
Cross-Language Entity Alignment Based on Dual-Relation Graph and Neighbor Entity Screening
Abstract
:1. Introduction
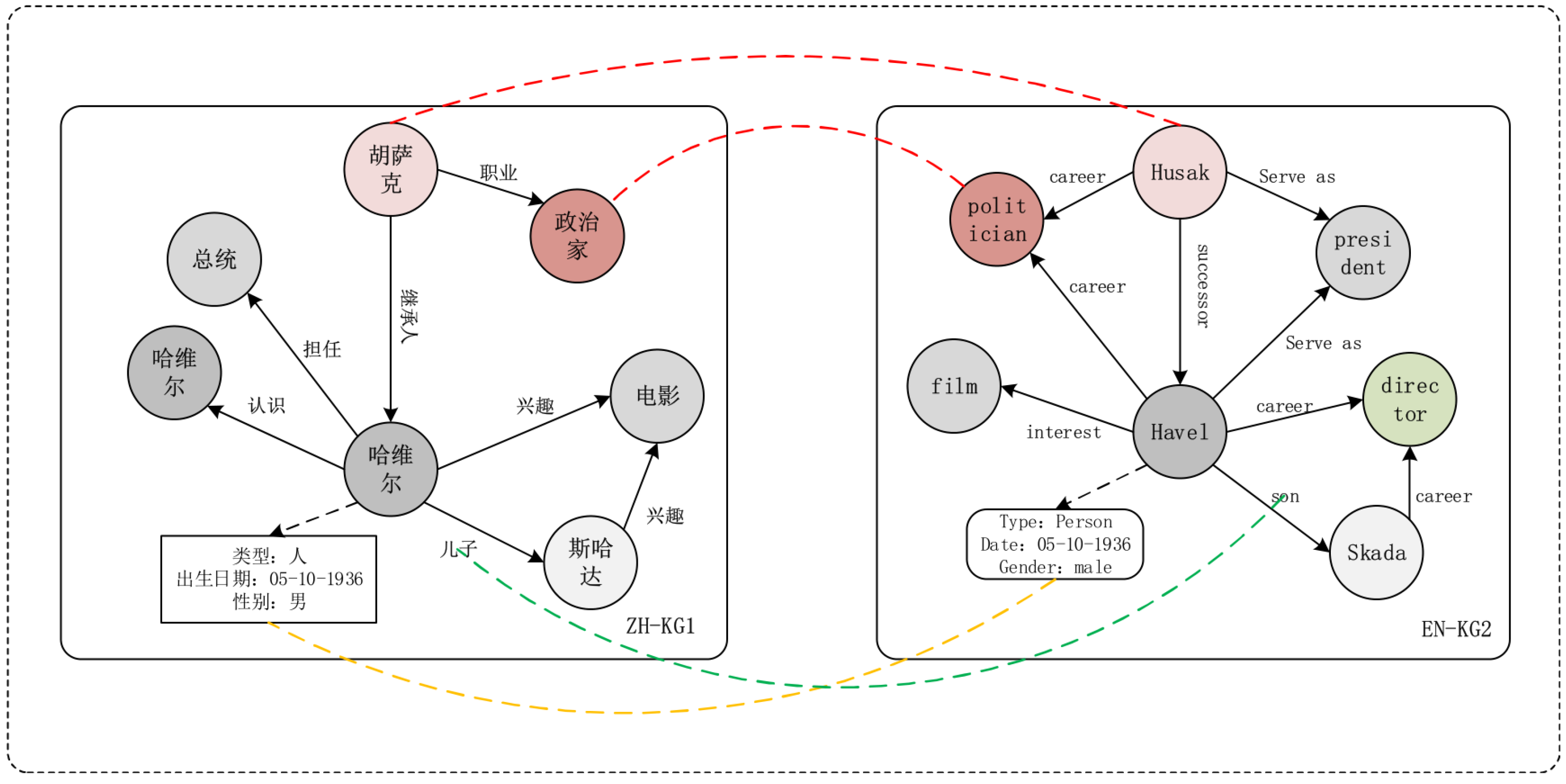
- We proposed a neighboring-entity-screening rule that used the entity name and its attributes as the main evidence for screening. In the neighboring entity set of the central entity, we identified all entities with the same entity name as the central entity. Then, the attribute information of the entities was used as the main evidence to judge whether two entities with the same entity name referred to the same concept in the reality corpus.
- Dual-relation graph was used to make full use of relations. This paper used the dual-relation graph not only to strengthen the role of entity relations but also to avoid the impact of insufficient attribute information and to reduce the errors in the entity screening process.
- A cross-language entity alignment method based on neighboring-entity screening and a dual-relation graph was proposed. We used a graph convolutional network, combined with neighboring-entity-screening rules and a dual-relation graph to realize cross-language entity alignment and achieve excellent results on public datasets, such as DBP15K, which proved the importance of entity screening.
2. Related Work
2.1. Traditional Entity Alignment Methods
2.2. Entity Alignment Based on Representation Learning
2.2.1. Entity Alignment Based on Translation Model
2.2.2. Entity Alignment Based on Graph Convolutional Networks
3. Methods
3.1. Problem Definition
3.2. Symbol Definition
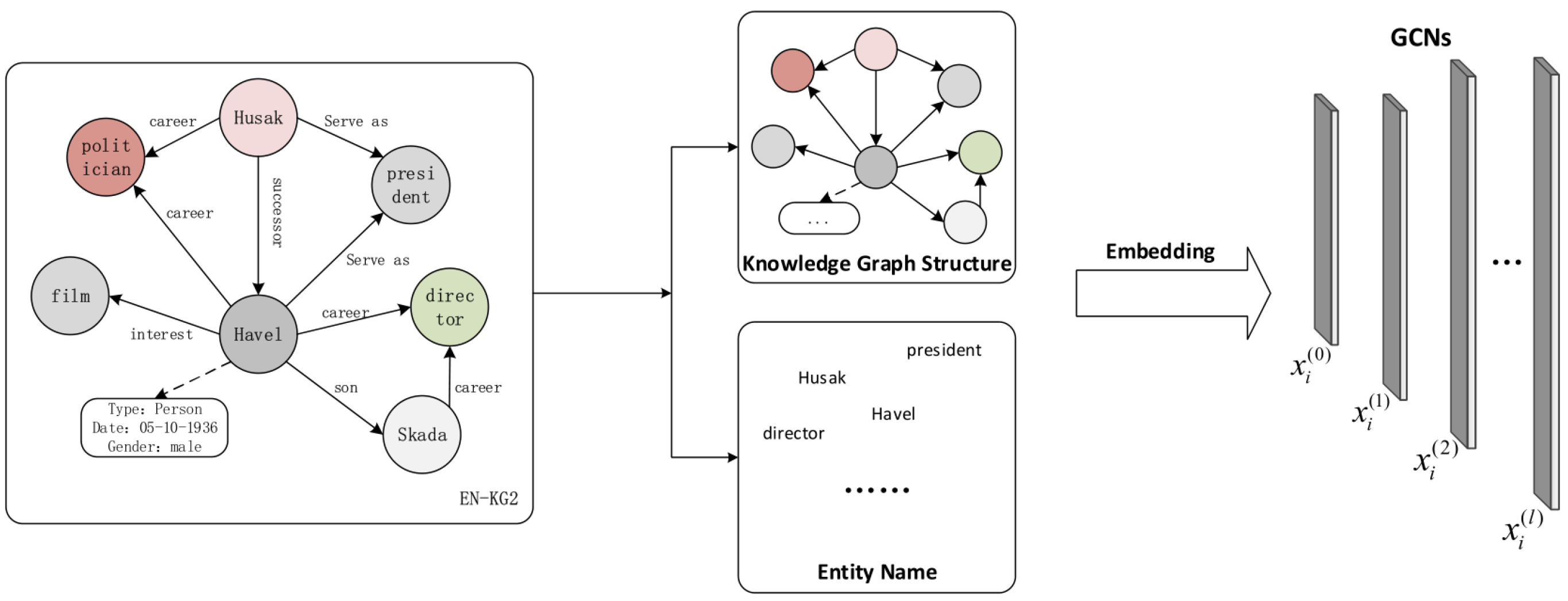
3.3. Entity Alignment Based on Entity Screening and Dual-Relation Graph
3.3.1. Dual Relation Graph Construction
3.3.2. Neighboring-Entity Screening
- (1)
- We first had to determine whether the name of the neighboring entity was the same as the central entity.
- (2)
- On the premise that the verification result in the first step was true (that is, the entity names of the two entities were the same), we compared the attribute information of the two entities.
3.3.3. Knowledge Embedding
3.3.4. Neighborhood Entity Sampling
3.3.5. Entity Alignment
4. Experimental Setup
4.1. Datasets
4.2. Comparison Model
- (1)
- (2)
- (3)
- MUGNN [32]: A novel multi-channel graph neural-network model (MuGNN) that remembered alignment-oriented knowledge graph embeddings by robustly encoding two knowledge graphs through multiple channels.
- (4)
- KECG [34]: A semi-supervised entity-alignment method combining a knowledge-embedding model and cross-graph model in order to better utilize seed alignments in order to propagate the entire graphs under KG-based constraints.
- (5)
- GCN-Align [21]: A novel approach for cross-lingual knowledge-graph alignment based on graph convolutional networks that could learn embeddings from the structural and attribute information of entities and then combine the results to obtain accurate alignment.
- (6)
- NMN [41]: A novel entity-alignment framework, neighborhood-matching network, that captured the topology structure and neighborhood differences of entities by estimating the similarity between entities.
- (7)
- (8)
- PSR [44]: A novel entity-alignment approach with three new components, which enabled high performance, high scalability, and high robustness.
4.3. Implementation Details
4.4. Metrics
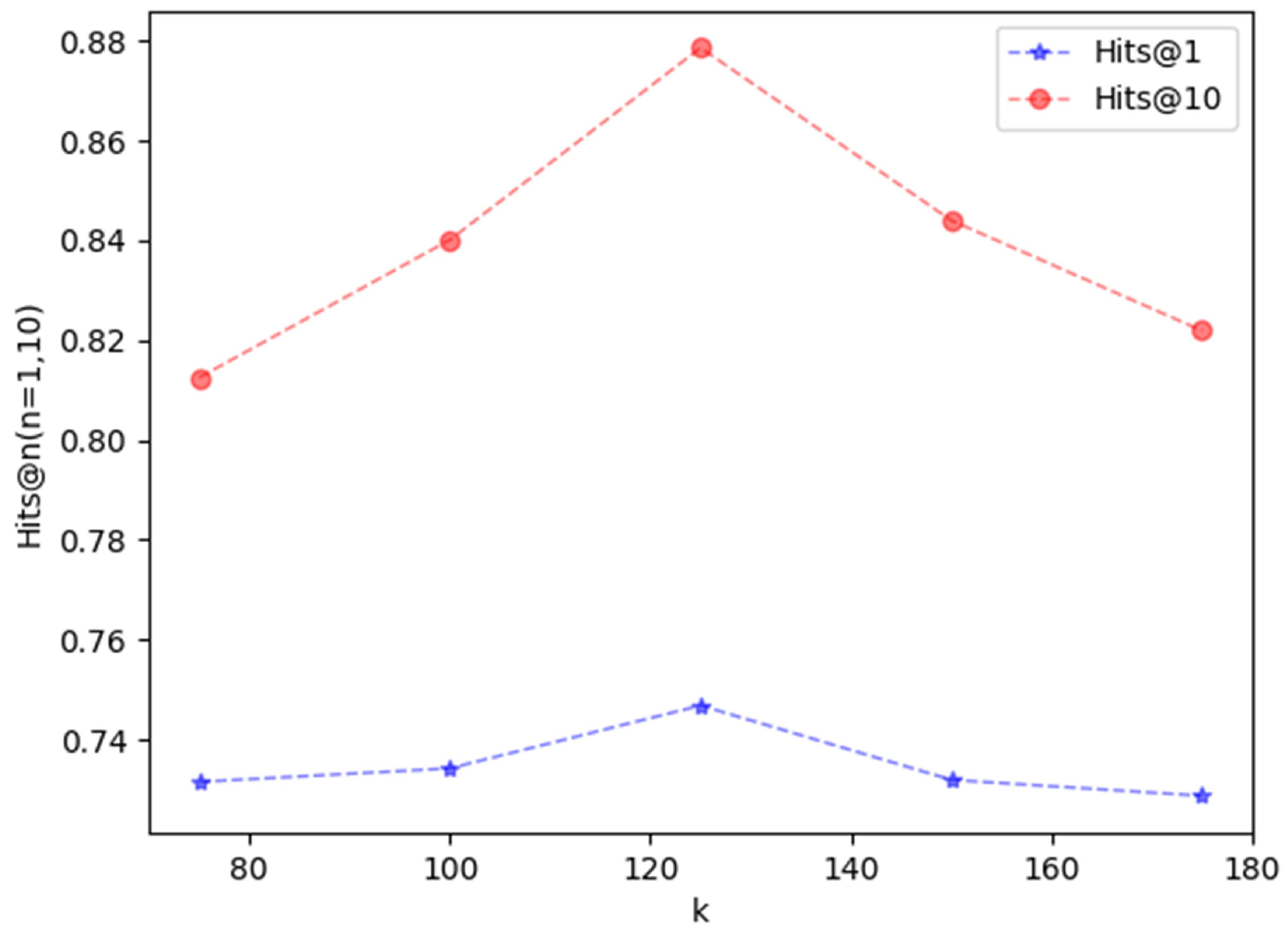
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Zeng, K.; Li, C.; Hou, L.; Li, J.; Feng, L. A comprehensive survey of entity alignment for knowledge graphs. AI Open 2021, 2, 1–13. [Google Scholar] [CrossRef]
- Zhang, R.; Trisedya, B.D.; Li, M.; Jiang, Y.; Qi, J. A benchmark and comprehensive survey on knowledge graph entity alignment via representation learning. VLDB J. 2022, 31, 1143–1168. [Google Scholar] [CrossRef]
- Jiang, T.; Bu, C.; Zhu, Y.; Wu, X. Combining embedding-based and symbol-based methods for entity alignment. Pattern Recognit. 2022, 124, 108433. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the NIPS’13: Proceedings of the 26th International Conference on Neural Information Processing Systems, Stateline, NV, USA, 5–10 December 2013; Volume 26. [Google Scholar]
- Nayyeri, M.; Vahdati, S.; Lehmann, J.; Yazdi, H.S. Soft marginal transe for scholarly knowledge graph completion. arXiv 2019, arXiv:1904.12211. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Sun, Z.; Hu, W.; Li, C. Cross-lingual entity alignment via joint attribute-preserving embedding. In Proceedings of the International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; pp. 628–644. [Google Scholar]
- Wu, Y.; Liu, X.; Feng, Y.; Wang, Z.; Yan, R.; Zhao, D. Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macau, China, 10–16 August 2019. [Google Scholar]
- Ngomo, A.C.N.; Auer, S. LIMES—A time-efficient approach for large-scale link discovery on the web of data. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Niu, X.; Rong, S.; Wang, H.; Yu, Y. An effective rule miner for instance matching in a web of data. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1085–1094. [Google Scholar]
- Yu, J.; Ma, X. English translation model based on intelligent recognition and deep learning. Wirel. Commun. Mob. Comput. 2022, 2022, 3079775. [Google Scholar] [CrossRef]
- Wang, X. Design of English Translation Model Based on Recurrent Neural Network. Math. Probl. Eng. 2022, 2022, 5177069. [Google Scholar] [CrossRef]
- Zhang, R.; Trisedy, B.D.; Li, M.; Jiang, Y.; Qi, J. A comprehensive survey on knowledge graph entity alignment via representation learning. arXiv 2021, arXiv:2103.15059. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Chen, M.; Tian, Y.; Chang, K.-W.; Skiena, S.; Zaniolo, C. Co-training Embeddings of Knowledge Graphs and Entity Descriptions for Cross-Lingual Entity Alignment. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence Main Track, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Mao, X.; Wang, W.; Xu, H.; Wu, Y.; Lan, M. Relational reflection entity alignment. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Newport Beach, CA, USA, 17–21 October 2020; pp. 1095–1104. [Google Scholar]
- Mikolov, T.; Le, Q.V.; Sutskever, I. Exploiting Similarities among Languages for Machine Translation. arXiv 2013, arXiv:1309.4168. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Zhu, H.; Xie, R.; Liu, Z.; Sun, M. Iterative entity alignment via knowledge embeddings. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Sun, Z.; Hu, W.; Zhang, Q.; Qu, Y. Bootstrapping Entity Alignment with Knowledge Graph Embedding. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence Main Track, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 4396–4402. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berrendorf, M.; Faerman, E.; Melnychuk, V.; Tresp, V.; Seidl, T. Knowledge graph entity alignment with graph convolutional networks: Lessons learned. In Advances in Information Retrieval, Proceedings of the 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020; Springer: Cham, Switzerland, 2020; pp. 3–11. [Google Scholar]
- Wang, Z.; Lv, Q.; Lan, X.; Zhang, Y. Cross-lingual knowledge graph alignment via graph convolutional networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 349–357. [Google Scholar]
- Akhtar, M.U.; Liu, J.; Xie, Z.; Liu, X.; Ahmed, S.; Huang, B. Entity alignment based on relational semantics augmentation for multi-lingual knowledge graphs. Knowl.-Based Syst. 2022, 252, 109494. [Google Scholar] [CrossRef]
- Jozashoori, S.; Sakor, A.; Iglesias, E.; Vidal, M.E. EABlock: A declarative entity alignment block for knowledge graph creation pipelines. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Newport Beach, CA, USA, 25–29 April 2022; pp. 1908–1916. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2019, arXiv:1609.02907. [Google Scholar]
- Xiong, F.; Gao, J. Entity Alignment for Cross-lingual Knowledge Graph with Graph Convolutional Networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macau, China, 10–16 August 2019; pp. 6480–6481. [Google Scholar]
- Guo, H.; Tang, J.; Zeng, W.; Zhao, X.; Liu, L. Multi-modal entity alignment in hyperbolic space. Neurocomputing 2021, 461, 598–607. [Google Scholar] [CrossRef]
- Cao, Y.; Liu, Z.; Li, C.; Li, J.; Chua, T.S. Multi-Channel Graph Neural Network for Entity Alignment. arXiv 2019, arXiv:1908.09898. [Google Scholar]
- Nguyen, T.T.; Huynh, T.T.; Yin, H. Entity alignment for knowledge graphs with multi-order convolutional networks. IEEE Trans. Knowl. Data Eng. 2020, 34, 4201–4214. [Google Scholar]
- Li, C.; Cao, Y.; Hou, L.; Shi, J.; Li, J.; Chua, T.S. Semi-supervised entity alignment via joint knowledge embedding model and cross-graph model. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2723–2732. [Google Scholar]
- Huang, H.; Li, C.; Peng, X. Cross-knowledge-graph entity alignment via relation prediction. Knowl.-Based Syst. 2022, 240, 107813. [Google Scholar] [CrossRef]
- Mao, X.; Wang, W.; Xu, H.; Lan, M.; Wu, Y. MRAEA: An efficient and robust entity alignment approach for cross-lingual knowledge graph. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 420–480. [Google Scholar]
- Chen, M.; Shi, W.; Zhou, B.; Roth, D. Cross-Lingual Entity Alignment with Incidental Supervision; EACL: Kiev, Ukraine, 2021; pp. 645–658. [Google Scholar]
- Zhu, Y.; Liu, H.; Wu, Z.; Du, Y. Relation-aware neighborhood matching model for entity alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; pp. 4749–4756. [Google Scholar]
- Zeng, W.; Zhao, X.; Tang, J.; Lin, X.; Groth, P. Reinforcement Learning–based Collective Entity Alignment with Adaptive Features. ACM Trans. Inf. Syst. (TOIS) 2021, 39, 1–31. [Google Scholar] [CrossRef]
- Zhu, R.; Ma, M.; Wang, P. Raga: Relation-aware graph attention networks for global entity alignment. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Delhi, India, 11–14 May 2021; pp. 501–513. [Google Scholar]
- Wu, Y.; Liu, X.; Feng, Y.; Wang, Z.; Zhao, D. Neighborhood Matching Network for Entity Alignment. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6477–6487. [Google Scholar]
- Tam, N.T.; Trung, H.T.; Yin, H.; Vinh, T.V.; Sakong, D.; Zheng, B.; Hung, N.Q.V. Multi-order graph convolutional networks for knowledge graph alignment. In Proceedings of the 37th IEEE Int Conf Data Eng, Chania, Greece, 19–22 April 2021; pp. 19–22. [Google Scholar]
- Mao, X.; Wang, W.; Wu, Y.; Lan, M. Boosting the speed of entity alignment 10×: Dual attention matching network with normalized hard sample mining. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 821–832. [Google Scholar]
- Mao, X.; Wang, W.; Wu, Y.; Lan, M. From Alignment to Assignment: Frustratingly Simple Unsupervised Entity Alignment. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2843–2853. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DBP15K | Entity | Relation | Attribute | Rel.Triples | Att. Triples | |
|---|---|---|---|---|---|---|
| ZH-EN | ZH | 66,469 | 2830 | 8113 | 153,929 | 379,684 |
| EN | 98,125 | 2317 | 7173 | 237,674 | 567,755 | |
| JA-EN | JA | 65,744 | 2043 | 5882 | 164,373 | 354,619 |
| EN | 95,680 | 2096 | 6066 | 233,319 | 497,230 | |
| FR-EN | FR | 66,858 | 1379 | 4547 | 192,191 | 528,665 |
| EN | 105,889 | 2209 | 6422 | 278,590 | 576,543 | |
| Model | ZH-EN | JA-EN | FR-EN | |||
|---|---|---|---|---|---|---|
| Hits@1 | Hits@10 | Hits@1 | Hits@10 | Hits@1 | Hits@10 | |
| JAPE | 0.4078 | 0.7321 | 0.3723 | 0.6819 | 0.3221 | 0.6658 |
| KECG | 0.4770 | 0.8350 | 0.4847 | 0.8499 | 0.4929 | 0.8442 |
| MUGNN | 0.4773 | 0.8421 | 0.4866 | 0.8573 | 0.4890 | 0.8681 |
| RDGCN | 0.7105 | 0.8529 | 0.7790 | 0.9069 | 0.8883 | 0.9602 |
| NMN | 0.7330 | 0.8605 | 0.7861 | 0.9013 | 0.9031 | 0.9662 |
| Dual−AMN | 0.7403 | 0.9019 | 0.7598 | 0.9490 | 0.7293 | 0.9284 |
| PSR | 0.8024 | 0.9140 | 0.7310 | 0.9311 | 0.8033 | 0.9380 |
| DRG+ESGCN | 0.7570 | 0.9073 | 0.8070 | 0.9330 | 0.9701 | 0.9730 |
| Model | ZH-EN | JA-EN | FR-EN | |||
|---|---|---|---|---|---|---|
| MR | MRR | MR | MRR | MR | MRR | |
| JAPE | 64 | 0.490 | 99 | 0.476 | 92 | 0.430 |
| KECG | 71.802 | 0.598 | 59.706 | 0.611 | 41.925 | 0.609 |
| RDGCN | 68.829 | 0.763 | 45.728 | 0.825 | 17.664 | 0.915 |
| Dual−AMN | 28.630 | 0.805 | 11.797 | 0.830 | 20.056 | 0.801 |
| PSR | 11.456 | 0.810 | 10.931 | 0.844 | 7.532 | 0.852 |
| ESGCN | 1.537 | 0.789 | 1.511 | 0.834 | 1.333 | 0.927 |
| DRG+ESGCN | 1.782 | 0.811 | 1.615 | 0.853 | 1.359 | 0.927 |
| Model | ZH-EN | JA-EN | FR-EN | |||
|---|---|---|---|---|---|---|
| Hits@10 | MRR | Hits@10 | MRR | Hits@10 | MRR | |
| NMN | 0.8605 | 0.799 | 0.9031 | 0.827 | 0.9662 | 0.926 |
| ESGCN | 0.8786 | 0.789 | 0.9099 | 0.834 | 0.9689 | 0.927 |
| DRGCN | 0.8679 | 0.791 | 0.9054 | 0.830 | 0.9673 | 0.926 |
| DRG+ESGNN | 0.8325 | 0.685 | 0.8810 | 0.761 | 0.9277 | 0.839 |
| DRG+ESGCN | 0.9073 | 0.811 | 0.9330 | 0.853 | 0.9730 | 0.927 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Zhang, W.; Wang, H. Cross-Language Entity Alignment Based on Dual-Relation Graph and Neighbor Entity Screening. Electronics 2023, 12, 1211. https://doi.org/10.3390/electronics12051211
Zhang X, Zhang W, Wang H. Cross-Language Entity Alignment Based on Dual-Relation Graph and Neighbor Entity Screening. Electronics. 2023; 12(5):1211. https://doi.org/10.3390/electronics12051211
Chicago/Turabian StyleZhang, Xiaoming, Wencheng Zhang, and Huiyong Wang. 2023. "Cross-Language Entity Alignment Based on Dual-Relation Graph and Neighbor Entity Screening" Electronics 12, no. 5: 1211. https://doi.org/10.3390/electronics12051211