1. Introduction
With the rapid development of computer technology, text detection and recognition in natural scenes stands out. It has attracted much attention in engineering applications [
1,
2]. Inspired by target detection, scene text detection has convincing performance advantages. It is also a research hotspot in the field of optical character recognition. It has become a hot development trend in today’s society, especially in the context of the rapid development of artificial intelligence [
3,
4,
5,
6,
7], It has become a necessity for the development of science and technology in the future, and has brought a revolutionary impact to the production and life of society [
8,
9,
10,
11]. Nowadays, with the rapid development of AI, it has gradually become integrated into all walks of life, bringing convenience to human life. One of the most novel, and closely integrated, means for AI is the text recognition method, based on natural scenes.
Text recognition, based on natural scenes, has been one of the hottest research projects in recent years. The rich text information in the images of specific scenes is of great significance for the understanding of the scene. Text is the cornerstone of human civilization, the crystallization of human wisdom, is a symbol to record human practice in social life [
12,
13], plays an indispensable role in the transmission of information, and is an important link connecting the world. The information transmitted by text breaks through the limits of space and time. Unlike society in the old era, the presentation of text is mostly saved and transmitted by paper materials. In today’s real social life, people have long been surrounded by text images with rich semantic information. If we only rely on human eyes to capture the complex text for extraction and analysis, manpower and time are highly consumed. Modern society has slowly entered the era of information technology. An increasing number of text images of specific scenes are widely disseminated and stored through the Internet. The digitization of images and the symbolization of texts enable people to realize the production, storage, dissemination and sharing of multimedia information at any time through the Internet. A large number of texts are saved in the form of documents, images or video data. Text images have also been greatly expanded by people’s creativity and editing. Therefore, the propagation speed and amount of information have increased rapidly and are in explosive growth, resulting in massive images and text content being piled up and becoming redundant. Since text is highly refined and can express rich and accurate semantic information, in some complex scenarios, a few simple indicative slogans can help people better understand the useful information contained in text images. The information can have enlightening value, enabling people to correctly understand and analyze specific scenes, and can have important significance in decision-making. With the rapid development of deep learning, this technology has also made breakthrough progress in the field of images. The ability to extract and recognize text in an image has continuously improved, and its performance and efficiency have also significantly improved. It has a very wide range of applications and has been promoted. It is used for image or video retrieval in intelligent transportation systems, real-time translation, and robot navigation. It provides effective additional information in practical application scenarios, such as in a blind guidance system for the visually impaired and industrial automation. On the one hand, it can improve the efficiency of various application scenarios, such as license plate recognition. The traffic management bureau can quickly detect license plate information of identified vehicles, and then judge whether the vehicle has a violation record. The packaging identification of goods, through identifying the text information on the packaging of goods, can track and locate the goods in an unmanned supermarket. In the scene of unmanned automatic driving, the road direction information is extracted by recognizing the text on the road sign, an, thus, assisting the navigation system to provide accurate guidance. The technology of machine recognition of image text has also become mature, which can make the relevant technology of text recognition apply to daily life and help people improve their lives. For example, by identifying the advertising information of street stores, the city’s subway transportation route map and the recognition of text information in different languages, people can better adapt to the surrounding environment and travel easily.
In recent years, the problem of text recognition, based on natural scenes, has also attracted extensive attention from all walks of life, and research efforts have increased. Its development can be divided into traditional text detection methods and text detection methods based on deep learning. The traditional text detection method detects the text region according to manually extracted features, and comprises the research method, based on sliding window, and the text detection method, based on connected region. The research method based on sliding window divides the image into multiple regions for detection. Some researchers obtain the characteristics of the text region by using the algorithm in traditional target detection for reference, use the sliding window to detect the possible regions of characters, infer the corresponding characters, according to the prediction scores of these regions, and then use the trained classifier to determine whether it is text, so as to locate the text region, Finally, the text content is obtained by combining the relationship between characters. Some researchers have also proposed an algorithm, based on symmetry, and a multi-mode learning method, based on a mixed linear model, and then extract features through the classifier to get the text region. The principle of a text research algorithm, based on sliding window, is simple, and can reduce the situation of adjacent text adhesion. However, the time complexity is high, and it requires sufficient computational power. How to set the step size and step length of the sliding window is a critical problem. If the window is too large, this affects the detectability, resulting in over-segmentation, and if it is too small, this results in too many detected areas, resulting in under-segmentation, and, ultimately, reduction in the robustness of text detection. The text detection method based on connected regions first gathers the pixels of the image into different connected components, according to the low-level characteristics of the image, and then obtains the connected regions of the text through the width and color of the characters. It also needs to judge these connected components through the classification model, filter out the noise areas, and, finally, combine the connected regions for application. In [
14], the authors address the problem of fast arbitrary shape text detection and propose using concentric masks to fit arbitrary shape text contours in an effective and robust manner. This encourages the network to learn more discriminative features related to concentric masks from multiple angles without additional computational costs. In [
15], the authors propose an end-to-end text recognition framework by mining the internal synergy of scene text detection and recognition, reducing the computational cost, and achieving good results on multiple complex data sets. In [
16], the authors propose scale-aware data enhancement technology to increase the diversity of training samples, effectively alleviating the dilemma of limited training data, and use shape similarity constraint technology to model the global shape structure of arbitrary shape scene text and background, from the perspective of loss function, which is helpful to locate the more accurate boundary of arbitrary shape scene text. The effectiveness of the algorithm was proved by experiments. In addition, optical character recognition (OCR) technology is also relatively mature. Its function is to extract text characters from the scanned document, and then carry out preprocessing and binarization on the image, respectively. Then, character segmentation on the detected text outline and the position of each text at the edge is conducted, and, finally, the recognition results of the separated single text character image integrated to obtain the final complete result. OCR has solved the problems of regular image text well, such as the recognition and digital archiving of scanned and printed text. However, with the development of digital multimedia, the media carrying text information is more complex. Traditional regular text and handwriting, as well as billboards, trademarks and other forms widely existing in natural scenes are rich. Images with complex image backgrounds are quite different. In addition, perspective, distortion, and confusion of texture information may also occur in the actual process of image acquisition. This also causes low accuracy of text location recognition.
Based on some limitations of traditional methods, in the following, we explain our proposed solutions in detail and solve them in detail. The contributions of this paper can be summarized in the following three aspects:
- (1)
By using the end-to-end model framework, we cascade the detection and recognition tasks together and complete them in the same algorithm, to prevent the cumulative transition caused by too many errors generated by previous modules. This leads to a large error detection, reduces manual pre-processing and subsequent processing, takes the model from the original input to the final output as much as possible, gives the model more space that can be automatically adjusted according to the data, and increases the overall fit of the model. The overall scale is smaller, faster and more real-time.
- (2)
We also integrate the multi-scale attention mechanism module to improve the processing ability of text detection and recognition, improve the attribute of feature extraction, distribute the attention of different scale features according to the weight, obtain the attention features of different scale feature maps, increase discrimination and ability to capture details of text information, and combine the feature pyramid (FPN) idea to design a multi-scale attention (MA) network module, This can suppress noise information in the text background and enhance the detection and recognition of important text information.
- (3)
We enrich the text features to be detected by combining the convolutional neural network (CNN) [
17] with the end-to-end algorithm and the multi-scale attention efficient deep learning network (EE-ACNN), which has certain invariance for the position and size of the text, expands its receptive field, produces good robustness for effective natural scene text information, and improves the recognition performance. We carried out experiments on text data sets to prove the feasibility of the method.
The logical structure of this paper is as follows.
In
Section 2, we introduce the relevant work, describe the research methods, and discuss the text detection methods based on deep learning. In
Section 3, we introduce the main methods of this paper, such as the architecture of CNN, the end-to-end framework and the fusion of multi-scale attention mechanism, and show the pseudocode of the whole algorithm. In
Section 4, we address the experimental part, show the experimental results, and conduct a comparative experiment, In
Section 5, we describe the methodology of this paper, discuss methods of recent years, and explain the shortcomings of the method. In
Section 6, we summarize the methods, and address prospects for future work.
2. Related Work
On the basis of previous methods, we combine the end-to-end model framework, multi-scale attention mechanism and CNN to carry out efficient text recognition tasks for natural scenes.
The task of text recognition is actually a multi-classification task, based on obtaining the results of text detection, converting the text information in the image into data information that can be understood and processed by a computer system, and, finally, presenting it to the public for visual display. The main research methods are the bottom-up text recognition method, based on a single character, and the top-down analysis method, based on sequential text pattern. In the recognition method based on a single character, the area to be recognized by text adopts the bottom-up analysis method, and the bottom-up method is the character-level text recognition method. The problem of text recognition detection is regarded as a series of sub-tasks, such as the region location of a single character, the classification of characters in the region and the language splicing of all characters. First, each character in the text region should be cut and classified separately. Then, it is fed into the designed feature extractor and text classifier to recognize each character. By combining the solutions of the above sub-tasks, the text character to be recognized is finally obtained and each text character is connected into a string. For each sub-task, different scholars have adopted different methods, forming a series of different methods. When classifying, we need to use a classifier with good performance. We also need to classify it into a character or text line through heuristic rules, language models or dictionaries, and then use the pre-trained classifier (Support Vector Machine) SVM to classify and recognize. Some scholars also try to deal with multiple types and fonts of characters through adaptive learning of character feature representation. For example, [
18] adopts the heuristic rules designed to form the recognized single character into the target text sequence. Some researchers use the Hough transform with the random forest classifier to capture the bottom sub-structure of characters with different granularity through strokes. This method is applicable to variant languages, but is not sensitive to the impact of noise. The recognition accuracy of these bottom-up methods mainly depends on the accurate location of the character text area and a high-precision character classifier, and, in the face of low-resolution images, the character background is complex and difficult to distinguish. In the context of multiple character fonts, the poor generalization and robustness of this single character recognition pattern is exposed, resulting in a sharp decline in recognition performance. For this reason, researchers use a set of features with high computational cost, such as aspect ratio and hole area, for training, and use sliding window with HOG descriptor for training. Text recognition methods based on the character level often need to rely on a large number of character data sets for training, so as to obtain better recognition results. Some researchers introduced the deep convolution network into the field of text research, input the cut character image into the model for feature training, and compared the final output with a fixed dictionary file to obtain the word. However, text recognition based on the character level needs to learn the feature information of different characters. The process is complex and there is the possibility of missing characters in the recognition process. Most traditional methods use manual design features, but these features are limited for high-level representation, and experts in related fields often need to spend a lot of time observing the data, which is not universal. In the top-down analysis method, based on sequential text pattern, the text image to be recognized needs to be considered as a whole, without the need to segment, detect and locate the characters. The global features of the input image are directly extracted, and predictive recognition performed. Compared with the recognition of individual characters, this method makes better use of the global information to judge. In previous research, some researchers proposed a synthetic scene text recognition database, MJSynth, and used CNN classification to output the input image, rendering the words into the image, and treating each word as a separate category, with about 90,000 category words. That is to say, the essence of this method is to equate recognition to a multi-classification task of a large number of labels, However, when the text characters to be recognized are not included in the preset categories, the correct results cannot be obtained, the problem of compound word recognition in the natural scenes cannot be solved, and the problem of high computational time has to be faced. This method can only effectively identify the categories of words in the dictionary. Some researchers proposed the deep text loop network DTRN, which transforms text recognition into a label sequence problem. The above text detection and recognition algorithms, based on traditional image processing, have a relatively complex overall structure, requiring artificial design of features, classifiers and subsequent processing algorithms, and appear to be less robust in the face of complex natural scene images.
In recent years, with the rapid development of deep learning [
19,
20,
21,
22,
23,
24,
25,
26], the accuracy of text recognition, based on deep learning, has greatly improved, compared with traditional text recognition methods, achieving a qualitative leap. The commonly used methods include correction-based recognition methods, attention-based recognition methods, and sequence-based recognition methods. The text in the natural scene is not completely presented in front of people, and there are also many situations that lead to inaccurate recognition. Therefore, in order to deal with the distortion, bending and distribution of the text in natural scenes, as well as the distortion of the text perspective when collecting images, in recent years researchers have proposed a series of methods and designed a deep learning correction algorithm for irregular text [
27]. However, this method has the disadvantage of weak generalization ability for small samples and low-frequency errors. Some researchers have also proposed STN network [
28] and MORN network [
29] to correct bent and deformed text. The STN network corrects text by using TPS transform and relies on a sampler to correct irregular text. The MORN network trains the offset of each part of a learning image by using a weak supervision method, samples according to the predicted offset, and obtains the corrected text image. However, this method may not be able to handle nonlinear text deformation, such as bending deformation, caused by paper deformation or shooting angle. With the remarkable success of attention mechanism in machine translation [
30], more and more scholars have also applied it to text recognition. Unlike the traditional coder–decoder framework, its input sequence can only be encoded into a fixed-length vector, while the decoding is based on the attention mechanism; that is, the text recognition task is regarded as a text translation task. The attention mechanism is combined with the Recurrent Neural Network (RNN) to build a prediction module. By using the attention mechanism, the sequence composed of variable length vectors can be output, more data details can be obtained, and a longer input sequence can be reasonably represented. The attention mechanism learns the alignment between the input instance image and the output text sequence by referring to the historical information of the target character and the encoded feature vector. However, there are problems, such as high computational complexity, which may lead to the slow running speed of the model and excessive attention to some noise, or abnormal information when processing a long sequence, resulting in the model over-fitting the training data. The method based on attention mechanism, proposed in [
31], gives different weights to the input at each moment of sequence decoding in the framework of a coding recognition network, extracts richer context information, and improves recognition performance. Some researchers have developed a framework based on a 2D attention mechanism for irregular text recognition [
32]. Instead of coding and decoding, the irregular text recognition task is converted into a character segmentation task through a complete convolutional neural network [
33]. However, the computational complexity is high, especially when processing high-resolution images, which may lead to slow running speed of the model and usually necessitates the specific position of each text in the image. Some researchers have proposed a recursive neural network based on attention mechanism. The recursive neural network decodes the image features extracted from the convolution layer into output characters, mainly used for text recognition in non-dictionary scenes. However, there may be problems, such as gradient disappearance or gradient explosion, and the data quality has a great impact on the performance of the model. The authors of [
34] propose network and attention modeling for text recognition in non-lexical scenes. This model first extracts the encoded image features from the input image through a recursive convolution layer, and then decodes it into output characters through a character-level language statistical recursive neural network with implicit learning. However, there is a disadvantage in insufficient use of text paragraphs and context information. The decoding algorithm based on the attention mechanism has a very good effect on the generation of irregular and curved text sequences, but it cannot learn the sequence relationship in the sequence. Although the method based on the attention mechanism has made great breakthroughs, there are still problems, such as high computational cost and difficulty in training convergence, and the decoding method needs to calculate the alignment relationship between the text image features and the predicted characters. Therefore, there is also a drift phenomenon, bringing extra storage overhead. If alignment errors occur, the accuracy of subsequent text recognition is also reduced. At the same time, the coupling between the attention module and the decoder is too high, resulting in error propagation and poor performance on vertical text.
3. Method
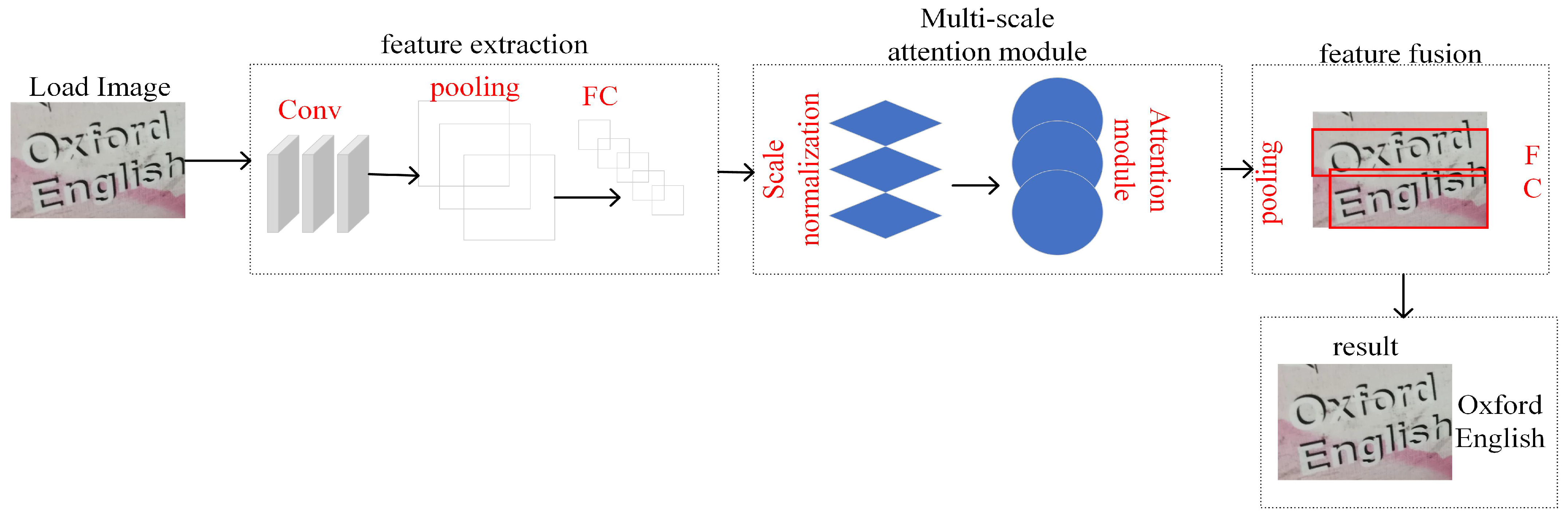
The overall algorithm module of this paper can be divided into the following three parts:
(1) CNN-based architecture; (2) End-to-end frame; (3) Fusion of multi-scale attention mechanism. The algorithm flow chart of this paper is shown in
Figure 1:
3.1. CNN’s Architecture
According to the different learning units, the deep learning model system can be roughly divided into three categories: automatic coding classifier (AE), deep confidence network (DBN) and convolutional neural network (CNN). Research shows that CNN, with its stronger learning ability, is more suitable for processing multi-dimensional vector data, so it is more often used in the classification and recognition of text images and videos [
35]. At the same time, convolution neural network is also one of the representative algorithms in deep learning. It is a feedforward neural network that includes convolution calculation and has a depth structure. This network is very suitable for processing one-dimensional time-domain sequence data and image data. Compared with other neural networks, CNN can perform efficient and fast learning on original data, has the ability of representation learning, and is widely used in computer vision, natural language processing and other fields. Convolutional neural network is a cognitive structure that mimics the information of the human brain. It is composed of multiple neurons. The connection between different neurons is complicated. It adopts a system structure of incomplete connection and is composed of several processing layers with different functions. Compared with traditional neural network, it has stronger ability in distinguishing features and has higher accuracy. The basic components of the traditional multi-layer neural network include input layer, hidden layer and output layer. The convolutional neural network divides the hidden layer of the traditional multi-layer neural network into multiple convolutional layers, pooling layers (also known as lower sampling layers) and activation layers, which deepen the number of layers of the neural network. In order to achieve the classification function, a fully connected layer (FC Layer) is also set as the final output layer. It can perform loss calculation and provide output classification results. The advantage of convolutional neural network is that it does not need to extract image features manually, and it has stable performance after full training. The image is input into the convolutional neural network through the input layer. The convolution in the convolution layer checks the input image for convolution operation, and generates the corresponding feature map. The lower sampling layer performs local feature extraction on the feature map generated after the upper convolution and a sub-sampling feature map is generated. Using multiple convolution layers and pooling layers to extract image features can effectively avoid the limitations and subjectivity of artificial feature extraction, making the model more adaptable to rotated and distorted images, and saving on the pre-processing process before image recognition, which can simplify the process of image recognition. Common CNN network models are composed of input layer (Input), convolution layer (Conv), activation function (ReLU), normalization (Norm), pooling layer (Pooling), full connection layer (FC), and so on. The following describes each part in detail.
3.1.1. Convolution Layer
The convolution layer is composed of several convolution units (Filter, also known as convolution core). The convolution core is used as a filter. Each filter extracts a specific feature. The parameters of each convolution unit are optimized by the back-propagation algorithm in the training stage; that is, given a group of input images, the convolution core scans each image in turn, and the resulting number is the weight. When a convolution of the convolution layer checks the different areas of the input layer for convolution, the weight value of the convolution kernel is unchanged; that is, a convolution kernel is only used to extract the same feature at different locations in the previous layer of a network. If the convolution kernel scans the same location of all the images, the weight value obtained is called weight sharing. Through the translation of the convolution unit on the image and the convolution operation, the product of the value of each pixel point on the image and the convolution kernel is added with bias, and then, through the operation of the activation function, a feature map of the input image is obtained. Therefore, the function of the convolution layer is mainly to extract the eigenvalues of the features in a range. After using different filters for the convolution operation, the eigenvalues of the same image can be extracted multiple times without causing excessive increase in the amount of data. It can better decompose and utilize the eigenvalues of the image. On this basis, combining it with a nonlinear activation function can better remove the redundancy of the data. This can not only reduce the number of network parameters, but also make the whole network obtain better robustness. The principle of calculating convolution is shown in Formula (1):
where,
represents the output of the convolution,
l represents the number of network layers,
i,
j represents the output of the convolution of the
i-th row and the
j-th column of the input image after the convolution of the
l-th layer,
represents the activation function, ∗ represents the activation operator of the convolution,
represents the
i-th row and the
j-th column of the input image of the
l-th layer, when
m is 0, accumulation begins,
represents the weight of the
m-th row and the
n-th column of the convolution kernel of the
l-th layer, and
represents the offset term of the function. Synchronized with layer
l, row
i and column
j,
represents the offset unit.
The convolution process of the convolution layer is shown in
Figure 2. The size of the input image was 5 × 5 and 3 × 3. A convolution kernel of 3 was used for the convolution operation. The step size was 1. The convolution layer was used as the feature extraction layer. The convolution operation was used to enhance the original face features and reduce the noise. After the convolution operation, the size was 3 × 3.
3.1.2. Pooling Layer
A pooling layer is also called a down-sampling layer. The more convolution cores, the more parameters, and the larger the dimension of the convolution layer, and, thus, the greater the complexity. Here we need to reduce the dimension of the convolution layer, so we must introduce a pooling layer that can reduce the dimension into the convolution network. In fact, pooling is also a kind of down-sampling, mainly for the secondary feature extraction of the feature map extracted from the previous convolution layer. By removing the unimportant sample information from the feature graph, the number of parameters is further reduced, so as to reduce the amount of computation. Although the pooling layer reduces the size of the image and loses some image information, it increases the perception field of vision, and, at the same time, enhances the robustness, and can also avoid the occurrence of over-fitting. The calculation formula of the pooling layer is as follows (2):
where,
is the pooled output feature map,
is the pooled input feature map,
is the sum of weighted input features, and
is the pooled function. The role of the pooling layer is to use the pooling function to carry out the overall output of the adjacent features, and obtain approximately unchanged results, while further improving the efficiency of the network. Generally, there are two pooling methods: maximum pooling and average pooling. Maximum pooling refers to taking the maximum convolution characteristic value as the obtained pooling characteristic value in the pooling area. Average pooling refers to taking the average of all convolution eigenvalues in the pooling area as the pooling eigenvalues, as shown in
Figure 3. The maximum pooling method was adopted in this paper, and the input was a 4 × 4 matrix, the convolution core size was 2 × 2, and the step size was 2. We used the formula to calculate the output size of the maximum pooling layer, and then conducted the two-dimensional maximum pooling process for each channel.
3.1.3. Normalization
In the neural network, each neuron has its own corresponding input and output, and the activation function represents the functional relationship between the two. In CNN, the nonlinear function is used as the activation function, but the gradient vanishing problem often occurs in training, which makes the effect less than expected. To solve this problem, we used the linear correction function, ReLu, as the activation function to improve the nonlinear ability of the model. When the gradient of the ReLu function is greater than 0, the value is 1, and the gradient remains unchanged, which can solve the problem and achieve an ideal training effect. In order to prevent problems, such as a sudden drop of convergence speed and disappearance of gradient during training, we normalize the network model to solve this problem. The essence of normalization is smooth operation, as shown in Formula (3):
where,
represents the normalized activation value of ReLU module in row
i and column
j,
represents the activation value in row
i and column
j of layer
l,
N represents the total convolution times, while
represents the average activation value,
represents the variance, and
represents the minimum value in the process.
3.1.4. Full Connection Layer
The full connection layer plays the role of “classifier” in the whole CNN, and can integrate and normalize the abstracted features obtained from the previous layers to obtain a highly purified feature classification probability. In the convolution neural network, a full connection layer is added between the last convolution layer and the output layer. This layer converts the final output of the convolution layer into a one-dimensional data sequence. Each element in the data sequence corresponds to a neuron, and connects with each neuron in the next layer by weight. The convolution layer, pooling layer and activation function layer map the original image data to the hidden layer feature space for representation. The full connection layer maps the learned “distributed feature representation” to the sample marker space. The full connection layer is mainly used to re-fit the features, which can reduce the loss of feature information, and then the Softmax function is used to classify, with the following definitions, as shown in Formulae (4) and (5):
where,
,
represents hidden feature,
,
is paranoid,
,
indicates the activation value of the
function. Its structure is shown in
Figure 4:
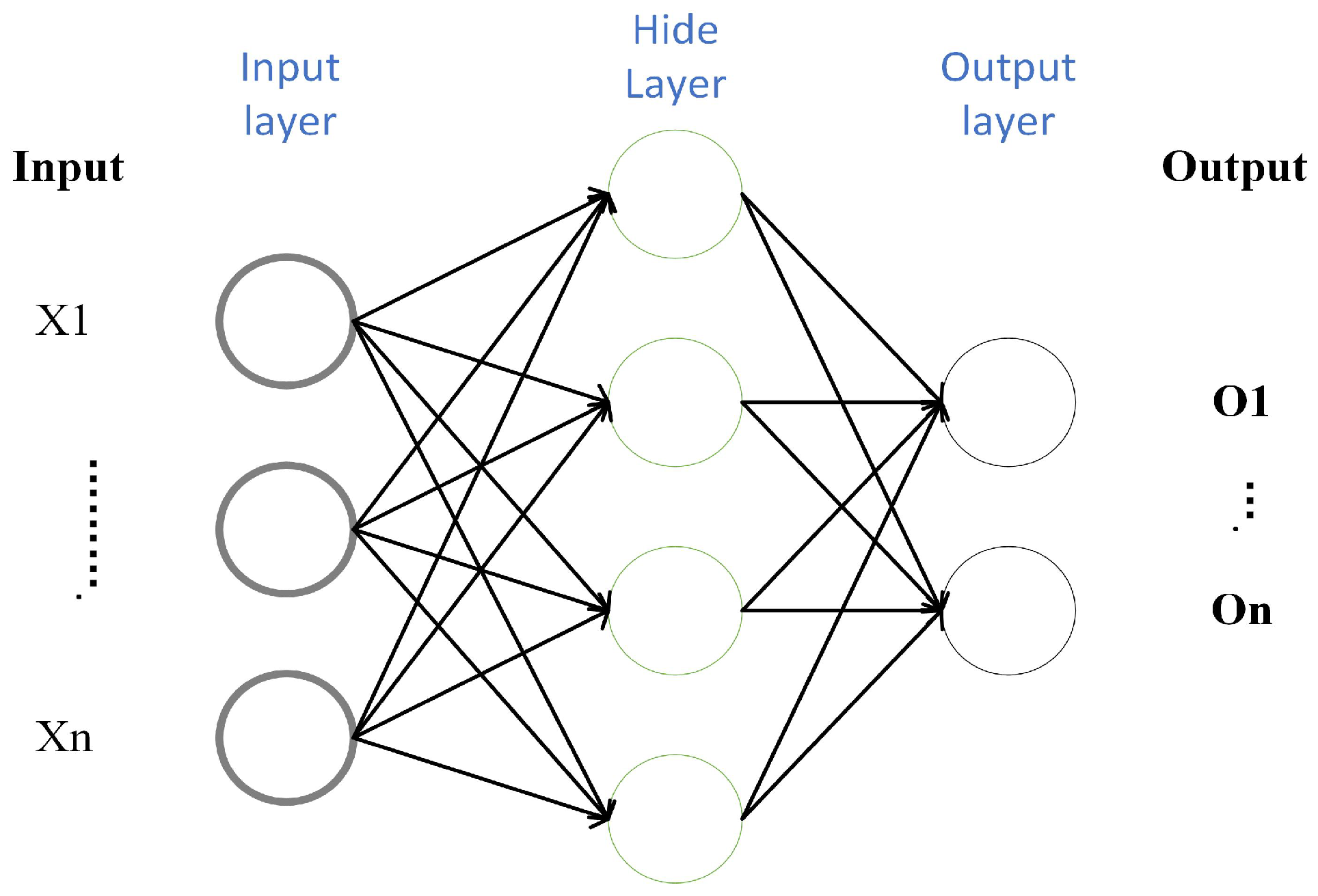
3.2. End-to-End Joint Architecture
The end-to-end framework principle of deep learning refers to transferring data from the input layer to the output layer, which is realized through a multi-layer neural network. The end-to-end framework is shown in
Figure 5. First, the original data is input into the network, and then, after a series of processing, the data is finally output to the output layer, so as to achieve the purpose of in-depth learning. It can extract features from the original data and use these features for prediction and classification. The core idea of the end-to-end framework is to map input data to output results without human intervention. The structure of the end-to-end framework usually includes the input layer, the hidden layer and the output layer. The input layer inputs the original data into the network, the hidden layer processes the input data, and the output layer outputs the processed data into the result. During the training process, the end-to-end framework continuously adjusts the network parameters according to the training data to achieve the optimal results. The advantage of the end-to-end framework is that it can effectively extract features, and can automatically complete feature extraction and classification without human intervention. In general, the end-to-end framework principle of deep learning is an effective machine learning technology to achieve the purpose of deep learning. We need to implement end-to-end quantitative parameter optimization methods, and use CNN as the backbone network to perform feature fusion.
The CNN network, inspired by the human visual nervous system, developed rapidly, and has natural advantages in image feature extraction. Mature models, based on CNN, such as LeNet5, VGG-Net and ResNet, have shown very good results in image recognition, image classification and other image fields. Therefore, in order to solve the problem of text recognition in natural scenes, the main part of this paper adopts the method of combining end-to-end and CNN. The input is the text image to be detected, and takes advantage of the image feature extraction advantages of CNN. Through gradually learning to extract features that can more fully represent the complexity of the image, the image features extracted by CNN combine the end-to-end features for detection.
We take the text image in the training data set as the input of the model. In view of the problem that the edge details of the text image are lost during detection, this paper proposes a new loss function to evaluate the model, as shown in Formula (6):
where,
represents the loss function,
N represents the total number of times,
represents the weight of each connection, and
represents the predefined real results in the dataset sample.
3.3. Multi-Scale Attention Mechanism
Deep learning attention mechanism is an effective machine learning technology, which can help the model better understand the input data. Its core idea is that the model can extract important features from the input data through automatic learning, and use these features for prediction and classification. The basic principle is that the model can automatically learn a set of weights, according to the different characteristics of the input data, to measure the importance of different features, and then this set of weights can be used to control the attention of the model to different features, so as to achieve better prediction and classification effects. There are many ways to realize the attention mechanism, the most common of which is the attention mechanism based on neural network. The attention mechanism based on neural network can automatically learn a set of weights by calculating the correlation between different features of input data, so as to measure the importance of different features. In addition, the attention mechanism of deep learning can also automatically learn a set of weights by calculating the similarity between different features of input data to measure the importance of different features, so as to achieve better prediction and classification results.
We applied the concept of multi-scale here. The problem of different target sizes and scales has always been one of the main difficulties of text detection in natural scenes. The multi-scale image pyramid is a common improvement scheme. Based on the image pyramid strategy, scale normalization method is applied, but its reasoning speed is slow. Other methods use multi-level features of different spatial resolutions to mitigate scale changes, or directly use the pyramid feature hierarchy proposed by the backbone network as a detector to predict and connect the features of different layers to generate better feature maps for prediction. In order to make up for the lack of semantics in the underlying features, the FPN network proposes a top-down approach to integrate multi-scale features to integrate strong semantic information in high-level features.
The core idea of the attention network module is to find the correlation between them based on the original data, and give different weights according to the importance. The multi-scale attention mechanism is an improvement of the attention mechanism. It reduces the dependence on external information, expands the scale, and is better at capturing the internal correlation of data or features. It can effectively improve the parallelism and efficiency of model training. It can adaptively recalibrate the characteristic response of channels through the interdependencies between explicit modeling channels, and small computational costs can obtain large performance improvements. In view of the diversity of scale changes caused by complex scene transformation and other factors in natural scenes, we adopted the idea of the feature pyramid (FPN), designed a multi-scale attention (MA) network module, and proposed a multi-scale attention network.
In regard to the attention mechanism, we need to perform different scale convolution kernel operations on different images. The multi-scale vector can be expressed as:
, and the calculation formula is:
represents the calculation formula of multi-scale attention. It mentions the concepts of and , which can be used for more detailed feature vectors. represents the vector set.
Through the design of CNN, in order to detect the feature map with both high resolution and strong semantic information in the natural scenes, the network combines the FPN structure that predicts the feature map at each level, based on the feature pyramid. In view of the phenomenon that the target scale is rich and the background is complex, with the different construction scale and location in the electric power construction scenario, this paper designed a multi-scale attention (MA) module, and, in order to alleviate the obstacles caused by the large changes in the target scale, we added the channel attention idea in the process of integration, as shown in
Figure 6:
5. Discussion
In the context of text recognition based on natural scenes, the method we proposed achieved good results under this application scenario. In view of the current social development situation, the current algorithm has low recognition accuracy for low-resolution and fuzzy scene text images, which limits the wide application of text recognition technology to a certain extent. The algorithm of improving image definition and super-resolution provides a solution for low-quality text recognition. In the field of image super-resolution, it is also challenging to apply the general landscape image super-resolution method to the specific scene of text recognition. Many researchers are making efforts to promote the development of text recognition. First of all, the emergence of optical character recognition technology has solved the recognition and digital archiving of printed fonts in scanned images. However, the recognition rate of text characters with curved designs, such as trademarks and billboards widely existing in natural scenes, is low, so researchers abstract the problem into the correction and recognition of irregular text, and conduct targeted research. Some researchers have proposed a deep learning text detection method based on semantic segmentation. Through EAST (Efficient and Accurate Scene Text) model [
43], and using PAVNet [
44] network as the feature extraction network, high-speed and accurate text detection is carried out. However, the small receptive field of this model limits the detection ability of long text objects. Some researchers also proposed a DSTD (Deep Scene Text Detection) detection algorithm that combines region proposal and semantic segmentation. Two branches share the features extracted from the backbone network, two branches predict the information of the text box respectively, and then combine the prediction results of the two branches to output the final prediction results. The PixelLink model, based on instance segmentation, has also been proposed by researchers. This model distinguishes text and non-text regions by classifying pixels, connects pixels in the text region, and obtains the final text box. Most of the content of domestic scene text is mainly in Chinese, which has strong contextual relevance. Therefore, the method of recognizing single characters is not suitable. Although the content and style of domestic scene text are rich, the text outline is mostly rectangular, and the text recognition method of arbitrary shape brings additional calculation costs. The algorithm based on the combination of region proposal and semantic segmentation combines the two algorithms into the same framework. This algorithm builds multiple classifiers, based on region proposal and semantic segmentation, and then fuses the results of each classifier to get the final result. Although the combination of the two ideas achieved better performance, the complexity of the algorithm structure was also greatly increased, which was not conducive to the application of the algorithm. Therefore, this type of algorithm is not the current mainstream research direction.
However, our method also has shortcomings. Due to the increasing complexity of images in natural scenes, the accuracy of text recognition on images needs to be improved. Secondly, before using the dataset, it is often necessary to manually label and cut the dataset images. It takes a lot of time and energy to eliminate the unnecessary parts. Finally, we need to improve it to cover a wider range of disciplines, such as the field of mathematics, etc. The complex algebraic formulae can be accurately identified, such as symbols of basic mathematics, Greek letters, symbols of ordinary letters, operators, arrow symbols, and negation operators, which can provide convenience for scientific researchers, teachers and students.
6. Conclusions
In this paper, we proposed an efficient neural network for text recognition in natural scenes, based on the end-to-end multi-scale attention mechanism, to solve the research problems under natural scenes. We use the end-to-end model framework to link the tasks of detection and recognition and complete them in the same algorithm. We also improve the processing ability of text detection and recognition by integrating the multi-scale attention mechanism module. We improve the attribute of feature extraction, combine the attention features of different branches, obtain the attention features of different scale feature maps, improve the optimization effect of the model, and then enrich the text features to be detected, expand the receptive field, and produce good robustness to effective natural text information through the efficient deep learning network, combining CNN, the end-to-end algorithm and multi-scale attention. We carried out experiments on data sets based on natural scenes to verify the advantages of our method.
In future work, we will continue to improve the scale of the algorithm, continue to optimize it, extend it to multi-disciplinary fields, and integrate features of different scales to carry out large-scale data validation. As this paper only studied English letters and Arabic numerals, and did not extend to other languages, it has certain limitations, and some symbols of complex mathematical formulae in the field of science and engineering could not be accurately identified, which is also a future research direction.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}