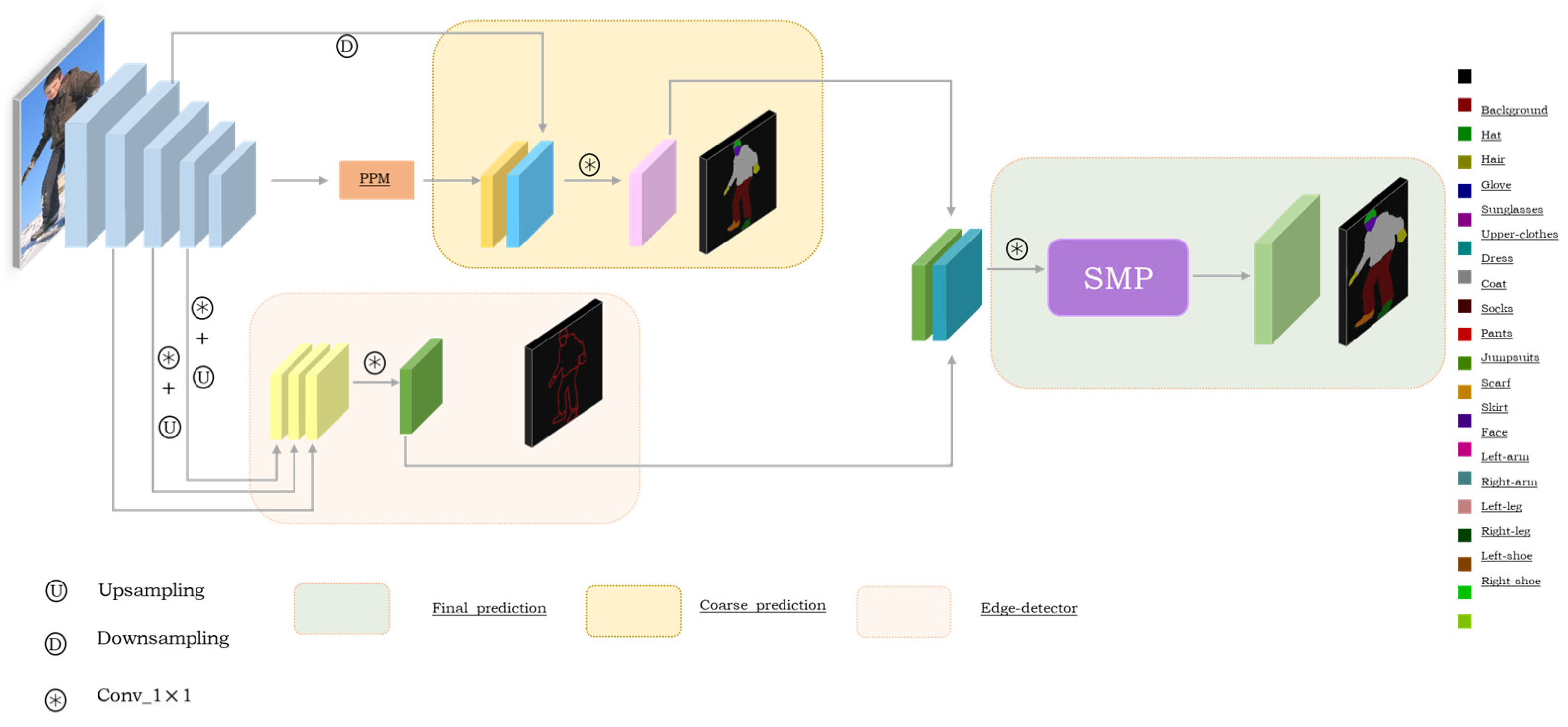
The main structure of the MCEP network proposed in this paper is shown in Figure 2. It is mainly based on the fully convolutional neural network. The backbone network adopts RESNET-101 to extract features as the shared feature weights of subsequent edge detection tasks and rough segmentation tasks. The edge detection module is used to extract the human edge information, and then the human edge feature and the coarse-parsing feature are fused into the SMP module to obtain the final fine-parsing result. The rest of this paper is organized as follows: in Section 3.1, we introduce the edge detection branch, Section 3.2 mainly introduces the process of fusing edge features and parsing features of the SMP module, and Section 3.3 describes our parsing module and a detailed explanation of the loss functions used.
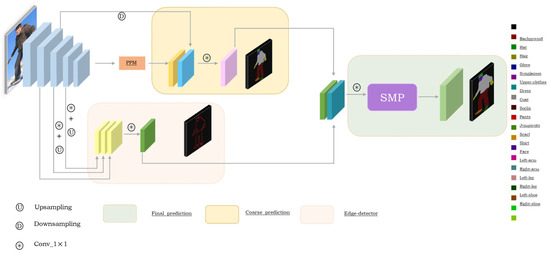
Figure 2.
Overview of the proposed network.
3.1. Edge Module
In human parsing, the problem of confusion about edge semantic information needs to be solved urgently. Especially when adjacent parts have a similar appearance, the existing methods cannot accurately distinguish the boundary pixels of adjacent semantic parts. This is because the low-level feature of the neural network contains more spatial details of the object and maintains a high resolution. Therefore, this paper upsamples Res3 and Res4 to the size of Res2. Then, they are concatenated and fed into a 1 × 1 convolution layer to generate the 2D prediction map, which is used to learn the edge representation of the human body. Then, the edge features f_e and coarse parsing features f_c are fused and fed into the SMP module for further refined prediction.
3.2. SMP Module
Many existing studies have shown that edge features are very effective for human parsing, and some methods have carried out further research based on edge and parsing. However, due to the complexity of realistic scenes, the problem of background occlusion has been difficult to solve, so it is necessary to filter out the background information and weigh the regions that are valuable for parsing. The edge feature retains the boundary information in the image, and concates it with the parsing features to obtain the mixed feature, which contains the explicit boundary information. Compared with the method of processing only analytic features, processing on mixed features can better locate small-scale categories due to the addition of boundary information. In addition, when the interference of background information is filtered, the foreground information of the human body can be more completely separated from the background due to the restriction of the edge information.
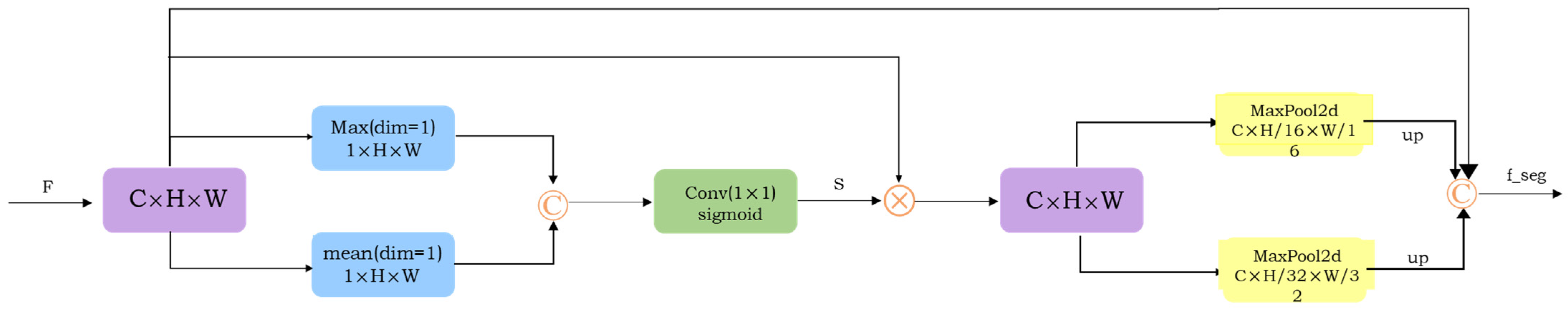
The architecture of SMP is shown in Figure 3. The purpose of this architecture is to selectively emphasize features and suppress features with less effect, so that the network can effectively process the more complex spatial and multi-scale features in the human parsing task. The coarse parsing features f_c and edge features f_e are convolved by 1*1 for information interaction fusion and dimension reduction to obtain the input feature F (C × H × W) of SMP. In the channel dimension, max and mean operations are performed, respectively, and then we concatenate them to generate two 2D maps, namely ∈, ∈ . We aggregate the two features by concatenating them in the channel dimension, and then a 1 × 1 convolution layer and sigmoid function is conducted to transform it into a two-dimensional spatial weight graph of , which is multiplied by input feature F to obtain the feature . The overall procedure can be formulated as follows:
where σ denotes the sigmoid function, represents a convolution operation with the filter size of 1 × 1, ⊕ represents the concatenation in the channel dimension, and ⊗ represents element-product. This operation can better locate the position of small-scale categories in the human body, enhance the spatial perception and generalization ability of the model, and accelerate the information flow of the two branches through complementary features, so as to further explore the relationship between the two branches’ features.
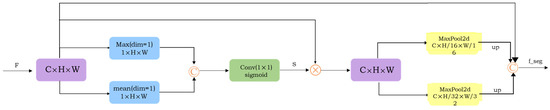
Figure 3.
The structure diagram of the SMP module, which feeds the mixture of edge features and coarse-parsing features into our module to calculate the correlation between them.
The experiment of Wing-Yin Yu a, Lai-Man Po et al. [11] shows that foreground information has a good effect on parsing. While interacting with human foreground information and edge information, it can also reduce the background influence of non-human parts. The advantage of average pooling is the ability to extract global information in a constant region, as different categories within a region (this area may contain pants, left leg, socks, left foot, shoes, and background) of the human body are not equally important for parsing the results. Directly performing average pooling may confuse contributions from different body parts. In order to reduce the interference of background information, global maximum-pooling is adopted. Global max-pooling can preserve the main features and highlight the foreground information (generally the depth of the foreground is deeper than the background), but it cannot obtain the position information of the image. Some strong features can only be counted once when they appear many times, resulting in the loss of the intensity information of some features. For , use two max-pooling with kernel sizes of 16 and 32, respectively, perform dimensionality reduction in the channel dimension to generate two global features and , and then aggregate the two features map by concatenating them in the channel dimension. A convolution layer parameterized by Wa is conducted to transform it into a hybrid feature f_seg, as can be calculated by the following formula:
Through the combination of only two scales of information, the interference of background information can be filtered out more effectively, local features and global features can be aggregated, and multi-scale context information can be modeled in parallel.
3.3. Human Parsing Module
As we all know, the pyramid pooling module (PPM) is used to integrate local information and global information in semantic segmentation tasks to obtain rich context information. When the human body’s posture is distorted or has similar appearances, such as left and right feet or arms, upper body clothes, and coats, it is difficult to determine without global information. The pyramid pooling module (PPM) performs feature encoding on Res5, and the encoded features are concatenated with the original input features after upsampling to achieve the fusion of local and global information. Some small-scale objects in the human body, such as sunglass, scarf, socks, etc., may lose details in the process of feature extraction due to the reduction in resolution. We employ the feature of Res2 of the base model and upsample the output of the PSP module to the same scale as Res2; then, we concatenate them as f_c. After being extracted from the edge module, the edge feature f_e and coarse parsing feature f_c will be further fed into the SMP module to obtain the final prediction f_seg. The total loss(L_total) of the MCEP network is as follows:
where L_coarse represents the coarse segmentation loss, L_edge represents the edge loss function, and L_fine represents the final fine segmentation loss. We use the cross-entropy loss function [32] for both parsing loss and edge loss, which can make the loss smoother and easier to converge and avoid excessive loss caused by misclassification. This is calculated as follows:
where is the true label, represents the predicted result, and n is the number of pixels of the kth class. The entire model is trained end-to-end.
L_total = L_coarse + L_fine + L_edge
4. Experiments
In this section, in order to verify the effectiveness of the method in this paper, experiments were carried out on single-person and multi-person datasets and compared with several existing state-of-the-art technologies.
Here, LIP [12] is a large-scale single-person dataset focusing on the semantic understanding of human body parts and clothing labels. The pictures in it are all taken in wild scenes, and the images generally have serious occlusions, pose deformations, and various complex backgrounds, etc. The dataset has a total of 50,462 images, of which the training set, test set, and validation set consist of 30,462, 10,000, and 10,000 images, respectively. Each image contains only 1 human target, 19 human body semantic part labels, and 1 background label. The 19 semantic annotations include hat, hair, sunglasses, upper clothes, dress, coat, socks, pants, gloves, scarf, skirt, jumpsuit, face, right arm, left arm, right leg, left leg, right foot, and left foot.
The CIHP [10] dataset provides 38,280 images in 20 categories. Among them, the images of the training set, verification set, and test set are 28,280, 5000, and 5000 images respectively.
This dataset is collected from the real scene, and has severe occlusion, deformation of posture, and changes in various appearance scene scales. Compared with the LIP dataset, it presents a greater challenge, because each image contains two or more detection targets. The images in this dataset are labeled with pixel-wise annotations on 20 categories and instance-level identities.
4.1. Subjective Evaluation
In order to verify the effectiveness of the proposed method, in this section, we compare it with several mainstream methods on single-person and multi-person datasets, respectively.
4.1.1. Single-Person Quantitative Analysis
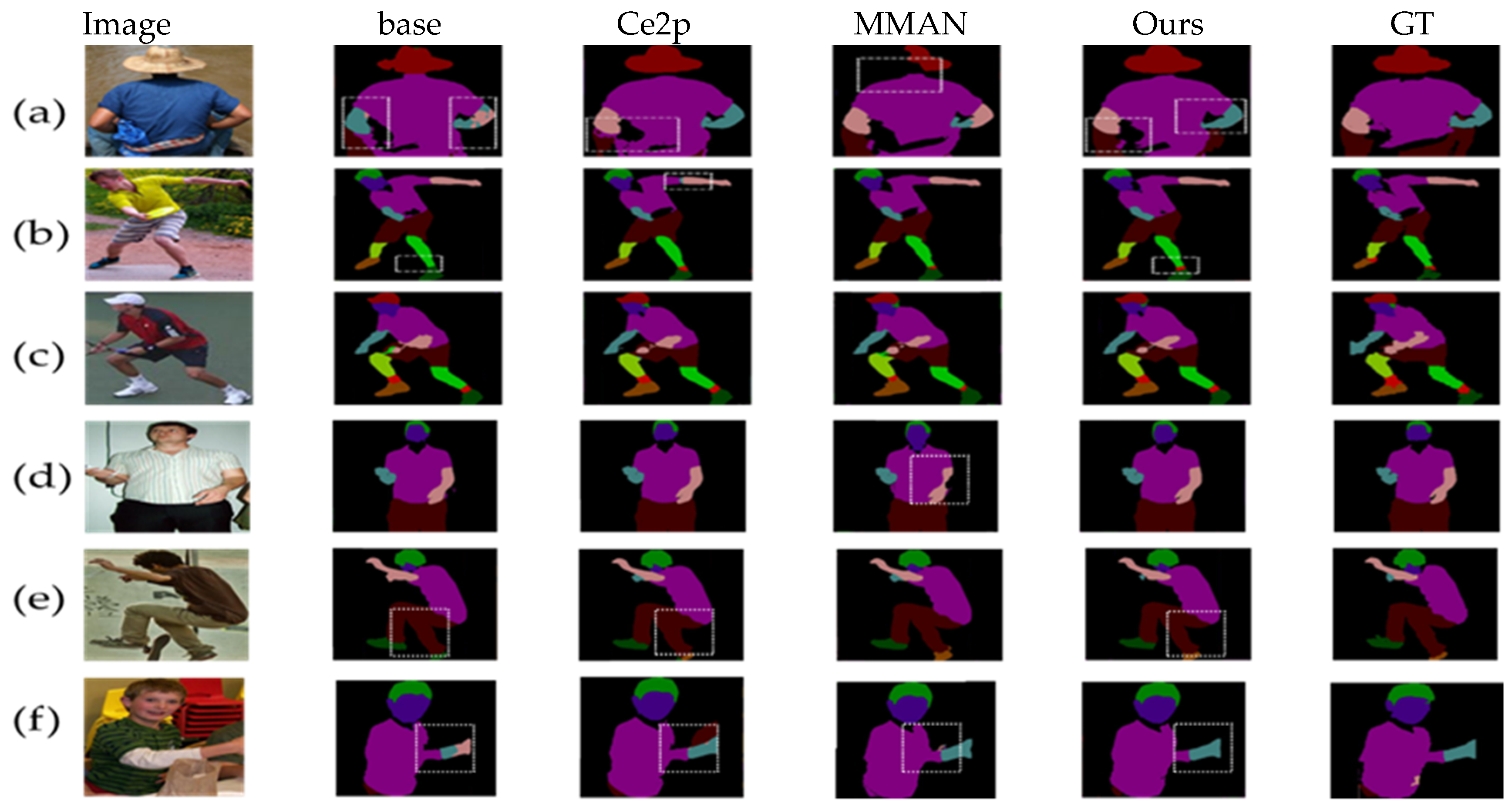
In Figure 4, we show the comparison of visual results of baseline, MMAN, CE2P, and our method. Some predicted regions are highlighted in the figure with white rectangles. In general, our method can achieve better results under different complex backgrounds and different postures. As shown in Figure 4a,f, our baseline network details are missing, and the parsing results are confused. In Figure 4a, the left and right hands are confused, the boundary pixel prediction between the hand and clothing is blurred and, in Figure 4f, the prediction of the arm and jacket boundary is confused. Although CE2P can correct these problems of wrong edge prediction, in Figure 4f, we find that there are still small flaws at the edges. However, our method can not only correct the semantic confusion under the baseline but can also obtain a more complete detailed structure of the human body, which is mainly benefited from the collection and filtering operation in the SMP module. Collection can make the details more complete, and filtering can further separate the foreground from the background and obtain richer semantic information, as shown in Figure 4b–f.
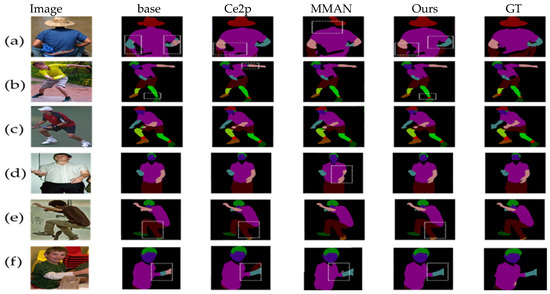
Figure 4.
Visual comparison with other state-of-the-art methods on the LIP validation set.
4.1.2. Multi-Person Quantitative Analysis
Figure 5 shows our visualization results on CIHP. It can be seen that it can also effectively solve the confusion and occlusion problems between adjacent pixels among multiple people.

Figure 5.
Some examples of visualizations on the multi-person dataset CIHP.
4.2. Objective Evaluation
In this subsection, we objectively evaluate and compare the proposed method and existing techniques using two advanced quality metrics, IoU and mIoU, respectively.
4.2.1. Metrics
For all test experiments of the above datasets, we used the mean intersection over union (mIoU) to evaluate the overall prediction effect of the model, and used the pixel-wise accuracy and mean accuracy to help evaluate the model performance.
Mean intersection over union (mIoU) score
Pixel-wise Accuracy (Pixel Acc.)
Mean Accuracy (Mean Acc.)
where C represents the category, and represents the pixel number relationship between the real tag i and the predicted tag j.
4.2.2. Training Details
The framework we use is PyTorch, and the backbone network uses the pre-trained model resnet101 on ImageNet [33]. The size of the training input image is 384 × 384, and the data is expanded by random scaling, cropping, and left-right flipping. This method adopts the “poly” learning rate policy with the base learning rate at 0.01 and power at 0.9; the stochastic gradient descent (SGD) optimizer is employed with a mini-batch, momentum of 0.9, and weight decay of 0.0005 for training purposes. All models are trained and tested on a GeForce RTX 1080 Ti GPU. The batch size is set to 6.
4.2.3. Experiments on Single-Person Datasets
In this paper, we compare our proposed MCEP net with several current advanced methods in the validation set for LIP, as shown in Table 1. From the table, we can see that the MCEP net proposed in this paper can achieve better results compared with the existing algorithms, and that its mIoU value can reach up to 55.31, which is 2.21 higher than that of CE2P. For gloves, dresses, scarf, skirts, and other small-scale objects, this is a great improvement without reducing the accuracy of other large-scale objects. For the scarf, the mIoU increased by 11.79, and the skirt increased by 7.91, which is a huge improvement in the human body parsing task. This also proves that the SMP module can indeed improve the localization and perception ability of small-scale objects in complex scenes.

Table 1.
Comparison of each class of IOU and mIoU with several recent methods in the LIP validation set.
4.2.4. Ablation Experiment
In order to verify the effectiveness of multi-layer max-pooling in the SMP module proposed in this paper, we conduct a series of experiments on the basic network. Experimental results show that double-layer parallel maximum-pooling can provide better gain, as shown in Table 2.
Table 2.
Ablation experiments; analytical performance comparison of the human body with different components.
4.2.5. Experiments on Multi-Person Datasets
In order to verify that our method is more consistent with real-life multi-person scenarios, we tested it on the multi-person dataset CIHP and compared it with current advanced methods, as shown in Table 3. We achieve better results than existing state-of-the-art methods on the multi-person dataset CIHP, achieving 60.7 mIoU and 55.8 for PGN by joint edge detection and human parsing. It is better than BraidNet plus mask-Rcnn [39] and M-ce2p, but our MCEPnet only uses pixel-level labels, while both of the other methods add object detection branches.
Table 3.
Comparison with current state-of-the-art methods on multi-person datasets.
4.3. Discussion
4.3.1. Extended Experiment
In order to verify that our SMP module can be applied to other semantic segmentation modules, this paper applies the SMP module to mainstream PSPnet and conducts experiments on the LIP dataset. The experimental results are shown in Table 4. The table only lists the small-scale categories of the human body, and it can be seen that after the addition of SMP module, the improvement is not less than 5.
Table 4.
Extended experiment, Comparison between PSPnet + SMP module and PSPnet.
4.3.2. Analysis of the Difference between the MCEPNet and CP-SSGNet
A detailed discussion of the difference between the CP-SSGNet and MCEPNet is provided in this section. The HNL in CP-SSGNet obtains mixed features by concatenating parsing features, edge features, and human posture features, calculates the similarity between mixed features and parsing features, and then obtains weights of 0~1 by softmax operation, which represents the spatial correlation between the mixed feature and the parsing feature, from which each position relationship between the mixed feature and the parsing feature is derived. The residuals are then computed with the parsing feature. The SMP module proposed in this paper is Figure 3 in Section 3.2. It concates edge features and parsing features to obtain feature F, and then processes them to obtain the spatial perception matrix S, which promotes the information flow between the two branches in the process of back propagation. The subsequent two-layer parallel max-pooling operation can filter out the interference of background information and aggregate local and global features to obtain multi-scale context information. Through simple convolution and pooling operations, the SMP module can effectively locate small-scale targets in the human body and filter out the interference of background information, thus, obtaining a more complete structure of the human body. Compared with HNL, SMP can better improve the accuracy of small-scale targets, as shown in Table 1. In addition, the position correlation matrix in HNL requires a lot of computation, while SMP is only composed of several convolution and pooling operations, which is more conducive to network convergence.
5. Conclusions and Future Work
The algorithm of MCEPnet proposed in this paper is mainly used to solve the problems of the inaccurate location of small target complex backgrounds and character occlusion. The SMP module in this algorithm can implicitly use edge information to promote parsing results, selectively emphasize features, suppress features with less effect, improve the accuracy of positioning small objects, and make it more powerful to deal with multi-scale targets and enhanced spatial awareness. However, SMP does not digitally model the relationship between edge information and parsing information to obtain a clear guide of edge structure to human body parsing. In the future, we intend to further model the edge structure to provide explicit guidance to assist our parsing task, and to combine explicit guidance with implicit guidance. In the field of autonomous driving, the detection of pedestrians requires extremely high accuracy, so we will try some small tricks to improve mIoU, such as a better backbone, attention strategy, the use of edge loss function and segmentation loss function, and the ratio between the two. In practical application, the detection speed is also very important. We will try to reduce the parameters of the model and optimize the structure of the network, so as to obtain better accuracy without increasing the reasoning cost.
Author Contributions
Methodology, K.G.; software, K.G.; validation, S.T., X.W.; re-sources, X.W.; data curation, K.G.; writing—original draft preparation, K.G.; writing—review and editing, S.T.; visualization, K.G. supervision, S.T.; project administration, S.T.; and funding acquisition, S.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Dataset were provided by Chengjun Liu, School of Electronic Information Engineering, Anhui University, Hefei Anhui, China.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zeng, D.; Huang, Y.; Bao, Q.; Zhang, J.; Su, C.; Liu, W. Neural Architecture Search for Joint Human Parsing and Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11385–11394. [Google Scholar]
- Yang, L.; Song, Q.; Wang, Z.; Liu, Z.; Xu, S.; Li, Z. Quality-aware network for human parsing. arXiv. 2022, arXiv:2103.05997. [Google Scholar] [CrossRef]
- Li, T.; Liang, Z.; Zhao, S.; Gong, J.; Shen, J. Self-learning with rectification strategy for human parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9263–9272. [Google Scholar]
- Sun, H.; Liu, X.; Xu, K.; Miao, J.; Luo, Q. Emergency vehicles audio detection and localization in autonomous driving. arXiv 2021, arXiv:2109.14797. [Google Scholar]
- Fan, J.; Xu, W.; Wu, Y.; Gong, Y. Human tracking using convolutional neural networks. IEEE Trans. Neural Netw. 2010, 21, 1610–1623. [Google Scholar] [PubMed]
- Cheng, L.; Guan, Y.; Zhu, K.; Li, Y. Recognition of human activities using machine learning methods with wearable sensors. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; pp. 1–7. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ruan, T.; Liu, T.; Huang, Z.; Wei, Y.; Wei, S.; Zhao, Y. Devil in the details: Towards accurate single and multiple human parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4814–4821. [Google Scholar]
- Gong, K.; Liang, X.; Li, Y.; Chen, Y.; Yang, M.; Lin, L. Instance-level Human Parsing via Part Grouping Network. arXiv 2018, arXiv:1808.00157. [Google Scholar] [CrossRef]
- Yu, W.-Y.; Po, L.-M.; Zhao, Y.; Zhang, Y.; Lau, K.-W. FEANet: Foreground-edge-aware network with DenseASPOC for human parsing. Image Vis. Comput. 2021, 109, 104145. [Google Scholar] [CrossRef]
- Gong, K.; Liang, X.; Zhang, D.; Shen, X.; Lin, L. Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 932–940. [Google Scholar]
- Zhou, T.; Wang, W.; Konukoglu, E.; Van Gool, L. Rethinking semantic segmentation: A prototype view. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2582–2593. [Google Scholar]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Xu, J.; De Mello, S.; Liu, S.; Byeon, W.; Breuel, T.; Kautz, J.; Wang, X. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 18134–18144. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer; pp. 234–241. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1520–1528. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, L.; Li, D.; Zhu, Y.; Tian, L.; Shan, Y. Dual super-resolution learning for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3774–3783. [Google Scholar]
- Liu, Y.; Zhang, S.; Xu, J.; Yang, J.; Tai, Y.-W. An accurate and lightweight method for human body image super-resolution. IEEE Trans. Image Process. 2021, 30, 2888–2897. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Zhou, T.; Wang, W.; Liu, S.; Yang, Y.; Van Gool, L. Differentiable multi-granularity human representation learning for instance-aware human semantic parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1622–1631. [Google Scholar]
- Nie, X.; Feng, J.; Yan, S. Mutual learning to adapt for joint human parsing and pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 502–517. [Google Scholar]
- Zhou, T.; Yang, Y.; Wang, W. Differentiable Multi-Granularity Human Parsing. IEEE Trans. Pattern Anal. Mach. Intelligence 2023. [Google Scholar] [CrossRef]
- Wang, W.; Zhou, T.; Qi, S.; Shen, J.; Zhu, S.-C. Hierarchical human semantic parsing with comprehensive part-relation modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3508–3522. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Barron, J.T.; Papandreou, G.; Murphy, K.; Yuille, A.L. Semantic image segmentation with task-specific edge detection using cnns and a discriminatively trained domain transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4545–4554. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Luo, Y.; Zheng, Z.; Zheng, L.; Guan, T.; Yu, J.; Yang, Y. Macro-micro adversarial network for human parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Liang, X.; Gong, K.; Shen, X.; Lin, L. Look into person: Joint body parsing & pose estimation network and a new benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 871–885. [Google Scholar]
- Liu, X.; Zhang, M.; Liu, W.; Song, J.; Mei, T. Braidnet: Braiding semantics and details for accurate human parsing. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 338–346. [Google Scholar]
- Zhang, X.; Chen, Y.; Zhu, B.; Wang, J.; Tang, M. Semantic-spatial fusion network for human parsing. Neurocomputing 2020, 402, 375–383. [Google Scholar] [CrossRef]
- Zhang, Z.; Su, C.; Zheng, L.; Xie, X. Correlating edge, pose with parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8900–8909. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).