
VEDAM: Urban Vegetation Extraction Based on Deep Attention Model from High-Resolution Satellite Images


Abstract
1. Introduction
2. Methodology
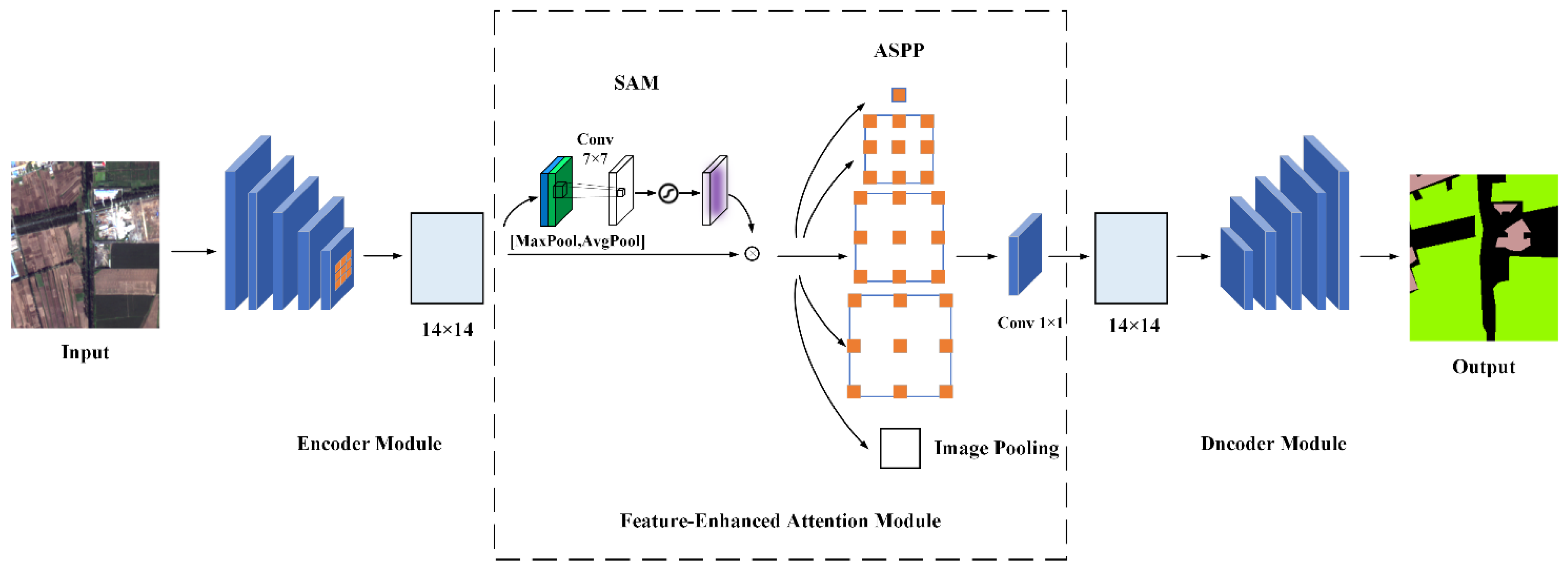
2.1. Network Architecture
2.2. Encoder Module
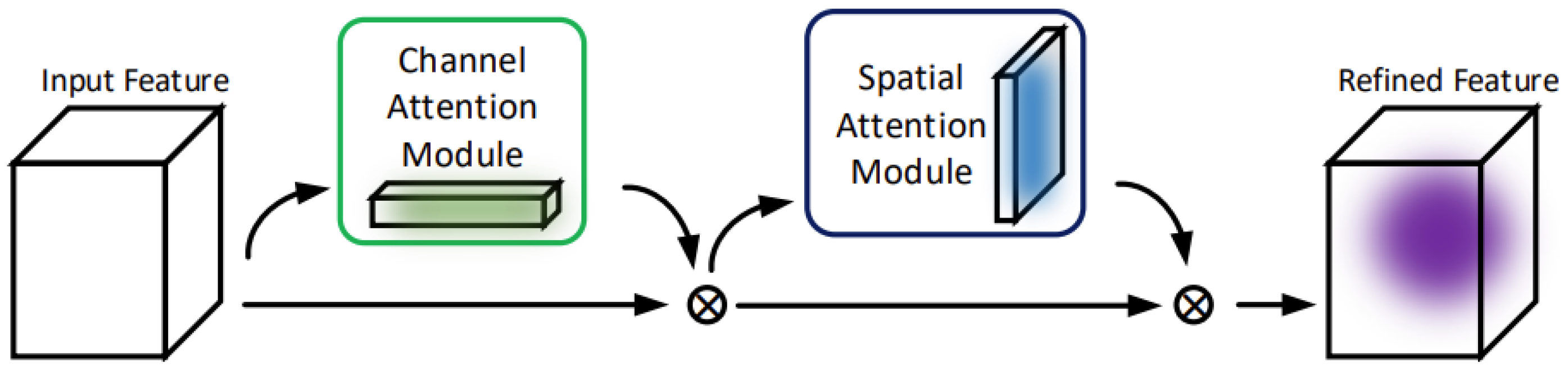
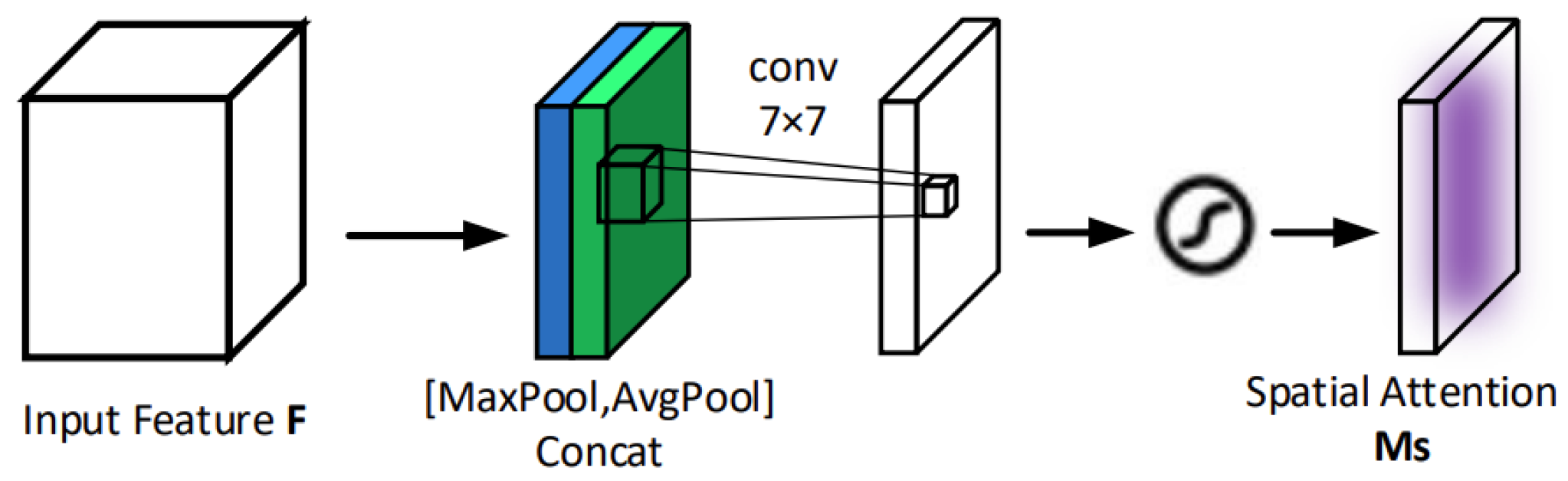
2.3. Feature-Enhanced Attention Module
2.4. Decoder Module
3. Experimental Settings
3.1. Gaofen Image Dataset (GID)
3.2. Experimental Implementation Details
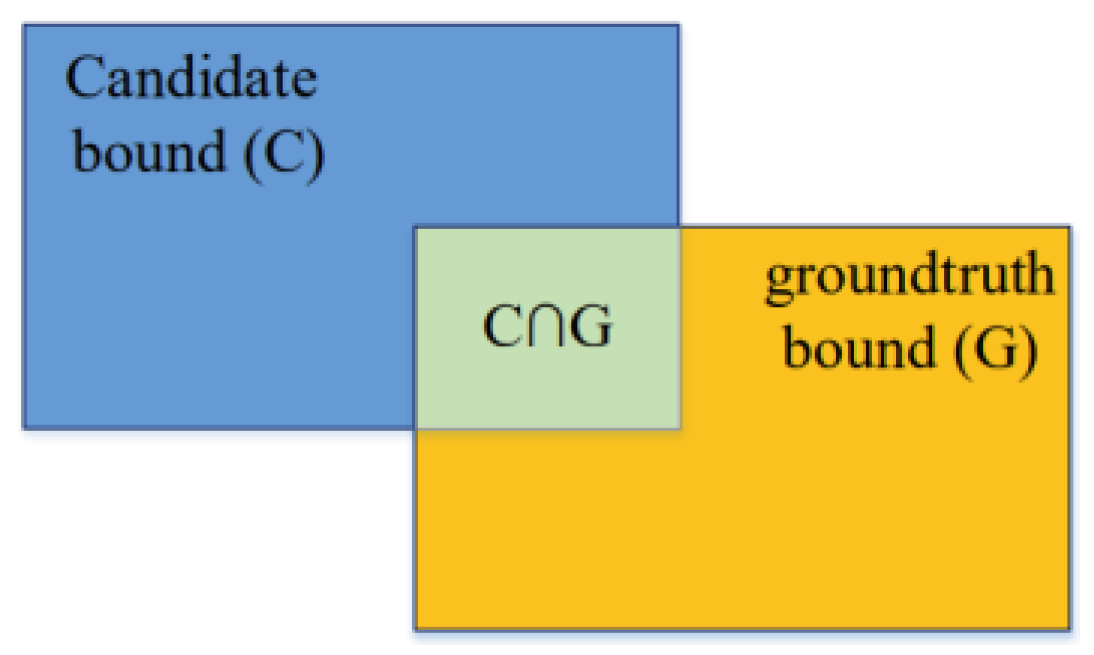
3.3. Comparative Methods and Evaluation Criteria
4. Experimental Results and Discussion
4.1. The Overall Results of the Classification Experiments
4.1.1. Performance on the GID Dataset
4.1.2. Performance in Vegetation Classes
4.2. The Results of the Comparative Experiments
4.2.1. Performance on the GID Dataset
4.2.2. Performance in Vegetation Classes
4.3. Effect of the CBAM
4.3.1. Performance on the GID Dataset
4.3.2. Performance in Vegetation Classes
4.4. Discussion
4.4.1. Analysis of Misclassification
4.4.2. Potential application value of VEDAM
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Jia, M.; Zhou, M.; Wang, B.; Durrani, T.S. Integrated Cooperative Spectrum Sensing and Access Control for Cognitive Industrial Internet of Things. IEEE Internet Things J. 2023, 10, 1887–1896. [Google Scholar] [CrossRef]
- Jia, M.; Gao, Z.; Guo, Q.; Lin, Y.; Gu, X. Sparse Feature Learning for Correlation Filter Tracking Toward 5G-Enabled Tactile Internet. IEEE Trans. Ind. Inform. 2020, 16, 1904–1913. [Google Scholar] [CrossRef]
- Jia, M.; Zhang, X.; Sun, J.; Gu, X.; Guo, Q. Intelligent Resource Management for Satellite and Terrestrial Spectrum Shared Networking toward B5G. IEEE Wirel. Commun. 2020, 27, 54–61. [Google Scholar] [CrossRef]
- Taubenböck, H.; Weigand, M.; Esch, T.; Staab, J.; Wurm, M.; Mast, J.; Dech, S. A new ranking of the world’s largest citiesdo administrative units obscure morphological realities? Remote Sens. Environ. 2019, 232, 111353. [Google Scholar] [CrossRef]
- White, M.A.; Brunsell, N.; Schwartz, M.D. Vegetation Phenology in Global Change Studies. In Phenology: An Integrative Environmental Science. Tasks for Vegetation Science; Schwartz, M.D., Ed.; Springer: Dordrecht, The Netherlands, 2003; Volume 39. [Google Scholar] [CrossRef]
- Luo, Z.; Sun, O.J.; Ge, Q.; Xu, W.; Zheng, J. Phenological responses of plants to climate change in an urban environment. Ecol. Res. 2007, 22, 507–514. [Google Scholar] [CrossRef]
- Bidolakh, D.I.; Bilous, A.M.; Kuziovych, V.S. The accuracy of measuring the height of trees with the use of a quadrocopter. Ukr. J. For. Wood Sci. 2019, 10, 19–26. [Google Scholar] [CrossRef]
- Bidolakh, D.I. Geoinformation monitoring of green stands using remote sensing methods. Ann. For. Sci. 2020, 11, 4–14. [Google Scholar]
- Ozdarici-Ok, A.; Ok, A.O.; Schindler, K. Mapping of Agricultural Crops from Single High-Resolution Multispectral Images—Data-Driven Smoothing vs. Parcel-Based Smoothing. Remote Sens. 2015, 7, 5611–5638. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Gharineiat, Z.; Tarsha Kurdi, F.; Campbell, G. Review of automatic processing of topography and surface feature identification LiDAR data using machine learning techniques. Remote Sens. 2022, 14, 4685. [Google Scholar] [CrossRef]
- Camuffo, E.; Mari, D.; Milani, S. Recent Advancements in Learning Algorithms for Point Clouds: An Updated Overview. Sensors 2022, 22, 1357. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S. Learning selfhood scales for urban land cover mapping with very-high-resolution satellite images. Remote Sens. Environ. 2016, 178, 172–190. [Google Scholar] [CrossRef]
- Melaas, E.K.; Wang, J.A.; Miller, D.L.; Friedl, M.A. Interactions between urban vegetation and surface urban heat islands: A case study in the boston metropolitan region. Environ. Res. Lett. 2016, 11, 054020. [Google Scholar] [CrossRef]
- Schreyer, J.; Geiß, C.; Lakes, T. TanDEM-X for Large-Area Modeling of Urban Vegetation Height: Evidence from Berlin, Germany. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1876–1887. [Google Scholar] [CrossRef]
- De, S.; Bhattacharyya, S.; Chakraborty, S.; Dutta, P. Hybrid Soft Computing for Multilevel Image and Data Segmentation; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Zhang, L.B.; Li, H. Region of interest detection based on visual attention and threshold segmentation in high spatial resolution remote sensing images. KSII Trans. Internet Inf. Syst. 2013, 7, 1843–1859. [Google Scholar] [CrossRef]
- Ghamisi, P.; Couceiro, M.S.; Ferreira, N.M.F.; Kumar, L. Use of Darwinian Particle Swarm Optimization technique for the segmentation of Remote Sensing images. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4295–4298. [Google Scholar] [CrossRef]
- Gaetano, R.; Masi, G.; Poggi, G.; Verdoliva, L.; Scarpa, G. Marker-Controlled Watershed-Based Segmentation of Multiresolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2987–3004. [Google Scholar] [CrossRef]
- Mylonas, S.K.; Stavrakoudis, D.G.; Theocharis, J.B.; Mastorocostas, P.A. Spectral-spatial classification of remote sensing images using a region-based GeneSIS Segmentation algorithm. In Proceedings of the 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Beijing, China, 6–11 July 2014; pp. 1976–1984. [Google Scholar] [CrossRef]
- Sellaouti, A. Méthode Collaborative de Segmentation et Classification d’objets à Partir d’images de Télédétection à Très Haute Résolution Spatiale. (Collaborative Method of Segmentation and Classification of Objects from Remote Sensing Images with Very High Spatial Resolution). Doctoral Dissertation, Tunis El Manar University, Tunis, Tunisie, 2014. [Google Scholar]
- Mylonas, S.K.; Stavrakoudis, D.G.; Theocharis, J.B. A GA-based sequential fuzzy segmentation approach for classification of remote sensing images. In Proceedings of the 2012 IEEE International Conference on Fuzzy Systems, Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Michel, J.; Inglada, J. Multi-Scale Segmentation and Optimized Computation of Spatial Reasoning Graphs for Object Detection in Remote Sensing Images. In Proceedings of the IGARSS 2008-2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. III-431–III-434. [Google Scholar] [CrossRef]
- Ren, J.; Zeng, X.; McKee, D. Segmentation of multispectral images and prediction of CHI-A concentration for effective ocean colour remote sensing. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 2303–2306. [Google Scholar] [CrossRef]
- Masi, G.; Gaetano, R.; Poggi, G.; Scarpa, G. Superpixel-based segmentation of remote sensing images through correlation clustering. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1028–1031. [Google Scholar] [CrossRef]
- Costa, W.S.; Fonseca, L.M.G.; Körting, T.S.; Simões, M.; Bendini, H.D.N.; Souza, R.C.M. Segmentation of optical remote sensing images for detecting homogeneous regions in space and time. In Proceedings of the XVIII Brazilian Symposium on GeoInformatics (GEOINFO 2017), Salvador, BA, Brazil, 4–6 December 2017; Unifacs: Salvador, BA, Brazil, 2017; Volume 18, pp. 40–51. [Google Scholar] [CrossRef]
- Chen, C.Y.; Feng, H.M.; Chen, H.C.; Jou, S.-M. Dynamic image segmentation algorithm in 3D descriptions of remote sensing images. Multimed. Tools Appl. 2016, 75, 9723–9743. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, Z.; Xie, Z.; Wu, L. Quality assessment of building footprint data using a deep autoencoder network. Int. J. Geogr. Inf. Sci. 2017, 31, 1929–1951. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Kalayeh, M.M.; Shah, M. On Symbiosis of Attribute Prediction and Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1620–1635. [Google Scholar] [CrossRef]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-Supervised Semantic Segmentation With High- and Low-Level Consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1369–1379. [Google Scholar] [CrossRef]
- Li, K.; Wu, Z.; Peng, K.-C.; Ernst, J.; Fu, Y. Guided Attention Inference Network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2996–3010. [Google Scholar] [CrossRef] [PubMed]
- Lin, D.; Huang, H. Zig-Zag Network for Semantic Segmentation of RGB-D Images. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2642–2655. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; David, P.; Foroosh, H.; Gong, B. A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1823–1841. [Google Scholar] [CrossRef]
- Gao, H.; Yuan, H.; Wang, Z.; Ji, S. Pixel Transposed Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1218–1227. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Liu, F.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for Dense Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1228–1242. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Salient Object Detection with Recurrent Fully Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1734–1746. [Google Scholar] [CrossRef]
- Han, B.-B.; Zhang, Y.-T.; Pan, Z.-X.; Tai, X.-Q.; Li, F.-F. Residual dense spatial pyramid network for urban remote sensing image segmentation. J. Image Graph. 2020, 25, 2656. [Google Scholar]
- Li, W.; Zhao, W.; Zhong, H.; He, C.; Lin, D. Joint Semantic-geometric Learning for Polygonal Building Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 1958–1965. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4096–4105. [Google Scholar]
- Ayhan, B.; Kwan, C. Application of Deep Belief Network to Land Cover Classification Using Hyperspectral Images. In Advances in Neural Networks-ISNN 2017; Cong, F., Leung, A., Wei, Q., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10261. [Google Scholar] [CrossRef]
- Yuan, M.; Ren, D.; Feng, Q.; Wang, Z.; Dong, Y.; Lu, F.; Wu, X. MCAFNet: A Multiscale Channel Attention Fusion Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2023, 15, 361. [Google Scholar] [CrossRef]
- Li, L.; Zhang, W.; Zhang, X.; Emam, M.; Jing, W. Semi-Supervised Remote Sensing Image Semantic Segmentation Method Based on Deep Learning. Electronics 2023, 12, 348. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network With Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 905–909. [Google Scholar] [CrossRef]
- Tan, X.; Xiao, Z.; Wan, Q.; Shao, W. Scale Sensitive Neural Network for Road Segmentation in High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 533–537. [Google Scholar] [CrossRef]
- Saltiel, T.M.; Dennison, P.E.; Campbell, M.J.; Thompson, T.R.; Hambrecht, K.R. Tradeoffs between UAS Spatial Resolution and Accuracy for Deep Learning Semantic Segmentation Applied to Wetland Vegetation Species Mapping. Remote Sens. 2022, 14, 2703. [Google Scholar] [CrossRef]
- Behera, T.K.; Bakshi, S.; Sa, P.K. A Lightweight Deep Learning Architecture for Vegetation Segmentation using UAV-captured Aerial Images. Sustain. Comput. Inform. Syst. 2023, 37, 100841. [Google Scholar] [CrossRef]
- Kwan, C.; Ayhan, B.; Budavari, B.; Lu, Y.; Perez, D.; Li, J.; Bernabe, S.; Plaza, A. Deep Learning for Land Cover Classification Using Only a Few Bands. Remote Sens. 2020, 12, 2000. [Google Scholar] [CrossRef]
- Kwan, C.; Gribben, D.; Ayhan, B.; Bernabe, S.; Plaza, A.; Selva, M. Improving Land Cover Classification Using Extended Multi-Attribute Profiles (EMAP) Enhanced Color, Near Infrared, and LiDAR Data. Remote Sens. 2020, 12, 1392. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Gill, L.; Ghosh, B. Drone Image Segmentation Using Machine and Deep Learning for Mapping Raised Bog Vegetation Communities. Remote Sens. 2020, 12, 2602. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Yang, M.-D.; Tseng, H.-H.; Hsu, Y.-C.; Tsai, H.P. Semantic Segmentation Using Deep Learning with Vegetation Indices for Rice Lodging Identification in Multi-date UAV Visible Images. Remote Sens. 2020, 12, 633. [Google Scholar] [CrossRef]
- Wu, C.; Ju, B.; Xiong, N.; Yang, G.; Wu, Y.; Yang, H.; Huang, J.; Xu, Z. U-net super-neural segmentation and similarity calculation to realize vegetation change assessment in satellite imagery. arXiv 2019, arXiv:1909.04410. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Heryadi, Y.; Irwansyah, E.; Miranda, E.; Soeparno, H.; Herlawati; Hashimoto, K. The Effect of Resnet Model as Feature Extractor Network to Performance of DeepLabV3 Model for Semantic Satellite Image Segmentation. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Geoscience, Electronics and Remote Sensing Technology (AGERS), Jakarta, Indonesia, 7–8 December 2020; pp. 74–77. [Google Scholar] [CrossRef]
- Zeng, F.; Yang, B.; Zhao, M.; Xing, Y.; Ma, Y. MASANet: Multi-Angle Self-Attention Network for Semantic Segmentation of Remote Sensing Images. Teh. Vjesn. 2022, 29, 1567–1575. [Google Scholar] [CrossRef]
- Kwan, C.; Gribben, D.; Ayhan, B.; Li, J.; Bernabe, S.; Plaza, A. An Accurate Vegetation and Non-Vegetation Differentiation Approach Based on Land Cover Classification. Remote Sens. 2020, 12, 3880. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Wu, Q.; Luo, F.; Wu, P.; Wang, B.; Yang, H.; Wu, Y. Automatic Road Extraction from High-Resolution Remote Sensing Images Using a Method Based on Densely Connected Spatial Feature-Enhanced Pyramid. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3–17. [Google Scholar] [CrossRef]
- Ni, Z.-L.; Bian, G.-B.; Wang, G.-A.; Zhou, X.-H.; Hou, Z.-G.; Chen, H.-B.; Xie, X.-L. Pyramid Attention Aggregation Network for Semantic Segmentation of Surgical Instruments. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11782–11790. [Google Scholar] [CrossRef]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.-S.; Li, J.; Wong, A. Squeeze-and-attention networks for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13065–13074. [Google Scholar] [CrossRef]
- Chen, L.; Tian, X.; Chai, G.; Zhang, X.; Chen, E. A New CBAM-P-Net Model for Few-Shot Forest Species Classification Using Airborne Hyperspectral Images. Remote Sens. 2021, 13, 1269. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.; Chen, W.; Li, Y.; Wang, J. Research on Recognition of Fly Species Based on Improved RetinaNet and CBAM. IEEE Access 2020, 8, 102907–102919. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoderdecoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Landcover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Zang, Y.; Wang, C.; Yu, Y.; Luo, L.; Yang, K.; Li, J. Joint Enhancing Filtering for Road Network Extraction. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1511–1525. [Google Scholar] [CrossRef]
- Kraemer, H.C. Kappa coefficient. Wiley StatsRef Stat. Ref. Online 2014, 1–4. [Google Scholar] [CrossRef]
- El Amin, A.M.; Liu, Q.; Wang, Y. Zoom out CNNs features for optical remote sensing change detection. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 812–817. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vegetation | |||||||
|---|---|---|---|---|---|---|---|
| Forest | Farmland | Meadow | |||||
| garden land | arbor forest | shrub land | paddy field | irrigated land | dry cropland | natural meadow | artificial meadow |
| Back Ground | Industria Land | Urban Residential | Rural Residential | Traffic Land | Vegetation | River | Lake | Pond | |
|---|---|---|---|---|---|---|---|---|---|
| ACC | 0.9644 | 0.9961 | 0.9936 | 0.9949 | 0.9930 | 0.9815 | 0.9988 | 0.9994 | 0.9987 |
| Recall | 0.9468 | 0.9599 | 0.9622 | 0.9223 | 0.9314 | 0.9746 | 0.9890 | 0.9892 | 0.9725 |
| Precision | 0.9562 | 0.9533 | 0.9652 | 0.9339 | 0.8487 | 0.9737 | 0.9788 | 0.9792 | 0.9611 |
| F-score | 0.9515 | 0.9566 | 0.9637 | 0.9281 | 0.8882 | 0.9742 | 0.9839 | 0.9842 | 0.9668 |
| IoU | 0.9075 | 0.9168 | 0.9299 | 0.9658 | 0.7988 | 0.9496 | 0.9683 | 0.9688 | 0.9357 |
| mIoU | 0.9157 | ||||||||
| Kappa | 0.9450 | ||||||||
| Paddy Field | Irrigated Land | Dry Cropland | Garden Plot | Arbor Woodland | Shrub Land | Natural Grassland | Artificial Grassland | |
|---|---|---|---|---|---|---|---|---|
| ACC | 0.9982 | 0.9884 | 0.9984 | 0.9993 | 0.9962 | 0.9996 | 0.9991 | 0.9996 |
| Recall | 0.9656 | 0.9746 | 0.9548 | 0.9337 | 0.9697 | 0.9717 | 0.9582 | 0.9750 |
| Precision | 0.9687 | 0.9745 | 0.9679 | 0.9248 | 0.9663 | 0.8735 | 0.9590 | 0.9408 |
| F-score | 0.9671 | 0.9745 | 0.9613 | 0.9292 | 0.9680 | 0.9199 | 0.9586 | 0.9576 |
| IoU | 0.9364 | 0.9503 | 0.9254 | 0.8678 | 0.9380 | 0.8518 | 0.9205 | 0.9186 |
| mIoU | 0.9136 | |||||||
| Back Ground | Industrial Land | Urban Residential | Rural Residential | Traffic Land | Vegetation | River | Lake | Pond | ||
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | U-Net | 0.9474 | 0.9935 | 0.9894 | 0.9931 | 0.9922 | 0.9700 | 0.9983 | 0.9985 | 0.9979 |
| SegNet | 0.9229 | 0.9901 | 0.9823 | 0.9900 | 0.9898 | 0.9548 | 0.9950 | 0.9947 | 0.9965 | |
| VEDAM | 0.9644 | 0.9961 | 0.9936 | 0.9949 | 0.9930 | 0.9815 | 0.9988 | 0.9994 | 0.9987 | |
| Recall | U-Net | 0.9124 | 0.9256 | 0.9453 | 0.9180 | 0.8720 | 0.9721 | 0.9811 | 0.9513 | 0.9478 |
| SegNet | 0.9125 | 0.8362 | 0.9536 | 0.8065 | 0.7983 | 0.9192 | 0.9086 | 0.9172 | 0.9247 | |
| VEDAM | 0.9468 | 0.9599 | 0.9622 | 0.9223 | 0.9314 | 0.9746 | 0.9890 | 0.9892 | 0.9725 | |
| Precision | U-Net | 0.9429 | 0.9299 | 0.9365 | 0.8924 | 0.8686 | 0.9455 | 0.9735 | 0.9622 | 0.9470 |
| SegNet | 0.8821 | 0.9377 | 0.8624 | 0.9034 | 0.8518 | 0.9526 | 0.9553 | 0.8107 | 0.9043 | |
| VEDAM | 0.9562 | 0.9533 | 0.9652 | 0.9339 | 0.8487 | 0.9737 | 0.9788 | 0.9792 | 0.9611 | |
| F-score | U-Net | 0.9274 | 0.9277 | 0.9408 | 0.9051 | 0.8703 | 0.9586 | 0.9773 | 0.9567 | 0.7474 |
| SegNet | 0.8970 | 0.8841 | 0.9057 | 0.8522 | 0.8241 | 0.9356 | 0.9314 | 0.8607 | 0.9144 | |
| VEDAM | 0.9515 | 0.9566 | 0.9637 | 0.9281 | 0.8882 | 0.9742 | 0.9839 | 0.9842 | 0.9668 | |
| IoU | U-Net | 0.8646 | 0.8652 | 0.8883 | 0.8266 | 0.7745 | 0.9205 | 0.9555 | 0.9171 | 0.9001 |
| SegNet | 0.8133 | 0.7922 | 0.8277 | 0.7425 | 0.7009 | 0.8790 | 0.8715 | 0.7554 | 0.8422 | |
| VEDAM | 0.9075 | 0.9168 | 0.9299 | 0.8658 | 0.7988 | 0.9496 | 0.9683 | 0.9688 | 0.9357 | |
| mIoU | U-Net | 0.8792 | ||||||||
| SegNet | 0.8027 | |||||||||
| VEDAM | 0.9157 | |||||||||
| Kappa | U-Net | 0.9129 | ||||||||
| SegNet | 0.8727 | |||||||||
| VEDAM | 0.9450 | |||||||||
| Paddy Field | Irrigated Land | Dry Cropland | Garden Plot | Arbor Woodland | Shrub Land | Natural Grassland | Artificial Grassland | ||
|---|---|---|---|---|---|---|---|---|---|
| ACC | U-Net | 0.9972 | 0.9818 | 0.9973 | 0.9989 | 0.9930 | 0.9992 | 0.9984 | 0.9986 |
| SegNet | 0.9951 | 0.9679 | 0.9916 | 0.9984 | 0.9905 | 0.9992 | 0.9977 | 0.9987 | |
| VEDAM | 0.9982 | 0.9884 | 0.9984 | 0.9993 | 0.9962 | 0.9996 | 0.9991 | 0.9996 | |
| Recall | U-Net | 0.9477 | 0.9728 | 0.9399 | 0.8711 | 0.9596 | 0.9274 | 0.9384 | 0.9669 |
| SegNet | 0.8866 | 0.9140 | 0.6399 | 0.7579 | 0.9449 | 0.6858 | 0.9152 | 0.8823 | |
| VEDAM | 0.9656 | 0.9746 | 0.9548 | 0.9337 | 0.9697 | 0.9717 | 0.9582 | 0.9750 | |
| Precision | U-Net | 0.9483 | 0.9487 | 0.9313 | 0.8823 | 0.9238 | 0.7396 | 0.9136 | 0.8005 |
| SegNet | 0.9287 | 0.9432 | 0.9375 | 0.8778 | 0.8987 | 0.9238 | 0.8780 | 0.8670 | |
| VEDAM | 0.9687 | 0.9745 | 0.9679 | 0.9248 | 0.9663 | 0.8735 | 0.9590 | 0.9408 | |
| F-score | U-Net | 0.9480 | 0.9606 | 0.9356 | 0.8767 | 0.9413 | 0.8229 | 0.9258 | 0.8759 |
| SegNet | 0.9071 | 0.9283 | 0.9607 | 0.8135 | 0.9212 | 0.7872 | 0.8962 | 0.8760 | |
| VEDAM | 0.9671 | 0.9745 | 0.9613 | 0.9292 | 0.9680 | 0.9199 | 0.9586 | 0.9576 | |
| IoU | U-Net | 0.9011 | 0.9242 | 0.8790 | 0.7804 | 0.8891 | 0.6991 | 0.8619 | 0.7792 |
| SegNet | 0.8300 | 0.8663 | 0.6138 | 0.6856 | 0.8540 | 0.6491 | 0.8120 | 0.7794 | |
| VEDAM | 0.9364 | 0.9503 | 0.9254 | 0.8678 | 0.9380 | 0.8518 | 0.9205 | 0.9186 | |
| mIoU | U-Net | 0.8393 | |||||||
| SegNet | 0.7613 | ||||||||
| VEDAM | 0.9136 | ||||||||
| Back Ground | Industrial Land | Urban Residential | Rural Residential | Traffic Land | Vegetation | River | Lake | Pond | ||
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | VEDAM | 0.9644 | 0.9961 | 0.9936 | 0.9949 | 0.9930 | 0.9815 | 0.9988 | 0.9994 | 0.9987 |
| VEDAM w/o SAM | 0.9600 | 0.9956 | 0.9929 | 0.9939 | 0.9924 | 0.9789 | 0.9985 | 0.9993 | 0.9983 | |
| VEDAM-CAM | 0.9613 | 0.9958 | 0.9932 | 0.9946 | 0.9929 | 0.9794 | 0.9987 | 0.9994 | 0.9983 | |
| VEDAM-CBAM | 0.9621 | 0.9958 | 0.9932 | 0.9949 | 0.9931 | 0.9797 | 0.9986 | 0.9993 | 0.9980 | |
| Recall | VEDAM | 0.9468 | 0.9599 | 0.9622 | 0.9223 | 0.9314 | 0.9746 | 0.9890 | 0.9892 | 0.9725 |
| VEDAM w/o SAM | 0.9310 | 0.9509 | 0.9592 | 0.9323 | 0.9360 | 0.9777 | 0.9903 | 0.9728 | 0.9658 | |
| VEDAM-CAM | 0.9503 | 0.9434 | 0.9573 | 0.9118 | 0.8946 | 0.9712 | 0.9756 | 0.9831 | 0.9632 | |
| VEDAM-CBAM | 0.9413 | 0.9578 | 0.9687 | 0.9340 | 0.9187 | 0.9729 | 0.9910 | 0.9883 | 0.9222 | |
| Precision | VEDAM | 0.9562 | 0.9533 | 0.9652 | 0.9339 | 0.8487 | 0.9737 | 0.9788 | 0.9792 | 0.9611 |
| VEDAM w/o SAM | 0.9592 | 0.9512 | 0.9607 | 0.9013 | 0.8315 | 0.9638 | 0.9702 | 0.9866 | 0.9526 | |
| VEDAM-CAM | 0.9449 | 0.9625 | 0.9656 | 0.9355 | 0.8712 | 0.9712 | 0.9880 | 0.9856 | 0.9547 | |
| VEDAM-CBAM | 0.9552 | 0.9495 | 0.9557 | 0.9233 | 0.8609 | 0.9704 | 0.9709 | 0.9744 | 0.9778 | |
| F-score | VEDAM | 0.9515 | 0.9566 | 0.9637 | 0.9281 | 0.8882 | 0.9742 | 0.9839 | 0.9842 | 0.9668 |
| VEDAM w/o SAM | 0.9449 | 0.9511 | 0.9599 | 0.9165 | 0.8807 | 0.9707 | 0.9802 | 0.9796 | 0.9592 | |
| VEDAM-CAM | 0.9476 | 0.9529 | 0.9614 | 0.9235 | 0.8827 | 0.9712 | 0.9818 | 0.9843 | 0.9590 | |
| VEDAM-CBAM | 0.9482 | 0.9536 | 0.9622 | 0.9286 | 0.8889 | 0.9717 | 0.9809 | 0.9813 | 0.9492 | |
| IoU | VEDAM | 0.9075 | 0.9168 | 0.9299 | 0.8658 | 0.7988 | 0.9496 | 0.9683 | 0.9688 | 0.9357 |
| VEDAM w/o SAM | 0.8956 | 0.9067 | 0.9230 | 0.8459 | 0.7868 | 0.9430 | 0.9611 | 0.9601 | 0.9216 | |
| VEDAM-CAM | 0.9005 | 0.9100 | 0.9257 | 0.8579 | 0.7901 | 0.9440 | 0.9642 | 0.9692 | 0.9212 | |
| VEDAM-CBAM | 0.9015 | 0.9114 | 0.9271 | 0.8668 | 0.8000 | 0.9449 | 0.9625 | 0.9633 | 0.9033 | |
| mIoU | VEDAM | 0.9157 | ||||||||
| VEDAM w/o SAM | 0.9049 | |||||||||
| VEDAM-CAM | 0.9092 | |||||||||
| VEDAM-CBAM | 0.9090 | |||||||||
| Kappa | VEDAM | 0.9450 | ||||||||
| VEDAM w/o SAM | 0.9379 | |||||||||
| VEDAM-CAM | 0.9402 | |||||||||
| VEDAM-CBAM | 0.9415 | |||||||||
| Paddy Field | Irrigated Land | Dry Cropland | Garden Plot | Arbor Woodland | Shrub Land | Natural Grassland | Artificial Grassland | ||
|---|---|---|---|---|---|---|---|---|---|
| ACC | VEDAM | 0.9982 | 0.9884 | 0.9984 | 0.9993 | 0.9962 | 0.9996 | 0.9991 | 0.9996 |
| VEDAM w/o SAM | 0.9981 | 0.9871 | 0.9983 | 0.9993 | 0.9953 | 0.9994 | 0.9989 | 0.9995 | |
| VEDAM-CAM | 0.9978 | 0.9871 | 0.9984 | 0.9991 | 0.9958 | 0.9992 | 0.9990 | 0.9994 | |
| VEDAM-CBAM | 0.9979 | 0.9870 | 0.9985 | 0.9990 | 0.9955 | 0.9994 | 0.9990 | 0.9996 | |
| Recall | VEDAM | 0.9656 | 0.9746 | 0.9548 | 0.9337 | 0.9697 | 0.9717 | 0.9582 | 0.9750 |
| VEDAM w/o SAM | 0.9601 | 0.9796 | 0.9494 | 0.9284 | 0.9740 | 0.9756 | 0.9462 | 0.9614 | |
| VEDAM-CAM | 0.9414 | 0.9703 | 0.9578 | 0.9392 | 0.9681 | 0.9709 | 0.9513 | 0.9635 | |
| VEDAM-CBAM | 0.9668 | 0.9669 | 0.9675 | 0.9488 | 0.9764 | 0.9846 | 0.9579 | 0.9701 | |
| Precision | VEDAM | 0.9687 | 0.9745 | 0.9679 | 0.9248 | 0.9663 | 0.8735 | 0.9590 | 0.9408 |
| VEDAM w/o SAM | 0.9706 | 0.9645 | 0.9673 | 0.9193 | 0.9474 | 0.7859 | 0.9509 | 0.9351 | |
| VEDAM-CAM | 0.9773 | 0.9728 | 0.9636 | 0.8836 | 0.9608 | 0.7254 | 0.9529 | 0.9128 | |
| VEDAM-CBAM | 0.9553 | 0.9757 | 0.9597 | 0.8595 | 0.9480 | 0.7768 | 0.9508 | 0.9485 | |
| F-score | VEDAM | 0.9671 | 0.9745 | 0.9613 | 0.9292 | 0.9680 | 0.9199 | 0.9586 | 0.9576 |
| VEDAM w/o SAM | 0.9653 | 0.9720 | 0.9583 | 0.9239 | 0.9605 | 0.8705 | 0.9485 | 0.9480 | |
| VEDAM-CAM | 0.9590 | 0.9715 | 0.9607 | 0.9105 | 0.9645 | 0.8304 | 0.9521 | 0.9375 | |
| VEDAM-CBAM | 0.9610 | 0.9713 | 0.9635 | 0.9019 | 0.9620 | 0.8684 | 0.9543 | 0.9592 | |
| IoU | VEDAM | 0.9364 | 0.9503 | 0.9254 | 0.8678 | 0.9380 | 0.8518 | 0.9205 | 0.9186 |
| VEDAM w/o SAM | 0.9329 | 0.9455 | 0.9199 | 0.8585 | 0.9240 | 0.7707 | 0.9021 | 0.9012 | |
| VEDAM-CAM | 0.9212 | 0.9447 | 0.9243 | 0.8358 | 0.9313 | 0.7100 | 0.9086 | 0.8823 | |
| VEDAM-CBAM | 0.9250 | 0.9442 | 0.9297 | 0.8214 | 0.9268 | 0.7674 | 0.9126 | 0.9215 | |
| mIoU | VEDAM | 0.9136 | |||||||
| VEDAM w/o SAM | 0.8944 | ||||||||
| VEDAM-CAM | 0.8823 | ||||||||
| VEDAM-CBAM | 0.8936 | ||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Zhao, M.; Xing, Y.; Zeng, F.; Sun, Z. VEDAM: Urban Vegetation Extraction Based on Deep Attention Model from High-Resolution Satellite Images. Electronics 2023, 12, 1215. https://doi.org/10.3390/electronics12051215
Yang B, Zhao M, Xing Y, Zeng F, Sun Z. VEDAM: Urban Vegetation Extraction Based on Deep Attention Model from High-Resolution Satellite Images. Electronics. 2023; 12(5):1215. https://doi.org/10.3390/electronics12051215
Chicago/Turabian StyleYang, Bin, Mengci Zhao, Ying Xing, Fuping Zeng, and Zhaoyang Sun. 2023. "VEDAM: Urban Vegetation Extraction Based on Deep Attention Model from High-Resolution Satellite Images" Electronics 12, no. 5: 1215. https://doi.org/10.3390/electronics12051215
APA StyleYang, B., Zhao, M., Xing, Y., Zeng, F., & Sun, Z. (2023). VEDAM: Urban Vegetation Extraction Based on Deep Attention Model from High-Resolution Satellite Images. Electronics, 12(5), 1215. https://doi.org/10.3390/electronics12051215